
Abstract
In wireless sensor network (WSN), limited energy resources with the nodes is a complex challenge as far as data routing, collecting and aggregating the data is concerned as all these processes are energy demanding. Network lifetime, stability period, and potential of the WSN are some of the parameters which are to be maximized subject to the constraints. The cluster head selection in the heterogeneous wireless sensor network has not been explored much and needs to be improved further to discover the potential of WSN in this area. In this study, optimal cluster head selection in heterogeneous wireless sensor network through Diversity-Driven Multi-Parent Evolutionary Algorithm with Adaptive Non-Uniform Mutation has been suggested. The efficacy of the proposed technique is tested on Classical Benchmark Functions, and obtained results are compared with the state of the art of algorithms. This algorithm is also validated on a heterogeneous wireless sensor network with cluster head selection as a multi-objective optimization problem. The residual energy of sensor node and distance travelled are to be optimized in order to minimize the fitness function. Simulation suggested that the proposed algorithm is found to be reliable and outperforms in terms of remaining energy of nodes, alive nodes versus round, dead nodes versus rounds, the lifespan of network, throughput, and stability period.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Wireless sensor network (WSN) is the set of teeny, battery-operated sensor nodes in the defined covered area. These sensor nodes have the responsibility to collect, process, and aggregates the data and then forward it to the processing center called a sink. There are many challenges associated with these networks, such as the data acquisition is accomplished in a remote or dense area, which can be inaccessible, limited energy resources, limited onboard processing and computing, and the distributed nature of WSNs. Various energy-aware routing protocols are present in the literature to address these issues [1,2,3] A WSN has wide scope in many fields such as monitoring, tracking, and surveillance in the military [4, 5], natural calamity conditions [6], health monitoring in biomedical field [7, 8], and in dangerous environment analysis and seismic sensing [9, 10].
The deployment of sensor nodes is accomplished randomly or uniformly. On the basis of deployment WSN can be classified into two classes: structured and unstructured. An unstructured WSN carries a heavy group of sensor nodes. The maintenance of the network is difficult in the unstructured network as it is a challenging task to manage, process, connection, and detection of failures due to a large number of sensor nodes. In the structured WSN, there are few sensor nodes, and deployment of these nodes are pre-planned, so it becomes easy to maintain the network. The lifespan of sensor nodes relies upon the residual energy in the nodes; hence it becomes vital to use the energy-efficient resources in WSNs. The conventional routing protocols include direct-transmission (DT) [11] and minimum-transmission energy (MTE) [12], are not capable of distributing the energy load among nodes in the wireless sensor network. In the direct-transmission, sensors send information directly to the sink, due to this fact, nodes having more distance from the sink would die first. In the MTE nodes, follow the minimum distance path, where cost reflects the transmission power expended. For this problem, the LEACH protocol was proposed in the literature. To enhance the lifetime of a network and to save energy, nodes are grouped and termed as clusters, and a cluster head is selected in each cluster. Remaining sensor nodes behave as cluster members. Each sensor node must relate to only one cluster. The cluster head collects the data from each cluster members and aggregates information and transmits the useful information to the base station (BS) or sink via single-hop or multi-hop communication. The clustering in WSN can be classified in the following: centralized, distributed and hybridized clustering. Also, clustering can be achieved in equal or unequal manner. The equal clustering algorithms are LEACH, HEED etc. and unequal clustering algorithms are ULEACH, UHEED, EEUC, EDUC etc. the hot spot problem is associated with equal clustering due to which unbalanced energy consumption in clusters. The sensor network also categorized as homogeneous WSN and Heterogeneous WSN. If all sensor nodes have the same energy amount, this is called a homogeneous network. In contrast, if some percentage of sensor nodes contained extra energy than other nodes is called a heterogeneous network.
Different type of engineering optimization problems are tackled by numerous optimization algorithms available in the literature including slime mould algorithm (SMA) [13], salp swarm algorithm (SSA) and its variants [14,15,16], sine cosine algorithm (SCA) [17,18,19], Harris hawk optimizer [20, 21], grey wolf optimizer (GWO) [22,23,24], gravitational search algorithm (GSA) [25], Multi-verse optimizer (MVO) [26], whale optimization algorithm (WOA) [27, 28]. The fuzzy theory is also investigated in the literature as in [29, 30].
In this paper, Diversity driven multi-parent evolutionary algorithm-based optimal cluster-head selection in the heterogeneous WSN is proposed. The paper is arranged as follows: the first section described the background and brief introduction to the paper. The second section presents the literature review, and the third section highlights the contributions of the paper. In the fourth section, the proposed algorithm is detailed, and the next fifth section elaborates the problem formulation. The sixth section presents the results and discussion of the proposed work, presenting the competitive performance of the proposed algorithm. Finally, the seventh section concludes the paper.
2 Related Works
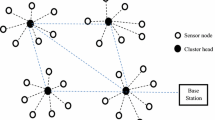
In this section, various cluster head selection and energy-efficient techniques are discussed, which are gives the motivation to design the proposed algorithm. The architecture of wireless sensor nodes with the cluster head and sink is given in Fig. 1.

The Wireless sensor node architecture with cluster heads and sink
Various energy based routing protocols are explored in the literature such as low energy adaptive clustering hierarchy (LEACH) version of LEACH (VLEACH) [31], LEACH-B protocol [32], hybrid energy-efficient distributed (HEED) protocol [33], adaptive multi clustering algorithm based on fuzzy logic (Adaptive MCFL) [34], and Cluster chain weight metrics approach (CCWM) [35]. The LEACH protocol guarantees that the energy load is well distributed dynamically chosen based on a priori optimal probability. The role of the cluster head is performed through each sensor node by rotating uniformly. Cluster-head.
In the literature, various optimization-based energy-aware routing protocols and cluster head selection techniques are also proposed described in Table 1. The parameters considered and identified problems are summarised in this section. Every method delivers new contributions to energy-efficient routing or cluster head selection.
Ghugar et al. proposed a protocol layer trust-based intrusion detection system (LB-IDS) [44] and physical layer trust-based intrusion detection system (PL-IDS) [45] to provide security for wireless sensor network. A light weight trust management technique based on penalty and reward policy has been proposed by Sahoo et al. to detect malicious, selfish and compromised nodes [46]. Bhoi et al. proposed a density-based clustering method to identify the faults in WSNs [47], a software defined network based fault detection in WSN [48] and a geometric constraint based range free localization scheme for WSNs [49]. A fault detection method for heterogeneous WSN is proposed by Swain et al. by incorporating three phases namely; clustering phase, fault detection phase and fault classification phase [50].
3 Contribution of the Paper
The significant contributions of the paper are talked about as follows.
-
(1)
Proposed new optimization technique A diversity driven multi-parent evolutionary algorithm is proposed in this paper, which furthers the process of searching the search space by sensing the diversity of the population to avoid local optimum.
-
(2)
Optimized cluster head selection for the heterogeneous network The proposed algorithm is modified for the application on heterogeneous wireless sensor node network to choose cluster head in order to enhance the life of the network.
-
(3)
Use of fuzzy set theory to formulate fitness function and uneven clustering Fuzzy set theory is used in decision making to choose a solution effectively out of the available non-inferior solutions. Uneven clustering is also performed using the fuzzy theory.
Here a fitness function is designed to evaluate cost function for the selection of cluster head. In this paper, the residual energy of sensor nodes and the distance between nodes and sink is considered in the creation of the objective function. Also, to approve the proposed optimization algorithm, the wireless sensor network is simulated. Also, the presentation of the calculation is widely dissected with different points of view, such as alive nodes, residual energy of nodes and cluster head. The efficacy of the optimization algorithm is tested on benchmark functions, which include unimodal, multi-modal, separable, and non-separable characteristics.
4 Proposed Algorithm
This section is covering the detailed steps of operation performed. The proposed algorithm is named as Diversity-driven multi-parent evolutionary algorithm (DDMPEA) with adaptive non-uniform mutation (ANUM) [51]. In this algorithm, the multi-parent selection strategy is adopted for crossover operation to generate new offspring. Some defined percentages of individuals are selected randomly from the initial population, ensuring that parents are chosen once in an iteration. For mutation, Adaptive non-uniform mutation (ANUM) is applied conditionally based on a probability index calculated from the fitness variance of the population, which signifies the actual aggregation of the population in the search space defined by the problem objective. This mutation helps in diverting the population from local minima as sensed by the search space aggregation. The steps for the proposed algorithm are illustrated in detail as follows:
4.1 Initialization of Population
The initial NP numbers of members are randomly generated within the search space using uniform distribution using the following equation
where \(r_{ij}\) the uniform random number for \(i^{th}\) member of the population and \(j^{th}\) dimension of the variable, NP is the size of the population, and D is the dimension of the search space. \(x_{j}^{min}\) and \(x_{j}^{max}\) are the minimum and maximum of \(j^{th}\) dimension of the control variable.
4.2 Opposition-Based Learning
The optimization algorithms initially randomly chose the members, and to obtain the optimal solution quality of these members is improved. The computational time is calculated using the distance and initial guesses obtained through an optimum solution. By utilizing the opposite solution of initial guesses simultaneously, it can be possible to enhance the search process to obtain better solutions. The initial position, either from the uniformly random distribution or its opposite guess, is chosen. The initial position and its opposite are being used to compute the objective function. Based on this, a decision has been taken for solutions to be considered primarily, which has the capability to accelerate the convergence. The same method can be used not only to initial positions but also continues to each position in the current population [30]. The oppositional learning in population is initialized as
4.3 Multi Parent DE Crossover
In the multi-parent crossover, three parents are selected randomly for crossover to generate offspring. A pool of mating parents is created by selecting the best P% of the total population. Out of this pool three members \(x_{r1} ,x_{r2} \;{\text{and}}\;x_{r3}\) are randomly chosen for the crossover operation and create an offspring as per the following equation
where \(\alpha_{ij}\) is a weighting factor and is a random number from a normal distribution with a mean of 0.7 and a variance of 0.1. t represents the index for the current generation. It is taken care that once a member is selected for the crossover is not selected again in the same iteration. The following equation is used to fix the off-limit offspring.
After the multi-parent crossover operation, fitness value is evaluated from newly created offspring by solving the objective definition of the problem at hand [52].
4.4 Adaptive Non-uniform Mutation Strategy
The mutation is an operator used to maintain diversity from one generation to next. Fitness variance of the population is used as a signal of the diminishing diversity of the population. Whenever an algorithm tends to stick in a local minimum, the fitness variance of the population tends to become zero. This condition is used to trigger the adaptive non-uniform mutation to perturb the population from being stuck somewhere in a local optimum. Hence, the proposed algorithm kicks out the population from premature convergence situation by using an adaptive non-uniform mutation operator. The adaptive non-uniform mutation is performed according to Eq. (5).
where \(\eta\) stands for the weighting factor from a normal distribution with a value of a mean as 0 and a variance of 1[53]. \(Om_{ij}^{t}\) is a mutated version of offspring \(O_{ij}^{t}\). This mutation is carried out if \(r_{i} \left( {0,1} \right) < P_{m}\), where \(r_{i} \left( {0,1} \right)\) is a uniform random number between 0 and 1 for \(i^{th}\) offspring. \(P_{m}\) is the mutation probability and is defined as
where \(\sigma_{1}\) is the threshold value of variance based on the search space range of the search variables as
\(\sigma^{2}\) is the fitness variance of the population. The degree of diversity, \(h\), in the \(t^{th}\) iteration is defined as
where \(x_{best}^{t}\) is a position of the variable in the search space corresponding to the best fitness value and \(d_{2}\) is \(L_{2} - norm\) of \(d\).
The parameter \(h\) is the normalized distance of the member of the population from the optimum point, not necessarily the global optimum. The value of \(h\) signifies the diversity in the population. When the value of \(h\) is high, particles are more dispersed in space and requiring the small value of mutation probability. When the value of \(h\) is small, particles are congregated to assemble in the near proximity of a probable local optimum and hence to require significant mutation probability. The essential requirement is to improve the solutions in terms of enhanced ability of exploration is fulfilled by mutation strategy. When the algorithm stuck at local minima, an individual’s position and its interaction with the rest of the population are relatively estimated by employing the concept of the fitness variance.

The fitness variance, which is used as an indicator of a stuck population, is calculated using Eq. (9).
where \(f_{avg}\) is the average of fitness values of population, \(f\) is the returning factor and \(f_{i}\) is the fitness of \(i^{th}\) individual. The returning factor is used to control the fitness variance of particles. The value of returning factor is calculated as
This fitness variance hints about the degree of the congregation of the population. The smaller the value of fitness variance, the nearer the particles are assembling at a point in the search space; otherwise, they are randomly dispersed in the search space [54].
A pool is created involving the present population at time \(t\), newly created offspring from crossover and the mutated offspring when the following steps are performed. This population from this pool is arranged according to their cost evaluations. Finally, the best \(NP\) members are selected from this pool to substitute the individuals of the present population. The gradual procedure is elaborated in Algorithm-1. The flow chart of proposed algorithm is given in Fig. 2.

Flow Chart of Diversity driven multi-parent evolutionary algorithm with adaptive non-uniform mutation
5 Problem Formulation for Cluster-Head Selection in Heterogeneous Wireless Sensor Networks
In this section, the formulation of the problem for heterogeneous wireless sensor networks is discussed in which a portion of the nodes has an additional energy source initially. The scenario in which a population percentage of sensor nodes carries additional energy resources compared to other sensor nodes in different proportions is considered. In this structure, the total number of nodes, \(n\), are divided into three categories; advanced nodes, intermediate nodes and normal nodes expressed by \(N_{ADV}\), \(N_{INT}\) and \(N_{NRM}\) respectively.
where \(m_{0}\) and \(m\) are the fractions of intermediate and advanced nodes, respectively. The energy of the advanced nodes and intermediate nodes are α and β times higher in energy as compared to normal nodes, respectively [55]. The energy of normal, intermediated and advanced nodes is as follows
where the total energy of the network is denoted by \(E_{T}\) and \(E_{0}\) represents the initial energy of the sensor node.
The problem of cluster head selection in a heterogeneous wireless sensor network is created as a multi-objective optimization problem. The two objectives which are considered are residual energy of the node and the distances between cluster heads and base station and cluster head and other nodes. The objectives considered are conflicting in nature in the sense that when distance objective is decreasing, the residual energy of the nodes increases as with lesser distances consumed energy decreases. Search space is searched for non-inferior solutions by employing the proposed algorithm DDMPEA-ANUM. Fuzzy set theory is used for decision making to find the best solution.
5.1 System Energy Dissipation Model
The calculation of energy dissipation for data transmission in WSN is carried out by comparing the distance travelled like the distance between the transmitter and the receiver, and the critical value \(d_{0} = \sqrt {\frac{{E_{efs} }}{{E_{amp} }}}\). In transmission of each packet energy loss occurs which follows a free-space and multi-path fading model. A model for radio transmission and reception is shown in Fig. 3.

Radio energy dissipation model
The energy required in the transmission of \(k\)-bit data at the distance \(d\), is given by \(E_{dis} \left( {l,d} \right)\) and calculated as
where \(E_{efs}\) is for free space energy model, \(E_{amp}\) is an energy consumed in the power amplifier and \(E_{elec}\) represents the electronic energy of the circuit given as
where \(E_{TX}\) is transmitter circuit’s energy and \(E_{DA}\) is energy required in data aggregation. \(d\) is the distance between the sender node and the receiver node. \(k\) represents the packet size of the data transmitted. The energy consumed during the reception of data per bit is given by
Hence the total energy consumed by cluster head nodes is given by
and the total energy dissipated by other nodes is given by
5.2 Residual Energy of the NODE
The energy estimation of each node is revise subsequently to sending or getting \(k\). bytes of information. This procedure is rehashed until each node is said to be a dead node. A node is said to be dead node when the leftover energy gets negative or zero. The residual energy of the node in the current round is considered as the first objective for evaluating the optimum cluster. The cluster head consumes more energy as compared to other sensor nodes as it has the responsibility of transmitting, receiving, aggregating, and forwarding the data. After every round of communication the cluster head decreases its energy more rapidly than the other nodes. Therefore, the re-establishment of cluster heads in each round on the basis of the residual energy of a node becomes obligatory. The residual energy of the node is represented mathematically as
where \(E_{R}^{{t_{r} }}\) is the residual energy of \(i^{th}\) node after \(t_{r}\) number of rounds and \(E_{C}^{{t_{r} }}\) is the energy consumed in the \(t_{r}^{th}\) round. It is clear that for each type of heterogeneous nodes, the value of \(E_{R}^{{t_{r} }}\) will be different according to the type of node. For the first round \(\left( {t_{r} = 1} \right)\), \(E_{R}^{{t_{r} }}\) would be \(E_{ADV} , E_{INT}\) and \(E_{NRM}\) for advanced, intermediate, and normal nodes, respectively. It is obvious that the node with the higher value of energy wins the selection of a node to be cluster head.
5.3 Distance Between Node and Sink
Any communication that takes place between nodes and cluster head or between nodes and sink consumes some energy according to the role performed by the node. Higher the distance between the nodes while communicating; higher energy will be required and vice-versa. The distance between sensor nodes to sink is calculated as
This is the second fitness objective for the multi-objective problem at hand. The distance between sensor nodes and cluster heads is calculated as
where \(N_{CH}\) are the number of cluster heads specified.
5.4 Decision Making
In the problem at hand, two objectives are considered, which are of conflicting nature as residual energy is to be maximized, and the distances between the cluster heads and base station are bound to be reduced. Hence, to find the best-compromised solution, the fuzzy set theory is employed. In general, the decision-maker's assessment is of an imprecise type, and it is worth thinking that the DM might have blurred or imprecise objectives for each objective feature. The Fuzzy Sets are described as membership functions by equations. These functions reflect a membership degree in some fuzzy sets by using values from 0 to 1. The membership function is defined by assuming \(\mu \left( {F_{i}^{k} } \right)\) is a decreasing and continuous function that is strictly monotonous. In fuzzy set theory membership values are calculated for both fitness parameters; residual energy of each node (considered as \(F_{i}^{1}\)) and distance between sink and nodes (considered as \(F_{i}^{2}\)) as given below
The satisfaction level of \(F_{i}^{k}\) objective of non-inferior solution arranged in range of [0,1], is reflected by the value of membership function. The accomplishment of \(k\) non dominated solutions [56] given below
The solution corresponding to the maximum membership \(\mu_{D}^{i}\) chosen as the best solution. Hence the problem statement becomes
In the proposed work, the clusters are re-elected after each round, and as a result, the load is very much conveyed and adjusted among the nodes of the network. After cluster head selection, uneven clustering is accomplished using fuzzy theory based on the distance between nodes and sink. The working procedure for optimum clustering is given in Algorithm-2.

5.5 Implementation
The proposed protocol works in two stages, namely, setup stage and steady stage (Fig. 4). In this step, the wireless sensor network is formulated by the uniformly random deployment of heterogenous energy sensor nodes termed as advanced, intermediate, and normal nodes at the start. From the second iteration onwards, the locations of these nodes are modified employing the proposed algorithm in the crossover and mutation steps. Then, the decision maker chooses the configuration to be updated to further the process of the algorithm. The base station or sink is placed in the center of the formulated network. After the network formulation, cluster heads are selected, and nodes are assigned to their cluster heads on the basis of the distance between sensor nodes and the sink and the residual energy of nodes. Cluster head selection operation is performed by employing the proposed optimization technique. The parameters utilized in the formulation of fitness function are residual energy of each node and distance between nodes and sink.

Flow chart of DDMPEA with ANUM for CH selection and working of proposed protocol
The second stage, that is, the steady-state stage, indicates the initialization of data transmission. It is run for some specified number of rounds in every iteration. For communication to take place, the threshold value of the distance is compared with the distance between sensor nodes and the sink. This helps to make the decision that communication occurs via single hop or multiple hops. When data is received by the cluster head, it collects, processed the data and forwards it to the sink. Also, the energy of each node is analysed if it is equal or less than zero if it happens so, the node is flagged as the dead node. This dead node does not participate in the process further after it is flagged as so.
As mentioned in Eq. (9) of the proposed algorithm, the fitness variance is calculated using the objective function value of each member. But in the case of the problem at hand, there is only one objective value collectively for the whole NP population, i.e., the number of live nodes after a certain specified number of data transmission rounds executed. Hence, this parameter is molded according to the problem at hand to the location variance of sensor nodes. The advantage of this modification is that whenever nodes tend to aggregate at a particular location, the mutation is performed. The two-dimensional spatial variance of the sensor node locations is calculated as follows
where \(\left( {\overline{x},\overline{y}} \right)\) is the mean of all the sensor node locations. The value of mutation probability is modified accordingly as
The whole working process of DDMPEA with ANUM applied in this work is described in Algorithm-3 as follows.

6 Results and Discussion
The efficacy of DDMPEA with ANUM is tested in two different scenarios. First, on the basic benchmark optimization problems and second on the cluster head selection in case of a heterogeneous wireless sensor network. The simulation is carried out in MATLAB-2015b platform running under the windows-10 operating system with the Intel Core i3 processor @ 1.70 GHz frequency with 4 GB RAM memory. The obtained results are tabulated and discussed in this section.
6.1 Basic Benchmark Functions
This section discusses the performance of the proposed algorithm tested on benchmark functions. The functions \(f_{1} - f_{7}\) are unimodal while functions \(f_{8} - f_{23}\) are multi-modal [18]. The results are obtained and tabulated in terms of mean, median, standard deviation, and worst values in Table 2. The population size is taken as 50, and maximum iterations are set to 1000 for comparison. The other optimization algorithms considered for comparison are SCA [17], PSO[57], TLBO[58], MFO[59], DE[60], WOA [27], GWO[22], CSA[61] and SCA-PSO[18] as available in the literature.
For functions \(f_{1} , f_{2} , f_{3} {\text{ and }}f_{4}\), the results obtained from the proposed algorithm are competitive to the results obtained from other algorithms. Functions \(f_{8}\) to \(f_{13}\) are multi-modal, separable and non-separable, high dimensional benchmark functions which are usually used to benchmark the ability of an algorithm to tackle with the premature convergence problem. From the results obtained, it is observed that functions \(f_{9}\), \(f_{10}\) and \(f_{11}\) gives competitive results as compared to the results from other algorithms in terms of mean, median, standard deviation and worst value. Hence, it can be inferred that the proposed algorithm works effectively to solve the premature convergence problem. This observation shows the better exploration ability of the proposed algorithm. SCA perform better for function \(f_{8}\). For functions \(f_{12}\) and \(f_{13}\) classical DE performs better compared to results from other algorithms.
Functions \(f_{14}\) to \(f_{23}\) are the multi-modal low dimensional functions. It can be observed from Table 1, the proposed algorithm works effectively for these functions too. Functions \(f_{16}\), \(f_{18}\), \(f_{19}\), \(f_{20}\), \(f_{22}\) and \(f_{23}\) gives optimum global values in terms of mean, median, standard deviation and worst value. The convergence behaviour of benchmark functions and their box plots are given in Figs. 5 and 6., respectively. From the box plots, it is observed that proposed algorithm gives results with minimum standard deviation in case of almost all considered functions.

Convergence behaviour for the results of DDMPEA with ANUM algorithm

Box plots of the results of proposed algorithm for function f1–f6, f9–f12, f16–f20
6.1.1 Statistical Analysis of Benchmark Functions
The comparison of results obtained by the proposed algorithm with the results available in the literature from other algorithms is tabulated based on the mean, standard deviation, median, and worst values from 30 independent runs. For the comparison of results from each run, a nonparametric test, the Wilcoxon rank-sum test is conducted with a 5% significance level, and obtained p values are shown in Table 3. The null hypothesis is rejected if the p-values are less than 0.05, which represents that the better objective functions values are obtained by the proposed algorithm in each case are statistically significant and have not occurred by chance. For this analysis, the best value is considered of which has the smallest mean value. In case if there exists more than one mean value of compared algorithms, then algorithm which have the smallest standard deviation is selected. Not applicable (N/A) is written for the best algorithm because the best algorithm cannot be compared with itself.
From Table 3, it is clear that DDMPEA with ANUM obtained best results for function \(f_{5} , f_{6} , f_{9} - f_{11} , f_{16} - f_{19}\) and \(f_{21} - f_{23}\). For function \(f_{8}\) CSA gives the best values. For remaining functions, the proposed algorithm gives competitive results as compared to other optimization algorithms.
6.2 Heterogeneous Wireless Sensor Network
Validating the proposed algorithm on benchmark problems, the application of heterogeneous wireless sensor networks is investigated. The parameters considered for simulation of heterogeneous WSN are given in Table 4. The heterogeneous energy sensor nodes are deployed randomly in area 100 × 100 m2, and the sink is located in the middle of the network.
The 0.5 J is taken as initial energy of normal nodes, and the intermediate nodes have energy two times of normal nodes, while advanced nodes have three times more energy of normal nodes. The number of intermediate nodes is ten percent of total sensor nodes in the considered network, and the number of advanced nodes is 20 percent of total nodes, and energy fraction is given in Table 4. The assumptions considered for the proposed protocol.
A few assumptions are considered about the qualities for a portion of the sensor nodes enlisted bellow.
-
In the network, all sensor nodes are stationary after the deployment, including the sink. They have enough capacity for forwarding and receiving data packets from other nodes and sink, covering their sensing range. Also, the coverage area is taken in meter square.
-
The deployed nodes are heterogeneous in terms of their initial energy, i.e., some of the nodes have more energy resources compared to other nodes. Hence three types of nodes are considered advanced, intermediate, and normal nodes.
-
The sink is viewed as having an infinite energy source.
-
Once the sensor nodes are depleting their energies, they cannot be recharged again. Also, the sensor nodes are not aware of their location.
-
The different components, for example, signal blurring, happen during transmission and gathering, impedance, and sign misfortune because of different natural elements, and physical deterrents are not thought of.
6.2.1 Performance Measures
The analysis of the proposed protocol is carried out using measures such as network lifetime, residual energy of the network, stability period, and the number of data packets transmitted to the sink (network throughput).
The lifetime of a network The number of alive nodes in the network represents the lifetime of the network, i.e. the active nodes having sufficient energy for transmission of data packets.
residual energy of the network As the data transmission takes place in the wireless sensor network, the sum of residual energy of sensor nodes decreases gradually due to the fact that nodes squander their energy during the data transmission with other sensor nodes and the sink. This performance measure is obtained by adding residual energy of all nodes after each round of data transmission.
Stability Period The stability period of WSN is defined in terms of numbers of the round until the first sensor node consumes its total energy in the process of data transmission. This first dead sensor node can be advanced, intermediate, or normal.
Network throughput The number of data packets satisfyingly transmitted over time is termed as network throughput. This performance metric plays a vital role as it ensures the reliability of the network to obtain the best network performance.
6.2.2 Simulation Analysis
The simulation analysis of the proposed protocol is carried out on the basis of performance measures discussed in Sect. 6.2.1. The working process is described in Sect. 5.5 for a heterogeneous wireless sensor network. The obtained results of the proposed protocol are compared with other optimization algorithms based protocols such as GAOC, GADA_LEACH, TEDRP, and DCH_GA from genetic algorithm based paper [55].
Network Lifetime From Fig. 7., it is evident that in the proposed protocol, sensor nodes die after 21,000 rounds whereas GAOC, GADA-LEACH, and DCH-GA cover 19,648, 17,113, 18,498 and 14,729 rounds respectively. The improvement in network lifetime by proposed protocols as compared to other protocols, in terms of percentage is 6.88, 22.71, 13.52, and 42.57% compared to GAOC, GADA-LEACH, TEDRP, and DCH-GA respectively. The alive nodes vs. rounds given in Fig. 8.

Comparison of DDMPEA with ANUM with other protocols in terms of stability period, HND and network lifetime

Alive nodes vs. rounds for proposed algorithm
The dead nodes vs. rounds given in Fig. 9. In the proposed work, half sensor node dead (HND) after 10,627 rounds of data transmission in the wireless sensor network. The HND for GAOC, GADA-LEACH, TEDRP, and DCH-GA are 10,674, 7722, 9086, and 7111, respectively.

Dead nodes vs rounds for proposed protocol
The residual energy of the network The occurrence of the data transmission process in heterogeneous wireless sensor networks costs the energy loss of sensor nodes. The remaining energy in WSN is observed after each round of data transmission. Figure 10. presents energy consumption per round in the data communication process. The figure is given for 100 sensor nodes, which are used to cover the 100 × 100 m2 area. The total energy for this configuration is 70 J.

Residual energy of heterogeneous WSN for 100 sensor nodes
Stability period From Figs. 7. and 8., it is clear that the proposed algorithm shows improvement in the stability period of WSN in percentage as 0.77, 33.41, 33.71 and 62.69% as compared to GAOC, GADA-LEACH, TEDRP and DCH-GA respectively. This improvement ensures reliable data transmission in the network.
Network throughput This parameter is related to the number of data packets transmitted successfully to the base station. The proposed algorithm transmits 1,680,000 data bits to the sink from the cluster heads. This performance metric plays a significant role in acquiring a higher network lifespan.
6.2.3 Summarized Analysis of Proposed Protocol
From the obtained results, it is clear that the proposed method not only enhances the reliability but also improves the stability period of the network. The comparative analysis and percentage improvement in performance metrics are shown in Tables 5 and 6.
7 Conclusion
In a given study, a new technique named 'Diversity driven multi-parent evolutionary algorithm with adaptive non-uniform mutation' has been suggested for cluster head selection in heterogeneous wireless sensor networks. Residual energy and distance travelled are two objective functions that are to be optimized simultaneously in order to minimize the overall fitness function. Fuzzy set theory is utilized to evaluate membership function for both objective functions, i.e. residual energy and distance travelled. The best value of a membership function is selected for cluster head selection based on higher cardinal ranking. The clustering of nodes is achieved utilizing fuzzy theory based on the remaining energy of nodes and distance between sensor nodes and base station. The proposed algorithm proved to be beneficial as it shows the improvement in the stability period, alive nodes, and network lifetime in comparison with other optimization-based methods. The percentage improvement in the stability period is 0.77, 62.91, 33.71, and 33.41 percentage as compared to GAOC, DCH-GA, TEDRP, and GADA-LEACH, respectively. In the same manner, the percentage improvement in network lifetime is 6.88, 42.51, 13.52, and 22.71% as compared to these protocols. The efficacy of the proposed algorithm is also validated on benchmark functions, and improvement is observed in terms of mean, worst, median, best, and standard deviation.
For future work, we are going to investigate the following issues: First, the proposed DDMPEA with ANUM can be applied to other challenging real-world problems like signal processing and fault diagnosis. Second, it could be interesting to incorporate DDMPEA with ANUM with some effective mechanisms of other metaheuristics, such as SCA, and SSA.
References
Potthuri, S., Shankar, T., & Rajesh, A. (2018). Lifetime improvement in wireless sensor networks using hybrid differential evolution and simulated annealing ( DESA ). Ain Shams Engineering Journal, 9(4), 655–663. https://doi.org/10.1016/j.asej.2016.03.004.
John, J., & Rodrigues, P. (2019). MOTCO: Multi-objective Taylor crow optimization algorithm for cluster head selection in energy aware wireless sensor network. Mobile Networks and Applications, 24(5), 1509–1525. https://doi.org/10.1007/s11036-019-01271-1.
Kumar, D. (2013). Performance analysis of energy efficient clustering protocols for maximising lifetime of wireless sensor networks. IET Wireless Sensor System, 4(1), 9–16. https://doi.org/10.1049/iet-wss.2012.0150.
Simon, G., et al. (2004). Sensor network-based countersniper system. In Proceedings of second international conference embeded networked sensor systems (Sensys), Balt. MD.
Yick, J., Mukherjee, B., & Ghosal, D. (2005). Analysis of a prediction-based mobility adaptive tracking algorithm. In 2nd international conference broadband networks, BROADNETS (vol. 2005, pp. 809–816). https://doi.org/10.1109/ICBN.2005.1589681.
Castillo-Effen, M., Quintela, D. H., Jordan, R., Westhoff, W., & Moreno, W. (2004). Wireless sensor networks for flash-flood alerting. In Proceedings of IEEE international caracas conference devices, circuits system ICCDCS (pp. 142–146). https://doi.org/10.1109/iccdcs.2004.1393370.
Gao, T., Greenspan, D., Welsh, M., Juang, R. R., & Alm, A. (2005). Vital signs monitoring and patient tracking over a wireless network. In Annual international conference ieee engineering in medicine and biology proceedings (vol. 7, pp. 102–105).
Lorincz, K., et al. (2004). Sensor networks for emergency response: Challenges and opportunities. In IEEE pervasive computing pervasive computing first response (Special Issue).
Werner-Allen, G., et al. (2006). Deploying a wireless sensor network on an active volcano. IEEE Internet Computing, 10(2), 18–25. https://doi.org/10.1109/MIC.2006.26.
Yick, J., Mukherjee, B., & Ghosal, D. (2008). Wireless sensor network survey. Computer Networks, 52(12), 2292–2330. https://doi.org/10.1016/j.comnet.2008.04.002.
Bagci, F. (xxxx). Energy-efficient communication protocol for wireless microsensor networks. In Proceeding of 33rd Hawai international conference system science
Shepard, T. J. (xxxx). A Channel access scheme for large dense packet radio networks. In Proceeding of ACM SIGCOMM (pp. 219–230). https://doi.org/10.1145/248157.248176.
Li, S., Chen, H., Wang, M., Heidari, A. A., & Mirjalili, S. (2020). Slime mould algorithm: A new method for Stochastic optimization. Future Generation Computer Systems, 2, 13.
Mirjalili, S., Gandomi, A. H., Zahra, S., & Saremi, S. (2017). Salp Swarm Algorithm: A bio-inspired optimizer for engineering design problems. Advances in Engineering Software, 114, 163–191. https://doi.org/10.1016/j.advengsoft.2017.07.002.
Faris, H., Mirjalili, S., Aljarah, I., Mafarja, M., & Heidari, A. A. (2020). Salp Swarm algorithm: Theory, literature review, and application in extreme learning machines. Studies in Computational Intelligence, 811, 185–199. https://doi.org/10.1007/978-3-030-12127-3_11.
Wu, J., Nan, R., & Chen, L. (2019). Improved salp swarm algorithm based on weight factor and adaptive mutation. Journal of Experimental and Theoretical Artificial Intelligence, 00(00), 1–23. https://doi.org/10.1080/0952813X.2019.1572659.
Mirjalili, S. (2016). SCA: A Sine Cosine Algorithm for solving optimization problems. Knowledge-Based System, 96, 120–133. https://doi.org/10.1016/j.knosys.2015.12.022.
Nenavath, H., Kumar, R., & Das, S. (2018). A synergy of the sine-cosine algorithm and particle swarm optimizer for improved global optimization and object tracking. Swarm and Evolutionary Computation, 43, 1–30. https://doi.org/10.1016/j.swevo.2018.02.011.
Gupta, S., Deep, K., Mirjalili, S., & Hoon, J. (2020). A modified sine cosine algorithm with novel transition parameter and mutation operator for global optimization. Expert Systems with Applications, 2020, 113395.
Heidari, A. A., Mirjalili, S., Faris, H., Aljarah, I., Mafarja, M., & Chen, H. (2019). Harris hawks optimization: Algorithm and applications. Future Generation Computer Systems. https://doi.org/10.1016/j.future.2019.02.028.
Kamboj, V. K., Nandi, A., Bhadoria, A., & Sehgal, S. (2020). An intensify Harris Hawks optimizer for numerical and engineering optimization problems. Applied Soft Computing, 89, 106018. https://doi.org/10.1016/j.asoc.2019.106018.
Mirjalili, S., Mohammad, S., & Lewis, A. (2014). Grey Wolf Optimizer. Advances in Engineering Software, 69, 46–61. https://doi.org/10.1016/j.advengsoft.2013.12.007.
Miao, Z., Yuan, X., Zhou, F., Qiu, X., Song, Y., & Chen, K. (2020). Grey wolf optimizer with an enhanced hierarchy and its application to the wireless sensor network coverage optimization problem. Applied Soft Computing Journal, 96(2020), 106602. https://doi.org/10.1016/j.asoc.2020.106602.
Al-betar, M. A., Awadallah, M. A., Faris, H., Aljarah, I., & Hammouri, A. I. (2018). Natural selection methods for Grey Wolf Optimizer. Expert Systems with Applications, 113, 481–498. https://doi.org/10.1016/j.eswa.2018.07.022.
Golzari, S., Zardehsavar, M. N., Mousavi, A., Saybani, M. R., Khalili, A., & Shamshirband, S. (2018). KGSA: A gravitational search algorithm for multimodal optimization based on k-means niching technique and a novel elitism strategy. Open Mathematics, 16(1), 1582–1606. https://doi.org/10.1515/math-2018-0132.
Mirjalili, S., Mirjalili, S. M., & Hatamlou, A. (2016). Multi-verse optimizer: A nature-inspired algorithm for global optimization. Neural Computing and Applications, 27(2), 495–513. https://doi.org/10.1007/s00521-015-1870-7.
Mirjalili, S., & Lewis, A. (2016). The Whale optimization algorithm. Advances in Engineering Software, 95, 51–67. https://doi.org/10.1016/j.advengsoft.2016.01.008.
Jadhav, A. N., & Gomathi, N. (2018). WGC: Hybridization of exponential grey Wolf optimizer with whale optimization for data clustering. Alexandria Engineering Journal, 57(3), 1569–1584. https://doi.org/10.1016/j.aej.2017.04.013.
Zhou, W., Zhou, P., Wang, Y., & Wang, N. (2019). Station-keeping control of an underactuated stratospheric airship. International Journal of Fuzzy Systems, 21(3), 715–732. https://doi.org/10.1007/s40815-018-0566-4.
Singh, M., & Dhillon, J. S. (2016). Multiobjective thermal power dispatch using opposition-based greedy heuristic search. International Journal of Electrical Power and Energy Systems, 82, 339–353. https://doi.org/10.1016/j.ijepes.2016.03.016.
Yassein, L. (2009). Improvement on LEACH protocol of wireless sensor network (VLEACH). International Journal of Digital Content Technology and its Applications, 3(2), 132–136. https://doi.org/10.4156/jdcta.vol3.issue2.yassein.
Mu, T., & Tang, M. (2010). LEACH-B: An improved LEACH protocol for wireless sensor network. In 2010 6th international conference wireless communication network mobile computing WiCOM 2010 (pp. 2–5). https://doi.org/10.1109/WICOM.2010.5601113.
Younis, O., & Fahmy, S. (2004). HEED: A hybrid, energy-efficient, distributed clustering approach for ad hoc sensor networks. IEEE Transactions on Mobile Computing, 3(4), 366–379. https://doi.org/10.1109/TMC.2004.41.
Mirzaie, M., & Mazinani, S. M. (2017). Adaptive MCFL: An adaptive multi-clustering algorithm using fuzzy logic in wireless sensor network. Computer Communications, 111, 56–67. https://doi.org/10.1016/j.comcom.2017.07.005.
Mahajan, S., Malhotra, J., & Sharma, S. (2014). An energy balanced QoS based cluster head selection strategy for WSN. Egyptian Informatics Journal, 15(3), 189–199. https://doi.org/10.1016/j.eij.2014.09.001.
Shankar, T. (xxxx). Whale optimization based energy-efficient cluster head selection algorithm for wireless sensor networks (pp. 1–22).
Guo, L., Li, Q., & Chen, F. (2011). A novel cluster-head selection algorithm based on hybrid Genetic Optimization for wireless sensor networks. Journal Networks, 6(5), 815–822. https://doi.org/10.4304/jnw.6.5.815-822.
Kuila, P., & Jana, P. K. (2014). Energy efficient clustering and routing algorithms for wireless sensor networks: Particle swarm optimization approach. Engineering Applications of Artificial Intelligence, 33, 127–140. https://doi.org/10.1016/j.engappai.2014.04.009.
Zeng, B., & Dong, Y. (2016). An improved harmony search based energy-efficient routing algorithm for wireless sensor networks. Applied Soft Computing Journal, 41, 135–147. https://doi.org/10.1016/j.asoc.2015.12.028.
Karaboga, D., Okdem, S., & Ozturk, C. (2012). Cluster based wireless sensor network routing using artificial bee colony algorithm. Wireless Networks, 18(7), 847–860. https://doi.org/10.1007/s11276-012-0438-z.
Chen, R. C., Chang, W. L., Shieh, C. F., & Zou, C. C. (2012). Using hybrid artificial bee colony algorithm to extend wireless sensor network lifetime. In Proceeding 3rd international conference innovation bio-inspired computing application IBICA (pp. 156–161). https://doi.org/10.1109/IBICA.2012.27.
Kumar, R., & Kumar, D. (2016). Multi-objective fractional artificial bee colony algorithm to energy aware routing protocol in wireless sensor network. Wireless Networks, 22(5), 1461–1474. https://doi.org/10.1007/s11276-015-1039-4.
Vinodhini, R., & Gomathy, C. (2020). MOMHR: A dynamic multi-hop routing protocol for WSN using Heuristic based multi-objective function. Wireless Personal Communication, 111(2), 883–907. https://doi.org/10.1007/s11277-019-06891-0.
Ghugar, U., Pradhan, J., Bhoi, S. K., & Sahoo, R. R. (2019). LB-IDS: Securing wireless sensor network using protocol layer trust-based intrusion detection system. Journal Computing Networks Communication., 5, 71.
Ghugar, U., Pradhan, J., & Kumar, S. (2018). PL-IDS: physical layer trust based intrusion detection system for wireless sensor networks. International Journal Information Technology, 10(4), 489–494. https://doi.org/10.1007/s41870-018-0147-7.
Ranjan, R., Sudhabindu, S., Souvik, R., Sourav, S., & Bhoi, K. (2018). Guard against trust management vulnerabilities in Wireless Sensor Network. Arabian Journal for Science and Engineering, 43(12), 7229–7251. https://doi.org/10.1007/s13369-017-3052-7.
Bhoi, S. K., Panda, S. K., & Khilar, P. M. (2013). A density-based clustering paradigm to detect faults in wireless sensor networks. In International conference on advances in computing (pp. 865–871).
Bhoi, S. K., Obaidat, M. S., Puthal, D., Singh, M., & Hsiao, K.-F. (2018). Software defined network based fault detection in industrial wireless sensor networks. In IEEE global communication conference (GLOBECOM) (pp. 1–6).
Singh, M., Bhoi, S. K., & Khilar, P. M. (2017). Geometric constraint-based range-free localization scheme for wireless sensor networks. IEEE Sensors Journal, 17(16), 5350–5366.
Swain, R. R., Khilar, P. M., & Bhoi, S. K. (2018). Heterogeneous fault diagnosis for wireless sensor networks. Ad Hoc Networks, 69, 15–37. https://doi.org/10.1016/j.adhoc.2017.10.012.
Chauhan, S., Singh, M., & Aggarwal, A. K. (2020). Diversity driven multi-parent evolutionary algorithm with adaptive non-uniform mutation. Journal of Experimental and Theoretical Artificial Intelligence, 2020, 1–32.
Ali, M. Z., Awad, N. H., Suganthan, P. N., Shatnawi, A. M., & Reynolds, R. G. (2018). An improved class of real-coded Genetic Algorithms for numerical optimization✰. Neurocomputing, 275, 155–166. https://doi.org/10.1016/j.neucom.2017.05.054.
Wang, H., Wang, W., & Wu, Z. (2013). Particle Swarm optimization with adaptive mutation for multimodal optimization. Applied Mathematics and Computation, 221, 296–305. https://doi.org/10.1016/j.amc.2013.06.074.
Jun, T., & Xiaojuan, Z. (2009). Particle swarm optimization with adaptive mutation. In 2009 WASE international conference information engineering ICIE 2009 (Vol. 2, No. 1, pp. 234–237). https://doi.org/10.1109/ICIE.2009.59.
Verma, S., Sood, N., & Sharma, A. K. (2019). Genetic algorithm-based Optimized Cluster Head selection for single and multiple data sinks in Heterogeneous Wireless Sensor Network. Applied Soft Computing Journal, 85, 105788. https://doi.org/10.1016/j.asoc.2019.105788.
Dhillon, J. S., Parti, S. C., & Kothari, D. P. (2001). Fuzzy decision making in multiobjective long-term scheduling of hydrothermal system.
Eberhart, R., & Kennedy, J. (1995). A new optimizer using particle swarm theory. In Proceeding of sixth international symposium micro machine human science IEEE (pp. 39–43). https://doi.org/10.1109/mhs.1995.494215.
Rao, R. V., Savsani, V. J., & Vakharia, D. P. (2011). Teaching-learning-based optimization: A novel method for constrained mechanical design optimization problems. Computing Design, 43(3), 303–315. https://doi.org/10.1016/j.cad.2010.12.015.
Mirjalili, S. (2015). Moth-flame optimization algorithm: A novel nature-inspired heuristic paradigm. Knowledge-Based System, 89, 228–249. https://doi.org/10.1016/j.knosys.2015.07.006.
Storn, R. (1997) Differrential evolution-a simple and efficient adaptive scheme for global optimization over continuous spaces. In Technical report, international computing science institution (Vol. 11).
Askarzadeh, A. (2016). A novel metaheuristic method for solving constrained engineering optimization problems: Crow search algorithm. Computers and Structures, 169, 1–12. https://doi.org/10.1016/j.compstruc.2016.03.001.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Chauhan, S., Singh, M. & Aggarwal, A.K. Cluster Head Selection in Heterogeneous Wireless Sensor Network Using a New Evolutionary Algorithm. Wireless Pers Commun 119, 585–616 (2021). https://doi.org/10.1007/s11277-021-08225-5
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11277-021-08225-5