
Abstract
This paper develops and compares different strategies which involve algorithms for column generation for the problem solving of agricultural field partitioning into rectangular-shaped management zones, represented by an integer linear programming model. The main objective of this paper is to select an efficient alternative to solve the linear relaxation of the problem, which does not alter significantly the quality of the integer solution proposed. The paper also describes the model addressed, the solving method studied and computational results for a set of various problem sizes.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
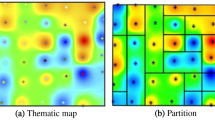
The problem of delineating site-specific management zones in agricultural fields arises in the context of precision agriculture, where the control of variability in soil properties is essential to increase productivity and crop quality. Dividing a field into high internal homogeneity zones with respect to any soil property (pH, organic material, phosphorus, etc.) allows the farmer to face this variability. Furthermore, establishing a rectangular management zone partition provides practical advantages with respect to the use of agricultural machinery.
This paper presents different strategies based on the column generation technique to solve the problem proposed in [2], focused on the delineation of rectangular management zones, considering a fixed internal homogeneity level to solve the problem, measured by the relative variance of partition criterion used to assess the efficiency of the field division (see [6]).
Hereinafter, the problem discussed is considered as: given a set of sample points in a field, \(S = \left \{1,\ldots,N\right \}\), and a set of potential quarters \(Z = \left \{1,\ldots,K\right \}\), where each potential quarter covers a subset of these sample points, find the subset of Z with the minimum number of elements, which is a partition of field, with a given maximum relative variance. The following parameters are defined to introduce the solved model: parameter c zs , s ε S, z ε Z indicates whether quarter z covers sample point s or not; n z , z ε Z indicates the number of sample points considered in quarter z; σ z 2, z ε Z is the variance of quarter z with respect to the soil property analyzed; σ T 2 is the total variance of field with respect to soil property analyzed; and LS is the maximum number of quarters to set in a partition. While, the decision variable of the problem is q z , a binary variable indicating whether potential quarter z ε Z is part of the partition or not. Accordingly, the model will be:
s. t.
The objective function (1) minimizes the amount of potential quarters which are part of a partition. Constraint (2) is typical in partition models and ensures each soil sampling point to be covered by one single potential quarter. Constraint (3) establishes an upper bound to the number of quarters or zones where the field is divided, which is also needed to compute a lower bound on the optimal solution of the linear relaxation of the problem, as will be explained in Sect. 2. Constraint (4) is a linear equivalent rearrangement of a nonlinear constraint that establishes an upper bound (1 −α) on the relative variance of field delineation, with a given value of \(\alpha \epsilon \left [0,1\right ]\) (see [6]). Finally, constraint (5) states that each decision variable q z is binary. Herein this paper is organized as follows: Sect. 2 presents the algorithmic strategies developed, Sect. 3 presents the results obtained from several computational experiences, while Sect. 4 presents the conclusions of this research.
2 Algorithmic Strategies
The column generation method is a technique used in linear programming for solving problems with a large number of variables and a relatively small number of restrictions, which also have been successfully used in many integer programming problem solving. Several uses of this technique are referred to by Desaulniers et al. [3]. For more details about this method refer e.g. to [5]. Regarding the extension of this technique to integer programming problems, see [1] and [8], and particularly, for in set partitioning problems, see [7]. To the best of our knowledge, this is the first time that a column generation algorithm has been used to solve a management zone delineation problem.
Model (1)–(5) has set a partitioning problem structure with a formulation making it suitable to the application of the column generation method. So, linear relaxation of this model is considered as the Master Problem (MP) in the column generation scheme. Notice that each of the N sample points could be represented by the ordered pair (i, j) where i = 1, . . , n and j = 1, . . , m. Therefore, the MP has a total of \(n(n + 1)m(m + 1)/4\) variables and nm + 2 constraints, for a rectangular field represented by N = nm sample points, so the number of potential quarters grows polynomially with the number of sample points. Therefore, the complete enumeration of all the potential quarters is feasible but computationally expensive and it unnecessarily increases the problem size. It is interesting, then, to explore a more efficient strategy for solving the Master Problem (1)–(5).
2.1 The Pricing Problem
As usual in column generation, the pricing problem aims to verify the optimality of the Reduced Master Problem (RMP) by solving the minimization of the reduced cost function represented in terms of the set of potential quarter decision variables, whose optimal solution will be added to the RMP in case of a negative optimal value function. The potential quarter obtained should be rectangular shaped and must meet a set of sample points adjacent to each other. With this in mind, the pricing problem (SP) variable is x s , a binary variable whose value is 1 if sample point s is covered by the new potential quarter, and 0 if not. The problem parameters correspond only to dual variable values p s , ω and π of constraints (2)–(4) from RMP, respectively. SP can be represented as follows:
s. t.
In the formulation above, target function (6) also includes function σ z 2(x), corresponding to the variance calculation of selected sample points, where the value of each sample point is d s :
2.2 Column Generation Strategies
Starting a column generation algorithm requires an initial RMP, that is, an initial set of columns and the corresponding variables. In this case, an initial set of potential quarters (q z ) each covering a single sample point, which means σ z 2 = 0, provides an initial feasible solution. We also set LS = N, which is its trivial value.
Considering this initial RMP, for each iteration of the column generation algorithm, four different strategies to explore the pricing problem feasible solutions and identify new columns to be added to the RMP are proposed. Strategies I and II avoid solving the pricing problem (6)–(8) to optimality by iteratively fixing a size for the potential quarters to be considered (determined by an adjacent number of rows and columns), and then enumerating them and evaluating their reduced costs according to the objective value function (6). If a potential quarter with negative reduced cost is identified, its constraint coefficients are saved in order to be included into RMP up to a predefined number of negative potential quarters per iteration. The difference between these two strategies is that in Strategy I potential quarters are generated in ascending size order, while in Strategy II they are generated in descending size order. The algorithm stops after covering all possible quarter sizes and then solving the RMP as an integer program, where parameter LS is set with a slightly higher value than the best objective value reached by the application of the column generation algorithm.
On the other hand, Strategies III and IV are designed to improve the solution obtained by applying first Strategy I and II, respectively, and then by solving to optimality the RMP in the next iterations according to the column generation method. The difference between Strategies III and IV is that in the former only the column with the lowest reduced cost is added to the RMP at each iteration, while in Strategy IV a set of columns (including the optimal one) is added to the RMP, controlling the number of columns added at each iteration. Strategies III and IV use an optimality gap as a termination criteria to avoid the well known tailing-off effect, which appears as a slow convergence towards the MP optimal solution almost reached. Therefore, the duality based lower bound presented in [4] is used, specially designed for Set Partitioning formulations. To derive this duality based lower bound we need to add a redundant constraint that sets an upper bound on the sum of the variables (q z ), that justifies the use of constraint (3) in model (1)–(5). If we consider a parameter δ ≤ SP ∗, where SP ∗ is the optimal value of SP, the lower bound can be calculated according to the following expression:
During the algorithm execution, if the gap between the best upper and lower bounds is lower than a preset limit, the algorithm ends and an integrality condition is imposed on variables of the resulting RMP, which is solved to optimality by using solver CPLEX 12.4. This procedure does not guarantee the optimal solution for the MP. However, its quality level can be known by rounding up the lower bounds obtained from this algorithm. Section 3 presents results using the different strategies.
3 Computational Results
To compare the algorithmic strategies described in Sect. 2, computational experiments were carried out with randomly generated data sets, which represented 10 different instances with a minimum of 42 and a maximum of 900 sample points. Algorithms were coded in AMPL, both linear relaxations and integer linear problems were solved by using solver CPLEX 12.4 and were carried out on Intel Core i5-2450M 2.50 GHz with 8 GB of RAM.
Table 1 shows the set of different instances that we considered when studying the performance of the different strategies. It also shows the optimal value of model (1)–(5) for the first six instances of the problem. For the larger instances it was not possible to get an optimal solution after 50,000 s of running, considering that this time also included the complete generation of all possible potential quarters for solving (1)–(5) to optimality.
Tables 2 and 3 show the results for Strategies I and II. The UB column presents the best solution reached for the linear relaxation of the problem, while IS shows the objective value obtained by using CPLEX 12.4 after imposing the integrality condition. The #col column indicates the number of variables generated at the end of the algorithm. The gap column presents the difference between the upper bound reached by the application of Strategies I or II and the best known lower bound for each instance of the problem. Regarding the time, the results favor Strategy I where the potential quarters are considered in descending size order, however, looking at the upper bound that each one obtained, it is consistently worse than the one obtained in ascending size order. It means a significant negative impact in computational times (not shown in these results) when we implement Strategies III and IV using Strategy I, resulting in a higher algorithm end time. Therefore, only Strategy II was used with Strategies III and IV.
Table 4 shows the results obtained by using Strategy III, while Table 5 corresponds to Strategy IV. In these tables, the columns from left to right represent: the solved instance, #col is the number of total variables generated at the end of the algorithm, UB and LB are upper and lower bounds on the optimal value of the linear relaxation of the problem; gap % is the percentage gap between UB and LB, with tolerance at 2 % to complete algorithms, IS is the objective function value getting the last iteration of the algorithm when we solved the Reduced Master Problem as an integer program; ISLB is the lower bound for the Master Problem obtained from LB rounded upwards, so when ISLB is equal to IS, the optimal solution is observed and finally, Time is the completion time of the algorithm in seconds.
Results indicate that Strategy IV had better performance in time and determined the best upper and lower bounds on the optimal value of the linear relaxation of model (1)–(5). Moreover, we can observe that in nine of the ten instances Strategy IV reached the optimal solution of the problem.
4 Conclusions
This paper presents different strategies to implement a column generation method for problem solving in delineating rectangular management zones in agricultural fields. More precisely, four strategies were proposed for selecting an efficient implementation of a column generation algorithm for solving a linear relaxation of the considered problem. These strategies combine some heuristics for solving the pricing problem and different stopping criteria through dual based lower bound for early finishing of the algorithm.
Numerical examples with sets of sample points of different sizes were carried out, which show that the strategy of adding more than one column to the new reduced Master Problem in each iteration leads to better results both in the quality of generated bounds for the optimal value as well as in computational time. No differences were observed in the quality of solutions obtained for integer variables, so that the results also show the quality of the adopted methodology.
References
Barnhart, C., Johnson, E.L., Nemhauser, G.L., Savelsbergh, M.W.P., Vance, P.H.: Branch-and-price: column generation for solving huge integer programs. Oper. Res. 46(3), 316–329 (1998)
Cid-García, N.M., Albornoz, V., Ríos-Solís, Y.A, Ortega, R.: Rectangular shape management zone delineation using integer linear programming. Comput. Electron. Agric. 93, 1–9 (2013)
Desaulniers, G., Desrosiers, J., Solomon, M.M.: Column Generation. Springer, New York (2005)
Ghoniem, A., Sherali, H.: Complementary column generation and bounding approaches for set partitioning formulations. Optim. Lett. 3(1), 123–126 (2009)
Nemhauser, G.: Column generation for linear and integer programming. In: Extra Volume: Optimization Stories, Documenta Mathematica, pp. 65–73. Fakultät für Mathematik, Universität Bielefeld, Germany (2012)
Ortega, R., Santibáñez, O.A.: Determination of management zones in corn (zea mays l.) based on soil fertility. Comput. Electron. Agric. 58, 49–59 (2007)
Rönnberg, E., Torbjörn, L.: All-integer column generation for set partitioning: basic principles and extensions. Eur. J. Oper. Res. 233(3), 529–538 (2013)
Vanderbeck, F., Wolseym L.A.: An exact algorithm for ip column generation. Oper. Res. Lett. 19(4), 151–159 (1996)
Acknowledgements
This research was partially supported by DGIP (Grant USM 28.13.69 and Graduate Scholarship), and CIDIEN of the Universidad Técnica Federico Santa María.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Albornoz, V.M., Ñanco, L.J. (2016). An Empirical Design of a Column Generation Algorithm Applied to a Management Zone Delineation Problem. In: Fonseca, R., Weber, GW., Telhada, J. (eds) Computational Management Science. Lecture Notes in Economics and Mathematical Systems, vol 682. Springer, Cham. https://doi.org/10.1007/978-3-319-20430-7_26
Download citation
DOI: https://doi.org/10.1007/978-3-319-20430-7_26
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-20429-1
Online ISBN: 978-3-319-20430-7
eBook Packages: Business and ManagementBusiness and Management (R0)