
Abstract
The success of deep learning is usually accompanied by the growth in neural network depth. However, the traditional training method only supervises the neural network at its last layer and propagates the supervision layer-by-layer, which leads to hardship in optimizing the intermediate layers. Recently, deep supervision has been proposed to add auxiliary classifiers to the intermediate layers of deep neural networks. By optimizing these auxiliary classifiers with the supervised task loss, the supervision can be applied to the shallow layers directly. However, deep supervision conflicts with the well-known observation that the shallow layers learn low-level features instead of task-biased high-level semantic features. To address this issue, this paper proposes a novel training framework named Contrastive Deep Supervision, which supervises the intermediate layers with augmentation-based contrastive learning. Experimental results on nine popular datasets with eleven models demonstrate its effects on general image classification, fine-grained image classification and object detection in supervised learning, semi-supervised learning and knowledge distillation. Codes have been released in
 .
.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

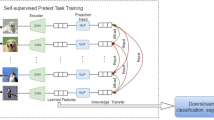

1 Introduction
Along with the growth in large-scale datasets and computation resources, deep neural networks have become the most dominant models for various tasks [14, 52]. However, the increasing depth of neural networks also introduces challenges in their training process. Traditional supervised training method only applies the supervision to the last layer and then propagates the error from the last layer to the shallow layers (Fig. 1(a)), which leads to hardship in optimizing the intermediate layers such as gradient vanishing [29].
Recently, deep supervision (a.k.a. deeply-supervised net) has been proposed to address this issue by optimizing the intermediate layers directly [38]. As shown in Fig. 1(b), deep supervision adds several auxiliary classifiers to the intermediate layers in different depths. During the training phase, these classifiers are optimized with the original final classifier together by the same training loss (e.g. cross entropy for classification tasks). Both experimental and theoretical analyses have demonstrated its effectiveness in facilitating model convergence [62].
However, success comes with remaining obstacles. In general, different layers in convolutional neural networks tend to learn features at different levels. Usually, the shallow layers learn low-level features such as colors and edges, while the last several layers learn more high-level task-related semantic features such as categorical knowledge for classification tasks [82]. However, deep supervision forces the shallow layers to learn the task-related knowledge, which disobeys the original feature extraction process in neural networks. As pointed out in MSDNet [28], this conflict sometimes leads to accuracy degradation in the final classifier. This observation indicates that the supervised task loss is probably not the best supervision for optimizing the intermediate layers.

The overview of the four methods. “\(\rightarrow \)” and “
 ” indicate the path of forward computation and gradients backward computation. “proj” and “fc” indicate the projection heads and the fully connected classifiers, respectively. The gray dash line indicates whether the feature is task-irrelevant or task-biased. (a) Traditional supervised learning only applies supervision to the last layer and propagates it to the previous layers, leading to gradient vanishing. (c) Deep supervision trains both the last layer and the intermediate layers directly, which addresses gradient vanishing but makes all the layers be biased to the task. (d) Our method introduces contrastive learning to supervise the intermediate layer and thus avoid these problems.
” indicate the path of forward computation and gradients backward computation. “proj” and “fc” indicate the projection heads and the fully connected classifiers, respectively. The gray dash line indicates whether the feature is task-irrelevant or task-biased. (a) Traditional supervised learning only applies supervision to the last layer and propagates it to the previous layers, leading to gradient vanishing. (c) Deep supervision trains both the last layer and the intermediate layers directly, which addresses gradient vanishing but makes all the layers be biased to the task. (d) Our method introduces contrastive learning to supervise the intermediate layer and thus avoid these problems.
In this paper, we argue that contrastive learning can provide better supervision for intermediate layers than the supervised task loss. Contrastive learning is one of the most popular and effective techniques in representation learning [7, 8, 34]. Usually, it regards two augmentations from the same image as a positive pair and different images as negative pairs. In the training period, the neural network is trained to minimize the distance of a positive pair while maximizing the distance of a negative pair. As a result, the network can learn the invariance to various data augmentation, such as Color Jitter and Random Gray Scale. Considering that these data augmentation invariances are usually low-level, task-irrelevant and transferable to various vision tasks [3, 64], we argue that they are more beneficial knowledge to be learned by intermediate layers.
Motivated by these observations, we propose a novel training framework named Contrastive Deep Supervision. It optimizes the intermediate layers with contrastive learning instead of traditional supervised learning. As shown in Fig. 1(d), several projection heads are attached in the intermediate layers of the neural networks and trained to perform contrastive learning. These projection heads can be discarded in the inference period to avoid additional computation and storage. Different from deep supervision which trains the intermediate layers to learn the knowledge for a specific task, the intermediate layers in our method are trained to learn the invariance to data augmentation, which makes the neural network generalize better. Besides, since contrastive learning can be performed on unlabeled data, the proposed contrastive deep supervision can also be easily extended in the semi-supervised learning paradigm.
Moreover, contrastive deep supervision can be further utilized to boost the performance of another deep learning technique – knowledge distillation. Knowledge distillation (KD) is a popular model compression approach which aims to transfer the knowledge from a cumbersome teacher model to a lightweight student model [2, 15, 23]. Recently, abundant research finds that distilling the “crucial knowledge” inside the backbone features such as attention and relation [49, 58, 72] leads to better performance than directly distilling all the backbone features. In this paper, we show that the data augmentation invariances learned by the intermediate layers in contrastive deep supervision are more beneficial knowledge to be distilled. By combining contrastive deep supervision with the naïve feature distillation, the distilled ResNet18 achieves 73.23% accuracy on ImageNet, which outperforms the baseline and the second-best KD method by 4.02% and 2.16%, respectively.
Extensive experiments on nine datasets with eleven neural networks methods have been conducted to evaluate its effectiveness on general image classification, fine-grained image classification, object detection in supervised learning, semi-supervised learning and knowledge distillation, which demonstrates that contrastive deep supervision enables neural networks to learn better visual representation. In the discussion section, we further explain the effectiveness of our method from the perspective of regularization methods, which prevents models from overfitting and leads to better uncertainty estimation. To sum up, the main contributions of our paper can be summarized as follows.
-
We propose contrastive deep supervision, a neural network training method in which the intermediate layers are directly optimized with contrastive learning. It enables neural networks to learn better visual representation at no expense of additional parameters and computation during inference.
-
From the perspective of deep supervision, this paper firstly shows that the intermediate layers can be trained with supervision besides the task loss.
-
From the perspective of representation learning, we firstly show that contrastive learning and supervised learning can be combined in a one-stage deep-supervision manner instead of the two-stage “pretrain-finetune” scheme.
-
Extensive experiments on nine datasets, eleven neural networks with eleven comparison methods demonstrate the effectiveness of our method on general classification, fine-grained classification and object detection in supervised learning, semi-supervised learning and knowledge distillation.
2 Related Work
2.1 Deep Supervision
Deep neural networks usually contain a large number of layers, which increases the difficulty of optimization. To address this issue, deeply supervised net (a.k.a. deep supervision) is proposed to directly supervise the intermediate layers of deep neural networks [38]. Wang et al. show that deep supervision can alleviate the vanishing gradient problem and thus leads to significant performance improvements [62]. Usually, deep supervision attaches several auxiliary classifiers at the intermediate layers and supervises these auxiliary classifiers with the task loss (e.g. cross-entropy loss in classification). Recently, several methods have been proposed to improve deep supervision with knowledge distillation, which aims to minimize the difference between the prediction of the deepest classifier and the auxiliary classifiers in the intermediate layers [40, 55]. Besides classification, abundant research has also demonstrated the effectiveness of deep supervision methods in dynamic neural networks [78], semantic segmentation [51, 73, 81], object detection [39], knowledge distillation [76] and so on.
2.2 Contrastive Learning
In the last several years, contrastive learning has become the most popular method in representation learning [5, 18, 24, 27, 32, 60, 61, 63, 68, 74]. Oord et al. propose the contrastive predictive coding, which aims to predict the low dimension embedding of future signals with an auto-regressive model [47]. He et al. propose MoCo, which introduces a dynamic memory bank to record the embeddings of negative samples [9, 11, 19]. Then, SimCLR is proposed to show the importance of large batch size and long training time in contrastive learning [7, 8]. Recently, abundant research has been proposed to study the influence of negative samples further. BYOL is introduced to demonstrate that contrastive learning is effective even without negative samples [16]. SimSiam gives a detailed study on the importance of batch normalization, negative samples, memory bank, and the stop-gradient operation [10]. Besides self-supervised learning, contrastive learning has also shown its power in the traditional supervised learning paradigm. Khosla et al. show that state-of-the-art performance can be achieved on ImageNet with the basic contrastive learning in SimCLR by building the positive pairs with label supervision [6, 34]. Park et al. apply contrastive learning to unpaired image-to-image translation, which breaks the limitation of cycle reconstruction [48].
2.3 Knowledge Distillation
Knowledge distillation, which aims to facilitate the training of a lightweight student model under the supervision of an over-parameterized teacher model, has become one of the most popular methods in model compression. Knowledge distillation is first proposed by Bucilua et al. [2] and then expanded by Hinton et al. [23], who introduces a temperature-characterized softmax to soften the distribution of teacher logits. Instead of distilling the knowledge of the logits, more and more techniques are proposed to distill the information in teacher features or its variants, such as attention maps [42, 72], negative values [22], task-oriented information [76], relational information [43, 49, 58], Gram matrix [69], mutual information [1], context information [75] and so on. Besides model compression, knowledge distillation has also achieved significant success in self-supervised learning [30, 46], semi-supervised learning [37, 56], multi-exit neural network [70, 77, 78], incremental learning [83] and model robustness [65, 79].
3 Methodology
3.1 Deep Supervision
In this subsection, we revisit the formulation of deep supervision methods. Let c be a given backbone classifier, deep supervision introduces several shallow classifiers by using the intermediate features in c. More specifically, assume \(c= g \circ f\) where g is the final classifier, f is the feature extractor operator and \(f=f_K \circ f_{K-1}\circ \cdot \cdot \cdot f_1\). K denotes the number of convolutional stages in f. At each feature extraction stage i, deep supervision attaches an auxiliary classifier \(g_i\) for providing intermediate supervision. Thus, there are K classifiers in total which have the following form:
Given a set of training samples \(\mathcal {X}=\{x_i\}^n_{i=1}\) and its corresponding labels \(\mathcal {Y}=\{y_i\}^n_{i=1}\), the training loss of deep supervision \(\mathcal {L}_{\text {DS}}\) can be formulated as
where \(\mathcal {L}_{\text {CE}}\) indicates the cross entropy loss. The first and the second item in the loss function indicate the standard training loss and the additional loss from deep supervision for the intermediate layers, respectively. \(\alpha \) is a hyper-parameter to balance the two loss items. Recently, some research has been proposed to apply layer-wise consistency on deep supervision, which additionally minimizes the KL divergence between the prediction of auxiliary classifiers and the final classifier [40, 55]. These methods can also be considered as the knowledge distillation which regards the final classifier as the teacher and the auxiliary classifiers as the students. Their training loss can be formulated as
where \(\beta \) is a hyper-parameter to balance the two loss functions.
3.2 Contrastive Deep Supervision
In this subsection, we first introduce the formulation of contrastive learning. For a minibatch of N images \(\{x_1, x_2, ..., x_N\}\), we apply stochastic data augmentation to each image twice, resulting in a batch of 2N images. For convenience, we denote \(x_i\) and \(x_{N+i}\) images as the two augmentations from the same image, which is regarded as a positive pair. Denote \(z= c(x)\) as the normalized projection head outputs, contrastive learning loss (a.k.a. NT-Xtent [7]) can be formulated as
where \(\mathbbm {1}\in \{0, 1\}\) is an indicator function evaluating to 1 if \(k\ne i\) and \(\tau \) is a temperature hyper-parameter. Intuitively, \(\mathcal {L}_{\text {Contra}}\) encourages the encoder network to learn similar representation for different augmentations from the same image while increasing the difference between representations of the augmentations from different images.
The main difference between deep supervision and our method is that deep supervision trains the auxiliary classifiers by the cross entropy loss while our method trains them with the contrastive loss \(\mathcal {L}_{\text {Contra}}\). By denoting the contrastive loss at \(c_i\) as \(\mathcal {L}_{\text {Contra}}(\mathcal {X};c_i)\), then the training loss of our contrastive deep supervision \(\mathcal {L}_{\text {CDS}}\) can be formulated as
where the first and the second item indicate the standard training loss and the additional loss in our method for the intermediate layers, respectively. \(\lambda _1\) is a hyper-parameter to balance the two loss items.
Based on the above formulation on supervised learning, we can extend contrastive deep supervision in semi-supervised learning and knowledge distillation.
Semi-supervised Learning. In semi-supervised learning, we assume that there is a labeled dataset \(\mathcal {X}_1\) with its labels \(\mathcal {Y}_1\) and an unlabeled dataset \(\mathcal {X}_2\). On the labeled data, contrative deep supervision can be appled directly with \(\mathcal {L}_{\text {CDS}}\). On the unlabeled data, due to the lack of labels, contrastive deep supervision only optimize the contrastive learning loss \(\mathcal {L_{\text {Contra}}}\), which can be formulated as
Knowledge Distillation. The intermediate layers in contrastive deep supervision are supervised with contrastive learning and thus they can learn the invariance to different data augmentation. As shown in previous research, these data augmentation invariance is beneficial to various downstream tasks [31]. In this paper, we further propose to improve knowledge distillation with contrastive deep supervision by transferring the data augmentation invariance learned by the teachers to the students. Denote the student model and the teacher model in knowledge distillation as \(f^\mathcal {S}\) and \(f^\mathcal {T}\) respectively, the naïve feature-based knowledge distillation directly minimizes the distance between the backbone features of the student and the teacher, which can be formulated as
In contrast, knowledge distillation with contrastive deep supervision minimizes the distance between the embedding vectors (the output of the projection heads) of the student and the teacher, which can be formulated as
Now we can formulate the overall training loss of the student as
where \(\lambda _2\) and \(\lambda _3\) are the hyper-parameters to balance different loss items. Following previous works in deep supervision, we do not set an individual hyper-parameter for each projection head for convenience in hyper-parameter tuning.
3.3 Other Details and Tricks
Design of Projection Heads. In contrastive deep supervision, several projection heads are added to the intermediate layers of neural networks during the training period. These projection heads map the backbone features into a normalized embedding space, where the contrastive learning loss is applied. As discussed in related works, the architecture of the projection head is crucial to model performance [8]. Usually, the projection head is a non-linear projection stacked by two fully connected layers and a ReLU function. However, in contrastive deep supervision, the input feature comes from the intermediate layers instead of the final layer, and thus it is more challenging to project them properly [8]. Hence, we increase the complexity of these projection heads by adding convolutional layers before the non-linear projection.
Contrastive Learning. The proposed contrastive deep supervision is a general training framework and does not depend on a specific contrastive learning method. In this paper, we adopt SimCLR [7] and SupCon [34] as the contrastive learning method in most experiments. We argue that the performance of our method can be further improved by using better contrastive learning method.
Negative Samples. Previous studies show that the number of negative samples has a vital influence on the performance of contrastive learning. Accordingly, a large batch size, a momentum encoder or a memory bank is usually required [7, 16, 19]. In contrastive deep supervision, we do not use any of these solutions because the supervised loss (\(\mathcal {L}_{\text {CE}}\) in Eq. 5) is enough to prevent contrastive learning from converging to the collapsing solutions.
4 Experiment
4.1 Experiment Setting
Common Image Classification. For common image classification, our method has been evaluated on three datasets, including CIFAR10, CIFAR100 and ImageNet [13, 36] with kinds of neural networks including ResNet (RNT), ResNeXt (RXT), Wide ResNet (WRN), SENet (SET), PreAct ResNet (PAT), MobileNetv1, MobileNetv2, ShuffleNetv1 and ShuffleNetv2 [20, 21, 25, 26, 54, 66, 71, 80].
Fine-Grained Image Classification. For fine-grained image classification, our method has been evaluated on five popular datasets, including CUB200-2011 [59], Stanford Cars [35], Oxford Flowers [45], Stanford Dogs [33] and FGVC Aircraft [44]. ResNet50 is utilized as the classifier for all the experiments.
Object Detection. For object detection, our method has been evaluated on MS COCO2017 [41] with Faster RCNN and RetinaNet by MMdetection [4].
Semi-supervised Learning. Semi-supervised learning experiments have been conducted on CIFAR100, CIFAR10 with ResNet18. For each dataset, we have evaluated our method with 10%, 20%, 30% and 40% labels.

Experimental results of semi-supervised training on CIFAR100 and CIFAR10 with ResNet18.

Influence from the number of projection heads.
Comparison Methods. Three previous deep supervision methods are utilized for comparison, including DSN [38], DKS [55] and DHM [40]. In knowledge distillation experiments, we have evaluated our method with nine knowledge distillation methods, including KD [23], FitNet [53], AT [72], RKD [49], SP [58] and CRD [57]. Besides, we also cite results on ImageNet of CC [50], OKD [84], and SSKD [67] from the paper of SSKD.
4.2 Experimental Results
Image Classification. Experimental results on CIFAR100, CIFAR10 and ImageNet are shown in Table 1, Table 2 and Table 3, respectively. It is observed that: (a) Our method achieves 3.44% and 1.70% top-1 accuracy improvements on CIFAR100 and CIFAR10 on average, respectively. It consistently outperforms the second-best deep supervision method by 1.05% and 0.90% on the two datasets, respectively. (b) On ImageNet, contrastive deep supervision leads to 3.64%, 3.02% and 2.95% top-1 accuracy improvements on ResNet18, ResNet34 and ResNet50, respectively. On average, it outperforms the baseline and the second-best method by 3.20% and 1.83% top-1 accuracy, respectively.
Object Detection. Table 4 shows the performance of our method on object detection. In these experiments, We firstly pretrain the ResNets on ImageNet with standard training (Baseline), three deep supervision methods, and our method, and then finetuning them as the backbone for object detection models, including RetinaNet and Faster RCNN on COCO2017 datasets. It is observed that with backbones pre-trained with our method, there are 0.9 and 0.8 AP improvements on Faster RCNN and RetinaNet respectively, which outperforms the second-best method by 0.6 AP, indicating that the representation learned with our method are more beneficial to downstream tasks.
Fine-Grained Image Classification. Experiments on fine-grained image classification are shown in Table 6. It is observed that: (a) Contrastive deep supervision leads to consistent and significant accuracy improvements on the five datasets. On average, it leads to 3.80%, 2.43%, 1.73%, 4.77% and 2.25% accuracy improvements on the five datasets, respectively. (b) Besides, the benefits of our method in “finetuning from ImageNet” and “training from scratch” are very similar (except on Aircraft), which indicates that the effectiveness of our method is consistent in different training settings.
Semi-supervised Learning. Experiments on semi-supervised learning with ResNet18 on CIFAR10 and CIFAR100 are shown in Fig. 2. It is observed that: (a) Our method leads to consistent accuracy improvements at all the ratios of labeled data. (b) The benefits of our method become larger when there is less labeled data, which indicates that our method is effective in using the unlabeled data to optimize the intermediate layers.
Knowledge Distillation. Knowledge distillation experiments on ImageNet and CIFAR are shown in Table 7 and Table 8, respectively. It is observed that: (a) Our method achieves 5.07% and 2.20% top-1 accuracy improvements on CIFAR100 and CIFAR10 on average, outperforming the second-best KD method by 1.40% and 0.87% on the two datasets, respectively. (b) The similar results can also be observed in ImageNet experiments. Our method leads to 4.02%/2.55%, 3.48%/2.14% and 3.38%/2.22% top-1/top-5 accuracy improvements on ResNet18, ResNet34 and ResNet50, respectively. On average, it outperforms the baseline and the second-best method by 3.62% and 1.76% top-1 accuracy, respectively.
5 Discussion
5.1 Contrastive Deep Supervision as a Regularizer
Loss Curves. Regularization methods in deep learning are usually utilized to avoid model overfitting by introducing additional penalties or loss. In this subsection, we show that the contrastive learning loss introduced by our method in the intermediate layers works as a regularizer. Figure 4 shows the cross entropy loss between predicted results and labels during the training period from two ResNet18 models trained by the standard method and our method, respectively. It is observed that at most of epochs, the baseline model has lower cross entropy loss than our model. When both models are converged (epoch 280–300), the baseline model has only 0.005 loss while our model still has 0.025 loss. These observations indicate that there is serve overfitting in the baseline model while deep contrastive supervision can alleviate overfitting and thus improve the accuracy.
Uncertainty Estimation. Besides, the comparison on expected calibrated error (ECE) of models trained with the standard method and our method has been shown in Fig. 5. A lower ECE indicates that the predicted probability of a neural network estimates representative of the true correctness likelihood better [17]. It is observed that compared with the baseline model, our method leads to a lower ECE, indicating better uncertainty estimation and interpretability.
5.2 Comparison with Contrastive Learning
Comparison between our method and two “pretrain & finetune” contrastive learning methods is shown in Table 9. It is observed that without a large batch size and the advanced data augmentation policy (AutoAugment), contrastive deep supervision (Ours\(^1\)) with only 25% training time achieves 0.4% lower accuracy than SupCon\(^3\). Besides, contrastive deep supervision with the same training time and data augmentation (Ours\(^3\)) achieves 1.1% and 1.6% higher accuracy than SupCon\(^3\) and BYOL+DSN, respectively, which demonstrates the advantage of our method over the traditional contrastive learning methods.
5.3 Ablation Study on Knowledge Distillation
The main difference between the naïve feature distillation and feature distillation with our contrastive deep supervision is “what to distill”. Naïve feature distillation distills the backbone features while our method distills the embedding learned by contrastive deep supervision. To further demonstrate its effectiveness, we have trained a ResNet50 model on CIFAR100 with both contrastive deep supervision and distillation on backbone features. Experimental results show this model achieves 82.26% accuracy, which is 1.27% lower than distilling the embedding. These results demonstrate that distilling the embedding learned by contrastive deep supervision is more beneficial.

Comparison on the cross entropy loss between predicted results and labels during the training period. Note that our method also leads to better accuracy (80.84% vs 77.45%)

Comparison on reliability diagrams. “GAP” indicates the difference between confidence and accuracy. “Output” indicates accuracy. ECE: Expected Calibrated Error (lower is better).
5.4 Sensitivity Study
Where to Apply Projection Heads. We study the influence from the position of projection heads with the following four schemes: (1)uniform scheme - applying projection heads into different depths uniformly; (2) downsampling scheme - applying projection heds into the layers before downsampling; (3) shallow scheme - applying projection heads into only the shallower layers; (4) deep scheme - applying projection heads to only the deeper layers; Experimental results on CIFAR100 with ResNet50 show that the four schemes achieves 81.23%, 81.31%, 81.07% and 80.99% accuracy, respectively. It is observed that both uniform and downsampling schemes leads to excellent performance, indicating our method is not sensitive to where to apply projection heads.
The Number of Projection Heads. We have studied the influence from the number of projection heads in Fig. 3. It is observed that when there are less than five projection heads, more projection heads tend to achieve better performance. The fifth projection head does not leads to more accuracy improvements.
6 Conclusion
This paper proposes contrastive deep supervision, a novel training methodology that directly optimizes the intermediate layers of deep neural networks with contrastive learning. It enables the neural network to learn better visual representation without additional computation and storage in inference. Experiments on nine datasets with eleven neural networks have demonstrated its effectiveness in general image classification, fine-grained image classification and object detection for traditional supervised learning, semi-supervised learning and knowledge distillation. It outperforms the previous deep supervision methods, knowledge distillation methods, and contrastive learning methods by a clear margin. Besides, we also show that contrastive deep supervision works as a regularizer to prevent models from overfitting, and thus leads to better uncertainty estimation.
References
Ahn, S., Hu, S.X., Damianou, A., Lawrence, N.D., Dai, Z.: Variational information distillation for knowledge transfer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9163–9171 (2019)
Buciluǎ, C., Caruana, R., Niculescu-Mizil, A.: Model compression. In: Proceedings of the 12th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 535–541. ACM (2006)
Chaitanya, K., Erdil, E., Karani, N., Konukoglu, E.: Contrastive learning of global and local features for medical image segmentation with limited annotations. In: Advances in Neural Information Processing Systems, vol. 33 (2020)
Chen, K., et al.: Mmdetection: open mmlab detection toolbox and benchmark. arXiv preprint. arXiv:1906.07155 (2019)
Chen, L., Wang, D., Gan, Z., Liu, J., Henao, R., Carin, L.: Wasserstein contrastive representation distillation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, 19–25 June 2021, pp. 16296–16305. Computer Vision Foundation/IEEE (2021)
Chen, L., Wang, D., Gan, Z., Liu, J., Henao, R., Carin, L.: Wasserstein contrastive representation distillation. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 16296–16305 (2021)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. In: International Conference on Machine Learning, pp. 1597–1607. PMLR (2020)
Chen, T., Kornblith, S., Swersky, K., Norouzi, M., Hinton, G.E.: Big self-supervised models are strong semi-supervised learners. In: Advances in Neural Information Processing Systems, vol. 33, pp. 22243–22255 (2020)
Chen, X., Fan, H., Girshick, R., He, K.: Improved baselines with momentum contrastive learning. arXiv preprint. arXiv:2003.04297 (2020)
Chen, X., He, K.: Exploring simple siamese representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 15750–15758 (2021)
Chen, X., Xie, S., He, K.: An empirical study of training self-supervised visual transformers. arXiv e-prints pp. arXiv-2104 (2021)
Cubuk, E.D., Zoph, B., Mane, D., Vasudevan, V., Le, Q.V.: Autoaugment: learning augmentation strategies from data. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (2019)
Deng, J., et al.: Imagenet: a large-scale hierarchical image database. In: CVPR, pp. 248–255 (2009)
Devlin, J., Chang, M.W., Lee, K., Toutanova, K.: Bert: pre-training of deep bidirectional transformers for language understanding. In: NAACL (2018)
Furlanello, T., Lipton, Z.C., Tschannen, M., Itti, L., Anandkumar, A.: Born again neural networks. In: ICML (2018)
Grill, J.B., et al.: Bootstrap your own latent-a new approach to self-supervised learning. In: Advances in Neural Information Processing Systems, vol. 33, pp. 21271–21284 (2020)
Guo, C., Pleiss, G., Sun, Y., Weinberger, K.Q.: On calibration of modern neural networks. In: International Conference on Machine Learning, pp. 1321–1330. PMLR (2017)
Han, Z., Fu, Z., Chen, S., Yang, J.: Contrastive embedding for generalized zero-shot learning. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021, pp. 2371–2381. Computer Vision Foundation/IEEE (2021)
He, K., Fan, H., Wu, Y., Xie, S., Girshick, R.: Momentum contrast for unsupervised visual representation learning. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 9729–9738 (2020)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR, pp. 770–778 (2016)
He, K., Zhang, X., Ren, S., Sun, J.: Identity mappings in deep residual networks. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 630–645. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_38
Heo, B., Kim, J., Yun, S., Park, H., Kwak, N., Choi, J.Y.: A comprehensive overhaul of feature distillation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1921–1930 (2019)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. In: NeurIPS (2014)
Hou, J., Graham, B., Nießner, M., Xie, S.: Exploring data-efficient 3d scene understanding with contrastive scene contexts. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021. pp. 15587–15597. Computer Vision Foundation/IEEE (2021)
Howard, A.G., et al.: Mobilenets: efficient convolutional neural networks for mobile vision applications. In: CVPR (2017)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: CVPR, pp. 7132–7141 (2018)
Hu, Q., Wang, X., Hu, W., Qi, G.: Adco: adversarial contrast for efficient learning of unsupervised representations from self-trained negative adversaries. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021, pp. 1074–1083 (2021)
Huang, G., Chen, D., Li, T., Wu, F., van der Maaten, L., Weinberger, K.Q.: Multi-scale dense networks for resource efficient image classification. In: ICLR (2018)
Huang, G., Sun, Yu., Liu, Z., Sedra, D., Weinberger, K.Q.: Deep networks with stochastic depth. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9908, pp. 646–661. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46493-0_39
Hyun Lee, S., Ha Kim, D., Cheol Song, B.: Self-supervised knowledge distillation using singular value decomposition. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 335–350 (2018)
Jaiswal, A., Babu, A.R., Zadeh, M.Z., Banerjee, D., Makedon, F.: A survey on contrastive self-supervised learning. Technologies 9(1), 2 (2021)
Jeon, S., Min, D., Kim, S., Sohn, K.: Mining better samples for contrastive learning of temporal correspondence. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, 19–25 June 2021, pp. 1034–1044 (2021)
Khosla, A., Jayadevaprakash, N., Yao, B., Fei-Fei, L.: Novel dataset for fine-grained image categorization. In: First Workshop on Fine-Grained Visual Categorization, IEEE Conference on Computer Vision and Pattern Recognition. Colorado Springs, CO (2011)
Khosla, P., Teterwak, P., Wang, C., Sarna, A., Tian, Y., Isola, P., Maschinot, A., Liu, C., Krishnan, D.: Supervised contrastive learning. In: Advances in Neural Information Processing Systems,vol. 33, pp. 18661–18673 (2020)
Krause, J., Stark, M., Deng, J., Fei-Fei, L.: 3d object representations for fine-grained categorization. In: 4th International IEEE Workshop on 3D Representation and Recognition (3dRR-13), Sydney, Australia (2013)
Krizhevsky, A., Hinton, G.: Learning multiple layers of features from tiny images. Technical report Citeseer (2009)
Laine, S., Aila, T.: Temporal ensembling for semi-supervised learning. In: International Conference on Learning Representations (ICLR), vol. 4, p. 6 (2017)
Lee, C.Y., Xie, S., Gallagher, P., Zhang, Z., Tu, Z.: Deeply-supervised nets. In: Artificial Intelligence and Statistics, pp. 562–570 (2015)
Li, C., Zeeshan Zia, M., Tran, Q.H., Yu, X., Hager, G.D., Chandraker, M.: Deep supervision with shape concepts for occlusion-aware 3d object parsing. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 5465–5474 (2017)
Li, D., Chen, Q.: Dynamic hierarchical mimicking towards consistent optimization objectives. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 7642–7651 (2020)
Lin, T.Y., et al.: Microsoft COCO: common objects in context. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8693, pp. 740–755. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10602-1_48
Liu, M., Chen, X., Zhang, Y., Li, Y., Rehg, J.M.: Attention distillation for learning video representations. In: BMVC (2020)
Liu, Y., Shu, C., Wang, J., Shen, C.: Structured knowledge distillation for dense prediction. IEEE Transactions on Pattern Analysis and Machine Intelligence (2020)
Maji, S., Kannala, J., Rahtu, E., Blaschko, M., Vedaldi, A.: Fine-grained visual classification of aircraft. Technical report (2013)
Nilsback, M.E., Zisserman, A.: Automated flower classification over a large number of classes. In: 2008 Sixth Indian Conference on Computer Vision, Graphics & Image Processing, pp. 722–729. IEEE (2008)
Noroozi, M., Vinjimoor, A., Favaro, P., Pirsiavash, H.: Boosting self-supervised learning via knowledge transfer. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 9359–9367 (2018)
Oord, A.v.d., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint. arXiv:1807.03748 (2018)
Park, T., Efros, A.A., Zhang, R., Zhu, J.-Y.: Contrastive learning for unpaired image-to-image translation. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12354, pp. 319–345. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58545-7_19
Park, W., Kim, D., Lu, Y., Cho, M.: Relational knowledge distillation. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3967–3976 (2019)
Peng, B., et al.: Correlation congruence for knowledge distillation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 5007–5016 (2019)
Reiß, S., Seibold, C., Freytag, A., Rodner, E., Stiefelhagen, R.: Every annotation counts: multi-label deep supervision for medical image segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, virtual, 19–25 June 2021, pp. 9532–9542. Computer Vision Foundation/IEEE (2021)
Ren, S., He, K., Girshick, R., Sun, J.: Faster r-cnn: towards real-time object detection with region proposal networks. In: Advances in Neural Information Processing Systems, pp. 91–99 (2015)
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: Fitnets: hints for thin deep nets. In: ICLR (2015)
Sandler, M., Howard, A., Zhu, M., Zhmoginov, A., Chen, L.C.: Mobilenetv 2: inverted residuals and linear bottlenecks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4510–4520 (2018)
Sun, D., Yao, A., Zhou, A., Zhao, H.: Deeply-supervised knowledge synergy. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6997–7006 (2019)
Tarvainen, A., Valpola, H.: Mean teachers are better role models: Weight-averaged consistency targets improve semi-supervised deep learning results. In: Advances in Neural Information Processing Systems, pp. 1195–1204 (2017)
Tian, Y., Krishnan, D., Isola, P.: Contrastive representation distillation. In: ICLR (2020)
Tung, F., Mori, G.: Similarity-preserving knowledge distillation. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1365–1374 (2019)
Wah, C., Branson, S., Welinder, P., Perona, P., Belongie, S.: The caltech-ucsd birds-200-2011 dataset. Technical report, CNS-TR-2011-001, California Institute of Technology (2011)
Wang, F., Liu, H.: Understanding the behaviour of contrastive loss. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021, pp. 2495–2504. Computer Vision Foundation/IEEE (2021)
Wang, L., Huang, J., Li, Y., Xu, K., Yang, Z., Yu, D.: Improving weakly supervised visual grounding by contrastive knowledge distillation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021, pp. 14090–14100. Computer Vision Foundation/IEEE (2021)
Wang, L., Lee, C.Y., Tu, Z., Lazebnik, S.: Training deeper convolutional networks with deep supervision. arXiv preprint. arXiv:1505.02496 (2015)
Wang, P., Han, K., Wei, X., Zhang, L., Wang, L.: Contrastive learning based hybrid networks for long-tailed image classification. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021, pp. 943–952 (2021)
Xie, E., et al.: Detco: unsupervised contrastive learning for object detection. arXiv preprint. arXiv:2102.04803 (2021)
Xie, Q., Luong, M.T., Hovy, E., Le, Q.V.: Self-training with noisy student improves imagenet classification. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 10687–10698 (2020)
Xie, S., Girshick, R., Dollár, P., Tu, Z., He, K.: Aggregated residual transformations for deep neural networks. In: CVPR, pp. 5987–5995 (2017)
Xu, G., Liu, Z., Li, X., Loy, C.C.: Knowledge distillation meets self-supervision. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, J.-M. (eds.) ECCV 2020. LNCS, vol. 12354, pp. 588–604. Springer, Cham (2020). https://doi.org/10.1007/978-3-030-58545-7_34
Yang, M., Li, Y., Huang, Z., Liu, Z., Hu, P., Peng, X.: Partially view-aligned representation learning with noise-robust contrastive loss. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021, pp. 1134–1143. Computer Vision Foundation/IEEE (2021)
Yim, J., Joo, D., Bae, J., Kim, J.: A gift from knowledge distillation: Fast optimization, network minimization and transfer learning. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4133–4141 (2017)
Yu, J., Huang, T.S.: Universally slimmable networks and improved training techniques. In: The IEEE International Conference on Computer Vision (ICCV) (2019)
Zagoruyko, S., Komodakis, N.: Wide residual networks. In: BMVC (2016)
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. In: ICLR (2017)
Zeng, G., Yang, X., Li, J., Yu, L., Heng, P.-A., Zheng, G.: 3D U-net with multi-level deep supervision: fully automatic segmentation of proximal femur in 3d mr images. In: Wang, Q., Shi, Y., Suk, H.-I., Suzuki, K. (eds.) MLMI 2017. LNCS, vol. 10541, pp. 274–282. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-67389-9_32
Zhang, H., Koh, J.Y., Baldridge, J., Lee, H., Yang, Y.: Cross-modal contrastive learning for text-to-image generation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2021, Virtual, 19–25 June 2021, pp. 833–842. Computer Vision Foundation/IEEE (2021)
Zhang, L., Kaisheng, M.: Improve object detection with feature-based knowledge distillation: towards accurate and efficient detectors. In: ICLR (2021)
Zhang, L., Shi, Y., Shi, Z., Ma, K., Bao, C.: Task-oriented feature distillation. In: NeurIPS (2020)
Zhang, L., Song, J., Gao, A., Chen, J., Bao, C., Ma, K.: Be your own teacher: improve the performance of convolutional neural networks via self distillation. In: arXiv preprint:1905.08094 (2019)
Zhang, L., Tan, Z., Song, J., Chen, J., Bao, C., Ma, K.: Scan: a scalable neural networks framework towards compact and efficient models. ArXiv abs/1906.03951 (2019)
Zhang, L., Yu, M., Chen, T., Shi, Z., Bao, C., Ma, K.: Auxiliary training: Towards accurate and robust models. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 372–381 (2020)
Zhang, X., Zhou, X., Lin, M., Sun, J.: Shufflenet: an extremely efficient convolutional neural network for mobile devices. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 6848–6856 (2018)
Zhang, Y., Chung, A.C.S.: Deep supervision with additional labels for retinal vessel segmentation task. In: Frangi, A.F., Schnabel, J.A., Davatzikos, C., Alberola-López, C., Fichtinger, G. (eds.) MICCAI 2018. LNCS, vol. 11071, pp. 83–91. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-00934-2_10
Zhou, B., Khosla, A., Lapedriza, A., Oliva, A., Torralba, A.: Object detectors emerge in deep scene cnns. arXiv preprint. arXiv:1412.6856 (2014)
Zhou, P., Mai, L., Zhang, J., Xu, N., Wu, Z., Davis, L.S.: M2kd: multi-model and multi-level knowledge distillation for incremental learning. arXiv preprint. arXiv:1904.01769 (2019)
Zhu, X., Gong, S., et al.: Knowledge distillation by on-the-fly native ensemble. In: Advances in Neural Information Processing Systems, vol. 31 (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Zhang, L., Chen, X., Zhang, J., Dong, R., Ma, K. (2022). Contrastive Deep Supervision. In: Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T. (eds) Computer Vision – ECCV 2022. ECCV 2022. Lecture Notes in Computer Science, vol 13686. Springer, Cham. https://doi.org/10.1007/978-3-031-19809-0_1
Download citation
DOI: https://doi.org/10.1007/978-3-031-19809-0_1
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-19808-3
Online ISBN: 978-3-031-19809-0
eBook Packages: Computer ScienceComputer Science (R0)