
Abstract
Knowledge distillation, which involves extracting the “dark knowledge” from a teacher network to guide the learning of a student network, has emerged as an important technique for model compression and transfer learning. Unlike previous works that exploit architecture-specific cues such as activation and attention for distillation, here we wish to explore a more general and model-agnostic approach for extracting “richer dark knowledge” from the pre-trained teacher model. We show that the seemingly different self-supervision task can serve as a simple yet powerful solution. For example, when performing contrastive learning between transformed entities, the noisy predictions of the teacher network reflect its intrinsic composition of semantic and pose information. By exploiting the similarity between those self-supervision signals as an auxiliary task, one can effectively transfer the hidden information from the teacher to the student. In this paper, we discuss practical ways to exploit those noisy self-supervision signals with selective transfer for distillation. We further show that self-supervision signals improve conventional distillation with substantial gains under few-shot and noisy-label scenarios. Given the richer knowledge mined from self-supervision, our knowledge distillation approach achieves state-of-the-art performance on standard benchmarks, i.e., CIFAR100 and ImageNet, under both similar-architecture and cross-architecture settings. The advantage is even more pronounced under the cross-architecture setting, where our method outperforms the state of the art by an average of 2.3% in accuracy rate on CIFAR100 across six different teacher-student pairs. The code and models are available at: https://github.com/xuguodong03/SSKD.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


1 Introduction
The seminal paper by Hinton et al. [15] show that the knowledge from a large ensemble of models can be distilled and transferred to a student network. Specifically, one can raise the temperature of the final softmax to produce soft targets of the teacher for guiding the training of the student. The guidance is achieved by minimizing the Kullback-Leibler (KL) divergence between teacher and student outputs. An interesting and inspiring observation is that despite the teacher model assigns probabilities to incorrect classes, the relative probabilities of incorrect answers are exceptionally informative about generalization of the trained model. The hidden knowledge encapsulated in these secondary probabilities is sometimes known as “dark knowledge”.
In this work, we are fascinated on how one could extract richer “dark knowledge” from neural networks. Existing studies focus on what types of intermediate representations of teacher networks should student mimic. These representations include feature map [36, 37], attention map [44], gram matrix [42], and feature distribution statistics [16]. While the intermediate representations of the network could provide more fine-grained information, a common characteristic shared by these medium of knowledge is that they are all derived from a single task (typically the original classification task). The knowledge is highly task-specific, and hence, such knowledge may only reflect a single facet of the complete knowledge encapsulated in a cumbersome network. To mine for richer “dark knowledge”, we need an auxiliary task apart from the original classification task, so as to extract richer information that is complementary to the classification knowledge.

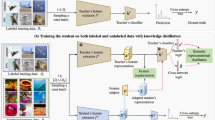
Difference between conventional KD [15] and SSKD. We extend the mimicking on normal data and on a single classification task to the mimicking on transformed data and with an additional self-supervision pretext task. The teacher’s self-supervision predictions contain rich structured knowledge that can facilitate more rounded knowledge distillation on the student. In this example, contrastive learning on transformed images serves as the self-supervision pretext task. It constructs a single positive pair and several negative pairs through image transformations \(t(\cdot )\), and then encourages the network to recognize the positive pair. The backbone of the teacher and student are represented as \(f_t\) and \(f_s\), respectively, while the corresponding output is given as t and s with subscript representing the index
In this study, we show that a seemingly different learning scheme – self-supervised learning, when treated as an auxiliary task, can help gaining more rounded knowledge from a teacher network. The original goal of self-supervised learning is to learn representations with natural supervisions derived from data via a pretext task. Examples of pretext tasks include exemplar-based method [8], rotation prediction [10], jigsaw [29], and contrastive learning [3, 26]. To use self-supervised learning as an auxiliary task for knowledge distillation, one can apply the pretext task to a teacher by appending a lightweight auxiliary branch/module to the teacher’s backbone, updating the auxiliary module with the backbone frozen, and then extract the corresponding self-supervised signals from the auxiliary module for distillation. An example of combining a contrastive learning pretext task [3] with knowledge distillation is shown in Fig. 1.
The example in Fig. 1 reveals several advantages of using self-supervised learning as an auxiliary task for knowledge distillation (we name the combination as SSKD). First, in conventional knowledge distillation, a student mimics a teacher from normal data based on a single classification task. SSKD extends the notion to a broader extent, i.e., mimicking on transformed data and on an additional self-supervision pretext task. This enables the student to capture richer structured knowledge from the self-supervision predictions of teacher, which cannot be sufficiently captured by a single task. We show that such structured knowledge not only improves the overall distillation performance, but also regularizes the student to generalize better on few-shot and noisy-label scenarios.
Another advantage of SSKD is that it is model-agnostic. Previous knowledge distillation methods suffer from degraded performance under cross-architecture settings, for the knowledge they transfer is architecture-specific. For example, when transfer the feature of ResNet50 [12] to ShuffleNet [49], student may have trouble in mimicking due to the architecture gap. In contrast, SSKD transfers only the last layer’s outputs, hence allowing a flexible solution space for the student model to search for intermediate features that best suit its own architecture.
Contributions: We propose a novel framework called SSKD that leverages self-supervised tasks to facilitate extraction of richer knowledge from teacher network to student network. To our knowledge, this is the first work that defines the knowledge through self-supervised tasks. We carefully investigate the influence of different self-supervised pretext tasks and the impact of noisy self-supervised predictions to the performance of knowledge distillation. We show that SSKD greatly boosts the generalizability of student networks and offers significant advantages under few-shot and noisy-label scenarios. Extensive experiments on two standard benchmarks, CIFAR100 [22] and ImageNet [5], demonstrate the effectiveness of SSKD over other state-of-the-art methods.
2 Related Work
Knowledge Distillation. Knowledge distillation trains a smaller network using the supervision signals from both ground truth labels and a larger network. Hinton et al. [15] propose to match the outputs of classifiers of two models by minimizing the KL-divergence of the category distribution. Besides the final layer logits, teacher network also distills compact feature representations from its backbone. FitNets [37] proposes to mimic the intermediate feature maps of teacher network. AT [44] uses attention transfer to teach student which region is the key for classification. FSP [42] distills the second order statistics (Gram matrix) between different layers. AB [14] forces student to learn the binarized values of pre-activation map. IRG [24] explores transferring the similarity between samples. KDSVD [18] calls its method as self-supervised knowledge distillation. Nevertheless, the study regards the teacher’s correlation maps of feature singular vectors as self-supervised labels. The label is obtained from the teacher rather than a self-supervised pretext task. Thus, their notion of self-supervised learning differ from the conventional one. Our work, to our knowledge, is the first study that investigates defining the knowledge via self-supervised pretext tasks. CRD [40] also combines self-supervision (SS) with distillation. The difference is the purpose of SS and how contrastive task is performed. In CRD, contrastive learning is performed across teacher and student networks to maximize the mutual information between two networks. In SSKD, contrastive task serves as a way to define knowledge. It is performed separately in two networks and then matched together through KL-divergence, which is very different from CRD.
Self-supervised Learning. Self-supervision methods design various pretext tasks whose labels can be derived from the data itself. In the process of solving these tasks, the network learn useful representations. Based on pretext tasks, SS methods can be grouped into several categories, including construction-based methods such as inpainting [34] and colorization [48], prediction-based methods [6, 8, 10, 20, 27, 29, 30, 45, 47], cluster-based methods [2, 46], generation-based methods [7, 9, 11] and contrastive-based methods [3, 13, 26, 31, 39]. Exemplar [8] applies heavy transformation to each training image and treat all the images generated from the same image as a separate category. Jigsaw puzzle [29] splits the image into several non-overlapping patches and forces the network to recognise the shuffled order. Jigsaw++ [30] also involves SS and KD. But it utilizes knowledge transfer to boost the self-supervision performance, which solves an inverse problem of SSKD. Rotation [20] feeds the network with rotated images and forces it to recognise the rotation angle. SimCLR [3] applies augmentation to training samples and requires the network to match original image and transformed image through contrastive loss. Considering the excellent performance obtained by SimCLR [3], we adopt it as our main pretext task in SSKD. However, SSKD is not limited to using only contrastive learning, many other pretext tasks [8, 20, 29] can also serve the purpose. We investigate their usefulness in Sect. 4.1.
3 Methodology
This section is divided into three main sections. We start with a brief review of knowledge distillation and self-supervision in Sect. 3.1. For self-supervision, we discuss contrastive prediction as our desired pretext task, although SSKD is not limited to contrastive prediction. Sect. 3.2 specifies the training process of teacher and student model. Finally, we discuss the influence of noisy self-supervised predictions and ways to handle the noise in Sect. 3.3.
3.1 Preliminaries
Knowledge Distillation. Hinton et al. [15] suggest that the soft targets predicted by a well-optimized teacher model can provide extra information, comparing to one-hot hard labels. The relatively high probabilities assigned to wrong categories encode semantic similarities between different categories. Forcing a student to mimic teacher’s prediction causes the student to learn this secondary information that cannot be expressed by hard labels alone. To obtain the soft targets, temperature scaling is introduced in [15] to soften the peaky distribution:
where x is the data sample, i is the category index, \(s_{i}(x)\) is the score logit that x obtains on category i, and \(\tau \) is the temperature. The knowledge distillation loss \(L_{kd}\) measured by KL-divergence is:
where t and s denote teacher and student models, respectively, C is the total number of classes, \(\mathcal {D}_x\) indicates the dataset. The complete loss function L of the student model is a linear combination of the standard cross-entropy loss \(L_{ce}\) and knowledge distillation loss \(L_{kd}\):
Contrastive Prediction as Self-supervision Task. Motivated by the success of contrastive prediction methods [3, 13, 26, 31, 39] for self-supervised learning, we adopt contrastive prediction as the self-supervision task in our framework. The general goal of contrastive prediction is to maximize agreement between a data point and its transformed version via a contrastive loss in latent space.
Given a mini-batch containing N data points \(\{x_i\}_{i=1:N}\), we apply independent transformation \(t(\cdot )\) (sampled from the same distribution \(\mathcal {T}\)) to each data point and obtain \(\{\widetilde{x}_i\}_{i=1:N}\). Both \(x_i\) and \(\widetilde{x}_i\) are fed into the teacher or student networks to extract representations \(\phi _i=f(x_i), \widetilde{\phi }_i=f(\widetilde{x}_i)\). We follow Chen et al. [3] and add a projection head on the top of the network. The projection head is a 2-layer multilayer perceptron. It maps the representations into a latent space where the contrastive loss is applied, i.e., \(z_i=\mathrm {MLP}(\phi _i), \widetilde{z}_i=\mathrm {MLP}(\widetilde{\phi }_i)\).
We take \((\widetilde{x}_i,x_i)\) as the positive pair and \((\widetilde{x}_i, x_k)_{k\ne i}\) as the negative pair. Given some \(\widetilde{x}_i\), the contrastive prediction task is to identify the corresponding \(x_i\) from the set \(\{x_i\}_{i=1:N}\). To meet the goal, the network should maximize the similarity between positive pairs and minimize the similarity between negative pairs. In this work, we use a cosine similarity. If we organize the similarities between \(\{\widetilde{x}_i\}\) and \(\{x_i\}\) into matrix form \(\mathcal {A}\), then we have:
where \(\mathcal {A}_{i,j}\) represents the similarity between \(\widetilde{x}_i\) and \(x_j\). The loss of contrastive prediction is:
where \(\tau \) is another temperature parameter (can be different from \(\tau \) in Eq. (1)). The loss form is similar to softmax loss and can be understood as maximizing the probability that \(\widetilde{z_i}\) and \(z_i\) come from a positive pair. In the process of matching \(\{\widetilde{x}_i\}\) and \(\{x_i\}\), the network learns transformation invariant representations. In SSKD, however, the main goal is not to learn representations invariant to transformations, but to exploit contrastive prediction as an auxiliary task for mining richer knowledge from the teacher model.
3.2 Learning SSKD
The framework of SSKD is shown in Fig. 2. Both teacher and student consist of three components: a backbone \(f(\cdot )\) to extract representations, a classifier \(p(\cdot )\) for the main task and a self-supervised (SS) module for specific self-supervision task. In this work, contrastive prediction is selected as the SS task, so the SS module \(c_t(\cdot ,\cdot )\) and \(c_s(\cdot ,\cdot )\) consist of a 2-layer MLP and a similarity computation module. More SS tasks will be compared in the experiments.

Training scheme of SSKD. Input images are transformed by designated transformations to prepare data for the self-supervision task. Teacher and student networks both contain three components, i.e., backbone \(f(\cdot )\), classifier \(p(\cdot )\) and SS module \(c(\cdot ,\cdot )\). Teacher’s training are split into two stages. The first stage trains \(f_t(\cdot )\) and \(p_t(\cdot )\) with a classification task, and the second stage fine-tunes \(c_t(\cdot ,\cdot )\) with a self-supervision task. In student’s training, we force the student to mimic teacher on both classification output and self-supervision output, besides the standard label loss
Training the Teacher Network. The inputs are normal data \(\{x_i\}\) and transformed version \(\{\widetilde{x}_i\}\). The transformation \(t(\cdot )\) is sampled from a predefined transformation distribution \(\mathcal {T}\). In this study, we select four transformations, i.e., color dropping, rotation, cropping followed by resize and color distortion, as depicted in Fig. 2. More transformations can be included. We feed x and \(\widetilde{x}\) to the backbone and obtain their representations \(\phi =f_t(x), \widetilde{\phi }=f_t(\widetilde{x})\).
The training of teacher network contains two stages. In the first stage, the network is trained with the classification loss. Only the backbone \(f_t(\cdot )\) and classifier \(p_t(\cdot )\) are updated. Note that the classification loss is not computed on transformed data \(\widetilde{x}\) because the transformation \(\mathcal {T}\) is much heavier than usual data augmentation. Its goal is not to enlarge the training set but to make the \(\widetilde{x}\) visually less similar to x. It makes the contradistinction much harder, which is beneficial to representation learning [3]. Forcing the network to classify \(\widetilde{x}\) correctly can destroy the semantic information learned from x and hurt the performance. In the second stage, we fix \(f_t(\cdot )\) and \(p_t(\cdot )\), and only update parameters in SS module \(c_t(\cdot ,\cdot )\) using the contrastive prediction loss in Eq. (5).
The two stages of training have distinct roles. The first stage is simply the typical training of a network for classification. The second stage, aims at adapting the SS module to use the features from the existing backbone for contrastive prediction. This allows us to extract knowledge from the SS module for distillation. It is worth pointing out that the second-stage training is highly efficient given the small MLP head, thus it is easy to prepare a teacher network for SSKD.
Training the Student Network. After training the teacher’s SS module, we apply softmax (with temperature scale \(\tau \)) to the teacher’s similarity matrix \(\mathcal {A}\) (Eq. (4)) along the row dimension leading to a probability matrix \(\mathcal {B}^t\), with \(\mathcal {B}^t_{i,j}\) representing the probability that \(\widetilde{x_i}\) and \(x_j\) is a positive pair. Similar operations are applied to the student to obtain \(\mathcal {B}^s\). With \(\mathcal {B}^t\) and \(\mathcal {B}^s\), we can compute the KL-divergence loss between the SS module’s output of both teacher and student:
The transformed data point \(\widetilde{x}\) is the side product of contrastive prediction task. Though we do not require the student to classify them correctly, we can encourage the student’s classifier output \(p_s(f_s(\widetilde{x}))\) to be close to that of teacher’s. The loss function is:
The final loss for student network is the combination of aforementioned terms, i.e., cross entropy loss \(L_{ce}\), \(L_{kd}\) in Eq. (2), \(L_{ss}\) in Eq. (6), and \(L_{T}\) in Eq. (7):
where the \(\lambda _i\) is the balancing weight.
3.3 Imperfect Self-supervised Predictions
When performing contrastive prediction, a teacher may produce inaccurate predictions, e.g., assigning \(x_k\) to the \(\widetilde{x_i}\), \(i \ne k\). This is very likely since the backbone of the teacher is not fine-tuned together with the SS module for contrastive prediction. Similar to conventional knowledge distillation, those relative probabilities that the teacher assigns to incorrect answers contain rich knowledge of the teacher. Transferring this inaccurate but structured knowledge is the core of our SSKD.
Nevertheless, we empirically found that an extremely incorrect prediction may still mislead the learning of the student. To ameliorate negative impacts of those outliers, we adopt an heuristic approach to perform selective transfer. Specifically, we define the error level of a prediction as the ranking of the corresponding ground truth label in the classification task. Given a transformed sample \(\widetilde{x}_i\) and corresponding positive pair index i, we sort the scores that the network assigns to each \(\{x_i\}_{i=1:N}\) in a descending order. The rank of \(x_i\) represents the error level of the prediction about \(\widetilde{x}_i\). The rank of 1 means the prediction is completely correct. A lower rank indicates a higher degree of error. During the training of student, we sort all the \(\widetilde{x}\) in a mini-batch in an ascending order according to error levels of the teacher’s prediction, and only transfer all the correct predictions and the top-\(k\%\) ranked incorrect predictions. This strategy suppresses potential noise in teacher’s predictions and transfer only beneficial knowledge. We show our experiments in Sect. 4.1.
4 Experiments
The experiments section consists of three parts. We first conduct ablation study to examine the effectiveness of several components of SSKD in Sect. 4.1. Comparison with state-of-the-art methods is conducted in Sect. 4.2. In Sect. 4.3, we further show SSKD’s advantages under few-shot and noisy-label scenarios.
Evaluations are conducted on CIFAR100 [22] and ImageNet [5] datasets, both of which are widely used as the benchmarks for knowledge distillation. CIFAR100 consists of 60, 000 \(32\times 32\) colour images, with 50, 000 images for training and 10, 000 images for testing. There are 100 classes, each contains 600 images. ImageNet is a large-scale classification dataset, containing 1, 281, 167 images for training and 50, 000 images for testing.
4.1 Ablation Study
Effectiveness of Self-supervision Auxiliary Task. The motivation behind SSKD is that teacher’s inaccurate self-supervision output encodes rich structured knowledge of teacher network and mimicking this output can benefit student’s learning. To examine this hypothesis, we train a student network whose only training signals come from teacher’s self-supervision output, i.e., set \(\lambda _1\),\(\lambda _2\), \(\lambda _3\) in Eq. (8) to be 0, and observe whether student can learn good representations.
We first demonstrate the utility by examining the student’s feature distribution. We select vgg13 [38] and vgg8 as the teacher and student networks, respectively. The CIFAR100 [22] training split is selected as the training set. After the training, we use the student backbone to extract features (before logits) of CIFAR100 test set. We randomly select 9 categories out of 100 and visualize the features with t-SNE. The results are shown in Fig. 3(a). Though the accuracy of teacher’s contrastive prediction is only around \(50\%\), mimicking this inaccurate output still makes student learn highly clustered patterns, showing that teacher’s self-supervision output does transfer meaningful structured knowledge.
To test the effectiveness of designed \(L_T\) and \(L_{ss}\), we compare three variants of SSKD with CIFAR100 on four teacher-student pairs. The three variants are: 1) conventional KD, 2) KD with additional loss \(L_T\) (KD + \(L_T\)), 3) full SSKD (KD + \(L_T\) + \(L_{ss}\)). The results are shown in Fig. 3(b). On all four different teacher-student pairs, \(L_T\) and \(L_{ss}\) boost the accuracies by a large margin, showing the effectiveness of our designed components.

Effectiveness of self-supervision auxiliary task. Mimicking the self-supervision output benefits the feature learning and final classification performance. (a) t-SNE visualization of learned features by mimicking teacher’s self-supervision output. Each color represents one category. (b) The consistent improvement across all four tested teacher-student network pairs demonstrates the effectiveness of including self-supervision task as an auxiliary task
Influence of Noisy Self-supervision Predictions. As discussed in Sect. 3.3, removing some extreme outliers are beneficial for SSKD. Some transformed samples with large error levels may play a misleading role. To examine this conjecture, we compare several students that receive different proportions of incorrect predictions from teacher. Specifically, we sort all the transformed \(\widetilde{x}\) in a mini-batch according to their error levels in an ascending order. We transfer all the correct predictions. For incorrect predictions, we only transfer top-\(k\%\) samples with the smallest error levels. A higher k value indicates a higher number of predictions with larger error levels being transferred to student network. Experiments are conducted on CIFAR100 with three teacher-student pairs. The results are shown in Table 1. The general trend shows that incorrect predictions are beneficial (\(k=0\) yields the lowest accuracies). Removing extreme outliers help to give a peak performance between \(k=50\) and \(k=75\) across different acchitectures. When comparing with other methods in Sect. 4.2 and 4.3, we fix \(k=75\) for all the teacher-student pairs.
Influence of Different Self-supervision Tasks. Different pretext tasks in self-supervision would result in different qualities of extracted features. Similarly, distillation with different self-supervision tasks also lead to students with different performances. Here, we examine the influence of SS method’s performance on SSKD. We employ the commonly used linear evaluation accuracy as our metric. In particular, each method first trains a network with its own pretext task. A single layer classifier is then trained by using the representations extracted from the fixed backbone. In this way, the classification accuracies represent the quality of SS methods. In Table 2, we compare four widely used self-supervision methods: Exemplar [8], Rotation [20], Jigsaw [29] and Contrastive [3]. We list the linear evaluation accuracies each method obtains on ImageNet with ResNet50 [12] network and also student’s accuracies when they are incorporated, respectively, into KD. We find that the performance of SSKD is positively correlated with the corresponding SS method.
4.2 Benchmark
CIFAR100. We compare our method with representative knowledge distillation methods, including: KD [15], FitNet [37], AT [44], SP [41], VID [1], RKD [32], PKT [33], AB [14], FT [19], CRD [40]. ResNet [12], wideResNet [43], vgg [38], ShuffleNet [49] and MobileNet [17] are selected as the network backbones. For all competing methods, we use the implementation of [40]. For a fair comparison, we combine all competing methods with conventional KD [15] (except KD itself). And we omit “+KD” notation in all the following tables (except for Table 5) and figures for simplicity.Footnote 1
We compare performances on 11 teacher-student pairs to investigate the generalization ability of each method. Following CRD [40], we split these pairs into 2 groups according to whether teacher and student have similar architecture styles. The results are shown in Table 3 and Table 4. In each table, the second partition after the header show the accuracies of the teacher’s and student’s performance when they are trained individually, while the third partition show the student’s performance after knowledge distillation.
For teacher-student pairs with a similar architecture, SSKD performs the best in four out of five pairs (Table 3). The gap between SSKD and the best-performing competing methods is 0.52% (averaged on five pairs). Notably, in all six teacher-student pairs with different architectures, SSKD consistently achieves the best results (Table 4), surpassing the best competing methods by a large margin with an average absolute accuracy difference of 2.14%. Results on cross-architecture pairs clearly demonstrate that our method does not rely on architecture-specific cues. Instead, SSKD distills knowledge only from the outputs of the final layer of teacher model. Such strategy allows a larger solution space for student model to search intermediate representations that best suit its own architecture.
ImageNet. Limited by computation resources, we only conduct one teacher-student pair on ImageNet, i.e., ResNet34 as teacher and ResNet18 as student. As shown in Table 5, for both Top-1 and Top-5 error rates, our SSKD obtains the best performances. The results on ImageNet demonstrate the scalability of SSKD to large-scale dataset.
Teacher-Student Similarity. SSKD can extract richer knowledge by mimicking self-supervision output and make student much more similar to teacher than other KD methods. To examine this claim, we analyze the similarity between student and teacher networks using two metrics, i.e., KL-divergence and CKA similarity [21]. Small KL-divergence and large CKA similarity indicate that student is similar to teacher. We use vgg13 and vgg8 as teacher and student, respectively, and use CIFAR100 as the training set. We compute the KL-divergence and CKA similarity between teacher and student on three sets, i.e., test partitions of CIFAR100, STL10 [4] and SVHN [28]. As shown in Table 6, our method achieves the smallest KL-divergence and the largest CKA similarity on CIFAR100 test set. Compared to CIFAR100, STL10 and SVHN have different distributions that have not been seen during training, therefore more difficult to mimic. However, the proposed SSKD still obtains the best results in all the metrics except KL-divergence in STL10. From this similarity analysis, we conclude that SSKD can help student mimic teacher better and get a larger similarity to teacher network.
4.3 Further Analysis

Accuracies on CIFAR100 test set under few-shot and noisy-label scenarios. (a) Students are trained with subsets of CIFAR100. SSKD achieves the best results in all cases. The superiority is especially striking when only 25% of the training data is available. (b) Students are trained with data with perturbed labels. The accuracies of FT and CRD drop dramatically as noisy labels increase, while SSKD is much more stable and maintains a high performance in all cases
Few-Shot Scenario. In a real-world setting, the number of samples available for training is often limited [25]. To investigate the performance of SSKD under few-shot scenarios, we conduct experiments on subsets of CIFAR100. We randomly sample images of each class to form a new training set. We train student model using newly crafted training set, while maintaining the same test set. Vgg13 and vgg8 are chosen as teacher and student model, respectively. We compare our student’s performance with KD [15], AT [44] and CRD [40]. The percentages of reserved samples are 25\(\%\), 50\(\%\), 75\(\%\) and 100\(\%\). For a fair comparison, we employ the same data for different methods.
The results are shown in Fig. 4(a). In all data proportions, SSKD achieves the best result. As training samples decrease, the superiority of our method becomes more apparent, e.g., \(\sim \)7% absolute improvement in accuracy compared to all competing methods when the percentage of reserved samples are 25\(\%\). Previous methods mainly focus on learning various intermediate features of teacher or exploring the relations between samples. The excessive mimicking leads to overfitting on the training set. In SSKD, the transformed images and self-supervision task endow the student model with structured knowledge that provides strong regularization, hence making it generalizes better to test set.
Noisy-Label Scenario. Our SSKD forces student to mimic teacher on both classification task and self-supervision task. The student learns more well rounded knowledge from the teacher model than relying entirely on annotated labels. Such strategy strengthens the ability of student to resist label noise. In this section, we investigate the performance of KD [15], FT [19], CRD [40] and SSKD when trained with noisy label data. We choose vgg13 and vgg8 as the teacher and student models, respectively. We assume the teacher is trained with clean data and will be shared by all students. This assumption does not affect evaluation on robustness of different distillation methods. When training student models, we randomly perturb the labels of certain portions of training data and use the original test data for evaluation. We introduce same disturbances to all methods. Since the loss weight of cross entropy on labels affects how well a model resists label noise, we use the same loss weight for all methods for a fair comparison. We set the percentage of disturbed labels to be \(0\%\), \(10\%\), \(30\%\) and \(50\%\). Results are shown in Fig. 4(b). SSKD outperforms competing methods in all noise ratios. As noise data increase, the performance of FT and CRD drop dramatically. KD and SSKD are more stable. Specifically, accuracy of SSKD only drop by a marginal \(0.45\%\) when the percentage of noise data increases from \(0\%\) to \(50\%\), demonstrating the robustness of SSKD against noisy data labels. We attribute the robustness to the structured knowledge offered by self-supervised tasks.
5 Conclusion
In this work, we proposed a novel framework called SSKD, the first attempt that combines self-supervision with knowledge distillation. It employs contrastive prediction as an auxiliary task to help extracting richer knowledge from teacher network. A selective transfer strategy is designed to suppress the noise in teacher knowledge. We examined our method by conducting thorough experiments on CIFAR100 and ImageNet using various architectures. Our method achieves state-of-the-art performances, demonstrating the effectiveness of our approach. Further analysis showed that our SSKD can make student more similar to teacher and work well under few-shot and noisy-label scenarios.
Notes
- 1.
For experiments on CIFAR100, since we add the conventional KD with competing methods, the results are slightly better than those reported in CRD [40]. More details on experimental setting are provided in the supplementary material.
References
Ahn, S., Hu, S.X., Damianou, A., Lawrence, N.D., Dai, Z.: Variational information distillation for knowledge transfer. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
Caron, M., Bojanowski, P., Joulin, A., Douze, M.: Deep clustering for unsupervised learning of visual features. In: The European Conference on Computer Vision (2018)
Chen, T., Kornblith, S., Norouzi, M., Hinton, G.: A simple framework for contrastive learning of visual representations. arXiv preprint arXiv:2002.05709 (2020)
Coates, A., Ng, A., Lee, H.: An analysis of single-layer networks in unsupervised feature learning. In: Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, vol. 15, pp. 215–223 (2011)
Deng, J., Dong, W., Socher, R., Li, L., Kai, L., Fei-Fei, L.: ImageNet: a large-scale hierarchical image database. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 248–255 (2009)
Doersch, C., Gupta, A., Efros, A.A.: Unsupervised visual representation learning by context prediction. In: The IEEE International Conference on Computer Vision (2015)
Donahue, J., Simonyan, K.: Large scale adversarial representation learning. In: Advances in Neural Information Processing Systems, pp. 10541–10551 (2019)
Dosovitskiy, A., Fischer, P., Springenberg, J.T., Riedmiller, M., Brox, T.: Discriminative unsupervised feature learning with exemplar convolutional neural networks. arXiv preprint arXiv:1406.6909 (2014)
Dumoulin, V., et al.: Adversarially learned inference. In: International Conference on Learning Representations (2017)
Gidaris, S., Singh, P., Komodakis, N.: Unsupervised representation learning by predicting image rotations. In: International Conference on Learning Representations (2018)
Goodfellow, I., et al.: Generative adversarial nets. In: Advances in Neural Information Processing Systems, pp. 2672–2680 (2014)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hénaff, O.J., Razavi, A., Doersch, C., Eslami, S.M.A., van den Oord, A.: Data-efficient image recognition with contrastive predictive coding. arXiv preprint arXiv:1905.09272 (2019)
Heo, B., Lee, M., Yun, S., Choi, J.Y.: Knowledge transfer via distillation of activation boundaries formed by hidden neurons. In: AAAI, pp. 3779–3787 (2019)
Hinton, G., Vinyals, O., Dean, J.: Distilling the knowledge in a neural network. In: NIPS Deep Learning and Representation Learning Workshop (2015)
Hou, Y., Ma, Z., Liu, C., Hui, T.W., Loy, C.C.: Inter-region affinity distillation for road marking segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition (2020)
Howard, A.G., et al.: MobileNets: efficient convolutional neural networks for mobile vision applications. arXiv preprint arXiv:1704.04861 (2017)
Lee, S.H., Kim, D.H., Song, B.C.: Self-supervised knowledge distillation using singular value decomposition. In: Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y. (eds.) ECCV 2018. LNCS, vol. 11210, pp. 339–354. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-01231-1_21
Kim, J., Park, S., Kwak, N.: Paraphrasing complex network: network compression via factor transfer. In: Advances in Neural Information Processing Systems, pp. 2760–2769 (2018)
Kolesnikov, A., Zhai, X., Beyer, L.: Revisiting self-supervised visual representation learning. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
Kornblith, S., Norouzi, M., Lee, H., Hinton, G.E.: Similarity of neural network representations revisited. In: International Conference on Machine Learning. Proceedings of Machine Learning Research, vol. 97, pp. 3519–3529 (2019)
Krizhevsky, A.: Learning multiple layers of features from tiny images. Technical report (2009)
Lan, X., Zhu, X., Gong, S.: Knowledge distillation by on-the-fly native ensemble. In: Advances in Neural Information Processing Systems, pp. 7528–7538 (2018)
Liu, Y., et al.: Knowledge distillation via instance relationship graph. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
Liu, Z., Miao, Z., Zhan, X., Wang, J., Gong, B., Yu, S.X.: Large-scale long-tailed recognition in an open world. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
Misra, I., van der Maaten, L.: Self-supervised learning of pretext-invariant representations. arXiv preprint arXiv:1912.01991 (2019)
Misra, I., Zitnick, C.L., Hebert, M.: Shuffle and learn: unsupervised learning using temporal order verification. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9905, pp. 527–544. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46448-0_32
Netzer, Y., Wang, T., Coates, A., Bissacco, A., Wu, B., Ng, A.Y.: Reading digits in natural images with unsupervised feature learning. In: NIPS Workshop on Deep Learning and Unsupervised Feature Learning (2011)
Noroozi, M., Favaro, P.: Unsupervised learning of visual representations by solving jigsaw puzzles. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9910, pp. 69–84. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46466-4_5
Noroozi, M., Vinjimoor, A., Favaro, P., Pirsiavash, H.: Boosting self-supervised learning via knowledge transfer. In: IEEE Conference on Computer Vision and Pattern Recognition (2018)
van den Oord, A., Li, Y., Vinyals, O.: Representation learning with contrastive predictive coding. arXiv preprint arXiv:1807.03748 (2018)
Park, W., Kim, D., Lu, Y., Cho, M.: Relational knowledge distillation. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
Passalis, N., Tefas, A.: Learning deep representations with probabilistic knowledge transfer. In: The European Conference on Computer Vision (2018)
Pathak, D., Krähenbühl, P., Donahue, J., Darrell, T., Efros, A.: Context encoders: feature learning by inpainting. In: IEEE Conference on Computer Vision and Pattern Recognition (2016)
Peng, B., Jin, X., Liu, J., Li, D., Wu, Y., Liu, Y., Zhou, S., Zhang, Z.: Correlation congruence for knowledge distillation. In: The IEEE International Conference on Computer Vision (2019)
Rao, A., et al.: A unified framework for shot type classification based on subject centric lens. In: The European Conference on Computer Vision (2020)
Romero, A., Ballas, N., Kahou, S.E., Chassang, A., Gatta, C., Bengio, Y.: FitNets: hints for thin deep nets. arXiv preprint arXiv:1412.6550 (2014)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Tian, Y., Krishnan, D., Isola, P.: Contrastive multiview coding. arXiv preprint arXiv:1906.05849 (2019)
Tian, Y., Krishnan, D., Isola, P.: Contrastive representation distillation. In: International Conference on Learning Representations (2020)
Tung, F., Mori, G.: Similarity-preserving knowledge distillation. In: The IEEE International Conference on Computer Vision (2019)
Yim, J., Joo, D., Bae, J., Kim, J.: A gift from knowledge distillation: fast optimization, network minimization and transfer learning. In: IEEE Conference on Computer Vision and Pattern Recognition (2017)
Zagoruyko, S., Komodakis, N.: Wide residual networks. arXiv preprint arXiv:1605.07146 (2016)
Zagoruyko, S., Komodakis, N.: Paying more attention to attention: improving the performance of convolutional neural networks via attention transfer. In: International Conference on Learning Representations (2017)
Zhan, X., Pan, X., Liu, Z., Lin, D., Loy, C.C.: Self-supervised learning via conditional motion propagation. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
Zhan, X., Xie, J., Liu, Z., Ong, Y.S., Loy, C.C.: Online deep clustering for unsupervised representation learning. In: IEEE Conference on Computer Vision and Pattern Recognition (2020)
Zhang, L., Qi, G.J., Wang, L., Luo, J.: AET vs. AED: unsupervised representation learning by auto-encoding transformations rather than data. In: IEEE Conference on Computer Vision and Pattern Recognition (2019)
Zhang, R., Isola, P., Efros, A.A.: Colorful image colorization. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9907, pp. 649–666. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46487-9_40
Zhang, X., Zhou, X., Lin, M., Sun, J.: ShuffleNet: an extremely efficient convolutional neural network for mobile devices. In: IEEE Conference on Computer Vision and Pattern Recognition (2018)
Acknowledgement
This research was supported by SenseTime-NTU Collaboration Project, Collaborative Research Grant from SenseTime Group (CUHK Agreement No. TS1610626 & No. TS1712093), and NTU NAP.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Xu, G., Liu, Z., Li, X., Loy, C.C. (2020). Knowledge Distillation Meets Self-supervision. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12354. Springer, Cham. https://doi.org/10.1007/978-3-030-58545-7_34
Download citation
DOI: https://doi.org/10.1007/978-3-030-58545-7_34
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58544-0
Online ISBN: 978-3-030-58545-7
eBook Packages: Computer ScienceComputer Science (R0)