
Abstract
Informative features play a crucial role in the single image super-resolution task. Channel attention has been demonstrated to be effective for preserving information-rich features in each layer. However, channel attention treats each convolution layer as a separate process that misses the correlation among different layers. To address this problem, we propose a new holistic attention network (HAN), which consists of a layer attention module (LAM) and a channel-spatial attention module (CSAM), to model the holistic interdependencies among layers, channels, and positions. Specifically, the proposed LAM adaptively emphasizes hierarchical features by considering correlations among layers. Meanwhile, CSAM learns the confidence at all the positions of each channel to selectively capture more informative features. Extensive experiments demonstrate that the proposed HAN performs favorably against the state-of-the-art single image super-resolution approaches.
B. Niu and W. Wen—Equal contribution.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Single image super-resolution (SISR) is an important task in computer vision and image processing. Given a low-resolution image, the goal of super-resolution (SR) is to generate a high-resolution (HR) image with necessary edge structures and texture details. The advance of SISR will immediately benefit many application fields, such as video surveillance and pedestrian detection.
SRCNN [3] is an unprecedented work to tackle the SR problem by learning the mapping function from LR input to HR output using convolutional neural networks (CNNs). Afterwards, numerous deep CNN-based methods [26, 27] have been proposed in recent years and generate a significant progress. The superior reconstruction performance of CNNs based methods are mainly from deep architecture and residual learning [7]. Networks with very deep layers have larger receptive fields and are able to provide a powerful capability to learn a complicated mapping between the LR input and the HR counterpart. Due to the residual learning, the depth of the SR networks are going to deeper since residual learning could efficiently alleviate the gradient vanishing and exploding problems.
Though significant progress have been made, we note that the texture details of the LR image often tend to be smoothed in the super-resolved result since most existing CNN-based SR methods neglect the feature correlation of intermediate layers. Therefore, generating detailed textures is still a non-trivial problem in the SR task. Although the results obtained by using channel attention [2, 40] retain some detailed information, these channel attention-based approaches struggle in preserving informative textures and restoring natural details since they treat the feature maps at different layers equally and result in lossing some detail parts in the reconstructed image.
To address these problems, we present a novel approach termed as holistic attention network (HAN) that is capable of exploring the correlations among hierarchical layers, channels of each layer, and all positions of each channel. Therefore, HAN is able to stimulate the representational power of CNNs. Specifically, we propose a layer attention module (LAM) and a channel-spatial attention module (CSAM) in the HAN for more powerful feature expression and correlation learning. These two sub-attention modules are inspired by channel attention [40] which weighs the internal features of each layer to make the network pay more attention to information-rich feature channels. However, we notice that channel attention cannot weight the features from multi-scale layers. Especially the long-term information from the shallow layers are easily weakened. Although the shallow features can be recycled via skip connections, they are treated equally with deep features across layers after long skip connection, hence hindering the representational ability of CNNs. To solve this problem, we consider exploring the interrelationship among features at hierarchical levels, and propose a layer attention module (LAM). On the other hand, channel attention neglects that the importance of different positions in each feature map varies significantly. Therefore, we also propose a channel-spatial attention module (CSAM) to collaboratively improve the discrimination ability of the proposed SR network.
Our contributions in this paper are summarized as follows:
-
We propose a novel super-resolution algorithm named Holistic Attention Network (HAN), which enhances the representational ability of feature representations for super-resolution.
-
We introduce a layer attention module (LAM) to learn the weights for hierarchical features by considering correlations of multi-scale layers. Meanwhile, a channel-spatial attention module (CSAM) is presented to learn the channel and spatial interdependencies of features in each layer.
-
The proposed two attention modules collaboratively improve the SR results by modeling informative features among hierarchical layers, channels, and positions. Extensive experiments demonstrate that our algorithm performs favorably against the state-of-the-art SISR approaches.
2 Related Work
Numerous algorithms and models have been proposed to solve the problem of image SR, which can be roughly divided into two categories. One is the traditional algorithm [11, 12, 35], the other one is the deep learning model based on neural network [4, 15, 16, 19, 22, 30, 31, 41]. Due to the limitation of space, we only introduce the SR algorithms based on deep CNN.
Deep CNN for Super-Resolution. Dong et al. [3] proposed a CNN architecture named SRCNN, which was the pioneering work to apply deep learning to single image super-resolution. Since SRCNN successfully applied deep learning network to SR task, various efficient and deeper architectures have been proposed for SR. Wang et al. [33] combined the domain knowledge of sparse coding with a deep CNN and trained a cascade network to recover images progressively. To alleviate the phenomenon of gradient explosion and reduce the complexity of the model, DRCN [16] and DRRN [30] were proposed by using a recursive convolutional network. Lai et al. [19] proposed a LapSR network which employs a pyramidal framework to progressively generate \(\times 8\) images by three sub-networks. Lim et al. [22] modified the ResNet [7] by removing batch normalization (BN) layers, which greatly improves the SR effect.
In addition to above MSE minimizing based methods, perceptual constraints are proposed to achieve better visual quality [28]. SRGAN [20] uses a generative adversarial networks (GAN) to predict high-resolution outputs by introducing a multi-task loss including a MSE loss, a perceptual loss [14], and an adversarial loss [5]. Zhang et al. [42] further transferred textures from reference images according to the textural similarity to enhance textures. However, the aforementioned models either result in the loss of detailed textures in intermediate features due to the very deep depth, or produce some unpleasing artifacts or inauthentic textures. In contrast, we propose a holistic attention network consists of a layer attention and a channel-spatial attention to investigate the interaction of different layers, channels, and positions.
Attention Mechanism. Attention mechanisms direct the operational focus of deep neural networks to areas where there is more information. In short, they help the network ignore irrelevant information and focus on important information [8, 9]. Recently, attention mechanism has been successfully applied into deep CNN based image enhancement methods. Zhang et al. [40] proposed a residual channel attention network (RCAN) in which residual channel attention blocks (RCAB) allow the network to focus on the more informative channels. Woo et al. [34] proposed channel attention (CA) and spatial attention (SA) modules to exploit both inter-channel and inter-spatial relationship of feature maps. Kim et al. [17] introduced a residual attention module for SR which is composed of residual blocks and spatial channel attention for learning the inter-channel and intra-channel correlations. More recently, Dai et al. [2] presented a second-order channel attention (SOCA) module to adaptively refine features using second-order feature statistics.

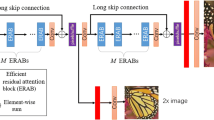
Network architecture of the proposed holistic attention network (HAN). Given a low-resolution image, the first convolutional layer of the HAN extracts a set of shallow feature maps. Then a series of residual groups further extract deeper feature representations of the low-resolution input. We propose a layer attention module (LAM) to learn the correlations of each output from RGs and a channel-spatial attention module (CSAM) to investigate the interdependencies between channels and pixels. Finally, an upsampling block produces the high-resolution image
However, these attention based methods only consider the channel and spatial correlations while ignore the interdependencies between multi-scale layers. To solve this problem, we propose a layer attention module (LAM) to exploit the nonlinear feature interactions among hierarchical layers.
3 Holistic Attention Network (HAN) for SR
In this section, we first present the overview of HAN network for SISR. Then we give the detailed configurations of the proposed layer attention module (LAM) and channel-spatial attention module (CSAM).
3.1 Network Architecture
As shown in Fig. 1, our proposed HAN consists of four parts: feature extraction, layer attention module, channel-spatial attention module, and the final reconstruction block.
Features Extraction. Given a LR input \(I_{LR}\), a convolutional layer is used to extract the shallow feature \(F_0\) of the LR input
Then we use the backbone of the RCAN [40] to extract the intermediate features \(F_i\) of the LR input
where \(H_{RB_i}\) represents the i-th residual group (RG) in the RCAN, N is the number of the residual groups. Therefore, except \(F_{N}\) is the final output of RCAN network backbone, all other feature maps are intermediate outputs.
Holistic Attention. After extracting hierarchical features \(F_i\) by a set of residual groups, we further conduct a holistic feature weighting, which includes: i) layer attention of hierarchical features, and ii) channel-spatial attention of the last layer of RCAN.
The proposed layer attention makes full use of features from all the preceding layers and can be represented as
where \( H_{LA} \) represents the LAM which learns the feature correlation matrix of all the features from RGs’ output and then weights the fused intermediate features \(F_i\) capitalized on the correlation matrix (see Sect. 3.2). As a results, LAM enables the high contribution feature layers to be enhanced and the redundant ones to be suppressed.
In addition, channel-spatial attention aims to modulate features for adaptively capturing more important information of inter-channel and intra-channel for the final reconstruction, which can be written as
where \( H_{CSA} \) represents the CSAM to produce channel-spatial attention for discriminately abtaining feature information, \(F_{CS}\) denotes the filtered features after channel-spatial attention (details can be found in Sect. 3.3). Although we can filter all the intermediate features of \(F_i\) using CSAM, we only modulate the last feature layer of \(F_N\) as a trade-off between accuracy and speed.
Image Reconstruction. After obtaining features from both LAM and CSAM, we integrate the layer attention and channel-spatial attention units by element-wise summation. Then, we employ the sub-pixel convolution [29] as the last upsampling module, which converts the scale sampling with a given magnification factor by pixel translation. We perform the sub-pixel convolution operation to aggregate low-resolution feature maps and simultaneously impose projection to high dimensional space to reconstruct the HR image. We formulate the process as follows
Where \( U_{\uparrow } \) represents the operation of sub-pixel convolution, and \( I_{SR} \) is the reconstructed SR result. The long skip connection is introduced in HAN to stabilize the training of the proposed deep network, i.e., the sub-pixel upsampling block takes \(F_0 + F_L + F_{CS}\) as input.
Loss Function. Since we employ the RCAN network as the backbone of the proposed method, only \( L_{1} \) distance is selected as our loss function as in [40] for a fair comparison
Where \(H_{HAN}\), \( \varTheta \), and m denote the function of the proposed HAN, the learned parameter of the HAN, and the number of training pairs, respectively. Note that we do not use other sophisticated loss functions such as adversarial loss [5] and perceptual loss [14]. We show that simply using the naive image intensity loss \(L(\varTheta )\) can already achieve competitive results as demonstrated in Sect. 4.

Architecture of the proposed layer attention module
3.2 Layer Attention Module
Although dense connections [10] and skip connections [7] allow shallow information to be bypassed to deep layers, these operations do not exploit interdependencies between the different layers. In contrast, we treat the feature maps from each layer as a response to a specific class, and the responses from different layers are related to each other. By obtaining the dependencies between features of different depths, the network can allocate different attention weights to features of different depths and automatically improve the representation ability of extracted features. Therefore, we propose an innovative LAM that learns the relationship between features of different depths, which automatically improve the feature representation ability.
The structure of the proposed layer attention is shown in Fig. 2. The input of the module is the extracted intermediate feature groups FGs, with the dimension of \( N \) \(\times \) \( H \) \(\times \) \( W \) \(\times \) \( C \), from N residual groups. Then, we reshape the feature groups FGs into a 2D matrix with the dimension of \( N\times HWC\), and apply matrix multiplication with the corresponding transpose to calculate the correlation \(W_{la} = w_{i,j=1}^N\) between different layers
where \(\delta (\cdot )\) and \(\varphi (\cdot )\) denote the softmax and reshape operations, \( w_{i,j} \) represents the correlation index between i-th and j-th feature groups. Finally, we multiply the reshaped feature groups FGs by the predicted correlation matrix with a scale factor \( \alpha \), and add the input features FGs
where \( \alpha \) is initialized to 0 and is automatically assigned by the network in the following epochs. As a result, the weighted sum of features allow the main parts of network to focus on more informative layers of the intermediate LR features.

Architecture of the proposed channel-spatial attention module
3.3 Channel-Spatial Attention
The existing spatial attention mechanisms [17, 34] mainly focuse on the scale dimension of the feature, with little uptake of channel dimension information, while the recent channel attention mechanisms [2, 40, 41] ignore the scale information. To solve this problem, we propose a novel channel-spatial attention mechanism (CSAM) that contains responses from all dimensions of the feature maps. Note that although we can perform the CSAM for all the feature groups FGs extracted from RCAN, we only modulate the last feature group of \(F_N\) for a trade-off between accuracy and speed as shown in Fig. 1.
The architecture of the proposed CSAM is shown in Fig. 3. Given the last layer feature maps \( F_N \in R^{H\times W \times C} \), we feed \(F_N\) to a 3D convolution layer [13] to generate correlation matrix by capturing joint channel and spatial features. We operate the 3D convolution via convolving 3D kernels with the cube constructed from multiple neighboring channels of \(F_N\). Specifically, we perform 3D convolutions with kernel size of \( 3\times 3\times 3 \) with step size of 1 (i.e., three groups of consecutive channels are convolved with a set of 3D kernels respectively), resulting in three groups of channel-spatial correlation matrix \(W_{csa}\). By doing so, our CSAM can extract powerful representations to describe inter-channel and intra-channel information in continuous channels.
In addition, we perform element-wise multiplication with the correlation matrix \( W_{csa} \) and the input feature \( F_N \). Finally, multiply the weighted result by a scale factor \( \beta \), and then add the input feature \(F_N\) to obtain the weighted features
where \(\sigma (\cdot )\) is the sigmoid function, \( \odot \) is the element-wise product, the scale factor \( \beta \) is initialized as 0 and progressively improved in the follow iterations. As a results, \(F_{CS}\) is the weighted sum of all channel-spatial position features as well as the original features. Compared with conventional spatial attention and channel attention, our CSAM adaptively learns the inter-channel and intra-channel feature responses by explicitly modelling channel-wise and spatial feature interdependencies.
4 Experiments
In this section, we first analyze the contributions of the proposed two attention modules. We then compare our HAN with state-of-the-art algorithms on five benchmark datasets. The implementation code will be made available to the public. Results on more images can be found in the supplementary material.

Visual comparison for 4\(\times \) SR with BI degradation model on the Urban100 datasets. The best results are highlighted. Our method obtains better visual quality and recovers more image details compared with other state-of-the-art SR methods
4.1 Settings
Datasets. We selecte DIV2K [32] as the training set as like in [2, 22, 40, 41]. For the testing set, we choose five standard datasets: Set5 [1], Set14 [36], B100 [23], Urban100 [11], and Manga109 [24]. Degraded data was obtained by bicubic interpolation and blur-downscale degradation model. Following [40], the reconstruct RGB results by the proposed HAN are first converted to YCbCr space, and then we only consider the luminance channel to calculate PSNR and SSIM in our experiments.
Implementation Details. We implement the proposed network using PyTorch platform and use the pre-trained RCAN (\( \times 2 \)), (\( \times 3 \)), (\( \times 4 \)), (\( \times 8 \)) model to initialize the corresponding holistic attention networks, respectively. In our network, patch size is set as \( 64 \times 64 \). We use ADAM [18] optimizer with a batch size 16 for training. The learning rate is set as \( 10^{-5} \). Default values of \( \beta _{1}\) and \(\beta _{2}\) are used, which are 0.9 and 0.999, respectively, and we set \( \epsilon =10^{-8} \). We do not use any regularization operations such as batch normalization and group normalization in our network. In addition to random rotation and translation, we do not apply other data augmentation methods in the training. The input of the LAM is selected as the outputs of all residual groups of RCAN, we use \(N=10\) residual groups in out network. For all the results reported in the paper, we train the network for 250 epochs, which takes about two days on an Nvidia GTX 1080Ti GPU.

Visual comparison for 8\(\times \) SR with BI model on the Manga109 dataset. The best results are highlighted

Visual comparison for 3\(\times \) SR with BD model on the Urban100 dataset. The best results are highlighted
4.2 Ablation Study About the Proposed LAM and CSAM
The proposed LAM and CSAM ensure that the proposed SR method generate the feature correlations between hierarchical layers, channels, and locations. One may wonder whether the LAM and CSAM help SISR. To verify the performance of these two attention mechanisms, we compare the method without using LAM and CSAM in Table 1, where we conduct experiments on the Manga109 dataset with the magnification factor of \(\times 4\).
Table 1 shows the quantitative evaluations. Compared with the baseline method which is identical to the proposed network except for the absence of these two modules LAM and CSAM. CSAM achieves better results by up to 0.06 dB in terms of PSNR, while LAM promotes 0.16 dB on the test dataset. In addition, the improvement of using both LAM and CSAM is significant as the proposed algorithm improves 0.2 dB, which demonstrates the effectiveness of the proposed layer attention and channel-spatial attention blocks. Figure 4 further shows that using the LAM and CSAM is able to generate the results with clearer structures and details.
4.3 Ablation Study About the Number of Residual Group
We conduct an ablation study about feeding different numbers of RGs to the proposed LAM. Specifically, we apply severally three, six, and ten RGs to the LAM, and we evaluate our model on five standard datasets. As shown in Table 2, we compare our three models with RCAN, although using fewer RGs, our algorithm still generates higher PSNR values than the baseline of RCAN. This ablation study demonstrates the effectiveness of the proposed LAM.
4.4 Ablation Study About the Number of CSAM
In the paper, the channel-spatial attention module (CSAM) can extract powerful representations to describe inter-channel and intra-channel information in continuous channels. We conduct an ablation study about using different numbers of CSAM. We use one, three, five, and ten CSAMs in RGs. As shown in Table 4, with the increase of CSAM, the values of PSNR are increasing on the testing datasets. This ablation study demonstrates the effectiveness of the proposed CSAM.
4.5 Results with Bicubic (BI) Degradation Model
We compare the proposed algorithm with 11 state-of-the-art methods: SRCNN [3], FSRCNN [4], VDSR [15], LapSRN [19], MemNet [31], SRMDNF [38], D-DBPN [6], RDN [41], EDSR [22], SRFBN [21] and SAN [2]. We provide more comparisons in supplementary material. Following [2, 22, 40], we also propose self-ensemble model and donate it as HAN+.
Quantitative Results. Table 3 shows the comparison of 2\(\times \), 3\( \times \), 4\( \times \), and 8\( \times \) SR quantitative results. Compared to existing methods, our HAN+ performs best on all the scales of reconstructed test datasets. Without using self-ensemble, our network HAN still obtains great gain compared with the recent SR methods. In particular, our model is much better than SAN which also uses the same backbone network of RCAN and has more computationally intensive attention module. Specifically, when we compare the reconstruction results at \( \times \)8 scale on the Set5 dataset, the proposed HAN advances 0.11 dB in terms of PSNR than the competitive SAN.
To further evaluate the proposed HAN, we conduct experiments on the large test sets of B100, Urban100, and Manga109. Our algorithm still performs favorably against the state-of-the-art methods. For example, the super-resolved results by the proposed HAN is 0.06 dB and 0.35 dB higher than the very recent work of SAN for the 4\( \times \) and 8\( \times \) scales, respectively.
Visual Results. We also show visual comparisons of various methods on the Urban100 dataset for 4\(\times \) SR in Fig. 4. As shown, most compared SR networks cannot recover the grids of buildings accurately and suffer from unpleasant blurring artifacts. In contrast, the proposed HAN obtains clearer details and reconstructs sharper high-frequency textures.
Take the first and fourth images in Fig. 4 as example, VDSR and EDSR fail to generate the clear structures. The results generated by the recent work of RCAN, SRFBN, and SAN still contain noticeable artifacts caused by spatial aliasing. In contrast, our approach effectively suppresses such artifacts through the proposed two attention modules. As shown, our method accurately reconstructs the grid patterns on windows in the first row and the parallel straight lines on the building in the fourth image.
For 8\(\times \) SR, we also show the super-resolved results by different SR methods in Fig. 5. As show, it is challenging to predict HR images from bicubic-upsampled input by VDSR and EDSR. Even the state-of-the-art methods of RCAN and SRFBN cannot super-resolve the fine structures well. In contrast, our HAN reconstructs high-quality HR images for 8\(\times \) results by using cross-scale layer attention and channel-spatial attention modules on the limited information.
4.6 Results with Blur-Downscale Degradation (BD) Model
Quantitative Results. Following the protocols of [37, 38, 41], we further compare the SR results on images with blur-downscale degradation model. We compare the proposed method with nine state-of-the-art super-resolution methods: SPMSR [25], SRCNN [3], FSRCNN [4], VDSR [15], IRCNN [37], SRMD [39], RDN [41], RCAN [40],SRFBN [21] and SAN [2]. Quantitative results on the 3\(\times \) SR are reported in Table 5. As shown, both the proposed HAN and HAN+ perform favorably against existing methods. In particular, our HAN+ yields the best quantitative results and HAN obtains the second best scores for all the datasets, 0.06–0.2 dB PSNR better than the attention-based methods of RCAN and SAN and 0.2–0.8 dB better than the recently proposed SRFBN.
Visual Quality. In Fig. 6, we show visual results on images from the Urban 100 dataset with blur-downscale degradation model by a scale factor of 3. Both the full images and the cropped regions are shown for comparison. We find that our proposed HAN is able to recover structured details that were missing in the LR image by properly exploiting the layer, channel, and spatial attention in the feature space.
As shown, VDSR and EDSR suffer from unpleasant blurring artifacts and some results even are out of shape. RCAN alleviate it to a certain extent, but still misses some details and structures. SRFBN and SAN also fail to recover these structured details. In contrast, our proposed HAN effectively suppresses artifacts and exploits the scene details and the internal natural image statistics to super-resolve the high-frequency contents.
5 Conclusions
In this paper, we propose a holistic attention network for single image super-resolution, which adaptively learns the global dependencies among different depths, channels, and positions using the self-attention mechanism. Specifically, the layer attention module captures the long-distance dependencies among hierarchical layers. Meanwhile, the channel-spatial attention module incorporates the channel and contextual information in each layer. These two attention modules are collaboratively applied to multi-level features and then more informative features can be captured. Extensive experimental results on benchmark datasets demonstrate that the proposed model performs favorably against the state-of-the-art SR algorithms in terms of accuracy and visual quality.
Change history
08 December 2020
In the originally published version of chapter 12, the first affiliation stated a wrong city and country. This has been corrected.
References
Bevilacqua, M., Roumy, A., Guillemot, C., Alberi-Morel, M.L.: Low-complexity single-image super-resolution based on nonnegative neighbor embedding. In: BMVC (2012)
Dai, T., Cai, J., Zhang, Y., Xia, S.T., Zhang, L.: Second-order attention network for single image super-resolution. In: CVPR (2019)
Dong, C., Loy, C.C., He, K., Tang, X.: Learning a deep convolutional network for image super-resolution. In: Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T. (eds.) ECCV 2014. LNCS, vol. 8692, pp. 184–199. Springer, Cham (2014). https://doi.org/10.1007/978-3-319-10593-2_13
Dong, C., Loy, C.C., Tang, X.: Accelerating the super-resolution convolutional neural network. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 391–407. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_25
Goodfellow, I., et al.: Generative adversarial nets. In: NIPS (2014)
Haris, M., Shakhnarovich, G., Ukita, N.: Deep back-projection networks for super-resolution. In: CVPR (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: CVPR (2016)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: CVPR (2018)
Hu, Y., Li, J., Huang, Y., Gao, X.: Channel-wise and spatial feature modulation network for single image super-resolution. IEEE Trans. Circ. Syst. Video Technol. (2019)
Huang, G., Liu, Z., Van Der Maaten, L., Weinberger, K.Q.: Densely connected convolutional networks. In: CVPR (2017)
Huang, J.B., Singh, A., Ahuja, N.: Single image super-resolution from transformed self-exemplars. In: CVPR (2015)
Huang, S., Sun, J., Yang, Y., Fang, Y., Lin, P., Que, Y.: Robust single-image super-resolution based on adaptive edge-preserving smoothing regularization. TIP 27(6), 2650–2663 (2018)
Ji, S., Xu, W., Yang, M., Yu, K.: 3D convolutional neural networks for human action recognition. TPAMI 35(1), 221–231 (2012)
Johnson, J., Alahi, A., Fei-Fei, L.: Perceptual losses for real-time style transfer and super-resolution. In: Leibe, B., Matas, J., Sebe, N., Welling, M. (eds.) ECCV 2016. LNCS, vol. 9906, pp. 694–711. Springer, Cham (2016). https://doi.org/10.1007/978-3-319-46475-6_43
Kim, J., Kwon Lee, J., Mu Lee, K.: Accurate image super-resolution using very deep convolutional networks. In: CVPR (2016)
Kim, J., Kwon Lee, J., Mu Lee, K.: Deeply-recursive convolutional network for image super-resolution. In: CVPR (2016)
Kim, J.H., Choi, J.H., Cheon, M., Lee, J.S.: Ram: Residual attention module for single image super-resolution. arXiv preprint arXiv:1811.12043 (2018)
Kingma, D.P., Ba, J.: Adam: a method for stochastic optimization. arXiv preprint arXiv:1412.6980 (2014)
Lai, W.S., Huang, J.B., Ahuja, N., Yang, M.H.: Deep Laplacian Pyramid Networks for fast and accurate super-resolution. In: CVPR (2017)
Ledig, C., et al.: Photo-realistic single image super-resolution using a generative adversarial network. In: CVPR (2017)
Li, Z., Yang, J., Liu, Z., Yang, X., Jeon, G., Wu, W.: Feedback network for image super-resolution. In: CVPR (2019)
Lim, B., Son, S., Kim, H., Nah, S., Mu Lee, K.: Enhanced deep residual networks for single image super-resolution. In: CVPR (2017)
Martin, D., Fowlkes, C., Tal, D., Malik, J.: A database of human segmented natural images and its application to evaluating segmentation algorithms and measuring ecological statistics. In: ICCV (2001)
Matsui, Y., et al.: Sketch-based manga retrieval using manga109 dataset. Multimedia Tools Appl. 76(20), 21811–21838 (2016). https://doi.org/10.1007/s11042-016-4020-z
Peleg, T., Elad, M.: A statistical prediction model based on sparse representations for single image super-resolution. TIP 23(6), 2569–2582 (2014)
Ren, W., Yang, J., Deng, S., Wipf, D., Cao, X., Tong, X.: Face video deblurring using 3D facial priors. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 9388–9397 (2019)
Ren, W., et al.: Deep non-blind deconvolution via generalized low-rank approximation. In: Advances in Neural Information Processing Systems, pp. 297–307 (2018)
Sajjadi, M.S., Scholkopf, B., Hirsch, M.: EnhanceNet: single image super-resolution through automated texture synthesis. In: ICCV (2017)
Shi, W., et al.: Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: CVPR (2016)
Tai, Y., Yang, J., Liu, X.: Image super-resolution via deep recursive residual network. In: CVPR (2017)
Tai, Y., Yang, J., Liu, X., Xu, C.: MemNet: a persistent memory network for image restoration. In: ICCV (2017)
Timofte, R., Agustsson, E., Van Gool, L., Yang, M.H., Zhang, L.: NTIRE 2017 challenge on single image super-resolution: methods and results. In: CVPRW (2017)
Wang, Z., Liu, D., Yang, J., Han, W., Huang, T.: Deep networks for image super-resolution with sparse prior. In: ICCV (2015)
Woo, S., Park, J., Lee, J.Y., So Kweon, I.: CBAM: convolutional block attention module. In: ECCV (2018)
Yang, J., Wright, J., Huang, T., Ma, Y.: Image super-resolution as sparse representation of raw image patches. In: CVPR (2008)
Zeyde, Roman, Elad, Michael, Protter, Matan: On single image scale-up using sparse-representations. In: Boissonnat, J.-D., et al. (eds.) Curves and Surfaces 2010. LNCS, vol. 6920, pp. 711–730. Springer, Heidelberg (2012). https://doi.org/10.1007/978-3-642-27413-8_47
Zhang, K., Zuo, W., Gu, S., Zhang, L.: Learning deep CNN denoiser prior for image restoration. In: CVPR (2017)
Zhang, K., Zuo, W., Zhang, L.: Learning a single convolutional super-resolution network for multiple degradations. In: CVPR (2018)
Zhang, L., Wu, X.: An edge-guided image interpolation algorithm via directional filtering and data fusion. TIP 15(8), 2226–2238 (2006)
Zhang, Y., Li, K., Li, K., Wang, L., Zhong, B., Fu, Y.: Image super-resolution using very deep residual channel attention networks. In: ECCV (2018)
Zhang, Y., Tian, Y., Kong, Y., Zhong, B., Fu, Y.: Residual dense network for image super-resolution. In: CVPR (2018)
Zhang, Z., Wang, Z., Lin, Z., Qi, H.: Image super-resolution by neural texture transfer. In: CVPR (2019)
Acknowledgements
This work is supported by the National Key R&D Program of China under Grant 2019YFB1406500, National Natural Science Foundation of China (No. 61971016, U1605252, 61771369), Fundamental Research Funds of Central Universities (Grant No. N160504007), Beijing Natural Science Foundation (No. L182057), Peng Cheng Laboratory Project of Guangdong Province PCL2018KP004, and the Shaanxi Provincial Natural Science Basic Research Plan (2019JM-557).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
1 Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Niu, B. et al. (2020). Single Image Super-Resolution via a Holistic Attention Network. In: Vedaldi, A., Bischof, H., Brox, T., Frahm, JM. (eds) Computer Vision – ECCV 2020. ECCV 2020. Lecture Notes in Computer Science(), vol 12357. Springer, Cham. https://doi.org/10.1007/978-3-030-58610-2_12
Download citation
DOI: https://doi.org/10.1007/978-3-030-58610-2_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-58609-6
Online ISBN: 978-3-030-58610-2
eBook Packages: Computer ScienceComputer Science (R0)