
Abstract
The use of deep convolutional neural networks (CNNs) for image super-resolution (SR) from low-resolution (LR) input has achieved remarkable reconstruction performance with the utilization of residual structures and visual attention mechanisms. However, existing single image super-resolution (SISR) methods with deeper network architectures can encounter representational bottlenecks in CNN-based networks and neglect model efficiency in model statistical inference. To solve these issues, in this paper, we design a channel hourglass residual structure (CHRS) and explore an efficient channel attention (ECA) mechanism to extract more representative features and ease the computational burden. Specifically, our CHRS, consisting of several nested residual modules, is developed to learn more discriminative representations with fewer model parameters, and the ECA is presented to efficiently capture local cross-channel interaction by subtly applying 1D convolution. Finally, we propose an efficient residual attention network (ERAN), which not only fully learns more representative features but also pays special attention to network learning efficiency. Extensive experiments demonstrate that our ERAN achieves certain improvements in model performance and implementation efficiency compared to other previous state-of-the-art methods.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Because of the strong representation abilities of deep convolutional neural networks (CNNs), deep CNN-based networks, including pioneering residual network [1], feature pyramid network [2] and stacked hourglass network [3], have achieved great progress in computer vision tasks such as object classification [1, 4, 5], target detection [6,7,8,9] and many other endeavors [3, 10,11,12,13,14]. In recent years, single image super-resolution (SISR) [15], which aims to recover visual high-resolution (HR) output from low-resolution (LR) input, has drawn much attention from researchers. While there always exists an ill-posed problem where the same LR image can be downsampled from diverse HR images, many significant CNN-based networks [17,18,19,20,21,22,23] have emerged in SISR for modeling the nonlinear mapping function from an LR image to HR more accurately. Dong et al. [16] first designed a three-layer CNN named SRCNN to model the nonlinear mapping function and obtained surprising performance. For further improvements of reconstruction, Kim et al. [17] designed a deeper network whose depth reached 20 and achieved high effectiveness. After the appearance of the pioneering residual network [1], Lim et al. [18] modified the general residual module and proposed a more complex network termed EDSR, which obtained notable performance but encountered many model parameters. Then, the dense SR model RDN [19], which utilized hierarchical features by dense connection, was presented, but its performance was similar to EDSR. Later, more advanced networks were built, including RCAN [20] and SAN [21], which both introduced an attention mechanism into SR models. Although they obtained a significant learning capacity for a CNN by stacking modified residual modules and introducing the general channel attention (CA) mechanism to learn the interdependencies among feature channels, they seldom focused on learning discriminative representations with a more efficient residual module and rarely considered modeling channel-wise interactions efficiently. Recently, Lan et al. [22] proposed a network with a dual global pathway named ERN, the designed local wider residual block in which the batch normalization (BN) layers were removed expanded wider channels before the activation layer; as a result, the expanded wider channels increased the number of parameters. These deep networks cannot learn discriminative features while maintaining fewer model parameters; that is, they are not efficient.
To address these limitations, we propose an efficient residual attention network (ERAN) to improve the model’s learning effectiveness and efficiency. We propose a channel hourglass residual structure (CHRS) to deepen the residual block and generate a nested residual block for extracting discriminative features efficiently. To the best of our knowledge, our CHRS is the first to apply the hourglass structure among feature channels. Furthermore, we present an efficient channel attention (ECA) mechanism to model the channel-wise interdependencies of features. Then, we integrate this mechanism into our CHRS and generate an efficient residual attention block (ERAB). Finally, we use a Laplacian pyramid framework similar to [23] to build our SR network.
In summary, there are three contributions offered in this work:
-
We propose an efficient residual attention network (ERAN) to reconstruct high-performance HR image from the corresponding LR. Our ERAN is much deeper than most previous CNN-based networks and achieves better SR performance while reducing model parameters to some extent.
-
We propose a channel hourglass residual structure (CHRS) to deepen the residual block and generate nested residuals for accelerating information flow, bypassing massive low-frequency information and learning discriminative representation efficiently.
-
We propose an efficient channel attention (ECA) mechanism to drive the model to efficiently learn the channel-wise interdependencies in the SISR network.
The remainder of this paper is organized as follows: the next section presents an overview of the related work. Section 3 describes the proposed model in detail. Section 4 shows the empirical research results. Section 5 presents the conclusion.
2 Related work
In recent years, unprecedented progress has been made in deep image super-resolution. The pioneering CNN-based SR work proposed by Dong et al. [16] employed a three-layer CNN to learn the mapping function from LR images to HR images and was termed SRCNN. Benefiting from the prediction performance of the CNN, its results showed great improvements when quantitatively and visually compared with the early interpolation-based method [24]. To increase the learning capacity of the network, Kim et al. [17] deepened the depth of the network to 20 and obtained remarkable SR performance. As skip connections were proposed in CNN networks [1, 25], much deeper models rapidly emerged. Lim et al. [18] designed a very wide and deep network named EDSR by stacking many modified residual blocks. Their network achieved significant improvements in performance and demonstrated the significance of model depth in image SISR. Other deep SR works, such as RDN [19] and SRDenseNet [26], which were derived from the dense-connection network [25], paid more attention to utilizing hierarchical features from different convolution layers. Their operations, stemming from densely concatenating features of different layers, increased the reuse of features and enabled further feature fusion. To achieve better visual SR performance, Ledig et al. [27] proposed SRGAN, which was based on a generative adversarial network (GAN) [28] and combined perceptual and adversarial loss with l2 loss. Although the blurring and oversmoothing artifacts were alleviated to a certain extent by applying SRGAN, its reconstruction results may not have been faithful because of the produced unpleasing artifacts. Then, Lan et al. [21] expanded wider channels in general residual block removed batch normalization (BN) layers and proposed one deep network with a dual global pathway named ERN.
An attention mechanism can generally be regarded as allocating available processing resources towards the most informative part of input. Massive works integrated with attention mechanisms have been proposed for different tasks, including image classification [29] and SISR [20, 21]. To resolve the limitation of network depth and explore the general channel attention (CA) mechanism in SISR, Zhang et al. [20] designed a very deep RCAN network composed of many residual channel attention blocks (RCABs) and residual in residual (RIR) structures. An RIR structure can drive the model to bypass abundant low-frequency information and reconstruct more accurate results. SAN [21] introduced a second-order channel-wise attention module and a nonlocal attention mechanism and combined them with an effective residual structure; eventually, the network successfully captured discriminative representations and long-distance spatial contextual information. Although both methods obtain notable improvements quantitatively and visually when integrated with the general CA mechanism, they are burdened with heavy computational costs.
Recently, Wang et al. [30] proposed an efficient channel attention (ECA) block in the classification task to efficiently model channel-wise interdependencies across feature maps and obtained accurate performance with fewer parameters. However, there are few proposed works that explore the impact of ECA on SISR.
3 Our model
To make full use of the powerful representation of the residual module and efficient channel-wise mechanism in the SISR task, we design a deep advanced residual network integrated with the ECA mechanism and name it an efficient residual attention network (ERAN) (see Fig. 1).

Network architecture of our ERAN for 4× SR.
3.1 Network architecture
As shown in Fig. 1, our ERAN is mainly made up of four parts: shallow feature extraction, efficient residual blocks (ERABs) for deep feature extraction, upscale modules of SR levels and corresponding reconstruction blocks. Let us suppose that ILR and ISR represent the input and output of our network, respectively. Similar to [18, 20, 27], given ILR as the input, we extract its shallow feature maps F0 using only one convolutional layer (Conv)
where Hf (∙) is the convolution operation.
Similar to [23], our model consists of B = log2(S) reconstruction levels, where S denotes the scale factor, i.e., the ×2 network has 1 level, and the ×4 network has 2 levels and so on. There are M ERABs at each level in our network. The first ERAB at level b extracts features from its input, and the extracted features act as the input of the next ERAB at the same level. The output of the last ERAB at level b denotes acquired abstract features at the current level, so we altogether have B groups of abstract features from corresponding B levels
where FDF − b, HERB − M and Fup − (b − 1) represent the acquired abstract features at level b, the M-th ERAB operation at level b and the upsampled feature maps at level b − 1, respectively. Then, the deep abstract features FDF − b are upscaled by the upscale module at the b level
where Hup − b↑ and Fup − b are the upscale module and upscaled feature maps at level b, respectively. There are several choices for upscaling models, such as transposed convolution [31] and ESPCN [32], in which good trade-offs between computation and performance are obtained by applying these post-upscaling strategies. Following [20, 21], we adopt sub-pixel convolution [32] in our upscale model. Next, we use one convolution layer at each level to reconstruct the result at the current level.
There are some available choices for the loss function to optimize the SR model, such as L1 [18, 20,21,22], L2 [16, 17], perceptual and adversarial losses [27]. For fair comparisons with advanced methods [20,21,22], we also choose the L1 loss function for model optimization. Hence, the objective function of ERAN is defined as:
where Θ is the parameter set of our model. For fast and effective convergence in the training process, the Adam optimization algorithm [33] is adopted to optimize the complex network.
3.2 Channel hourglass residual structure (CHRS)
The hourglass network [3] is a novel design with the ability to capture diverse feature maps and fuse them together. It can generate pixel-wise predictions, which coincide with the goal of the SISR task. Motivated by the theory [1, 3, 17, 19] that a deeper network can obtain a more abstract expression and a residual in residual (RIR) structure can accelerate information flow and bypass abundant low-frequency information in the LR inputs, we subtly design a deeper channel hourglass residual structure, i.e., the CHRS (see Fig. 2), which consists of P nested residuals for image SR.

The architecture of our channel hourglass residual structure (CHRS), consisting of P=3 nested residuals, makes the depth of CHRS reach 6
We now show more details about our CHRS. Suppose Finput denotes input feature maps with C channels and H × W size. The channels of the later layer in CHRS are halved to C/2 while keeping the H × W size unchanged at all times. After intermediate feature maps reach the fewest channels, i.e.,\( \frac{C}{2^P} \), the CHRS starts twofold increasing convolution kernels to double the channels and combines corresponding cross-scale feature maps by P element-wise additions. These RIR operations can make the CHRS bypass abundant low-frequency information and capture powerfully expressive information. Table 1 clearly shows the difference in efficiency between the general residual module [1] removed BN layers and our CHRS. Our CHRS has fewer parameters but a larger module depth and more residual connections under the same input size and output size. Note that the feature resolutions of different layers in our CHRS are all the same, which makes the CHRS be easily extended to other state-of-the-art SR networks. These dense residual connections across different layers accelerate the information flow and make the CHRS focus on high-frequency information during model training. Different from the usage of ReLU in [20], in our CHRS, all convolution layers except the last are followed by the LeakyReLU activation function.
3.3 Efficient Channel attention (ECA) module
In this section, we revisit the general channel attention (CA) mechanism and clarify more details about the ECA module (see Fig. 3).

Efficient channel attention (ECA) module used in our ERAN
3.3.1 Revisiting Channel attention (CA) mechanism
Suppose that given feature maps X = [x1, x2, ⋯, xc] with C channels and H × W size, global average pooling is used to learn the channel-wise global statistic information z. Then, we can obtain the c-th value of z by
where xc(i, j) denotes the pixel value of the c-th feature map xc at spatial position (i, j). Then, a sigmoid gating mechanism is adopted in [20, 21] to capture the channel-wise weights
where σ(∙) and δ(∙) denote the sigmoid gating function and ReLU function, respectively, and WU and WD are the weight settings of the channel-upscaling layer and the channel-downscaling layer, respectively. To avoid high computing complexity, WD are often set to \( C\times \left(\frac{C}{r}\right) \), and WU are set to \( \left(\frac{C}{r}\right)\times C \). Although convolution operations that change the numbers of convolution kernels limit model complexity in the CA module, the channel information and its weight are not directly corresponding.
3.3.2 Efficient channel attention (ECA) mechanism
The ECA mechanism (see Fig. 3) is motivated by the general channel attention (CA) mechanism used in the RCAN; it models interdependencies among feature channels adaptively and efficiently by considering local cross-channel interaction. The ECA module investigates one 1D convolution layer with an adaptive kernel size to replace the two 2D convolution layers in the general CA module and makes the network focus on capturing powerful feature maps efficiently.
Given the feature maps z ∈ RC without reducing the dimension, channel-wise weights can be obtained by
where W and σ(∙) are parameter matrices with the dimension of C × C and a sigmoid gating function, respectively. To capture the discriminative representation among feature channels efficiently, the key step is how to model the local cross-channel interaction. Considering zi and its k neighbors, the weight of zi can be calculated by
where \( {\Omega}_i^k \) is the group of k adjacent channels of zi. In brief, such local aggregation can be exactly implemented by 1D convolution with a kernel size of k
where conv1D(∙) is a 1D convolution layer and its kernel size equals k.
Hence, the remaining key issue is how to set the value of k. Considering the similar philosophy, feature maps with different channel dimension C should reasonably have different statistical values of k; therefore, a mapping function ϕ(∙) may be available from k to C
Generally, a linear function, i.e., ϕ(k) = γ ∗ k − q, is usually adopted to model the simplest corresponding mapping. However, the simple linear function limits the expression of complicated relations between k and C. To better describe the complex quantitative relations, we introduce a nonlinear function, i.e.,
to replace the linear one. The reason why an exponential function is used is that the channel dimension C of feature maps is usually set to a power of 2. Then, given a channel dimension value of C, the kernel size k can be calculated adaptively by
where |t|odd is the odd number nearest to t. Following [30], in our experiments, γ and q are always set to 2 and 1, respectively. Clearly, using nonlinear mapping φ(∙) gives feature maps with different channel numbers different range interactions and drives the model to adaptively learn the interdependencies among feature channels.
3.4 Efficient residual attention block (ERAB)
To take advantage of the feature maps with channel-wise weights effectively, we incorporate the ECA mechanism into our CHRS and generate an efficient residual attention block (ERAB) (see Fig. 4) to learn discriminative representation.

The architecture of the proposed efficient residual block (ERAB)
Inspired by the effectiveness of residual blocks and residual in residual (RIR) structure in [20], long skip connections are added into our model to enhance information flow in the network. For the m-th ERAB at the b-th level, we have
where Rb, m(∙) indicates the function of efficient channel attention (ECA), and its components GAPb, m(∙), \( {conv}_{1D}^{b,m}\left(\bullet \right) \) and σb, m(∙) are the global average pooling function, 1D convolution layer and corresponding sigmoid gating function, respectively. Fb, m − 1 and Fb, m denote the input and output of the m-th ERAB in which the residual Xb, m is learned after the input feature maps Fb, m − 1 are dealt with by P − 1 residual subunits. Considering the trade-off between the performance of our ERAB and module computation, in our experiments, P is always set to 3.
3.5 Joint optimization with added losses
Our network architecture with multiple SR levels is similar to the Laplacian pyramid framework [23], but we use our ERABs to extract deep features. In addition, we only obtain the SR result from the last level, i.e., the results of internal levels are only used to supervise and optimize the result at the last level. Theoretically the same LR image can be downsampled from infinite HR images, and there are many possible functions to choose in mapping function space. To alleviate the learning diversity for the deep model, we adopt a network architecture similar to the Laplacian pyramid framework so that internal levels can help the model learn the mapping function from LR to HR image more accurately.
At each SR level of our model, there are M ERABs and one sub-pixel convolution layer. Each sub-pixel convolution layer is connected to a corresponding convolution layer to recover the HR image at the current level. For ×4 and ×8 SR models, M is always set to 30.
4 Experimental results
In this section, we first clarify our experimental settings in detail, including datasets, evaluation metrics, optimizer and related equipment. Then, we verify the contribution of each component and the impact from different combinations of components in the proposed ERAN. We show the results quantitatively and visually compared with other advanced methods. Finally, we present a model complexity analysis, including the parameters of different models.
4.1 Settings
Following [34], we train our networks on DIV2K [35] and Flickr2K [18] datasets. After training, we test our models on five benchmark datasets, including SET5 [36], SET14 [37], BSDS100 [38], URBAN100 [39] and MANGA109 [40], and adopt the peak signal-to-noise ratio (PSNR) and structural similarity index (SSIM) [41] on the Y channel as evaluation metrics after transforming the SR results to YCbCr space. We carry out extensive experiments with a bicubic (BI) degradation model and use scaling factors ×4 and ×8 for training and testing.
During training, the ADAM [33] optimizer with β1 = 0.9, β2 = 0.99, and ε = 10−8 is practically adopted to optimize our model. We conduct all experiments using Pytorch [42] on a computer equipped with one GTX 1080Ti GPU, one Intel i7-8700k CPU and 24 GB system memory. The learning rate is initially set to 10−4 and decays with a cosine annealing strategy.
4.2 Ablation investigation
We analyze the effects of the channel hourglass residual structure (CHRS) and efficient channel attention (ECA) mechanism compared with the channel attention (CA) mechanism and conduct a series of experiments to demonstrate the effectiveness of our network.
First, we train our model without the CHRS, ECA and CA on the DIV2K and Flickr2K datasets, and we obtain a basic performance value of 32.59 dB PNSR with general residual modules removed BN layers. Next, we carry out verification experiments with the CA, ECA or CHRS to analyze the effects and obtain corresponding results of 32.62 dB PNSR, 32.63 dB PNSR, and 32.60 dB PNSR, respectively. These clear results demonstrate the ability of each block to improve the model reconstruction performance. Then, we implement different experiments with different combinations of CA, ECA and CHRS. We observe that the model with the CA and CHRS achieves a 32.64 dB PSNR, which is better than the 32.62 dB PSNR of the module with CA only. The model with ECA and CHRS achieves a 32.66 dB PSNR, which is the best of these results. These findings show a powerful representation of our ERAB and the notable performance of our ERAN. All results are shown in Table 2.
4.3 Comparisons with advanced methods
To further verify the effectiveness of our ERAN, we conduct a large number of experiments and compare our results quantitatively and visually with other state-of-the-art methods, such as SRCNN [16], VDSR [17], LapSRN [23], EDSR [18], RDN [19], SRDenseNet [26], RCAN [20], SAN [21], and ERN [22]. Similar to [20, 21], the self-ensemble strategy is adopted to further improve our ERAN, denoted as ERAN+.
PSNR/SSIM results
Quantitative evaluation results of ×4 and ×8 SR are shown in Table 3. For ×4 SR, our ERAN+ provides the best quantitative performance, with the highest PNSR and SSIM values on all datasets compared with previous advanced networks. Even without the self-ensemble strategy, our ERAN can yield comparable or superior results on five test datasets. In terms of a larger scaling factor (e.g., 8), our ERAN+ still achieves the best value of evaluation metrics, surpassing the outputs of the recent advanced CNN-based method SAN. All experimental records show that our model yields better performance than most state-of-the-art methods.
Visual results
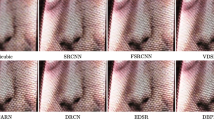
Figure 5 presents visual comparisons of SR scale ×4 on the datasets of Urban100 and Manga109. For image “img_016” and image “MiraiSan”, the early bicubic method yields widespread blurring and even loses the main outlines. Other recent methods (e.g., EDSR, RCAN and SAN) can recover the main structure but have difficulty reconstructing clearer details and present some blurring artifacts or distorted edges. For our ERAN, it can be observed that our model can recover more details, especially yield sharper edges, and more natural performance benefited from the better captured high-frequency information.

Visual comparisons for 4× SR with the BI model on the Urban100 and Manga109 datasets. The best results are highlighted
4.4 Model complexity analysis
Our goal is to obtain good performance with fewer parameters. The details of different advanced methods are shown in Table 4, and a corresponding visual illustration is presented in Fig. 6. We replace the residual channel attention block (RCAB) in RCAN with our ERAB, and the new RCAN model is denoted as RCAN+ERAB. RCAN+ERAB can obtain better performance with fewer parameters than RCAN for 4× SR on the Set5 dataset. In addition, our ERAN, with the fewest parameters, performs better than other state-of-the-art methods. This demonstrates the good trade-off of our ERAN between superior performance and model complexity.

Performance and the number of parameters on Set5
5 Conclusions
We propose a very deep efficient residual attention network (ERAN) for accurate and efficient image SR. Specifically, the channel hourglass residual structure (CHRS) allows the ERAN to deepen the network by applying several nested residual modules, accelerate information flow and bypass massive low-frequency information from LR images by residual in residual (RIR) structure. In addition to designing the CHRS to learn discriminative representation with fewer model parameters, we propose an efficient channel attention (ECA) mechanism to efficiently learn channel-wise interdependencies by applying 1D convolution, and integrate this mechanism into the CHRS to generate an efficient residual attention block (ERAB). Extensive experiments on SISR with BI models demonstrate the effectiveness, efficiency of our ERAN and the generalization ability of our ERAB.
References
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. In proceedings of the IEEE conference on computer vision and pattern recognition, pp 770–778
Lin T Y, Dollár P, Girshick R, He K, Hariharan B, Belongie S (2017) Feature pyramid networks for object detection. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp. 2117–2125
Newell A, Yang K, Deng J (2016) Stacked hourglass networks for human pose estimation. In European conference on computer vision. Springer, Cham, pp 483–499
Cen F, Zhao X, Li W, Wang G (2021) Deep feature augmentation for occluded image classification. Pattern Recogn 111:107737
Qi C, Zhang J, Jia H, Mao Q, Wang L, Song H (2021) Deep face clustering using residual graph convolutional network. Knowl-Based Syst 211:106561
Tian Z, Shen C, Chen H, He T (2020) Fcos: a simple and strong anchor-free object detector. IEEE Transactions on Pattern Analysis and Machine Intelligence
Liu Y, Wang Y, Wang S, Liang T, Zhao Q, Tang Z, Ling H (2020) Cbnet: a novel composite backbone network architecture for object detection. In: Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, pp 11653–11660
Li X, Song D, Dong Y (2020) Hierarchical feature fusion network for salient object detection. IEEE Trans Image Process 29:9165–9175
Li Z, Xi T, Zhang G, Liu J, He R (2021) AutoDet: pyramid network architecture search for object detection. Int J Comput Vis:1–19
Li X, Zhao H, Han L, Tong Y, Tan S, Yang K (2020) Gated fully fusion for semantic segmentation. In: Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, pp 11418–11425
Zhang H, Tian Y, Wang K, Zhang W, Wang FY (2019) Mask SSD: an effective single-stage approach to object instance segmentation. IEEE Trans Image Process 29:2078–2093
Quan Y, Chen Y, Shao Y, Teng H, Xu Y, Ji H (2021) Image denoising using complex-valued deep CNN. Pattern Recogn 111:107639
Xu W, Song H, Zhang K, Liu Q, Liu J (2020) Learning lightweight multi-scale feedback residual network for single image super-resolution. Comput Vis Image Underst 197:103005
Koller O, Camgoz NC, Ney H, Bowden R (2019) Weakly supervised learning with multi-stream CNN-LSTM-HMMs to discover sequential parallelism in sign language videos. IEEE Trans Pattern Anal Mach Intell 42(9):2306–2320
Freeman WT, Pasztor EC, Carmichael OT (2000) Learning low-level vision. Int J Comput Vis 40(1):25–47
Dong C, Loy CC, He K, Tang X (2015) Image super-resolution using deep convolutional networks. IEEE Trans Pattern Anal Mach Intell 38(2):295–307
Kim J, Kwon Lee J, Mu Lee K (2016) Accurate image super-resolution using very deep convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1646–1654
Lim B, Son S, Kim H, Nah S, Mu Lee K (2017) Enhanced deep residual networks for single image super-resolution. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp 136–144
Zhang Y, Tian Y, Kong Y, Zhong B, Fu Y (2020) Residual dense network for image restoration. IEEE Transactions on Pattern Analysis andMachine Intelligence
Zhang Y, Li K, Li K, Wang L, Zhong B, Fu Y (2018) Image super-resolution using very deep residual channel attention networks. In: Proceedings of the European conference on computer vision (ECCV), pp 286–301
Dai T, Cai J, Zhang Y, Xia S T, Zhang L (2019) Second-order attention network for single image super-resolution. In: proceedings of the IEEE conference on computer vision and pattern recognition, pp 11065–11074
Lan R, Sun L, Liu Z, Lu H, Su Z, Pang C, Luo X (2020) Cascading and enhanced residual networks for accurate single-image super-resolution. IEEE transactions on cybernetics
Lai W S, Huang J B, Ahuja N, Yang M H (2017) Deep laplacian pyramid networks for fast and accurate super-resolution. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 624–632
Zhang L, Wu X (2006) An edge-guided image interpolation algorithm via directional filtering and data fusion. IEEE Trans Image Process 15(8):2226–2238
Huang G, Liu Z, Van Der Maaten L, Weinberger K Q (2017) Densely connected convolutional networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4700–4708
Tong T, Li G, Liu X, Gao Q (2017) Image super-resolution using dense skip connections. In: Proceedings of the IEEE international conference on computer vision, pp 4799–4807
Ledig C, Theis L, Huszár F, Caballero J, Cunningham A, Acosta A, ..., Shi W (2017) Photo-realistic single image super-resolution using a generative adversarial network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 4681–4690
Goodfellow I, Pouget-Abadie J, Mirza M, Xu B, Warde-Farley D, Ozair S et al (2014) Generative adversarial nets. Adv Neural Inf Proces Syst 27:2672–2680
Hu J, Shen L, Sun G (2018) Squeeze-and-excitation networks. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 7132–7141
Wang Q, Wu B, Zhu P, Li P, Zuo W, Hu Q (2020) ECA-net: efficient channel attention for deep convolutional neural networks. In: Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, pp 11534–11542
Dong C, Loy CC, Tang X (2016) Accelerating the super-resolution convolutional neural network. In European conference on computer vision (pp. 391-407). Springer, Cham
Shi W, Caballero J, Huszár F, Totz J, Aitken AP, Bishop R, ..., Wang Z (2016) Real-time single image and video super-resolution using an efficient sub-pixel convolutional neural network. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 1874–1883
Kingma D, Ba J. (2014) Adam: a method for stochastic optimization. Computer Science
Wang X, Yu K, Wu S, Gu J, Liu Y, Dong C, ..., Change Loy C (2018) Esrgan: Enhanced super-resolution generative adversarial networks. In: Proceedings of the European Conference on Computer Vision (ECCV), pp 0–0
Timofte R, Agustsson E, Van Gool L, Yang M H, Zhang L (2017) Ntire 2017 challenge on single image super-resolution: methods and results. In: Proceedings of the IEEE conference on computer vision and pattern recognition workshops, pp 114–125
Bevilacqua M, Roumy A, Guillemot C, Alberi-Morel ML (2012) Low-complexity single-image super-resolution based on nonnegative neighbor embedding
Zeyde R, Elad M, Protter M (2010) On single image scale-up using sparse-representations. In international conference on curves and surfaces (pp. 711-730). Springer, Berlin, Heidelberg
Arbelaez P, Maire M, Fowlkes C, Malik J (2010) Contour detection and hierarchical image segmentation. IEEE Trans Pattern Anal Mach Intell 33(5):898–916
Huang JB, Singh A, Ahuja N (2015) Single image super-resolution from transformed self-exemplars. In: Proceedings of the IEEE conference on computer vision and pattern recognition, pp 5197–5206
Matsui Y, Ito K, Aramaki Y, Fujimoto A, Ogawa T, Yamasaki T, Aizawa K (2017) Sketch-based manga retrieval using manga109 dataset. Multimed Tools Appl 76(20):21811–21838
Wang Z, Bovik AC, Sheikh HR, Simoncelli EP (2004) Image quality assessment: from error visibility to structural similarity. IEEE Trans Image Process 13(4):600–612
Paszke A, Gross S, Chintala S, Chanan G, Yang E, DeVito Z, ..., Lerer A (2017) Automatic differentiation in pytorch
Acknowledgments
The authors acknowledge the anonymous reviewers for their helpful comments.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Hao, F., Zhang, T., Zhao, L. et al. Efficient residual attention network for single image super-resolution. Appl Intell 52, 652–661 (2022). https://doi.org/10.1007/s10489-021-02489-x
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10489-021-02489-x