
Abstract
We study the detection of change-points in time series. The classical CUSUM statistic for detection of jumps in the mean is known to be sensitive to outliers. We thus propose a robust test based on the Wilcoxon two-sample test statistic. The asymptotic distribution of this test can be derived from a functional central limit theorem for two-sample U-statistics. We extend a theorem of Csörgő and Horváth to the case of dependent data.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
- Asymptotic Distribution
- Block Length
- Functional Central Limit Theorem
- CUSUM Test
- Main Theoretical Result
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
1 Introduction
Change-point tests address the question whether a stochastic process is stationary during the entire observation period or not. In the case of independent data, there is a well-developed theory; see the book by Csörgő and Horváth [6] for an excellent survey. When the data are dependent, much less is known. The CUSUM statistic has been intensely studied, even for dependent data; see again Csörgő and Horváth [6]. The CUSUM test, however, is not robust against outliers in the data. In the present paper, we study a robust test which is based on the two-sample Wilcoxon test statistic. Simulations show that this test outperforms the CUSUM test in the case of heavy-tailed data.
In order to derive the asymptotic distribution of the test, we study the stochastic process
where \(h: \mathbb{R}^{2} \rightarrow \mathbb{R}\) is a kernel function. In the case of independent data, the asymptotic distribution of this process has been studied by Csörgő and Horváth [5]. In the present paper, we extend their result to short range dependent data \((X_{i})_{i\geq 1}\). Similar results have been obtained for long range dependent data by Dehling, Rooch and Taqqu [10], albeit with completely different methods.
U-statistics have been introduced by Hoeffding [14], where the asymptotic normality was established both for the one-sample as well as the two-sample U-statistic in the case of independent data. The asymptotic distribution of one-sample U-statistics of dependent data was studied by Sen [18, 19], Yoshihara [22], Denker and Keller [12, 13] and by Borovkova, Burton and Dehling [3] in the so-called non-degenerate case, and by Babbel [1] and Leucht [16] in the degenerate case. For two-sample U-statistics, Dehling and Fried [8] established the asymptotic normality of \(\sum _{i=1}^{n_{1}}\sum _{ j=n_{1}+1}^{n_{1}+n_{2}}h(X_{ i},X_{j})\) for dependent data, when \(n_{1},n_{2} \rightarrow \infty\). The main theoretical result of the present paper is a functional version of this limit theorem.
In our paper, we focus on data that can be represented as functionals of a mixing process. In this way, we cover most examples from time series analysis, such as ARMA and ARCH processes, but also data from chaotic dynamical systems. For a survey of processes that have a representation as functional of a mixing process, see e.g. Borovkova, Burton and Dehling [3]. Earlier references can be found in Ibragimov and Linnik [15], Denker [11] and Billingsley [2].
2 Definitions and Main Results
Given the samples \(X_{1},\ldots,X_{n_{1}}\) and \(Y _{1},\ldots,Y _{n_{2}}\), and a kernel h(x, y), we define the two-sample U-statistic
More generally, one can define U-statistics with multivariate kernels \(h: \mathbb{R}^{k} \times \mathbb{R}^{l} \rightarrow \mathbb{R}\). In the present paper, for the ease of exposition, we will restrict attention to bivariate kernels h(x, y). The main results, however, can easily be extended to the multivariate case.
Assuming that \((X_{i})_{i\geq 1}\) and \((Y _{i})_{i\geq 1}\) are stationary processes with one-dimensional marginal distribution functions F and G, respectively, we can test the hypothesis H: F = G using the two-sample U-statistic. E.g., the kernel \(h(x,y) = y - x\) leads to the U-statistic
and thus to the familiar two-sample Gauß-test. Similarly, the kernel \(h(x,y) = 1_{\{x\leq y\}}\) leads to the U-statistic
and thus to the 2-sample Mann-Whitney-Wilcoxon test.
In the present paper, we investigate tests for a change-point in the mean of a stochastic process \((X_{i})_{i\geq 1}\). We consider the model
where \((\mu _{i})_{i\geq 1}\) are unknown constants and where (ξ i ) i ≥ 1 is a stochastic process. We want to test the hypothesis \(H:\;\mu _{1} =\ldots =\mu _{n}\) against the alternative that there exists 1 ≤ k ≤ n − 1 such that \(\mu _{1} =\ldots =\mu _{k}\neq \mu _{k+1} =\ldots =\mu _{n}\).
Tests for the change-point problem are often derived from 2-sample tests applied to the samples X 1, …, X k and X k+1, …, X n , for all possible 1 ≤ k ≤ n − 1. For two-sample tests based on U-statistics with kernel h(x, y), this leads to the test statistic \(\sum _{i=1}^{k}\sum _{j=k+1}^{n}h(X_{i},X_{j})\), 1 ≤ k ≤ n, and thus to the process
In this paper, we will derive a functional limit theorem for the process \((U_{n}(\lambda ))_{0\leq \lambda \leq 1}\), n ≥ 1. Specifically, we will show that under certain technical assumptions on the kernel h and on the process (X i ) i ≥ 1, a properly centered and renormalized version of \((U_{n}(\lambda ))_{0\leq \lambda \leq 1}\) converges to a Gaussian process.
In our paper, we will assume that the process (ξ i ) i ≥ 0 is weakly dependent. More specifically, we will assume that (ξ i ) i ≥ 0 can be represented as a functional of an absolutely regular process.
Definition 1.
-
(i)
Given a stochastic process \((X_{n})_{n\in \mathbb{Z}}\) we denote by \(\mathcal{A}_{l}^{k}\) the \(\sigma -\) algebra generated by (X k , …, X l ). The process is called absolutely regular if
$$\displaystyle{ \beta (k) =\sup _{n}\left \{\sup \sum _{j=1}^{J}\sum _{ i=1}^{I}\vert P(A_{ i} \cap B_{j}) - P(A_{i})P(B_{j})\vert \right \}\rightarrow 0, }$$(7)as \(k \rightarrow \infty\), where the last supremum is over all finite \(\mathcal{A}_{1}^{n}-\) measurable partitions (A 1, …, A I ) and all finite \(\mathcal{A}_{n+k}^{\infty }-\) measurable partitions (B 1, …, B J ).
-
(ii)
The process (X n ) n ≥ 1 is called a two-sided functional of an absolutely regular sequence if there exists an absolutely regular process \((Z_{n})_{n\in \mathbb{Z}}\) and a measurable function \(f: \mathbb{R}^{\mathbb{Z}} \rightarrow \mathbb{R}\) such that
$$\displaystyle{X_{i} = f((Z_{i+n})_{n\in \mathbb{Z}}).}$$Analogously, (X n ) n ≥ 1 is called a one-sided functional if \(X_{i} = f((Z_{i+n})_{n\geq 0})\).
-
(iii)
The process (X n ) n ≥ 1 is called 1-approximating functional with coefficients (a k ) k ≥ 1 if
$$\displaystyle{ E\left \vert X_{i} - E(X_{i}\vert Z_{i-k},\ldots,Z_{i+k})\right \vert \leq a_{k}. }$$(8)
In addition to weak dependence conditions on the process (X i ) i ≥ 1, the asymptotic analysis of the process (6) requires some continuity assumptions on the kernel functions h(x, y). We use the notion of 1-continuity, which was introduced by Borovkova, Burton and Dehling [3]. Alternative continuity conditions have been used by Denker and Keller [13].
Definition 2.
The kernel h(x, y) is called 1-continuous, if there exists a function \(\phi: (0,\infty ) \rightarrow (0,\infty )\) with ϕ(ε) = o(1) as \(\epsilon \rightarrow 0\) such that for all ε > 0
for all random variables \(X,X^{{\prime}},Y\) and \(Y ^{{\prime}}\) having the same marginal distribution as X 1, and such that X, Y are either independent or have joint distribution \(P_{(X_{1},X_{k})}\), for some integer k.
The most important technical tool in the study of U-statistics is Hoeffding’s decomposition, originally introduced by Hoeffding [14]. If \(E\vert h(X,Y )\vert <\infty\) for two independent random variables X and Y with the same distribution as X 1, we can write
where the terms on the right-hand side are defined as follows:
Here, F denotes the distribution function of the random variables X i . Observe that, by Fubini’s theorem,
In addition, the kernel g(x, y) is degenerate in the sense of the following definition.
Definition 3.
Let (X i ) i ≥ 1 be a stationary process, and let g(x, y) be a measurable function. We say that g(x, y) is degenerate if
for all \(x,y \in \mathbb{R}\).
The following theorem, a functional central limit theorem for two-sample U-statistics of dependent data, is the main theoretical result of the present paper.
Theorem 1.
Let (X n ) n≥1 be a 1-approximating functional with constants (a k ) k≥1 of an absolutely regular process with mixing coefficients (β(k)) k≥1 , and let h(x,y) be a 1-continuous bounded kernel, satisfying
Then, as \(n \rightarrow \infty\) , the D[0,1]-valued process
converges in distribution towards a mean-zero Gaussian process with representation
where \((W_{1}(\lambda ),W_{2}(\lambda ))_{0\leq \lambda \leq 1}\) is a two-dimensional Brownian motion with mean zero and covariance function \(\mathop{\mathrm{Cov}}\nolimits (W_{k}(s),W_{l}(t)) =\min (s,t)\sigma _{kl}\) , where
Remark 1.
-
(i)
In the case of i.i.d. data, Theorem 1 was established by Csörgő and Horváth [5]. In the case of long-range dependent data, weak convergence of the process \((T_{n}(\lambda ))_{0\leq \lambda \leq 1}\) has been studied by Dehling, Rooch and Taqqu [10] and by Rooch [17], albeit with a normalization different from n 3∕2.
-
(ii)
Using the representation (15), one can calculate the autocovariance function of the process \((Z(\lambda ))_{0\leq \lambda \leq 1}\). We obtain
$$\displaystyle\begin{array}{rcl} \mathop{\mathrm{Cov}}\nolimits (Z(\lambda ),Z(\mu ))& =& \sigma _{11}[(1-\lambda )(1-\mu )\min \{\lambda,\mu \}] {}\\ & & +\sigma _{22}[\lambda \mu (1 -\mu -\lambda +\min \{\lambda,\mu \})] {}\\ & & +\sigma _{12}[\mu (1-\lambda )(\lambda -\min \{\lambda,\mu \}) +\lambda (1-\mu )(\mu -\min \{\lambda,\mu \})]. {}\\ \end{array}$$ -
(iii)
We conjecture that a similar theorem also holds for unbounded kernels under some moments conditions and faster mixing rates (similar to Theorem 2.7 of Sharipov, Wendler [20]). As our main application is the Wilcoxon test, where the kernel is bounded, we restrict the theorem to the case of bounded kernels.
-
(iv)
For the kernel \(h(x,y) = y - x\), we can analyze the asymptotic behavior of the process T n (λ) using the functional central limit theorem (FCLT). Note that, since \(X_{j} - X_{i} = (X_{j} - E(X_{j})) - (X_{i} - E(X_{i}))\), we may assume without loss of generality that X i has mean zero. Then we get the representation
$$\displaystyle\begin{array}{rcl} T_{n}(\lambda )& =& \frac{1} {n^{3/2}}\sum _{i=1}^{[n\lambda ]}\sum _{ j=[n\lambda ]+1}^{n}(X_{ j} - X_{i}) \\ & =& \frac{[n\lambda ]} {n} \frac{1} {\sqrt{n}}\sum _{i=1}^{n}X_{ i} - \frac{1} {\sqrt{n}}\sum _{i=1}^{[n\lambda ]}X_{ i}. {}\end{array}$$(17)Thus, weak convergence of \((T_{n}(\lambda ))_{0\leq \lambda \leq 1}\) can be derived from the FCLT for the partial sum process \(\frac{1} {\sqrt{n}}\sum _{i=1}^{[n\lambda ]}X_{i}\). Such FCLTs have been proved under a wide range of conditions, e.g. for functionals of uniformly mixing data in Billingsley [2].
We finally want to state an important special case of Theorem 1, namely when the kernel is anti-symmetric, i.e. when \(h(x,y) = -h(y,x)\). Kernels that occur in connection with change-point tests usually have this property. For anti-symmetric kernels, the limit process has a much simpler structure; moreover one can give a simpler direct proof in this case. Note that for independent random variables X, Y we have by anti-symmetry that \(Eh(X,Y ) = -Eh(Y,X) = -Eh(X,Y )\) and so \(\theta = Eh(X,Y ) = 0\).
Theorem 2.
Let (X n ) n≥1 be a 1-approximating functional with constants (a k ) k≥1 of an absolutely regular process with mixing coefficients (β(k)) k≥1 , and let h(x,y) be a 1-continuous bounded anti-symmetric kernel, such that (13) holds. Then, as \(n \rightarrow \infty\) , the D[0,1]-valued process
converges in distribution towards the mean-zero Gaussian process \(\sigma \,W^{(0)}(\lambda ),\;0 \leq \lambda \leq 1\) , where (W 0 (λ)) 0≤λ≤1 is a standard Brownian bridge and
3 Application to Change Point Problems
In this section, we will apply Theorem 1 in order to derive the asymptotic distribution of two change-point test statistics. Specifically, we wish to test the hypothesis
against the alternative of a level shift at an unknown point in time, i.e.
We consider the following two test statistics,
Theorem 3.
Let (X n ) n≥1 be a 1-approximating functional with constants (a k ) k≥1 of an absolutely regular process with mixing coefficients (β(k)) k≥1 , satisfying (13) , and assume that X 1 has a distribution function F(x) with bounded density. Then, under the null hypothesis H 0 ,
where (W (0) (λ)) 0≤λ≤1 denotes the standard Brownian bridge process, and where
Assuming that \(E\vert X_{i}\vert ^{2+\delta } <\infty\) , \(\beta (k) = O(k^{-(2+\delta )/\delta })\) and \(a_{k} = O(k^{-(1+\delta )/2\delta })\) , and under the null hypothesis H 0 ,
where
Proof.
We will establish weak convergence of T 1, n . In order to do so, we will apply Theorem 1 to the kernel h(x, y) = 1{x < y}. Borovkova, Burton and Dehling [3] showed that this kernel is 1-continuous. By continuity of the distribution function of X 1, we get that \(\theta =\int \!\!\int 1_{\{x<y\}}dF(x)dF(y) = 1/2\). Moreover, we get
Note that \(h_{2}(x) = -h_{1}(x)\). Hence \(W_{2}(\lambda ) = -W_{1}(\lambda )\), and thus the limit process in Theorem 1 has the representation
Here W 1(λ) is a Brownian motion with variance \(\sigma _{1}^{2}\). Weak convergence of T 2, n can be shown directly from the functional central limit theorem for the partial sum process; see Corollary 3.2 of Wooldridge and White [21]. We have to check the L 2-near epoch dependence. Note that by our assumptions
so the condition of Corollary 3.2 of Wooldridge and White [21] holds. Hence, the partial sum process \(( \frac{1} {\sqrt{n}}\sum _{i=1}^{[nt]}X_{i})_{0\leq t\leq 1}\) converges in distribution to \((\sigma _{2}\,W(t))_{0\leq t\leq 1}\), where W is standard Brownian motion. Convergence in distribution of T 2, n follows by an application of the continuous mapping theorem.
Remark 2.
-
(i)
The distribution of \(\sup _{0\leq \lambda \leq 1}\vert W(\lambda )\vert\) is the well-known Kolmogorov-Smirnov distribution. Quantiles of the Kolmogorov-Smirnov distribution can be found in most statistical tables.
-
(ii)
In order to apply Theorem 3, we need to estimate the variances \(\sigma _{1}^{2}\) and \(\sigma _{2}^{2}\). Regarding \(\sigma _{2}^{2}\) given in expression (27), we apply the non-overlapping subsampling estimator
$$\displaystyle{ \hat{\sigma }_{2}^{2} = \frac{1} {[n/l_{n}]}\sum _{i=1}^{[n/l_{n}]} \frac{1} {l_{n}}\left (\sum _{j=(i-1)l_{n}+1}^{il_{n} }X_{j} -\frac{l_{n}} {n} \sum _{j=1}^{n}X_{ j}\right )^{2} }$$(29)investigated by Carlstein [4] for α-mixing data. In case of AR(1)-processes, Carlstein derives
$$\displaystyle{ l_{n} =\max (\lceil n^{1/3}(2\rho /(1 -\rho ^{2}))^{2/3}\rceil,1) }$$(30)as the choice of the block length which minimizes the MSE asymptotically, with ρ being the autocorrelation coefficient at lag 1.
Regarding \(\sigma _{1}^{2}\) given in (25), one faces the additional challenge that the distribution function F is unknown. This problem has been addressed, e.g. in Dehling, Fried, Sharipov, Vogel and Wornowizki [9], for the case of functionals of absolutely regular processes and F being estimated by the empirical distribution function F n . The authors find the subsampling estimator for \(\sigma _{1}^{2}\)
employing non-overlapping subsampling, to give smaller biases, but somewhat larger MSEs than the corresponding overlapping subsampling estimator. The adaptive choice of the block length l n proposed by Carlstein worked well in their simulations if the data were generated from a stationary ARMA(1,1) model and an estimate of ρ was plugged in. In the next section, we will explore this and other proposals in situations with level shifts and normally or heavy-tailed innovations.
4 Simulation Results
The assumptions regarding the underlying process (X i ) in Theorem 1 are satisfied by a wide range of time series, such as AR and ARMA processes. To illustrate the results and to investigate the finite sample behavior and the power of the tests based on T 1, n and T 2, n , we will give some simulation results. We study the underlying change-point model
Within this model, the hypothesis of no change is equivalent to μ = 0. We assume that the noise follows an AR(1) process, i.e. that
where − 1 < ρ < 1, and where the innovations ε i are i.i.d. random variables with mean zero, bounded density and finite second moments. The innovations ε i are generated from a standard normal or a t ν -distribution with ν = 3 degrees of freedom, scaled to have the same 84.13 % percentile as the standard normal, which is 1. The autoregression coefficient is varied in ρ = { 0. 0, 0. 4, 0. 8}, corresponding to zero, moderate or strong positive autocorrelation, and the sample size is n = 200. For the choice of the block length we used Carlstein’s adaptive rule outlined above, or a fixed block length of l n = 9, which is in good agreement with the empirical findings of Dehling et al. [10] for larger sample sizes, and their theoretical result that l n should be chosen as \(o(\sqrt{n})\) to achieve consistency. For comparison, we also include tests employing overlapping subsampling for estimation of the asymptotical variance, applying the same block lengths as the non-overlapping versions.
Table 1 contains the empirical levels (i.e. the fraction of rejections) of the tests with an asymptotic level of 5 %, obtained from 4000 simulation runs for each situation. Note that the tests developed under the assumption of independence, not adjusting for autocorrelation, become strongly oversized with an increasingly positive autocorrelation, i.e. they reject a true null hypothesis far too often, and are practically useless already for ρ = 0. 4. The performance of the adjusted tests is much better in this respect and in a good agreement with the asymptotic results. Only if the autocorrelation is strong (ρ = 0. 8), the tests with a fixed block length become somewhat anti-conservative (oversized), and even more so for the CUSUM-test. Longer block lengths are needed for stronger positive autocorrelations, and Carlstein’s adaptive block length (30) adjusts for this. There is little difference between the tests employing overlapping and non-overlapping subsampling here.
In order to investigate the powers of the tests under the alternative, we consider shifts of increasing height μ, generating 400 data sets for each situation. The sample size is again n = 200, and the change point is at observation number \(\tau = [\lambda n] = 100\).
Figure 1 illustrates the powers of the different versions of the tests in case of Gaussian or t 3-distributed innovations and several autocorrelation coefficients ρ. Under normality, the CUSUM test T 2, n is somewhat more powerful than the test T 1, n based on the Wilcoxon statistic, while under the t 3-distribution it is the other way round. The CUSUM test with the fixed block length considered here becomes strongly oversized if ρ is large, while this effect is less severe for the test based on the Wilcoxon statistic. Carlstein’s adaptive choice of the block length increases the power if ρ is small and improves the size of the test substantially if ρ is large. The tests employing overlapping subsampling (not shown here) perform even slightly more powerful in case of zero or moderate autocorrelations, but much less powerful in case of strong autocorrelations. We have also considered the case of negative autocorrelation (\(\rho = -0.4\), not shown here). We obtained similar results for the power of the test based on the Wilcoxon statistic relatively to that of the CUSUM test, and little difference between using a fixed or the adaptive block length.

Power of the tests in case of a shift in the middle of an AR(1) process with Gaussian (left) or t 3-innovations (right) and different lag one correlations ρ = 0. 0 (top), ρ = 0. 4 (middle) or ρ = 0. 8 (bottom), n = 200. Wilcoxon test T n, 1 (bold lines) and CUSUM test T n, 2 (thin lines). Adjustment by non-overlapping subsampling with fixed (black) or adaptive block length (dashed)
The tests with Carlstein’s adaptive choice of the block length could be improved further by using a more sophisticated estimate of ρ than the ordinary sample autocorrelation used here. The latter is positively biased in the presence of a shift, which leads to too large choices of the block length. This negative effect becomes more severe for larger values of ρ, since the plug-in-estimate of the asymptotically MSE-optimal choice of l n increases more rapidly if \(\hat{\rho }\) is close to 1, while it is rather stable for moderate and small values of \(\hat{\rho }\). In our study, for ρ = 0 the average value chosen for l n increases from about 2 to about 3, only, as the height of the shift increases, while it increases from about 6 to about 9 if ρ = 0. 4, and even from about 16 to about 24 if ρ = 0. 8. An estimate of the autocorrelation coefficient which resists shifts could be used, e.g. by applying a stepwise procedure which estimates the possible time of occurrence of a shift before calculating \(\hat{\rho }\) from the corrected data, but this will not be pursued here.
5 Data Example
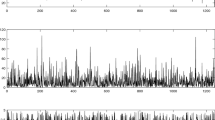
For illustration we apply the tests to time series data representing the monthly average daily minimum temperatures in Potsdam, Germany, measured between January 1893 and December 1992. The 1200 data points for these 100 years have been deseasonalized by subtracting the median value from each calendar month, see Fig. 2. Our interest is in whether the level of this time series is constant or whether there is a monotonic change. Such a systematic change is likely to show a trend-like behavior and not a sharp shift, but nevertheless we would like a change-point test to detect such a change if its null hypothesis is a constant level.

Deseasonalized time series representing the monthly average daily minimum temperatures in Potsdam, Germany
The empirical autocorrelation and partial autocorrelation functions suggest a first order autoregressive model with lag-one autocorrelation about 0.25 for the deseasonalized data. The test statistics take their maximum values after time point 595, i.e. rather in the middle of the time series. The resulting p-values are 0.23 and 0.16 for the CUSUM test with the fixed and the adaptive block length, respectively. As opposed to this, both versions of the Wilcoxon based test become significant as the corresponding p-values are 0.04 and 0.015, respectively. The differences between the results agree with the better power behavior of the Wilcoxon based test relatively to the CUSUM test in case of the (left-)skewed distributions of minimum temperatures, and the better power of the versions employing the adaptive block length over those with the fixed block length considered here in case of small positive autocorrelations. The sample median of the second time period is about 0.4 degrees larger than that of the first period.
6 Auxiliary Results
In this section, we will prove some auxiliary results which will play a crucial role in the proof of Theorem 1. The main result of this section is the following proposition, which essentially shows that the degenerate part in the Hoeffding decomposition of the U-statistic T n (λ) is uniformly negligible.
Proposition 1.
Let (X n ) n≥1 be a 1-approximating functional with constants (a k ) k≥1 of an absolutely regular process with mixing coefficients (β(k)) k≥1 , satisfying
Moreover, let g(x,y) be a 1-continuous bounded degenerate kernel. Then, as \(n \rightarrow \infty\) ,
in probability.
The proof of Proposition 1 requires some moment bounds for increments of U-statistics of degenerate kernels, which we will now state as separate lemmas.
Lemma 1.
Let (X n ) n≥1 be a 1-approximating functional with constants (a k ) k≥1 of an absolutely regular process with mixing coefficients (β(k)) k≥1 , satisfying
Moreover, let g(x,y) be a 1-continuous bounded degenerate kernel. Then, there exists a constant C 1 such that
Proof.
We can write
The elements of the first sum all are bounded, hence
Concerning the second sum, by Lemma 5, we get
with \(k =\max \{ \vert i_{2} - i_{1}\vert,\vert j_{2} - j_{1}\vert \}\). We will first treat the summands with \(k = i_{2} - i_{1}\). Suppose for one moment that k is fixed and we will bound the number of indices that appear in the sum. Observe that in this case we have [n λ] ways to choose i 1, once i 1 is chosen we have one way to pick i 2 because \(i_{2} = i_{1} + k\). For j 1 we have as before n − [n λ] ways to pick this index and then for each j 1, j 2 need to be in the interval [j 1, j 1 + k] and there are exactly k integers in such interval.
Analogously we can find the bounds for the terms with \(k = i_{1} - i_{2}\), \(k = j_{2} - j_{1}\) and \(k = j_{1} - j_{2}\) using the conditions of summability.
We now define the process G(λ), 0 ≤ λ ≤ 1, by
Lemma 2.
Under the conditions of Lemma 1 , there exists a constant C such that
for all 0 ≤μ ≤η ≤ 1.
Proof.
We can write
using the stationarity of the process \((X_{n})_{n\in \mathbb{N}}\) and Lemma 1.
Proof of Proposition 1.
From Lemma 2 we obtain, using Chebyshev’s inequality,
for all ε > 0. Thus we get for 0 ≤ k ≤ m ≤ n with \(k,m,n \in \mathbb{N}\)
as m − k ≤ n. Now consider the variables
and suppose that \(S_{i} =\zeta _{1} +\zeta _{2} +\ldots +\zeta _{i}\) with S 0 = 0, then \(S_{i} = G_{n}( \frac{i} {n})\). In consequence the inequality (46) is equivalent to
So the assumption of Theorem 7 are satisfied with the variables (47) in the role of the ξ i , \(\beta = 1/2\), \(\alpha = 2/3\) and \(u_{l} = C^{3/4}/n^{5/4}\), u o = 0 and hence
where K depends only of α and β. Thus, (35) holds as \(n \rightarrow \infty\). □
7 Proof of Main Results
In this section, we will prove Theorems 1 and 2. Note that Theorem 2 is a direct consequence of Theorem 1, applied to anti-symmetric kernels. We will nevertheless present a direct proof of Theorem 2, since this proof is much simpler than the proof in the general case. Moreover, Theorem 2 covers those cases that are most relevant in applications.
The first part of the proof is identical for both Theorems 1 and 2. Note that, for each λ ∈ [0, 1], the statistic T n (λ) is a two-sample U-statistic. Thus, using the Hoeffding decomposition (11), we can write T n (λ) as
By Proposition 1, we know that
in probability. Thus, by Slutsky’s lemma, it suffices to show that the sum of the first two terms, i.e.
converges in distribution to the desired limit process.
Proof of Theorem 2.
It remains to show that (51) converges in distribution to \(\sigma W^{(0)}(\lambda ),0 \leq \lambda \leq 1\), where (W (0)(λ))0 ≤ λ ≤ 1 is standard Brownian bridge on [0, 1], and where \(\sigma ^{2}\) is defined in (19). By antisymmetry of the kernel h(x, y), we obtain that \(h_{2}(x) = -h_{1}(x)\). Hence, in this case, (51) can be rewritten as
By Proposition 2.11 and Lemma 2.15 of Borovkova, Burton and Dehling [3], the sequence (h 1(X i )) i ≥ 1 is a 1-approximating functional with approximating constant \(C\sqrt{a_{k}}\). Since h 1(X i ) is bounded, the L 2-near epoch dependence in the sense of Wooldridge and White [21] also holds, with the same constants. Moreover, the underlying process (Z n ) n ≥ 1 is absolutely regular, and hence also strongly mixing. Thus we may apply the invariance principle in Corollary 3.2 of Wooldridge and White [21], and obtain that the partial sum process
converges weakly to Brownian motion (W(λ))0 ≤ λ ≤ 1 with \(\mathop{\mathrm{Var}}\nolimits (W(1)) =\sigma ^{2}\). The statement of the Theorem follows with the continuous mapping theorem for the mapping \(x(t)\mapsto x(t) - tx(1),\;0 \leq t \leq 1\).
The proof of Theorem 1 requires an invariance principle for the partial sum process of \(\mathbb{R}^{2}\)-valued dependent random variables; see Proposition 2 below. For mixing processes, such invariance principles have been established even for partial sums of Hilbert space valued random vector, e.g. by Dehling [7]. In this paper, we provide an extension of these results to functionals of mixing processes.
Proposition 2.
Let \((X_{n})_{n\in \mathbb{N}}\) be a 1-approximating functional of an absolutely regular process with mixing coefficients (β(k)) and let h 1 (⋅), h 2 (⋅) be bounded1–continuous functions with mean zero, such that
Then, as \(n \rightarrow \infty\) ,
where (W 1 (t),W 2 (t)) 0≤t≤1 is a two-dimensional Brownian motion with mean zero and covariance \(E(W_{k}(s)\,W_{l}(t)) =\min (s,t)\sigma _{kl}\) , where \(\sigma _{k,l}\) as defined in (16) .
Proof.
To prove (54), we need to establish finite dimensional convergence and tightness. Concerning finite-dimensional convergence, by the Cramér-Wold device it suffices to show the convergence in distribution of a linear combination of the coordinates of the vector
for \(0 = t_{0} <t_{1} <\ldots <t_{j} <\ldots <t_{k} = 1\). Any such linear combination can be expressed as
for \((a_{j},b_{j})_{j=1}^{k} \in \mathbb{R}^{2\,k}\). By using the Cramér-Wold device again, the weak convergence of this sum is equivalent to the weak convergence of the vector
to
Since (X n ) n ≥ 1 is a 1-approximating functional, it can be coupled with a process consisting of independent blocks. Given integers \(L:= L_{n} = [n^{3/4}]\) and \(l_{n} = [n^{1/2}]\), we introduce the (l, L) blocking (B m ) m ≥ 0 of the variables (a j h 1(X i ) + b j h 2(X i )) with \(i = [nt_{j-1}] + 1,\ldots,[nt_{j}]\), j = 0, …, k and
and separating blocks
By Theorem 5 there exists a sequence of independent blocks \((B_{m}^{{\prime}})\) with the same blockwise marginal distribution as (B m ) and such that
where \(\alpha _{l}:= (2\sum _{k=[l_{n}/3]}^{\infty }a_{k})^{1/2}\). We can express the components of our vector (57) as a sum of blocks
where R j denotes the set of indices not contained in the blocks. Observe that by the Lemma 3 for any set \(A \subset \{ 1,\ldots,n\}\)
and hence
so it follows with the Chebyshev inequality that this term is negligible. For the last summand, we have that
Furthermore, we need to show that we can replace the blocks B m by the independent coupled blocks \(B_{m}^{{\prime}}\):
as \(n \rightarrow \infty\) by our conditions on the mixing coefficients and approximation constants. Here we used that fact that \(\alpha _{n} \rightarrow 0\) and thus, for almost all \(n \in \mathbb{N}\),
With the above arguments the result holds if we show the convergence of
Since this vector has independent components, we only need to show the one-dimensional convergence, which is a consequence of Theorem 4, using the summability condition (53).
We now turn to the question of tightness and show that, for each ε and η, there exist a δ, 0 < δ < 1, and an integer n 0 such that, for 0 ≤ t ≤ 1,
with
(h 2 can be treated in the same way) and by Theorem 8, this condition reduces to: For each positive ε there exist a α > 1 and an integer n 0, s. t.
Let t ≥ s, s, t ∈ [0, 1]. By Lemma 4 we get
and this implies
By Theorem 7
and we get the assertion. Thus we have established tightness of each of the two coordinates of the partial sum process, which implies tightness of the vector-valued process.
Proof of Theorem 1.
From Proposition 2 we obtain that
in distribution on the space (D([0, 1]))2. We consider the functional given by
This is a continuous mapping from (D[0, 1])2 to D[0, 1], so we may apply the continuous mapping theorem to (73), and obtain
Together with the remarks at the beginning of this section, this proves Theorem 1.
References
Babbel, B.: Invariance principles for U-statistics and von Mises functionals. J. Stat. Plan. Inference 22, 337–354 (1989)
Billinsgley, P.: Convergence of Probability Measures. 2nd edn. Wiley, New York (1999)
Borovkova, S.A., Burton, R.M., Dehling, H.G.: Limit theorems for functionals of mixing processes with applications to U-statistics and dimension estimation. Trans. Am. Math. Soc. 353, 4261–4318 (2001)
Carlstein, E.: The use of subseries values for estimating the variance of a general statistic from a stationary sequence. Ann. Stat. 14, 1171–1179 (1986)
Csörgő, M., Horvath, L.: Invariance principles for changepoint problems. J. Multivar. Anal. 27, 151–168 (1988)
Csörgő, M., Horvath, L.: Limit Theorems in Change Point Analysis. Wiley, New York (1997)
Dehling, H.: Limit theorems for sums of weakly dependent Banach space valued random variables. Z. für Wahrscheinlichkeitstheorie und verwandte Gebiete 63, 393–432 (1983)
Dehling, H., Fried, R.: Asymptotic distribution of two-sample empirical U-quantiles with applications to robust tests for shifts in location. J. Multivar. Anal. 105, 124–140 (2012)
Dehling, H., Fried, R., Sharipov, O.Sh., Vogel, D., Wornowizki, M.: Estimation of the variance of partial sums of dependent processes. Stat. Probab. Lett. 83, 141–147 (2013)
Dehling, H., Rooch, A., Taqqu, M.S.: Nonparametric change-point tests for long-range dependent data. Scand. J. Stat. 40, 153–173 (2013)
Denker, M.: Asymptotic Distribution Theory in Nonparametrics Statistics. Vieweg Verlag, Braunschweig/Wiesbaden (1985)
Denker, M., Keller, G.: On U-statistics and v. Mises’ statistics for weakly dependent processes. Z. für Wahrscheinlichkeitstheorie und verwandte Gebiete 64, 505–522 (1983)
Denker, M., Keller, G.: Rigorous statistical procedures for data from dynamical systems. J. Stat. Phys. 44, 67–93 (1986)
Hoeffding, W.: A class of statistics with asymptotically normal distribution. Ann. Math. Stat. 19, 293–325 (1948)
Ibragimov, I.A., Linnik, Yu.V.: Independent and Stationary Sequences of Random Variables. Wolters-Noordhoff, Groningen (1971)
Leucht, A.: Degenerate U- and V-statistics under weak dependence: asymptotic theory and bootstrap consistency. Bernoulli 18, 552–585 (2012)
Rooch, A.: Change-point tests for long-range dependent data. Dissertation, Ruhr-Universität Bochum (2012)
Sen, P.K.: On the properties of U-statistics when the observations are not independent. I. Estimation of non-serial parameters in some stationary stochastic processes. Calcutta Stat. Assoc. Bull. 12, 69–92 (1963)
Sen, P.K.: Limiting behavior of regular functionals of empirical distributions for stationary ∗-mixing processes. Z. für Wahrscheinlichkeitstheorie und Verwandte Gebiete 25, 71–82 (1972)
Sharipov, O.Sh., Wendler, M.: Bootstrap for the sample mean and for U-statistics of mixing and near-epoch dependent processes. J. Nonparametric Stat. 24, 317–342 (2012)
Wooldridge, J.M., White, H.: Some invariance principles and central limit theorems for dependent heterogeneous processes. Econ. Theory 4, 210–230 (1988)
Yoshihara, K.-I.: Limiting behavior of U-statistics for stationary, absolutely regular processes. Z. für Wahrscheinlichkeitstheorie und verwandte Gebiete 35, 237–252 (1976)
Acknowledgements
The authors wish to thank the referees for their very careful reading of an earlier version of this manuscript, and for their many thoughtful comments that helped to improve the presentation of the paper. This research was supported by the Collaborative Research Center 823, Project C3 Analysis of Structural Change in Dynamic Processes, of the German Research Foundation DFG.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Some Auxiliary Results from the Literature
Appendix: Some Auxiliary Results from the Literature
In this section, we collect some known lemmas and theorems for weakly dependent data. We start with some results on the behaviour of partials sums:
Lemma 3 (Borovkova, Burton, Dehling [3], Lemma 2.23).
Let \((X_{k})_{k\in \mathbb{Z}}\) be a 1-approximating functional with constants (ak)k≥0 of an absolutely regular process with mixing coefficients (β(k))k≥0. Suppose moreover that EXi = 0 and that one of the following two conditions holds:
-
1.
X 0 is bounded a.s. and \(\sum _{k=0}^{\infty }(a_{k} +\beta (k)) <\infty.\)
-
2.
\(E\vert X_{0}\vert ^{2+\delta } <\infty\) and \(\sum _{k=0}^{\infty }(a_{k}^{ \frac{\delta }{ 1+\delta } } +\beta ^{ \frac{\delta }{1+\delta } }(k)) <\infty.\)
Then, as \(N \rightarrow \infty\) ,
and the sum on the r.h.s. converges absolutely.
Lemma 4 (Borovkova, Burton, Dehling [3], Lemma 2.24).
Let \((X_{k})_{k\in \mathbb{Z}}\) be a 1-approximating functional with constants (a k ) of an absolutely regular process with mixing coefficients (β(k)) k≥0 . Suppose moreover that EX i = 0 and that one of the following two conditions holds:
-
1.
X 0 is bounded a.s. and \(\sum _{k=0}^{\infty }k^{2}(a_{k} +\beta (k)) <\infty.\)
-
2.
\(E\vert X_{0}\vert ^{4+\delta } <\infty\) and \(\sum _{k=0}^{\infty }k^{2}(a_{k}^{ \frac{\delta }{ 3+\delta } } +\beta ^{ \frac{\delta }{4+\delta } }(k)) <\infty.\)
Then there exits a constant C such that
Theorem 4 (Borovkova, Burton, Dehling [3], Theorem 4).
Let \((X_{k})_{k\in \mathbb{Z}}\) be a 1-approximating functional with constants (a k ) k≥0 of an absolutely regular process with mixing coefficients (β(k)) k≥0 . Suppose moreover that EX i = 0, \(E\vert X_{0}\vert ^{4+\delta } <\infty\) and that
for some δ > 0. Then, as \(n \rightarrow \infty,\)
where \(\sigma ^{2} = EX_{0}^{2} + 2\sum _{j=1}^{\infty }E(X_{0}X_{j}).\) In case \(\sigma ^{2} = 0\) , \(\mathcal{N}(0,0)\) denotes the point mass at the origin. If X 0 is bounded, the CLT continues to hold if (77) is replaced by the condition that \(\sum _{k=0}^{\infty }k^{2}(a_{k} +\beta (k)) <\infty\) .
An important tool to derive asymptotic results for weakly dependent data are coupling methods. We will apply this method in the proof of Proposition 2.
Theorem 5 (Borovkova, Burton, Dehling [3], Theorem 3).
Let \((X_{n})_{n\in \mathbb{N}}\) be a 1-approximating functional with summable constants (a k ) k≥0 of an absolutely regular process with mixing rate (β(k)) k≥0 . Then given integers K,L and N, we can approximate the sequence of \((K + 2L,N)-\) blocks (B s ) s≥1 by a sequence of independent blocks \((B_{s}^{{\prime}})_{s\geq 1}\) with the same marginal distribution in such a way that
where \(\alpha _{L}:= \left (2\sum _{l=L}^{\infty }a_{l}\right )^{1/2}.\)
In statistical application, the question of how to estimate \(\sigma ^{2}\) is important. In the situation when the observations are a functional of α-mixing process, Dehling et al. [10] propose the estimation of the variance of partial sums of dependent processes by the subsampling estimator
with \(\hat{T}_{i}(l) =\sum _{ j=(i-1)l+1}^{il}F_{n}(X_{j})\) and \(\tilde{U}_{n} = \frac{1} {n}\sum _{j=1}^{n}F_{ n}(X_{j})\), where F n (⋅ ) is the empirical distribution function.
Theorem 6 (Dehling, Fried, Sharipov, Vogel, Wornowizki [9], Theorem 1.2).
Let (X k ) k≥1 be a stationary, 1-approximating functional of an α-mixing processes. Suppose that for some δ > 0, \(E\vert X_{1}\vert ^{2+\delta } <\infty\) , and that the mixing coefficients (α k ) k≥1 and the approximation constants (a k ) k≥1 satisfy
In addition, we assume that F is Lipschitz-continuous, that \(\alpha _{k} = O(n^{-8})\) and that \(a_{m} = O(m^{-12})\) . Then, as \(n \rightarrow \infty\) , \(l_{n} \rightarrow \infty\) and \(l_{n} = o(\sqrt{n})\) , we have \(\hat{D}_{n}\longrightarrow \sigma\) in L 2 .
To deal with the degenerate kernel g, we need to find upper bounds for the expectations \(E\left (g(X_{i_{1}},X_{j_{1}})g(X_{i_{2}},X_{j_{2}})\right )\), in terms of the maximal distance among the indices. Since 1 ≤ i 1 < i 2 ≤ [n λ] and \([n\lambda ] + 1 \leq j_{1} <j_{2} \leq n\), we get i 1 < i 2 < j 1 < j 2.
Lemma 5 (Dehling, Fried [8], Proposition 6.1).
Let (X n ) n≥1 be a 1-approximating functional with constants (a k ) k≥1 of an absolutely regular process with mixing coefficients (β(k)) k≥1 and let g(x,y) be a 1-continuous bounded degenerate kernel. Then we have
where \(S = \vert \sup _{x,y}g(x,y)\vert\) and \(k =\max \left \{i_{2} - i_{1},j_{1} - i_{2},j_{2} - j_{1}\right \}\) .
The following two results are useful for proving tightness of a stochastic process. The first one is used to control the fluctuation of maximum. Let ξ 1, …, ξ n be random variables, and define \(S_{k} =\xi _{1} +\ldots +\xi _{k}\) (S 0 = 0), and \(M_{n} =\max _{0\leq k\leq n}\vert S_{k}\vert\).
Theorem 7 (Billingsley [2], Theorem 10.2).
Suppose that β ≥ 0 and α > 1∕2 and that there exist nonnegative numbers u 1 ,…,u n such that for all positive λ
then for all positive λ
where K β,α is a constant depending only on β and α.
Theorem 8 (Billingsley [2], Theorem 8.4).
The sequence {Y n }, defined by
is tight if for each ε > 0 there exist a λ > 1 and a \(n_{0} \in \mathbb{N}\) such that for n ≥ n 0
Rights and permissions
Copyright information
© 2015 Springer Science+Business Media New York
About this chapter
Cite this chapter
Dehling, H., Fried, R., Garcia, I., Wendler, M. (2015). Change-Point Detection Under Dependence Based on Two-Sample U-Statistics. In: Dawson, D., Kulik, R., Ould Haye, M., Szyszkowicz, B., Zhao, Y. (eds) Asymptotic Laws and Methods in Stochastics. Fields Institute Communications, vol 76. Springer, New York, NY. https://doi.org/10.1007/978-1-4939-3076-0_12
Download citation
DOI: https://doi.org/10.1007/978-1-4939-3076-0_12
Publisher Name: Springer, New York, NY
Print ISBN: 978-1-4939-3075-3
Online ISBN: 978-1-4939-3076-0
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)