
Abstract
Clustering in Metric Spaces can be conveniently performed by the so called k-medians method. It consists of a variant of the popular k-means algorithm in which cluster medians (most centered cluster points) are used instead of the conventional cluster means. Two main aspects of the k-medians algorithm deserve special attention: computing efficiency and initialization. Efficiency issues have been studied in previous works. Here we focus on initialization. Four techniques are studied: Random selection, Supervised selection, the Greedy-Interchange algorithm and the Maxmin algorithm. The capabilities of these techniques are assessed through experiments in two typical applications of Clustering; namely, Exploratory Data Analysis and Unsupervised Prototype Selection. Results clearly show the importance of a good initialization of the k-medians algorithm in all the cases. Random initialization too often leads to bad final partitions, while best results are generally obtained using Supervised selection. The Greedy-Interchange and the Maxmin algorithms generally lead to partitions of high quality, without the manual effort of Supervised selection. From these algorithms, the latter is generally preferred because of its better computational behaviour.
Chapter PDF
Similar content being viewed by others

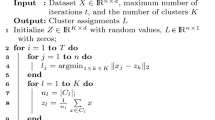

Key words
References
R.O. Duda and P.E. Hart. Pattern Classification and Scene Analysis. Wiley, 1973.
E. Granum and M. G. Thomason. Automatically Inferred Markov Network Models for Classification of Chromosomal Band Pattern Structures. Cytometry, 11, 1990.
A. K. Jain and R. C. Dubes. Algorithms for Clustering Data. Prentice Hall, 1988.
A. Juan and E. Vidal. Application of the K-Nearest-Neighbour Rule to the Classification of Banded Chromosomes. In ICPR’00 (accepted).
A. Juan and E. Vidal. Fast k-means-like clustering in metric spaces. Pattern Recognition Letters, 15(1):19–25, 1994.
A. Juan and E. Vidal. Fast Median Search in Metric Spaces. In A. Amin, D. Dori, P. Pudil, and H. Freeman, editors, Advances in Pattern Recognition, volume 1451, pages 905–912. Springer-Verlag, 1998.
O. Kariv and S. L. Hakimi. An Algorithmic Approach to Network Location Problems. II: The p-Medians. SIAM Journal on Applied Math., 37(3):539–560, 1979.
I. Katsavounidis. A new initialization technique for generalized Lloyd iteration. IEEE Signal Processing Letters, 1(10):144–146, October 1994.
C. Lundsteen, J. Philip, and E. Granum. Quantitative analysis of 6985 digitized trypsin G-banded human metaphase chromosomes. Clinical Genetics, 18, 1980.
Mirchandani P.B. and Francis R.L. editors. Discrete Location Theory. Wiley, 1990.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2000 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Juan, A., Vidal, E. (2000). Comparison of Four Initialization Techniques for the K-Medians Clustering Algorithm. In: Ferri, F.J., Iñesta, J.M., Amin, A., Pudil, P. (eds) Advances in Pattern Recognition. SSPR /SPR 2000. Lecture Notes in Computer Science, vol 1876. Springer, Berlin, Heidelberg. https://doi.org/10.1007/3-540-44522-6_87
Download citation
DOI: https://doi.org/10.1007/3-540-44522-6_87
Published:
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-67946-2
Online ISBN: 978-3-540-44522-7
eBook Packages: Springer Book Archive
