
Abstract
To statistically model large data sets of sequences of knowledge processes during asynchronous, online forums, we must address analytic difficulties involving the whole data set (missing data, nested data, and the tree structure of online messages), dependent variables (multiple, infrequent, discrete outcomes and similar adjacent messages), and explanatory variables (sequences, indirect effects, false-positives, and robustness). Statistical discourse analysis (SDA) addresses all of these issues, as shown in an analysis of 1,330 asynchronous messages written by 17 students during a 13-week online educational technology course. The results showed how attributes at multiple levels (individual and message) affected knowledge creation processes. Men were more likely than women to theorize. Asynchronous messages created a micro-time context; opinions and asking about purpose preceded new information; and anecdotes, opinions, different opinions, elaborating ideas, and asking about purpose or information preceded theorizing. These results show how informal thinking precedes formal thinking and how social metacognition affects knowledge creation.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
Introduction
The benefits of online discussions have increased both their uses and records of their uses, which allow detailed analyses to inform design and to improve their productivity. Unlike face-to-face talk, students on asynchronous, online forums can participate at different places and times and have more time to gather information, contemplate ideas, and evaluate claims before responding, resulting in superior decision-making, problem solving, writing, and knowledge creation (KC; Luppicini 2007; Tallent-Runnels et al. 2006; Glassner et al. 2005). For example, studies using aggregate counts from online forum data showed how specific actions (e.g., “why” or “how” questions, explanations, evidence, summaries) are related to KC (Lee et al. 2006; Lin and Lehman 1999; Wise and Chiu 2011).
While aggregate counts provide descriptive summaries, they do not fully utilize the information relating to the time and order of collaboration and learning processes (Reimann 2009) or capture the sequential data needed to test KC hypotheses about how group members’ actions/posts/messages are related to one another (Chiu 2008a). Aggregate counts cannot illuminate the relationships among processes that contribute to knowledge creation. In contrast, analyses of sequences of messages can test whether some types of messages (e.g., asking for an explanation) or sequences of messages (different opinion followed by asking for explanation) often precede target types of messages (e.g., theorizing). These results can help us understand the temporal and causal relationships among different types of messages or message sequences that aid or hinder knowledge creation. We show how statistical discourse analysis (SDA, Chiu 2008b) can model these sequences to test these KC hypotheses. To explicate SDA, we introduce a specific set of data (Fujita 2009) and hypotheses to contextualize the methodological issues.
Data
In this study, we examine asynchronous, online forum messages written by students in a 13-week online graduate educational technology course delivered using Web-Knowledge Forum. These data are the second iteration of a larger design-based research study (Fujita 2009). Data sources included questionnaire responses, learning journals, and discourse in Knowledge Forum. One of the authors participated in the course both as a design researcher collaborating closely with the instructor and as a teaching assistant interacting in course discussions with students. The goals for this study were twofold: to improve the quality of online graduate education in this particular instance and to contribute to the theoretical understanding of how students collaborate to learn deeply and create knowledge through progressive discourse (Bereiter 1994, 2002).
Participants
Participants were 17 students (12 females, 5 males) (see Table 6.2). They ranged in age from mid-20s to mid-40s. Five were students in academic programs (4 M.A., 1 Ph.D.); 12 were students in professional programs (9 M.Ed., 3 Ed.D.). See Table 6.A1 in Appendix for details.
Procedure
Students were encouraged to engage in progressive discourse through three intervention activities: a reading by Bereiter (2002), classroom materials called Discourse for Inquiry (DFI) cards, and the scaffold supports feature built into Knowledge Forum. The DFI cards were adapted from classroom materials developed by Woodruff and Brett (1999) to help elementary school teachers and preservice teachers improve their face-to-face collaborative discussion. These adapted activities can model thinking processes and discourse structures in the online Knowledge Forum environment, which help online graduate students engage in progressive discourse. There were three DFI cards: Managing Problem Solving outlined commitments to progressive discourse (Bereiter 2002), Managing Group Discourse suggested guidelines for supporting or opposing a view, and Managing Meetings provided two strategies to help students deal with anxiety. The cards were in a portable document file (.pdf) that students could download, print out, or see as they worked online.
Knowledge Forum, an extension of the CSILE (Computer Supported Intentional Learning Environment), is specially designed to support knowledge building. Students work in virtual spaces to develop their ideas, represented as “notes,” which we will refer to in this chapter as “messages.” It offers sophisticated features not available in other conferencing technologies, such as “scaffold supports” (labels of thinking types), “rise above” (a higher-level integrative note, such as a summary or synthesis of facts into a theory), and a capacity to connect ideas through links between messages in different views. Students select a scaffold support and typically use it as a sentence opener while composing messages; hence, they self-code their messages by placing yellow highlights of thinking types in the text that bracket segments of body text in the messages. At the beginning of the course, only the Theory Building and Opinion scaffolds built into Knowledge Forum were available. Later, in week 9, two students designed the “Idea Improvement” scaffolds (e.g., What do we need this idea for?) as part of their discussion leadership (see Table 6.1). The Idea Improvement scaffolds were intended by the student designers of the scaffolds to emphasize the socio-cognitive dynamics of “improvable ideas,” one of the 12 knowledge building principles (Scardamalia 2002) for progressive discourse. In this study, we focus our analysis on tracing messages with scaffold supports that build on or reply to one another. Types of scaffold supports relevant to our hypotheses are organized and renamed (italicized) in terms of cognition, social metacognition, and dependent variables.
Hypotheses
We test whether recent cognition or social metacognition facilitate new information or theoretical explanations (Chiu 2000; Lu et al. 2011). Introducing new information and creating theoretical explanations are both key processes that contribute to knowledge building discourse. New information provides grist that theoretical explanations can integrate during discourse to yield knowledge creation. As students propose integrative theories that explain more facts, they create knowledge through a process of explanatory coherence (Thagard 1989). Hence, new information and theoretical explanations are suitable target processes to serve as dependent variables in our statistical model.
Researchers have shown that many online discussions begin with sharing of opinions (Gunawardena et al. 1997). Students often activate familiar, informal concepts before less familiar, formal concepts (Chiu 1996). During a discussion, comments by one student (e.g., a key word) might spark another student to activate related concepts in his or her semantic network and propose a new idea (Nijstad et al. 2003). When students do not clearly understand these ideas, they can ask questions to elicit new information, elaborations, or explanations (Hakkarainen 2003). Also, students may disagree (different opinions) and address their differences by introducing evidence or explaining their ideas (Howe 2009). Whereas individual metacognition is monitoring and regulating one’s own knowledge, emotions, and actions (Hacker and Bol 2004), social metacognition is defined as group members’ monitoring and controlling one another’s knowledge, emotions, and actions (Chiu and Kuo 2009). Specifically, we test whether three types of cognition (informal opinion, elaboration, and evidence) and three types of social metacognition (ask for explanation, ask about use and different opinion) increase the likelihoods of new information or theoretical explanations in subsequent messages (see Table 6.2). To reduce omitted variable bias, additional individual and time explanatory variables were added. For example, earlier studies showed that males were more likely than females to make claims, argue, elaborate, explain, and critique others (Lu et al. 2011).
Analysis
To test the above hypotheses, we must address analytic difficulties involving the data, the dependent variables, and the explanatory variables (see Table 6.3). Data issues include missing data, nested data, and the tree structure of online messages. Difficulties involving dependent variables include discrete outcomes, infrequent outcomes, similar adjacent messages, and multiple outcomes. Explanatory variable issues include sequences, indirect effects, false-positives, and robustness of results. SDA addresses each of these analytic difficulties, as described below.
SDA addresses the data issues (missing data, nested data, and tree structure of online messages) with Markov Chain Monte Carlo multiple imputation (MCMC-MI), multilevel analysis, and identification of the previous message. Missing data can reduce estimation efficiency, complicate data analyses, and bias results. By estimating the missing data, MCMC-MI addresses this issue more effectively than deletion, mean substitution, or simple imputation, according to computer simulations (Peugh and Enders 2004).
Messages are nested within different topic folders in the online forum, and failure to account for similarities in messages within the same topic folder (vs. different topic folders) can underestimate the standard errors (Goldstein 1995). To address this issue, SDA models nested data with a multilevel analysis (Goldstein 1995; cf. hierarchical linear modeling, Bryk and Raudenbush 1992).
Unlike a linear, face-to-face conversation in which one turn of talk often follows the one before it, an asynchronous message in an online forum might follow a message written much earlier. Still, each message in a topic folder and its replies are linked to one another by multiple threads and single connections in a tree structure. See Fig. 6.1, for an example, of a topic message (1) and its 8 responses (2, 3, …, 9).

Tree structure showing how nine messages are related to one another
These nine messages occur along three discussion threads: (a) 1 → 2 (→ 3; → 7), (b) 1 → 4 (→ 6; → 8 → 9), and (c) 1 → 5. Messages in each thread are ordered by time, but they are not necessarily consecutive. In thread (b), for example, message #6 followed message #4 (not #5). To capture the tree structure of the messages, we identify the immediate predecessor of each message. Then, we can reconstruct the entire tree to identify any ordinal predecessor of any message.
SDA addresses the dependent variable difficulties (discrete, infrequent, serial correlation, and multiple) with logit regressions, a logit bias estimator, I2 index of Q-statistics, and multivariate outcome analyses. The dependent variables are often discrete (a justification occurs in a conversation or it does not) rather than continuous (e.g., test scores), so standard regressions such as ordinary least squares can bias the standard errors. To model discrete dependent variables, we use a logit regression (Kennedy 2008). As infrequent dependent variables can bias the results of a logit regression, we estimate the logit bias and remove it (King and Zeng 2001).
As adjacent messages often resemble one another more than messages that are far apart, failure to model this similarity (serial correlation of errors) can bias the results (Kennedy 2008). An I2 index of Q-statistics tested all topics simultaneously for serial correlation of residuals in adjacent messages (Huedo-Medina et al. 2006). If the I2 index shows significant serial correlation, adding the dependent variable of the previous message as an explanatory variable often eliminates the serial correlation (e.g., when modeling the outcome variable theory, add whether it occurs in the previous message [theory (−1)], Chiu and Khoo 2005; see paragraph below on vector auto-regression, Kennedy 2008).
Multiple outcomes (new information, theorizing) can have correlated residuals that can underestimate standard errors (Goldstein 1995). If the outcomes are from different levels, separate analyses must be done at each level, as analyzing them in the same model overcounts the sample size of the higher-level outcome(s) and biases standard errors. To model multiple outcomes properly at the same level of analysis, we use a multivariate outcome, multilevel analysis (Goldstein 1995).
Furthermore, SDA addresses the explanatory variable issues (sequences, indirect effects, false-positives, robustness) with vector auto-regression, multilevel M-tests, the two-stage linear step-up procedure, and robustness tests. A vector auto-regression (VAR, Kennedy 2008) combines attributes of sequences of recent messages into a local context (micro-time context) to model how they influence the subsequent messages. For example, the likelihood of new information in a message might be influenced by attributes of earlier messages (e.g., different opinion in the previous message) or earlier authors (e.g., gender of the author of the previous message).
Multiple explanatory variables can yield indirect, mediation effects or false-positives. As single-level mediation tests on nested data can bias results downward, multilevel M-tests are used for multilevel data – in this case, messages within topics (MacKinnon et al. 2004). Testing many hypotheses of potential explanatory variables also increases the likelihood of a false-positive (type I error). To control for the false discovery rate (FDR), the two-stage linear step-up procedure was used, as it outperformed 13 other methods in computer simulations (Benjamini et al. 2006).
To test the robustness of the results, three variations of the core model can be used. First, a single outcome, multilevel model can be run for each dependent variable. Second, subsets of the data (e.g., halves) can be run separately to test the consistency of the results for each subset. Third, the analyses can be repeated for the original data set (without the estimated data).
Analysis Procedure
After MCMC-MI of the missing data to yield a complete data set, each online message’s preceding message was identified and stored to capture the tree structure of the messages. Then, we simultaneously modeled two process variables in students’ messages (new information and theorizing) with SDA (Chiu 2001).
For Process ymt (the process variable y [e.g., new information] for message m in topic t), β y is the grand mean intercept. The message- and topic-level residuals are e mt and f t , respectively. As analyzing rare events (target processes occurred in less than 10 % of all messages) with logit/probit regressions can bias regression coefficient estimates, King and Zeng’s (2001) bias estimator was used to adjust them.
First, a vector of student demographic variables was entered: male and young (Demographics). Each set of predictors was tested for significance with a nested hypothesis test ( χ 2 log likelihood, Kennedy 2008).
Next, schooling variables were entered: doctoral student, Masters of Education student, Masters of Arts student, and part-time student (Schooling). Then, students’ job variables were entered: teacher, postsecondary teacher, and technology (Job). Next, students’ experience variables were entered: KF experience and number of past online courses (Experience).
Then, attributes of the previous message were entered: opinion (−1), elaboration (−1), anecdote (−1), ask about use (−1), ask for explanation (−1), different opinion (−1), new information (−1), theory (−1), and any of these processes (−1) (Previous). The attributes of the message two responses ago along the same thread (−2) were entered, then, those of the message three responses ago along the same thread (−3), and so on until none of the attributes in a message were significant.
Structural variables (Demographics, Schooling, Job, Experience) might show moderation effects, so a random effects model was used. If the regression coefficients of an explanatory variable in the Previous message (e.g., evidence; β ypt = β yt + f yj ) differed significantly (f yj ≠ 0?), then a moderation effect might exist, and their interactions with processes were included.
The multilevel M-test (MacKinnon et al. 2004) identified multilevel mediation effects (within and across levels). For significant mediators, the percentage change is 1 − (b′/b), where b′ and b are the regression coefficients of the explanatory variable, with and without the mediator in the model, respectively. The odds ratio of each variable’s total effect (TE = direct effect plus indirect effect) was reported as the increase or decrease (+TE % or –TE %) in the outcome variable (Kennedy 2008). As percent increase is not linearly related to standard deviation, scaling is not warranted.
An alpha level of .05 was used. To control for the false discovery rate, the two-stage linear step-up procedure was used (Benjamini et al. 2006). An I 2 index of Q-statistics tested messages across all topics simultaneously for serial correlation, which was modeled if needed (Goldstein et al. 1994; Huedo-Medina et al. 2006; Ljung and Box 1979).
Conditions of Use
SDA relies on two primary assumptions and requires a minimum sample size. Like other regressions, SDA assumes a linear combination of explanatory variables. (Nonlinear aspects can be modeled as nonlinear functions of variables [e.g., age2] or interactions among variables [anecdote × ask about use].) SDA also requires independent residuals (no serial correlation as discussed above). In addition, SDA has modest sample size requirements. Green (1991) proposed the following heuristic sample size, N, for a multiple regression with M explanatory variables and an expected explained variance R 2 of the outcome variable:
For a large model of 20 explanatory variables with a small expected R 2 of 0.10, the required sample size is 91 messages: = 8 × (1 − 0.10)/0.10 + 20 − 1. Less data are needed for a larger expected R 2 or smaller models. Note that statistical power must be computed at each level of analysis (message, topic, class, school … country). With 1,330 messages, statistical power exceeded 0.95 for an effect size of 0.1 at the message level. The sample sizes at the topic level (13) and the individual level (17) were very small, so any results at these units must be interpreted cautiously.
Results
Summary Statistics
In this study, 17 students wrote 1,330 messages on 13 topics, organized into folders in the forum. Students who posted more messages on average than other students had the following profile: older, enrolled in Masters of Arts (M.A.) programs, part-time students, not teachers, worked in technology fields, or had Knowledge Forum (KF) experience (older: m = 47 vs. other m =37 messages; M.A.: 64 vs. 36; part-time: 47 vs. 27; not teachers: 55 vs. 36; technology: 54 vs. 39; KF: 44 vs. 32). Students posted few messages with the following attributes (see Table 6.4, panel B): new information (1 %), theory (4 %), opinion (5 %), elaboration (2 %), anecdotal evidence (1 %), ask for explanation (9 %), ask about use (2 %), and different opinion (1 %). Most messages were none of the above (83 %). (As some messages included more than one of these attributes, these percentages do not sum up to 100 %.)
Explanatory Model
As none of the second-level (topic) variance components were significant, a single-level analysis was sufficient. All results discussed below describe first entry into the regression, controlling for all previously included variables. Ancillary regressions and statistical tests are available upon request.
New Information
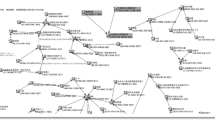
The attributes of previous messages were linked to new information in the current message. After an opinion, new information was 7 % more likely in the next message. After a question about use three messages before, new information was 10 % more likely. Together, these explanatory variables accounted for about 26 % of the variance of new information. See Fig. 6.2.

Path diagram for new information and theorize. Thicker lines indicate stronger links. *p < .05, **p < .01, ***p < .001
Theorize
Gender and attributes of previous messages were significantly linked to theorizing. Men were 22 % more likely than women to theorize. Demographics accounted for 5 % of the variance in theorizing.
Attributes of earlier messages up to three messages before were linked to theorizing. After an explanation or an elaboration, theorizing was 21 % or 39 % more likely, respectively. If someone asked about the use of an idea, gave an opinion, or gave a different opinion two messages before, theorizing was 21 %, 54 %, or 12 % more likely, respectively. After anecdotal evidence three messages before, theorizing was 34 % more likely. Altogether, these explanatory variables accounted for 38 % of the variance of theorizing.
Other variables were not significant. As the I2 index of Q-statistics for each dependent variable was not significant, serial correlation was unlikely.
Discussion
During asynchronous, online discussions, students have more time to gather information, contemplate ideas, and evaluate claims, so they often display higher levels of knowledge creation than during face-to-face discussions (Hara et al. 2000; Luppicini 2007; Tallent-Runnels et al. 2006). Extending this research beyond aggregate attributes of separate messages, this study examined the relationships among messages with a new method, statistical discourse analysis. Both individual characteristics and the micro-time context of recent messages’ cognition and social metacognition affected the likelihoods of subsequent new information and theorizing.
Demographics and Job
Past studies of primary and secondary school students had shown that individual differences in gender accounted for little of the variance in discussion behaviors (Chen and Chiu 2008), but this study showed that these men were more likely than these women to theorize. Gender accounted for five percent of the variance. This result is consistent with the research that boys are more active than girls during online discussions in high school (e.g., Lu et al. 2011).
Micro-time Context of Recent Messages
Beyond the effects of individual characteristics, both cognitive and social metacognitive aspects of recent messages showed micro-time context effects on subsequent messages. These results showed that asynchronous messages are more than simply lists of individual cognition (Thomas 2002); instead, these messages influence and respond to one another.
Informal cognition (opinions, elaborations, anecdotes) often preceded formal cognition (new information, theorizing). After a message containing an opinion, messages containing new information and theorizing were more likely to follow. Anecdotes and elaborations were also more likely to be followed by theorizing. Together, these results are consistent with the views that familiar, informal cognition is often activated before more formal cognition (Chiu 1996) and that the former can facilitate the latter through spreading activation of related semantic networks both in the individual and among group members (Nijstad et al. 2003). This order of informal cognition before formal cognition also reflects the social nature of knowledge building discourse; individuals share their informal experiences, which group members consider, reshape, and integrate into formal, public, structured knowledge. For educators, these results suggest that students often share their ideas informally and teachers should encourage students to use one another’s ideas to create formal knowledge.
Social metacognition, in the form of questions and different opinions, also affected the likelihoods of new information and theorizing. Reflecting students’ knowledge interests, their questions identify key goals and motivate knowledge building. Questions about use of a particular idea had the largest effect on inducing more new information, showing their power to influence other’s behaviors, which is consistent with Bereiter and Scardamalia’s (2006) conceptions of “design mode” teaching and earlier research (e.g., Chen et al. 2012). Furthermore, both types of questions elicited more theorizing, which is also consistent with earlier studies (e.g., Lu et al. 2011). These results suggest that educators can design instruction to give students autonomy or “collective cognitive responsibility” (Scardamalia 2002; Zhang et al. 2009) so that students can create their own learning goals (or at least subgoals) and ask questions to motivate themselves and their classmates to build knowledge that is meaningful to them. Lastly, a different opinion had the largest effect on a subsequent theory, consistent with past disequilibrium research showing that disagreements provoke explanations (e.g., Chiu and Khoo 2003). Together, these results suggest useful prompts that a teacher might encourage students to use during online discussions, for example, through brief cue cards or direct teacher questioning.
Statistical Discourse Analysis
This study showcases a new methodology for analyzing relationships among individual characteristics and nonlinear, asynchronous messages during an online discussion. Such analyses must address analytic difficulties involving the data, the dependent variables, and the explanatory variables. First, data issues include missing data, nested data, and the tree structure of online messages. Second, difficulties involving dependent variables include discrete outcomes, infrequent outcomes, similar adjacent messages, and multiple outcomes. Lastly, explanatory variable issues include sequences, indirect effects, false-positives, and robustness of results.
SDA addresses each of these analytic difficulties as follows (see Table 6.3). First, SDA addresses the data issues (missing data, nested data, tree structure of online messages) with Markov Chain Monte Carlo multiple imputation (MCMC-MI), multilevel analysis, and identification of the previous message. Second, SDA addresses the dependent variable difficulties (discrete, infrequent, serial correlation, and multiple) with logit regressions, a logit bias estimator, I2 index of Q-statistics, and multivariate outcome analyses. Lastly, SDA addresses the explanatory variable issues (sequences, indirect effects, false-positives, robustness) with vector auto-regression, multilevel M-tests, the two-stage linear step-up procedure, and robustness tests.
Conclusion
This study extends the online discussion research beyond aggregated attributes of separate messages to relationships among messages by showcasing a new methodology, statistical discourse analysis. The results showed that both individual characteristics and the micro-time context of recent messages’ cognition and social metacognition affected the likelihoods of subsequent new information and theorizing. Unlike past studies of students, this exploratory study with a few students suggests that gender in adults might account for substantial differences in online behaviors. Specifically, men were more likely than women to theorize. Rather than simply being lists of individual cognition, asynchronous messages create a micro-time context that affects subsequent messages. Informal cognition (opinions, anecdotes, elaborations) facilitates more formal cognition (new information and theoretical explanations). Meanwhile, social metacognition, in the form of questions and different opinions, had the strongest effects on subsequent new information and theoretical explanations.
References
Benjamini, Y., Krieger, A. M., & Yekutieli, D. (2006). Adaptive linear step-up procedures that control the false discovery rate. Biometrika, 93, 491–507.
Bereiter, C. (1994). Implications of postmodernism for science, or science as progressive discourse. Educational Psychologist, 29(1), 3–12.
Bereiter, C. (2002). Education and mind in the knowledge age. Mahwah: Lawrence Erlbaum Associates.
Bereiter, C., & Scardamalia, M. (2006). Education for the knowledge age: Design-centered models of teaching and instruction. In P. A. Alexander & P. H. Winne (Eds.), Handbook of educational psychology (2nd ed., pp. 695–713). Mahwah: Lawrence Erlbaum.
Bryk, A. S., & Raudenbush, S. W. (1992). Hierarchical linear models. London: Sage.
Chen, G., & Chiu, M. M. (2008). Online discussion processes. Computers & Education, 50(3), 678–692.
Chen, G., Chiu, M. M., & Wang, Z. (2012). Social metacognition and the creation of correct, new ideas: A statistical discourse analysis of online mathematics discussions. Computers in Human Behavior, 28(3), 868–880.
Chiu, M. M. (1996). Exploring the origins, uses and interactions of student intuitions: Comparing the lengths of paths. Journal for Research in Mathematics Education, 27(4), 478–504.
Chiu, M. M. (2000). Group problem solving processes: Social interactions and individual actions. Journal for the Theory of Social Behavior, 30(1), 27–50.
Chiu, M. M. (2001). Analyzing group work processes: Towards a conceptual framework and systematic statistical analyses. In F. Columbus (Ed.), Advances in psychology research (Vol. 4, pp. 193–222). Huntington: Nova Science.
Chiu, M. M. (2008a). Effects of argumentation on group micro-creativity: Statistical discourse analyses of algebra students’ collaborative problem solving. Contemporary Educational Psychology, 33, 382–402.
Chiu, M. M. (2008b). Flowing toward correct contributions during group problem solving: A statistical discourse analysis. Journal of the Learning Sciences, 17(3), 415–463.
Chiu, M. M., & Khoo, L. (2003). Rudeness and status effects during group problem solving: Do they bias evaluations and reduce the likelihood of correct solutions? Journal of Educational Psychology, 95, 506–523.
Chiu, M. M., & Khoo, L. (2005). A new method for analyzing sequential processes: Dynamic multi-level analysis. Small Group Research, 36, 1–32.
Chiu, M. M., & Kuo, S. W. (2009). From metacognition to social metacognition: Similarities, differences, and learning. Journal of Education Research, 3(4), 1–19.
Fujita, N. (2009). Group processes supporting the development of progressive discourse in online graduate courses. Unpublished Doctoral Dissertation, University of Toronto, Toronto. Retrieved from http://hdl.handle.net/1807/43778
Glassner, A., Weinstoc, M., & Neuman, Y. (2005). Pupils’ evaluation and generation of evidence and explanation in argumentation. British Journal of Educational Psychology, 75, 105–118.
Goldstein, H. (1995). Multilevel statistical models. Sydney: Edward Arnold.
Goldstein, H., Healy, M., & Rasbash, J. (1994). Multilevel models with applications to repeated measures data. Statistics in Medicine, 13, 1643–1655.
Green, S. B. (1991). How many subjects does it take to do a regression analysis? Multivariate Behavioral Research, 26, 499–510.
Gunawardena, C. N., Lowe, C. A., & Anderson, T. (1997). Analysis of a global online debate and the development of an interaction analysis model for examining social construction of knowledge in computer conferencing. Journal of Educational Computing Research, 17(4), 397–431.
Hacker, D. J., & Bol, L. (2004). Metacognitive theory. In D. M. McInerney & S. Van Etten (Eds.), Big theories revisited (Vol. 4, pp. 275–297). Greenwich: Information Age.
Hakkarainen, K. (2003). Emergence of progressive-inquiry culture in computer-supported collaborative learning. Learning Environments Research, 6(2), 199–220.
Hara, N., Bonk, C. J., & Angeli, C. (2000). Content analysis of online discussion in an applied educational psychology course. Instructional Science, 28, 115–152.
Howe, C. (2009). Collaborative group work in middle childhood. Human Development, 52(4), 215–239.
Huedo-Medina, T. B., Sanchez-Meca, J., Marin-Martinez, F., & Botella, J. (2006). Assessing heterogeneity in meta-analysis. Psychological Methods, 11, 193–206.
Kennedy, P. (2008). Guide to econometrics. Cambridge: Wiley-Blackwell.
King, G., & Zeng, L. (2001). Logistic regression in rare events data. Political Analysis, 9, 137–163.
Lee, E., Chan, C., & van Aalst, J. (2006). Students assessing their own collaborative knowledge building. International Journal of Computer-Supported Collaborative Learning, 1(1), 57–87.
Lin, X., & Lehman, J. D. (1999). Supporting learning of variable control in a computer-based biology environment. Journal of Research in Science Teaching, 36, 837–858.
Ljung, G., & Box, G. (1979). On a measure of lack of fit in time series models. Biometrika, 66, 265–270.
Lu, J., Chiu, M., & Law, N. (2011). Collaborative argumentation and justifications: A statistical discourse analysis of online discussions. Computers in Human Behavior, 27, 946–955.
Luppicini, R. (2007). Review of computer mediated communication research for education. Instructional Science, 35(2), 141–185.
MacKinnon, D. P., Lockwood, C. M., & Williams, J. (2004). Confidence limits for the indirect effect: Distribution of the product and resampling methods. Multivariate Behavioral Research, 39, 99–128.
Nijstad, B. A., Diehl, M., & Stroebe, W. (2003). Cognitive stimulation and interference in idea generating groups. In P. B. Paulus & B. A. Nijstad (Eds.), Group creativity: Innovation through collaboration (pp. 137–159). New York: Oxford University Press.
Peugh, J. L., & Enders, C. K. (2004). Missing data in educational research. Review of Educational Research, 74, 525–556.
Reimann, P. (2009). Time is precious: Variable and event-centred approaches to process analysis in CSCL research. International Journal of Computer-Supported Collaborative Learning, 4(3), 239–257.
Scardamalia, M. (2002). Collective cognitive responsibility for the advancement of knowledge. In B. Smith (Ed.), Liberal education in a knowledge society (pp. 67–98). Chicago: Open Court.
Scardamalia, M., & Bereiter, C. (1994). Computer support for knowledge-building communities. The Journal of the Learning Sciences, 3(3), 265–283.
Tallent-Runnels, M. K., Thomas, J. A., Lan, W. Y., Cooper, S., Ahern, T. C., Shaw, S. M., & Liu, X. (2006). Teaching courses online. Review of Educational Research, 76(1), 93–135.
Thagard, P. (1989). Explanatory coherence. Behavioral and Brain Sciences, 1989(12), 435–502.
Thomas, M. J. W. (2002). Learning within incoherent structures: The space of online discussion forums. Journal of Computer Assisted Learning, 18, 351–366.
Wise, A., & Chiu, M. M. (2011). Analyzing temporal patterns of knowledge construction in a role-based online discussion. International Journal of Computer-Supported Collaborative Learning, 6(6), 445–470.
Woodruff, E., & Brett, C. (1999). Collaborative knowledge building: Preservice teachers and elementary students talking to learn. Language and Education, 13(4), 280–302.
Zhang, J., Scardamalia, M., Reeve, R., & Messina, R. (2009). Designs for collective cognitive responsibility in knowledge building communities. Journal of the Learning Sciences, 18(1), 7–44.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Appendix: Ancillary Data
Appendix: Ancillary Data
Rights and permissions
Copyright information
© 2014 Springer Science+Business Media Singapore
About this chapter
Cite this chapter
Chiu, M.M., Fujita, N. (2014). Statistical Discourse Analysis of Online Discussions: Informal Cognition, Social Metacognition, and Knowledge Creation. In: Tan, S., So, H., Yeo, J. (eds) Knowledge Creation in Education. Education Innovation Series. Springer, Singapore. https://doi.org/10.1007/978-981-287-047-6_6
Download citation
DOI: https://doi.org/10.1007/978-981-287-047-6_6
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-287-046-9
Online ISBN: 978-981-287-047-6
eBook Packages: Humanities, Social Sciences and LawEducation (R0)