
Abstract
This study revised a statistical method (statistical discourse analysis or SDA) designed for linear sequences of turns of talk to apply to branches of messages in asynchronous online discussions. The revised SDA was used to test for cognitive and social metacognitive relationships among 17 students’ 1,330 asynchronous messages during a 13-week online graduate educational technology course. Multivocality benefits included enhancing a statistical method to expand its scope, exposure to other analytic methods’ simpler user-interfaces, and potential integration of multiple methods into a computer program capable of semiautomatic analyses.
I appreciate the generous sharing of data by Nobuku Fujita, the research assistance of Choi Yik Ting, and comments from participants in the Alpine Rendez-Vous workshop.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Social Metacognition
- Discussion Statistical Analysis (SDA)
- Asynchronous Online Discussion
- Educational Technology Course
- Semi-automatic Analysis
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
Introduction
This study considers how to revise a statistical method designed for face-to-face talk, statistical discourse analysis (SDA), to apply it to participant-coded online discussions (Fujita, Chap. 20, this volume). Unlike the linear sequence of turns of talk however, asynchronous online messages often branch out into separate threads. Applying a successful, revised SDA to online discussion can capitalize on participants’ self-coding of messages to enable analyses of large databases and extend online discussion research beyond messages’ aggregate attributes (e.g., Gress, Fior, Hadwin, & Winne, 2010) to relationships among messages. As earlier turns of talk affect later turns of talk, earlier online messages might influence later messages (Chiu, 2000a; Chiu, 2001; Jeong, 2006). Specifically, I examine how cognitive and social metacognitive aspects of earlier messages affect ideas and explanations in later messages. Whereas individual metacognition is monitoring and control of one’s own knowledge, emotions, and actions (Hacker & Bol, 2004), social metacognition is defined as group members’ monitoring and control of one another’s knowledge, emotions, and actions (Chiu & Kuo, 2009). By understanding how cognitive and social metacognitive components of recent online messages create a micro-time context that aid or hinder students’ ideas and explanations, educators can help students engage in beneficial online processes to learn more.
This study contributes to the research literature in two ways. First, I introduce a new method to model branches of online messages across multiple topics. Second, this method tests how explanatory variables at multiple levels (individual characteristics, cognitive and social metacognitive aspects of messages) influenced 1,330 asynchronous online messages during a 13-week educational technology course. By examining students’ asynchronous online messages, researchers can build a more comprehensive understanding of students’ online processes and their influences to develop appropriate teacher interventions and computer environments.
Theoretical Framework
Unlike students talking face-to-face, those in asynchronous online discussions can participate at different places and times, a valuable resource for improving their learning (Dubrovsky, Kiesler, & Sethna, 1991; Harasim, 1993; Tallent-Runnels et al., 2006). As students writing asynchronous, online messages have more time than those in face-to-face conversations to gather information, contemplate ideas, and evaluate claims before responding, they often display higher levels of decision making, problem solving and writing (Hara, Bonk, & Angeli, 2000; Luppicini, 2007; Tallent-Runnels et al., 2006). During higher quality discussions, students explain and synthesize ideas more often, so they typically learn more (Clark & Sampson, 2008; Glassner, Weinstoc, & Neuman, 2005).
A natural follow-up question is whether students’ sequences of online messages affect their content. Researchers have shown that online discussions can begin with students sharing ideas, recognizing conflicts, and then resolving them by synthesizing ideas (Gunawardena, Lowe, & Anderson, 1997; Howe, 2009). In addition to expressing ideas (cognition), students also monitor and control one another’s ideas and actions through questions, evaluations (agree vs. disagree), and summaries (social metacognition).
Many researchers advocate using clear, formal concepts rather than imprecise, informal concepts (also known as preconceptions or intuitions; e.g., Piaget, 1985; Vygotsky, 1986). However, informal concepts may not necessarily compete with formal concepts; instead, students might initially activate familiar, informal concepts before activating less familiar, formal concepts (Chiu, 1996). During a discussion, a student’s comments (e.g., a key word) might spark another student to activate related concepts in his or her semantic network and propose a new idea (Nijstad, Diehl, & Stroebe, 2003). Consider the following example. Ada and Bill are posting messages about whether teachers should allow students to use the Internet during class lessons.
-
Ada: I think students can use the Internet to access useful pages, such as …
-
Bill: Yes, they can use the mathematical tools on these pages to solve problems.
When students share ideas, they implicitly recognize and agree with one another’s ideas. When other students disagree or do not understand these ideas, they can ask questions to get facts, explanations, or examples of how to use these ideas (Hakkarainen, 2003). Such questions can also serve as polite disagreements.
-
Ada: I’m not clear on what you mean by Internet tools? How could you use them?
Students can respond with facts, explanations or uses (Lu, Chiu, & Law, 2011). Ideally, the explanations incorporate facts into theoretical models with specific applications.
-
Bill: Internet tools are computer programs on a webpage that everyone can access. For example, anyone can graph a line by typing its equation at this website …
Even in the absence of questions, people often support their ideas with explanations, especially when they anticipate disagreements (Chiu & Khoo, 2003; Clark & Sampson, 2008). Explanations also often foster further explanation by others (Chiu, 2008b).
As students share more ideas, they are more likely to disagree with at least one of their groupmate’s ideas (Jeong, 2003). Disagreements can include identifying areas of disagreement, their sources, bases, or their extents.
-
Dan: While Internet tools can be useful, they can also be a crutch …
In response, other students might ask questions (as above) or propose different opinions along with facts, anecdotes, and explanations (Clark & Sampson, 2008).
-
Ada: That’s possible, but it needn’t be a crutch if students have to plot points …
In an advanced discussion, students try to reconcile different views into an integrated summary by identifying areas of agreement, clarifying meanings, proposing and negotiating compromises and syntheses (Wise & Chiu, 2011).
-
Fay: I think we can all agree that Internet tools can be useful in these six ways: … However, we need to be careful to …
Students summarizing ideas often show higher levels of cognition, and these summaries often elevate the levels of cognition in the subsequent time period, suggesting that summaries are pivotal messages that radically change the interaction (Wise & Chiu, 2011).
Table 23.1 summarizes the hypotheses. To reduce omitted variable bias, the explanatory model controls for several individual variables (such as gender; for a full list of control variables, see analysis section below). For example, earlier studies showed that male students were more likely than female students to make claims, argue, elaborate, explain, and critique others (Lu et al., 2011).
Method
In this study, I examine relationships among asynchronous discussion messages posted by students in a 13-week online graduate educational technology course delivered using Web-Knowledge Forum. For a description of the data, see Fujita (this volume, Chap. 20).
Data
As SDA was designed for turns of talk, it required revision to analyze branches of messages.
Unlike a linear, face-to-face conversation in which one conversation turn typically follows the one before it, an asynchronous message in an online discussion might follow a message written much earlier (branches of messages), forming a message tree. See Fig. 23.1 for an example of relationships among 10 messages. The number “1” denotes the initial message; “2” through “10” indicate 9 reply messages in the order of time.

The tree structure of relationships between a problem and its reply messages
The messages occurred along five discussion threads: (a) 1 → 2 → 4, (b) 1 → 2 → 5 → 9 → 10, (c) 1 → 3 → 6, (d) 1 → 3 → 7, and (e) 1 → 8. Messages in each thread were ordered by time, but they were not necessarily consecutive. In thread (c) for example, message #3 followed message #1 (not #2) and message #6 followed message #3 (not #5). By storing each message’s previous message on its thread in a variable, I can capture the structure of the tree of messages. Then, I change my application of SDA to examine the previous message on a thread, not the most recent message.
Analysis
This section specifies the assumptions underlying the analysis, its purpose, units of interaction, representations of the data, and the analytic manipulations.
Assumptions Underlying the Analysis
Theoretical assumptions. Statistical discourse analysis (SDA, Chiu & Khoo, 2005) has several theoretical assumptions. First, as with any statistics (e.g., count, mean, standard deviation), SDA assumes that instances of a category (e.g., summarize) with the same value (e.g., is vs. is not [coded as 1 vs. 0]) are sufficiently similar to be treated as equivalent for the purpose of this analysis.
This specific study has at least four additional theoretical assumptions. Second, participant-coded message characteristics are sufficiently similar to be treated as equivalent for the purpose of this analysis. Third, aspects of recent messages, participating individuals and time constitute a micro-context in which future messages emerge. Fourth, aspects of recent messages, their authors and the time period can influence later messages. Fifth, residuals reflect attributes related to the dependent variables that are not specified in the theoretical model and not correlated with the explanatory variables.
Methodological assumptions. Like other regressions, SDA assumes a linear combination of explanatory variables (Nonlinear aspects can be modeled as nonlinear functions of variables [e.g., age squared] or interactions among variables [new fact x opinion].) SDA also requires independent residuals and a modest, minimum sample size.
Purpose of Analysis
This analysis has two purposes. First, the revised SDA shows how to model trees of messages rather than linear turns. Second, the revised SDA tests whether variables are linked to greater or reduced likelihoods of cognitive (new information, theory) and social metacognitive (ask for explanation, summary) characteristics of each message.
Units of Interaction That are Taken as Basic in the Analysis
While the unit of analysis is a message, the unit of interaction is a sequence of one type of message following another. The interaction as a whole is characterized by the probabilities of these sequences, which is modeled with SDA.
Representations of Data and Analytic Interpretations
I used the standard representations of a database table, a summary statistics table, and a path diagram. The database table initially had one message per row. Next, I added columns (variables) for coding whether each attribute occurred in each message. Then, I performed statistical analyses to test relationships across this table of vectors, resulting in a summary statistics table and a table of results of regression models (via SDA). To aid reader comprehension, I capitalize on readers’ understanding of spatial relationships to convert the regression results into a path diagram.
Analytic Manipulations
Testing the above hypotheses requires addressing analytic difficulties involving the data set (missing data, branches of messages, topic differences, serial correlation), dependent variables (binary, infrequent, multiple), and explanatory variables (sub-threads of messages, cross-level interactions, indirect effects, false positives) see Table 23.2.
To address these difficulties, a simplified version of statistical discourse analysis (SDA) is used (Chiu, 2008a; Chiu & Khoo, 2005). First, missing data can reduce estimation efficiency, complicate data analyses, and bias results. Computer simulations showed that estimating the missing data with Markov Chain Monte Carlo multiple imputation (MCMC-MI) addressed these missing data issues more effectively than deletion, mean substitution, or simple imputation (Peugh & Enders, 2004). Second, to capture the tree structure of branches of messages, a variable identifies and stores the message to which the current message responds along a thread (in Fig. 23.1 for example, message 4 responds to message 2 [not message 3]), thereby enabling identification of any ordinal predecessor of any message along a thread. Third, messages within the same topic (especially those near one another) likely resemble one another more than messages across topics, so they are likely not independent. Modeling messages across topics requires multilevel analysis (Goldstein, 1995; also known as hierarchical linear modeling, Bryk & Raudenbush, 1992). Fourth, resemblances among adjacent messages can result in serial correlation of errors if not modeled properly (Kennedy, 2008). An I 2 index of Q-statistics can test messages across many topics simultaneously for serial correlation, which can be modeled if needed (Goldstein, Healy, & Rasbash, 1994; Huedo-Medina et al., 2006; Ljung & Box, 1979).
The four dependent variables were binary and infrequent (new fact, ask for explanation, theory, and summarize). To model a binary dependent variable, Logit or Probit is used. When dependent variables occur far less than 50 % of the time, standard regressions will yield biased results. To remove this bias, King and Zeng’s (2001) bias estimator is used. Multiple outcomes can have correlated residuals that underestimate standard errors. To model several dependent variables properly, a multivariate outcome analysis is needed (Goldstein, 1995).
The explanatory variables can include sub-threads of messages, have interactions across levels, yield indirect effects, show false positives, or yield different results during robustness tests. Sub-threads of explanatory variables are modeled with vector auto-regression (VAR, Kennedy, 2008). To model interactions across levels, multilevel random effects are used (Goldstein, 1995). As single-level mediation tests on nested data can bias results downward, multilevel M-tests test for indirect, multilevel mediation effects, in this case, messages within topics (MacKinnon, Lockwood & Williams, 2004). Testing many hypotheses of potential explanatory variables increases the likelihood of a false positive (Type I error). To control for the false discovery rate (FDR), the two-stage linear step-up procedure was used, as it outperformed 13 other methods in computer simulations (Benjamini et al., 2006). To test the robustness of the results, three variations of the core model can be used. First, a single outcome, multilevel model can be run for each dependent variable. Second, subsets of the data (e.g., halves) can be run separately to test the consistency of the results for each subset. Third, the analyses can be repeated with the original data set.
Analysis Procedure
After MCMC-MI estimation of the missing data to yield a complete data set (Peugh & Enders, 2004), the message to which each message responded was identified to store the data set’s tree structure. Then, four process variables in students’ messages (new fact, ask for explanation, theory, and summarize) were simultaneously modeled as follows (Chiu & Khoo, 2005).
For Process ynt (the process variable y [e.g., theorize] for message n in topic t), β y is the grand mean intercept. The unexplained message-level component (or residual) is e nt , and the unexplained topic-level component is f t . As analyzing rare events (these processes occurred in less than 10 % of all messages) with Logit/Probit regressions can bias regression coefficient estimates, King and Zeng’s (2001) bias estimator was used to adjust them.
First, a vector of student demographic variables was entered: male and young (Demographics). Each set of predictors was tested for significance with a nested hypothesis test (χ 2 log likelihood, Kennedy, 2008).
Next, schooling variables were entered: doctoral student, Master’s of Education student, Master’s of Arts student, and part-time student (Schooling). Then, students’ job variables were entered: teacher, post-secondary teacher, and technology (Job). Next, students’ experience variables were entered: Knowledge Forum experience and number of past online courses (Experience).
Then, aspects of the previous message were entered: ask for explanation (-1), ask about use (-1), new fact (-1), theory (-1), summarize (-1), different opinion (-1), elaboration (-1), anecdote (-1), opinion (-1), and any of these supportive processes (-1) (Previous_One). Next, the above aspects of the message two responses ago along the same thread (-2) were entered (Previous_Two). Then, those of the message three responses ago along the same thread (-3) were entered, and so on until none of the explanatory variables in a message along a thread were significant.
Structural variables (Demographics , Schooling , Job , Experience) might show moderation effects, so a random effects model was used. If the regression coefficients of an explanatory variable in the Previous message (e.g., evidence; β ypt = β y0t + f y0j ) differed significantly (f y0j ≠ 0?), then an interaction effect across levels might occur and tested accordingly with multilevel random effects cross-level interaction variables (Goldstein, 1995).
The multilevel M-test captures indirect multilevel, mediation effects (within and across levels, MacKinnon, Lockwood & Williams, 2004). For significant mediators, the percentage change is 1 − (b'/b), where b' and b are the regression coefficients of the explanatory variable, with and without the mediator in the model, respectively. The odds ratio of each variable’s total effect (E = direct effect plus indirect effect) was reported as the increase or decrease (+E% or −E%) in the dependent variable (Kennedy, 2008). As percent increase is not linearly related to standard deviation, scaling is not warranted.
An alpha level of.05 was used. To control for the false discovery rate, the two-stage linear step-up procedure was used (Benjamini et al., 2006). An I 2 index of Q-statistics tested messages across all topics simultaneously for serial correlation, which was modeled if needed (Goldstein et al., 1994; Huedo-Medina et al., 2006; Ljung & Box, 1979).
Sample Size
SDA has modest sample size requirements. Green (1991) proposed the following heuristic sample size, N, for a multiple regression with M explanatory variables and an expected explained variance R 2 of the outcome variable:
For a large model of 20 explanatory variables with a small expected R 2 of 0.10, the required sample size is 91 messages: = 8 × (1 − 0.10)/0.10 + 20 − 1. Less data are needed for a larger expected R 2 or for smaller models. Note that statistical power must be computed at each level of analysis (message, topic, group, class, school … country). With 1,330 messages, statistical power exceeded 0.95 for an effect size of 0.1 at the message level. At the individual level, the sample size (17) is very small, so any individual results must be interpreted cautiously.
Results
Summary Statistics
There were 1,330 messages by 17 students on 13 topics in the study. Students who were older, enrolled in master’s of arts programs, were part-time students, were not teachers, worked in technology fields, or had Knowledge Forum (KF) experience posted more messages on average than other students (older: m = 47 vs. other m = 37 messages; master’s of arts: 64 vs. 36; part-time: 47 vs. 27; not teachers: 55 vs. 36; technology: 54 vs. 39; KF: 44 vs. 32). Students posted few messages with the following attributes (see Table 23.3, panel B): summarize (3 %), theory (4 %), ask for explanation (9 %), new fact (1 %), ask about use (2 %), different opinion (1 %), elaboration (2 %), opinion (5 %), example (1 %). Indeed, most messages (83 %) lacked any of these attributes. As some messages included more than one of these attributes, these percentages do not sum up to 100 %.
Explanatory Model
As none of the topic-level (level 2) variance components were significant, a single-level (message level) analysis was sufficient. All results discussed below describe first entry into the regression, controlling for all previously included variables. Ancillary regressions and statistical tests are available upon request.
H-1: New information. The attributes of previous messages were linked to a new fact in current message. After an opinion, new information was 7 % more likely in the next message. After a question about use (-3) three messages ago, new information was 10 % more likely. Together, these explanatory variables accounted for about 26 % of the variance of new information (see Fig. 23.2).

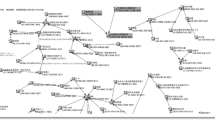
Path diagram of Ask for explanation, Theorize, New information, and Summarize. Solid lines indicate positive links. Dashed lines indicate negative links. Thicker lines indicate larger links. *p < 0.05, **p < 0.01, ***p < 0.001
H-2: Ask for explanation. Students’ gender, educational study and occupation, and discussion process were all significantly linked to asking for an explanation. Men were 24 % more likely than women to ask for an explanation. Meanwhile, students in doctoral programs were 19 % less likely to ask for an explanation. Post secondary teacher and non-post secondary teachers were 1 % and 22 % less likely to ask for an explanation respectively. Controlling for teacher occupation, the gender effect was reduced by 21 %. Demographic and occupation variables accounted for 11 % of the variance in explanation requests.
Attributes of earlier messages were linked to explanation requests. After a question about use, an explanation request was 14 % more likely. After any discussion process, an explanation request was 9 % more likely. After an explanation request (-2) two messages ago, another explanation request was 8 % more likely. Together, these explanatory variables accounted for about 22 % of the variance of an explanation request.
H-3: Theorize. Gender and attributes of previous messages were significantly linked to theorizing. Men were 21 % more likely than women to theorize. Demographics accounted for 5 % of the variance in theorizing.
Attributes of earlier messages up to three messages ago were linked to theorizing. After an explanation (-1) or an elaboration (-1), theorizing was 21 % or 38 % more likely, respectively. If someone asked about the use of an idea (-2), gave an opinion (-2) or gave a different opinion (-2) two messages ago, theorizing was 21 %, 56 %, or 12 % more likely, respectively. After anecdotal evidence (-3) three messages ago, theorizing was 33 % more likely. Altogether, these explanatory variables accounted for 38 % of the variance of theorizing.
H-4: Summarize. Gender, occupation, and attributes of previous messages were linked to summary. Men were 22 % more likely to summarize than women. Meanwhile, teachers or technology workers were 14 % or 1 % less likely to summarize respectively. Controlling for teacher, the link between gender and summary was no longer significant. Demographics accounted for 15 % of the variance in summary.
After any discussion process, a summary was only 1 % more likely. After a new fact (-2) two messages ago however, a summary was 10 % more likely. Together, these explanatory variables accounted for about 22 % of the variance of summaries.
Other variables were not significant and the results did not differ significantly across topics. The I 2 index of Q-statistics for each dependent variable was not significant, indicating no serial correlation. Robustness tests showed similar results.
Discussion
To analyze relationships among asynchronous online messages, I revised SDA to apply to branches of messages. As a result, researchers can use this revised SDA to analyze large data sets of participants’ self-coded online messages, with the potential for semiautomatic analyses through integrated computer programs. Specifically, this analysis showed that both individual characteristics and recent messages’ cognitive and social metacognitive aspects affected the likelihoods of new information, explanation requests, theories, and summaries.
Extending SDA to Online Data
A large data set of 1,330 participant-coded online messages that branch off into multiple threads offers opportunities for multivocality advances in analytic methods in two ways: extending SDA to analyze relationships among messages and taking steps toward semiautomatic analyses. Unlike the linear sequence of turns of talk, Fujita’s data set of online messages often branch out into separate sub-threads. To capture this branching structure, I store each message’s previous message along its thread in a variable. Tracing messages backwards along this variable, I can identify any ordinal predecessor of any message along each thread. Then, I change my application of SDA to examine the previous message on a thread, not the most recent message (according to time). Hence, one benefit of multivocality is improving statistical methods (e.g., SDA) in response to challenging data structures (e.g., nonlinear branches of messages).
As the large data set includes participant-coding of their messages, it offers the potential for semiautomatic analyses that integrate multiple analyses encoded into computer programs. Unlike transcripts of audiotapes or videotapes that must be coded afterwards, the participant coding occurs during the writing of the message and reflects the author’s intention (Fujita, this section). Whether participant coding yields sufficiently similar categories of codes is an open question and a valuable research area. If participant coding is viable in some cases, the codes can be entered into specific computer programs to yield descriptive and temporal analyses, as shown by the other authors in this section (Law & Wong, Chap. 22, this volume; Teplovs & Fujita, Chap. 21, this volume). As the revised SDA algorithm can be encoded into a computer program, it can be integrated with other software [e.g., Teplovs & Fujita’s KISSME in this section; Dyke, Lund, and Girardot’s (2009) TATIANA]. Guided by descriptive statistics and extended social network analyses (KISSME) from this potential integrated software, users can select participant-coded explanatory variables and dependent variables in the SDA portion of the software, which can test the model to show all results and only significant results. As SDA identifies both typical results and exceptions to the model, both types of sub-threads of messages can be further examined (e.g., via TATIANA). Thus, two additional potential benefits of multivocality are (a) understanding and appropriating other analysts’ user interfaces and (b) integration of multiple analyses into a computer program capable of semiautomatic analyses.
Demographics and Occupation
In this specific analysis, the results show the need to examine explanatory variables at the individual level as well as the message level. Past studies of students had shown that individual differences in gender, past achievement and status accounted for little of the variance in discussion behaviors (e.g., Chen & Chiu, 2008; Chiu, 2008b; Lu et al., 2011), but this study showed that individual differences in adults, specifically gender and occupation, accounted for a mean of 10 % of the variance in explanation, theories and summaries. Compared to women, men were more likely to ask for explanations, theorize and summarize. These results are consistent with the research that men are more active than women during online discussions (e.g., Lu, Chiu, & Law, 2011). Compared to gender, job accounted for much more of the differences in explanation requests and summaries. Doctoral students and teachers (especially primary and secondary teachers) were less likely to ask for explanations. Cumulatively, job had the largest effects on explanation requests. Meanwhile, teachers and technology workers were less likely than other students to summarize. Further research can examine the origins of these substantial job differences in online behaviors and on larger data sets.
Micro-time Context of Recent Messages
Beyond the effects of individual characteristics, these results showed that asynchronous messages are more than simply lists of individual cognition (Thomas, 2002); instead, these messages both influence and respond to one another. Specifically, both cognitive and social metacognitive aspects of recent messages showed micro-time context effects.
Informal and formal cognition do not compete; instead, informal cognition preceded formal cognition. Opinions, anecdotes, elaborations and information increased the likelihoods of subsequent information, theories and summaries. After an opinion, new information or theorizing was more likely to follow. Anecdotes and elaborations were also more likely to be followed by theorizing. Together, the last three results are consistent with the view that familiar, informal cognition is activated faster than formal cognition (Chiu, 1996), and that the former can facilitate the latter through spreading activation of related semantic networks both in the individual and among group members (Nijstad et al., 2003).
Social metacognition, in the form of questions and different opinions, affected the likelihood of new information, explanation requests and theories. Questions about use had the largest effect on inducing more information, showing the power of questions to influence other’s behaviors, consistent with earlier research (e.g., Chen, Chiu, & Wang, 2010). Furthermore, both types of questions elicited more explanation requests and theories; the latter is consistent with earlier studies (e.g., Lu et al., 2011). Lastly, a different opinion had the largest effect on a subsequent theory, consistent with face-to-face research showing that disagreements provoke explanations (e.g., Chiu, 2008a).
Conclusion
Showing several benefits of multivocality, this study revised a statistical method designed for linear sequences of turns of talk to apply to branches of messages in asynchronous online discussions, in this case to test for cognitive and social metacognitive relationships among messages. To capture the branching structures of messages, each message’s previous message on along its thread was stored in a variable. Then, changing SDA to examine the previous message on a thread expanded SDA’s scope to analyses of messages in asynchronous online discussions as well as face-to-face talk. Exposure to other authors’ computer programs and displays also suggest opportunities to improve the SDA user-interface and integration of multiple analyses into a computer program capable of semiautomatic analyses.
The results showed that both individual characteristics and the micro-time context of recent messages’ cognition and social metacognition affected the likelihoods of subsequent new facts, explanation requests, theories and summaries. Unlike past studies of students, this study showed that gender and occupation differences in adults account for substantial differences in online behaviors. Specifically, men were more likely than women to ask for explanations, theorize and summarize. Doctoral students and teachers were less likely to ask for explanations, and teachers and technology specialists were less likely to summarize.
Rather than simply being lists of individual cognition, asynchronous messages create a micro-time context that affects subsequent messages. Informal cognition (opinions, anecdotes, elaborations) facilitates formal cognition (facts and theories). Meanwhile, social metacognition, in the form of questions and different opinions, had the strongest effects on subsequent facts and theories. Together, revised SDA and its results offer opportunities to improve understanding of the relationships among online messages, which can help educators and students to improve online discussion processes.
References
Benjamini, Y., Krieger, A. M., & Yekutieli, D. (2006). Adaptive linear step-up procedures that control the false discovery rate. Biometrika, 93, 491–507.
Bryk, A. S., & Raudenbush, S. W. (1992). Hierarchical linear models. London: Sage.
Chen, G., & Chiu, M. M. (2008). Online discussion processes. Computers & Education, 50(3), 678–692.
Chen, G., Chiu, M. M., & Wang, Z. (2010). Group micro-creativity in online discussions. In K. Gomez, L. Lyons, & J. Radinsky (Eds.), Proceedings of the 9th International Conference of the Learning Sciences (Vol. 1, pp. 357–364). Chicago, IL: International Society of the Learning Sciences.
Chiu, M. M. (1996). Exploring the origins, uses and interactions of student intuitions. Journal for Research in Mathematics Education, 27(4), 478–504.
Chiu, M. M. (2000a). Group problem solving processes: Social interactions and individual actions. Journal for the Theory of Social Behavior, 30(1), 27–50.
Chiu, M. M. (2000b). Status effects on solutions, leadership, and evaluations during group problem solving. Sociology of Education, 73(3), 175–195.
Chiu, M. M. (2001). Analyzing group work processes. In F. Columbus (Ed.), Advances in psychology research (Vol. 4, pp. 193–222). Huntington, NY: Nova Science.
Chiu, M. M. (2008a). Effects of argumentation on group micro-creativity. Contemporary Educational Psychology, 33, 382–402.
Chiu, M. M. (2008b). Flowing toward correct contributions during group problem solving: A statistical discourse analysis. Journal of the Learning Sciences, 17(3), 415–463.
Chiu, M. M., & Khoo, L. (2003). Rudeness and status effects during group problem solving. Journal of Educational Psychology, 95, 506–523.
Chiu, M. M., & Khoo, L. (2005). A new method for analyzing sequential processes. Small Group Research, 36, 1–32.
Chiu, M. M., & Kuo, S. W. (2009). From metacognition to social metacognition. Journal of Education Research, 3(4), 1–19.
Clark, D. B., & Sampson, V. (2008). Assessing dialogic argumentation in online environments to relate structure, grounds, and conceptual quality. Journal of Research in Science Teaching, 45(3), 293–321.
Dubrovsky, V. J., Kiesler, S. B., & Sethna, B. N. (1991). The equalization phenomenon. Human-Computer Interaction, 6, 119–146.
Dyke, G., Lund, K., Girardot, J.-J. (2009). Tatiana: an environment to support the CSCL analysis process. CSCL 2009, Rhodes, Greece.
Fujita, N. (this volume). Online graduate education course using knowledge forum. In D. D. Suthers, K. Lund, C. P. Rosé, C. Teplovs & N. Law (Eds.), Productive multivocality in the analysis of group interactions, Chapter 20. New York, NY: Springer.
Glassner, A., Weinstoc, M., & Neuman, Y. (2005). Pupils’ evaluation and generation of evidence and explanation in argumentation. British Journal of Educational Psychology, 75, 105–118.
Goldstein, H. (1995). Multilevel statistical models. Sydney: Edward Arnold.
Goldstein, H., Healy, M., & Rasbash, J. (1994). Multilevel models with applications to repeated measures data. Statistics in Medicine, 13, 1643–1655.
Gress, C. L. Z., Fior, M., Hadwin, A. F., & Winne, P. H. (2010). Measurement and assessment in computer-supported collaborative learning. Computers in Human Behavior, 26, 806–814.
Gunawardena, C. N., Lowe, C. A., & Anderson, T. (1997). Analysis of a global online debate and the development of an interaction analysis model for examining social construction of knowledge in computer conferencing. Journal of Educational Computing Research, 17(4), 397–431.
Hacker, D. J., & Bol, L. (2004). Metacognitive theory. In D. M. McInerney & S. Van Etten (Eds.), Big theories revisited (Vol. 4, pp. 275–297). Greenwich, CO: Information Age.
Hakkarainen, K. (2003). Emergence of progressive-inquiry culture in computer-supported collaborative learning. Learning Environments Research, 6(2), 199–220.
Hara, N., Bonk, C. J., & Angeli, C. (2000). Content analysis of online discussion in an applied educational psychology course. Instructional Science, 28, 115–152.
Harasim, L. M. (1993). Global networks. Cambridge, MA: MIT Press.
Howe, C. (2009). Collaborative group work in middle childhood. Human Development, 52(4), 215–239.
Huedo-Medina, T. B., Sanchez-Meca, J., Marin-Martinez, F., & Botella, J. (2006). Assessing heterogeneity in meta-analysis. Psychological Methods, 11, 193–206.
Jeong, A. (2003). The sequential analysis of group interaction and critical thinking in online threaded discussions. American Journal of Distance Education, 17, 25–43. Jeong, A. (2006). The effects of conversational language on group interaction and group performance in computer-supported collaborative argumentation. Instructional Science, 34(5), 367–397.
Kennedy, P. (2008). Guide to econometrics. Cambridge: Wiley-Blackwell.
King, G., & Zeng, L. (2001). Logistic regression in rare events data. Political Analysis, 9, 137–163.
Law, N., & Wong, O.-W. (this volume). Exploring pivotal moments in students’ knowledge building progress using participation and discourse marker indicators as heuristic guides. In D. D. Suthers, K. Lund, C. P. Rosé, C. Teplovs & N. Law (Eds.), Productive Multivocality in the Analysis of Group Interactions, Chapter 22. New York, NY: Springer.
Ljung, G., & Box, G. (1979). On a measure of lack of fit in time series models. Biometrika, 66, 265–270.
Lu, J., Chiu, M., & Law, N. (2011). Collaborative argumentation and justifications: A statistical discourse analysis of online discussions. Computers in Human Behavior, 27, 946–955.
Luppicini, R. (2007). Review of computer mediated communication research for education. Instructional Science, 35(2), 141–185.
MacKinnon, D. P., Lockwood, C. M., & Williams, J. (2004). Confidence limits for the indirect effect: Distribution of the product and resampling methods. Multivariate Behavioral Research, 39, 99–128. Nijstad, B. A., Diehl, M., & Stroebe, W. (2003). Cognitive stimulation and interference in idea generating groups. In P. B. Paulus & B. A. Nijstad (Eds.), Group creativity: Innovation through collaboration (pp. 137–159). New York, NY: Oxford University Press.
Peugh, J. L., & Enders, C. K. (2004). Missing data in educational research. Review of Educational Research, 74, 525–556.
Piaget, J. (1985). Equilibration of cognitive structures. Chicago: University of Chicago Press.
Tallent-Runnels, M. K., Thomas, J. A., Lan, W. Y., Cooper, S., Ahern, T. C., Shaw, S. M., et al. (2006). Teaching courses online. Review of Educational Research, 76(1), 93–135.
Teplovs, C., & Fujita, N. (this volume). Socio-dynamic latent semantic learner models. In D. D. Suthers, K. Lund, C. P. Rosé, C. Teplovs & N. Law (Eds.), Productive multivocality in the analysis of group interactions, Chapter 21. New York, NY: Springer.
Thomas, M. J. W. (2002). Learning within incoherent structures: The space of online discussion forums. Journal of Computer Assisted Learning, 18, 351–366.
Vygotsky, L. (1986). Thought and language. (A. Kozulin, Trans.). Cambridge, MA: MIT Press. (original work published 1934).
Wise, A., & Chiu, M. M. (2011). Analyzing temporal patterns of knowledge construction in a role-based online discussion. International Journal of Computer-Supported Collaborative Learning, 6, 445–470.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer Science+Business Media New York
About this chapter
Cite this chapter
Chiu, M.M. (2013). Statistical Discourse Analysis of an Online Discussion: Cognition and Social Metacognition. In: Suthers, D., Lund, K., Rosé, C., Teplovs, C., Law, N. (eds) Productive Multivocality in the Analysis of Group Interactions. Computer-Supported Collaborative Learning Series, vol 15. Springer, Boston, MA. https://doi.org/10.1007/978-1-4614-8960-3_23
Download citation
DOI: https://doi.org/10.1007/978-1-4614-8960-3_23
Published:
Publisher Name: Springer, Boston, MA
Print ISBN: 978-1-4614-8959-7
Online ISBN: 978-1-4614-8960-3
eBook Packages: Humanities, Social Sciences and LawEducation (R0)