
Abstract
In the information age, the ability to analyze data has a fundamental role. In this field, recommender systems, that are able to provide suggests to users analyzing the information provided to system, play a central role. Moreover, the use of contextual information make recommender systems more reliable. This paper aims to describe a novel approach for context-aware recommender systems that exploits the tensor decomposition CANDECOMP properties in order to provide ratings forecasts. The proposed approach is tested on DePaulMovie dataset in order to evaluate its accuracy, and the numerical results are promising.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In the big data [14] era, the ability to select information is fundamental. This achievement is not simple among all data available for a system. Indeed, the number of collected data is enormous. In this field, one of the most important tools able to support users is recommender system (RS) [7, 11, 13].
Recommender systems (RSs) are information filtering tools that give support to users in order to select among all available items [25]. They are able to select the right information about users preferences and items features in order to provide an estimation that allows to classify items between useful or not for users.
The elements of RSs are users of the system, items that have to be suggested and transaction [25], that represent the interaction between a user and the system. The most common transaction form is rating, an implicit or explicit evaluation of the user preference about an item [25]. Moreover, rating can be seen as a function that has as domain the Cartesian product of users set U and items set I.
The principal problem of RSs is to determinate \(r_{ui} = r \left( u,i \right) \) \(\forall \left( u,i \right) \in U\times I\). The mode to achieve rating forecast enables to classify RSs based on the different strategies.
The most common recommendation strategies are content-based, collaborative filtering and hybrid [6].
Content-based RSs [12, 23] are based on the creation of users and items profiles. These profiles are exploited in order to obtain user-item affinity. The most common form exploited to calculate user-item affinity is cosine similarity [17].
Collaborative filtering RSs [31] are based on known ratings provided by users and can be divided in two different classes: memory-based and model-based. Memory-based ones aim to divide users (user-based) or items (item-based) into groups [24]. Model-based ones aim to create a numerical model of the problem through the factorization of ratings matrix [25].
Hybrid RSs exploits the principal features of the previous methods in order to overcome the problems of the single method [10].
The development of RSs brought to the introduction of new elements in order to improve provided rating forecasts. Context [2, 16] is one of these elements and allows to obtain context-aware recommender systems [9]. The awareness of context is exploited in order to obtain more appropriate rating forecasts.
Context can be defined as “any information useful to characterize the situation of an entity that can affect the way users interact with systems” [1, 30] and allows to define a new rating function that has as domain the Cartesian product of users set U, items set I and the contextual sets \(C_1,\dots ,C_n\) that contain the contextual information analyzed by the system.
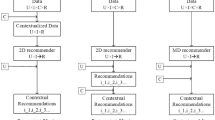
The introduction of context in a recommender system is possible through three different strategies [2, 10]:
-
Contextual Pre-Filtering: the contextual information is analyzed before the recommendation phase in order to select the proper elements to provide to recommender system;
-
Contextual Post-Filtering: the contextual information is exploited in order to select the proper rating forecasts provided by the recommendation phase;
-
Contextual Modeling: contextual information are exploited in the recommendation phase in order to generate appropriate rating forecasts.

Strategies for introducing contextual information into a recommender system [2]
Figure 1 presents a summary of the described strategies.
The aim of this paper is the description of a novel context-aware recommendation approach. The paper is organized as follows: Sect. 2 contains background and related works; in Sect. 3 the proposed approach is described, Sect. 4 presents the experimental phase exploited to evaluate the method described in Section 3; in Sect. 5 there are conclusions and future works.
2 Background and Related Works
In the recommender systems field, there is a great variety of strategies that are exploited in order to obtain rating forecasts.
Content-based methods can exploit term frequency and inverse document frequency in order to create profiles [22, 28]. Another technique exploited in content-based recommendation is Latent Dirichlet Allocation [28].
In memory-based recommendation, the clustering of users or items can be obtained through Pearson correlation [18] or through K-nearest neighbors algorithm [29]. In model-based recommendation, there are various factorization methods exploited such as probabilistic matrix factorization (PMF), non-negative matrix factorization (NMF) and singular value decomposition (SVD) [8]. In particular, singular value decomposition allows to factorize the ratings matrix \(R \in \mathbb {R}^{m \times n}\) that refers to a system of m users and n items, in the product of three matrices: the matrices \(U \in \mathbb {R}^{m \times m}\) and \(V \in \mathbb {R}^{n \times n}\) defined matrices of left and right singular vectors, and the matrix \(D = \text{ diag } \left( \sigma _1,\dots ,\sigma _p \right) \in \mathbb {R}^{m \times n}\) defined matrix of the singular values, where \(p=\min \{m,n\}\).
Fixed the value \(k \in \mathbb {N} \text{: } k \le p\), the Eckart-Young Theorem [12] allows to approximate the rating matrix through the matrices \(U_k \in \mathbb {R}^{m \times k}\) obtained from U, \(V_k \in \mathbb {R}^{n \times k}\) obtained from V, and \(D_k \in \mathbb {R}^{k \times k}\) obtained from D.
The Eckart-Young Theorem guarantees that the matrix \( R_k = U_k D_k V_k^T\) is the matrix of rank k that best approximates the ratings matrix R [12].
Matrix factorization is also exploited by context-aware RSs. Indeed, Baltrunas et al. [4] developed context-aware matrix factorization (CAMF), a contextual modeling method that support the matrix factorization with bias related to contextual information. Instead, splitting approaches [10, 32] are pre-filtering methods that select the proper row or columns of the ratings matrix and generate rating forecasts through the matrix factorization. These approaches divide the known rating in the specific context. Thus, there are more rows of rating matrix referred to the user \(u \in U\) (user splitting) or more columns of rating matrix referred to the item \(i \in I\) (item splitting) on the basis of the contextual information.
The Tensor factorization [21] is also exploited by context-aware RSs. Karatzoglou et al. [20] exploit high-order singular value decomposition (HOSVD) [3] in order to generate rating forecasts through a machine learning algorithm. Instead, Chen et al. [15] propose a multi-criteria recommender system that exploits stacked denoising autoencoder and CANDECOMP. In particular, canonical decomposition (CANDECOMP) allows to factorize tensor \(\mathcal {R} \in \mathbb {R}^{m \times n \times l}\) through the sum of s rank-1 tensors [21]:
where \(A \in \mathbb {R}^{m \times s}\), \(B \in \mathbb {R}^{n \times s}\) and \(C \in \mathbb {R}^{l \times s}\) are matrices with columns of unitary norm and \(\lambda = \left( \lambda _1,\dots ,\lambda _s\right) \in \mathbb {R}^s\) (Fig. 2).

Graphical representation of CANDECOMP [21]
The CANDECOMP is exploited in Sect. 3 in order to describe a novel approach for Context-Aware Recommender Systems.
3 The Proposed Approach
In this section, the proposed approach is described. It consists of an heuristic method that exploits CANDECOMP and SVD properties in order to generate rating forecasts.
The system is supposed to have m users, n items and one contextual dimension that can assume l values. Thus, the ratings tensor \(\mathcal {R} \in \mathbb {R}^{m \times n \times l}\) has three dimensions. Instead, the matrix \(R \in \mathbb {R}^{m \times n}\) contains the ratings without context and can be given by dataset. If the dataset does not provide known ratings without context, they can be calculated through the average of all l contextual domains.
Firstly, the singular value decomposition role is evaluated. The relation (4) allows to approximate the known rating. Indeed, the product of matrices \( P = U_k \sqrt{D_k} \in \mathbb {R}^{m \times k}\) and \(Q = V_k \sqrt{D_k} \in \mathbb {R}^{n \times k}\) approximates the rating matrix:
The relation (6) is made explicit trough the relation (7) where \(p_{ih} = {\left( U_k\right) }_{ih} \sqrt{\sigma _h}\) and \(q_{jh} = {\left( V_k\right) }_{jh} \sqrt{\sigma _h}\).
P and Q are matrices that create fake numerical profiles of users and items, respectively. The objective of the proposed approach is the construction of ratings forecasts through the calculation of the fake numerical profile of the l contextual dimensions. In order to achieve this purpose, the contextual dimension \(z \in \{1,\dots ,l \}\) is fixed, and the following hypothesis are done:
-
the values k of relation (4) and s of relation (5) coincide;
-
the matrix A of relation (5) is equal to \(U_k\) of relation (6);
-
the matrix B of relation (5) is equal to \(V_K\) of relation (6).
-
The relation \(\lambda _h = \sigma _h \times \gamma _h h=1,\ldots ,k\) is supposed valid, where \(\gamma _h > 0 h=1,\ldots ,k\)
The done hypothesis can be integrated in the relation (5).
The matrix \(W \in \mathbb {R}^{l \times k}\) has the elements \( W_{zh} = \gamma _h C_{zh}\) \(h=1,\dots ,k z = 1,\dots ,l\). Thus, the previous relation can be reformulated as follows:
Let the element \(t \in \{1,\dots ,k\}\) fixed, the weighted average on items can be done as follows:
Thus, the weighted average on users can be done:
In order to simplify the relation (11), the following quantities are defined:
The relations (12) and (13) allow to reformulate the relation (11) as follows:
The relation (14) consists of a linear system that allows to determinate the fake numerical profile \(\left( W_{z1},\dots ,W_{zk}\right) \) of the context dimension z. The resolution of all the l linear systems allows to identify the elements of the matrix \(W \in \mathbb {R}^{l \times k}\).
In the operative phase, the averages calculated are done on the known ratings in the system.
Finally, in order to improve the rating forecasts, contextual bias are exploited. Indeed, the rating forecasts are calculated as follows:
where \(\bar{r}_z\) is the average of all known ratings in the context z, \(b_{iz}\) is the user i bias in the context z, \(b_{jz}\) is the item j bias in the context z and \(\sum _{h=1}^k P_{ih} Q_{jh} W_{zh}\) is seen as the affinity of user i and item j in the context z.
The principal advantage of the proposed approach is the possibility to calculate the context profiles in order to support the collaborative filtering recommendation method with a content-based one. Indeed, a hybrid recommendation method can be developed through a proper initialization of users and items profiles. The disadvantage of the proposed method is the need of known rating in order to calculate the context profiles.
4 Experimental Phase
In this section, the experimental phase is described. The numerical results are obtained through the dataset DePaulMovie [19, 33] that contains 5043 known ratings collected on 97 users, 79 items and 3 context dimensions. The 5043 ratings are divided in 1448 ratings without context and 3595 contextual ratings.
The contextual information exploited by the dataset are location that can assume the values home and cinema, companion that can assume the values alone, family and friends, and time that can assume the values weekend and weekday. Since the proposed approach is defined on one contextual dimension, the three contextual domain of DePaulMovie are taken into account as shown in Table 1. Indeed, the value of l is 12, the value of m is 97 and the value of n is 79.
The aim of the experimental phase is the evaluation of the proposed approach accuracy. In order to achieve this aim, mean absolute error (MAE) and root mean squared error (RMSE) are calculated according to the following formulas:
where D is the dataset that contains the contextual ratings, \(\mathcal {R}_{ijz}\) is the known rating in the dataset D and \(\hat{\mathcal {R}}_{ijz}\) is the rating forecast provided by the context-aware recommender system. Moreover, the cross-validation fivefold [26] technique is exploited.
The results of the comparison methods are taken from CarsKit [33]. In Table 2 the numerical results are presented.
Table 2 proves that the proposed approach returns better results than the comparison methods.
5 Conclusions and Future Works
In this paper, a focus on recommender systems and context-aware recommender systems is done. In particular, the singular value decomposition and CANDECOMP are presented in Sect. 2, and they are exploited in Sect. 3 in order to present an heuristic context-aware recommender system. Finally, the numerical results are shown in Sect. 4. The experimental phase evidences that the proposed approach return better results than the comparison methods.
In order to improve the proposed approach, some improvements can be exploited. Since all items and users has the some contextual profile, a neighbor method will be exploited in order to divide items that improve their ratings in the contextual dimension and items that get worse their ratings in the contextual dimension. Moreover, others dataset is going to be exploited in order to confirm the goodness of the proposed approach.
Finally, a proper method in order to create users and items profiles is going to be developed in order to obtain an hybrid approach that enables the system to overcome the cold star problem related to lack of known ratings.
References
Abowd GD, Dey AK, Brown PJ, Davies N, Smith M, Steggles P (1999) Towards a better understanding of context and context-awareness. In: International symposium on handheld and ubiquitous computing. Springer, pp 304–307
Adomavicius G, Tuzhilin A (2011) Context-aware recommender systems. In: Recommender systems handbook. Springer, pp 217–253
Ballester-Ripoll R, Lindstrom P, Pajarola R (2019) Tthresh: tensor compression for multidimensional visual data. IEEE Trans Vis Comput Graph 26(9):2891–2903
Baltrunas L, Ludwig B, Ricci F (2011) Matrix factorization techniques for context aware recommendation. In: Proceedings of the fifth ACM conference on recommender systems, pp 301–304
Baltrunas L, Ricci F (2009) Context-based splitting of item ratings in collaborative filtering. In: Proceedings of the third ACM conference on recommender systems, pp 245–248
Batmaz Z, Yurekli A, Bilge A, Kaleli C (2019) A review on deep learning for recommender systems: challenges and remedies. Artif Intell Rev 52(1):1–37
Bobadilla J, Ortega F, Hernando A, Gutiérrez A (2013) Recommender systems survey. Knowl-Based Syst 46:109–132
Bokde D, Girase S, Mukhopadhyay D (2015) Matrix factorization model in collaborative filtering algorithms: a survey. Procedia Comput Sci 49:136–146
Carbone M, Colace F, Lombardi M, Marongiu F, Santaniello D, Valentino C (2021) An adaptive learning path builder based on a context aware recommender system. In: 2021 IEEE frontiers in education conference (FIE). IEEE, pp 1–5
Casillo M, Colace F, Conte D, Lombardi M, Santaniello D, Valentino C (2021) Context-aware recommender systems and cultural heritage: a survey. J Amb Intell Humanized Comput, pp 1–19
Casillo M, Colace F, De Santo M, Lombardi M, Mosca R, Santaniello D (2020) A recommender system for enhancing coastal tourism. In: The international research & innovation forum. Springer, pp 113–122
Casillo M, Conte D, Lombardi M, Santaniello D, Troiano A, Valentino C (2022) A content-based recommender system for hidden cultural heritage sites enhancing. In: Proceedings of sixth international congress on information and communication technology. Springer, pp 97–109
Casillo M, De Santo M, Lombardi M, Mosca R, Santaniello D, Valentino C (2021) Recommender systems and digital storytelling to enhance tourism experience in cultural heritage sites. In: 2021 IEEE international conference on smart computing (SMARTCOMP). IEEE, pp 323–328
Chen R, Hua Q, Chang Y-S, Wang B, Zhang L, Kong X (2018) A survey of collaborative filtering-based recommender systems: from traditional methods to hybrid methods based on social networks. IEEE Access 6:64301–64320
Chen Z, Gai S, Wang D (2019) Deep tensor factorization for multi-criteria recommender systems. In: 2019 IEEE international conference on big data (big data). IEEE, pp 1046–1051
Colace F, De Santo M, Lombardi M, Mosca R, Santaniello D (2020) A multilayer approach for recommending contextual learning paths. J Internet Serv Inf Secur 10(2):91–102
De Gemmis M, Lops P, Musto C, Narducci F, Semeraro G (2015) Semantics-aware content-based recommender systems. In: Recommender systems handbook. Springer, pp 119–159
Desrosiers C, Karypis G (2011) A comprehensive survey of neighborhood-based recommendation methods. Recommender systems handbook, pp 107–144
Ilarri S, Trillo-Lado R, Hermoso R (2018) Datasets for context-aware recommender systems: Current context and possible directions. In: 2018 IEEE 34th international conference on data engineering workshops (ICDEW). IEEE, pp 25–28
Karatzoglou A, Amatriain X, Baltrunas L, Oliver N (2010) Multiverse recommendation: n-dimensional tensor factorization for context-aware collaborative filtering. In: Proceedings of the fourth ACM conference on recommender systems, pp 79–86
Kolda TG, Bader BW (2009) Tensor decompositions and applications. SIAM Rev 51(3):455–500
Lops P, De Gemmis M, Semeraro G (2011) Content-based recommender systems: State of the art and trends. Recommender systems handbook, pages 73–105
Mohamed MH, Khafagy MH, Ibrahim MH (2019) Recommender systems challenges and solutions survey. In: 2019 international conference on innovative trends in computer engineering (ITCE), . IEEE, pp 149–155
Ning X, Desrosiers C, Karypis G (2015) A comprehensive survey of neighborhood-based recommendation methods. Recommender systems handbook, pp 37–76
Ricci F, Rokach L, Shapira B (2015) Recommender systems: introduction and challenges. In: Recommender systems handbook. Springer, pp 1–34
Rodriguez JD, Perez A, Lozano JA (2009) Sensitivity analysis of k-fold cross validation in prediction error estimation. IEEE Trans Pattern Anal Mach Intell 32(3):569–575
Said A, De Luca EW, Albayrak S (2011) Inferring contextual user profiles-improving recommender performance. In: Proceedings of the 3rd RecSys workshop on context-aware recommender systems
Somasundaram K, Murphy GC (2012) Automatic categorization of bug reports using latent dirichlet allocation. In: Proceedings of the 5th India software engineering conference, pp 125–130
Subramaniyaswamy V, Logesh R (2017) Adaptive KNN based recommender system through mining of user preferences. Wirel Person Commun 97(2):2229–2247
Villegas NM, Sánchez C, Díaz-Cely J, Tamura G (2018) Characterizing context-aware recommender systems: a systematic literature review. Knowledge-based systems 140:173–200
Wang X, He X, Wang M, Feng F, Chua T-S (2019) Neural graph collaborative filtering. In: Proceedings of the 42nd international ACM SIGIR conference on research and development in information retrieval, pp 165–174
Zheng Y, Burke R, Mobasher B (2014) Splitting approaches for context-aware recommendation: An empirical study. In: Proceedings of the 29th annual ACM symposium on applied computing, pp 274–279
Zheng Y, Mobasher B, Burke R (2015) Carskit: A java-based context-aware recommendation engine. In: 2015 IEEE international conference on data mining workshop (ICDMW). IEEE, pp 1668–1671
Zheng Y, Mobasher B, Burke RD (2013) The role of emotions in context-aware recommendation. Decisions@ RecSys, 21–28
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Colace, F., Conte, D., Gupta, B., Santaniello, D., Troiano, A., Valentino, C. (2023). A Novel Context-Aware Recommendation Approach Based on Tensor Decomposition. In: Yang, XS., Sherratt, S., Dey, N., Joshi, A. (eds) Proceedings of Seventh International Congress on Information and Communication Technology. Lecture Notes in Networks and Systems, vol 448. Springer, Singapore. https://doi.org/10.1007/978-981-19-1610-6_39
Download citation
DOI: https://doi.org/10.1007/978-981-19-1610-6_39
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-19-1609-0
Online ISBN: 978-981-19-1610-6
eBook Packages: EngineeringEngineering (R0)