
Abstract
Ongoing advancements in the improvement of multilayer convolutional neural organizations have brought about upgrades in the precision of important recognition jobs, for example, huge category picture classification and cutting-edge automated recognition of speech. Custom hardware accelerators are crucial in improving their performance, given the large computational demands of Convolution Neural Networks (CNN). The Field-Programmable Gate Arrays (FPGAs) reconfigurability, computational abilities, and high energy efficacy makes it a propitious CNN hardware acceleration tool. CNN have demonstrated their value in picture identification and recognition applications; nonetheless, they require high CPU use and memory transmission capacity tasks that cause general CPUs to neglect to accomplish wanted execution levels. Consequently, to increase the throughput of CNNs, hardware accelerators using Application-Specific Integrated Circuits (ASICs), FPGAs, and Graphic Processing Units (GPUs) have been employed to improve CNN performance. To bring out their synonymity and dissimilarity, we group the works into many groups. Thus, it is anticipated that this review will lead to the upcoming development of successful hardware accelerators and be beneficial to researchers in deep learning.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In the past decade, artificial intelligence (AI) and machine learning (ML) instruments have gained considerable prominence due to advancements in computational structure which consists of area, power, and effectiveness. A range of programs have started using AI algorithms to improve overall efficiency than conventional methods. These applications include image processing [1], for example, face identification, banking and statistical surveying [2], mechanical arms in the robotized producing area [3], medical services applications [4], database administration and management [5], and face checking and investigation security applications [6].
The explosive development of big data over the past decade has inspired revolutionary approaches to obtain data from various sensors such as photos and voice samples. In reality, these Convolution Neural Networks (CNNs) [7] now are conceived as the standard method among the proposed methods by delivering “human-like” accuracy in various computer vision-related applications, such as classification [8], detection, segmentation [9], and speech recognition [10].
As CNNs need up to 38 GOP/s to identify a single frame [11], this output is obtained at the expense of a high computational price. Hence, to accelerate their execution, dedicated hardware is required. The most frequently used platform for implementing CNNs is Graphics Processing Units (GPUs), as they provide the highest performance with respect to computational throughput, hitting 11 TFLOP/s [12].
Nonetheless, FPGA systems are considered to be better energy efficient in terms of power consumption (vs GPUs). Thereby, several FPGA-based CNN accelerators were suggested, targeting both data centers for High Performance Computing (HPC) [13] and embedded applications [14].
Although GPU implementations have shown exceptional computational efficiency, for two reasons, CNN acceleration is heading momentarily towards FPGAs. First, recent advances in FPGA technology have brought about FPGA performance with a recorded performance of 9.2 TFLOP/s for the latter in striking distance to GPUs. Second, recent CNN production patterns are increasing the sparsity of CNNs and using extremely compact types of data.
The remaining paper is structured in the following way: Literature Review, summarizing the use of AI algorithms in the past decade. Explanation of CNN and challenges of FPGA-based implementation. A detailed analysis of FPGA, GPU, and ASIC-based implementation of AI networks which compares between the power, area performance, and efficiency parameters. Finally, we look into the optimizations available and scope of future research.
2 Literature Review
Lately, the application of AI algorithm as a replacement of conventional algorithms have become popular. With the advent of ML and AI, there is a worry to basically address computational cost and power-burning through AI calculations. This leads to the necessity for particular equipment with high capacity to perform AI estimations with large scope issues [15]. The aim of all the research is to achieve better and more capable handling of AI algorithmic calculations. Numerous researches have been conducted over the span of the latest decade discussing hardware and programming advancements and execution strategies in this field [1, 16,17,18,19,20,21].
Here in Table 1, we discuss corresponding survey articles published roughly between 2009 and 2019 on the implementation of AI algorithms, more precisely neural nets for hardware. Few studies have covered hardware implementations of artificial neural networks [16, 19, 20]. While other studies have centered on FPGA-based deep learning neural network accelerators [1, 17, 18]. In [19], the FPGA implementation of coevolutionary neural networks was the subject of the authors (CNNs). The survey addressed GPU implementations in [21].
This examination distinguishes and addresses various papers. These papers were evaluated as per the hardware used. The bulk of the documents include FPGA-based implementations. With its high adaptability and solidness, the FPGA is viewed as a promising option for the use of these calculations. Likewise, recent FPGA design improvements have brought about making it more accessible because of which profound learning research has procured significant consideration [23].
One of the powerful “application-specific integrated circuit” (ASICs) is also used for AI algorithm implementation. ASICs are personalized chips that are conceived for a particular purpose. They save high-power and are speed-efficient, consume less silicon area, making them ideal solutions for accelerating AI algorithms [24]. To accelerate AI algorithms, graphical processing units (GPUs) are also used to pace up algorithms to hundreds of times the initial speed [25]. GPUs are made to carry out scalar and parallel intensive computing [26]. Unlike multicore CPUs, when accessing DRAM memories, GPUs try not to depend on shrouded latencies utilizing large cache memories [27]. Such highlights have made GPUs increasingly more useful for AI acceleration.
Using small single-board processors, some AI algorithms are applied. For example, raspberry pi. As a result of their little size and low force prerequisites, single-board PCs are viewed as a decision for AI usage.
3 Overview of CNN
One of the classic profound learning networks is the deep convolutional neural network. They are widely used in these areas for the continued development of deep learning technologies, machine vision, and language recognition [28]. Earlier studies have indicated that the calculation of the cutting-edge CNNs is overwhelmed by the convolutional layers [29, 30] formation.
It contains numerous falling layers, pooled layers, and fully-connected complex layers. The convolutionary neural network distinguishes the image as the input, and obtains the outcome across several “convolutional layers, pooling layers and associated layers.”
3.1 Model of Convolutional Layer
The input fin and convolution kernel composed of weights wij, comprises the convolution layer. The sampled function is set by balancing results to get the output fout. [30].
3.2 Model of Pooling Layer
The pooling layer typically uses the maximum scan or core scan to minimize the size of the input matrix. The activity will viably lessen the following layer’s data processing ability while forestalling the loss of characteristic information.
3.3 Full Connection Layer
The layer changes over the input to straight space, hence, changing over the input to a direct space. Output is received.
3.4 Activation Layer
A nonlinear change of the input is presented by the activation function excitation, and the output after each layer is regularly handled. Some common functions include nonlinear (Relu), trigonometric function (Tanh), shock response (Sigmod), etc.
4 Challenges in FPGA
4.1 Tradeoff Between RTL and HLS Approaches
Via high-level abstractions, the HLS-based design approach enables fast growth. This demonstrates the conventional plan utilizing the OpenCL-based methodology [31]. Key features including partitioning, automatic pipelining of the CNN model, etc., can also be supported but for HW performance, however, the resulting design cannot be optimized.
4.2 Necessity of Diligent Design
Considering the particular characteristics of both FPGAs and Convolutional Neural Net, the optimization of throughput demands careful design. In general, two architectures for the same use of resources may have significantly different performances [30],and thus, the use of resources may not be a reliable overall performance measure. There are vastly different criteria for separate CNN layers. In addition, the use of FPGA relies heavily on the burst duration of memory access [32], so the access pattern of CNN memory must be cautiously configured. Furthermore, the compute-throughput ought to be adjusted with the memory or the memory can end up being the bottleneck [19].
4.3 FPGAs Over GPUs/ASICs/CPUs
Although the computer software environments are already mature for developing convolutional Neural Net designs for CPUs or GPUs, those for FPGAs are even now nascent. Furthermore, despite the HLS software, it can take several months for an experienced HW designer to implement the CNN model on FPGAs [33]. Therefore, in general, modeling efforts for GPUs is quite less when compared to FPGAs. Accounting for rapid changes growth related to neural nets, it may not be feasible to re-architect accelerators based on FPGA with every upcoming neural net algorithm. Therefore, the most recent NN algorithm cannot efficiently model an FPGA-based architecture. In addition, a Field-Programmable Gate Array (FPGA) modeling demands greater resource overhead than an ASIC design because of reconfiguration of logic blocks and switches. These factors give these custom boards a competitive disadvantage over other HW acceleration computing platforms for NNs.
4.4 A Comparative Study Between FPGA, ASIC, and GPU
Here, we bring the execution technique, GPUs/FPGAs/ASICs, in relation to regular merit figures. A distinction between the three methods is seen in Table 2. Since the ASIC specification is unaltered post-production, it becomes unsuitable for application where subsequent to installation, the model needs to be revised. ASIC is better used where low power and area are the goal. In comparison to ASICs, FPGAs are available for post-implementation upgrades. It is worth mentioning that even though the ultimate objective is ASIC execution, FPGAs are also used for prototyping and validation [22].
GPUs provide a solution at the software level, while FPGAs and ASICs have a solution at the hardware level. FPGAs and ASICs thus have greater stability compared to GPUs during the deployment process. As a result, the implementation of the GPU is constrained by the current underlying hardware. Thus, in some situations, FPGAs can be quicker than GPUs.
5 A Compendium of Numerous Hardware Implementations
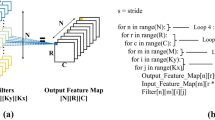
Implementation details of neural nets on various FPGA boards are shown in Table 3. Loop optimizations were first investigated in [30] to extract an FPGA-based CNN accelerator. This design was modeled utilizing HLS tools, therefore, it relies on the arithmetic of 32 floating points. Works in [34, 35] pursue the same unrolling scheme. In addition, [35] design has 16 bits of fixed-point arithmetic and RTL design, which results in an increase of performance by approximately two times. In recent works [36], the same unrolling and tiling scheme is used where authors report an improvement of x13.4 over their original works [30]. Consequently, unrolling and tiling loops can be proficient as it were for devices with large computational capabilities (i.e., DSP). This is often illustrated in works of Rahman et al. [34] which improves speed by 1.2 times over [30].
Conversely, all modeling factors looking for ideal loop unroll are fully explored in the works of Ma et al. [37, 40, 41]. More specifically, researchers show that using unroll function for single input arithmetic, the input FMs and weights are optimally reused [38, 39, 42,43,44,45,46].
6 Conclusion and Future Work
In this paper, a comprehensive study related to development and deployment of FPGA in CNN accelerators has been provided. To highlight their similarities and distinctions, we categorized the works based on many parameters. We outlined the influential avenues for study and summarized the key themes of numerous works. Usage of more than one FPGA is important for computational acceleration of massive and extensive Neural Net models, considering the limited hardware resources available on an FPGA board. This allows the architecture to be partitioned across several FPGAs. Although a software for automatic partitioning will not be readily accessible, the manual approach to partitioning is vulnerable to error and unscalable. In addition, random splitting will increase the complexity of interconnections in a manner that the I/O pin count cannot complete the requirement of number of connections.
Lately, researchers have also reconnoitered models of the spike neural network (SNN) that model the biological neuron more closely [47]. This study concentrates on (ANN) which is an acronym for artificial neural network. SNNs and ANNs vary considerably. As a result, their training rules and network architectural structure vary drastically. Large-scale SNN modeling onto SOC/FPGA boards will offer an exhilarating and remunerating challenge for IT designers later on [45].
References
Sze, V., Chen, Y. H., Yang, T. J., & Emer, J. S. (2017). Efficient processing of deep neural networks: A tutorial and survey. Proceedings of the IEEE.
Pau, L. F. (1991). Artificial intelligence and financial services. IEEE Transactions on Knowledge and Data Engineering.
Yao, X., Zhou, J., Zhang, J., & Boer, C. R. (2017). From intelligent manufacturing to smart manufacturing for industry 4.0 driven by next generation artificial intelligence and further on. In Proceedings—2017 5th International Conference on Enterprise Systems ES.
Bishnoi, L., & Narayan Singh, S. (2018). Artificial intelligence techniques used in medical sciences: A review. In Proceedings of 8th International Conference on Cloud Computing, Data Science & Engineering (Confluence).
Parker, D. S. (1989). Integrating AI and DBMS through stream processing.
Fraley, J. B., & Cannady, J. (2017). The promise of machine learning in cybersecurity. In Conference of Proceedings—IEEE SOUTHEASTCON.
Lecun, Y., Bengio, Y., & Hinton, G. (2015). Deep learning. Nature.
Russakovsky, O., Deng, J., Su, H., Krause, J., Satheesh, S., Ma, S., et al. (2015). ImageNet large scale visual recognition challenge. International Journal of Computer Vision.
Long, J., Shelhamer, E., & Darrell, T. (2015). Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
Zhang, Y., Pezeshki, M., Brakel, P., Zhang, S., Laurent, C., Bengio, Y., et al. (2016). Towards end-to-end speech recognition with deep convolutional neural networks. In Proceedings of Annual Conference of the International Speech Communication Association, INTERSPEECH.
Simonyan, K., & Zisserman, A. (2015). Very deep convolutional networks for large-scale image recognition. In 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings.
Nurvitadhi, E., Venkatesh, G., Sim, J., Marr, D., Huang, R., Ong, J. G. H., et al. (2017). Can FPGAs beat GPUs in accelerating next-generation deep neural networks? In FPGA 2017—Proceedings 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays.
Ovtcharov, K., Ruwase, O., Kim, J., Fowers, J., Strauss, K., & Chung, E. S. (2015). Accelerating deep convolutional neural networks using specialized hardware. Microsoft Research Whitepaper.
Qiu, J., Wang, J., Yao, S., Guo, K., Li, B., Zhou, E., et al. (2016). Going deeper with embedded FPGA platform for convolutional neural network. In FPGA 2016—Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays.
Rigos, S., Mariatos, V., & Voros. N. (2012). A hardware acceleration unit for face detection. In 2012 Mediterranean Conference on Embedded Computing.
Misra, J., & Saha. I. (2010). Artificial neural networks in hardware: A survey of two decades of progress. Neurocomputing.
Baji, T. (2018). Evolution of the GPU device widely used in AI and massive parallel processing. In 2018 IEEE Electron Devices Technology and Manufacturing Conference EDTM 2018—Proceedings.
Shawahna, A., Sait, S. M., & El-Maleh, A. (2019). FPGA-based accelerators of deep learning networks for learning and classification: A review.
Mittal, S. (2020). A survey of FPGA-based accelerators for convolutional neural networks. Neural Computing & Applications.
Guo, K., Zeng, S., Yu, J., Wang, Y., & Yang, H. (2017). [DL] A survey of FPGA-based neural network inference accelerator.
Blaiech, A. G., Ben Khalifa, K., Valderrama, C., Fernandes, M. A. C., & Bedoui, M. H. (2019). A survey and taxonomy of FPGA-based deep learning accelerators. The Journal of Systems Architecture.
Talib, M. A., Majzoub, S., Nasir, Q., & Jamal, D. (2020) A systematic literature review on hardware implementation of artificial intelligence algorithms. The Journal of Supercomputing.
Schneider, S., Taylor, G. W., Linquist, S., & Kremer, S. C. (2019). Past, present and future approaches using computer vision for animal re-identification from camera trap data. Methods in Ecology and Evolution.
Faraone, J., Gambardella, G., Fraser, N., Blott, M., Leong. P., & Boland, D. (2018). Customizing low-precision deep neural networks for FPGAs. In Proceedings—2018 International Conference on Field Programmable Logic and Applications FPL.
Cheng, K. T., & Wang, Y. C. (2011). Using mobile GPU for general-purpose computing a case study of face recognition on smartphones. In Proceedings of 2011 International Symposium on VLSI Design, Automation and Test VLSI-DAT 2011.
Ouerhani, Y., Jridi, M., & AlFalou, A. (2010). Fast face recognition approach using a graphical processing unit “GPU.” In 2010 IEEE International Conference on Imaging Systems and Techniques IST 2010—Proceedings.
Li, E., Wang, B., Yang, L., Peng, Y. T., Du, Y., Zhang, Y., et al. (2012). GPU and CPU cooperative acceleration for face detection on modern processors. In Proceedings—IEEE International Conference on Multimedia and Expo.
Lu, L., Liang, Y., Xiao, Q., & Yan, S. (2017). Evaluating fast algorithms for convolutional neural networks on FPGAs. In Proceeding—IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines FCCM 2017.
Szegedy, C., Liu, W., Jia, Y., Sermanet, P., Reed, S., Anguelov, D., et al. (2015). Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition.
Zhang, C., Li, P., Sun, G., Guan, Y., Xiao, B., & Cong, J. Optimizing FPGA-based accelerator design for deep convolutional neural networks. In FPGA 2015—2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays.
Suda, N., Chandra, V., Dasika, G., Mohanty, A., Ma, Y., Vrudhula, S., et al. (2016). Throughput-optimized openCL-based FPGA accelerator for large-scale convolutional neural networks. In FPGA 2016—Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays.
Zhang, C., Fang, Z., Zhou, P., Pan, P., & Cong, J. (2016). Caffeine: Towards uniformed representation and acceleration for deep convolutional neural networks. In IEEE/ACM International Conference on Computer-Aided Design Digital Technical Paper ICCAD.
Guan, Y., Liang, H., Xu, N., Wang, W., Shi, S., Chen, X., et al. (2017). FP-DNN: An automated framework for mapping deep neural networks onto FPGAs with RTL-HLS hybrid templates. In Proceedings—IEEE 25th Annual International Symposium on Field-Programmable Custom Computing Machines FCCM 2017.
Rahman, A., Lee, J., & Choi, K. (2016). Efficient FPGA acceleration of convolutional neural networks using logical-3D compute array. In Proceedings of 2016 Design, Automation & Test in Europe Conference & Exhibition DATE 2016.
Ma, Y., Suda, N., Cao, Y., Seo, J. S., & Vrudhula, S. (2016). Scalable and modularized RTL compilation of Convolutional Neural Networks onto FPGA. In FPL 2016—26th International Conference on Field-Programmable Logic and Applications.
Zhang, C., Wu, D., Sun, J., Sun, G., Luo, G., & Cong. J. (2016). Energy-efficient CNN implementation on a deeply pipelined FPGA cluster. In Proceedings of International Symposium on Low Power Electronics and Design.
Ma, Y., Cao, Y., Vrudhula, S., & Seo, J. S. (2017). Optimizing loop operation and dataflow in FPGA acceleration of deep convolutional neural networks. In FPGA 2017—Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays.
Liu, Z., Dou, Y., Jiang, J., Xu, J., Li, S., Zhou, Y., et al. (2017). Throughput-optimized FPGA accelerator for deep convolutional neural networks. ACM Transactions on Reconfigurable Technology and Systems.
Ma, Y., Cao, Y., Vrudhula, S., & Seo, J. S. An automatic RTL compiler for high-throughput FPGA implementation of diverse deep convolutional neural networks. In 2017 27th International Conference on Field-Programmable Logic and Applications FPL.
Li, H., Fan, X., Jiao, L., Cao, W., Zhou. X., & Wang. L. (2016). A high performance FPGA-based accelerator for large-scale convolutional neural networks. In FPL 2016—26th International Conference on Field-Programmable Logic and Applications.
Alwani, M., Chen, H., Ferdman, M., & Milder, P. (2016). Fused-layer CNN accelerators. In 2016 49th Annual IEEE/ACM International Symposium on Microarchitecture (MICRO).
Wei, X., Yu, C. H., Zhang, P., Chen, Y., Wang, Y., Hu, H., et al. (2017). Automated systolic array architecture synthesis for high throughput CNN inference on FPGAs. In Proceedings of the 54th Annual Design Automation Conference 2017.
Motamedi, M., Gysel, P., & Ghiasi, S. (2017). PLACID: A platform for FPGA-based accelerator creation for DCNNs. ACM Transactions on Multimedia Computing, Communications, and Applications.
Ma, Y., Kim, M., Cao, Y., Vrudhula, S., & Seo, J. S. (2017). End-to-end scalable FPGA accelerator for deep residual networks. In Proceedings—IEEE International Symposium on Circuits and Systems.
Maguire, L. P., McGinnity, T. M., Glackin, B., Ghani, A., Belatreche, A., & Harkin, J. (2007). Challenges for large-scale implementations of spiking neural networks on FPGAs. Neurocomputing.
Negi, A., Saxena, D., & Suneja, K. (2020). High level synthesis of chaos based text encryption using modified Hill Cipher algorithm (pp. 3–7).
Thapa, S., Adhikari, S., Naseem, U., Singh, P., Bharathy, G., & Prasad, M. (2020). Detecting Alzheimer’s disease by exploiting linguistic information from Nepali transcript. Communication in Computer and Information Science.
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Negi, A., Saxena, D., Kunal, Suneja, K. (2022). An Anatomization of FPGA-Based Neural Networks. In: Nayak, P., Pal, S., Peng, SL. (eds) IoT and Analytics for Sensor Networks. Lecture Notes in Networks and Systems, vol 244. Springer, Singapore. https://doi.org/10.1007/978-981-16-2919-8_45
Download citation
DOI: https://doi.org/10.1007/978-981-16-2919-8_45
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-2918-1
Online ISBN: 978-981-16-2919-8
eBook Packages: EngineeringEngineering (R0)