
Abstract
In this chapter, we propose ten trigonometric similarity measures based on the Choquet integral for Pythagorean fuzzy sets using the trigonometric functions cosine and cotangent. We show that the proposed trigonometric similarity measures are more sensitive expansions of some existing trigonometric similarity measures. Subsequently, we give applications of proposed similarity measures on pattern recognition and medical diagnosis to show the efficiency of these trigonometric similarity measures. We also compare the results with some previous results.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
1 Introduction
The notion of the fuzzy set was presented by Zadeh [35] via a membership function and it was expanded to the notion of intuitionistic fuzzy set (IFS) by Atanassov [1] via a membership function with a non-membership function such that the sum of these functions is less than or equal to one. However, data in real-world problems cannot always be represented by a fuzzy set or an IFS. For instance, if a decision-maker or expert uses the intuitionistic fuzzy environment to give their preferences with the membership degree 0.7 and the non-membership degree 0.4, then we see that the sum of these degrees is equal to 1.1 which is larger than 1 and so this case cannot be characterized with an IFS. Thus, these were expanded to some more useful notions to solve real-world problems. With this motivation, Yager [30] presented the notion of Pythagorean fuzzy set (PFS) that is represented by a membership function with a non-membership function such that the sum of squares of these functions is less than or equal to 1. For instance, in the example above, we obtain that \( 0.7^{2}+0.4^{2}\le 1 \). Therefore, a PFS is more useful than an IFS as well as a fuzzy set while handling real-life applications with imprecision and uncertainty.
Some expansions of PFSs such as interval-valued Pythagorean fuzzy sets [21], complex Pythagorean fuzzy sets [25], and Pythagorean fuzzy linguistic sets [9, 13, 22] were improved and they were applied to some extensive fields. One of these extensive areas of application is the notion of similarity measure for PFSs, which is an effective tool to find the degree of similarity between two objects. There are several versions of similarity measures for PFSs that satisfy some certain conditions and they have various applications to some different fields such as pattern recognition and medical diagnosis. For example, Peng and Garg [23] presented the concept of multiparametric similarity measures for PFSs with multiple parameters. Nyugen et al. [20] introduced the concept of exponential similarity measures by considering the exponential function. Firozja et al. [4] proposed new similarity measures by using triangular conorms. Another version of similarity measures is a cosine similarity measure [28, 33]. There exist various studies that introduce versions of cosine similarity measures for PFSs and that give applications of these similarity measures on pattern recognition, medical diagnosis, decision-making, and face recognition systems [5, 28, 31].
The process of combining several numerical values into a single representative one is called aggregation, and a numerical function performing this process is called an aggregation function. This concept has various application areas such as artificial intelligence, operations research, economics and finance, pattern recognition and image processing, data fusion, multicriteria decision-making, automated reasoning, etc. (see, e.g., [15]). The arithmetic mean and the weighted mean are the most well-known aggregation operators. Moreover, a cosine similarity measure uses the arithmetic mean or the weighted arithmetic mean to aggregate the cosine values of the angle among conjugate components of the vector representations of two PFSs. Various researchers have studied and enhanced the theory of PFSs using aggregation operators. For example, Zeng et al. [36] developed some induced ordered weighted aggregation operator for PFSs. Wei and Lu [29] presented a power aggregation operator for PFS to solve decision-making problems. Recently, Garg [10, 12] presented some neutrality operation-based Pythagorean fuzzy geometric aggregation operators and then defined some novel Pythagorean fuzzy weighted, ordered weighted, and hybrid neutral averaging aggregation operators for Pythagorean fuzzy information, which can neutrally treat the membership and non-membership degrees. Moreover, Garg [8, 11] developed some new probabilistic aggregation operators with Pythagorean fuzzy information by using an ordered weighted average operator. All of these existing aggregation operators ignore the interaction between the elements. In this paper, to overcome this deficiency, we use the notion of Choquet integral with respect to a fuzzy measure that considers the interaction between elements.
Choquet integral is a non-linear continuous aggregation operator that uses non-additive measures. In 1953, Choquet [3] presented the notion of fuzzy measure (or capacity or non-additive measure) and Choquet integral. The notion of fuzzy measure permits assignment of “weights”on subsets of the universal set and it has been used in a wide range of fields as a common disciplinary method such as decision-making, pattern recognition, and medical diagnosis [7, 14, 16, 26, 27]. Actually, the Choquet integral is an extension of Lebesgue integral and a non-additive extension of the weighted arithmetic mean. Although a fuzzy integral has more complicated structure due to the lack of additivity in contrast to the additive integrals such as Lebesgue integral, use of a fuzzy measure and a fuzzy integral is more effective in the aggregation. In [19], it is shown that the Choquet integral performs significantly more orders than the weighted arithmetic mean and that the difference gets larger when the number of the elements of the set gets larger. Moreover, it has been proved in [18] that when the number of the element of the finite set increases, the probability of getting more optimal ranking in the Choquet integral increases compared to the weighted arithmetic mean. Actually, fuzzy measures and fuzzy integrals let us to take the preferences into account that are not contained in the weights in the weighted arithmetic mean [24]. In the literature, there are some studies that consider the Choquet integral as an aggregation function for some fuzzy sets (see, e.g., [6, 17]) and there are some studies that consider fuzzy measure theory to introduce a similarity measure for IFSs (see, e.g., [2, 32]). In this chapter, we use the Choquet integral to present some trigonometric similarity measures for PFSs instead of weighted arithmetic mean.
This chapter presents a synthesis which is an innovative tool by considering the Choquet integral to define a similarity measure for PFSs via some trigonometric functions inspired by the definition of the weighted cosine similarity measure for PFSs. The remainder of this chapter is organized as follows: in Sect. 2, the notion of PFS is recalled and the existing similarity measures for PFS are given. In Sect. 3, we recall the notions of fuzzy measure and the Choquet integral. Then we propose ten trigonometric similarity measures for PFSs via the Choquet integral. In Sect. 4, we compare the proposed similarity measures with some existing similarity measures for PFSs and to express the effectiveness of proposed similarity measures, we apply them on some pattern recognition and medical diagnosis problems.
2 Preliminaries
The notion of PFS was defined by Yager [30] to model real-life problems including imprecision, uncertainty, and vagueness situations more precisely with higher accuracy. In this section, we start with recalling the notion of PFS and some existing trigonometric similarity measures for PFSs.
Definition 1
Let \( \mathbb {U}=\left\{ \xi _{1},\xi _{2},\ldots ,\xi _{n} \right\} \) be a finite set. A PFS \( \tilde{{A}} \) in \( \mathbb {U} \) is given with
where \(\mu _{\tilde{{A}}}\) and \(\nu _{\tilde{{A}}}\) are functions from \(\mathbb {U}\) to [0, 1] with the condition \(\mu _{\tilde{{A}}}^{2}(\xi )+\nu _{\tilde{{A}}}^{2}(\xi )\le 1 \), for any \( \xi \in X \). The numbers \( \mu _{\tilde{{A}}}(\xi ) \) and \( \nu _{\tilde{{A}}}(\xi ) \) indicate the membership degree and the non-membership degree of the element \( \xi \) to the set \(\tilde{{A}}\), respectively [30].
For any PFS \( \tilde{{A}} \) of \( \mathbb {U} \), \( \pi _{\tilde{{A}}}(\xi )=(1-\mu _{\tilde{{A}}}^{2}(\xi )-\nu _{\tilde{{A}}}^{2}(\xi ))^{1/2} \) is called the hesitancy degree of \( \xi \) to \( \tilde{{A}} \), for each \( \xi \in \mathbb {U} \) [30]. It is obvious that \(0\le \pi _{\tilde{{A}}}(\xi )\le 1 \).

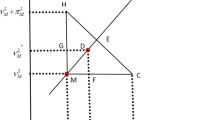
Comparison of IFSs and PFSs
If \((r_{\tilde{{A}}}(\xi ),\theta _{\tilde{{A}}}(\xi ))\) is the polar coordinates of \((\mu _{\tilde{{A}}}(\xi ),\nu _{\tilde{{A}}}(\xi ))\) for a point \(\xi \in \mathbb {U}\), then the function \(d_{\tilde{{A}}}:X\rightarrow [0,1]\) can be considered the direction of commitment at point \(\xi \) where \(d_{\tilde{{A}}}(\xi ):=(1-\theta _{\tilde{{A}}}(\xi ))\frac{\pi }{2}\) [30]. The function \(d_{\tilde{{A}}}\) scales the first quadrant between zero and one, i.e., if \(\theta _{\tilde{{A}}}(\xi )=\frac{\pi }{2}\) then \(\mu _{\tilde{{A}}}(\xi )=0\) and \(\nu _{\tilde{{A}}}(\xi )=r_{\tilde{{A}}}(\xi )\) which means the direction \(d_{\tilde{{A}}}(\xi )=0\) and if \(\theta _{\tilde{{A}}}(\xi )=0\) then \(\mu _{\tilde{{A}}}(\xi )=r_{\tilde{{A}}}(\xi )\) and \(\nu _{\tilde{{A}}}(\xi )=0\) which means the direction \(d_{\tilde{{A}}}(\xi )=1\). Therefore, a PFS \(\tilde{{A}}\) can be expressed by either \((\mu _{\tilde{{A}}},\nu _{\tilde{{A}}})\) or \((r_{\tilde{{A}}},d_{\tilde{{A}}})\) (see Fig. 1).
Now, we examine some similarity measures for PFSs. Peng and Garg [23] proposed two similarity measures for PFSs by using relation of similarity measures with distance measures.
Let \( \tilde{{A}}=\left\{ <\xi ,\mu _{\tilde{{A}}}(\xi ), \nu _{\tilde{{A}}}(\xi )> | \xi \in \mathbb {U}\right\} \) and \( \tilde{{B}}=\left\{ <\xi ,\mu _{\tilde{{B}}}(\xi ), \nu _{\tilde{{B}}}(\xi )> | \xi \in \mathbb {U}\right\} \) be two PFSs in a finite set \(\mathbb {U} =\left\{ \xi _{1},\xi _{2},\ldots ,\xi _{n}\right\} \). Two similarity measures between \( \tilde{{A}} \) and \( \tilde{{B}}\) are given with
and
where \( k\ge 0 \), \( p\ge 1 \), and \( t_{k} \) are parameters such that \( t_{k}\ge k+1 \).
Following similarity measures are the weighted versions of the similarity measures recalled in (2)–(3):
and
where \( \omega _{i} \in [0,1]\) for each \( i=1,2,\ldots ,n \) and \( \sum _{i=1}^{n} \omega _{i}=1 \).
Effectiveness of these similarity measures was illustrated with some case studies of pattern recognition in [23] and the decision-maker tried to explain the effect of variables on the samples using the 1–8 scale for k and the 1–9 scale for p and \( t_{k} \). That is, by limiting the parameters, the decision-maker studied the examples under special choices. Moreover, when \( t_{k}=1, k=0 \) and \( \tilde{{A}} \) and \( \tilde{{B}} \) two PFSs such that \( \nu _{\tilde{{A}}}^{2}(\xi _{i})= \nu _{\tilde{{B}}}^{2}(\xi _{i}) \) for any \( i=1,2,\ldots ,n \) and we obtain that \( S_{1}(\tilde{{A}}, \tilde{{B}})=S_{2}(\tilde{{A}}, \tilde{{B}})= 1\) for any \( p\ge 1 \). As a result, the \( \mu \) membership function and p parameter lose their importance and information carried by \( \mu \) becomes insignificant and so it is neglected. Moreover, a contradiction emerges when the similarity of different PFSs is equal to one. The main reason of this contradiction is the use of relation of similarity measure with distance measure to obtain similarity measure for PFSs.
Nyugen et al. [20] proposed three weighted exponential similarity measures for PFSs by using exponential function:
and
where \( S_{i}^{\mu }(\tilde{{A}},\tilde{{B}}):=e^{-\left| \mu _{\tilde{{A}}}^{2}(\xi _{i})-\mu _{\tilde{{B}}}^{2}(\xi _{i}) \right| } \) and \( S_{i}^{\nu }(\tilde{{A}},\tilde{{B}}):=e^{-\left| \nu _{\tilde{{A}}}^{2}(\xi _{i})-\nu _{\tilde{{B}}}^{2}(\xi _{i}) \right| } \) and \( \omega _{i} \in (0,1]\) for each \( i=1,2,\ldots ,n \) and \( \sum _{i=1}^{n} \omega _{i}=1\).
These similarity measures were applied to some pattern recognition problems. Since the proposed similarity measures are given with the help of the exponential function, as the number of elements of the universal set and p variable increase, the effort of calculating the similarity increases.
Firozja et al. [4] presented similarity measures for PFSs via the notion of S-norm. They applied them some pattern recognition and medical diagnosis problems to show the effectiveness of proposed similarity measures. Based on S-norm three weighted similarity measures between \( \tilde{{A}} \) and \( \tilde{{B}}\) are given with
where “\( \vee \)” and “\( \wedge \)” denote the maximum operator and minimum operator, respectively. Moreover, \( \omega _{i} \in [0,1]\) for each \( i=1,2,\ldots ,n \) and \( \sum _{i=1}^{n} \omega _{i}=1 \).
However, the proposed similarity measures do not evaluate the Pythagorean fuzzy information carried by \( \mu \) and \( \nu \) well enough in some cases. In [4], the distance between components is more important than the information carried by fuzzy values. As a result, the decision-making process becomes difficult because the similarities of two different Pythagorean fuzzy sets or values are equal.
Wei and Wei [28] proposed two similarity measures via cosine function among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}} \) by using the arithmetic mean:
They also proposed four more similarity measures via cosine function among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}} \) by using the arithmetic mean:
Moreover, they proposed four similarity measures via cotangent function among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}} \) by using the arithmetic mean:
Following similarity measures [28] are the weighted versions of the similarity measures recalled in (12)–(21):
where \( 0 \le \omega _{1}, \omega _{2},\ldots , \omega _{n} \le 1\) with \( \sum _{i=1}^{n} \omega _{i}=1 \).
3 Trigonometric Similarity Measures Defined with the Choquet Integral For PFSs
As we mentioned before, the notion of the Choquet integral is a non-additive extension of the notion of weighted arithmetic mean. In this study, we consider the Choquet integral and cosine and cotangent functions to construct ten new similarity measures motivating from the trigonometric similarity measures (22)–(31) defined by [28].
First of all, let us recall some basic notions of fuzzy measure theory that are used in this section.
Definition 2
Let \( \mathbb {U}\ne \varnothing \) be a finite set and let \( P(\mathbb {U}) \) be the family of all subsets of \( \mathbb {U} \). If
-
(i)
\( \sigma (\varnothing )=0, \)
-
(ii)
\( \sigma (\mathbb {U})=1, \)
-
(iii)
\( A\subseteq B \) implies \( \sigma (A)\le \sigma (B) \) (monotonicity), then the set function \( \sigma :P(\mathbb {U})\rightarrow [0,1] \) is called a fuzzy measure on \( \mathbb {U} \) [3].
Note that, a fuzzy measure need not to be additive.
Definition 3
Let \(\mathbb {U} =\left\{ \xi _{1},\xi _{2},\ldots ,\xi _{n}\right\} \) be a finite set and let \( \sigma \) be a fuzzy measure on \( \mathbb {U} \). The Choquet integral [3] of a function \( f:\mathbb {U}\rightarrow [0,1] \) with respect to \( \sigma \) is defined by
where the sequence \( \left\{ \xi _{(k)} \right\} _{k=0}^{n} \) is a new permutation of the sequence \( \left\{ \xi _{k} \right\} _{k=0}^{n} \) such that \( 0:{=}f(\xi _{(0)}) {\le } f(\xi _{(1)})\le f(\xi _{(2)})\le \cdots \le f(\xi _{(n)})\) and \( E_{(k)}:=\left\{ \xi _{(k)}, \xi _{(k+1)},\ldots , \xi _{(n)} \right\} \).
If \( \sigma \) is an additive measure then the Choquet integral reduces to weighted arithmetic mean.
Throughout this section we let \( \mathbb {U}=\left\{ \xi _{1},\xi _{2},\ldots ,\xi _{n}\right\} \) be a finite set, \( \tilde{{A}} \) and \( \tilde{{B}} \) be two PFSs in \( \mathbb {U} \) and \( \sigma \) be a fuzzy measure on \( \mathbb {U} \).

The angle between vector representations
Definition 4
A Choquet cosine similarity measure among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}} \) is given with
where
for \( i=1,2,\ldots ,n \).
In Fig. 2, we see that \(\cos {\theta _{i}}=f_{\tilde{{A}},\tilde{{B}}}(\xi _{i})\) for any \( i=1,2,\ldots , n \).
Proposition 1
The cosine similarity measure \( W_{\textit{PFC}^{1}}^{(C,\sigma )} \) satisfies the following properties:
\(\mathbf {(P_{1})}\) \(0\le W_{\textit{PFC}^{1}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}})\le 1 \)
\(\mathbf {(P_{2})}\) \( W_{PFC^{1}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}})=W_{\textit{PFC}^{1}}^{(C,\sigma )}(\tilde{{B}},\tilde{{A}}) \)
\(\mathbf {(P_{3})}\) If \( \tilde{{A}}=\tilde{{B}} \) then \(W_{\textit{PFC}^{1}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}}) =1 \).
Proof
\(\mathbf {(P_{1})}\) Since \(f_{\tilde{{A}},\tilde{{B}}}(\xi _{i})\in [0,1] \) for any \(i=1,2,\ldots , n\) and the Choquet integral is monotone we have \( 0\le W_{\textit{PFC}^{1}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}})\le 1 \) immediately.
\(\mathbf {(P_{2})}\) It is trivial since \( f_{\tilde{{A}},\tilde{{B}}}(\xi _{i})=f_{\tilde{{B}},\tilde{{A}}}(\xi _{i}) \) for any \(i=1,2,\ldots ,n\)
\(\mathbf {(P_{3})}\) If \( \tilde{{A}}=\tilde{{B}} \) then we have \( \mu _{\tilde{A}}(\xi _{i})=\mu _{\tilde{B}}(\xi _{i}) \) and \( \nu _{\tilde{A}}(\xi _{i})=\nu _{\tilde{B}}(\xi _{i})\), for \( i=1,2,\ldots ,n \), which yields that \(f_{\tilde{{A}},\tilde{{B}}}(\xi _{i})=1 \). Hence, we obtain \(W_{\textit{tPFC}^{1}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}}) =1 \). \(\square \)
Considering the functions \(\mu \), \(\nu \), and \(\pi \) we propose another similarity measure via cosine function and the Choquet integral.
Definition 5
A Choquet cosine similarity measure among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}} \) is given with
where
for \( i=1,2,\ldots , n \).
Remark 1
Similar to the proof of Proposition 1 it can be proved that \(W_{\textit{PFC}^{2}}^{(C,\sigma )}\) satisfies the conditions \(P_{1}-P_{3}\).
Definition 6
Considering the cosine function and the Choquet integral two new similarity measures among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}}\) are given with
where
and
for \( i=1,2,\ldots ,n \), respectively.
Proposition 2
The cosine similarity measure \( W_{\textit{PFCS}^{k}}^{(C,\sigma )}\) satisfies \(P_{1},P_{2}\) and the following properties:
\(\mathbf {(P'_{3})}\) \( \tilde{{A}}=\tilde{{B}} \) if and only if \(W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}}) =1 \).
\(\mathbf {(P_{4})}\) If \(\tilde{{C}} \) is an PFS in \(\mathbb {U} \) and \(\tilde{{A}}\subset \tilde{{B}}\subset \tilde{{C}} \) then \( W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{C}})\le W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}}) \) and \( W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{C}})\le W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{B}},\tilde{{C}}) \).
Proof
\(P_{1}\) and \(P_{2}\) can be proved similar to Proposition 1.
\(\mathbf {(P'_{3})}\) For any two PFSs \( \tilde{{A}} \) and \( \tilde{{B}} \) in \( \mathbb {U} \), if \( \tilde{{A}}{=}\tilde{{B}} \) , this implies \( \mu _{\tilde{A}}^{2}(\xi _{i}){=}\mu _{\tilde{B}}^{2}(\xi _{i}) \) and \( \nu _{\tilde{A}}^{2}(\xi _{i}){=}\nu _{\tilde{B}}^{2}(\xi _{i}) \), for \( i{=}1,2,\ldots ,n \). Thus, \( \left| \mu _{\tilde{A}}^{2}(\xi _{i}){-}\mu _{\tilde{B}}^{2}(\xi _{i})\right| {=}0 \) and \( \left| \nu _{\tilde{A}}^{2}(\xi _{i})-\nu _{\tilde{B}}^{2}(\xi _{i})\right| {=}0 \). Therefore, we have \( h^{(k)}_{\tilde{{A}},\tilde{{B}}}(\xi _{i})=1 \) and so \( W_{PFC^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}})=1 \) for \( k=1,2 \).
Conversely, let \( W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}})=1 \) for \( k=1,2 \). Then, since \( \cos 0=1 \) we have \(h^{(k)}_{\tilde{{A}},\tilde{{B}}}(\xi _{i})=1 \) which yields that \( \left| \mu _{\tilde{A}}^{2}(\xi _{i})-\mu _{\tilde{B}}^{2}(\xi _{i})\right| =0 \) and \( \left| \nu _{\tilde{A}}^{2}(\xi _{i})-\nu _{\tilde{B}}^{2}(\xi _{i})\right| =0 \), \(i=1,2,\ldots ,n \). Therefore, we obtain \( \mu _{\tilde{A}}^{2}(\xi _{i})=\mu _{\tilde{B}}^{2}(\xi _{i}) \) and \( \nu _{\tilde{A}}^{2}(\xi _{i})=\nu _{\tilde{B}}^{2}(\xi _{i}) \), for \( i=1,2,\ldots ,n \). Hence, \({\tilde{{A}}=\tilde{{B}}} \).
\(\mathbf {(P_{4})}\) If \(\tilde{{A}}\subset \tilde{{B}}\subset \tilde{{C}} \) then \( \mu _{\tilde{A}}(\xi _{i})\le \mu _{\tilde{B}}(\xi _{i})\le \mu _{\tilde{C}}(\xi _{i}) \) and \( \nu _{\tilde{A}}(\xi _{i})\ge \nu _{\tilde{B}}(\xi _{i})\ge \nu _{\tilde{C}}(\xi _{i}) \), for \( i=1,2,\ldots ,n \). Then, \( \mu _{\tilde{A}}^{2}(\xi _{i})\le \mu _{\tilde{B}}^{2}(\xi _{i})\le \mu _{\tilde{C}}^{2}(\xi _{i}) \) and \( \nu _{\tilde{A}}^{2}(\xi _{i})\ge \nu _{\tilde{B}}^{2}(\xi _{i})\ge \nu _{\tilde{C}}^{2}(\xi _{i}) \), for \( i=1,2,\ldots ,n \). Thus, we have
So, we obtain \( h^{(k)}_{\tilde{{A}},\tilde{{C}}}(\xi _{i})\le h^{(k)}_{\tilde{{A}},\tilde{{B}}}(\xi _{i}) \) and \( h^{(k)}_{\tilde{{A}},\tilde{{C}}}(\xi _{i})\le h^{(k)}_{\tilde{{B}},\tilde{{C}}}(\xi _{i}) \) which yields that \(W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{C}}) \le W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}}) \) and \( W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{C}}) \le W_{\textit{PFCS}^{k}}^{(C,\sigma )}(\tilde{{B}},\tilde{{C}}) \), for \( k=1,2 \). Hence, the proof is completed.
\(\square \)
Definition 7
Considering the cosine function and the Choquet integral two similarity measures among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}}\) are given with
where
and
for \( i=1,2,\ldots ,n \), respectively.
Remark 2
Similar to the proof of Proposition 2 it can be proved that \(W_{\textit{PFCS}^{3}}^{(C,\sigma )}\) and \(W_{\textit{PFCS}^{4}}^{(C,\sigma )}\) satisfy the conditions \(P_{1},P_{2},P'_{3}\) and \(P_{4}\).
Definition 8
Considering the cotangent function and the Choquet integral two similarity measures among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}} \) are given with
where
and
for \( i=1,2,\ldots ,n \), respectively.
Definition 9
Considering the cotangent function and the Choquet integral two new similarity measures among PFS \( \tilde{{A}} \) and PFS \( \tilde{{B}} \) are given with
where
and
for \( i=1,2,\ldots ,n \), respectively.
Proposition 3
The cotangent similarity measure \( W_{\textit{PFCT}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}}),(k=1,2,3,4) \) satisfies \(P_{1},P_{2},P'_{3}\) and \(P_{4}\).
Proof
\(P_{1}\) and \(P_{2}\) can be proved similar to Proposition 1.
\(\mathbf {(P'_{3})}\) For any two PFSs \( \tilde{{A}} \) and \( \tilde{{B}} \) in \( \mathbb {U} \), if \( \tilde{{A}}=\tilde{{B}} \) , then we have \( \mu _{\tilde{A}}^{2}(\xi _{i})=\mu _{\tilde{B}}^{2}(\xi _{i}) \) and \( \nu _{\tilde{A}}^{2}(\xi _{i})=\nu _{\tilde{B}}^{2}(\xi _{i}) \), for \( i=1,2,\ldots ,n \). Thus, we obtain \( \left| \mu _{\tilde{A}}^{2}(\xi _{i})-\mu _{\tilde{B}}^{2}(\xi _{i})\right| =0 \) and \( \left| \nu _{\tilde{A}}^{2}(\xi _{i})-\nu _{\tilde{B}}^{2}(\xi _{i})\right| =0 \) which implies \( q^{(k)}_{\tilde{{A}},\tilde{{B}}}(\xi _{i})=1 \) and so \( W_{\textit{PFCT}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}})=1 \) for \( k=1,2,3,4 \). Conversely, if \( W_{\textit{PFCT}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}})=1 \) for \( k=1,2,3,4 \), then since \( \cot \dfrac{\pi }{4}=1\) we have \(q^{(k)}_{\tilde{{A}},\tilde{{B}}}(\xi _{i})=1 \) and so \( \left| \mu _{\tilde{A}}^{2}(\xi _{i})-\mu _{\tilde{B}}^{2}(\xi _{i})\right| =0 \) and \( \left| \nu _{\tilde{A}}^{2}(\xi _{i})-\nu _{\tilde{B}}^{2}(\xi _{i})\right| =0 \), \(i=1,2,\ldots ,n \). Thus, we obtain \( \mu _{\tilde{A}}^{2}(\xi _{i})=\mu _{\tilde{B}}^{2}(\xi _{i}) \) and \( \nu _{\tilde{A}}^{2}(\xi _{i})=\nu _{\tilde{B}}^{2}(\xi _{i}) \), for \( i=1,2,\ldots ,n \) which yields that \({\tilde{{A}}=\tilde{{B}}} \).
\(\mathbf {(P_{4})}\) If \(\tilde{{A}}\subset \tilde{{B}}\subset \tilde{{C}} \) then \( \mu _{\tilde{A}}(\xi _{i})\le \mu _{\tilde{B}}(\xi _{i})\le \mu _{\tilde{C}}(\xi _{i}) \) and \( \nu _{\tilde{A}}(\xi _{i})\ge \nu _{\tilde{B}}(\xi _{i})\ge \nu _{\tilde{C}}(\xi _{i}) \), for \( i=1,2,\ldots ,n \). Then, \( \mu _{\tilde{A}}^{2}(\xi _{i})\le \mu _{\tilde{B}}^{2}(\xi _{i})\le \mu _{\tilde{C}}^{2}(\xi _{i}) \) and \( \nu _{\tilde{A}}^{2}(\xi _{i})\ge \nu _{\tilde{B}}^{2}(\xi _{i})\ge \nu _{\tilde{C}}^{2}(\xi _{i}) \), for \( i=1,2,\ldots ,n \).
\(\mathbf{Case} 1 :\) Let \( \left| \mu _{\tilde{A}}^{2}(\xi _{i})-\mu _{\tilde{C}}^{2}(\xi _{i})\right| \ge \left| \nu _{\tilde{A}}^{2}(\xi _{i})-\nu _{\tilde{C}}^{2}(\xi _{i})\right| \). Then from the assumption of non-membership functions, we have
On the other hand, from the assumption of the membership functions, we have
\(\mathbf{Case} 2 :\) Let \( \left| \mu _{\tilde{A}}^{2}(\xi _{i})-\mu _{\tilde{C}}^{2}(\xi _{i})\right| \le \left| \nu _{\tilde{A}}^{2}(\xi _{i})-\nu _{\tilde{C}}^{2}(\xi _{i})\right| \). Then from the assumption of membership functions, we have
Furthermore, from the assumption of the non-membership functions, we have
Both in Case 1 and Case 2, we have \( q^{(k)}_{\tilde{{A}},\tilde{{C}}}(\xi _{i})\le q^{(k)}_{\tilde{{A}},\tilde{{B}}}(\xi _{i}) \) and \( q^{(k)}_{\tilde{{A}},\tilde{{C}}}(\xi _{i})\le q^{(k)}_{\tilde{{B}},\tilde{{C}}}(\xi _{i}) \) which implies that \( W_{\textit{PFCT}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{C}}) \le W_{\textit{PFCT}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{B}}) \) and \( W_{\textit{PFCT}^{k}}^{(C,\sigma )}(\tilde{{A}},\tilde{{C}}) \le W_{\textit{PFCT}^{k}}^{(C,\sigma )}\) \((\tilde{{B}},\tilde{{C}}) \), for \( k=1,2,3,4 \). Thus, the proof is completed. \(\square \)
Remark 3
If we consider additive measures instead of fuzzy measures, then the similarity measures proposed in Definitions 4–9 are reduced to (22)–(31), respectively. On the other hand, considering the weights as measures of singletons we conclude that trigonometric similarity measures (22)–(31) are considered as trigonometric similarity measures based on the Choquet integral given in Definitions 4–9, respectively.
4 Applications
In this section, to show the effectiveness of the proposed Choquet similarity measures, we give some applications on pattern recognition and medical diagnosis problems.
4.1 Pattern Recognition Problem
A pattern recognition problem investigates how an object is coherent with a given pattern. We apply the proposed Choquet similarity measures to show their outperforming and suitability in pattern recognition. We consider a pattern recognition problem which is studied in [5, 28]. Wei and Wei [28] obtained that pattern \( \tilde{{A}} \) belongs to class \( \tilde{{A}_{3}} \), using similarity measures between (12) and (21) (Table 1 of [28]).
Example 1
Let \( \tilde{{A}_{1}},\tilde{{A}_{2}} \text { and} \,\,\,\,\tilde{{A}_{3}} \) be three patterns which are represented by using following PFSs of a finite set \( \mathbb {U}=\left\{ \xi _{1},\xi _{2},\xi _{3} \right\} \):
Let \( \tilde{{A}} = \left\{ \left\langle \xi _{1}, 0.5, 0.3\right\rangle , \left\langle \xi _{2}, 0.6, 0.2\right\rangle , \left\langle \xi _{3}, 0.8, 0.1\right\rangle \right\} \) be a pattern that needs to be classified in one of three classes \( \tilde{{A}_{1}},\tilde{{A}_{2}} \text { and} \,\,\,\,\tilde{{A}_{3}} \).

Visualization of the rankings of the alternatives according to ten trigonometric similarity measures
We use a hypothetical fuzzy measure. For this purpose, we use the hypothetical weights used in [28] as the fuzzy measures of singletons and we create the remaining measures using the monotonicity property of the fuzzy measure as follows (Table 1).
From the recognition principle of maximum degree of similarity between PFSs, the process of assigning the pattern \( \tilde{{A}} \) to \( \tilde{{A}_{i}} \) is described by
The rankings obtained by ten similarity measures are visualized in Fig. 3 and comparison of the results is given in Table 2. The numerical result presented in Tables 2 and Eq. (53) shows that \( k=\tilde{{A}_{3}} \) for each similarity measure. Namely, \( \tilde{{A}} \) pattern belongs to class \( \tilde{{A}_{3}} \) with respect to each trigonometric similarity measure. When the results are compared to the results in [5, 28], we see that they are in agreement (see Table 2).
4.2 Medical Diagnosis Problem
A medical diagnosis aims to determine which disease explains the symptoms of a patient. In this process, patterns of symptoms are compared with patterns of disease. Now, we apply proposed Choquet similarity measures to show their outperforming and suitability in medical diagnosis problems. We consider a medical diagnosis problem that was studied in [28]. Wei and Wei [28] obtained unknown class \( \Phi \) belonging to class \( \Psi _{2} \) according to similarity measures between (13) and (21) except for (12) (see Table 3 of [28]).
Example 2
Let us consider a set of diagnoses and symptoms as follows:
\( \Psi {=}\lbrace \Psi _{1}(\text {Viral fever}), \Psi _{2}(\text {Malaria}), \Psi _{3}(\text {Typhoid}), \Psi _{4}(\text {Stomach problem})\), \(\Psi _{5}(\text {Chest} \text {Problem})\rbrace \)
\(Z {=}\lbrace \zeta _{1}(\text {Temperature}), \zeta _{2}(\text {Headache}), \zeta _{3}(\text {Stomach pain}), \zeta _{4}(\text {Cough}),\) \(\zeta _{5}(\text {Chest pain})\rbrace .\)
Assume that a patient that has all the symptoms is represented by the following PFS:
\( \Phi (\text {Patient}){=}\left\{ \langle \zeta _{1}, 0.8, 0.1\right\rangle , \left\langle \zeta _{2}, 0.6, 0.1\right\rangle , \left\langle \zeta _{3}, 0.2, 0.8\right\rangle , \left\langle \zeta _{4}, 0.6, 0.1\right\rangle , \left\langle \zeta _{5}, 0.1, 0.6\right\rangle \rbrace \).
Moreover, assume that each diagnosis \( \Psi _{i}(i=1,2,3,4,5) \) is given as PFSs:
Our aim is to classify \( \Phi \) into one of the diagnosis \( \Psi _{i}(i=1,2,3,4,5) \). First of all we construct a fuzzy measure. As in the pattern recognition problem, we use a hypothetical fuzzy measure for this example by taking into account the hypothetical weights given in [28] as fuzzy measures of singletons (see Table 4).

Visualization of the rankings of the alternatives according to ten trigonometric similarity measures
When we consider Table 3, it is seen that the results are in agreement with the results in [28] all except for \(\textit{WPFC}^{1}(\Psi _{i},\Phi ) \), \(\textit{WPFCT}^{1}(\Psi _{i},\Phi ) \) and \(\textit{WPFCT}^{2}(\Psi _{i},\Phi )\), whereas they are fully compatible with the results in [5]. From (53), we see that \( k=\Psi _{2} \) for each similarity measure. Namely, \( \Phi \) patient has viral fever. Therefore, the ten similarity measures proposed are more sensitive and consistent than the ones suggested by Wei and Wei [28].
The rankings obtained by ten similarity measures are also visualized in Fig. 4.
Now, we give the comparison of the proposed similarity measures with the similarity measures (6)–(11). The numerical results presented in Table 5 show that the proposed Choquet cosine similarity measure consistent with [4] and [20]. Namely, pattern \( \tilde{{A}} \) belongs to class \( \tilde{{A_{3}}} \). However, as the decision-maker and the fuzzy environment change, the weights vary, and this increases the sensitivity. For example, when we consider Table 6, patient P has typhoid in [4] while it has malaria with respect to proposed Choquet integral model. The reason of this change is that when solving the medical diagnosis problem in this model, the weights of symptoms and their interaction with each other are taken into account with the help of fuzzy measure. The similarity measures given in Tables 5 and 6 are defined similar to Definitions 4–9 with the help of Choquet integral.
5 Conclusion
In this paper, we propose new similarity measures based on the Choquet integral for PFSs. Moreover, we apply this measures to pattern recognition and medical diagnosis problems and then we compare our results with some existing results. We see that our results are consistent with the literature while some of them are incompatible. The main reason of this difference is the sensitivity of the Choquet integral. The proposed Choquet integral model has a wide range of applications. In the future, we shall expand the proposed Choquet integral model with some different information measures and fuzzy environments and we shall apply them to decision-making, risk analysis, and many other fields under uncertain environments [9, 13, 34].
References
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20(1):87–96
Cha J, Lee S, Kim KS, Pedrycz W (2017) On the design of similarity measures based on fuzzy integral. In: Joint 17th world congress of international fuzzy systems association and 9th international conference on soft computing and intelligent systems, pp 1–6
Choquet G (1953) Theory of capacities. Annales de L’Institut Fourier 5:131–295
Firozja MA, Agheli B, Jamkhaneh EB (2020) A new similarity measure for Pythagorean fuzzy sets. Comp Intell Syst 6:67–74
Garg H (2016) A novel correlation coefficients between Pythagorean fuzzy sets and its applications to decision-making processes. Int J Intell Syst 31(12):1234–1252
Garg H, Agarwal N, Tripathi A (2017) Choquet integral-based information aggregation operators under the interval-valued intuitionistic fuzzy set and Its Applications To Decision-Making Process. Int J Uncertainty Quantif 7(3):249–269
Garg H (2018) New exponential operational laws and their aggregation operators for interval-valued pythagorean fuzzy multicriteria decision-making. Int J Intell Syst 33(3):653–683
Garg H (2018a) Some methods for strategic decision-making problems with immediate probabilities in Pythagorean fuzzy environment. Int J Intell Syst 33(4):687–712
Garg H (2018b) Linguistic Pythagorean fuzzy sets and its applications in multi attribute decision making process. Int J Intell Syst 33(6):1234–1263
Garg H (2019) Novel neutrality operations based Pythagorean fuzzy geometric aggregation operators for multiple attribute group decision analysis. Int J Intell Syst 34(10):2459–2489
Garg H (2019) New Logarithmic operational laws and their aggregation operators for Pythagorean fuzzy set and their applications. Int J Intell Syst 34(1):82–106
Garg H (2020a) Neutrality operations-based Pythagorean fuzzy aggregation operators and its applications to multiple attribute group decision-making process. J Amb Intell Human Comput 11(7):3021–3041
Garg H (2020b) Linguistic interval-valued Pythagorean fuzzy sets and their application to multiple attribute group decision-making process. In: Cognitive computation. Springer (2020). https://doi.org/10.1007/s12559-020-09750-4
Grabisch M (1996) The application of fuzzy integrals in multi criteria decision making. Eur J Oper Res 89(3):445–456
Grabisch M, Marichal JL, Mesiar R, Pap E (2009) Aggregation functions. In Encyclopedia of mathematics and its applications, no 127. Cambridge University Press
Grabisch M (2016) Set functions. Games and capacities in decision making. Theory and decision library C volume. Springer, p 46
Khan MSA, Abdullah S, Ali A, Amin F, Hussain F (2019) Pythagorean hesitant fuzzy choquet integral aggregation operators and their application to multi-attribute decision-making. Soft Comput 23(1):251–267
Lust T (2015) Choquet integral versus weighted sum in multicriteria decision contexts. In: 3rd international conference on algorithmic decision theory, vol 9346. Springer International Publishing, Lexington, KY, USA, Berlin, pp 288–304
Meyer P, Pirlot M (2012) On the expressiveness of the additive value function and the Choquet integral models. From multiple criteria decision aid to preference learning, Mons, Belgium, pp 48–56
Nguyen XT, Nguyen VD, Nguyen VH, Garg H (2019) Exponential similarity measures for Pythagorean fuzzy sets and their applications to pattern recognition and decision making process. Comp Intell Syst 5(2):217–228
Peng XD, Yang Y (2016) Fundamental properties of intervalvalued Pythagorean fuzzy aggregation operators. Int J Intell Syst 31(5):444–487
Peng XD, Yang Y (2016) Multiple attribute group decision making methods based on Pythagorean fuzzy linguistic set. Comput Eng Appl J 52(23):50–54
Peng X, Garg H (2019) Multiparametric similarity measures on Pythagorean fuzzy sets with applications to pattern recognition. Appl Intell 49(12):4058–4096
Torra V, Narukawa Y (2007) Modeling decisions: information fusion and aggregation operators. Springer, Berlin/Heidelberg, Germany
Ullah K, Mahmood T, Ali Z, Jan N (2020) On some distance measures of complex Pythagorean fuzzy sets and their applications in pattern recognition. Compl Intell Syst 6:15–27
Unver M, Ozcelik G, Olgun M (2018) A fuzzy measure theoretical approach for multi criteria decision making problems containing sub-criteria. J Intell Fuzzy Syst 35(6):6461–6468
Unver M, Ozcelik G, Olgun M (2020) A presubadditive fuzzy measure model and its theoretical interpretation. Turkic World Math Soc J Appl Eng Math 10(1):270–278
Wei GW, Wei Y (2018) Similarity measures of Pythagorean fuzzy sets based on cosine function and their applications. Int J Intell Syst 33(3):634–652
Wei GW, Lu M (2018) Pythagorean fuzzy power aggregation operators in multiple attribute decision making. Int J Intell Syst 33(1):169–186
Yager RR (2013) Pythagorean fuzzy subsets. In: Proceeding of the joint IFSA world congress and NAFIPS annual meeting. Edmonton, Canada, pp 57–61
Yager RR (2014) Pythagorean membership grades in multicriteria decision making. Trans Fuzzy Syst 22:958–965
Yang L, Ha M (2008) A new similarity measure between intuitionistic fuzzy sets based on a Choquet integral model. In: Fifth international conference on fuzzy systems and knowledge discovery, vol 3, pp 116–121
Ye J (2011) Cosine similarity measures for intuitionistic fuzzy sets and their applications. Math Comput Model 53(1–2):91–97
Ye J (2014) Vector similarity measures of simplified neutrosophic sets and their application in multicriteria decision making. Int J Fuzzy Syst 16(2):204–211
Zadeh LA (1965) Fuzzy sets. Inform Control 8(3):338–353
Zeng S, Mu Z, Balezentis T (2018) A novel aggregation method for Pythagorean fuzzy multiple attribute group decision making. Int J Intell Syst 33(3):573–585
Acknowledgments
The authors are grateful to the reviewers for carefully reading the chapter and for offering substantial comments and suggestions which enabled them to improve the presentation.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Singapore Pte Ltd.
About this chapter

Cite this chapter
Türkarslan, E., Olgun, M., Ünver, M., Yardimci, Ş. (2021). Some Trigonometric Similarity Measures Based on the Choquet Integral for Pythagorean Fuzzy Sets and Applications to Pattern Recognition. In: Garg, H. (eds) Pythagorean Fuzzy Sets. Springer, Singapore. https://doi.org/10.1007/978-981-16-1989-2_4
Download citation
DOI: https://doi.org/10.1007/978-981-16-1989-2_4
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-16-1988-5
Online ISBN: 978-981-16-1989-2
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)