
Abstract
Based on the research of information security and business continuity management, a key business node identification model for the business process based on AE-VIKOR (Analytic hierarchy process and Entropy weighting VIKOR, AE-VIKOR) method is proposed. Firstly, the business nodes are obtained based on the business process, and the importance decision matrix of business nodes is constructed by quantifying the evaluation attributes of nodes. Secondly, the attribute weight is improved from subjective and objective dimensions to form the combination weight decision matrix, and the AE-VIKOR method is used to calculate the business importance coefficient to identify the key nodes. Finally, when an information security event occurs in the system, the impact of key business nodes on business continuity is analyzed, and the business continuity risk value is calculated to evaluate the business risk to prove the effectiveness of the model. The experimental results of civil aviation departure control system show that the AE-VIKOR method can effectively identify key business nodes, and the impact of key business nodes on business continuity is analyzed, which further proves the efficiency and accuracy of the model.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Nowadays, with the rapid development of the Internet, related research fields are more concerned about information security and business continuity management recently. The multi system cooperation of smart mobile devices is closely related to its business continuity. Therefore, when an information security event occurs in a system, it may lead to delay or stagnation of business execution, which will inevitably affect business continuity. Based on the management of business continuity, at present, there are many achievements in the research of business continuity security [1,2,3,4,5]. Key business node identification is very important for business recovery which is one of the research hotspots in the field of risk assessment for the business process. Based on information security risk assessment and business continuity management, Torabi et al. [6] put business continuity risk management into the framework of information security risk assessment through business continuity risk analysis. Belov et al. [7] proposed a risk value calculation of the business completion rate by studying the situation of the business resource completion rate and quantitatively assessed the business system risk. Hariyanti et al. [8] proposed a new ISRA (Information security risk assessment) model based on the business process to improve the model based on the organization’s assets. VIKOR (Vise Kriterijumska Optimizacija I Kompromisno Resenje in Serbian) is one of the common methods of multi attribute decision making which is often used in risk assessment [9], economics, management and other hot fields.
The contributions of this paper can be summarized as follows. A key business node identification model for the business process based on AE-VIKOR is proposed. The model mainly focused on as follows: 1) The combined weighting from the subjective and objective dimensions is used to improve the attribute weights of the VIKOR method of multi attribute decision-making. 2) When information security events occur in the system, the model can analyze the impact of key business nodes on business continuity, calculate the risk value of business continuity.
The organization of this paper is described as follows: In Sect. 2, data preparation module and data operation module are described in detail. Decision module and analysis module are expounded in Sect. 3. In Sect. 4, the effectiveness of the model is verified by analyzing the business continuity of the departure business and the loading business. Conclusion is given in Sect. 5.
2 Data Preparation Module and Data Operation Module
The key business node identification model is composed of four modules: data preparation module, data operation module, decision module and analysis module (see Fig. 1). Data preparation module and data operation module are described in detail in Sect. 2.

Key business node identification model
2.1 Data Preparation Module
Through the analysis of the business process, this model extracts all businesses into nodes to form the business node set to be evaluated, which is recorded as M = {n1, n2, n3 … nm}. Three factors are used to evaluate business importance, which are business node relevance, business user, and business priority. The specific process of indicator quantification of the business node importance attribute is as follows.
According to node centrality theory [10], business relevance can be measured according to the direct relationship between other business nodes and the business node, the value of business node relevance is calculated in Eq. (1). The larger the value is, the more important the business node is. In Eq. (1), gi is the ratio of connected nodes number of business node i to total nodes number except for it. hi means nodes number directly connected to node i. m is the total number of business nodes.
In this paper, business user types are divided into staff, ordinary users, both staff and ordinary users, and 1, 2, 3 level is used to assignment for business user types. The larger the value is, the more important the business is. The importance levels for business user types are defined in Table 1.
The higher business priority level, the higher the importance of business. The business priority assignment is based on the service characteristics and application types of the business. The business priority level is divided into 1, 2, 3, and 4 levels. The assignment table is shown in Table 2.
The data preparation module forms the node importance decision matrix X through the quantification of attributes and the nodes obtained. The matrix X is normalized by Eq. (2) for comparison. Where, \( {\text{x}}_{\text{j}}^{ \hbox{max} } \,{ = }\,{\text{max\{ x}}_{\text{i1}} ,\,{\text{x}}_{\text{i2}} ,\,{\text{x}}_{\text{i3}} {\text{\},}}\) \( {\text{x}}_{\text{j}}^{ \hbox{min} } \,{ = }\,{\text{min\{ x}}_{\text{i1}} ,\,{\text{x}}_{\text{i2}} ,\,{\text{x}}_{\text{i3}} {\text{\}.}}\) The standardized matrix is R.
2.2 Data Operation Module
This paper uses the combined weighting to determine the attribute weight to eliminate some subjective influence of attributes and enhance the accuracy of the model.
AHP is used to calculate the subjective weight. Firstly, the business relevance is the local attribute of the business nodes, and its impact is relatively low. Users’ impact is stronger than that of the business relevance, and the impact of the business type is greater than others. Therefore, the comparison of the attribute of node importance evaluation is shown in Table 3. Where, 2, 4 indicates that the influence degree of attribute i and attribute j is between 3, 5. According to the subjective influence of business attributes on business importance, an initial comparison matrix A is constructed. Matrix A is normalized to form matrix B according to Eq. (3) Calculate the sum of each row of matrix B and get the set S is {0.3185, 0.7815, 1.9000}. The set is standardized to get the other set S1 is {0.1062, 0.2605, 0.6333}. The element of set S1 is the subjective weight. After the consistency test, the calculation of consistency test index CI is shown in Eq. (4)–(5). After testing, the subjective weight assignment conforms to the consistency test index. Therefore, the subjective weight of each attribute is obtained which are \( w_{1}^{A} \) = 0.1062, \( w_{2}^{A} \) = 0.2065, \( w_{3}^{A} \) = 0.6333.
Using entropy value to modify the objective weight provides a more reliable basis for the evaluation of business importance. The objective weight is calculated in Eq. (6)–(8).
Where Sij is the proportion of each indicator of each node in Eq. (6). In Eq. (7), ej is the information entropy of the j-th index. The objective weight of each attribute is obtained, which are defined as \( {\text{w}}_{ 1}^{\text{A}} \), \( {\text{w}}_{ 2}^{\text{A}} \), \( {\text{w}}_{ 3}^{\text{A}} \).
Combined weight combines subjective weight and objective weight Firstly, weight matrix Y is constructed based on the subjective and the objective method. The combined weight of attributes is calculated by (9)–(11), which is defined as \( {\text{w}}_{\text{z}}^{\text{A}} \), \( {\text{w}}_{\text{z}}^{\text{A}} \), \( {\text{w}}_{\text{z}}^{\text{A}} \).
\( \lambda_{ \hbox{max} } \), \( \varvec{X}^{\varvec{*}} \) are the largest eigenvalue and the largest eigenvector of respectively in the Eq. (9).The standardized decision matrix C of node importance combined weight is calculated by Eq. (12).
3 Decision Module and Analysis Module
3.1 Decision Module
The business importance coefficient is calculated and sorted based on the AE-VIKOR method in the module. AE-VIKOR method improves the evaluation attribute weight of the VIKOR method by combined weighting in the data operation module. VIKOR method is one of the common methods of the multi attribute decision model. The method considers both the maximum group utility and the minimum individual regret effect of the object, it focuses on ranking and selecting from a set of alternatives, and determines compromise solutions for a problem with conflicting criteria, which can help the decision-makers to reach a final decision. TOPSIS (Technique for Order Performance by Similarity to Ideal Solution) [11] is also one of the classic multi attribute evaluation methods. AE-VIKOR and TOPSIS are compared by experiments. The maximum group utility value is measured by Ui, the minimum individual regret effect value is calculated by Ki, and Qi is decision value calculated by the Eq. (13)–(15), v is the coefficient of decision-making mechanism, v = 1/2.
Where \( U^{*} \, = \,\min_{i} U_{i} \), \( U^{ - } \, = \,\max_{i} U_{i} \), \( K^{*} \, = \,\min_{i} \,K_{i} \), \( K^{ - } = \max_{i} K_{i} \).
AE-VIKOR method is also a compromise ranking method, the feasible solution of which is closest to the ideal solution. Therefore, the AE-VIKOR method is without loss of generality to meet the following two conditions: Condition 1: Acceptable advantage. The first two nodes in sorting are Qi, Qj. The conditions shown in formula (16) need to be met. Condition 2: Acceptable stability. The importance coefficients of key business nodes rank first in Ui, Ki. If the above two conditions are met at the same time, the model recognition results are considered valid. Where m is the number of business nodes.
The value of Qi calculated based on the AE-VIKOR method is the business importance coefficient. The key business node is the largest business importance coefficient. Through the calculation of the AE-VIKOR method, the business importance coefficient is between [0, 1].
3.2 Analysis Module
Information security is closely related to business continuity management in the Internet era. The relationship between information security and business continuity is shown in Fig. 2.

Relationship between information security and business continuity
The business continuity risk value is calculated by combining the importance coefficient of key business according to business user number, business average execution time of, and resource utilization in this paper. The maximum of business user’s numbers, average execution time and resource utilization are respectively set as umax, tmax, rmax. When an information security event occurs, the number of business users, business execution time, and resource utilization rate at i time are defined as ui, ti, ri and the business continuity risk value is calculated by Eq. (17)–(19).
Where, the business importance coefficient is Qi, L is the business continuity risk value. \( \Delta P \) is between 0 and 1, and the business importance coefficient is between 0 and 1, business continuity risk is classified according to business continuity risk value. When the risk value of business continuity is higher than 0.15, it is considered that business continuity is at higher risk. The business risk value is between 0 and 0.15, so the business continuity risk level table is shown in Table 4 below.
4 Experimental Results and Analysis
4.1 Calculate the Business Importance Coefficient
The civil aviation industry is one of the key industries of information security. Therefore, the experimental object is the civil aviation departure control business process. Its business process is shown in Fig. 3.

Departure control business
All businesses in the departure business process are extracted into nodes to form the business node set to be evaluated, which is recorded as N = {n1, n2, n3, n4, n5, n6, n7, n8, n9}.respectively represents every business in departure control system in Fig. 3. The decision matrix of node importance is formed by the node and the attributes of each node. According to the assignment of node attribute indicators in the data module, the assignment of departure business node importance attribute indicators is shown in Table 5 The standardized node importance decision matrix R is formed as follows.
The subjective weight is wA= {0.1062, 0.2605, 0.6333}, which calculated by the AHP method. According to the objective weight calculated by the Entropy method in Sect. 2.2 is wO = {0.3273, 0.3298, 0.3429}, the combined weight of the two is wZ = {0.2228, 0.2756, 0.5016}. The importance coefficient of departure business node is calculated as Di = {0.1975, 0.1464, 0.5199, 1.000, 0.4844, 0.4947, 0.1048, 0.057, 0.1176} by the AE-VIKOR. It can be seen that the most important factor of n4 the node is that check-in is the key business of the departure control system.
4.2 Business Continuity Analysis and Risk Assessment
The maximum number of business users, average execution time, and resource utilization rate of the passenger check-in system at T0 time are respectively corresponding to 1000, 10 s, and 90%. After the information security event occurs in the check-in system at T0 time, the check-in system data within 1 h can be obtained through monitoring. The loading system is specially monitored and obtained to compare with the check-in system. Table 6 shows the execution of the check-in business system after the information security event.
It can be seen from Fig. 4 that the business continuity risk value of check-in business increases rapidly after T0 time, while that of the loading business is relatively slow compared with the check-in business. At T4 time, the check-in business continuity risk is close to the higher risk, and the loading business continuity at T4 time is medium. Therefore, the experiment further proves the validity and accuracy of the model.

Business continuity analysis of check-in and loading business
4.3 Comparison of Key Business Identification Methods
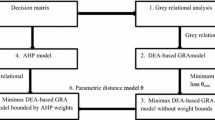
In this paper, the AE-VIKOR method is compared with the other four methods. The calculation method and business node ranking of business nodes are shown in Fig. 5 As can be seen from Fig. 5, the AE-VIKOR method is more accurate than the other four methods.

Different methods used to calculate nodes importance
A combined weight to improve the attribute weight in the AE-VIKOR method used to calculate the business importance coefficient to ensure the accuracy of the results to facilitate the analysis and management of business continuity.
5 Conclusion
The attribute weight is improved by the combined weight and the AE-VIKOR method is used to identify the key business node in this paper. Business continuity risk assessment is carried out by analyzing the key business node’s impact on business continuity. The experimental results show that the key business node identification model based on the AE-VIKOR method is more accurate, and the business continuity risk assessment is carried out reasonably. The next step is to analyze the impact of key business on business recovery priority after information security events occur in the system, and further improve the recognition ability and adaptive ability of the model.
References
Moldagulova, A., Uskenbayeva, R.K., Satybaldiyeva, R.Z., Kamennova, M.S., Kalpeeva, Z.B., Bektemyssova, G.U.: On identification of hybrid business processes for effective implementation in the form of cloud services. In: 2019 19th International Conference on Control, Automation and Systems (ICCAS), pp. 51–54, IEEE, Jeju (2019)
Sherzod, G., Abdukhalil, G., Viktoriya, V.: Formalization of the business process security. In: 2019 International Conference on Information Science and Communications Technologies (ICISCT), pp. 1–3. IEEE, Tashkent (2019)
Ming, Q., Songtao, L.: Overview of system wide information management and security analysis. In: 2017 IEEE 13th International Symposium on Autonomous Decentralized System (ISADS), pp. 191–194, IEEE, Bangkok (2017)
Stergiopoulos, G., Dedousis, P., Gritzalis, D.: Automatic network restructuring and risk mitigation through business process asset dependency analysis. Comput. Secur. 96, 101869 (2020)
Matulevičius, R., Norta, A., Samarütel, S.: Security requirements elicitation from airline turnaround processes. Bus. Inf. Syst. Eng. 60, 3–20 (2018)
Torabi, S., Giahi, R., Sahebjamnia, N.: An enhanced risk assessment framework for business continuity management systems. Saf. Sci. 89, 201–218 (2016)
Belov, V.M., Pestunov, A.I., Pestunova, T.M.: On the issue of information security risks assessment of business processes. In: Proceedings of the 14th International Scientific-Technical Conference on Actual Problems of Electronics Instrument Engineering APEIE, pp. 136–139. IEEE, Piscataway (2018)
Hariyanti, E., Djunaidy, A., Siahaan, D.O.: A conceptual model for information security risk considering business process perspective. In: 2018 4th International Conference on Science and Technology (ICST), pp. 1–6. IEEE (2018)
Yang, J., Han, J., Zhang, X.: Information system security risk assessment based on IDAV multi-criteria decision model. In: 2018 12th IEEE International Conference on Anti-counterfeiting, Security, and Identification (ASID), pp. 121–127. IEEE, Xiamen (2018)
Shen, Y., Gu, C., Zhao, P.: Structural vulnerability assessment of multi-energy system using a pagerank algorithm. Energy Procedia 158, 6466–6471 (2019)
Piwowarski, M., Danuta, M., Małgorzata, Ł., Mariusz, B., Kesra, N.: TOPSIS and VIKOR methods in study of sustainable development in the EU countries. Procedia Comput. Sci. 126, 1683–1692 (2018)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Xie, L., Ni, H., Xu, G., Zhang, J. (2020). A Key Business Node Identification Model for Business Process Based on AE-VIKOR Method. In: Xu, G., Liang, K., Su, C. (eds) Frontiers in Cyber Security. FCS 2020. Communications in Computer and Information Science, vol 1286. Springer, Singapore. https://doi.org/10.1007/978-981-15-9739-8_47
Download citation
DOI: https://doi.org/10.1007/978-981-15-9739-8_47
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-9738-1
Online ISBN: 978-981-15-9739-8
eBook Packages: Computer ScienceComputer Science (R0)