
Abstract
Computer-aided systems are gaining interest in every field over the world. The medical field has also enhanced to a great extent with the use of computer-aided diagnosis. Among the different diseases in the era, breast cancer has shown a rapid hike in the number of deaths. Scoring of nuclear atypia is an efficient method for the prognosis of breast cancer. The biopsy samples taken from the suspicious tissues are analysed under microscope by the pathologists and are graded. But manual grading highly depends on the pathologists and can cause variation in the results. Hence, the requirement of computer-aided systems for grading has increased. Many studies related to nuclear atypia scoring have taken place in the literature based on different algorithms and classifiers. This paper gives an overview of the different studies in the literature, related to nuclear atypia scoring. Various techniques are used for nuclear atypia scoring. Multifarious image processing techniques are used for this. The aim of this study is to analyse these techniques and their results and know the most efficient one from them. Our analysis shows that promising results are achieved by machine learning techniques. Scores obtained using these techniques are comparable to manual grading.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Cancer is one of the most common death-causing diseases in the current era. The disease involves the abnormal growth of cells which divides itself, spreading to other parts of the body. Hence, this growth should be controlled or else it results in death. Some kinds of cancer have rapid growth, whereas others divide at a slow rate. Different types of cancer include breast cancer, prostate cancer, lung cancer, leukaemia, etc. Cancer can be caused due to many reasons. Causes of cancer include consumption of alcohol, smoking, increased body weight, age, the problem with immune systems or even genetics. According to the recent study by the American Cancer Society [26] in 2018, about 1.7 million people were expected to diagnose with cancer, and death of 609,640 was estimated. Since these numbers are huge, the problem has to be solved. Many studies are taking place for the prevention and detection of this disease. Cancer occurs in different stages. It varies from stage 0 to stage 4. Stage defines the size and spread of the tumour. However, the determination of stage is important because it is based on the stage that the treatments and prognosis are determined. If breast cancer is diagnosed in the initial stage, there is a high possibility for a cure. That is, early detection has a high influence on recovery.
Among the different types of cancers, the most common kind of cancer is breast cancer. It is mostly seen in women. According to the study by the World Health Organization (WHO), about 627,000 women in the world die from breast cancer. The cancer is formed in the lobules or ducts of the breast. The symptoms for breast cancer include a lump or mass in the breast, thickness, redness, scaling, swelling, distortion, and more. The main two types of breast cancer are ductal carcinoma and lobular carcinoma. They can be invasive or non-invasive. An invasive carcinoma spreads fast to other tissues. On the other hand, non-invasive carcinoma does not spread from its original tissue. Age, gender, family history, pregnancy, hormones, body weight, etc., can be the reason behind the cause of breast cancer. But the exact reason for breast cancer is still undefined. However, once a patient is diagnosed with cancer, the only solution is to take the treatment as soon as possible. The common treatment involves the lumpectomy and mastectomy. Lumpectomy is the surgical removal of the tumour and the surrounding tissues. On the other hand, a mastectomy involves surgical removal of the breast. Other than the surgery, chemotherapies, radiation therapies, hormone therapies, and other medications are also taken by the patient.

a Manual grading; b Automated grading
Early detection followed by appropriate treatment can help to increase the rate of survival from the disease. Even though there are many technologies for the detection of cancer, a biopsy is used to finalize malignancy. The system focuses on nuclear atypia scoring which is based on the Nottingham grading system. The biopsy samples are graded based on nuclear atypia.
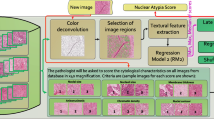
The manual process of grading requires a lot of human effort, and it can vary according to the pathologist. Therefore, computer-aided systems are now gaining interest. Many studies have emerged based on computer-aided systems for breast cancer grading. The grading mainly involves pre-processing, segmentation, feature selection, and classification of the images. Different algorithms are used for each of the stages for obtaining an accurate result.
Figure 1 shows a comparison of stages in the manual and computerized grading system. The manual grading is depicted in Fig. 1a. It begins with the sample collection followed by the preparation of slides. The slides are stained to distinguish the cells under the microscope. These slides are then observed under the microscope by the pathologists and are graded. Figure 1b defines the automated grading. Training and testing are the two phases involved. Each phase comprises pre-processing, segmentation, and feature extraction. The data is trained first to generate a model, and this model is used for testing and grading.
Mammography is one of the most common technologies used for breast cancer detection. It can be used for detecting the disease at an early stage. But the problem was that its results were not perfect. It resulted in many false positives and false negatives [11, 19, 27]. Another technique is ultrasound imaging, which assesses the morphology, orientation, and internal structure of the tumour. It is usually done after mammography. If mammography generates a positive result, the ultrasound imaging is used to detect the size, location, and shape of the tumour. The problems with the machines and other objects result in noise and complicate the process. Magnetic resonance imaging (MRI) is also widely used for detection. From the image, the traces of cancer are identified, if any. An MRI detects cancer more efficiently, compared to mammography and ultrasound [17]. But MRI is too much sensitive and results with many false positives. It also lacks specificity, and it is costly. However, people with a high chance of the disease are recommended to take an annual MRI [26]. Even though there are different methods for breast cancer detection, the final verification has to be done with the help of breast biopsy. In a biopsy, samples of tissues or cells are extracted from the suspicious region, and then a pathologist analyses them through the microscope to check malignancy. The analysis of the biopsy sample is a lengthy process, and there are many methods for it [25]. The most common prognostic determinants for malignancy in a biopsy are lymph node (LN) status, tumour size, and histological grade. Among the three, the most accepted determinant is histological grading which is simple and less expensive. It defines the morphological features of the tumour cells and provides high accuracy results. Hence, the use of histological grading in breast cancer has gained wide acceptance.
But the manual process of breast cancer grading (BCG) [29] requires a large amount of time and effort. It requires the pathologist to examine thousands of slides via a microscope to check malignancy. The analysis is to be carried out by more than one pathologist for the confirmation of the result, and it requires a great amount of human labour. A comparison of manual and automatic grading is given in [27] by F. Schnorrenberg. The accuracy of manual process is affected by the inter–intra observer variation, and the individual nucleus is counted and classified based on the stain intensity. On the other hand, the automated system provides the facility to assess many areas and gives a better result.
As a result, image processing and computer-aided diagnosis (CAD) have received much attention.
Image processing is based on processes of digital images. It is used for classification, feature extraction, pattern recognition, and so on. CAD also contributes to the early detection of breast cancer. It is the use of computer technologies to create technical designs or patterns. Lots of studies have taken place in the literature related to image processing [1, 12, 18, 28] systems in mammography. The mammography images are analysed to identify the mass and calcifications. The same can be used to automate histological grading. Tutac et al. [29] suggest a solution to the automatic breast cancer grading using the Nottingham grading system.
Nottingham grading system [9] is a widely used breast cancer grading system. It analyses the invasive adenocarcinomas based on three components: (1) tubule formation (2) mitotic count, and (3) nuclear atypia (NA). Tubule formation gives the degree of glandular differentiation in invasive ductal carcinoma. Mitotic count refers to the rate of spreading of cancer cells. Nuclear atypia refers to the difference in the structure of cell nuclei compared to the original cells. There are many studies that make use of the Nottingham grading system for breast cancer grading [6, 24]. The three components in NGS are given a score of 1, 2, or 3. At the end, the three grades are added together, providing a minimum score of 3 (\(1+1+1\)) and a maximum score of 9 (\(3+3+3\)). These scores are then converted to histological grades. Besides the combined use of the three components, each of them can be used individually for breast cancer detection. In tubule formation, the cells form a tubular structure. It contains a clear white blob, called lumina, surrounded by tubular structures. The smaller the number of tubular structures, the higher will be the grade. In [23], Nguyen et al. define the segmentation of the tubule structure for grading. The system identifies all the nuclei and lumens from the images and then classifies the malignant ones using a random forest classifier. On the other hand, Ko et al. in [16] suggest a method for tubule detection. It initially detects ROIs at the lesion areas. Then, it segments the gland and lumen. Later, the gland features, lumen features, and texture features are extracted and are then extracted using SVM classifier.
Whereas mitotic count relies on the rate of cell division. Mitosis is the process in which a cell is broken down to identical daughter cells. The counts of these daughter cells are then taken. They are found less in regions of tubule formation. Nateghi et al. [22] describe the use of a CAD system for mitosis detection. The paper suggests the use of a maximum likelihood algorithm to estimate the parameter of mitosis. Candidates are detected using this algorithm. The process is then followed by feature extraction and classification. The classification is done using the SVM classifier. Logambal and Saravanan in [20] and Amitha et al. in [2] use the SVM classifier for mitosis detection.
2 Methodology
There are many studies in the literature based on tubular formation and mitotic count, whereas the studies based on the third component, nuclear atypia (NA), are found less in the literature. Nuclear atypia differentiates the nuclei based on its size and shape. The nuclei are compared with original cells to determine the variation. Compared to these two methods, nuclear atypia (NA) gives an identical result for grading. In nuclear atypia scoring (NAS), the score of nuclear atypia is used for histological grading. The size, shape, and the chromatin distribution of the nucleus are analysed and are given a score accordingly. A score of 1 indicates low nuclear atypia (highly differentiated) and 3 indicate a strong nuclear atypia (rarely differentiated).
As specified before, automated grading can be done based on CAD. Chekkoury et al. in [4] suggest a system using CAD for malignancy detection. It differentiates the H&E stained biopsy samples based on malignancy. The slides are stained with haematoxylin and eosin (H&E) for microscopic evaluation. The method involves three stages: (1) image processing, (2) feature extraction, and (3) classification. The systems extract morphological, textual, and topological features for processing and are then classified to benign or malign using SVM classifier.
All these studies are carried out on Whole-Slide Histopathological Images. There are many technologies and algorithms of CAD and image processing in the literature, which are used in combination to grade the histological images. Some methods segment the image into regions for further processing. Images with high resolution are needed to be segmented for efficient processing [5, 21]. At the same time, images are also processed without segmentation.
Cosatto et al. in [5] describe methods of analysing the histological micrographs for grading of nuclear pleomorphism. The process is initiated with the colour separation process. Then, the nuclei that are larger than the normal threshold are detected and features are extracted using Hough transform. Then, an active contour model (ACM) is used for the purpose of segmentation of images. The outlines of the nuclei are then extracted for further classification. The shape features and texture features are taken into account. The system is then trained using support vector machine (SVM) classifier.
Lu et al. in [21] segmented the images into patches, after the process of stain normalization and separation. Textual and morphological features are then extracted, and histograms for each feature are constructed. Later features are extracted from each of the segment, and the support vector machine (SVM) classifier is used for the task of classification. It inferred that textual features are likely to contribute more classification process accuracy. Use of deep learning for nuclear pleomorphism was discussed in [31]. It focuses on two tasks in which one is the nuclear atypia scoring. It makes use of multi-resolution convolutional network (MR-CN) for processing. The method resulted in an accuracy of 79.87%.
The idea of a novel image level descriptors is presented in [15]. The images are segmented into regions. The region covariance (RC) descriptors are calculated for each region and are combined to a single form using the geodesic mean of region covariance (RC) or gmRC. This symmetric positive definite (SPD) matrix is derived and is plotted on a Riemannian manifold. For the purpose of classification, they used different machine learning classifiers like decision tree (DT) classifier, RUSBoost, kNN, linear discriminant analysis (LDA), and quadratic discriminant analysis (QDA). The result was derived with an accuracy of 83.3% under G-kNN classifier.
As defined in [15], the idea of SPD matrices and Riemannian manifold is used in [8]. But it performs sparse coding and dictionary learning on the SPD matrices for the task of classification. The experiment resulted in a higher accuracy of 87.92%. Apart from this, Dalle et al. [7] suggested a method that automatically selects and segments the critical cells in place of selecting all the cells and thus reducing the expense. It adapts the idea of region of interest (ROI) for cell selection and classification. It resulted in a minimum error rate of 7.8%. Whereas Faridi et al. [10] perform manual grading of nuclear atypia, after efficient pre-processing. While Dalle et al. [7] dealt with the critical cells, Faridi et al. in [10] suggest detecting the cancerous cells and deriving its exact outline. The segmentation is done in two ways: by detecting the centroid and cell boundary of the nuclei. The paper resulted in an accuracy of 87%.
3 Dataset
Most of the studies related to nuclear atypia scoring are done on the MITOS-ATYPIA-14 dataset [8, 10, 15, 21, 31]. This was a challenge conducted by the International Conference on Pattern Recognition (ICPR). It was a contest using breast cancer histological images. The contest had two parts: mitotic count and nuclear pleomorphism. The dataset contains haematoxylin and eosin (H&E) stained slides. These are scanned using two slide scanners. They are Hamamatsu Nanozoomer 2.0-HT and the Aperio Scanscope XT. Images of 10\(\times \), 20\(\times \), and 40\(\times \) magnification are taken. The dataset is divided into a training set and testing set. 80% is set aside for training and the rest for testing. Figure 2 shows the sample images in the dataset with nuclear atypia score (NAS) score 1, 2, and 3.

Sample dataset images with NAS \(=\) 1, NAS \(=\) 2 and NAS \(=\) 3

Taxonomy
4 Taxonomy
Figure 3 depicts the taxonomy on different techniques used in different stages of the grading. Pre-processing, segmentation, feature selection, and classification are the important stages in the computer-aided diagnosis [3]. Different methods can be adopted for each stage, and they are used in different combinations to provide better result.
4.1 Pre-processing
Pre-processing aims at the removal of unwanted distortions and highlighting the required features. It performs noise reduction and background removal. There are many pre-processing methods defined in the literature. It is performed prior to segmentation and detection. Different pre-processing techniques used for image processing. According to Irshad et al. [13], pre-processing methods are illumination normalization, colour normalization, noise reduction, image smoothing, and ROI detection. By illumination normalization, it means to correct the illumination of the image using white shading correction or by deriving its pattern from a set of images. Colour normalization techniques include histogram or quantile normalization. It is mainly focused on stain removal because the samples we take are stained with haematoxylin and eosin (H&E) dyes. Noise reduction aims at minimizing unwanted noise and artefacts. It uses morphology for this purpose. Region Of interest (ROI) plays simultaneously with noise reduction. Techniques like thresholding and clustering are used for this purpose. Cossato et al. [5] and Dalle et al. [7] used pre-processing for ROI detection. On the other hand, Khan et al. [15] and Das et al. [8] used stain normalization. Bilateral filtering was used by Faridi et al. [10], which is the same as image smoothing or noise reduction.
4.2 Segmentation
Segmentation is required to divide the images into smaller regions. The images can be of high resolution, and sometimes it is required to break it down to patches. The traditional image processing techniques for segmentation are specified the in paper by Irshad et al. [13]. They are thresholding, morphology, region growing, watershed, ACM, K-means clustering, probabilistic models, and graph cuts. Thresholding refers to the process of converting an image to a binary form. It assigns each pixel a value of 0 or 1 depending on a threshold value. Morphology processes the image as geometrical structures based on the morphological features. Region growing is a segmentation method which initially identifies the seed point and then classifies its neighbouring pixels. Watershed is also a segmentation method which begins from a particular pixel. It mainly aims at dividing the foreground and background image. Veta et al. [30] suggest the use of watershed for segmentation. It initially processes the image using region of interest (ROI) and is then segmented. Active contour model (ACM) is used to obtain the contour of objects using the gradient information. It is also called deformable models. It is also used to identify the nuclei boundary in nuclei segmentation. Jing et al. [14] suggest the use of a hybrid ACM for segmentation. The K-means clustering divides the image into k clusters iteratively. The probabilistic model is an extension of K-means clustering. And finally, graph cut considers the image as a weighted undirected graph, and a certain set of algorithms are used for segmentation.
Nguyen et al. in [23] and Cosatto et al. in [5] use an ACM for segmentation. On the other hand, Dalle et al. [7] segment the image using polar transform segmentation. It segments on the basis of polar coordinates. Xu et al. [31] use convolution network, and Khan et al. [15] use HyMap. HyMap stands for a hybrid magnitude-phase approach. Among all these, ACM was found to have a better result. Table 1 summarizes some of the techniques used for segmentation.
4.3 Feature Selection
Feature selection involves the extraction of cytological features, morphological features, texture features, topological features, and more [3]. Cytology features comprise size and shape. Morphological features detect shape and margin. Texture features indicate the pattern of nuclei tissue. Similarly, there are many features. Table 2 lists the different types of features and their description. Figure 4 shows the different features that can be extracted from the image in the MITOS-ATYPIA1-14 dataset. They include the nuclei size, anisonucleosis, nucleoli size, chromatin density, nuclei contour, and membrane thickness.

Features
4.4 Classification
Features extracted are given as input for classification. The most commonly used classification is the SVM classifier. SVM with ACM resulted in high accuracy of 89% [5]. Deep learning has also been widely used in classification. Studies infer that deep learning has a better impact on classification [31]. Other algorithms used were G-kNN [15] and KSCDL [7]. Table 3 lists out the different techniques used in different stages in different literature studies.
5 Conclusion
In this paper, we reviewed the different techniques used in literature for nuclear atypia scoring. The studies made use of different techniques for better results. However, the CAD systems has highly influenced the field of breast cancer detection. Many methodologies and techniques have been suggested in the literature for efficient grading using CAD systems. In the whole process, the analysis of biopsy sample is a crucial step in grading of cancer. It is based on this grading that further procedures are determined. Each stage in processing is important, and hence, there are related studies for each.
References
Abdallah YM, Elgak S, Zain H, Rafiq M, Ebaid EA, Elnaema AA (2018) Breast cancer detection using image enhancement and segmentation algorithms. Biomed Res 29(20):3732–3736
Amitha H, Selvamani I, Dhas DAS (2017) Development of computer aided system for detection and classification of mitosis using SVM. In: 2017 international conference on inventive computing and informatics (ICICI). IEEE, pp 954–958
Aswathy M, Jagannath M (2017) Detection of breast cancer on digital histopathology images: present status and future possibilities. Inform Med Unlocked 8:74–79
Chekkoury A, Khurd P, Ni J, Bahlmann C, Kamen A, Patel A, Grady L, Singh M, Groher M, Navab N, et al (2012) Automated malignancy detection in breast histopathological images. In: Medical imaging 2012: computer-aided diagnosis, vol 8315. International Society for Optics and Photonics, p 831515
Cosatto E, Miller M, Graf HP, Meyer JS (2008) Grading nuclear pleomorphism on histological micrographs. In: 2008 19th international conference on pattern recognition. IEEE, pp 1–4
Dalle JR, Leow WK, Racoceanu D, Tutac AE, Putti TC (2008) Automatic breast cancer grading of histopathological images. In: 2008 30th annual international conference of the IEEE engineering in medicine and biology society. IEEE, pp 3052–3055
Dalle JR, Li H, Huang CH, Leow WK, Racoceanu D, Putti TC (2009) Nuclear pleomorphism scoring by selective cell nuclei detection. In: WACV
Das A, Nair MS, Peter SD (2018) Sparse representation over learned dictionaries on the Riemannian manifold for automated grading of nuclear pleomorphism in breast cancer. IEEE Trans Image Process 28(3):1248–1260
Elston CW, Ellis IO (2002) Pathological prognostic factors in breast cancer. I. The value of histological grade in breast cancer: experience from a large study with long-term follow-up. Histopathology 1991; 19; 403–410: author commentary. Histopathology 41(3a):151
Faridi P, Danyali H, Helfroush MS, Jahromi MA (2016) An automatic system for cell nuclei pleomorphism segmentation in histopathological images of breast cancer. In: 2016 IEEE signal processing in medicine and biology symposium (SPMB). IEEE, pp 1–5
Guo R, Lu G, Qin B, Fei B (2018) Ultrasound imaging technologies for breast cancer detection and management: a review. Ultrasound Med Biol 44(1):37–70
Guzmán-Cabrera R, Guzmán-Sepúlveda J, Torres-Cisneros M, May-Arrioja D, Ruiz-Pinales J, Ibarra-Manzano O, Aviña-Cervantes G, Parada AG (2013) Digital image processing technique for breast cancer detection. Int J Thermophys 34(8–9):1519–1531
Irshad H, Veillard A, Roux L, Racoceanu D (2013) Methods for nuclei detection, segmentation, and classification in digital histopathology: a review-current status and future potential. IEEE Rev Biomed Eng 7:97–114
Jing J, Wan T, Cao J, Qin Z (2016) An improved hybrid active contour model for nuclear segmentation on breast cancer histopathology. In: 2016 IEEE 13th international symposium on biomedical imaging (ISBI). IEEE, pp 1155–1158
Khan AM, Sirinukunwattana K, Rajpoot N (2015) A global covariance descriptor for nuclear atypia scoring in breast histopathology images. IEEE J Biomed Health Inform 19(5):1637–1647
Ko CC, Cheng CY, Lin CH (2016) A computer-aided grading system of breast carcinoma: scoring of tubule formation. In: 2016 30th international conference on advanced information networking and applications workshops (WAINA). IEEE, pp 918–923
Lehman CD, Schnall MD (2005) Imaging in breast cancer: magnetic resonance imaging. Breast Cancer Res 7(5):215
Li Y, Chen H, Cao L, Ma J (2016) A survey of computer-aided detection of breast cancer with mammography. J Health Med Inf 4(7)
Løberg M, Lousdal ML, Bretthauer M, Kalager M (2015) Benefits and harms of mammography screening. Breast Cancer Res 17(1):63
Logambal G, Saravanan V (2015) Cancer diagnosis using automatic mitotic cell detection and segmentation in histopathological images. In: 2015 global conference on communication technologies (GCCT). IEEE, pp 128–132
Lu C, Ji M, Ma Z, Mandal M (2015) Automated image analysis of nuclear atypia in high-power field histopathological image. J Microsc 258(3):233–240
Nateghi R, Danyali H, Sadegh Helfroush M, Tashk A (2014) Intelligent cad system for automatic detection of mitotic cells from breast cancer histology slide images based on teaching-learning-based optimization. Comput Biol J 2014
Nguyen K, Barnes M, Srinivas C, Chefd’Hotel C (2015) Automatic glandular and tubule region segmentation in histological grading of breast cancer. In: Medical imaging 2015: digital pathology, vol 9420. International Society for Optics and Photonics, p 94200G
Petushi S, Garcia FU, Haber MM, Katsinis C, Tozeren A (2006) Large-scale computations on histology images reveal grade-differentiating parameters for breast cancer. BMC Med Imaging 6(1):14
Rakha EA, Reis-Filho JS, Baehner F, Dabbs DJ, Decker T, Eusebi V, Fox SB, Ichihara S, Jacquemier J, Lakhani SR et al (2010) Breast cancer prognostic classification in the molecular era: the role of histological grade. Breast Cancer Res 12(4):207
Society AC (2017) Breast cancer facts & figures 2017–2018
Tang J, Rangayyan RM, Xu J, El Naqa I, Yang Y (2009) Computer-aided detection and diagnosis of breast cancer with mammography: recent advances. IEEE Trans inf Technol Biomed 13(2):236–251
Tang J, Rangayyan RM, Xu J, El Naqa I, Yang Y (2009b) Computer-aided detection and diagnosis of breast cancer with mammography: recent advances. IEEE Trans Inf Technol Biomed 13(2):236–251
Tutac AE, Racoceanu D, Putti T, Xiong W, Leow WK, Cretu V (2008) Knowledge-guided semantic indexing of breast cancer histopathology images. In: 2008 international conference on biomedical engineering and informatics, vol 2. IEEE, pp 107–112
Veta M, Van Diest PJ, Kornegoor R, Huisman A, Viergever MA, Pluim JP (2013) Automatic nuclei segmentation in H&E stained breast cancer histopathology images. PLoS ONE 8(7):e70221
Xu J, Zhou C, Lang B, Liu Q (2017) Deep learning for histopathological image analysis: towards computerized diagnosis on cancers. In: Deep learning and convolutional neural networks for medical image computing. Springer, Cham, pp 73–95
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Shaji, S., Sreeraj, M., Joy, J., Kuriakose, A. (2020). On Computer-Aided Diagnosis of Breast Cancers Using Nuclear Atypia Scoring. In: Jayakumari, J., Karagiannidis, G., Ma, M., Hossain, S. (eds) Advances in Communication Systems and Networks . Lecture Notes in Electrical Engineering, vol 656. Springer, Singapore. https://doi.org/10.1007/978-981-15-3992-3_57
Download citation
DOI: https://doi.org/10.1007/978-981-15-3992-3_57
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-3991-6
Online ISBN: 978-981-15-3992-3
eBook Packages: EngineeringEngineering (R0)