
Abstract
Sentiment analysis on text mining has a vital role in the process of review classification. Text classification needs some techniques like natural language processing, text mining, and machine learning to get meaningful knowledge. This paper focuses on performance analysis of text classification algorithms commonly named Support vector machine, random forest and extreme Gradient Boosting by creating confusion matrices for training and testing applying features on a product review dataset. We did comparison research on the performance of the three algorithms by computing the confusion matrix for accuracy, positive and negative prediction values. We used unigram, bigram and trigrams for the future extraction on the three classifiers using different number of features with and without stop words to determine which algorithms works better in case of text mining for sentiment analysis.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Recently, researches about natural language processing and text mining became very important because of the increase of sources that gives electronic datasets according to [1] many text mining procedures are required to analyze data on social media and e-commerce websites for the identification of different patterns on texts. We classify the documents based on categories that are predefined for text classification. We use a corpus to be the primary structure for management and representation a collection of the dataset. All preprocessing data techniques can be performed on the corpus. The performance of a document classification technique is acquired by creating the confusion matrix on training and testing datasets. The latest news and discoveries in the field of exchange of information and opinions carve the way of computer applications designed for the analysis and detection sentiments expressed on the Internet. Presented in the literature under the name opinion mining and sentiment analysis, sentiment analysis is used among others for the detection of opinions on websites and social networks, the clarification on the behavior of consumers, product recommendation and explanation of the election results. It is used to look for evaluative texts on the Internet such as criticism and recommendations and analyze automatically or manually feelings that are there expressed to understand public opinion better. It has already been demonstrated in previous studies that feelings of Analysis prove particularly attractive for those who have an interest in knowing the public, it whether for personal, commercial, or political reasons. Thus, many systems Autonomous have already been developed for automatic sentiment analysis. In this research paper, we made a comparative study of three machines learning algorithms which are Support vector machine, random forest, and extreme Gradient Boosting for classification and made the confusion matrix results.
2 Literature Reviews
The most used algorithm for document classification is called Support Vector Machines. The main feature of Support Vector Machines is to build a hyperplane between the classes that provide maximum margins and use these cut off points for text classification. For feature two-dimensional case the created hyper plane is a straight line. The main advantage of Support Vector Machines is that it can create datasets with many attributes with less overfitting than other methods [2, 5]. Nevertheless, SVM classification has speed limitations during both training and testing phases [3]. XGBoost was designed for speed and performance using gradient-boosted decision trees. It represents an element for machine boosting, or in other words applying to boost the machines, initially made by Tianqi Chen [4] and further taken up by many developers. RF is an ensemble of classification that proceed by voting the result of individual decision trees. Several techniques and methods have been suggested by researchers in order to grow a random forest classifier [7]. Among these methods, the authors method has gained increasing popularity because it has higher performance against other methods [8].
In [10], the author considered sentimental classification based on categorization aspect with negative sentiments and positive sentiments. They have experimented with three different machine learning algorithms which are Naive Bayes classification, Maximum Entropy and Support Vector machine, classification applied over the n-gram techniques.
In [6] they have used balanced review dataset for training and testing, to identify the features and the score methods to determine whether the reviews are negative or negative. They used classification to classify the sentences obtained from web search through search query using the product name as a search condition.
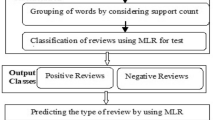
3 Implementation Procedure
(See Fig. 1).

Implementation flowchart
3.1 Dataset
(See Table 1).

3.2 Feature Extraction
Feature extraction relates to dimension reductions. It is a technique for dimension reduction that can reduce an initial dataset into groups for data processing. When the dataset one usually input to an algorithm is being processed, it can be converted into less data and information. This procedure is named feature extraction.
The extracted features ought to contain all needed information from the inputted data so that the experimentation procedure can be done by using reduced representation instead of the complete initial dataset.
Term occurrence (To): \( {\text{To}}_{{{\text{t}},{\text{d}}}} \) of term \( {\text{t}} \) in document \( {\text{d}} \) is defined as the number of times that a term \( {\text{t}} \) occurs in document \( {\text{d}} \).
Term Frequency: \( {\text{To}}_{{{\text{t}},{\text{d}}}} \) is the normalized form of \( {\text{To}}_{{{\text{t}},{\text{d}}}} \) to prevent a bias towards very long documents in order to measure the importance of the term \( {\text{t}} \) within the particular document \( {\text{d}} \).
Inverse Document Frequency (\( lef_{t} \)): Estimate the rarity of a term in the whole document collection. (If a term occurs in all the document, 0 will be the Tfidf.)
-
With \( \left| D \right| \): The total number of documents in the corpus
-
\( \left| {\left\{ {d:t \in d} \right\}} \right| \): The number of the document where the term \( t \) appears i.e. (\( n_{t,d} \ne {\mathbf{0}} \)).
Term Frequency - Inverse Document Frequency ( \( TFidf_{t,d} \) ):
Finally, the tf-idf of the term \( t \) in document \( d \) is computed as follows:
Evaluation Method:
-
Precision: the Precision is the fraction of retrieved values that are relevant. It encompasses all retrieved values and only considers the topmost results returned by the system at a cutt-off point. This kind of measure is named Precision [9].
$$ Precision = \frac{relevant\,value\, + \,retrevied\,value}{retrevied\,value } $$ -
Recall: Recall is the fraction of the relevant value plus de retrieved value divided by the relevant value. In the classification binary, recall is called sensitivity [9]. It is trivial to get the recall of 100% by returning all values in response to the query. Recall equation is defined by:
$$ recall = \frac{relevant\,value\, + \,retrevied\,value}{relevant\,value } $$ -
F1-score: F1 score can be seen as a the average weight of the precision and recall, the F1 score task 1 as best value and the 0 as least value. The contribution of the precision and the recall to the F1 score are equal. The formula for the F1 score is:
$$ F1\,score = 2\,*\,\frac{precision\,*\,recall}{precision\, + \,recall } $$
3.3 Confusion Matrix
The methods for the classification of the review dataset can be obtained by the terms frequencies of correctness by computing statistical measures that are True Positives, True Negatives, False Positive and False Negatives. These are the elements of the Confusion Matrix which is a table that has been generated for a classifier on a binary dataset and can be used to justify the performance of a classifier.
Precision and Recall performances of their experimentation have been tested so that they can predict the false data and the correct data. The assessment is made with Confusion Matrices in which True Positive rate is a definite class and it is considered a positive class. True Negative rate is considered a class negative. False Positive rate is a negative class Classified as a positive and neutral classes, False Negative rate is a definite class that is classified as a negative and neutral class.
3.4 Classification Model
The way the dataset was used in the model of our experiment is represented by the classification methodology in Fig. 2 as well as the flow of work chart in Fig. 3 This review dataset included test and train data types. Both datasets were used in our model. The dataset was split into test and train type datasets. Both datasets were first concatenated to make the data into one file. Python was used as the environment in which this combined data had to run. Moving further, the XGBoost, RF and SVM packages were downloaded on the Anaconda software, which has in-built packages. Using Python, the required packages had to be called. The dataset was opened on the Python on jupyter notebook platform and, by setting various parameters related to, the code was run on the three machine learning algorithms on a product review dataset. The results included confusion matrix, Precision, accuracy and we used matplotlib to draw the results.

XGBoost classifier confusion matrix

Support vector machine confusion matrix

Random forest classifier confusion matrix
4 Results
In this part we presented the best results for the confusion matrices of our implementation which is for the bigram with stop words using 200 features.



For this research we did the confusion matrix using the unigram, bigram and trigram for the entire three-machine learning algorithm. We used different sets of selected features with and without stop words respectively 100, 200, 300.
From all these 3 classifiers we choose the one that has the highest accuracy and presented it in the figure. Our results have shown that the classifier works better for bigram with stop words using 200 features.
5 Comparative Analysis
After plotting this confusion matrix, the values which are obtained for all our four classes are used to calculate the accuracy of the algorithm’s prediction. As a result, the bar graph that has been plotted are for the actual results and predicted results for all classes that are positive, negative, and neutral (Fig. 5).

Confusion matrices bar plot
Confusion matrices of all the algorithms been obtained, we calculated the score for the accuracy. The best performing algorithm will be best at predicting and that model will be considered for further for the Sentiment analysis tasks. We did a comparative analysis for the three machine learning algorithms, and the results are shown in Fig. 4. On top as per the results obtained, the support vector machine is getting the lowest accuracy, and the random forest comes on the second position. As per the results, the XGBoost is getting the highest accuracy. The calculation of accuracy value of Analysis towards the SVM method’s result that was done using need to have the accuracy, Precision, and recall performance evaluation from the experiment with the confusion matrix method. The evaluation done by using Confusion Matrix includes the following indicators: True Positive Rate (TP rate), True Negative Rate (TN Rate), False Positive Rate (FP Rate) and False Negative Rate (FN rate). The TP rate is the percentage of the positive class, which was classified as the positive class, whereas the TN rate is the percentage of the class negatively classified as a negative class. FP rate is class negative, which is classified as the positive class. The FN rate is a class positive that is classified as a negative class.
6 Conclusion
In Sum, a comparative analysis of the performance of the support vector machine, random forest, XGBoost review classification techniques is presented in this paper. All the results were found using the Python package and the implementation of the document classification techniques was done using the anaconda Jupiter notebook libraries. Sentimental Analysis of reviews Classification Algorithms using Confusion Matrix indicated that XGBoost has a better performance better classification than support vector machine and random forest. There is a large need in the industry for use of Sentiment Analysis because every company wants to know how consumers feel about their services and products. In future work, different types of approaches, such as machine learning and products reviews should be combined in order to overcome their challenges and improve their performance by using their merits. In order to get a better understanding of natural language processing, a complete knowledge as well as reasoning methods that originates in human thoughts and psychology will be needed.
References
Irfan, R., et al.: A survey on text mining in social network. Knowl. Eng. Rev. 30(2), 157–170 (2015)
Nugroho, A.S., Witarto, A.B., Handoko, D.: Support Vector Machine Teoridan Aplikasinya dalam Bioinformatika 1 (2003)
Kim, J., Kim, B.-S., Savarese, S.: Comparing image classification methods nearest neighbor, support vector machines. Applied Mathematics in Electrical and Computer Engineering. ISBN 978-1-61804-064-0
Brownlee, J.: A gentle introduction to XGBoost for applied machine learning. Mach. Learn. Mastery. http://machinelearningmastery.com/gentle-introduction-xgboost-applied-machine-learning/. Accessed 2 March 2018
Xia, R., Zong, C., Li, S.: Ensemble of feature sets and classification algorithms for sentiment classification. Inf. Sci. 181(6), 1138–1152 (2011)
Dave, K., Lawrence, S., Pennock, D.M.: Mining the peanut gallery: opinion extraction and semantic classification of product reviews. In: Proceedings of the 12th International Conference on World Wide Web, pp. 519–528. ACM (2003)
Dietterich, T.G.: An experimental comparison of three methods for constructing ensembles of decision trees: bagging, boosting, and randomization. Mach. Learn. 40(2), 139–157 (2000)
Banfield, R.E., Hall, L.O., Bowyer, K.W., Kegelmeyer, W.P.: A comparison of decision tree ensemble creation techniques. IEEE Trans. Pattern Anal. Mach. Intell. 29(1), 173–180 (2007)
Tang, D., Wei, F., Yang, N., Zhou, M., Liu, T., Qin, B.: Learning sentiment-specific word embedding for twitter sentiment classification (2014)
Pang, B., Lee, L.: A sentimental education: sentiment analysis using subjectivity summarization based on minimum cuts. In: ACL 2004 Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics (2004). Article no. 271
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2019 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Gaye, B., Wulamu, A. (2019). Sentiment Analysis of Text Classification Algorithms Using Confusion Matrix. In: Ning, H. (eds) Cyberspace Data and Intelligence, and Cyber-Living, Syndrome, and Health. CyberDI CyberLife 2019 2019. Communications in Computer and Information Science, vol 1137. Springer, Singapore. https://doi.org/10.1007/978-981-15-1922-2_16
Download citation
DOI: https://doi.org/10.1007/978-981-15-1922-2_16
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-1921-5
Online ISBN: 978-981-15-1922-2
eBook Packages: Computer ScienceComputer Science (R0)