
Abstract
Although the use of the convolutional neural network (CNN) improved the accuracy of object recognition, it still had a long-running time. In order to solve these problems, the training and testing datasets were split at four different proportions to reduce the impact of inherent error. Using model fine-tuning, the model converged in a small number of iterations, and the average recognition accuracy of BWN test can reach 96.8%. In the segmented dataset, the recognition accuracy of the former was 4.7 percentage points higher than the latter by comparing color dataset and grayscale dataset, which proved that a certain amount of color features will have a positive impact on the model. The segmented dataset was 0.9 percentage points higher than the color dataset; it shows that the model focused more on features of contour and texture by eliminating the background of images. The experiments showed that the binarized convolutional neural network can effectively improve recognition efficiency and accuracy compared with traditional methods.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Plant diseases are one of the three natural disasters in China. In China, more than 250 billion kg of grain, fruits, vegetables, oil, and cotton is lost every year.
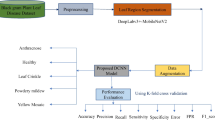
Visual inspection is one of the main traditional methods for diagnosing plant diseases. However, there are two problems: The judgments made by farmers based on experience are not all correct and the situation of plants will be worse without timely and effective treatment for diseases [1]. In order to realize the diagnosis of agricultural diseases rapidly and accurately, researchers have explored methods for identifying multiple plant diseases [2], using machine learning and image processing technology. Convolutional neural network is good at extracting the features of contour and texture of leaves. Generally speaking, the deeper the network, the more the parameters and the larger models. It spends a long time to classify objects. In order to solve these problems, this paper proposes an effective way to classify plant diseases by using binarized convolutional neural networks. It aims to speed up the operation by binarizing the parameters.
2 Related Work
Kan et al. [3] extracted the contours and texture features of the leaves by radial basis function (RBF) neural network. The average recognition rate is 83.3%. Tan et al. [4] can effectively identify lesion area of soybean by calculating the color value of leaves and creating a multilayered BP neural network. The average recognition accuracy can reach 92.1%. Zhang et al. [5] used the cloning algorithm and K-nearest neighbor algorithm to classify leaves, which achieved a recognition rate of 91.37%. Wang et al. [6] used the support vector machine (SVM) to identify the leaves; the accuracy of the classifier can reach 91.41%.
Dyrmann et al. [7] used convolutional neural networks to classify plant images taken with mobile phones, and the average recognition accuracy reached 86.2%. Mohanty et al. [8] carried out experiments on 26 diseases of 14 kinds of plant; they choose two models, three datasets, and five datasets with different proportions, which also achieved good results. Lee et al. [9] explored how the CNN extracts features of leaves. They tested different methods and contrasted various experimental results. The results show that the CNN has a better effect on classification.
3 Dataset
This paper obtained 54,306 leaf images from PlantVillage by color, grayscale, and segmentation, which contains a total of 38 plant types. According to the number of different types of leaves in the dataset, the number of different kinds of leaf images ranges from 64 to 1166. In order to make up for the shortcomings, this paper expands the dataset by enhancing the exposure of the blade, changing the color of the image, and rotating the image. Rotating the image is to eliminate the effects of inherent bias [10]. Then, the images are labeled by category, and center cropped to a size of 224 × 224.
4 Convolutional Neural Networks
Generally speaking, to classify two objects there are two steps: data forward transmission and weight updating. When starting to train a model, there are two choices: one is to completely reset the parameters and train from scratch; the other is model fine-tuning. And the latter was used in this paper. Generally, the basic structure of CNN includes a feature extraction layer and a feature mapping layer. The former includes a convolution layer and a pooling layer, where each neuron is connected to the acceptance domain of the previous layer, and then extracts features of that acceptance domain [11]. The process of forward transmission is shown in Formula 1.
The back-propagation process is actually a process of weight update. In this paper, SGD and Adam are used to update the weight. The process of feature extraction and weight update is continuous, until the global optimal solution is found. In most experiments, the results are local optimum; it is necessary to adjust the learning rate and select the loss function, so that the network can find the global optimum solution.
The parameter update is shown in Formula (2).
5 Binarized Convolutional Neural Network
In the article [12], the parameters with single-precision floating point are converted into parameters that only occupy 1 bit, which theoretically reduces the memory space by 32 times. Moreover, the speed of the model is accelerated to about twice as fast. Symbolic functions can be expressed as:
The binarized convolution neural network converts the weights and the activation values of hidden layers into 1 or −1. There are two ways of conversion: deterministic method and stochastic method. The former is simple and intuitive. If the weight or activation value is greater than 0, it is converted to 1; if it is less than 0, it is converted to −1. The latter calculates a probability p for the input. When p is greater than a threshold, it is +1, otherwise it is −1. Since the random numbers generated by hardware, which is more difficult to implement. Therefore, the first method is adopted in this paper.
In this paper, we take a method of approximating the real weights by using a binarized weight B and a scale factor α. The process of conversion is shown in Formula (4), where ⊕ represents the convolution operation of input and binarization weights.
The binarized VGG16 network is used for experiments in this paper. Same as ordinary convolutional neural networks, the binarized network also includes the input layer, the hidden layer, and the output layer. The hidden layer includes convolution layer and pooling layer, where binarized convolution and pooling operation are used. The forward transmission process of the binary network can be divided into four steps: first let the input pass through a Batch Normal, then binarize the input value, and binary convolution and pooling are used. Finally output the classification through a classifier. The weight is updated with full precision during the training process.
The forward transmission of binarized network:
The process of binarized model update is shown in Fig. 1.

Schematic diagram of binarized model training
6 Training and Discussion
6.1 Experiment Platform
The experimental environment is Ubuntu 16.04 LTS 64-bit system, using PyTorch as the deep learning open-source framework and using python as the programming language. The computer memory is 64G, equipped with Intel Xeon(R) CPU E5-1640 v4 3.6 GHz x12 processor. The graphics card is a NVIDIA GTX1080Ti.
6.2 Parameter Selection in Experiment
The train and test dataset are divided into multiple batches in this paper; each batch has 32 images. The full-precision model uses SGD to optimize the model with a learning rate of 0.005 and regularization coefficient of 5e−4. The learning rate become 0.1 times of the original per 20 epoch. The binarized model uses Adam to optimize the model with learning rate of 0.001, regularization coefficient of 1e−5. The learning rate become 0.1 times of the original per 30 epoch.
In order to prevent over-fitting, four different proportions are set: train set: 80, 60, 30, 20%; test set: 20, 30, 60, 80%. The more the sample ratio, the smaller the influence of experimental inherent on the results. At the same time, in order to make a fair comparison, the hyper-parameters are standardized.
In order to compare the effect of the dataset under different conditions, the collected images are divided into color dataset, gray dataset, and segmented dataset. The segmented dataset eliminates the influence of the background on the picture.
6.3 Analysis and Discussion
The results are shown in the line chart. It can be seen from the chart, under the same condition, the average accuracy of the full-precision model is slightly higher than that of the binarized model. Due to the high initial learning rate, the accuracy of the two networks is improved rapidly before 20 epochs, and eventually, it tends to be stable.
It can be seen from the green polyline, because of the fine-tuning of the model the initial accuracy of the full-precision model is higher. The color, segmentation, and grayscale datasets, respectively, reach the accuracy of 0.6, 0.7, and 0.5. For the red polyline, even if the parameter of trained model is used, the binarized parameter leads to lower initial accuracy, but the accuracy tends to be stable after 30 epochs. Four proportion datasets are set in this paper. It can be seen from the last line chart that the green polyline and red polyline have a higher accuracy, followed by yellow and blue polyline. It proves that the more the training sample, the more features can be extracted to train networks (Fig. 2).

Line chart of experimental results
In this paper, it is shown in Table 1 that the convolutional neural network is more suitable for plant detection compared with the traditional methods. Most of the traditional methods rely on features of manual extraction but such features cannot fully reflect the diseases. The convolutional structures can extract features automatically as it has the ability to eliminate interference caused by noise. In this paper, softmax is used to classify leaves, and the average accuracy can reach 99.0% on segmented datasets.
The VGG16 has a huge amount of float parameters, which can extract picture features more comprehensively. When the floating point parameters are binarized, the model loses part of the features, which makes the features blurred and reduces the expression ability of the model. From another point of view, it speeds up the calculation of the model. In the experiment, the average recognition accuracy of the full-precision model is slightly higher than that of the binarized model. The former can reach 99.0%, and the latter can reach 96.8%. In terms of time, the speed of forward transmission of the latter is 2.7 ms per picture, which is about twice as fast as the former. That is to say the binarized model gets faster speed by losing part of its accuracy (Table 2).
In this paper, three kinds of datasets are chosen. It can be seen from Table 3 that the model performs best under the segmented dataset. The average accuracy can reach 96.8%. But the accuracy of the color dataset is 0.9% lower than the segmented dataset, which indicates that the model pays more attention to the features of leaf diseases. The accuracy of grayscale dataset is reduced by 4.7% compared with the color dataset, which means that in addition to some physical features such as contours and veins, color can also have a positive effect on the plant identification.
Not all the data can be used for training. In the experiment, the overexposed images are generated due to the randomness of the parameters, which directly covered the features of texture and contour. The model could not extract useful features, so the accuracy is not high. The overexposed images should be deleted.
6.4 Conclusion
In this paper, the PlantVillage dataset and extended dataset are selected, and the binarized model is used to identify plant diseases. The experiment shows that the full-precision model and the binarized model both have the best performance under the segmented dataset, which can reach high accuracy and spend less time. Comparing the three datasets, the physical features such as leaf outline and plant meridians, the features of color, and background also have a great impact on the model. Comparing the convolutional models with the traditional models, the former can extract more details for training, also it can adapt to a complex environment.
The binarized model can work well in experiment, and the calculation speed is twice as fast as the full-precision model, which provides a basis for plant disease research.
References
Cao X, Zhou Y et al (2016) Progress in monitoring and forecasting of plant diseases. J Plant Prot 3:1–7
Zhang R, Wang Y (2016) Research on machine learning with algorithm and development. J Commun Univ China (Sci Technol) 23(2):10–18
Kan J, Wang Y, Yang X et al (2010) Plant recognition method based on leaf images. Sci Technol Rev 28(23):81–85
Tan F, Ma X (2009) The identification of plant diseases based on leaf images. J Agric Mech Res 31(6):41–43
Zhang N, Liu W (2013) Plant leaf recognition method based on clonal selection algorithm and K nearest neighbor. J Comput Appl 33(07):2009–2013
Wang L, Huai Y, Peng Y (2007) Method of identification of foliage from plants based on extraction of multiple features of leaf images. J Beijing For Univ 165:535–547
Dyrmann M, Karstoft H, Midtiby HS (2016) Plant species classification using deep convolutional neural network. Biosyst Eng 151:72–80
Mohanty SP, Hughes DP, Salathé M (2016) Using deep learning for image-based plant disease detection. Front Plant Sci 7:1419
Lee SH, Chan CS, Mayo SJ et al (2017) How deep learning extracts and learns leaf features for plant classification. Pattern Recogn 71:1–13
Zhong Z, Zheng L, Kang G et al (2017) Random erasing data augmentation. arXiv preprint arXiv:1708.04896
Ghazi MM, Yanikoglu B, Aptoula E (2017) Plant identification using deep neural networks via optimization of transfer learning parameters. Neurocomputing 235:228–235
Courbariaux M, Bengio Y (2016) BinaryNet: Training deep neural networks with weights and activations constrained to +1 or −1. arXiv:1602.02830
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Singapore Pte Ltd.
About this paper

Cite this paper
Pu, X., Ning, Q., Lei, Y., Chen, B., Tang, T., Hu, R. (2020). Plant Diseases Identification Based on Binarized Neural Network. In: Liang, Q., Wang, W., Mu, J., Liu, X., Na, Z., Chen, B. (eds) Artificial Intelligence in China. Lecture Notes in Electrical Engineering, vol 572. Springer, Singapore. https://doi.org/10.1007/978-981-15-0187-6_2
Download citation
DOI: https://doi.org/10.1007/978-981-15-0187-6_2
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-15-0186-9
Online ISBN: 978-981-15-0187-6
eBook Packages: EngineeringEngineering (R0)