
Abstract
The CALMET/CALPUFF modeling system is employed to simulate the dispersion and transport of tracer gas at a nuclear power plant site located in a complex valley and upland terrain where weak wind prevails. Using the surface and upper air meteorological observations obtained from a field experiment, the three-dimensional diagnostic wind fields are generated by CALMET module. Three different algorithms of dispersion coefficients are used to model the ground concentration distributions of tracer under different wind conditions, which are using measured turbulence velocity variances, similarity theory, and PG stability-dependent dispersion curves with coefficients modified according to the in situ turbulence measurement to calculate dispersion coefficients, respectively. The results show that turbulence and modified PG methods can better predict high observed concentrations than the similarity method, while all the three methods overpredict the low observed concentrations mainly due to underestimations on wind speed and overestimations on mixing layer heights in modeling. The turbulence and modified PG methods overestimate the observed peak concentrations by less than 30%, while the similarity method underestimates by about 20%. Overall, the turbulence and modified PG methods perform better than the similarity method, with less dependence of simulated concentration residues on wind speed and mixing height. From the viewpoint of engineering application, CALPUFF model with modified PG method to calculate dispersion coefficients is recommended at the site with hilly-valley complex terrain to simulate the transport and dispersion of gaseous effluent.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Atmospheric dispersion models are necessary tools for the estimation of atmospheric dispersion from nuclear facilities in the assessment of the radiological impacts from normal and accidental releases. The most widely used models are Gaussian plume models because of their simplicity and rapidity of calculation. However, the limitations inherent in the steady-state Gaussian plume models usually make them fail over complex terrain and under calm and light wind speed conditions, which are frequently encountered at inland nuclear power plant (NPP) sites in China. In these cases, the temporal and spatial variation of meteorology and the causality effects for the plume to travel from one point to another should be taken into account.
To better understand the atmospheric dispersion characteristics at the sites of complex flow pattern, field experiments should be carried out and more suitable models should be employed. Puff models are regarded as advanced models which can overcome the limitations of Gaussian plume models and are suitable for the simulation under the above complex conditions. In addition, puff models are far less computationally expensive than particle models, thus they are often more than adequate, and are used for regulatory purposes [1]. CALPUFF is a comprehensive three-dimensional Gaussian puff model recommended by the US Environmental Protection Agency (EPA) for regulatory applications [2]. Both long-range transport and near-field impacts on complex flow or dispersion situations which may involve complex terrain, stagnation, inversion, recirculation, light, and calm wind conditions can be adequately modeled by CALPUFF. In addition to the transport wind fields, dispersion coefficients are other crucial parameters that influence the dispersion of airborne effluents and the following dose estimates. Several calculational approaches of dispersion coefficients have been developed in CALPUFF based on available data. Compared with the commonly used Pasquill–Gifford dispersion curves and other similar stability-related dispersion relationships, CALPUFF also has more sophisticated methods to calculate dispersion coefficients, which are similarity theory-based and real turbulence measurement-based dispersion schemes, and the complex schemes involve more details of input parameters.
In the present study, CALPUFF modeling system is used to study the atmospheric dispersion characteristics at an inland nuclear power plant site over complex terrain. Performances of various dispersion schemes are evaluated by comparing the modeling results with the measured tracer concentrations from the field experiments.
2 Field Experiments
The field experiments were conducted from December 20, 2008, to January 3, 2009 at a typical inland NPP site surrounded by low-level hills with a river valley traversing across the site area. Figure 1 shows the location and topography of the site area. The site surroundings are characterized by irrigated agricultural land. The annual mean wind speed is 1.5 m s−1, and the occurrence frequency of low wind speed (wind speed at 10 m height is lower than 2 m s−1) is about 50% [3]. The field experiments include meteorological measurements and tracer releases and sampling under different weather conditions.

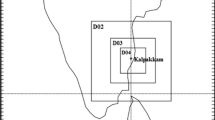
Location, topography, and layout of the experimental site. The red rectangles in (a) and (b) mark the location of the modeling domain. The triangles and circles in (b) represent the surface meteorological stations and upper air stations, respectively. Plus signs in (c) represent the tracer samplers. The center of the domain marked by the pentagram is the release tower
In situ wind velocity, wind direction, and temperature were measured at 5 levels (i.e., 10, 30, 50, 70, and 100 m) on the release tower every 10 min. Four CSAT3 ultrasonic anemometers of 10 Hz sampling frequency were installed at 10, 30, 50, and 100 m heights on the tower, measuring the fluctuating components of wind velocity and temperature. Eight surface meteorological stations instrumented with anemometers were set up within the radius of 10 km from the release tower. Data were recorded at 10-min intervals, and hourly averages were used for dispersion modeling. Two radiosondes were released every 2–3 h, providing wind and temperature profiles from ground to 1000 m height during the tracer experiment period. The locations of the surface and upper air stations are shown in Fig. 1b.
There were a total of 23 releases of sulfur hexafluoride (SF6) with release heights 10, 30, and 70 m above the ground, respectively, mostly under unstable and neutral conditions. Except three releases lasting for about 100 min, the duration of each of the other releases is 1 h. Depending on the prevailing wind direction at the site, the sampling array consisting of 116 air samplers was set up in the river valley in the south and northeast of the release tower. Four samplings, each of which lasted for 10 min, were taken for each release trial at each sampler. The interval between adjacent two samplings was 5 min.
Constrained by the topography and logistics, the samplers were gridded distributed. The most distant sampler was about 5 km from the release tower, and the closest one was about 0.2 km. The average spacing between adjacent samplers was about 200 m. The layout of the samplers is shown in Fig. 1c. To facilitate the evaluation of modeling results, we approximate the samplers into 5 arcs according to their distances to the release source following Hanna’s methods [4]. The five arcs are 500 m (450–550 m), 700 m (650–750 m), 900 m (850–950 m), 1100 m (1050–1150 m), and 1300 m (1200–1400 m) from the release point, respectively. Samplers beyond the ranges are sparsely distributed and cannot capture the overall distribution of ground concentration and thus are not used in current study. Before conducting model evaluation, the tracer concentration data went through rigorous quality assurance (QA) procedures.
3 Atmospheric Dispersion Model
The CALPUFF modeling system is used to simulate the dispersion of tracer gas over complex terrain in the present study. The model’s formulations and theoretical background can be found in the related technical documents [2, 5]. The focus of this study which is the schemes to calculate dispersion coefficients is briefly highlighted below.
Five dispersion options, involving three levels of input data listed below, are provided in CALPUFF:
-
(1)
dispersion coefficients computed from direct measurements of turbulence, σ v and σ w ;
-
(2)
dispersion coefficients from internally calculated σ v and σ w using micrometeorological variables u *, w *, L, h, etc., from CALMET based on similarity theory;
-
(3)
dispersion coefficients from PG stability-dependent dispersion curves and user choice of various relationships.
The most desirable approach is to relate the dispersion coefficients directly to the measured turbulence velocity variances (σ v and σ w ). However, these data are not always available and the quality of the data is very important to lead to accurate modeling results. The default dispersion option in CALPUFF is the second one, which uses similarity theory and micrometeorological variables derived from routinely available meteorological observations and surface characteristics. The third option is the commonly used dispersion methodology in Gaussian plume models, which are empirically derived and can become invalid under low wind speed conditions over complex terrain. In the present study, we use a modified form of PG stability-dependent dispersion curves with coefficients derived from the in situ turbulence measurement. Figure 2 shows the modified curves with original PG curves for comparison. It can be seen that the modified horizontal and vertical dispersion curves in the near-field with downwind distance less than 5 km at all stabilities (except for the vertical dispersion coefficient under A stability class and beyond 500 m) are above the original PG curves, which reflects the influences of local complex terrain and flow pattern on the near-field dispersion.

Modified PG stability-dependent atmospheric dispersion coefficients of the site
In the following study, the above three dispersion schemes referred as turbulence, similarity, and modified PG methods for simplification are evaluated by comparing the modeling results with the observational tracer concentrations. To carry out the evaluation on the same basis, the same hourly gridded wind fields are used for the three dispersion schemes, which are generated from the diagnostic wind field model CALMET by using the surface and upper air data listed in Sect. 2. In case of upper air data missing during high wind speed episodes, the NCEP FNL reanalysis data of 1° × 1° resolution are used instead. The modeling domain is set to be 10 km × 10 km, with the release tower at the center (Fig. 1c). The horizontal grid spacing of the meteorological grid is 100 m, and the sampling grid size is 50 m to better predict the near-field peak concentrations. In the vertical direction, ten grid cells are used with the cell face heights 0, 20, 40, 80, 160, 300, 600, 1000, 1500, 2200, and 3000 m, respectively. The modeling time step of CALPUFF is set to be 1 min, and 40-min averages are calculated for each release trial to compare with the measured concentrations.
4 Evaluation Methodology
Because typical variations in wind direction are about 20 to 40° (or more in light winds), predicted plumes often completely fail to overlap observed plumes, even though the magnitude and patterns may be similar [6]. From the viewpoint of engineering application, high concentrations (or doses) are of great concern. Thus, model evaluation in the current paper is mainly based on the peak concentration anywhere along a sampling line.
The performance of the three dispersion schemes is evaluated using two basic methodologies. The first method is using scatter plots, quantile–quantile plots, and residual box plots to quantitatively compare the observed and predicted concentrations. The second method involves the application of statistical procedures that quantify several relevant performance measures.
In a scatter plot, the paired observations and predictions are plotted against each other, from which the magnitude of the model’s over- or underpredictions can be visually inspected. Quantile–quantile (Q–Q) plot is used to find out whether a model can generate a concentration distribution that is similar to the observed one. Biases at low or high concentrations are quickly revealed in this plot. In a residual box plot, model residuals defined as the ratio of predicted (C p) to observed (C o) concentrations are plotted, in the form of a box diagram, versus independent variables such as ambient wind speed, mixing height, and atmospheric stability. The significant points for each box diagram represent the 1st, 10th, 25th, 50th, 75th, 90th, and 99th percentiles of the cumulative distribution of the n points considered in the box. A good performing model should not show any trend of the residuals when they are plotted versus independent variables [7].
Predictions of the three dispersion schemes are compared with the experimental tracer data using the statistical performance measures recommended by Hanna et al. [8], which include the fractional bias (FB), the geometric mean bias (MG), the normalized mean square error (NMSE), the geometric variance (VG), the correlation coefficient (R), and the fraction of predictions within a factor of two of observations (FAC2). They are defined as
where C o and C p refer to the observed and predicted concentrations, respectively, and an overbar indicates an average. σ o and σ p represent the standard deviations of the observed and predicted values, respectively.
The statistical indexes FB and MG provide a value for the total error and indicate whether the predicted concentrations underestimate or overestimate the observed values. NMSE and VG both deal with variances and reflect systematic and random errors. Correlation coefficient R describes the degree of agreement between the variables. FAC2 is the most robust measure, because it is not overly influenced by outliers. A perfect model would have MG, VG, and FAC2 = 1 and FB and NMSE = 0. Chang and Hanna [7] have given suggestions regarding the magnitudes of the performance measures expected of “good” models based on unpaired in space comparisons, which are listed as below:
FAC2 is about 50%.
The mean bias is within ±30% of the mean.
The random scatter is about a factor of two to three of the mean.
5 Evaluation Results
Figure 3a shows the scatter plot of observed versus predicted arc maximum concentrations for turbulence, similarity and modified PG dispersion schemes. It can be seen that predictions of the turbulence and modified PG methods match well with the observed values for high and medium concentration ranges, with most of the points falling within a factor of 4 lines, while the similarity method underestimates high observed concentrations. All the three schemes tend to overpredict the low observed concentrations. From the distributions in the Q–Q plot (Fig. 3b), the underestimation at high concentration part by the similarity method and overprediction at low concentration part by all the schemes can be clearly discerned. Over most of the range, the distributions of the turbulence and modified PG method show less bias than that of the similarity method.

a Scatter plots and b Q–Q plots of observed versus predicted arc peak concentrations. The thin solid lines indicate a factor of two scatter, and dashed lines represent a factor of four scatter
Figure 4 shows the percentage of predicted cases within a factor of 2, 4, 6, and more than 6 by the three schemes. The turbulence and modified PG schemes behave quite similar, with FAC2 49.3 and 48.0%, and FAC4 78.7 and 77.3%, respectively. The magnitudes of FAC2 and FAC4 are lower for the similarity scheme, which are 42.7 and 70.7%, respectively.

Bar graph showing the percentage of predicted cases within a factor of 2, 4, 6, and more than 6 by the three schemes
Figures 5 and 6 show residual box plots of C p/C o as a function of wind speed and mixing height, respectively. The trend is not obvious under low and medium wind speed conditions (wind speed less than 4 m/s), with larger scatters for the similarity method. For higher wind bin with wind speed between 4 and 6 m/s, all the three methods show overpredictions. Comparison between the measured wind speeds at the surface stations with the modeled values shows that CALMET underestimates the observed wind speeds under high wind speed conditions, which results in the overestimated concentrations at high winds. Moreover, discrete tracer samplers may miss the actual plume centerlines under high wind speed conditions, when the dispersive plume is thin.

Residual box plots of a turbulence method, b similarity method, and c modified PG method as a function of wind speed (m/s). Dashed lines indicate a factor of two scatter

Residual box plots of a turbulence method, b similarity method, and c modified PG method as a function of modeled mixing height (m). Dashed lines indicate a factor of two scatter
Figure 6 suggests little overall trend with mixing height for the turbulence and modified PG method. However, distinct underestimation with mixing height below 500 m and pronounced overestimation with mixing height above 1500 m is found for the similarity method. By analyzing the measured temperature profiles, cases of mixing heights below 500 m correspond to the conditions of low-level inversions with the measured mixing heights less than 300 m, while the modeling results are larger than 400 m. Overprediction of mixing heights leads to overestimation of dispersion coefficients for the similarity method and hence the underestimation of plume concentrations. Trials with mixing heights higher than 1500 m correspond to high wind conditions. Besides the reasons analyzed previously, two radiosondes were not released during high wind speed periods, thus the mixing heights were calculated using the NCEP FNL reanalysis data with a spatial resolution 1° × 1° during these periods. The resolution is too coarse to accurately reflect the evolution of mixing layer over the complex terrain, which subsequently influences the simulation of ground concentration. Compared with the similarity method, predictions by the turbulence and modified PG methods have a less dependence on the meteorological variables.
Table 1 summarizes the results of statistical performance evaluation for the three dispersion methods. Overall, the performances for the turbulence method and the modified PG method are comparable. The similarity method has a larger scatter. To better interpret the statistical measures, Eq. (1) is rewritten as following:
Ignore the random scatter between C p and C o, then Eq. (4) becomes [9]
Thus, the turbulence, similarity, and modified PG dispersion methods yield values of FB corresponding to 26.5% overprediction, 17.7% underprediction, and 23.6% overprediction, respectively, and values of VG corresponding to the random scatter of a factor of 3, 4, and 3 of the mean, respectively. FAC2 values for turbulence and modified PG methods are close to 50% and slightly lower, about 43%, for the similarity method. According to the good models’ criteria in Sect. 4, CALPUFF model with the turbulence or the modified PG dispersion scheme is suitable for the inland NPP site over the complex hilly and valley terrain.
6 Conclusions and Discussion
Comprehensive field experiments including both meteorological measurements and tracer releases and samplings were conducted at a typical inland NPP site located over a complex hilly and valley terrain to investigate the site-specific atmospheric dispersion characteristics and to validate the atmospheric dispersion models. Because of the powerful abilities of CALPUFF to simulate the near-field impacts on complex flow situations, it is chosen as the preferred model. Three dispersion schemes in CALPUFF involving different levels of sophistication of input data are used to model the ground concentration distributions of the tracer gas, which are using direct measurements of turbulence, the micrometeorological variables in conjunction with the similarity theory, and the PG stability-dependent dispersion curves with coefficients modified according to the turbulence measurements, respectively, to calculate the dispersion coefficients. The modeled arc maximum concentrations are compared to the observed values by various methodologies, such as the scatter plot, quantile–quantile plot, residue box plot, and a set of statistical performance measures.
In general, the turbulence scheme and the modified PG scheme are found to have similar performance, with overall overestimation between 20 and 30% and a random scatter of a factor of 3. The two schemes predict well for the high and medium concentration ranges. An underestimation of about 20% is found for the similarity scheme, with a random scatter of a factor of 4. For the similarity scheme, the calculated dispersion coefficients strongly depend on the meteorological variables derived from CALMET. The errors of wind field and other micrometeorological variables can be transferred to the dispersion module and then influence the predicted concentrations. Thus, the model residuals show remarkable trends with wind speed and mixing height, which is not obvious for the other two schemes. The similarity scheme underestimates the high concentration part by about a factor of 2. All the three schemes overpredict the low concentration ranges mainly due to underestimations on wind speed and overestimations on mixing layer heights in modeling, and the probable miss of plume centerline during sampling at high wind speed conditions.
Overall, CALPUFF model with the turbulence dispersion scheme or the modified PG dispersion curves shows good performance at the inland site. However, long-term measurement of turbulence is usually unavailable at most sites. In this way, the parameterization formulas of dispersion coefficients can be derived from the short-term in situ turbulence measurement, which is usually taken at Chinese NPP sites for two typical seasons (e.g., winter and summer). The modified PG stability-dependent dispersion formulas or curves can be used instead of the original PG option to better reflect the site-specific dispersion characteristics. The open access of the source codes of CALPUFF facilitates this modification. From the viewpoint of engineering application, CALPUFF model with modified PG dispersion curves is recommended at sites over such hilly and valley complex terrain.
References
Bluett J, Gimson N, Fisher G, et al. Good Practice Guide for Atmospheric Dispersion Modeling [R]. Ministry for the Environment, Wellington, New Zealand, 2004.
Scire J S, Strimaitis D G, Yamartino R J. A User’s Guide for the CALPUFF Dispersion Model (version 5) [R]. Earth Tech, Inc., Concord, 2000.
Zhu H, Zhang H S, Cai X H, et al. Using CALPUFF for near-field atmospheric dispersion simulation over complex terrain[J]. Acta Scientiarum Naturalium Universitatis Pekinensis, 2013, 49(3): 452–462 (in Chinese)
Hanna S R, Britter R, Franzese P. A baseline urban dispersion model evaluated with Salt Lake City and Los Angeles tracer data [J]. Atmospheric Environment. 2003, 37(36): 5069–5082.
Scire J S, Robe F R, Fernau M E et al. A User’s Guide for the CALMET Meteorological Model (Version 5.0) [R], Earth Tech, Inc., Concord, 2000.
Weil J C, Sykes R I, Venkatram A. Evaluating air quality models: review and outlook [J]. Journal of Applied Meteorology, 1992, 31: 1121–1145.
Chang J C, Hanna S R. Air quality model performance evaluation [J]. Meteorology and Atmospheric Physics, 2004, 87: 167–196.
Hanna S R, Chang J C, Strimaitis D G. Hazardous gas model evaluation with field observations [J]. Atmospheric Environment, 1993, 27A: 2265–2285.
Chang J C, Franzese P, Chayantrakom K., et al. Evaluations of CALPUFF, HPAC, and VLSTRACK with two mesoscale field datasets [J]. Journal of Applied Meteorology, 2003, 42: 453–466.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer Science+Business Media Singapore
About this paper
Cite this paper
Zhu, H., Li, F. (2017). Evaluation of Algorithms of Dispersion Coefficients with a Field Tracer Experiment over Complex Terrain. In: Jiang, H. (eds) Proceedings of The 20th Pacific Basin Nuclear Conference. PBNC 2016. Springer, Singapore. https://doi.org/10.1007/978-981-10-2314-9_42
Download citation
DOI: https://doi.org/10.1007/978-981-10-2314-9_42
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-2313-2
Online ISBN: 978-981-10-2314-9
eBook Packages: EnergyEnergy (R0)