
Abstract
In this paper, chemical properties of wheat dough are predicted using different soft computing tools. Here, back-propagation and genetic algorithm techniques are used to predict the parameters and a comparative study is made. Wheat grains are stored at controlled environmental conditions. The content of fat, moisture, ash, time and temperature are considered as inputs whereas protein and carbohydrate contents are chosen as outputs. The prediction algorithm is developed using back-propagation algorithm, number of layers are optimized and mean square errors are minimized. The errors are further reduced by optimizing the weights using Genetic Algorithm and again the outputs are obtained. The error between predicted and actual outputs is calculated. It has been observed that with back-propagation along GA model algorithm, errors are less compared to the simple back-propagation algorithm. Hence, the given network can be considered as beneficial as it predicts more accurately. Numerical results along with discussions are presented.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
In recent years modelling, simulation and control of internal parameters of physical systems or processes have become crucial areas of active research. Increasing demands for reliable and detailed analysis of various practical problems has made numerical modelling and simulation of physical systems an important area of research. This is true for both analyses of the systems themselves through simulations, as well as for design of associated controllers for system or process control. Moreover, most practical physical systems are governed by Partial Differential Equations (PDEs) and are of high dimensional in nature. They appear in various application areas such as thermal processes, chemical processes, agricultural and biological systems etc. These systems involve strong or weak interactions between different physical phenomena. Hence, lots of challenges are involved in modelling, simulation, prediction of the data from a physical system.
In current software-reliability research, the concern is how to develop general prediction models. Existing models typically rely on assumptions about development environments, the nature of software failures occurring. A possible solution is to develop models that don’t require making assumptions about the development environment and external parameters. An interesting and difficult way to develop a model is using time-series prediction that predicts a complex sequential process. Recent advances in back-propagation (BP) networks [1, 2] show that they can be used in applications that involve predictions. This method has a significant advantage over analytical models as they do not require any assumptions. Using any input, BP can automatically develop its own internal model and predicts the future behaviour of the system. As it adjusts model complexity to match the complexity of the failure history, it can be more accurate than some commonly used analytical models. The main disadvantage of the BP method is that proper selection of weights is necessary to avoid slow convergence or local minima problem [3, 4]. To overcome these difficulties, in this work, genetic algorithm (GA) is used to optimize the weights of BP networks.
Here, wheat grains are stored at controlled temperature and humidity conditions and then dough is prepared from the grinded flour. Using AOAC standard methods [5], the internal parameters of wheat, viz., protein, carbohydrate, fat ash, moisture contents are determined. The main disadvantage involved here is that the chemical tests are time-consuming, laborious and costly. To overcome these difficulties, models are developed using different soft-computing tools like, BP and GA to predict these parameters. It has been observed from the literature that development of models based on GA-BP to predict the chemical parameters for stored grains has not been explored much. The paper is organized in the following way. In Sect. 2, Materials and methods, adopted to achieve the input data are discussed. Different soft-computing algorithms based on BP and GA are discussed in detail in Sect. 3. These algorithms are used to forecast the carbohydrate and protein values of wheat grains. Complete discussion along with numerical analysis is presented in Sect. 4. Finally the paper is concluded in Sect. 5.
2 Materials and Methods
2.1 Sample Storage
The wheat grains were collected from the markets of Punjab. The grains were placed in a storage chamber for duration of one year with temperature maintained at 20 °C and humidity around 25 %.The grains were packed in airtight zip-locked plastic bags so the humidity has least effect on grains properties.
2.2 Chemical Analysis
Sample of grains from the storage chamber was taken every month and immediate analysis was carried out using standard methods [5]. Moisture content in grains was checked using oven method [6] where grains were heated for one hour at 130 °C. Kjeldahl method [7] was applied for determining N2 content in the grain sample. Soxhlet apparatus process [8] was used for finding the fat content where grain samples were refluxed using petroleum ether. After drying the sample for 6 h the percentage weight gives the fat content. For determining the carbohydrate contents Anthrone method [9] had been used. The grains were mixed with Anthrone solution and the absorption was measured in the UV region.
2.3 Dough Preparation and Rheological Analysis
For preparing dough, 5 gm of wheat sample was grinded using a blade grinder and water was mixed in ratio of 1 ml: 1 gm of wheat flour. The prepared dough was then wrapped in aluminium foil and was kept undisturbed for ten minutes to allow relaxation. Several essential rheological tests were carried out like, stress sweep (with small deformation); creep-recovery test (large deformation) [10, 11] temperature sweep dynamic oscillations etc.
3 Soft Computing Tools
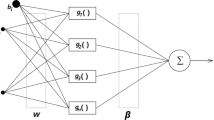
3.1 Back Propagation
Back propagation (BP) is a technique of training multilayer ANNs which uses supervised learning technique [12]. Due to its flexibility it has been effectively employed in broad variety of applications like, modelling, control, prediction etc [13, 14]. In this algorithm, inputs are normalized and the network parameter such as number of hidden layers, number of neurons is selected. After that weights are selected for connecting input and hidden neurons and hidden and output neurons [15]. The values of weights are usually selected between −1 and 1. The weighted sum of inputs (x j ) is connected to the jth hidden layer and is given as
with θ j is taken as bias. Using the values of inputs, the output of hidden layer can be calculated as
This function is termed as sigmoid function. Again, the output for the next layer can be calculated as
Finally, the outputs are evaluated and they are compared with the desired outputs and errors are evaluated. The error between the actual and desired outputs is given as
where D j is the desired output. The weights are chosen in such a way that the errors are minimized [16, 17].
The main drawback of this method is that the solutions may stuck into a local minima. To overcome this difficulty, gradient decent algorithm may be used where the solutions do not stuck at local minima but it settles to global minima [3], [18]. In this paper, fat, moisture, ash, time and temperature are given as inputs to the BP network and protein and carbohydrate contents are chosen as outputs. Different layers can be placed between the inputs and outputs. Here we have chosen Elman network [19] to optimize the number of layers. It has been observed that only two layers with 20 units (12 units at first hidden layer and 6 units at second layer) are sufficient to efficiently determine and predict the output data.
3.2 Genetic Algorithm
It has been observed that the previous algorithm is slow and several times it got stuck at local minima. Hence, we have combined it with a new search algorithm known as Genetic Algorithm (GA) [20]. The GA is a searching technique which is based on natural selection process. The process is intended to repeat the process of natural systems [21, 22]. Randomly weights are selected, each weight is represented as gene and the string of genes is represented as one chromosome. The weight matrix can be given as
if 5 ≤ xkd+1 ≤ 9, and
if 0 ≤ xkd+1 < 5,
where d is number of digits of a gene and (x kd+1 ,…) represent the genes of a chromosome. Now these weights are used in BP algorithm and the outputs are calculated using activation function. Population size is the number of chromosomes selected for the problem. The presentation of every chromosome is predicted using fitness function that measure how fine given data performs. The best performing chromosomes are selected for producing the next generation and the least performing chromosomes are removed from the previous population to generate new population. The errors are calculated using Eq. 4 and a fitness function is determined by reversing the error.
This algorithm is again used to predict the internal parameters of grains. In the next section the results obtained using both the algorithms are given and a comparative study is made.
4 Results and Discussions
Wheat grains were stored in a controlled atmosphere (with temperature at 20 °C and humidity at 20–25 %) for one year. The inputs provided are fat, ash, moisture, temperature and protein and carbohydrate values were predicted. Their range along with mean and standard deviation (SD) are summarized in Table 1 (Fig. 1 and Table 2).

Prediction of protein using BP
The given data is divided into two portions. First about 80 % of data was used for training of the network while the left over 20 % data was retained for testing the algorithm. The input layer has five neurons, next the first hidden layer consists of twelve neurons, followed by the second hidden layer with six neurons and the at the output layer there are two neurons. So this network is stated as four layered network. Firstly random weights are selected and the input layer and hidden layers are trained using activation functions. The output of the layer becomes the input for the preceding layer and hence outputs are obtained and errors are evaluated using BP and GA mechanism. At the end weights are adjusted and fed back to the network till the error gets reduced. For updating weights, the learning rate and momentum coefficient were chosen as 0.5 and 0.01 respectively. The correlation coefficients (R 2) given in Table 3 were evaluated by plotting the predicted data versus given data. Figures 2, 3, 4 show the relation between predicted and actual values of protein and carbohydrate content. It was observed that the average values of R 2 for the both models BP and GA were satisfactory.

Prediction of protein using GA-BP

Prediction of carbohydrate using BP

Prediction of carbohydrate using BP GA-BP
The values of mean average error (MAE) and percentage error for both BP and GA models were calculated and given in Table 2. From that table we can conclude that GA based BP neural network provides very good results. The main advantages of this algorithm as evaluated with Back Propagation neural network is that the number of iterations were lesser than simple BP and the network has never got stuck into global minima. With this network the protein and carbohydrate future data can be predicted without any chemical analysis.
From the above analysis, neural network model based on GA has predicted values were found to be very close to the observed values as compared to BP model. This shows that GA model show better potential in predicting data for future purposes. The better presentation of GA may be due to heuristic search for the optimal. Thus, this algorithm has a better possibility to attain the global minima. On the other hand, back propagation algorithm has many times fallen behind GA model might be due to local optima problem. Therefore, GA based NN model is considered to be more helpful for predicting data for future. The main disadvantage of the BP model is the proper selection of weights to avoid slow convergence and local minima problem. To overcome these difficulties, genetic algorithm based NNs can be used.
5 Conclusion
In this paper, internal parameters of wheat grains are predicted using a GA based BP model. As a comparative study, the same parameters are predicted using a simple BP based model. Advantages of GA based network over the conventional BP network are discussed. It has been studied that this model can be considered as better choice for achieving a complex relationship between inputs and outputs which is otherwise very difficult to obtain mathematically. Hence, it is better to apply GA algorithm for training the data, so that search space can be reduced to perform better and to avoid the difficulty of the convergence at local minima.
References
Zhixin, S., Bingqing, L.: Research of improved back-propagation neural network algorithm. In: 12th IEEE International Conference, China (2010)
Jung, I., Wang, G.:. Pattern classification of back-propagation algorithm using exclusive connecting network. World Acad. Sci. Eng. Technol. 1 (2007)
Toussaint, M.: Lecture Notes on Gradient Decent. Machine Learning & Robotics, Berlin (2012)
Bottou, L.: Large-scale machine learning with stochastic gradient descent. In: Proceedings of Compstat, pp 177–180 (2010)
AOAC, Official Methods of Analysis, 15th edition of Association of official Analytic alchemists, Arlington, VA. AOCS, vol. 1 (1998)
Can, K.S., Lim, S.C., Ong, C.E.: Measuring the moisture content of wood during processing. Forest Res. Inst. Malaysia 36 (2005)
Amin, M., Flowers, T.H.: Evaluation of kjeldahl digestion method. Journal of Research (Science), Bahauddin Zakariya University, Multan, Pakistan, vol. 15 (2004)
Ahmad, A., Alkarkhi, A.F.M., Hena, S.: Extraction, separation and identification of chemical ingredients of Elephantopus Scaber L. Int. J. Chem. 1 (2009)
Sadasivam, S., Manickam, A.: Biochemical methods, 2nd edn. New Age International (P) Ltd (2005)
Malkin, A., Isayev, A.: Rheology, Concepts, Methods and Applications. Chemtec Publishing (2006)
Zhai, H., Salomon, D., Miliron, E.: Using Rheological Properties to Evaluate Storage Stability and Setting Behavior of Emulsified Asphalts. Idaho Asphalt Supply, Inc. White Paper, USA, vol. 11 (2006)
Saduf, M.A.W.: Comparative study of back propagation learning algorithms for neural networks. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 3 (2013)
Popescu, O., Popescu, D., Wilder, J., Karwe, M.: A new approach to modelling and control of a food extrusion process using artificial neural network and an expert system. J. Food Process Eng 24, 17–36 (2001)
Kashaninejad, M., Dehghani, A.A., Kashiri, M.: Modeling of wheat soaking using two artificial neural networks. J. Food Eng. 91, 602–607 (2009)
Llave, Y.A., Hagiwara, T., Sakiyama, T.: Artificial neural network model for prediction of cold spot temperature in retort sterilization of starch- based foods. J. Food Eng. 109, 553–560 (2012)
Sablani, S., Shaur Rahman, M.: Using neural networks to predict thermal conductivity of food as a function of moisture content. Temp. Apparent Porosity Food Res. Int. 36, 617–623 (2013)
Qiao, J., Wang, N., Ngadi, M., Kazemi, S.: Predicting mechanical properties of fried chicken nuggets using image processing and neural network techniques. J. Food Eng. 79, 1065–1070 (2007)
Choi, B., Lee, J.H., Kim, D.H.: Solving local minima problem with large number of hidden nodes on two-layered feed-forward artificial neural networks. Neurocomputing 71(16–18), 3640–3643 (2008)
Wagarachchi, N.M., Karunananda, A.S.: Mathematical modeling of hidden layer architecture in artificial neural networks. In: International Conference on Information Security and Artificial Intelligence, vol. 56 (2012)
Whitley, D.: Applying genetic algorithms to neural network problems. In: International Neural Network Society, pp. 1–6 (2008)
Koehn, P.: Combining Genetic Algorithms and Neural Networks, A Thesis Presented for the Master of Science Degree. The University of Tennessee, Knoxville, December (1994)
Mandal, S.N., Ghosh, A., Roy, S., Pal Choudhury, J., Chaudhuri, S.R.B.: A novel approach of genetic algorithm in prediction of time series data. Int. J. Comput. Appl. Adv. Comput. Commun. Technol. HPC Appl. ACCTHPCA(1) (2012)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer Science+Business Media Singapore
About this paper
Cite this paper
Kaur, M., Guha, P., Mishra, S. (2016). Intelligent Prediction of Properties of Wheat Grains Using Soft Computing Algorithms. In: Choudhary, R., Mandal, J., Auluck, N., Nagarajaram, H. (eds) Advanced Computing and Communication Technologies. Advances in Intelligent Systems and Computing, vol 452. Springer, Singapore. https://doi.org/10.1007/978-981-10-1023-1_8
Download citation
DOI: https://doi.org/10.1007/978-981-10-1023-1_8
Published:
Publisher Name: Springer, Singapore
Print ISBN: 978-981-10-1021-7
Online ISBN: 978-981-10-1023-1
eBook Packages: EngineeringEngineering (R0)