
Abstract
Stem taper process measured repeatedly among a series of individual trees is standardly analyzed by fixed and mixed regression models. This stem taper process can be adequately modeled by parametric stochastic differential equations (SDEs). We focus on the segmented stem taper model defined by the Gompertz, geometric Brownian motion and Ornstein-Uhlenbeck stochastic processes. This class of models enables the representation of randomness in the taper dynamics. The parameter estimators are evaluated by maximum likelihood procedure. The SDEs stem taper models were fitted to a data set of Scots pine trees collected across the entire Lithuanian territory. Comparison of the predicted stem taper and stem volume with those obtained using regression based models showed a predictive power to the SDEs models.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Diameter
- Geometric Brownian motion
- Gompertz process
- Ornstein-Uhlenbeck process
- Taper
- Transition probability density
- Stochastic differential equation
- Volume
1 Introduction
Deterministic and stochastic differential equations are probably the most commonly mathematical representations for describing continuous time processes [1, 2]. Biological experiments often imply repeated measurements on a series of experimental units. Stem taper process is usually measured repeatedly among a collection of individual trees. Traditionally, the relationship between volume, height and diameter has been modeled based on simple linear and nonlinear regressions. The base assumption of these regression models is that the observed variations from the regression curve are constant at different values of a covariate would be realistic if the variations were due to measurement errors. Instead, it is unrealistic, as the variations are due to random changes on growth rates induced by random environmental perturbations. Stochastic differential equations (SDEs) models do not have such weakness [3]. We propose to model these variations using SDEs that are deduced from the standard deterministic growth function by adding random variations to the growth dynamics [3–12]. Due to the specific characteristics of diameter dynamics, we thus consider SDEs models with drift and diffusion terms that can depend linearly or nonlinearly on state variables.
There is a long history characterizing the stem profile (taper) of trees. Mathematically defining stem taper is necessary for the accurate prediction of stem volume. Taper equations do just this and are important to foresters and forest scientists because they provide a flexible alternative to conventional volume equations. These equations are widely used in forestry to estimate diameter at any given height along a tree bole and therefore to calculate total or merchantable stem volume. One crucial element in these models is the functional response that describes the relative diameter of tree stem consumed per relative height for given quantities of diameter at breast height \(D\) and total tree height \(H\). The most commonly studied stem taper relations range from simple taper functions to more complex forms [13–20]. Taper curve data consist of repeated measurements of a continuous diameter growth process over height of individual trees. These longitudinal data have two characteristics that complicate their statistical analysis: (a) within-individual tree correlation that appears with data measured on the same tree and (b) independence but extremely high variability between the experimental taper curves of the different trees. Mixed models provide one of powerful tools to analysis of longitudinal data. These models incorporate the variability between individual trees by means of the expression of the model’s parameters and in terms of both fixed and random effects. Each parameter in the model may be represented by a fixed effect that stands for the mean value of the parameter as well as a random effect that expresses the difference between the value of the parameter fitted for each specific tree and the mean value of the parameter—the fixed effect. Random effects are conceptually random variables. They are modeled as such in terms of describing their distribution. This helps to avoid the problem of overparameterisation. A large number of mixed-effect taper regression models have been completed, and the study is still one of the important issues in progress [16, 17, 19].
The increasing popularity of mixed-effects models lies in their ability to model total variation, splitting it into its within- and between-individual tree components. In this paper, we propose to model these variations using SDEs that are deduced from the standard deterministic growth function by adding random variations to the growth dynamics [6–12]. Although numerous sophisticated models exist for stem profile [18, 20], relatively few models have been produced using SDEs [3, 12].
The basis of the work is a deterministic segmented taper model, which uses different SDEs for various parts of the stem to overcome local bias. In this paper an effort has been made to present a class of SDEs stem taper models and to show that they are quite viable and reliable for predicting not just diameter outside the bark for a given height but merchantable stem volume as well. Our main contribution is to expand stem taper and stem volume models by using SDEs and to show how an adequate model can be made. In this paper attention is restricted to homogeneous SDEs in the Gompertz, geometric Brownian motion and Ornstein-Uhlenbeck type.
2 Stem Taper Models
Consider a one-dimensional stochastic process \(Y(x)\) evolving in \(M\) different experimental units (e.g. trees) randomly chosen from a theoretical population (tree species). We suppose that the dynamics of the relative diameter \(Y^{i}=d\big /{D^{i}}\) versus the relative height \(x^{i}=h\big /{H^{i}} (x^{i}\in \left[ {0;1} \right] )\) is expressed by the Itô stochastic differential equation [21], where \(d\) is the diameter outside the bark at any given height \(h\), \(D^{i}\) is the diameter at breast height outside the bark of ith tree, \(H^{i}\) is the total tree height from ground to tip of \(i\)th tree. In this paper is used a class of the SDEs that are reducible to the Ornstein-Uhlenbeck process. The stochastic processes used in this work incorporated environmental stochasticity, which accounts for variability in the diameter growth rate that arises from external factors (such as soil structure, water quality and quantity, and levels of various soil nutrients) that equally affect all the trees in the stands.
The first utilized stochastic process of the relative diameter dynamics is defined in the following Gompertz form [6, 8]
where \(P(Y^{i}(x_0^i )=y_0^i )=1, i=1,\ldots ,M, Y^{i}(x^{i})\) is the value of the diameter growth process at the relative height \(x^{i}\ge x_0^i , \alpha _G , \beta _G ,\) and \(\sigma _G \) are fixed effects parameters (identical for the entire population of trees), \(y_0^i \) is non-random initial relative diameter. The \(W_G^i (x^{i}), i=1,\ldots ,M\) are mutually independent standard Brownian motions. The second stochastic process of the relative diameter dynamics is defined in the following geometric Brownian motion form [23]
where \(P(Y^{i}(x_0^i )=y_0^i )=1, i=1,\ldots ,M, \alpha _{GB} ,\) and \(\sigma _{GB} \) are fixed effects parameters (identical for the entire population of trees) and \(W_{GB}^i (x^{i})\) are mutually independent standard Brownian motions. The third stochastic process of the relative diameter dynamics is defined in the following Ornstein-Uhlenbeck form [22]
where \(P(Y^{i}(x_0^i )=y_0^i )=1, i=1,\ldots ,M, \alpha _O , \beta _O , \) and \(\sigma _O \) are fixed effects parameters (identical for the entire population of trees) and \(W_O^i (x^{i})\) are mutually independent standard Brownian motions.
In this paper is used a segmented stochastic taper process which consists of three different SDEs defined by (1)–(3). Max and Burkhart [24] proposed a segmented polynomial regression model that uses two joining points 0.15, 0.75 to link three different stem sections. Following this idea the stem taper models (with two joining points: 0.15, 0.75 or \(\frac{1.3}{H^{i}},\) 0.75) are defined in the two different forms
Using Eqs. (4), (5) and either fixing the stem butt and top or assuming that the stem butt and top were free, we define five stem taper models.
Model 1: Equation (4) and \(P(Y^{i}(x_0^i )=\gamma )=1, i=1,\ldots ,M\) (the stem butt and top of the \(i\)th tree are free), \(\gamma \) is additional fixed-effects parameter (identical for the entire population of trees).
Model 2: Equation (4) and \(P(Y^{i}(x_0^i )=y_0^i )=1, i=1,\ldots ,M\) (the stem butt of the \(i\)th tree is fixed and the top is free).
Model 3: Equation (4) and \(P(Y^{i}(x_0^i )=y_0^i )=1, P(Y^{i}(1)=0)=1, i=1,\ldots ,M\) (the stem butt and top of the \(i\)th tree are fixed).
Model 4: Equation (5) and \(P(Y^{i}(\frac{1.3}{H^{i}})=1)=1, i=1,\ldots ,M\) (the diameter at breast height of the \(i\)th tree is fixed and top is free).
Model 5: Equation (5) and \(P(Y^{i}(\frac{1.3}{H^{i}})=1)=1, P(Y^{i}(1)=0)=1, i=1,\ldots ,M\) (the diameter at breast height and top of the \(i\)th tree are fixed).
Assume that tree \(i\) is measured at \(n_i +1\) discrete relative height points \((x_0 ,x_1 \ldots ,\) \( x_{n_i } )\) \(i=1,\ldots ,M.\) Let \(\underline{y^{i}}\) be the vector of relative diameters for tree \(i\), \(\underline{y^{i}}=(y_0^i ,y_1^i ,\ldots , y_{n_i }^i ),\) where \(y^{i}(x_j^i )=y_j^i , \underline{y}=(\underline{y}^{1},\underline{y}^{2},\ldots ,\underline{y}^{M})\) is the \(n\)-dimensional total relative diameter vector, \(n=\sum \nolimits _{i=1}^M {(n_i +1)} .\) Therefore, we need to estimate fixed-effects parameters \(\gamma ,\alpha _G ,\beta _G ,\sigma _G ,\alpha _{GB} ,\beta _{GB} ,\sigma _{GB} ,\alpha _O ,\beta _O ,\sigma _O \) using all the data in \(\underline{y}\) simultaneously.
Models 2 and 3 use one tree-specific prior relative diameter \(y_0^i \) (this known initial condition additional needs stem diameter measured at a stem height of 0 m). Models 4 and 5 use known relative diameter at breast height, \(1\). The transition probability density function of the relative diameter stochastic processes \(Y^{i}(x_j^i ), x_j^i \in \left[ {0;1} \right] , i=1,\ldots ,M, j=0,\ldots ,n_i \) defined by Eqs. (1)–(3) can be deduced in the following form: for the Gompertz stochastic process [8]
for the geometric Brownian motion [22]
and for the Ornstein-Uhlenbeck stochastic process [23]
The conditional mean and variance functions \(m(x^{i}\left| \cdot \right. )\) and \(v(x^{i}\left| \cdot \right. )\) (\(x^{i}\) is the relative height of the \(i\)th tree) of the stochastic processes (1)–(3) are defined by
for the Gompertz stochastic process [8],
for the geometric Brownian motion [22] and for the Ornstein-Uhlenbeck process the conditional mean and variance functions \(m(x^{i}\left| \cdot \right. )\) and \(v(x^{i}\left| \cdot \right. )\) are defined by [23]
Using the transition probability densities (6), (9) and (10) of SDEs (1)–(3), the transition probability density functions of the relative diameter stochastic process, for Models 1–5 take the form, respectively
Using the conditional mean and variance functions (13)–(18) we define the trajectories of diameter’ and its variance’ for Models 1–5 in the following form, respectively
where \(\mathop \gamma \limits ^\wedge ,{\mathop \alpha \limits ^\wedge }_G ,{\mathop \beta \limits ^\wedge }_G ,{\mathop \sigma \limits ^\wedge }_G ,{\mathop \alpha \limits ^\wedge }_{ GB} ,{\mathop \sigma \limits ^\wedge }_{ GB} ,{\mathop \alpha \limits ^\wedge }_{OU} ,{\mathop \beta \limits ^\wedge }_O ,{\mathop \sigma \limits ^\wedge }_O \) are maximum likelihood estimators.
In this paper, we apply the theory of a one-stage maximum likelihood estimator for stem taper Models 1–5. As all models have closed form transition probability density functions (19)–(23), the log-likelihood function for Models 1, 2, 4, and Models 3, 5 are given, respectively
To assess the standard errors of the maximum likelihood estimators for stem taper Models 1–5, a study of the Fisher [25] information matrix was performed. The asymptotic variance of the maximum likelihood estimator is given by the inverse of the Fisher’ information matrix, which is the lowest possible achievable variance among the competing estimators. By defining \(p_k (\theta ^{k})\equiv \ln (L_k (\theta ^{k})),\) where \(k=1,\;2,\;3,\;4,\;5, \theta ^{1}=(\gamma ,\alpha _G ,\beta _G ,\sigma _G ,\alpha _{ GB} ,\beta _{ GB} ,\sigma _{ GB} ,\alpha _O ,\beta _O ,\sigma _O ), \theta ^{k}=(\alpha _G ,\beta _G ,\sigma _G ,\alpha _{ GB} ,\beta _{ GB} ,\sigma _{ GB} ,\alpha _O ,\beta _O ,\sigma _O ), k=2,\;3,\;4,\;5, L_k (\theta ^{k}) \) is defined by Eqs. (34), (35), the vector \(p_k (\theta ^{k})^{\prime }\equiv \frac{\partial p_1 (\theta ^{k})}{\partial \theta ^{k}},\) and the matrix \(p_k (\theta ^{k})^{\prime \prime }\equiv \left[ {\frac{\partial ^{2}p_k (\theta ^{k})}{\partial \theta _i^k \partial \theta _j^k }} \right] ^{T},\) we get that \(n^{{1/2}} ( {\hat{\theta }_{n}^{k} - \theta ^{k} } )\mathop \rightarrow \limits ^{d} N(0,[ {i(\theta ^{k} )} ]^{{ - 1}} ),\) where the Fisher’ information matrix is
The standard errors of the maximum likelihood estimators are defined by the diagonal elements of the matrix \(\left[ {i(\theta ^{k})} \right] ^{-1}, k=1,\;2,\;3,\;4,\;5.\)
The performance statistics of the stem taper equations for the diameter and the volume included four statistical indices: mean absolute prediction bias (MAB) [18], precision (P) [18], the least squares-based Akaike’ [26] information criterion (AIC) and a coefficient of determination (\(R^{2})\). The AIC can generally be used for the identification of an optimum model in a class of competing models.
3 Results and Discussion
We focus on the modeling of Scots pine (Pinus Sylvestris) tree data set. Scots pine trees dominate Lithuanian forests, growing on Arenosols and Podzols forest sites and covering 725,500 ha. Stem measurements for 300 Scots pine trees were used for volume and stem profile models analysis. All section measurements include of 3,821 data points. Summary statistics for the diameter outside the bark at breast height (D), total height (H), volume (V) and age (A) of all the trees used for parameters estimate and models comparison are presented in Table 1.
To test the compatibility between taper and volume equations of all used stem taper models, the observed and predicted volume values from the sampled trees were calculated in the following form
Using the estimation data set, the parameters of SDEs stem taper Models 1–5 were estimated by the maximum likelihood procedure. Estimation results are presented in Table 2. All parameters of the Models 1–5 are highly significant (\(p<0.001\)).
To test the reliability of all the tested stem taper models, the observed and predicted volume values for the sampled trees were calculated by Eq. (37). Table 3 lists the fit statistics for the new developed stem taper and volume models. The best values of the fit statistics were produced by the stem taper Models 2 and 3 with fixed tree butt.
Another way to evaluate and compare the stem taper and volume models is to examine the graphics of the residuals at different predicted diameters and volumes. The residuals are the differences between the measured and predicted diameters and volumes. Graphical diagnostics of the residuals for the stem taper and volume predictions indicated that the residuals calculated using the SDEs stem taper Model 3 had more homogeneous variance than the other models.

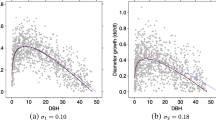
Stem tapers and standard deviations for three randomly selected trees generated using the SDEs stem taper Models 2 (left) and 3 (right): solid line—taper curve; dash dot line—standard deviation of a tree diameter; diamond—observed data
Taper profiles for three randomly selected Scots pine trees (diameters outside the bark at breast heights of 6.3 cm, 17.0 cm, 40.7 cm, and total tree heights of 6.8 m, 21.1 m, 30.3 m) were constructed using SDEs stem taper Models 2, 3 and are plotted in Fig. 1. Figure 1 includes the stem taper curves and the standard deviation curves. It is clear that all of the taper curves followed the stem data very closely.
4 Conclusion and Future Work
The new taper models were developed using SDEs. Comparison of the predicted stem taper and volume values calculated using SDEs Models 2 and 3 with the values obtained using the other models revealed a comparable predictive power of the stem taper Model 3 with fixed stem butt.
The SDEs approach allows us to incorporate new tree variables, mixed-effect parameters, and new forms of stochastic dynamics.
The variance functions developed here can be applied generate weights in every linear and nonlinear least squares regression stem taper model the weighted least squares form.
Finally, stochastic differential equation methodology may be of interest in diverse of areas of research that are far beyond the modelling of tree taper and volume.
References
Jana D, Chakraborty S, Bairagi N (2012) Stability, nonlinear oscillations and bifurcation in a delay-induced predator-prey system with harvesting. Eng Lett 20(3):238–246
Boughamoura W, Trabelsi F (2011) Variance reduction with control variate for pricing asian options in a geometric L’evy model. IAENG Int J Appl Math 41(4):320–329
Bartkevičius E, Petrauskas E, Rupšys P, Russetti G (2012) Evaluation of stochastic differential equations approach for predicting individual tree taper and volume, Lecture notes in engineering and computer science. In: Proceedings of the world congress on engineering, WCE 2012, 4–6 July 2012, vol 1. London, pp 611–615
Suzuki T (1971) Forest transition as a stochastic process. Mit Forstl Bundesversuchsanstalt Wein 91:69–86
Tanaka K (1986) A stochastic model of diameter growth in an even-aged pure forest stand. J Jpn For Soc 68:226–236
Rupšys P, Petrauskas E, Mažeika J, Deltuvas R (2007) The gompertz type stochastic growth law and a tree diameter distribution. Baltic For 13:197–206
Rupšys P, Petrauskas E (2009) Forest harvesting problem in the light of the information measures. Trends Appl Sci Res 4:25–36
Rupšys P, Petrauskas E (2010) The bivariate Gompertz diffusion model for tree diameter and height distribution. For Sci 56:271–280
Rupšys P, Petrauskas E (2010) Quantifying tree diameter distributions with one-dimensional diffusion processes. J Biol Syst 18:205–221
Rupšys P, Bartkevičius E, Petrauskas E (2011) A univariate stochastic gompertz model for tree diameter modeling. Trends Appl Sci Res 6:134–153
Rupšys P, Petrauskas E (2012) Analysis of height curves by stochastic differential equations. Int J Biomath 5(5):1250045
Rupšys P, Petrauskas E, Bartkevičius E, Memgaudas R (2011) Re-examination of the taper models by stochastic differential equations. Recent advances in signal processing, computational geometry and systems theory pp 43–47
Kozak A, Munro DD, Smith JG (1969) Taper functions and their application in forest inventory. For Chron 45:278–283
Max TA, Burkhart HE (1976) Segmented polynomial regression applied to taper equations. For Sci 22:283–289
Kozak A (2004) My last words on taper equations. For Chron 80:507–515
Trincado J, Burkhart HE (2006) A generalized approach for modeling and localizing profile curves. For Sci 52:670–682
Yang Y, Huang S, Meng SX (2009) Development of a tree-specific stem profile model for White spruce: a nonlinear mixed model approach with a generalized covariance structure. Forestry 82:541–555
Rupšys P, Petrauskas E (2010) Development of q-exponential models for tree height, volume and stem profile. Int J Phys Sci 5:2369–2378
Westfall JA, Scott CT (2010) Taper models for commercial tree species in the Northeastern United States. For Sci 56:515–528
Petrauskas E, Rupšys P, Memgaudas R (2011) Q-exponential variable form of a stem taper and volume models for Scots pine Pinus Sylvestris) in Lithuania. Baltic For 17(1):118–127
Itô K (1936) On stochastic processes. Jpn J Math 18:261–301
Oksendal BK (2002) Stochastic differential equations, an introduction with applications. Springer, New York, p 236
Uhlenbeck GE, Ornstein LS (1930) On the theory of Brownian motion. Physical Rev 36:823–841
Max TA, Burkhart HE (1976) Segmented polynomial regression applied to taper equations. For Sci 22:283–289
Fisher RA (1922) On the mathematical foundations of theoretical statistics. Philos Trans R Soc A-Math Phys Eng Sci 222:309–368
Akaike H (1974) A new look at the statistical model identification. IEEE Trans Autom Control 19:716–723
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer Science+Business Media Dordrecht
About this chapter
Cite this chapter
Rupšys, P. (2013). The Further Development of Stem Taper and Volume Models Defined by Stochastic Differential Equations. In: Yang, GC., Ao, Sl., Gelman, L. (eds) IAENG Transactions on Engineering Technologies. Lecture Notes in Electrical Engineering, vol 229. Springer, Dordrecht. https://doi.org/10.1007/978-94-007-6190-2_10
Download citation
DOI: https://doi.org/10.1007/978-94-007-6190-2_10
Published:
Publisher Name: Springer, Dordrecht
Print ISBN: 978-94-007-6189-6
Online ISBN: 978-94-007-6190-2
eBook Packages: EngineeringEngineering (R0)