
Abstract
Cluster ensemble technique has attracted serious attention in the area of unsupervised learning. It aims at improving robustness and quality of clustering scheme, particularly in scenarios where either randomization or sampling is the part of the clustering algorithm.
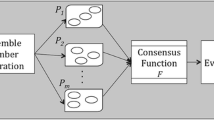
In this paper, we address the problem of instability and non robustness in K-means clusterings. These problems arise naturally because of random seed selection by the algorithm, order sensitivity of the algorithm and presence of noise and outliers in data. We propose a cluster ensemble method based on Discriminant Analysis to obtain robust clustering using K-means clusterer. The proposed algorithm operates in three phases. The first phase is preparatory in which multiple clustering schemes generated and the cluster correspondence is obtained. The second phase uses discriminant analysis and constructs a label matrix. In the final stage, consensus partition is generated and noise, if any, is segregated. Experimental analysis using standard public data sets provides strong empirical evidence of the high quality of resultant clustering scheme.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


References
Reza Ghaemi, M., Nasir Sulaiman, H.I., Mustapha, N.: A survey: Clustering ensembles techniques. In: Proceedings of World academy of science, Engineering and Technology 38, 2070–3740 (2070)
Topchy, A., Behrouz Minaei-Bidgoli, A., Punch, W.F.: Adaptive clustering ensembles. In: ICPR, pp. 272–275 (2004)
Kuncheva, L., et al.: Evaluation of stability of k-means cluster ensembles with respect to random initialization. IEEE Transcations on pattern analysis and machine intelligence 11(28), 1798–1808 (2006)
Fred, A.L.N., Jain, A.K.: Data clustering using evidence accumulation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 835–850 (2002)
Topchy, A., Jain, A.K., Punch, W.F.: A mixture model for clustering ensembles. In: SDM (2004)
Strehl, A., Ghosh, J.: Relationship-based clustering and cluster ensembles for high-dim. data. PhD thesis (May 2002)
Fischer, B., Buhmann, J.M.: Path-based clustering for grouping of smooth curves and texture segmentation. Transaction on Pattern Analysis and Machine Intelligence 25(4) (April 2003)
Bock, H.H.: Origins and extensions of the k-means algorithm in cluster analysis. Electronic Journal for History of Probability and Statistics 4(2) (2008)
Anderson, J., et al.: Machine Learning: An Artificial Intelligence Approach. Morgan Kaufmann, San Francisco (1983)
Han, J., Kamber, M.: Data Mining: Concepts and Techniques, 2nd edn., Morgan Kaufmann Publishers, San Diego (August 2006)
MacQueen, J.: Some methods for classification and analysis of mulivariate observations (2008)
Tapas, K., et al.: An efficient k-means clustering algorithm:analysis and implementation. CIKM, Mcleen, Virginia, USA, vol. 24(7) (July 2002)
Bradley, P.S., Fayyad, U.M.: Refining initial points for k-means clustering. In: ICML 1998, May 1998, vol. 24, pp. 91–99 (1998)
Dhillon, I.S., Yuqiang Guan, B.K.: Kernel k-means, spectral clustering and normalized cuts. In: KDD, Seattle, Washigton, USA (August 2004)
I, K.L., Hadjitodorov, S.T.: Using diversity in cluster ensembles. In: Proceedings IEEE International Conference on Systems, Man and Cybernatics, The Netherlands, pp. 1214–1219 (2004)
Fred, A.L.N.: Finding consistent cluster in data partitions. MCS 19(9), 309–318 (2001)
Strehl, A., Ghosh, J.: Cluster ensemble knowledge reuse framework for combining partitions (2002)
Topchy, A., Jain, A.K., Punch, W.: Combining multiple weak clusterings. In: Proceedings of the Third IEEE International Conference on Data Mining (2003)
Johnson, R.A., Wichern, D.W.: Applied Multivariate Statistical Analysis. Prentice-Hall, Upper Saddle River (August 1979)
Hu, X., Yoo, I.: Cluster ensemble and its applications in gene expression analysis. In: 2nd Asia-pacific Bioinformatics Conference, Dunedin, New Zealand
He, Z., Xiaofei, X., Deng, S.: A cluster ensemble method for clustering categorical data. In: Department of Computer Science and Engineering, Harbin Institute of Technology, China, August, vol. (2), pp. 153–172 (2002)
Minaei-Bidgoli, B., Topchy, A., Punch, W.F.: Ensembles of partitions via data resampling, Michigan State University, East Lancing, MI, USA
Frossyniotis, D., Stafylopatis, M.A.: A multi-clustering fusion algorithm. Journal of Computer Science and Technology 17(2), 118–128 (2002)
Narain, Malhotra, P.: Handbook of statistical genetics. IASRI, New Delhi-12 and Printed at S.C.Printers (1979)
Maimon, O., Rokech, L.: Data Mining and Knowledge discovery Handbook. Springer, Heidelberg (2004)
Ankerst, M., Breuig, M.M., Kriegel, H.P., Sander, J.: Optics: Ordering points to identify the clustering structure. In: ACM SIGMOD 1999 Int. Conf. on Management of Data, Philadelphia, PA (1999)
Chang, C.H., Fu, A.W., Zhang, Y.: Entropy based subspace clustering for mining numerical data. In: Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 1999), San Diego (August 1999)
Uci repository, http://www.ics.uci.edu
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2010 Springer-Verlag Berlin Heidelberg
About this paper
Cite this paper
Bhatnagar, V., Ahuja, S. (2010). Robust Clustering Using Discriminant Analysis. In: Perner, P. (eds) Advances in Data Mining. Applications and Theoretical Aspects. ICDM 2010. Lecture Notes in Computer Science(), vol 6171. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-14400-4_11
Download citation
DOI: https://doi.org/10.1007/978-3-642-14400-4_11
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-642-14399-1
Online ISBN: 978-3-642-14400-4
eBook Packages: Computer ScienceComputer Science (R0)