
Abstract
In this chapter, we provide an overview of existing algorithms for blind source separation of convolutive audio mixtures. We provide a taxonomy in which many of the existing algorithms can be organized and present published results from those algorithms that have been applied to real-world audio separation tasks.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
- Independent Component Analysis
- Finite Impulse Response
- Independent Component Analysis
- Source Separation
- Blind Source Separation
These keywords were added by machine and not by the authors. This process is experimental and the keywords may be updated as the learning algorithm improves.
During the past decades, much attention has been given to the separation of mixed sources, in particular for the blind case where both the sources and the mixing process are unknown and only recordings of the mixtures are available. In several situations it is desirable to recover all sources from the recorded mixtures, or at least to segregate a particular source. Furthermore, it may be useful to identify the mixing process itself to reveal information about the physical mixing system.
In some simple mixing models each recording consists of a sum of differently weighted source signals. However, in many real-world applications, such as in acoustics, the mixing process is more complex. In such systems, the mixtures are weighted and delayed, and each source contributes to the sum with multiple delays corresponding to the multiple paths by which an acoustic signal propagates to a microphone. Such filtered sums of different sources are called convolutive mixtures. Depending on the situation, the filters may consist of a few delay elements, as in radio communications, or up to several thousand delay elements as in acoustics. In these situations the sources are the desired signals, yet only the recordings of the mixed sources are available and the mixing process is unknown.
There are multiple potential applications of convolutive blind source separation. In acoustics different sound sources are recorded simultaneously with possibly multiple microphones. These sources may be speech or music, or underwater signals recorded in passive sonar [52.1]. In radio communications, antenna arrays receive mixtures of different communication signals [52.2,3]. Source separation has also been applied to astronomical data or satellite images [52.4]. Finally, convolutive models have been used to interpret functional brain imaging data and biopotentials [52.5,6,7,8].
This chapter considers the problem of separating linear convolutive mixtures focusing in particular on acoustic mixtures. The cocktail-party problem has come to characterize the task of recovering speech in a room of simultaneous and independent speakers [52.9,10]. Convolutive blind source separation (BSS) has often been proposed as a possible solution to this problem as it carries the promise to recover the sources exactly. The theory on linear noise-free systems establishes that a system with multiple inputs (sources) and multiple output (sensors) can be inverted under some reasonable assumptions with appropriately chosen multidimensional filters [52.11]. The challenge lies in finding these convolution filters.
There are already a number of partial reviews available on this topic [52.12,13,14,15,16,17,18,19,20,21,22]. The purpose of this chapter is to provide a complete survey of convolutive BSS and identify a taxonomy that can organize the large number of available algorithms. This may help practitioners and researchers new to the area of convolutive source separation obtain a complete overview of the field. Hopefully those with more experience in the field can identify useful tools, or find inspiration for new algorithms. Figure 52.1 provides an overview of the different topics within convolutive BSS and in which section they are covered. An overview of published results is given in Sect. 52.7.

Overview of important areas within blind separation of convolutive sources
The Mixing Model
First we introduce the basic model of convolutive mixtures. At the discrete time index t, a mixture of N source signals s(t) = [s 1(t),… , s N (t)]T are received at an array of M sensors. The received signals are denoted by x(t) = [x 1(t),… , x M (t)]T. In many real-world applications the sources are said to be convolutively (or dynamically) mixed. The convolutive model introduces the following relation between the m-th mixed signal, the original source signals, and some additive sensor noise v m (t):

The mixed signal is a linear mixture of filtered versions of each of the source signals, and a mnk represent the corresponding mixing filter coefficients. In practice, these coefficients may also change in time, but for simplicity the mixing model is often assumed stationary. In theory the filters may be of infinite length, which may be implemented as infinite impulse response (IIR) systems, however, in practice it is sufficient to assume K <∞. In matrix form the convolutive model can be written:

where A k is an M × N matrix that contains the k-th filter coefficients. v(t) is the M × 1 noise vector. In the z-domain the convolutive mixture (52.2) can be written:

where A(z) is a matrix with finite impulse response (FIR) polynomials in each entry [52.23].
Special Cases
There are some special cases of the convolutive mixture which simplify (52.2).
Instantaneous Mixing Model
Assuming that all the signals arrive at the sensors at the same time without being filtered, the convolutive mixture model (52.2) simplifies to

This model is known as the instantaneous or delayless (linear) mixture model. Here, A = A 0, is an M × N matrix containing the mixing coefficients. Many algorithms have been developed to solve the instantaneous mixture problem, see e.g., [52.17,24].
Delayed Sources
Assuming a reverberation-free environment with propagation delays the mixing model can be simplified to

where k mn is the propagation delay between source n and sensor m.
Noise Free
In the derivation of many algorithms, the convolutive model (52.2) is assumed to be noise-free, i.e.,

Over- and Underdetermined Sources
Often it is assumed that the number of sensors equals (or exceeds) the number of sources in which case linear methods may suffice to invert the linear mixing. However, if the number of sources exceeds the number of sensors the problem is underdetermined, and even under perfect knowledge of the mixing system linear methods will not be able to recover the sources.
Convolutive Model in the Frequency Domain
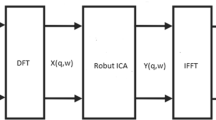
The convolutive mixing process (52.2) can be simplified by transforming the mixtures into the frequency domain. The linear convolution in the time domain can be written in the frequency domain as separate multiplications for each frequency:

At each frequency, ω = 2πf, A(ω) is a complex M × N matrix, X(ω) and V(ω) are complex M × 1 vectors, and similarly S(ω) is a complex N × 1 vector. The frequency transformation is typically computed using a discrete Fourier transform (DFT) within a time frame of length T starting at time t:

and correspondingly for S(ω, t) and V(ω, t). Often a windowed discrete Fourier transform is used:

where the window function w(τ) is chosen to minimize band overlap due to the limited temporal aperture. By using the fast Fourier transform (FFT) convolutions can be implemented efficiently in the discrete Fourier domain, which is important in acoustics as it often requires long time-domain filters.
Block-Based Model
Instead of modeling individual samples at time t one can also consider a block consisting of T samples. The equations for such a block can be written as:

The M-dimensional output sequence can be written as an MT × 1 vector:

where x T(t) = [x 1(t),⋯ , x M (t)]. Similarly, the N-dimensional input sequence can be written as an N(T + K − 1) × 1 vector:

From this the convolutive mixture can be expressed formally as:

where  has the following form:
has the following form:

The block-Toeplitz matrix  has dimensions MT × N(T + K − 1). On the surface, (52.12) has the same structure as an instantaneous mixture given in (52.4), and the dimensionality has increased by a factor T. However, the models differ considerably as the elements within
has dimensions MT × N(T + K − 1). On the surface, (52.12) has the same structure as an instantaneous mixture given in (52.4), and the dimensionality has increased by a factor T. However, the models differ considerably as the elements within  and
and  are now coupled in a rather specific way.
are now coupled in a rather specific way.
The majority of the work in convolutive source separation assumes a mixing model with a finite impulse response as in (52.2). A notable exception is the work by Cichocki, which also considers an autoregressive (AR) component as part of the mixing model [52.18]. The autoregressive moving-average (ARMA) mixing system proposed there is equivalent to a first-order Kalman filter with an infinite impulse response.
The Separation Model
The objective of blind source separation is to find an estimate y(t) that is a model of the original source signals s(t). For this, it may not be necessary to identify the mixing filters A k explicitly. Instead, it is often sufficient to estimate separation filters W l that remove the cross-talk introduced by the mixing process. These separation filters may have a feed-back structure with an infinite impulse response, or may have a finite impulse response expressed as feedforward structure.
Feedforward Structure
An FIR separation system is given by

or in matrix form

As with the mixing process, the separation system can be expressed in the z-domain as

and can also be expressed in block-Toeplitz form with the corresponding definitions for  and
and  [52.25]:
[52.25]:

Table 52.1 summarizes the mixing and separation equations in the different domains.
Relation Between Source and Separated Signals
The goal in source separation is not necessarily to recover identical copies of the original sources. Instead, the aim is to recover model sources without interferences from other sources, i.e., each separated signal y n (t) should contain signals originating from a single source only (Fig. 52.3). Therefore, each model source signal can be a filtered version of the original source signals, i.e.,

as illustrated in Fig. 52.2. The criterion for separation, i.e., interference-free signals, is satisfied if the recovered signals are permuted, and possibly scaled and filtered versions of the original signals, i.e.,

where P is a permutation matrix, and Λ(z) is a diagonal matrix with scaling filters on its diagonal. If one can identify A(z) exactly, and choose W(z) to be its (stable) inverse, then Λ(z) is an identity matrix, and one recovers the sources exactly. In source separation, instead, one is satisfied with convolved versions of the sources, i.e., arbitrary diagonal Λ(z).

The source signals Y(z) are mixed with the mixing filter A(z). An estimate of the source signals is obtained through an unmixing process, where the received signals X(z) are unmixed with the filter W(z). Each estimated source signal is then a filtered version of the original source, i.e., G(z) = W(z)A(z). Note that the mixing and the unmixing filters do not necessarily have to be of the same order

Illustration of a speech source. It is not always clear what the desired acoustic source should be. It could be the acoustic wave as emitted from the mouth. This corresponds to the signal as it would have been recorded in an anechoic chamber in the absence of reverberations. It could be the individual source as it is picked up by a microphone array, or it could be the speech signal as it is recorded on microphones close to the two eardrums of a person. Due to reverberations and diffraction, the recorded speech signal is most likely a filtered version of the signal at the mouth
Feedback Structure
The mixing system given by (52.2) is called a feedforward system. Often such FIR filters are inverted by a feedback structure using IIR filters. The estimated sources are then given by the following equation, where the number of sources equals the number of receivers:

and u nml are the IIR filter coefficients. This can also be written in matrix form

The architecture of such a network is shown in Fig. 52.4. In the z-domain, (52.21) can be written as [52.26]

provided [I + U(z)]−1 exists and all poles are within the unit circle. Therefore,

The feedforward and the feedback network can be combined to a so-called hybrid network, where a feedforward structure is followed by a feedback network [52.27,28].

Recurrent unmixing (feedback) network given by equation (52.21). The received signals are separated by an IIR filter to achieve an estimate of the source signals
Example: The TITO System
A special case, which is often used in source separation work is the two-input-two-output (TITO) system [52.29]. It can be used to illustrate the relationship between the mixing and unmixing system, feedforward and feedback structures, and the difference between recovering sources versus generating separated signals.
Figure 52.5 shows a diagram of a TITO mixing and unmixing system. The signals recorded at the two microphones are described by the following equations:


The mixing system is thus given by

which has the following inverse

If the two mixing filters a
12(z) and a
21(z) can be identified or estimated as  and
and  , the separation system can be implemented as
, the separation system can be implemented as


A sufficient FIR separating filter is

However, the exact sources are not recovered until the model sources y(t) are filtered with the IIR filter  . Thus, the mixing process is invertible, provided that the inverse IIR filter is stable. If a filtered version of the separated signals is acceptable, we may disregard the potentially unstable recursive filter in (52.27) and limit separation to the FIR inversion of the mixing system with (52.30).
. Thus, the mixing process is invertible, provided that the inverse IIR filter is stable. If a filtered version of the separated signals is acceptable, we may disregard the potentially unstable recursive filter in (52.27) and limit separation to the FIR inversion of the mixing system with (52.30).

The two mixed sources s
1 and s
2 are mixed by an FIR mixing system. The system can be inverted by an alternative system if the estimates  and
and  of the mixing filters a
12(z) and a
12(z) are known. Furthermore, if the filter
of the mixing filters a
12(z) and a
12(z) are known. Furthermore, if the filter  is stable, the sources can be perfectly reconstructed as they were recorded at the microphones
is stable, the sources can be perfectly reconstructed as they were recorded at the microphones
Identification
Blind identification deals with the problem of estimating the coefficients in the mixing process A k . In general, this is an ill-posed problem, and no unique solution exists. In order to determine the conditions under which the system is blindly identifiable, assumptions about the mixing process and the input data are necessary. Even though the mixing parameters are known, this does not imply that the sources can be recovered. Blind identification of the sources refers to the exact recovery of sources. Therefore one should distinguish between the conditions required to identify the mixing system and the conditions necessary to identify the sources. The limitations for the exact recovery of sources when the mixing filters are known are discussed in [52.11,30,31]. For a recent review on identification of acoustic systems see [52.32]. This review considers systems with single and multiple inputs and outputs for the case of completely known sources as well as blind identification, where both the sources and the mixing channels are unknown.
Separation Principle
Blind source separation algorithms are based on different assumptions on the sources and the mixing system. In general, the sources are assumed to be independent or at least uncorrelated. The separation criteria can be divided into methods based on higher-order statistics (HOS), and methods based on second-order statistics (SOS). In convolutive separation it is also assumed that sensors receive N linearly independent versions of the sources. This means that the sources should originate from different locations in space (or at least emit signals into different orientations) and that there are at least as many sources as sensors for separation, i.e., M ≥ N.
Instead of spatial diversity a series of algorithms make strong assumptions on the statistics of the sources. For instance, they may require that sources do not overlap in the time-frequency domain, utilizing therefore a form of sparseness in the data. Similarly, some algorithms for acoustic mixtures exploit regularity in the sources such as common onset, harmonic structure, etc. These methods are motivated by the present understanding on the grouping principles of auditory perception commonly referred to as auditory scene analysis. In radio communications a reasonable assumption on the sources is cyclo-stationarity or the fact that source signals take on only discrete values. By using such strong assumptions on the source statistics it is sometimes possible to relax the conditions on the number of sensors, e.g., M < N. The different criteria for separation are summarized in Table 52.2.
Higher-Order Statistics
Source separation based on higher-order statistics is based on the assumption that the sources are statistically independent. Many algorithms are based on minimizing second and fourth order dependence between the model signals. A way to express independence is that all the cross-moments between the model sources are zero, i.e.,

for all τ, α, β ={ 1, 2,…}, and n ≠ n′. Here E[⋅] denotes the statistical expectation. Successful separation using higher-order moments requires that the underlying sources are non-Gaussian (with the exception of at most one), since Gaussian sources have zero higher cumulants [52.60] and therefore equations (52.31) are trivially satisfied without providing useful conditions.
Fourth-Order Statistics
It is not necessary to minimize all cross-moments in order to achieve separation. Many algorithms are based on minimization of second- and fourth-order dependence between the model source signals. This minimization can either be based on second and fourth order cross-moments or second- and fourth-order cross-cumulants. Whereas off-diagonal elements of cross-cumulants vanish for independent signals the same is not true for all cross-moments [52.61]. Source separation based on cumulants has been used by several authors. Separation of convolutive mixtures by means of fourth-order cumulants has also been addressed [52.35,61,62,63,64,65,66,67,68,69,70,71]. In [52.72,73,74], the joint approximate diagonalization of eigenmatrices (JADE) algorithm for complex-valued signals [52.75] was applied in the frequency domain in order to separate convolved source signals. Other cumulant-based algorithms in the frequency domain are given in [52.76,77]. Second- and third-order cumulants have been used by Ye et al. [52.33] for separation of asymmetric signals. Other algorithms based on higher-order cumulants can be found in [52.78,79]. For separation of more sources than sensors, cumulant-based approaches have been proposed in [52.70,80]. Another popular fourth-order measure of non-Gaussianity is kurtosis. Separation of convolutive sources based on kurtosis has been addressed in [52.81,82,83].
Nonlinear Cross-Moments
Some algorithms apply higher-order statistics for separation of convolutive sources indirectly using nonlinear functions by requiring:

where f(⋅) and g(⋅) are odd, nonlinear functions. The Taylor expansion of these functions captures higher-order moments and this is found to be sufficient for separation of convolutive mixtures. This approach was among of the first for separation of convolutive mixtures [52.53] extending an instantaneous blind separation algorithm by Herault and Jutten (H-J) [52.84]. In Back and Tsoi [52.85], the H-J algorithm was applied in the frequency domain, and this approach was further developed in [52.86]. In the time domain, the approach of using nonlinear odd functions has been used by Nguyen Thi and Jutten [52.26]. They present a group of TITO (2 × 2) algorithms based on fourth-order cumulants, nonlinear odd functions, and second- and fourth-order cross-moments. This algorithm has been further examined by Serviere [52.54], and also been used by Ypma et al. [52.55]. In Cruces and Castedo [52.87] a separation algorithm can be found, which can be regarded as a generalization of previous results from [52.26,88]. In Li and Sejnowski [52.89], the H-J algorithm has been used to determine the delays in a beamformer. The H-J algorithm has been investigated further by Charkani and Deville [52.57,58,90]. They extended the algorithm further to colored sources [52.56,91]. Depending on the distribution of the source signals, optimal choices of nonlinear functions were also found. For these algorithms, the mixing process is assumed to be minimum-phase, since the H-J algorithm is implemented as a feedback network. A natural gradient algorithm based on the H-J network has been applied in Choi et al. [52.92]. A discussion of the H-J algorithm for convolutive mixtures can be found in Berthommier and Choi [52.93]. For separation of two speech signals with two microphones, the H-J model fails if the two speakers are located on the same side, as the appropriate separating filters can not be implemented without delaying one of the sources and the FIR filters are constrained to be causal. HOS independence obtained by applying antisymmetric nonlinear functions has also been used in [52.94,95].
Information-Theoretic Methods
Statistical independence between the source signals can also be expressed in terms of the joint probability function (PDF). If the model sources y are independent, the joint PDF can be written as

This is equivalent to stating that model sources y n do not carry mutual information. Information-theoretic methods for source separation are based on maximizing the entropy in each variable. Maximum entropy is obtained when the sum of the entropy of each variable y n equals the total joint entropy in y. In this limit variables do not carry any mutual information and are hence mutually independent [52.96]. A well-known algorithm based on this idea is the Infomax algorithm by Bell and Sejnowski [52.97], which was significantly improved in convergence speed by the natural gradient method of Amari [52.98]. The Infomax algorithm can also be derived directly from model equation (52.33) using maximum likelihood [52.99], or equivalently, using the Kullback-Leibler divergence between the empirical distribution and the independence model [52.100].
In all instances it is necessary to assume, or model, the probability density functions p s (s n ) of the underlying sources s n . In doing so, one captures higher-order statistics of the data. In fact, most information-theoretic algorithms contain expressions rather similar to the nonlinear cross-statistics in (52.32) with f(y n ) =∂ ln p s (y n )/∂y n , and g(y n ) = y n . The PDF is either assumed to have a specific form or it is estimated directly from the recorded data, leading to parametric and nonparametric methods, respectively [52.16]. In nonparametric methods the PDF is captured implicitly through the available data. Such methods have been addressed [52.101,102,103]. However, the vast majority of convolutive algorithms have been derived based on explicit parametric representations of the PDF.
Infomax, the most common parametric method, was extended to the case of convolutive mixtures by Torkkola [52.59] and later by Xi and Reilly [52.104,105]. Both feedforward and feedback networks were used. In the frequency domain it is necessary to define the PDF for complex variables. The resulting analytic nonlinear functions can be derived as [52.106,107]

where p(Y) is the probability density of the model source Y ∈ℂ. Some algorithms assume circular sources in the complex domain, while other algorithms have been proposed that specifically assume noncircular sources [52.108,109].
The performance of the algorithm depends to a certain degree on the selected PDF. It is important to determine if the data has super-Gaussian or sub-Gaussian distributions. For speech commonly a Laplace distribution is used. The nonlinearity is also known as the Bussgang nonlinearity [52.110]. A connection between the Bussgang blind equalization algorithms and the Infomax algorithm is given in Lambert and Bell [52.111]. Multichannel blind deconvolution algorithms derived from the Bussgang approach can be found in [52.23,111,112]. These learning rules are similar to those derived in Lee et al. [52.113].
Choi et al. [52.114] have proposed a nonholonomic constraint for multichannel blind deconvolution. Nonholonomic means that there are some restrictions related to the direction of the update. The nonholonomic constraint has been applied for both a feedforward and a feedback network. The nonholonomic constraint was applied to allow the natural gradient algorithm by Amari et al. [52.98] to cope with overdetermined mixtures. The nonholonomic constraint has also been used in [52.115,116,117,118,119,120,121,122]. Some drawbacks in terms of stability and convergence in particular when there are large power fluctuations within each signal (e.g., for speech) have been addressed in [52.115].
Many algorithms have been derived from (52.33) directly using maximum likelihood (ML) [52.123]. The ML approach has been applied in [52.99,124,125,126,127,128,129,130,131,132]. Closely related to the ML are the maximum a posteriori (MAP) methods. In MAP methods, prior information about the parameters of the model are taken into account. MAP has been used in [52.23,133,134,135,136,137,138,139,140,141].
The convolutive blind source separation problem has also been expressed in a Bayesian formulation [52.142]. The advantage of a Bayesian formulation is that one can derive an optimal, possibly nonlinear, estimator of the sources enabling the estimation of more sources than the number of available sensors. The Bayesian framework has also been applied [52.135,137,143,144,145].
A strong prior on the signal can also be realized via hidden Markov models (HMMs). HMMs can incorporate state transition probabilities of different sounds [52.136]. A disadvantage of HMMs is that they require prior training and they carry a high computational cost [52.146]. HMMs have also been used in [52.147,148].
Second-Order Statistics
In some cases, separation can be based on second-order statistics (SOS) by requiring only uncorrelated sources rather then the stronger condition of independence. Instead of assumptions on higher-order statistics these methods make alternate assumptions such as the nonstationarity of the sources [52.149], or a minimum-phase mixing system [52.50]. By itself, however, second-order conditions are not sufficient for separation. Sufficient conditions for separation are given in [52.15,150]. The main advantage of SOS is that they are less sensitive to noise and outliers [52.13], and hence require less data for their estimation [52.34,50,150,151,152]. The resulting algorithms are often also easier to implement and computationally efficient.
Minimum-Phase Mixing
Early work by Gerven and Compernolle [52.88] had shown that two source signals can be separated by decorrelation if the mixing system is minimum-phase. The FIR coupling filters have to be strictly causal and their inverses stable. The condition for stability is given as |a 12(z)a 21(z)| < 1, where a 12(z) and a 21(z) are the two coupling filters (Fig. 52.5). These conditions are not met if the mixing process is non-minimum-phase [52.153]. Algorithms based on second-order statistic assuming minimum-phase mixing can be found in [52.41,42,50,51,52,154,155,156,157,158].
Nonstationarity
The fact that many signals are nonstationary has been successfully used for source separation. Speech signals in particular can be considered non-stationary on time scales beyond 10 ms [52.159,160]). The temporally varying statistics of nonstationarity sources provides additional information for separation. Changing locations of the sources, on the other hand, generally complicate source separation as the mixing channel changes in time. Separation based on decorrelation of nonstationary signals was proposed by Weinstein et al. [52.29], who suggested that minimizing cross-powers estimated during different stationarity times should give sufficient conditions for separation. Wu and Principe proposed a corresponding joint diagonalization algorithm [52.103,161] extending an earlier method developed for instantaneous mixtures [52.162]. Kawamoto et al. extend an earlier method [52.163] for instantaneous mixtures to the case of convolutive mixtures in the time domain [52.153,164] and frequency domain [52.165]. This approach has also been employed in [52.166,167,168,169] and an adaptive algorithm was suggested by Aichner et al. [52.170]. By combining this approach with a constraint based on whiteness, the performance can be further improved [52.171].
Note that not all of these papers have used simultaneous decorrelation, yet, to provide sufficient second-order constraints it is necessary to minimize multiple cross-correlations simultaneously. An effective frequency-domain algorithm for simultaneous diagonalization was proposed by Parra and Spence [52.149]. Second-order statistics in the frequency domain is captured by the cross-power spectrum,


where the expectations are estimated around some time t. The goal is to minimize the cross-powers represented by the off-diagonal elements of this matrix, e.g., by minimizing:

where Λ y (ω, t) is an estimate of the cross-power spectrum of the model sources and is assumed to be diagonal. This cost function simultaneously captures multiple times and multiple frequencies, and has to be minimized with respect to W(ω) and Λ y (ω, t) subject to some normalization constraint. If the source signals are nonstationary the cross-powers estimated at different times t differ and provide independent conditions on the filters W(ω). This algorithm has been successfully used on speech signals [52.172,173] and investigated further by Ikram and Morgan [52.174,175,176] to determine the trade-offs between filter length, estimation accuracy, and stationarity times. Long filters are required to cope with long reverberation times of typical room acoustics, and increasing filter length also reduces problems associated with the circular convolution in (52.36) (see Sect. 52.5.3). However, long filters increase the number of parameters to be estimated and extend the effective window of time required for estimating cross-powers, thereby potentially losing the benefit of the nonstationarity of speech signals. A number of variations of this algorithm have been proposed subsequently, including time-domain implementations [52.177,178,179], and other methods that incorporate additional assumptions [52.174,180,181,182,183,184,185,186,187]. A recursive version of the algorithm was given in Ding et al. [52.188]. In Robeldo-Arnuncio and Juang [52.189], a version with noncausal separation filters was suggested. Based on a different way to express (52.36), Wang et al. [52.148,190,191,192] proposed a slightly different separation criterion that leads to a faster convergence than the original algorithm by Parra and Spence [52.149].
Other methods that exploit nonstationarity have been derived by extending the algorithm of Molgedey and Schuster [52.193] to the convolutive case [52.194,195] including a common two-step approach of sphering and rotation [52.159,196,197,198,199]. (Any matrix, for instance matrix W, can be represented as a concatenation of a rotation with subsequent scaling, which can be used to remove second-order moments, i.e., sphering, and an additional rotation.)
In Yin and Sommen [52.160] a source separation algorithm was presented based on nonstationarity and a model of the direct path. The reverberant signal paths are considered as noise. A time-domain decorrelation algorithm based on different cross-correlations at different time lags is given in Ahmed et al. [52.200]. In Yin and Sommen [52.201] the cost function is based on minimization of the power spectral density between the source estimates. The model is simplified by assuming that the acoustic transfer function between the source and closely spaced microphones is similar. The simplified model requires fewer computations. An algorithm based on joint diagonalization is suggested in Rahbar and Reilly [52.152,152]. This approach exploits the spectral correlation between the adjacent frequency bins in addition to nonstationarity. Also in [52.202,203] a diagonalization criterion based on nonstationarity was used.
In Olsson and Hansen [52.138,139] the nonstationary assumption has been included in a state-space Kalman filter model.
In Buchner et al. [52.204], an algorithm that uses a combination of non-stationarity, non-Gaussianity, and nonwhiteness has been suggested. This has also been applied in [52.205,206,207]. In the case of more source signals than sensors, an algorithm based on nonstationarity has also been suggested [52.70]. In this approach, it is possible to separate three signals: a mixture of two nonstationary source signals with short-time stationarity and one signal that is long-term stationary. Other algorithms based on the nonstationary assumptions can be found in [52.208,209,210,211,212,213,214].
Cyclo-Stationarity
If a signal is assumed to be cyclo-stationary, its cumulative distribution is invariant with respect to time shifts of some period T multiples thereof. Further, a signal is said to be wide-sense cyclo-stationary if the signals mean and autocorrelation is invariant to shifts of some period T [52.215], i.e.,


An example of a cyclo-stationary signal is a random-amplitude sinusoidal signal. Many communication signals have the property of cyclo-stationarity, and voiced speech is sometimes considered approximately cyclo-stationary [52.216]. This property has been used explicitly to recover mixed sources in, e.g., [52.34,55,118,216,217,218,219,220,221,222]. In [52.220] cyclo-stationarity is used to solve the frequency permutation problem (see Sect. 52.5.1) and in [52.118] it is used as additional criteria to improve separation performance.
Nonwhiteness
Many natural signals, in particular acoustic signals, are temporally correlated. Capturing this property can be beneficial for separation. For instance, capturing temporal correlations of the signals can be used to reduce a convolutive problem to an instantaneous mixture problem, which is then solved using additional properties of the signal [52.25,38,39,40,41,42,43]. In contrast to instantaneous separation where decorrelation may suffice for nonwhite signals, for convolutive separation additional conditions on the system or the sources are required. For instance, Mei and Yin [52.223] suggest that decorrelation is sufficient provided the sources are an ARMA process.
Sparseness in the Time/Frequency Domain
Numerous source separation applications are limited by the number of available microphones. It is in not always guaranteed that the number of sources is less than or equal to the number of sensors. With linear filters it is in general not possible to remove more than M − 1 interfering sources from the signal. By using nonlinear techniques, in contrast, it may be possible to extract a larger number of source signals. One technique to separate more sources than sensors is based on sparseness. If the source signals do not overlap in the time-frequency (T-F) domain it is possible to separate them. A mask can be applied in the T-F domain to attenuate interfering signal energy while preserving T-F bins where the signal of interest is dominant. Often a binary mask is used giving perceptually satisfactory results even for partially overlapping sources [52.224,225]. These methods work well for anechoic (delay-only) mixtures [52.226]. However, under reverberant conditions, the T-F representation of the signals is less sparse. In a mildly reverberant environment (T 60 ≤200 ms) underdetermined sources have been separated with a combination of independent component analysis (ICA) and T-F masking [52.47]. The first N − M signals are removed from the mixtures by applying a T-F mask estimated from the direction of arrival of the signal (Sect. 52.6.1). The remaining M sources are separated by conventional BSS techniques. When a binary mask is applied to a signal, artifacts (musical noise) are often introduced. In order to reduce the musical noise, smooth masks have been proposed [52.47,227].
Sparseness has also been used as a postprocessing step. In [52.77], a binary mask has been applied as post-processing to a standard BSS algorithm. The mask is determined by comparison of the magnitude of the outputs of the BSS algorithm. Hereby a higher signal-to-interference ratio is obtained. This method was further developed by Pedersen et al. in order to segregate underdetermined mixtures [52.228,229]. Because the T-F mask can be applied to a single microphone signal, the segregated signals can be maintained as, e.g., in stereo signals.
Most T-F masking methods do not effectively utilize information from more than two microphones because the T-F masks are applied to a single microphone signal. However, some methods have been proposed that utilize information from more than two microphones [52.225,230].
Clustering has also been used for sparse source separation [52.140,141,230,231,232,233,234,235,236]. If the sources are projected into a space where each source groups together, the source separation problem can be solved with clustering algorithms. In [52.45,46] the mask is determined by clustering with respect to amplitude and delay differences.
In particular when extracting sources from single channels sparseness becomes an essential criterion. Pearlmutter and Zador [52.237] use strong prior information on the source statistic in addition to knowledge of the head-related transfer functions (HRTF). An a priori dictionary of the source signals as perceived through a HRTF makes it possible to separate source signals with only a single microphone. In [52.238], a priori knowledge is used to construct basis functions for each source signals to segregate different musical signals from their mixture. Similarly, in [52.239,240] sparseness has been assumed in order to extract different music instruments.
Techniques based on sparseness are further discussed in the survey by OʼGrady et al. [52.21].
Priors from Auditory Scene Analysis and Psychoacoustics
Some methods rely on insights gained from studies of the auditory system. The work by Bergman [52.241] on auditory scene analysis characterized the cues used by humans to segregate sound sources. This motivated computational algorithms that are referred to as computational auditory scene analysis (CASA). For instance, the phenomenon of auditory masking (the dominant perception of the signal with largest power) has motivated the use of T-F masking for many year [52.242]. In addition to the direct T-F masking methods outlined above, separated sources have been enhanced by filtering based on perceptual masking and auditory hearing thresholds [52.191,243].
Another important perceptual cue that has been used in source separation is pitch frequency, which typically differs for simultaneous speakers [52.135,137,138,147,244,245]. In Tordini and Piazza [52.135] pitch is extracted from the signals and used in a Bayesian framework. During unvoiced speech, which lacks a well-defined pitch they use an ordinary blind algorithm. In order to separate two signals with one microphone, Gandhi and Hasegawa-Johnson [52.137] proposed a state-space separation approach with strong a priori information. Both pitch and mel-frequency cepstral coefficients (MFCC) were used in their method. A pitch codebook as well as an MFCC codebook have to be known in advance. Olsson and Hansen [52.138] used an HMM, where the sequence of possible states is limited by the pitch frequency that is extracted in the process. As a preprocessing step to source separation, Furukawa et al. [52.245] use pitch in order to determine the number of source signals.
A method for separation of more sources than sensors is given in Barros et al. [52.244]. They combined ICA with CASA techniques such as pitch tracking and auditory filtering. Auditory filter banks are used in order to model the cochlea. In [52.244] wavelet filtering has been used for auditory filtering. Another commonly used auditory filter bank is the Gammatone filter-bank (see, e.g., Patterson [52.246] or [52.247,248]). In Roman et al. [52.248] binaural cues have been used to segregate sound sources, whereby interaural time and interaural intensity differences (ITD and IID) have been used to group the source signals.
Time Versus Frequency Domain
The blind source separation problem can either be expressed in the time domain

or in the frequency domain

A survey of frequency-domain BSS is provided in [52.22]. In Nishikawa et al. [52.249] the advantages and disadvantages of the time and frequency-domain approaches are compared. This is summarized in Table 52.3.
An advantage of blind source separation in the frequency domain is that the separation problem can be decomposed into smaller problems for each frequency bin in addition to the significant gains in computational efficiency. The convolutive mixture problem is reduced to instantaneous mixtures for each frequency. Although this simplifies the task of convolutive separation a set of new problems arise: the frequency-domain signals obtained from the DFT are complex-valued. Not all instantaneous separation algorithms are designed for complex-valued signals. Consequently, it is necessary to modify existing algorithms correspondingly [52.5,250,251,252]. Another problem that may arise in the frequency domain is that there are no longer enough data points available to evaluate statistical independence [52.131]. For some algorithms [52.149] the frame size T of the DFT has to be much longer than the length of the room impulse response K (Sect. 52.5.3). Long frames result in fewer data samples per frequency [52.131], which complicates the estimation of the independence criteria. A method that addresses this issue has been proposed by Servière [52.253].
Frequency Permutations
Another problem that arises in the frequency domain is the permutation and scaling ambiguity. If separation is treated for each frequency bin as a separate problem, the source signals in each bin may be estimated with an arbitrary permutation and scaling, i.e.,

If the permutation P(ω) is not consistent across frequency then converting the signal back to the time domain will combine contributions from different sources into a single channel, and thus annihilate the separation achieved in the frequency domain. An overview of the solutions to this permutation problem is given in Sect. 52.6. The scaling indeterminacy at each frequency - the arbitrary solution for Λ(ω) - will result in an overall filtering of the sources. Hence, even for perfect separation, the separated sources may have a different frequency spectrum than the original sources.
Time-Frequency Algorithms
Algorithms that define a separation criteria in the time domain do typically not exhibit frequency permutation problems, even when computations are executed in the frequency domain. A number of authors have therefore used time-domain (TD) criteria combined with frequency-domain implementations that speed up computations [52.101,113,121,171,179,254,255,256,257]. However, note that second-order criteria may be susceptible to the permutation problem even if they are formulated in the time domain [52.184].
Circularity Problem
When the convolutive mixture in the time domain is expressed in the frequency domain by the DFT, the convolution becomes separate multiplications, i.e.,

However, this is only an approximation which is exact only for periodic s(t) with period T, or equivalently, if the time convolution is circular:

For a linear convolution errors occur at the frame boundary, which are conventionally corrected with the overlap-save method. However, a correct overlap-save algorithm is difficult to implement when computing cross-powers such as in (52.36) and typically the approximate expression (52.43) is assumed.
The problem of linear/circular convolution has been addressed by several authors [52.62,121,149,171,258]. Parra and Spence [52.149] note that the frequency-domain approximation is satisfactory provided that the DFT length T is significantly larger than the length of the un-mixing channels. In order to reduce the errors due to the circular convolution, the filters should be at least two times the length of the un-mixing filters [52.131,176].
To handle long impulse responses in the frequency domain, a frequency model which is equivalent to the time-domain linear convolution has been proposed in [52.253]. When the time-domain filter extends beyond the analysis window the frequency response is undersampled [52.22,258]. These errors can be mitigated by spectral smoothing or equivalently by windowing in the time domain. According to [52.259] the circularity problem becomes more severe when the number of sources increases.
Time-domain algorithms are often derived using Toeplitz matrices. In order to decrease the complexity and improve computational speed, some calculations involving Toeplitz matrices are performed using the fast Fourier transform. For that purpose, it is necessary to express the Toeplitz matrices in circulant Toeplitz form [52.23,121,171,195,260,261]. A method that avoids the circularity effects but maintains the computational efficiency of the FFT has been presented in [52.262]. Further discussion on the circularity problem can be found in [52.189].
Subband Filtering
Instead of the conventional linear Fourier domain some authors have used subband processing. In [52.142] a long time-domain filter is replaced by a set of short independent subband filters, which results in faster convergence as compared to the full-band methods [52.214]. Different filter lengths for each subband filter have also been proposed, motivated by the varying reverberation time of different frequencies (typically low frequencies have a longer reverberation time) [52.263].
The Permutation Ambiguity
The majority of algorithms operate in the frequency domain due to the gains in computational efficiency, which are important in particular for acoustic mixtures that require long filters. However, in frequency-domain algorithms the challenge is to solve the permutation ambiguity, i.e., to make the permutation matrix P(ω) independent of frequency. Especially when the number of sources and sensors is large, recovering consistent permutations is a severe problem. With N model sources there are N! possible permutations in each frequency bin. Many frequency-domain algorithms provide ad hoc solutions, which solve the permutation ambiguity only partially, thus requiring a combination of different methods. Table 52.4 summarizes different approaches. They can be grouped into two categories:
-
1.
Consistency of the filter coefficients
-
2.
Consistency of the spectrum of the recovered signals
The first exploits prior knowledge about the mixing filters, and the second uses prior knowledge about the sources. Within each group the methods differ in the way consistency across frequency is established, varying sometimes in the metric they use to measure distance between solutions at different frequencies.
Consistency of the Filter Coefficients
Different methods have been used to establish consistency of filter coefficients across frequency, such as constraints on the length of the filters, geometric information, or consistent initialization of the filter weights.
Consistency across frequency can be achieved by requiring continuity of filter values in the frequency domain. One may do this directly by comparing the filter values of neighboring frequencies after adaptation, and pick the permutation that minimize the Euclidean distance between neighboring frequencies [52.74,269]. Continuity (in a discrete frequency domain) is also expressed as smoothness, which is equivalent with a limited temporal support of the filters in the time domain. The simplest way to implement such a smoothness constraint is by zero-padding the time-domain filters prior to performing the frequency transformation [52.264]. Equivalently, one can restrict the frequency-domain updates to have a limited support in the time domain. This method is explained in Parra et al. [52.149] and has been used extensively [52.119,122,161,174,188,190,192,201,269,283]. Ikram and Morgan [52.174,176] evaluated this constraint and point out that there is a trade-off between the permutation alignment and the spectral resolution of the filters. Moreover, restricting the filter length may be problematic in reverberant environments where long separation filters are required. As a solution they have suggest to relax the constraint on filter length after the algorithm converges to satisfactory solutions [52.176].
Another suggestion is to assess continuity after accounting for the arbitrary scaling ambiguity. To do so, the separation matrix can be normalized as proposed in [52.265]:

where Λ(ω) is a diagonal matrix and  is a matrix with unit diagonal. The elements of
is a matrix with unit diagonal. The elements of  ,
,  are the ratios between the filters and these are used to assess continuity across frequencies [52.48,220].
are the ratios between the filters and these are used to assess continuity across frequencies [52.48,220].
Instead of restricting the unmixing filters, Pham et al. [52.202] have suggested to require continuity in the mixing filters, which is reasonable as the mixing process will typically have a shorter time constant. A specific distance measure has been proposed by Asano et al. [52.267,284]. They suggest to use the cosine between the filter coefficients of different frequencies ω 1 and ω 2:

where a n (ω) is the n-th column vector of A(ω), which is estimated as the pseudo-inverse of W(ω). Measuring distance in the space of separation filters rather than mixing filters was also suggested because these may better reflect the spacial configuration of the sources [52.285].
In fact, continuity across frequencies may also be assessed in terms of the estimated spatial locations of sources. Recall that the mixing filters are impulse responses between the source locations and the microphone locations. Therefore, the parameters of the separation filters should account for the position of the source in space. Hence, if information about the sensor location is available it can be used to address the permutation problem.
To understand this, consider the signal that arrives at an array of sensors. Assuming a distant source in an reverberation-free environment the signal approximates a plane wave. If the plane wave arrives at an angle to the microphone array it will impinge on each microphone with a certain delay (Fig. 52.6). This delay τ is given by the microphone distance d, the velocity of the wave c, and the direction-of-arrival (DOA) angle θ:

Filters that compensate for this delay can add the microphone signals constructively (or destructively) to produce a maximum (or minimum) response in the DOA. Hence, the precise delay in filters (which in the frequency domain correspond to precise phase relationships) establishes a relationship between different frequencies that can be used to identify correct permutations. This was first considered by Soon et al. [52.286].

Linear array with M sensors separated by distance d. The sensors are placed in a free field. A source signal is considered coming from a point source a distance r away from the sensor array. The source signal is placed in the far field, i.e., r ≫ d. Therefore the incident wave is planar and the arrival angle θ is the same for all the sensors
To be specific, each row in the separation matrix  defines a directivity pattern,
and therefore each row can be thought of as a separate beamformer. This directivity pattern is determined by the transfer function between the source and the filter output. The magnitude response of the n-th output is given by
defines a directivity pattern,
and therefore each row can be thought of as a separate beamformer. This directivity pattern is determined by the transfer function between the source and the filter output. The magnitude response of the n-th output is given by

where a(ω) is an M × 1 vector representing the propagation of a distant source with DOA θ to the sensor array. When M sensors are available, it is possible to place M − 1 nulls in each of the M directivity patterns, i.e., directions from which the arriving signal is canceled out. In an ideal, reverberation-free environment separation is achieved if these nulls point to the directions of the interfering sources. The locations of these nulls, as they may be identified by the separation algorithm, can be used to resolve the permutation ambiguity [52.77,81,131,266,287,288,289,290]. These techniques draw strong parallels between source separation solutions and beamforming. The DOAs do not have to be known in advance and can instead be extracted from the resulting separation filters. Note, however, that the ability to identify source locations is limited by the physics of wave propagation and sampling: distant microphones will lead to grading lobes which will confuse the source locations, while small aperture limits spatial resolution at low frequencies. Ikram and Morgan [52.175] extend the idea of Kurita et al. [52.266] to the case where the sensor space is wider than one half of the wavelength. Source locations are estimated at lower frequencies, which do not exhibit grating lobes. These estimates are then used to determine the correct nulls for the higher frequencies and hereby the correct permutations. In order to resolve permutations when sources arrive from the same direction, Mukai et al. [52.291] use a near-field model. Mitianoudis and Davies [52.268] suggested frequency alignment based on DOA estimated with the multiple signal classification (MuSIC) algorithm [52.292]. A subspace method has been used in order to avoid constraints on the number of sensors. Knaak et al. [52.222] include DOA information as a part of the BSS algorithm in order to avoid permutation errors. Although all these methods assume a reverberation-free environment they give reasonable results in reverberant environments as long as the source has a strong direct path to the sensors.
Two other methods also utilize geometry. In the case of moving sources, where only one source is moving, the permutation can be resolved by noting that only one of the parameters in the separation matrix changes [52.167]. If visual cues are available, they may also be used to solve the permutation ambiguity [52.148].
Instead of using geometric information as a separate step to solve the permutation problem Parra and Alvino include geometric information directly into the cost function [52.184,185]. This approach has been applied to microphone arrays under reverberant conditions [52.187]. Baumann et al. [52.72] have also suggested a cost function, which includes the DOA estimation. The arrival angles of the signals are found iteratively and are included in the separation criterion. Baumann et al. [52.73] also suggest a maximum-likelihood approach to solve the permutation problem. Given the probability of a permuted or unpermuted solution as function of the estimated zero directions, the most likely permutation is found.
Gotanda et al. [52.270] proposed a method to reduce the permutation problem based on the split spectral difference, and the assumption that each source is closer to one microphone. The split spectrum is obtained when each of the separated signals are filtered by the estimated mixing channels.
Finally, for iterative update algorithms a proper initialization of the separation filters can result in consistent permutations across frequencies. Smaragdis [52.250] proposed to estimate filter values sequentially starting with low frequencies and initializing filter values with the results of the previous lower frequency. This will tend to select solutions with filters that are smooth in the frequency domain, or equivalently, filters that are short in the time domain. Filter values may also be initialized to simple beamforming filters that point to estimated source locations. The separation algorithm will then tend to converge to solutions with the same target source across all frequencies [52.184,271].
Consistency of the Spectrum of the Recovered Signals
Some solutions to the permutation ambiguity are based on the properties of speech. Speech signals have strong correlations across frequency due to a common amplitude modulation.
At the coarsest level the power envelope of the speech signal changes depending on whether there is speech or silence, and within speech segments the power of the carrier signal induces correlations among the amplitude of different frequencies. A similar argument can be made for other natural sounds. Thus, it is fair to assume that natural acoustic signals originating from the same source have a correlated amplitude envelope for neighboring frequencies. A method based on this comodulation property was proposed by Murata et al. [52.159,196]. The permutations are sorted to maximize the correlation between different envelopes. This is illustrated in Fig. 52.7. This method has also been used in [52.198,199,203,263,287,293]. Rahbar and Reilly [52.152,209] suggest efficient methods for finding the correct permutations based on cross-frequency correlations.

For speech signals, it is possible to estimate the permutation matrix by using information on the envelope of the speech signal (amplitude modulation). Each speech signal has a particular envelope. Therefore, by comparison with the envelopes of the nearby frequencies, it is possible to order the permuted signals
Asano and Ikeda [52.294] report that the method sometimes fails if the envelopes of the different source signals are similar. They propose the following function to be maximized in order to estimate the permutation matrix:

where  is the power envelope of y and P(ω) is the permutation matrix. This approach has also been adopted by Peterson and Kadambe [52.232]. Kamata et al. [52.282] report that the correlation between envelopes of different frequency channels may be small, if the frequencies are too far from each other. Anemüller and Gramms [52.127] avoid the permutations since the different frequencies are linked in the update process. This is done by serially switching from low to high-frequency components while updating.
is the power envelope of y and P(ω) is the permutation matrix. This approach has also been adopted by Peterson and Kadambe [52.232]. Kamata et al. [52.282] report that the correlation between envelopes of different frequency channels may be small, if the frequencies are too far from each other. Anemüller and Gramms [52.127] avoid the permutations since the different frequencies are linked in the update process. This is done by serially switching from low to high-frequency components while updating.
Another solution based on amplitude correlation is the so-called amplitude modulation decorrelation (AMDecor) algorithm presented by Anemüller and Kollmeier [52.126,272]. They propose to solve the source separation problem and the permutation problems simultaneously. An amplitude modulation correlation is defined, where the correlation between the frequency channels ω k and ω l of the two spectrograms Y a(ω, t) and Y b(ω, t) is calculated as

This correlation can be computed for all combinations of frequencies. This results in a square matrix C(Y a, Y b) with sizes equal to the number of frequencies in the spectrogram, whose k, l-th element is given by (52.50). Since the unmixed signals y(t) have to be independent, the following decorrelation property must be fulfilled

This principle also solves the permutation ambiguity. The source separation algorithm is then based on the minimization of a cost function given by the Frobenius norm of the amplitude-modulation correlation matrix.
A priori knowledge about the source distributions has also been used to determine the correct permutations. Based on assumptions of Laplacian distributed sources, Mitianopudis and Davies [52.134,251,276] propose a likelihood ratio test to test which permutation is most likely. A time-dependent function that imposes frequency coupling between frequency bins is also introduced. Based on the same principle, the method has been extended to more than two sources by Rahbar and Reilly [52.152]. A hierarchical sorting is used in order to avoid errors introduced at a single frequency. This approach has been adopted in Mertins and Russel [52.212].
Finally, one of the most effective convolutive BSS methods to date (Table 52.5) uses the statistical relationship of signal powers across frequencies. Rather than solving separate instantaneous source separation problems in each frequency band Lee et al. [52.277,278,280] propose a multidimensional version of the density estimation algorithms. The density function captures the power of the entire model source rather than the power at individual frequencies. As a result, the joint statistics across frequencies are effectively captured and the algorithm converges to satisfactory permutations in each frequency bin.
Other properties of speech have also been suggested in order to solve the permutation indeterminacy. A pitch-based method has been suggested by Tordini and Piazza [52.135]. Also Sanei et al. [52.147] use the property of different pitch frequency for each speaker. The pitch and formants are modeled by a coupled HMM. The model is trained based on previous time frames.
Motivated by psychoacoustics, Guddeti and Mulgrew [52.243] suggest to disregard frequency bands that are perceptually masked by other frequency bands. This simplifies the permutation problem as the number of frequency bins that have to be considered is reduced. In Barros et al. [52.244], the permutation ambiguity is avoided due to a priori information of the phase associated with the fundamental frequency of the desired speech signal.
Nonspeech signals typically also have properties which can be exploited. Two proposals for solving the permutation in the case of cyclo-stationary signals can be found in Antoni et al. [52.273]. For machine acoustics, the permutations can be solved easily since machine signals are (quasi)periodic. This can be employed to find the right component in the output vector [52.221].
Continuity of the frequency spectra has been used by Capdevielle et al. [52.62] to solve the permutation ambiguity. The idea is to consider the sliding Fourier transform with a delay of one point. The cross-correlation between different sources are zero due to the independence assumption. Hence, when the cross-correlation is maximized, the output belongs to the same source. This method has also been used by Servière [52.253]. A disadvantage of this method is that it is computationally very expensive since the frequency spectrum has to be calculated with a window shift of one. A computationally less expensive method based on this principle has been suggested by Dapena and Servière [52.274]. The permutation is determined from the solution that maximizes the correlation between only two frequencies. If the sources have been whitened as part of separation, the approach by Capdevielle et al. [52.62] does not work. Instead, Kopriva et al. [52.86] suggest that the permutation can be solved by independence tests based on kurtosis. For the same reason, Mejuto et al. [52.275] consider fourth-order cross-cumulants of the outputs at all frequencies. If the extracted sources belong to the same sources, the cross-cumulants will be nonzero. Otherwise, if the sources belong to different sources, the cross-cumulants will be zero.
Finally, Hoya et al. [52.302] use pattern recognition to identify speech pauses that are common across frequencies, and in the case of overcomplete source separation, k-means clustering has been suggested. The clusters with the smallest variance are assumed to correspond to the desired sources [52.230]. Dubnov et al. [52.279] also address the case of more sources than sensors. Clustering is used at each frequency and Kalman tracking is performed in order to link the frequencies together.
Global Permutations
In many applications only one of the source signals is desired and the other sources are only considered as interfering noise. Even though the local (frequency) permutations are solved, the global (external) permutation problem still exists. Few algorithms address the problem of selecting the desired source signal from the available outputs. In some situations, it can be assumed that the desired signal arrives from a certain direction (e.g., the speaker of interest is in front of the array). Geometric information can determine which of the signals is the target [52.171,184]. In other situations, the desired speaker is selected as the most dominant speaker. In Low et al. [52.289], the most dominant speaker is determined on a criterion based on kurtosis. The speaker with the highest kurtosis is assumed to be the dominant. In separation techniques based on clustering, the desired source is assumed to be the cluster with the smallest variance [52.230]. If the sources are moving it is necessary to maintain the global permutation by tracking each source. For block-based algorithm the global permutation might change at block boundaries. This problem can often be solved by initializing the filter with the estimated filter from the previous block [52.186].
Results
The overwhelming majority of convolutive source separation algorithms have been evaluated on simulated data. In the process, a variety of simulated room responses have been used. Unfortunately, it is not clear whether any of these results transfer to real data. The main concerns are the sensitivity to microphone noise (often not better than −25 dB), nonlinearity in the sensors, and strong reverberations with a possibly weak direct path. It is suggestive that only a small subset of research teams evaluate their algorithms on actual recordings. We have considered more than 400 references and found results on real room recordings in only 10% of the papers. Table 52.5 shows a complete list of those papers. The results are reported as signal-to-interference ratio (SIR), which is typically averaged over multiple output channels. The resulting SIR are not directly comparable as the results for a given algorithm are very likely to depend on the recording equipment, the room that was used, and the SIR in the recorded mixtures. A state-of-the art algorithm can be expected to improve the SIR by 10-20 dB for two stationary sources. Typically a few seconds of data (2-10 s) will be sufficient to generate these results. However, from this survey nothing can be said about moving sources. Note that only eight (of over 400) papers reported separation of more than two sources, indicating that this remains a challenging problem.
Conclusion
We have presented a taxonomy for blind separation of convolutive mixtures with the purpose of providing a survey and discussion of existing methods. Further, we hope that this might stimulate the development of new models and algorithms which more efficiently incorporate specific domain knowledge and useful prior information.
In the title of the BSS review by Torkkola [52.13], it was asked: Are we there yet? Since then numerous algorithms have been proposed for blind separation of convolutive mixtures. Many convolutive algorithms have shown good performance when the mixing process is stationary, but still few methods work in real-world, time-varying environments. In these challenging environments, there are too many parameters to update in the separation filters, and too little data available in order to estimate the parameters reliably, while the less complicated methods such as null beamformers may perform just as well. This may indicate that the long demixing filters are not the solution for real-world, time-varying environments such as the cocktail-party situation.
Abbreviations
- AR:
-
autoregressive
- ARMA:
-
autoregressive moving-average
- BSS:
-
blind source separation
- CASA:
-
computational auditory scene analysis
- DFT:
-
discrete Fourier transform
- FFT:
-
fast Fourier transform
- FIR:
-
finite impulse response
- HMM:
-
hidden Markov models
- HOS:
-
higher-order statistics
- HRTF:
-
head-related transfer function
- ICA:
-
independent component analysis
- IIR:
-
infinite impulse response
- MAP:
-
maximum a posteriori
- MFCC:
-
mel-filter cepstral coefficient
- ML:
-
maximum-likelihood
- MuSIC:
-
multiple signal classification
- PDF:
-
probability density function
- SOS:
-
second-order statistics
- T-F:
-
time-frequency
- TD:
-
time domain
- TITO:
-
two-input-two-output
References
A. Mansour, N. Benchekroun, C. Gervaise: Blind separation of underwater acoustic signals, ICAʼ06 (2006) pp. 181-188
S. Cruces-Alvarez, A. Cichocki, L. Castedo-Ribas: An iterative inversion approach to blind source separation, IEEE Trans. Neural Netw. 11(6), 1423-1437 (2000)
K.I. Diamantaras, T. Papadimitriou: MIMO blind deconvoluition using subspace-based filter deflation, Proc. ICASSPʼ04, Vol. IV (2004) pp. 433-436
D. Nuzillard, A. Bijaoui: Blind source separation and analysis of multispectral astronomical images, Astron. Astrophys. Suppl. Ser. 147, 129-138 (2000)
J. Anemüller, T.J. Sejnowski, S. Makeig: Complex independent component analysis of frequency-domain electroencephalographic data, Neural Netw. 16(9), 1311-1323 (2003)
M. Dyrholm, S. Makeig, L.K. Hansen: Model structure selection in convolutive mixtures, ICAʼ06 (2006) pp. 74-81
C. Vayá, J.J. Rieta, C. Sánchez, D. Moratal: Performance study of convolutive BSS algorithms applied to the electrocardiogram of atrial fibrillation, ICAʼ06 (2006) pp. 495-502
L.K. Hansen: ICA of fMRI based on a convolutive mixture model, Ninth Annual Meeting of the Organization for Human Brain Mapping (2003)
E.C. Cherry: Some experiments on the recognition of speech, with one and two ears, J. Acoust. Soc. Am. 25(5), 975-979 (1953)
S. Haykin, Z. Chen: The cocktail party problem, Neural Comput. 17, 1875-1902 (2005)
M. Miyoshi, Y. Kaneda: Inverse filtering of room acoustics, IEEE Trans. Acoust. Speech. Signal Proc. 36(2), 145-152 (1988)
K.J. Pope, R.E. Bogner: Blind signal separation II. Linear convolutive combinations, Digital Signal Process. 6, 17-28 (1996)
K. Torkkola: Blind separation for audio signals - are we there yet?, ICAʼ99 (1999) pp. 239-244
K. Torkkola: Blind separation of delayed and convolved sources. In: Unsupervised Adaptive Filtering, Blind Source Separation, Vol. 1, ed. by S. Haykin (Wiley, New York 2000) pp. 321-375, Chap. 8
R. Liu, Y. Inouye, H. Luo: A system-theoretic foundation for blind signal separation of MIMO-FIR convolutive mixtures - a review, ICAʼ00 (2000) pp. 205-210
K.E. Hild: Blind Separation of Convolutive Mixtures Using Renyiʼs Divergence. Ph.D. Thesis (University of Florida, Gainesville 2003)
A. Hyvärinen, J. Karhunen, E. Oja: Independent Component Analysis (Wiley, New York 2001)
A. Cichocki, S. Amari: Adaptive Blind Signal and Image Processing (Wiley, New York 2002)
S.C. Douglas: Blind separation of acoustic signals. In: Microphone Arrays, ed. by M.S. Brandstein, D.B. Ward (Springer, Berlin, Heidelberg 2001) pp. 355-380, Chap. 16
S.C. Douglas: Blind signal separation and blind deconvolution. In: The Neural Networks for Signal Processing Handbook, Ser. Electrical Engineering and Applied Signal Processing, ed. by Y.H. Hu, J.-N. Hwang (CRC Press, Boca Raton 2002), Chap. 7
P.D. OʼGrady, B.A. Pearlmutter, S.T. Rickard: Survey of sparse and non-sparse methods in source separation, IJIST 15, 18-33 (2005)
S. Makino, H. Sawada, R. Mukai, S. Araki: Blind source separation of convolutive mixtures of speech in frequency domain, IEICE Trans. Fundamentals E88-A(7), 1640-1655 (2005)
R. Lambert: Multichannel Blind Deconvolution: FIR Matrix Algebra and Separation of Multipath Mixtures. Ph.D. Thesis (University of Southern California Department of Electrical Engineering, Los Angeles 1996)
S. Roberts, R. Everson: Independent Components Analysis: Principles and Practice (Cambridge University Press, Cambridge 2001)
A. Gorokhov, P. Loubaton: Subspace based techniques for second order blind separation of convolutive mixtures with temporally correlated sources, IEEE Trans. Circ. Syst. 44(9), 813-820 (1997)
H.-L. Nguyen Thi, C. Jutten: Blind source separation for convolutive mixtures, Signal Process. 45(2), 209-229 (1995)
S. Choi, A. Cichocki: Adaptive blind separation of speech signals: Cocktail party problem, ICSPʼ97 (1997) pp. 617-622
S. Choi, A. Cichocki: A hybrid learning approach to blind deconvolution of linear MIMO systems, Electron. Lett. 35(17), 1429-1430 (1999)
E. Weinstein, M. Feder, A. Oppenheim: Multi-channel signal separation by decorrelation, IEEE Trans. Speech Audio Process. 1(4), 405-413 (1993)
S.T. Neely, J.B. Allen: Invertibility of a room impulse response, J. Acoust. Soc. Am. 66(1), 165-169 (1979)
Y.A. Huang, J. Benesty, J. Chen: Blind channel identification-based two-stage approach to separation and dereverberation of speech signals in a reverberant environment, IEEE Trans. Speech Audio Process. 13(5), 882-895 (2005)
Y. Huang, J. Benesty, J. Chen: Identification of acoustic MIMO systems: Challenges and opportunities, Signal Process. 86, 1278-1295 (2006)
Z. Ye, C. Chang, C. Wang, J. Zhao, F.H.Y. Chan: Blind separation of convolutive mixtures based on second order and third order statistics, Proc. ICASSPʼ03, Vol. 5 (2003) pp. V-305, -308
K. Rahbar, J.P. Reilly, J.H. Manton: Blind identification of MIMO FIR systems driven by quasistationary sources using second-order statistics: A frequency domain approach, IEEE Trans. Signal Process. 52(2), 406-417 (2004)
D. Yellin, E. Weinstein: Multichannel signal separation: Methods and analysis, IEEE Trans. Signal Process. 44(1), 106-118 (1996)
B. Chen, A.P. Petropulu: Frequency domain blind MIMO system identification based on second- and higher order statistics, IEEE Trans. Signal Process. 49(8), 1677-1688 (2001)
B. Chen, A.P. Petropulu, L.D. Lathauwer: Blind identification of complex convolutive MIMO systems with 3 sources and 2 sensors, Proc. ICASSPʼ02, Vol. II (2002) pp. 1669-1672
A. Mansour, C. Jutten, P. Loubaton: Subspace method for blind separation of sources and for a convolutive mixture model, EUSIPCO 96, Signal Processing VIII, Theories and Applications (Elsevier, Amsterdam 1996) pp. 2081-2084
W. Hachem, F. Desbouvries, P. Loubaton: On the identification of certain noisy FIR convolutive mixtures, ICAʼ99 (1999)
A. Mansour, C. Jutten, P. Loubaton: Adaptive subspace algorithm for blind separation of independent sources in convolutive mixture, IEEE Trans. Signal Process. 48(2), 583-586 (2000)
N. Delfosse, P. Loubaton: Adaptive blind separation of convolutive mixtures, Proc. ICASSPʼ96 (1996) pp. 2940-2943
N. Delfosse, P. Loubaton: Adaptive blind separation of independent sources: A second-order stable algorithm for the general case, IEEE Trans. Circ. Syst.-I: Fundamental Theory Appl. 47(7), 1056-1071 (2000)
L.K. Hansen, M. Dyrholm: A prediction matrix approach to convolutive ICA, NNSPʼ03 (2003) pp. 249-258
Y. Hua, J.K. Tugnait: Blind identifiability of FIR-MIMO systems with colored input using second order statistics, IEEE Signal Process. Lett. 7(12), 348-350 (2000)
O. Yilmaz, S. Rickard: Blind separation of speech mixtures via time-frequency masking, IEEE Trans. Signal Process. 52(7), 1830-1847 (2004)
N. Roman: Auditory-based algorithms for sound segregatoion in multisource and reverberant environments. Ph.D. Thesis (The Ohio State University, Columbus 2005)
A. Blin, S. Araki, S. Makino: Underdetermined blind separation og convolutive mixtures of speech using time-frequency mask and mixing matrix estimation, IEICE Trans. Fundamentals E88-A(7), 1693-1700 (2005)
K.I. Diamantaras, A.P. Petropulu, B. Chen: Blind Two-Input-TwoOutput FIR Channel Identification based on frequency domain second- order statistics, IEEE Trans. Signal Process. 48(2), 534-542 (2000)
E. Moulines, J.-F. Cardoso, E. Cassiat: Maximum likelihood for blind separation and deconvolution of noisy signals using mixture models, Proc. ICASSPʼ97, Vol. 5 (1997) pp. 3617-3620
U.A. Lindgren, H. Broman: Source separation using a criterion based on second-order statistics, IEEE Trans. Signal Process. 46(7), 1837-1850 (1998)
H. Broman, U. Lindgren, H. Sahlin, P. Stoica: Source separation: A TITO system identification approach, Signal Process. 73(1), 169-183 (1999)
H. Sahlin, H. Broman: MIMO signal separation for FIR channels: A criterion and performance analysis, IEEE Trans. Signal Process. 48(3), 642-649 (2000)
C. Jutten, L. Nguyen Thi, E. Dijkstra, E. Vittoz, J. Caelen: Blind separation of sources: An algorithm for separation of convolutive mixtures. In: Higher Order Statistics. Proceedings of the International Signal Processing Workshop, ed. by J. Lacoume (Elsevier, Amsterdam 1992) pp. 275-278
C. Servière: Blind source separation of convolutive mixtures, SSAPʼ96 (1996) pp. 316-319
A. Ypma, A. Leshem, R.P. Duina: Blind separation of rotating machine sources: Bilinear forms and convolutive mixtures, Neurocomputing 49(1-4), 349-368 (2002)
N. Charkani, Y. Deville, J. Herault: Stability analysis and optimization of time-domain convolutive source separation algorithms, SPAWCʼ97 (1997) pp. 73-76
N. Charkani, Y. Deville: A convolutive source separation method with self-optimizing non-linearities, Proc. ICASSPʼ99, Vol. 5 (1999) pp. 2909-2912
N. Charkani, Y. Deville: Self-adaptive separation of convolutively mixed signals with a recursive structure. Part I: Stability analysis and optimization of asymptotic behaviour, Signal Process. 73(3), 225-254 (1999)
K. Torkkola: Blind separation of convolved sources based on information maximization, NNSPʼ96 (1996) pp. 423-432
P. Comon: Independent component analysis, a new concept?, Signal Process. 36(3), 287-314 (1994), special issue on Higher-Order Statistics
P. Comon, L. Rota: Blind separation of independent sources from convolutive mixtures, IEICE Trans. Fundamentals E86-A(3), 542-549 (2003)
V. Capdevielle, C. Servière, J.L. Lacoume: Blind separation of wide-band sources in the frequency domain, ICASSPʼ95, Vol. III (Detroit 1995) pp. 2080-2083
S. Icart, R. Gautier: Blind separation of convolutive mixtures using second and fourth order moments, Proc. ICASSPʼ96, Vol. 5 (1996) pp. 3018-3021
M. Girolami, C. Fyfe: A temporal model of linear anti-hebbian learning, Neural Process. Lett. 4(3), 139-148 (1996)
J.K. Tugnait: On blind separation of convolutive mixtures of independent linear signals in unknown additive noise, IEEE Trans. Signal Process. 46(11), 3117-3123 (1998)
C. Simon, P. Loubaton, C. Vignat, C. Jutten, G. dʼUrso: Separation of a class of convolutive mixtures: A contrast function approach, Proc. ICASSPʼ99 (1999) pp. 1429-1432
Y. Su, L. He, R. Yang: An improved cumulant-based blind speech separation method, Proc. ICASSPʼ00 (2000) pp. 1867-1870
P. Baxter, J. McWhirter: Blind signal separation of convolutive mixtures, AsilomarSSC, Vol. 1 (2003) pp. 124-128
S. Hornillo-Mellado, C.G. Puntonet, R. Martin-Clemente, M. Rodríguez-Álvarez: Characterization of the sources in convolutive mixtures: A cumulant-based approach, ICAʼ04 (2004) pp. 586-593
Y. Deville, M. Benali, F. Abrard: Differential source separation for underdetermined instantaneous or convolutive mixtures: Concept and algorithms, Signal Process. 84(10), 1759-1776 (2004)
M. Ito, M. Kawamoto, N. Ohnishi, Y. Inouye: Eigenvector algorithms with reference signals for frequency domain BSS, ICAʼ06 (2006) pp. 123-131
W. Baumann, D. Kolossa, R. Orglmeister: Beamforming-based convolutive source separation, Proc. ICASSPʼ03, Vol. V (2003) pp. 357-360
W. Baumann, D. Kolossa, R. Orglmeister: Maximum likelihood permutation correction for convolutive source separation, ICAʼ03 (2003) pp. 373-378
M.S. Pedersen, C.M. Nielsen: Gradient flow convolutive blind source separation, MLSPʼ04 (2004) pp. 335-344
J.-F. Cardoso, A. Souloumiac: Blind beamforming for non Gaussian signals, IEEE Proc. 140(6), 362-370 (1993)
D. Yellin, E. Weinstein: Criteria for multichannel signal separation, IEEE Trans. Signal Process. 42(8), 2158-2168 (1994)
D. Kolossa, R. Orglmeister: Nonlinear postprocessing for blind speech separation, ICAʼ04 (2004) pp. 832-839
P. Comon, E. Moreau, L. Rota: Blind separation of convolutive mixtures: A contrast-based joint diagonalization approach, ICAʼ01 (2001) pp. 686-691
E. Moreau, J. Pesquet: Generalized contrasts for multichannel blind deconvolution of linear systems, IEEE Signal Process. Lett. 4(6), 182-183 (1997)
Y. Li, J. Wang, A. Cichocki: Blind source extraction from convolutive mixtures in ill-conditioned multi-input multi-output channels, IEEE Trans. Circ. Syst. I: Regular Papers 51(9), 1814-1822 (2004)
R.K. Prasad, H. Saruwatari, K. Shikano: Problems in blind separation of convolutive speech mixtures by negentropy maximization, IWAENCʼ03 (2003) pp. 287-290
X. Sun, S. Douglas: Adaptive paraunitary filter banks for contrast-based multichannel blind deconvolution, Proc. ICASSPʼ01, Vol. 5 (2001) pp. 2753-2756
J. Thomas, Y. Deville, S. Hosseini: Time-domain fast fixed-point algorithms for convolutive ICA, IEEE Signal Process. Lett. 13(4), 228-231 (2006)
C. Jutten, J. Herault: Blind separation of sources, part I: An adaptive algorithm based on neuromimetic architecture, Signal Process. 24(1), 1-10 (1991)
A.D. Back, A.C. Tsoi: Blind deconvolution of signals using a complex recurrent network, NNSPʼ94 (1994) pp. 565-574
I. Kopriva, Ž. Devčić, H. Szu: An adaptive short-time frequency domain algorithm for blind separation of nonstationary convolved mixtures, IJCNNʼ01 (2001) pp. 424-429
S. Cruces, L. Castedo: A Gauss-Newton method for blind source separation of convolutive mixtures, Proc. ICASSPʼ98, Vol. IV (1998) pp. 2093-2096
S.V. Gerven, D.V. Compernolle: Signal separation by symmetric adaptive decorrelation: Stability, convergence, and uniqueness, IEEE Trans. Signal Process. 43(7), 1602-1612 (1995)
S. Li, T.J. Sejnowski: Adaptive separation of mixed broadband sound sources with delays by a beamforming Herault-Jutten network, IEEE J. Ocean. Eng. 20(1), 73-79 (1995)
N. Charkani, Y. Deville: Optimization of the asymptpotic preformance of time-domain convolutive source separation algorithms, ESANNʼ97 (1997) pp. 273-278
N. Charkani, Y. Deville: Self-adaptive separation of convolutively mixed signals with a recursive structure. Part II: Theoretical extensions and application to synthetic and real signals, Signal Process. 75(2), 117-140 (1999)
S. Choi, H. Hong, H. Glotin, F. Berthommier: Multichannel signal separation for cocktail party speech recognition: A dynamic recurrent network, Neurocomputing 49(1-4), 299-314 (2002)
F. Berthommier, S. Choi: Several improvements of the Hérault-Jutten model for speech segregation, ICAʼ03 (2003) pp. 1089-1094
M. Cohen, G. Cauwenbergh: Blind separation of linear convolutive mixtures through parallel stochastic optimization, ISCASʼ98, Vol. 3 (1998) pp. 17-20
M. Stanacevic, M. Cohen, G. Cauwenberghs: Blind separation of linear convolutive mixtures using orthogonal filter banks, ICAʼ01 (2001) pp. 260-265
G. Deco, D. Obradovic: An Information-Theoretic Approach to Neural Computing (Springer, New York 1996)
A.J. Bell, T.J. Sejnowski: An information-maximization approach to blind separation and blind deconvolution, Neural Comput. 7(6), 1129-1159 (1995)
S. Amari, S. Douglas, A. Cichocki, H.H. Yang: Multichannel blind deconvolution and equalization using the natural gradient, IEEE International Workshop on Wireless Communication (1997) pp. 101-104
B.A. Pearlmutter, L.C. Parra: Maximum likelihood blind source separation: A context-sensitive generalization of ICA, NIPSʼ97 (1997) pp. 613-619
J.-F. Cardoso: Blind signal separation: Statistical principles, Proc. IEEE 9(10), 2009-2025 (1998)
K. Kokkanikis, A.K. Nandi: Optimal blind separation of convolutive audio mixtures without temporal constraints, Proc. ICASSPʼ04, Vol. I (2004) pp. 217-220
K. Kokkinakis, A.K. Nandi: Multichannel speech separation using adaptive parameterization of source pdfs, ICAʼ04 (2004) pp. 486-493
H.-C. Wu, J.C. Principe: Generalized anti-hebbian learning for source separation, Proc. ICASSPʼ99, Vol. 2 (1999) pp. 1073-1076
J. Xi, J.P. Reilly: Blind separation and restoration of signals mixed in convolutive environment, Proc. ICASSPʼ97 (1997) pp. 1327-1330
J.P. Reilly, L.C. Mendoza: Blind signal separation for convolutive mixing environments using spatial-temporal processing, Proc. ICASSPʼ99 (1999) pp. 1437-1440
H. Sawada, R. Mukai, S. Araki, S. Makino: A robust and precise method for solving the permutation problem of frequency-domain blind source separation, IEEE Trans. Speech Audio Process. 12(5), 530-538 (2004)
H. Sawada, R. Mukai, S. Araki, S. Makino: Polar coordinate based nonlinear function for frequency domain blind source separation, Proc. ICASSPʼ02 (2002) pp. 1001-1004
J.-F. Cardoso, T. Adali: The maximum likelihood approach to complex ICA, Proc. ICASSP, Vol. V (2006) pp. 673-676
M. Novey, T. Adali: Adaptable nonlinearity for complex maximization of nongaussianity and a fixed-point algorithm, MLSP (2006)
M. Joho, H. Mathis, G.S. Moschytz: An FFT-based algorithm for multichannel blind deconvolution, ISCASʼ99, Vol. 3 (1999) pp. 203-206
R.H. Lambert, A.J. Bell: Blind separation of multiple speakers in a multipath environment, Proc. ICASSPʼ97, Vol. 1 (1997) pp. 423-426
R.H. Lambert: A new method for source separation, Proc. ICASSPʼ95, Vol. 3 (1995) pp. 2116-2119
T.-W. Lee, A.J. Bell, R. Orglmeister: Blind source separation of real world signals, ICNNʼ97 (1997) pp. 2129-2135
S. Choi, S. Amari, A. Cichocki, R. Liu: Natural gradient learning with a nonholonomic constraint for blind deconvolution of multiple channels, ICAʼ99 (1999) pp. 371-376
S.C. Douglas, X. Sun: Convolutive blind separation of speech mixtures using the natural gradient, Speech Commun. 39, 65-78 (2003)
K. Matsuoka, Y. Ohba, Y. Toyota, S. Nakashima: Blind separation for convolutive mixture of many voices, IWAENCʼ03 (2003) pp. 279-282
K. Matsuoka, S. Nakashima: Minimal distortion principle for blind source separation, ICAʼ01 (2001) pp. 722-727
W. Wang, M.G. Jafari, S. Sanei, J.A. Chambers: Blind separartion of convolutive mixtures of cyclostationary signals, Int. J. Adapt. Contr. Signal Process. 18, 279-298 (2004)
G.-J. Jang, C. Choi, Y. Lee, Y.-H. Oh: Adaptive cross-channel interference cancellation on blind signal separation outputs using source absence/presence detection and spectral subtraction, ICLSPʼ04, Vol. IV (2004) pp. 2865-2868
S.H. Nam, S. Beack: A frequency-domain normalized multichannel blind deconvolution algorithm for acoustical signals, ICAʼ04 (2004) pp. 524-531
M. Joho, P. Schniter: Frequency domain realization of a multichannel blind deconvolution algorithm based on the natural gradient, ICAʼ03 (2003) pp. 543-548
C. Choi, G. Jang, Y. Lee, S.R. Kim: Adaptive cross-channel interference cancellation on blind source separation outputs, ICAʼ04 (2004) pp. 857-864
L. Parra, C. Spence, B. de Vries: Convolutive source separation and signal modeling with ML, ISISʼ97 (1997)
L.C. Parra: Temporal models in blind source separation, Lect. Notes Comput. Sci. 1387, 229-247 (1998)
K. Yamamoto, F. Asano, W. van Rooijen, E. Ling, T. Yamada, N. Kitawaki: Estimation of the number of sound sources using support vector machines and its application to sound source separation, Proc. ICASSPʼ03, Vol. 5 (2003) pp. 485-488
J. Anemüller: Across-frequency processing in convolutive blind source separation. Ph.D. Thesis (Univ. Oldenburg, Oldenburg 2001)
J. Anemüller, T. Gramms: On-line blind separation of moving sound sources, ICAʼ99 (1999) pp. 331-334
S. Deligne, R. Gopinath: An EM algorithm for convolutive independent component analysis, Neurocomputing 49, 187-211 (2002)
J. Rosca, C. Borss, R. Balan: Generalized sparse signal mixing model and application to noisy blind source separation, Proc. ICASSPʼ04, Vol. III (2004) pp. 877-880
S.C. Douglas, H. Sawada, S. Makino: Natural gradient multichannel blind deconvolution and speech separation using causal FIR filters, IEEE Trans. Speech Audio Process. 13(1), 92-104 (2005)
S. Araki, R. Mukai, S. Makino, T. Nishikawa, H. Saruwatari: The fundamental limitation of frequency domain blind source separation for convolutive mixtures of speech, IEEE Trans. Speech Audio Process. 11(2), 109-116 (2003)
S. Ukai, T. Takatani, T. Nishikawa, H. Saruwatari: Blind source separation combining SIMO-model-based ICA and adaptive beamforming, Proc. ICASSPʼ05, Vol. III (2005) pp. 85-88
R.H. Lambert, C.L. Nikias: Polynomial matrix whitening and application to the multichannel blind deconvolution problem, MILCOMʼ95, Vol. 3 (1995) pp. 988-992
N. Mitianoudis, M. Davies: Audio source separation of convolutive mixtures, IEEE Trans. Speech Audio Process. 11(5), 489-497 (2002)
F. Tordini, F. Piazza: A semi-blind approach to the separation of real world speech mixtures, IJCNNʼ02, Vol. 2 (2002) pp. 1293-1298
H. Attias: Source separation with a sensor array using graphical models and subband filtering, NIPSʼ02, Vol. 15 (2002) pp. 1229-1236
M.A. Gandhi, M.A. Hasegawa-Johnson: Source separation using particle filters, ICLSPʼ04, Vol. III (2004) pp. 2449-2452
R.K. Olsson, L.K. Hansen: A harmonic excitation state-space approach to blind separation of speech, NIPS (2004)
R.K. Olsson, L.K. Hansen: Probabilistic blind deconvolution of non-stationary sources, EUSIPCOʼ04 (2004) pp. 1697-1700
S. Winter, H. Sawada, S. Araki, S. Makino: Hierarchical clustering applied to overcomplete BSS for convolutive mixtures, SAPAʼ04 (2004)
S. Winter, H. Sawada, S. Araki, S. Makino: Overcomplete BSS for convolutive mixtures based on hierarchical clustering, ICAʼ04 (2004) pp. 652-660
H. Attias: New EM algorithms for source separation and deconvolution, Proc. ICASSPʼ03, Vol. V (2003) pp. 297-300
C. Andrieu, S. Godsill: A particle filter for model based audio source separation, ICAʼ00 (2000) pp. 381-386
J.R. Hopgood: Bayesian blind MIMO deconvolution of nonstationary subband autoregressive sources mixed through subband all-pole channels, SSPʼ03 (2003) pp. 422-425
S.J. Godsill, C. Andrieu: Bayesian separation and recovery of convolutively mixed autoregressive sources, Proc. ICASSPʼ99, Vol. III (1999) pp. 1733-1736
K. Abed-Meraim, W. Qiu, Y. Hua: Blind system identification, Proc. IEEE 85(8), 1310-1322 (1997)
S. Sanei, W. Wang, J.A. Chambers: A coupled HMM for solving the permutation problem in frequency domain BSS, Proc. ICASSPʼ04, Vol. V (2004) pp. 565-568
W. Wang, D. Cosker, Y. Hicks, S. Sanei, J. Chambers: Video assisted speech source seperation, Proc. ICASSPʼ05, Vol. V (2005) pp. 425-428
L. Parra, C. Spence: Convolutive blind separation of non-stationary sources, IEEE Trans. Speech Audio Process. 8(3), 320-327 (2000)
D.W.E. Schobben, P.C.W. Sommen: On the indeterminacies of convolutive blind signal separation based on second-order statistics, ISSPAʼ99 (1999) pp. 215-218
J. Liang, Z. Ding: Blind MIMO system identification based on cumulant subspace decomposition, IEEE Trans. Signal Process. 51(6), 1457-1468 (2003)
K. Rahbar, J.P. Reilly: A frequency domain method for blind source separation of convolutive audio mixtures, IEEE Trans. Speech Audio Process. 13(5), 832-844 (2005)
M. Kawamoto, K. Matsuoka, N. Ohnishi: A method of blind separation for convolved non-stationary signals, Neurocomputing 22(1-3), 157-171 (1998)
A. Belouchrani, K. Abed-Meraim, J.-F. Cardoso, E. Moulines: A blind source separation technique using second-order statistics, IEEE Trans. Signal Process. 45(2), 434-444 (1997)
A.G. Lindgren, T.P. von Hoff, A.N. Kaelin: Stability and performance of adaptive algorithms for multichannel blind source separation and deconvolution, EUSIPCOʼ00, Vol. 2 (2000) pp. 861-864
H. Sahlin, H. Broman: Separation of real-world signals, Signal Process. 64, 103-113 (1998)
D.C.B. Chan, P.J.W. Rayner, S.J. Godsill: Multi-channel blind signal separation, Proc. ICASSPʼ96 (1996) pp. 649-652
C. Simon, C. Vignat, P. Loubaton, C. Jutten, G. dʼUrso: On the convolutive mixture - source separation by the decorrelation approach, Proc. ICASSPʼ98, Vol. 4 (1998) pp. 2109-2112
N. Murata, S. Ikeda, A. Ziehe: An Approach to Blind Source Separation Based on Temporal Structure of Speech Signals (RIKEN Brain Science Institute, Japan 1998), BSIS Technical Reports 98-2
B. Yin, P. Sommen: Adaptive blind signal separation using a new simplified mixing model, ProRISCʼ99, ed. by J. Veen (1999) pp. 601-606
H.-C. Wu, J.C. Principe: Simultaneous diagonalization in the frequency domain (SDIF) for source separation, ICAʼ99 (1999) pp. 245-250
A. Souloumiac: Blind source detection and separation using second order non-stationarity, Proc. ICASSPʼ95, Vol. III (1995) pp. 1912-1915
K. Matsuoka, M. Ohya, M. Kawamoto: A neural net for blind separation of nonstationary signals, Neural Netw. 8(3), 411-419 (1995)
M. Kawamoto, A.K. Barros, A. Mansour, K. Matsuoka, N. Ohnishi: Blind separation for convolutive mixtures of non-stationary signals, Int. Conf. Neural Inf. Process. (1998) pp. 743-746
M. Kawamoto, A.K. Barros, K. Matsuoka, N. Ohnishi: A method of real-world blind separation implemented in frequency domain, ICAʼ00 (2000) pp. 267-272
M. Ito, M. Maruyoshi, M. Kawamoto, T. Mukai, N. Ohneshi: Effectiveness of directional microphones and utilization of source arriving directions in source separation, ICONIPʼ02 (2002) pp. 523-526
M. Ito, Y. Takeuchi, T. Matsumoto, H. Kudo, M. Kawamoto, T. Mukai, N. Ohnishi: Moving-source separation using directional microphones, ISSPITʼ02 (2002) pp. 523-526
Y. Katayama, M. Ito, Y. Takeuchi, T. Matsumoto, H. Kudo, N. Ohnishi, T. Mukai: Reduction of source separation time by placing microphones close together, ISSPITʼ02 (2002) pp. 540-544
R. Aichner, S. Araki, S. Makino, T. Nishikawa, H. Saruwatari: Time domain blind source separation of non-stationary convolved signals by utilizing geometric beamforming, NNSPʼ02 (2002) pp. 445-454
R. Aichner, H. Buchner, S. Araki, S. Makino: On-line time-domain blind source separation of nonstationary convolved signals, ICAʼ03 (2003) pp. 987-992
H. Buchner, R. Aichner, W. Kellermann: A generalization of blind source separation algorithms for convolutive mixtures based on second-order statistics, IEEE Trans. Speech Audio Process. 13(1), 120-134 (2005)
E. Visser, T.-W. Lee: Speech enhancement using blind source separation and two-channel energy based speaker detection, Proc. ICASSPʼ03, Vol. 1 (2003) pp. 884-887
E. Visser, K. Chan, S. Kim, T.-W. Lee: A comparison of simultaneous 3-channel blind source separation to selective separation on channel pairs using 2-channel BSS, ICLSPʼ04, Vol. IV (2004) pp. 2869-2872
M.Z. Ikram, D.R. Morgan: A multiresolution approach to blind separation of speech signals in a reverberant environment, Proc. ICASSPʼ01, Vol. V (2001)
M. Ikram, D. Morgan: A beamforming approach to permutation alignment for multichannel frequency-domain blind speech separation, Proc. ICASSPʼ02 (2002) pp. 881-884
M.Z. Ikram, D.R. Morgan: Permutation inconsistency in blind speech separation: Investigation and solutions, IEEE Trans. Speech Audio Process. 13(1), 1-13 (2005)
L. Parra, C. Spence: On-line convolutive source separation of non-stationary signals, IEEE J. VLSI Signal Process. 26(1,2), 39-46 (2000)
M. Joho: Blind signal separation of convolutive mixtures: A time-domain joint-diagonalization approach, ICAʼ04 (2004) pp. 578-585
M. Joho: Convolutive blind signal separation in acoustics by joint approximate diagonalization of spatiotemporal correlation matrices, Asilomar SSC (2004)
S. Araki, S. Makino, R. Mukai, H. Saruwatari: Equivalence between frequency domain blind source separation and frequency domain adaptive beamformers, CRACʼ01 (2001)
C.L. Fancourt, L. Parra: The coherence function in blind source separation of convolutive mixtures of non-stationary signals, NNSP (2001) pp. 303-312
C.L. Fancourt, L. Parra: The generalized sidelobe decorrelator, WASPAAʼ01 (2001)
C. Fancourt, L. Parra: A comparison of decorrelation criteria for the blind source separation of non-stationary signals, SAMʼ02 (2002)
L. Parra, C. Alvino: Geometric source separation: Merging convolutive source separation with geometric beamforming, IEEE Trans. Speech Audio Process. 10(6), 352-362 (2002)
L. Parra, C. Fancourt: An Adaptive Beamforming Perspective on Convolutive Blind Source Separation. In: Noise Reduction in Speech Applications, ed. by G. Davis (CRC, Boca Raton 2002)
E. Visser, T.-W. Lee: Blind source sepoaration in mobile environments usinbg a priori knowledge, Proc. ICASSPʼ04, Vol. III (2004) pp. 893-896
M.S. Pedersen, L.K. Hansen, U. Kjems, K.B. Rasmussen: Semi-blind source separation using head-related transfere functions, Proc. ICASSPʼ04, Vol. V (2004) pp. 713-716
S. Ding, T. Hikichi, T. Niitsuma, M. Hamatsu, K. Sugai: Recursive method for blind source separation and its applications to real-time separations of acoustic signals, ICAʼ03 (2003) pp. 517-522
E. Robledo-Arnuncio, B.F. Juang: Issues in frequency domain blind source separation - a critical revisit, Proc. ICASSPʼ05, Vol. V (2005) pp. 281-284
W. Wang, J.A. Chambers, S. Sanei: A joint diagonalization method for convolutive blind separation of nonstationary sources in the frequency domain, ICAʼ03 (2003) pp. 939-944
W. Wang, J.A. Chambers, S. Sanei: A novel hybrid approach to the permutation problem of frequency domain blind source separation, ICAʼ04 (2004) pp. 532-539
W. Wang, S. Sanei, J.A. Chambers: Penalty function-based joint diagonalization approach for convolutive blind separation of nonstationary sources, IEEE Trans. Signal Process. 53(5), 1654-1669 (2005)
L. Molgedey, H. Schuster: Separation of independent signals using time-delayed correlations, Phys. Rev. Lett. 72(23), 3634-3637 (1994)
T.J. Ngo, N. Bhadkamkar: Adaptive blind separation of audio sources by a physically compact device using second order statistics, ICAʼ99 (1999) pp. 257-260
D.W. Schobben, P.C.W. Sommen: A frequency domain blind signal separation method based on decorrelation, IEEE Trans. Signal Process. 8(50), 1855-1865 (2002)
S. Ikeda, N. Murata: An approach to blind source separation of speech signals, ICANNʼ98, Vol. 2 (1998) pp. 761-766
S. Ikeda, N. Murata: A method of blind separation on temporal structre of signals, ICONIPʼ98, Vol. 2 (1998) pp. 737-742
S. Ikeda, N. Murata: A method of ICA in time-frequency domain, ICAʼ99 (1999) pp. 365-371
N. Murata, S. Ikeda, A. Ziehe: An approach to blind source separation based on temporal structure of speech signals, Neurocomputing 41(1-4), 1-24 (2001)
A. Ahmed, P.J.W. Rayner, S.J. Godsill: Considering non-stationarity for blind signal separation, WASPAAʼ99 (1999) pp. 111-114
B. Yin, P. Sommen: A new convolutive blind signal separation algorithm based on second order statistics using a simplified mixing model, EUSIPCOʼ00, Vol. 4 (2000) pp. 2049-2053
D.-T. Pham, C. Servière, H. Boumaraf: Blind separation of convolutive audio mixtures using nonstationarity, ICAʼ03 (2003) pp. 981-986
C. Servière, D. Pham: A novel method for permutation correction in frequency-domain in blind separation of speech mixtures, ICAʼ04 (2004) pp. 807-815
H. Buchner, R. Aichner, W. Kellermann: Blind source separation for convolutive mixtures exploiting nongaussianity, nonwhiteness, and nonstationarity, IWAENCʼ03 (2003) pp. 275-278
R. Aichner, H. Buchner, F. Yan, W. Kellermann: Real-time convolutive blind source separation based on a broadband approach, ICAʼ04 (2004) pp. 840-848
H. Buchner, R. Aichner, W. Kellermann: Trinicon: A versatile framework for multichannel blind signal processing, Proc. ICASSPʼ04, Vol. III (2004) pp. 889-892
R. Aichner, H. Buchner, W. Kellermann: On the causality problem in time-domain blind source separation and deconvolution algorithms, Proc. ICASSPʼ05, Vol. V (2005) pp. 181-184
B.S. Krongold, D.L. Jones: Blind source separation of nonstationary convolutively mixed signals, SSAPʼ00 (2000) pp. 53-57
K. Rahbar, J.P. Reilly: Blind source separation algorithm for MIMO convolutive mixtures, ICAʼ01 (2001)
A. Holobar, D. Zazula: A novel approach to convolutive blind separation of close-to-orthogonal pulse sources using second-order statistics, EUSIPCOʼ04 (2004) pp. 381-384
K.-C. Yen, Y. Zhao: Adaptive co-channel speech separation and recognition, IEEE Trans Speech Audio Process. 7(2), 138-151 (1999)
A. Mertins, I. Russel: An extended ACDC algorithm for the blind estimation of convolutive mixing systems, ISSPAʼ03, Vol. 2 (2003) pp. 527-530
Y. Zhao, R. Hu: Fast convergence speech source separation in reverberant acoustic environment, Proc. ICASSPʼ04, Vol. III (2004) pp. 897-900
I. Russell, J. Xi, A. Mertins, J. Chicharo: Blind source separation of nonstationary convolutively mixed signals in the subband domain, Proc. ICASSPʼ04, Vol. V (2004) pp. 484-484
A. Leon-Garcia: Probability, Random Processes for Electrical Engineering, 2nd edn. (Addison Wesley, Reading 1994)
S. Shamsunder, G.B. Giannakis: Multichannel blind signal separation and reconstruction, IEEE Trans. Speech, Audio Process. 5(6), 515-528 (1997)
L. Deneire, D.T. Slock: A Schur method for multiuser multichannel blind identification, Proc. ICASSPʼ99 (1999) pp. 2905-2908
C.T. Ma, Z. Ding, S.F. Yau: A two-stage algorithm for MIMO blind deconvolution of nonstationary colored signals, IEEE Trans. Signal Process. 48(4), 1187-1192 (2000)
I. Bradaric, A.P. Petropulu, K.I. Diamantaras: On blind identifiability of FIR-MIMO systems with cyclostationary inputs using second order statistics, Proc. ICASSPʼ02, Vol. II (2002) pp. 1745-1748
I. Bradaric, A.P. Petropulu, K.I. Diamantaras: On blind identifiability of FIR-MIMO systems with cyclostationary inputs using second order statistics, IEEE Trans. Signal Process. 51(2), 434-441 (2003)
M. Knaak, M. Kunter, D. Filbert: Blind source separation for acoustical machine diagnosis, DSPʼ02 (2002)
M. Knaak, S. Araki, S. Makino: Geometrically constrained ICA for robust separation of sound mixtures, ICAʼ03 (2003) pp. 951-956
T. Mei, F. Yin: Blind separation of convolutive mixtures by decorrelation, Signal Process. 84(12), 2297 (2004)
S. Rickard, O. Yilmaz: On the approximate W-disjoint orthogonality of speech, Proc. ICASSPʼ02, Vol. I (2002) pp. 529-532
S. Rickard, T. Melia, C. Fearon: DESPRIT - histogram based blind source separation of more sources than sensors using subspace methods, WASPAAʼ05 (2005) pp. 5-8
A. Jourjine, S. Rickard, O. Yilmaz: Blind separation of disjoint orthogonal signals: Demixing N sources from 2 mixtures, Proc. ICASSPʼ00, Vol. V (2000) pp. 2985-2988
S. Araki, S. Makino, H. Sawada, R. Mukai: Reducing musical noise by a fine-shift overlap-add method applied to source separation using a time-frequency mask, Proc. ICASSPʼ05, Vol. III (2005) pp. 81-84
M.S. Pedersen, D. Wang, J. Larsen, U. Kjems: Overcomplete blind source separation by combining ICA and binary time-frequency masking, MLSPʼ05 (2005)
M.S. Pedersen, D.L. Wang, J. Larsen, U. Kjems: Separating underdetermined convolutive speech mixtures, ICAʼ06 (2006) pp. 674-681
H. Sawada, S. Araki, R. Mukai, S. Makino: Blind extraction of a dominant source signal from mixtures of many sources, Proc. ICASSPʼ05, Vol. III (2005) pp. 61-64
H.-C. Wu, J.C. Principe, D. Xu: Exploring the time-frequency microstructure of speech for blind source separation, Proc. ICASSPʼ98, Vol. 2 (1998) pp. 1145-1148
J.M. Peterson, S. Kadambe: A probabilistic approach for blind source separation of underdetermined convolutive mixtures, Proc. ICASSPʼ03, Vol. 6 (2003) pp. 581-584
D. Luengo, I. Santamaria, L. Vielva, C. Pantaleon: Underdetermined blind separation of sparse sources with instantaneous and convolutive mixtures, NNSPʼ03 (2003) pp. 279-288
S.A. Abdallah, M.D. Plumbley: Application of geometric dependency analysis to the seperation of convolved mixtures, ICAʼ04 (2004) pp. 540-547
M. Babaie-Zadeh, A. Mansour, C. Jutten, F. Marvasti: A geometric approach for separating several speech signals, ICAʼ04 (2004) pp. 798-806
Y. Li, A. Cichocki, L. Zhang: Blind source estimation of FIR channels for binary sources: A grouping decision approach, Signal Process. 84(12), 2245-2263 (2004)
B.A. Pearlmutter, A.M. Zador: Monaural source separation using spectral cues, ICAʼ04 (2004) pp. 478-485
P. Smaragdis: Non negative matrix factor deconvolution, extraction of multiple sound sources from monophonic inputs, ICAʼ04 (2004) pp. 494-499
T. Virtanen: Separation of sound sources by convolutive sparse coding, SAPAʼ04 (2004)
M.S. Pedersen, T. Lehn-Schiøler, J. Larsen: BLUES from music: BLind Underdetermined Extraction of Sources from Music, ICAʼ06 (2006) pp. 392-399
A.S. Bregman: Auditory Scene Analysis, 2nd edn. (MIT Press, Cambridge 1990)
M. Weintraub: The GRASP sound separation system, Proc. ICASSPʼ84 (1984) pp. 69-72
R.R. Guddeti, B. Mulgrew: Perceptually motivated blind source separation of convolutive mixtures, Proc. ICASSPʼ05, Vol. V (2005) pp. 273-276
A.K. Barros, T. Rutkowski, F. Itakura, N. Ohnishi: Estimation of speech embedded in a reverberant and noisy environment by independent component analysis and wavelets, IEEE Trans. Neural Netw. 13(4), 888-893 (2002)
M. Furukawa, Y. Hioka, T. Ema, N. Hamada: Introducing new mechanism in the learning process of FDICA-based speech separation, IWAENCʼ03 (2003) pp. 291-294
R.D. Patterson: The sound of a sinusoid: Spectral models, J. Acoust Soc. Am. 96, 1409-1418 (1994)
T. Rutkowski, A. Cichocki, A.K. Barros: Speech enhancement from interfering sounds using CASA techniques and blind source separation, ICAʼ01 (2001) pp. 728-733
N. Roman, D. Wang, G.J. Brown: Speech segregation based on sound localization, J. Acoust. Soc. Am. 114(4), 2236-2252 (2003)
T. Nishikawa, H. Saruwatari, K. Shikano: Blind source separation of acoustic signals based on multistage ICA combining frequency-domain ICA and time-domain ICA, IEICE Trans. Fundamentals E86-A(4), 846-858 (2003)
P. Smaragdis: Efficient blind separation of convolved sound mixtures, WASPAAʼ97 (1997)
M. Davies: Audio source separation. In: Mathematics in Signal Processing V, ed. by J.G. McWhirter, I.K. Proudler (Oxford Univ. Press, Oxford 2001)
F. Duplessis-Beaulieu, B. Champagne: Fast convolutive blind speech separation via subband adaptation, Proc. ICASSPʼ03, Vol. 5 (2003) pp. 513-516
C. Servière: Separation of speech signals under reverberant conditions, EUSIPCOʼ04 (2004) pp. 1693-1696
T.-W. Lee, A.J. Bell, R.H. Lambert: Blind separation of delayed and convolved sources, NIPS, Vol. 9 (1997) pp. 758-764
T.-W. Lee, A. Ziehe, R. Orglmeister, T.J. Sejnowski: Combining time-delayed decorrelation and ICA: towards solving the cocktail party problem, Proc. ICASSPʼ98, Vol. 2 (1998) pp. 1249-1252
A. Westner, V.M. Bove Jr.: Blind separation of real world audio signals using overdetermined mixtures, ICAʼ99 (1999)
K. Kokkinakis, A.K. Nandi: Multichannel blind deconvolution for source separation in convolutive mixtures of speech, IEEE Trans. Audio Speech Lang. Process. 14(1), 200-212 (2006)
H. Sawada, R. Mukai, S. de la Kethulle, S. Araki, S. Makino: Spectral smoothing for frequency-domain blind source separation, IWAENCʼ03 (2003) pp. 311-314
H. Sawada, R. Mukai, S. Araki, S. Makino: Convolutive blind source separation for more than two sources in the frequency domain, Proc. ICASSPʼ04, Vol. III (2004) pp. 885-888
D.W.E. Schobben, P.C.W. Sommen: A new blind signal separation algorithm based on second-order statistics, IASTED SIPʼ06 (1998) pp. 564-569
H. Attias, J.C. Platt, A. Acero, L. Deng: Speech denoising and dereverberation using probabilistic models, NIPSʼ01, Vol. 13 (2001)
R. Aichner, H. Buchner, W. Kellermann: A novel normalization and regularization scheme for broadband convolutive blind source separation, ICAʼ06 (2006) pp. 527-535
H. Sawada, S. Araki, R. Mukai, S. Makino: Blind source separation with different sensor spacing and filter length for each frequency range, NNSPʼ02 (2002) pp. 465-474
P. Smaragdis: Blind separation of convolved mixtures in the frequency domain, Neurocomputing 22(1-3), 21-34 (1998)
V.C. Soon, L. Tong, Y.F. Huang, R. Liu: A wideband blind identification approach to speech acquisition using a microphone array, Proc. ICASSPʼ92, Vol. 1 (1992) pp. 293-296
S. Kurita, H. Saruwatari, S. Kajita, K. Takeda, F. Itakura: Evaluation of frequency-domain blind signal separation using directivity pattern under reverberant conditions, Proc. ICASSPʼ00 (2000) pp. 3140-3143
F. Asano, S. Ikeda, M. Ogawa, H. Asoh, N. Kitawaki: Combined approach of array processing and independent component analysis for blind separation of acoustic signals, IEEE Trans. Speech Audio Process. 11(3), 204-215 (2003)
N. Mitianoudis, M.E. Davies: Permutation alignment for frequency domain ICA using subspace beamforming methods, ICAʼ04 (2004) pp. 669-676
W. Baumann, B.-U. Köhler, D. Kolossa, R. Orglmeister: Real time separation of convolutive mixtures, ICAʼ01 (2001) pp. 65-69
H. Gotanda, K. Nobu, T. Koya, K. Kaneda, T. Ishibashi, N. Haratani: Permutation correction and speech extraction based on split spectrum through fastICA, ICAʼ03 (2003) pp. 379-384
S. Araki, S. Makino, R. Aichner, T. Nishikawa, H. Saruwatari: Subband based blind source separation with appropriate processing for each frequency band, ICAʼ03 (2003) pp. 499-504
J. Anemüller, B. Kollmeier: Amplitude modulation decorrelation for convolutive blind sourc separation, ICAʼ00 (2000) pp. 215-220
J. Antoni, F. Guillet, M. El Badaoui, F. Bonnardot: Blind separation of convolved cyclostationary processes, Signal Process. 85(1), 51-66 (2005)
A. Dapena, C. Serviere: A simplified frequency-domain approach for blind separation of convolutive mixtures, ICAʼ01 (2001) pp. 569-574
C. Mejuto, A. Dapena, L. Castedo: Frequency-domain infomax for blind separation of convolutive mixtures, ICAʼ00 (2000) pp. 315-320
N. Mitianoudis, M. Davies: New fixed-point ICA algorithms for convolved mixtures, ICAʼ01 (2001) pp. 633-638
I. Lee, T. Kim, T.-W. Lee: Complex fastiva: A robust maximum likelihood approach of mica for convolutive bss, ICAʼ06 (2006) pp. 625-632
T. Kim, H. Attias, S.-Y. Lee, T.-W. Lee: Blind source separation exploiting higher-order frequency dependencies, IEEE Trans. Audio Speech Lang. Process. 15(1), 70-79 (2006)
S. Dubnov, J. Tabrikain, M. Arnon-Targan: A method for directionally-disjoint source separation in convolutive environment, Proc. ICASSPʼ04, Vol. V (2004) pp. 489-492
A. Hiroe: Solution of permutation problem in frequency domain ica, using multivariate probability density functions, ICAʼ06 (2006) pp. 601-608
D. Kolossa, B.-U. Köhler, M. Conrath, R. Orgelmeister: Optimal permutation correlation by multiobjective genetic algorithms, ICAʼ01 (2001) pp. 373-378
K. Kamata, X. Hu, H. Kobataka: A new approach to the permutation problem in frequency domain blind source separation, ICAʼ04 (2004) pp. 849-856
H. Attias, C.E. Schreiner: Blind source separation and deconvolution: The dynamic component analysis algorithm, Neural Comput. 11, 803-852 (1998)
F. Asano, S. Ikeda, M. Ogawa, H. Asoh, N. Kitawaki: Blind source separation in reflective sound fields, HSCʼ01 (2001)
H. Sawada, S. Araki, R. Mukai, S. Makino: On calculating the inverse of separation matrix in frequency-domain blind source separation, ICAʼ06 (2006) pp. 691-699
V.C. Soon, L. Tong, Y.F. Huang, R. Liu: A robust method for wideband signal separation, ISCASʼ93 (1993) pp. 703-706
R. Mukai, S. Araki, H. Sawada, S. Makino: Removal of residual cross-talk components in blind source separation using LMS filters, NNSPʼ02 (2002) pp. 435-444
H. Saruwatari, S. Kurita, K. Takeda, F. Itakura, K. Shikano: Blind source separation based on subband ICA and beamforming, ICSLPʼ00, Vol. III (2000) pp. 94-97
S.Y. Low, S. Nordholm, R. Togneri: Convolutive blind signal separation with post-processing, IEEE Trans. Speech, Audio Process. 12(5), 539-548 (2004)
H. Saruwatari, T. Kawamura, T. Nishikawa, A. Lee, K. Shikano: Blind source separation based on a fast-convergence algorithm combining ICA and beamforming, IEEE Trans. Audio, Speech, Lang. Process. 14(2), 666-678 (2006)
R. Mukai, H. Sawada, S. Araki, S. Makino: Near-field frequency domain blind source separation for convolutive mixtures, Proc. ICASSPʼ04, Vol. IV (2004) pp. 49-52
R.O. Schmidt, R.E. Franks: Multiple source DF signal processing: an experimental system, IEEE Trans. Ant. Prop. 4(3), 281-290 (1986)
N. Murata, S. Ikeda: An on-line algorightm for blind source separation on speech signals, International Symposium on Theory and its Applications, Vol. 3 (1998) pp. 923-926
F. Asano, S. Ikeda: Evaluation and real-time implementation of blind source separation system using time-delayed decorrelation, ICAʼ00 (2000) pp. 411-416
S. Ukai, H. Saruwatari, T. Takatani, R. Mukai: Multistage SIMO-model-based blind source separation combining frequenct-domain ICA and time-domain ICA, Proc. ICASSPʼ04, Vol. IV (2004) pp. 109-112
S. Araki, S. Makino, A. Blin, R. Mukai, H. Sawada: Blind separation of more speech than sensors with less distortion by combining sparseness and ICA, IWAENCʼ03 (2003) pp. 271-274
R. Mukai, H. Sawada, S. Arakiand, S. Makino: Blind source separation for moving speech signals using blockwise ICA and residual crosstalk subtraction, IEICE Trans. Fundamentals E87-A(8), 1941-1948 (2004)
R. Mukai, H. Sawada, S. Araki, S. Makino: Frequency domain blind source separation for many speech signals, ICAʼ04 (2004) pp. 461-469
Y. Mori, H. Saruwatari, T. Takatani, K. Shikano, T. Hiekata, T. Morita: ICA and binary-mask-based blind source separation with small directional microphones, ICAʼ06 (2006) pp. 649-657
T. Nishikawa, H. Saruwatari, K. Shikano: Stable learning algorithm for blind separation of temporally correlated signals combining multistage ICA and linear prediction, ICAʼ03 (2003) pp. 337-342
T. Takatani, T. Nishikawa, H. Saruwatari, K. Shikano: Blind separation of binaural sound mixtures using SIMO-model-based independent component analysis, Proc. ICASSPʼ04, Vol. IV (2004) pp. 113-116
T. Hoya, A.K. Barros, T. Rutkowski, A. Cichocki: Speech extraction based upon a combined subband independent component analysis and neural memory, ICAʼ03 (2003) pp. 355-360
Author information
Authors and Affiliations
Corresponding authors
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2008 Springer-Verlag Berlin Heidelberg
About this chapter
Cite this chapter
Pedersen, M.S., Larsen, J., Kjems, U., Parra, L.C. (2008). Convolutive Blind Source Separation Methods. In: Benesty, J., Sondhi, M.M., Huang, Y.A. (eds) Springer Handbook of Speech Processing. Springer Handbooks. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-540-49127-9_52
Download citation
DOI: https://doi.org/10.1007/978-3-540-49127-9_52
Publisher Name: Springer, Berlin, Heidelberg
Print ISBN: 978-3-540-49125-5
Online ISBN: 978-3-540-49127-9
eBook Packages: EngineeringEngineering (R0)