
Abstract
We witness a rapid increase in the number of data streams due to Cloud Computing, Big Data and IoT development. We would like to access and share data streams using a data service approach. In this paper, we propose a flexible continuous data service model and a continuous data service composition algorithm for answering queries across data streams. Service operation instance is modeled as a view defined on data streams composed of two parts: a data part and a time synchronization part. The composition algorithm extends the traditional Bucket algorithm to find the contained rewriting of user query on views satisfying the containment relationship of both data part and time synchronization part. We also present use case and experimental studies indicating that the approach is effective and efficient.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others



Keywords
1 Introduction
Web services technology is a general medium for sharing data and functionality and enabling cross-organization collaboration for enterprise and web systems. Data services [1] or data-providing services [2] are a kind of services that allow query-like access to an organization’s data sources. Although the existing data processing framework provides composition models or query languages which allow us to retrieve desired data from multiple data sources, data services provide a flexible, controlled and standardized approach to access or query an organization’s data sources without exposing its databases directly [3]. Furthermore, when queries require to access data sources across organizations, several services can be composed to generate a response [4,5,6].
To bring the benefits of data services, we would like to access and share data streams using a data service approach. However, data streams are very different from traditional data sources. This makes the problem of data service modelling and composition challenging for accessing and sharing data streams. Firstly, unlike traditional snap-shot queries over data tables, queries over data streams are continuous. A continuous query is issued once and remains active for a long time. The answer to a continuous query is constructed progressively as new input stream tuples arrive [7]. Once executed, data services for queries on data streams need to continuously return results and consider temporal constraints. Secondly, for queries over multiple data sources, traditional data providing services are often modeled as parameterized views over data schemas [3, 4]. Based on the service model, services can be composed using a query rewriting approach to answer queries over multiple data sources [3, 4]. Because most of the stream query language do not support views [7], how to model data services as views over data streams is not trivial. And because queries for data streams need to be updated continuously, the traditional query rewriting approach is inapplicable to rewrite query over data streams directly.
In this paper, we introduce a data service model for continuous query over data streams, and call it “continuous data services”. Service operation inputs are not modeled as fixed query conditions. They are arbitrary query conditions modeled as a set of optional attributes of the underlying data model and condition predicates. “sliding window” is introduced into the service model to describe the temporal feature of services. The instance of the service operation can be modeled as a view defined on data streams. Based on the continuous data service model, we propose a continuous data service composition algorithm for answering queries across data streams. It improve the Bucket algorithm [8] for “answering queries using views” on persistent relation data to find the contained rewriting by checking the containment relationship between time synchronization part of the query and the rewriting. We describe an implementation, a use case and provide a performance evaluation of the proposed approach.
The rest of this paper is organized as follows: In Sect. 2, we motivate the need for conjunctive queries across data streams, and discuss the underlying challenges. In Sect. 3, we describe the continuous data service model. In Sect. 4, we propose the continuous data service composition algorithm. In Sect. 5, we describe our implementation and evaluate our approach. We overview related work in Sect. 6. We provide concluding remarks and future research outlook in Sect. 7.
2 Motivation
In this section, we describe a motivating scenario we use throughout the paper. Various systems for maritime freight logistics collect data like vessel trajectories, vessel basic information and so on. Among these data sources, the data stream  records trajectory points of a vessel, where
records trajectory points of a vessel, where  is the Maritime Mobile Service Identity,
is the Maritime Mobile Service Identity,  and
and  is the longitude and latitude of the vessel location, and
is the longitude and latitude of the vessel location, and  is the vessel’s speed. The relation data
is the vessel’s speed. The relation data  records static information of ships including the
records static information of ships including the  , the International Maritime Organization (imo) code, call sign, name, type, length, width, the Estimated Time of Arrival (eta), draught of the vessel. The relation data
, the International Maritime Organization (imo) code, call sign, name, type, length, width, the Estimated Time of Arrival (eta), draught of the vessel. The relation data  records the destination and the identification of the position message source.
records the destination and the identification of the position message source.
These systems are subordinate to different management domains and won’t expose full data access to their data sources directly. They provide access to the set of services with constraints described in Table 1. The underlying data streams of  are
are  and
and  . They have constraints that
. They have constraints that  must be greater than
must be greater than  and
and  greater than
greater than  with a time-based sliding window of window size
with a time-based sliding window of window size  and slide size
and slide size  . The underlying data streams of
. The underlying data streams of  is
is  and
and  . The time window of the stream has window size
. The time window of the stream has window size  and slide size
and slide size  . The underlying data stream of
. The underlying data stream of  is
is  . This data stream has constraints that the
. This data stream has constraints that the  must be less than
must be less than  with window size
with window size  and slide size
and slide size  . The underlying data streams of
. The underlying data streams of  are
are  and
and  . This service has constraints that the
. This service has constraints that the  must be less than
must be less than  with window size
with window size  and slide size
and slide size  . We also express the underlying query of the services as conjunctive queries extended with time-based sliding window semantics. Note that join predicates in this notation are expressed by multiple occurrences of the same variables.
. We also express the underlying query of the services as conjunctive queries extended with time-based sliding window semantics. Note that join predicates in this notation are expressed by multiple occurrences of the same variables.
Those services with sliding window constraints continuously push output to the service consumer once the consumer creates a connection with the service producer. The output is the query results in range of the configured window size that will be updated every slide size. So we call these services “continuous data services”.
Now assume the following query asks for vessels that have outstanding speed over a defined sliding window. Note we express the query as conjunctive queries extended with time-based sliding window semantics. And note that join predicates in this notation are expressed by multiple occurrences of the same variables.

Obviously service  is not useful to satisfy this query request, because
is not useful to satisfy this query request, because  has information only on vessels whose speed is less than 40 km whereas we are interested in vessels which has speed greater than 40 km. Although
has information only on vessels whose speed is less than 40 km whereas we are interested in vessels which has speed greater than 40 km. Although  is relevant to user query, it only has mmsi information and need to retrieve destination information by invoking other service like
is relevant to user query, it only has mmsi information and need to retrieve destination information by invoking other service like  . However,
. However,  only has information on vessels with mmsi greater than
only has information on vessels with mmsi greater than  , and
, and  has information on vessels with mmsi less than
has information on vessels with mmsi less than  , meaning
, meaning  and
and  are disjoint. So service
are disjoint. So service  is also not useful to answer this user query. We are left with one possible plan to use the services to answer this query. Firstly invoke
is also not useful to answer this user query. We are left with one possible plan to use the services to answer this query. Firstly invoke  to retrieve the list of vessels with a sliding window of window size
to retrieve the list of vessels with a sliding window of window size  and slide size
and slide size  . Then invoke
. Then invoke  where
where  is less than
is less than  with a sliding window of window size
with a sliding window of window size  and slide size
and slide size  . Results from both services are joint to answer
. Results from both services are joint to answer  . Note that the sliding window constraints of
. Note that the sliding window constraints of  and
and  is different, we also need to judge if the joint results can satisfy the query requirement. Also note that the results only vessels with
is different, we also need to judge if the joint results can satisfy the query requirement. Also note that the results only vessels with  less than 2000, which can satisfy the query is not equivalent with it. Note in this example, there is only one service composition plan satisfying the query, but there may be multiple plans in other examples.
less than 2000, which can satisfy the query is not equivalent with it. Note in this example, there is only one service composition plan satisfying the query, but there may be multiple plans in other examples.
3 Model of Continuous Data Service
3.1 Data Model
We use the synchronized relation model for describing the contents of data stream sources. The data model includes:
-
 and
and  .
.  is a tagged stream with the format of “
is a tagged stream with the format of “ ”, where
”, where  can be either insert (+), update (u), or delete (-) and
can be either insert (+), update (u), or delete (-) and  indicates the time at which the modification takes place. For detailed explanation of what is a tagged stream, please refer to [7]. Any tagged stream
indicates the time at which the modification takes place. For detailed explanation of what is a tagged stream, please refer to [7]. Any tagged stream  has a corresponding time-varying relation
has a corresponding time-varying relation  . The relation is continuously modified by
. The relation is continuously modified by  ’s tuples.
’s tuples. -
 .
.  are the attributes of the time-varying relation
are the attributes of the time-varying relation  .
. -
 .
.  is the time point where the relation
is the time point where the relation  is modified by the underlying
is modified by the underlying  ’s tuples.
’s tuples. -
 . sync synchronized stream is a special tagged stream “
. sync synchronized stream is a special tagged stream “ ”, where timepoint represents a time point which is the only attribute of sync. Synchronized stream is a kind of tagged stream. So it also has a corresponding time-varying relation
”, where timepoint represents a time point which is the only attribute of sync. Synchronized stream is a kind of tagged stream. So it also has a corresponding time-varying relation  .
. -
 .
.  is a synchronized relation of any arity. Figure 1 illustrates a synchronized stream of
is a synchronized relation of any arity. Figure 1 illustrates a synchronized stream of  . For traditional persistent data (e.g. data tables in a database), the tuples are reflected at any time. Here we denote the synchronized stream associated with the traditional persistent data as
. For traditional persistent data (e.g. data tables in a database), the tuples are reflected at any time. Here we denote the synchronized stream associated with the traditional persistent data as  .
.
 and
and  .
.  is a tagged stream with the format of “
is a tagged stream with the format of “ ”, where
”, where  can be either insert (+), update (u), or delete (-) and
can be either insert (+), update (u), or delete (-) and  indicates the time at which the modification takes place. For detailed explanation of what is a tagged stream, please refer to [
indicates the time at which the modification takes place. For detailed explanation of what is a tagged stream, please refer to [ has a corresponding time-varying relation
has a corresponding time-varying relation  . The relation is continuously modified by
. The relation is continuously modified by  ’s tuples.
’s tuples. .
.  are the attributes of the time-varying relation
are the attributes of the time-varying relation  .
. .
.  is the time point where the relation
is the time point where the relation  is modified by the underlying
is modified by the underlying  ’s tuples.
’s tuples. . sync synchronized stream is a special tagged stream “
. sync synchronized stream is a special tagged stream “ ”, where timepoint represents a time point which is the only attribute of sync. Synchronized stream is a kind of tagged stream. So it also has a corresponding time-varying relation
”, where timepoint represents a time point which is the only attribute of sync. Synchronized stream is a kind of tagged stream. So it also has a corresponding time-varying relation  .
. .
.  is a synchronized relation of any arity. Figure
is a synchronized relation of any arity. Figure  . For traditional persistent data (e.g. data tables in a database), the tuples are reflected at any time. Here we denote the synchronized stream associated with the traditional persistent data as
. For traditional persistent data (e.g. data tables in a database), the tuples are reflected at any time. Here we denote the synchronized stream associated with the traditional persistent data as  .
.
A synchronized stream of 
DataModel of  can be represented as a tuple:
can be represented as a tuple:  , where
, where  is a set of attributes,
is a set of attributes,  is the subscript index of the synchronization stream
is the subscript index of the synchronization stream  . For example, the value of
. For example, the value of  is 2 for
is 2 for  , 3 for
, 3 for  and 4 for
and 4 for  etc.
etc.
3.2 Continuous Query Containment
Query containment and equivalence provide a formal framework to compare different queries in a data integration system. In relational databases, a query  is said to be contained in
is said to be contained in  , denoted by
, denoted by  , if and only if
, if and only if  for any database instance
for any database instance  .
.  is equivalent to
is equivalent to  if and only if
if and only if  and
and  .
.
In stream processing system, a continuous query over  tagged streams
tagged streams  is semantically equivalent to a materialized view that is defined by a SQL expression over the time-varying relations
is semantically equivalent to a materialized view that is defined by a SQL expression over the time-varying relations  [7]. The big difference between time-varying relations and traditional relations is that the time-varying relations have arbitrary refresh conditions. The solution is to isolate the time synchronization streams out of the continuous query expression. Then the containment relationship is tested from two aspects: (1) test data containment using traditional query containment test method, and (2) test synchronization containment.
[7]. The big difference between time-varying relations and traditional relations is that the time-varying relations have arbitrary refresh conditions. The solution is to isolate the time synchronization streams out of the continuous query expression. Then the containment relationship is tested from two aspects: (1) test data containment using traditional query containment test method, and (2) test synchronization containment.
For example, if we want to check the containment relationship of a query  and a data service instance of
and a data service instance of  like this:
like this:

and

We first test containment of time part of  and
and  . The synchronization relation part of
. The synchronization relation part of  (i.e.
(i.e.  ) is contained in the synchronization relation part of
) is contained in the synchronization relation part of  (i.e.
(i.e.  ). Because any tuples satisfied by the selection and projection conditions of
). Because any tuples satisfied by the selection and projection conditions of  also satisfied
also satisfied  , the data part of
, the data part of  is contained in data part of
is contained in data part of  . We can conclude that
. We can conclude that  is contained in
is contained in  .
.
3.3 Continuous Data Service
We model a continuous service as a view defined on the underlying data streams. Any service subscribes one or multiple data streams or database tables, which is defined as  . Any service has zero to multiple operations in which inputs, outputs, window range, window slide size should be defined. Input and output parameters are from the attributes of the underlying synchronized relations corresponding with
. Any service has zero to multiple operations in which inputs, outputs, window range, window slide size should be defined. Input and output parameters are from the attributes of the underlying synchronized relations corresponding with  . Every service instance publishes one tagged stream on message queue.
. Every service instance publishes one tagged stream on message queue.
Such service can be expressed as follows:  , where:
, where:
-
 is the unique identity of the service.
is the unique identity of the service. -
 is the stream set of the service subscribed from message queue.
is the stream set of the service subscribed from message queue.  , where
, where  is a tagged stream defined in Section II. A Data model
is a tagged stream defined in Section II. A Data model  is corresponding with a time-varying relations
is corresponding with a time-varying relations  .
.  and
and  are the constraints applied on content and time of the tagged stream.
are the constraints applied on content and time of the tagged stream. -
 is the stream set of the service published to message queue.
is the stream set of the service published to message queue. 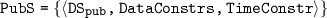 , where
, where  is a tagged stream. It is corresponding with a time-varying relation
is a tagged stream. It is corresponding with a time-varying relation  .
. -
 , where
, where 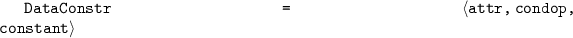 .
.  is the attribute of
is the attribute of 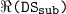 for
for  and
and  for
for  .
.  can be one of the condition operator from
can be one of the condition operator from  .
.  is a constant value.
is a constant value. -
 , where
, where 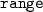 is range size of the sliding window of synchronized relation. Note that tumbling window and hopping window are both a special form of the sliding window. For tumbling window, range size is equal to slide size. And for hopping window, range size is a multiple of slide size.
is range size of the sliding window of synchronized relation. Note that tumbling window and hopping window are both a special form of the sliding window. For tumbling window, range size is equal to slide size. And for hopping window, range size is a multiple of slide size. -
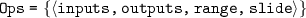 is the service operations.
is the service operations.  are a set of attributes of
are a set of attributes of  , the corresponding condition operator
, the corresponding condition operator  and constants.
and constants.  are a set of output parameters of the service operation.
are a set of output parameters of the service operation.  and
and  are the time constraint of the service request. A SyncSQL expression can be generated from Ops.
are the time constraint of the service request. A SyncSQL expression can be generated from Ops.
 is the unique identity of the service.
is the unique identity of the service. is the stream set of the service subscribed from message queue.
is the stream set of the service subscribed from message queue.  , where
, where  is a tagged stream defined in Section II. A Data model
is a tagged stream defined in Section II. A Data model  is corresponding with a time-varying relations
is corresponding with a time-varying relations  .
.  and
and  are the constraints applied on content and time of the tagged stream.
are the constraints applied on content and time of the tagged stream. is the stream set of the service published to message queue.
is the stream set of the service published to message queue. 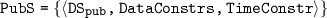 , where
, where  is a tagged stream. It is corresponding with a time-varying relation
is a tagged stream. It is corresponding with a time-varying relation  .
. , where
, where 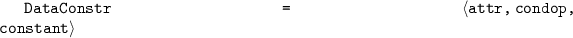 .
.  is the attribute of
is the attribute of  for
for  and
and  for
for  .
.  can be one of the condition operator from
can be one of the condition operator from  .
.  is a constant value.
is a constant value. , where
, where 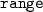 is range size of the sliding window of synchronized relation. Note that tumbling window and hopping window are both a special form of the sliding window. For tumbling window, range size is equal to slide size. And for hopping window, range size is a multiple of slide size.
is range size of the sliding window of synchronized relation. Note that tumbling window and hopping window are both a special form of the sliding window. For tumbling window, range size is equal to slide size. And for hopping window, range size is a multiple of slide size.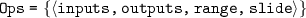 is the service operations.
is the service operations.  are a set of attributes of
are a set of attributes of  , the corresponding condition operator
, the corresponding condition operator  and constants.
and constants.  are a set of output parameters of the service operation.
are a set of output parameters of the service operation.  and
and  are the time constraint of the service request. A SyncSQL expression can be generated from Ops.
are the time constraint of the service request. A SyncSQL expression can be generated from Ops.The elements of the input and output set  are determined when a service is instantiated.
are determined when a service is instantiated.  of a service are also determined when a service is instantiated.
of a service are also determined when a service is instantiated.
Given a specific user inputs, the service has an associated instance. A service instance can also be defined as a query view on the underlying time-varying relations. We use the notation of conjunctive queries extended with synchronization stream to express the view. A data service  is transformed into a view:
is transformed into a view:

where  is all the attributes from all
is all the attributes from all  elements of
elements of  ,
,  are the underlying time-varying relation corresponding with all the elements of
are the underlying time-varying relation corresponding with all the elements of  . Note that not all subscribed streams have data constraints applied on them. If
. Note that not all subscribed streams have data constraints applied on them. If  has no data constraint, we can add a data constraint
has no data constraint, we can add a data constraint  on it:
on it:  . Thus all subscribed streams have data constraints represented as
. Thus all subscribed streams have data constraints represented as  .
.  is the intersection of all the window range size constraints applied on them.
is the intersection of all the window range size constraints applied on them.  is the synchronization stream applied on
is the synchronization stream applied on  .
.
A service instance of  can be transformed into a view like this:
can be transformed into a view like this:

 are data constraints from inputs of service operations.
are data constraints from inputs of service operations.  are synchronization stream from the time constraints of service operations.
are synchronization stream from the time constraints of service operations.  is the intersection of all the window range size constraints applied on
is the intersection of all the window range size constraints applied on  and from service operations.
and from service operations.
4 Data Services Composition for Answering Continuous Query
When services and service instances are transformed into views on time-varying relations, given a conjunctive query Q, we need to find the service composition plans to answer it. The problem of answering conjunctive query using views for traditional persistent data is NP-complete [9]. Bucket algorithm or minicon algorithm are the approaches to drastically reduce the number of rewritings we need to consider for a query given a set of views. So we can improve the Bucket algorithm [8] or MiniCon algorithm [10] to find the service composition plans to answer query Q. Here we give the improved Bucket algorithm. The main idea of Bucket algorithm is that we first consider each subgoal in the query in isolation, and determine which views may be relevant to that subgoal. Thus the number of query rewritings that need to be considered can be drastically reduced. In order to support finding relevant continuous data services or service instances, we improve the Bucket algorithm by adding the synchronization stream containment judgement and determining the service operation inputs and outputs after the relevant services are found.
The first step is shown in Algorithm 1. It constructs for each subgoal g in the query a bucket of relevant service or service instance atoms. In this algorithm, we check the containment relationship between the query sub-goal and the view transformed from the service or service instance.

The second step considers all the possible combinations of services and service instances. Each combination should include one of the service or service instance atoms from every bucket. Generate the candidate composition plans by checking if each combination is satisfied (if there exists no self-contradictory in the same combination). Keep those plans that is satisfied and delete those that is unsatisfied.

In the example explained in Sect. 2, the returned results contain only vessels with mmsi less than 2000, which is not equivalent with the query. In fact, the service composition plans that can answer user query can be divided into two categories: the equivalent composition plans and the contained composition plans. The former is equivalent with the query and the latter is contained in the query. There exists a maximally contained composition plan among the contained composition plans. So if a continuous query can be supported by mutiple composition plans, we can choose the equivalent or maximally contained composition plan among the candidates.
The third step searches the equivalent service composition plans or the contained service composition plans. Take the equivalent service composition plan as the example, the basic idea is to consider each candidate composition plan  , check if
, check if  when there exists no service atom in
when there exists no service atom in  . If there exists services and there exists data constraint atoms
. If there exists services and there exists data constraint atoms  and synchronization constraint atoms
and synchronization constraint atoms  such that
such that  and they can be used as the additional constraints on service when we instantiate it. The concrete steps for considering each
and they can be used as the additional constraints on service when we instantiate it. The concrete steps for considering each  are shown in Algorithm 2.
are shown in Algorithm 2.
In steps 4 and 20, when we judge the containment relationship between the plan and query, time synchronization containment relationship is checked first.
In step 5, we check if the equivalent composition plan that is more concise than the current plan  already exists. If it already exists, the current plan is abandoned. In steps 10 and 12, we use the additional data constraints
already exists. If it already exists, the current plan is abandoned. In steps 10 and 12, we use the additional data constraints  to instantiate a service. A method
to instantiate a service. A method  is called to determine the input and output parameters of the service operation. In this method, the
is called to determine the input and output parameters of the service operation. In this method, the  parameter value is taken as the output parameter value of the service operation. In step 10, we take additional data constraints in
parameter value is taken as the output parameter value of the service operation. In step 10, we take additional data constraints in  as the input parameter values of the service operation. The time constraints of
as the input parameter values of the service operation. The time constraints of  are taken as the time constraints of the service operation. In this method, we update
are taken as the time constraints of the service operation. In this method, we update  with the unsatisfied data constraints and returned. After the loop 7, all the services in
with the unsatisfied data constraints and returned. After the loop 7, all the services in  are instantiated. If the attributes of all the additional data constraints are also the data attributes of
are instantiated. If the attributes of all the additional data constraints are also the data attributes of  , it means that all the additional data constraints can be applied on the services, in other words, the services can satisfy the data constraints after instantiation. Otherwise, the services can not satisfy the data constraints and the service composition plan is abandoned.
, it means that all the additional data constraints can be applied on the services, in other words, the services can satisfy the data constraints after instantiation. Otherwise, the services can not satisfy the data constraints and the service composition plan is abandoned.
In step 20, if  ,
,  and all atoms of
and all atoms of  are service instances, delete the redundant plan than
are service instances, delete the redundant plan than  (in other words, the redundant plan
(in other words, the redundant plan  satisfying the condition that
satisfying the condition that  ) from the result set and add
) from the result set and add  into equivalent result set.
into equivalent result set.
To search the contained composition plan, if  and all atoms of
and all atoms of  are service instances, add
are service instances, add  into equivalent result set directly. If
into equivalent result set directly. If  is not contained in p and sub-goals of
is not contained in p and sub-goals of  overlap with that of
overlap with that of  , and there exist service atoms in
, and there exist service atoms in  , we should instantiate the services. Check whether all the additional constraints can be applied on the services when instantiating them. If they can’t be applied, this means that the services can not satisfy the data constraints after instantiation, in other words, the plan is not executable. We omit the pseudo code of this algorithm for searching contained composition plans due to limited space.
, we should instantiate the services. Check whether all the additional constraints can be applied on the services when instantiating them. If they can’t be applied, this means that the services can not satisfy the data constraints after instantiation, in other words, the plan is not executable. We omit the pseudo code of this algorithm for searching contained composition plans due to limited space.
5 Implementation and Evaluation
In this section, we first describe an implementation of our approach. Then we provide a use case and experimental evaluation.
5.1 Implementation
The architecture of our system is shown in Fig. 2. Firstly, relational databases and data stream sources should be registed and managed. When a query is posed, the query rewriter module uses the information from service registry to decide the candidate service composition plan. The service executor module is responsible for invocation and join/compose the service execution results.
Every service is implemented as a Spark Streaming job. The underlying data streams are subscribed by the service using Kafka. And the outputs of a service are published to Kafka, which can be subscribed by later services. For those Web based clients, we expose continuous data service as REST-like API over HTTP protocol based on a Web-based push technology - Sever-Sent Events (SSE) [11]. It allows the service to push query results to clients continuously. The client sends a request to a service and opens a single long-lived HTTP connection. The service then sends data continuously to the client without further action from the client.

Architecture of the implementation.
5.2 Case Study
In this section, we take the example introduced in Sect. 2 as the use case to introduce how our approach works.
Assume the outputs of  of an instance of
of an instance of  are
are  and no input parameters.
and no input parameters.  and
and  are 5 and 1 separately.
are 5 and 1 separately.
This instance of  can be expressed as:
can be expressed as:

In a similar way, the instance of  is:
is:

The instance of  can be expressed as follows:
can be expressed as follows:

Assume there is no instance for service  , so it is express as:
, so it is express as:

Query is expressed as Sect. 2. This query has sub-goals  ,
,  and TRAVEL.
and TRAVEL.
According to our algorithm, the steps to answer user query are as follows:
In the first step the algorithm creates buckets for each sub-goal of  . The contents of bucket for sub-goal
. The contents of bucket for sub-goal  are:
are:  ,
, , and
, and  .
.  is not in this bucket because the interpreted predicates of the view and the query are not mutually satisfiable. The contents of bucket for sub-goal
is not in this bucket because the interpreted predicates of the view and the query are not mutually satisfiable. The contents of bucket for sub-goal  are:
are:  . The contents of bucket for sub-goal
. The contents of bucket for sub-goal  are:
are:  .
.
In the second step of the algorithm, we combine elements from the buckets. The first combination, involving the first element from each bucket, yields the rewriting

However, while both  and
and  are relevant to the query in isolation, their combination is guaranteed to be empty because they cover disjoint sets of vessel identifiers.
are relevant to the query in isolation, their combination is guaranteed to be empty because they cover disjoint sets of vessel identifiers.
Consider the second elements in the left bucket yields the rewriting

Then we remove the first sub-goal, which is redundant, and generate service instance with the additional data constraints  . The output parameters of
. The output parameters of  instance operation are set to be variables from attributes of the underlying data stream which are also in the head of
instance operation are set to be variables from attributes of the underlying data stream which are also in the head of  , which is
, which is  . The inputs parameters are
. The inputs parameters are  .
.
So we would obtain  , which is the only contained composition plan the algorithm finds.
, which is the only contained composition plan the algorithm finds.
5.3 Experimental Evaluation
In this section, we give an experimental evaluation of our approach. The goal of the experimental evaluation is to analyze the factors that affect the performance of the service composition algorithm.
The service composition algorithm experiments were run on a computer with Intel(R) Core(TM) i5-2400 CPU 3.10 GHz and 8 GB memory. In order to experimentally evaluate our approach, we generated a set of continuous data services and service instances. We use three representative queries including the query example shown in Sect. 2. According to 80/20 rule (also known as Pareto principle), The method guarantees that the number of services and service instances that are related to user queries are about 20% of the total services and service instances generated. For each query, we generated various number of data services and data service instances from 100, 200, ... to 500. Figure 3 plots the total and average time to generate all composition plans for each query against the number of data sources. We can observe that the average generation time per composition plan is within 10ms, which is acceptable in real application.

Total and average time to generate compostion plans.
6 Related Work
Most of the research work on web service composition focus on traditional Effect-Providing services or application-logic services instead of Data-Providing services or data services. The traditional application-logic service composition algorithms are inapplicable and inefficient to data services that all share the same business function (i.e. data query) and have no side-effects [4].
Data integration approach is often adopted for the purpose of data services composition. Some use the query rewriting techniques as the composition algorithm [2,3,4,5, 12]. Others use visual mashup languages or constructs as composition approach [13, 14]. However, the data services model and composition algorithm in these work are inapplicable to data stream sources and data stream integration.
There are some related research work from data integration area such as InfoMaster [15] and Information Manifold [8]. Our work differs with these works in many ways. First, these works target toward resolving specific queries given a set of data sources, whereas in our work the focus is on constructing a composition of services that is independent of a particular input value. The composite service can be reused to answer a set of queries instead of a specific queries. Second, compared to previous query rewriting algorithms [10, 16] that were proposed for the traditional static relational data model, our composition algorithm is based on data stream model. As far as we know, our continuous data service model is the first service model to support data stream query and our algorithm is the first to address the problem of composing continuous data services to support data stream integration.
There are some related research work on service modeling for data streams such as [17, 18], however, the work cannot be used to solve the problem of query across various data sources directly. Some work has addressed the problem of supporting views in data stream management systems [7], however, the work is limited only to answering specific queries based on a set of data sources. Our work propose a continuous data service model which provides a flexible, controlled and standardized approach to access or query data stream. We address data stream integration problem by providing service composition approach. The composite service can access a set of conditions as input instead of limiting to answering specific queries.
7 Conclusion
In this paper, we presented an approach for conjunctive query on data streams by composing continuous data services. We introduce a flexible continuous data service model with continuous query as service operation. Service operation instance is modeled as a view defined on data streams in which the data part and time synchronization part are separated from each other. A continuous data service composition algorithm is introduced for answering queries across data streams. An experimental study is provided to evaluate the performance of our approach. As a future work, we plan to address location concerns when composing continuous data services.
References
Carey, M.J., Onose, N., Petropoulos, M.: Data services. Commun. ACM 55(6), 86–97 (2012)
Vaculín, R., Chen, H., Neruda, R., Sycara, K.: Modeling and discovery of data providing services. In: 2008 IEEE International Conference on Web Services, pp. 54–61, September 2008
Barhamgi, M., Benslimane, D., Ouksel, A.M.: Composing and optimizing data providing web services. In: Proceedings of the 17th International Conference on World Wide Web, pp. 1141–1142. ACM (2008)
Barhamgi, M., Benslimane, D., Medjahed, B.: A query rewriting approach for web service composition. IEEE Trans. Serv. Comput. 3(3), 206–222 (2010)
Zhou, L., Chen, H., Yu, T., Ma, J., Wu, Z.: Ontology-based scientific data service composition: a query rewriting-based approach. In: AAAI Spring Symposium: Semantic Scientific Knowledge Integration, pp. 116–121 (2008)
Zhang, F., Wang, G., Han, Y.: Automatic generation of service composition plans for correlated queries. In: 2013 10th Web Information System and Application Conference, pp. 143–149, November 2013
Ghanem, T.M., Elmagarmid, A.K., Larson, P.Å., Aref, W.G.: Supporting views in data stream management systems. ACM Trans. Database Syst. 35(1), 1–47
Levy, A.Y., Rajaraman, A., Ordille, J.J.: The world wide web as a collection of views: query processing in the information manifold. In: VIEWS, pp. 43–55 (1996)
Doan, A., Halevy, A., Ives, Z.: Principles of Data Integration, 1st edn. Morgan Kaufmann Publishers Inc., San Francisco (2012)
Pottinger, R., Halevy, A.: MiniCon: a scalable algorithm for answering queries using views. Int. J. Very Large Data Bases 10(2–3), 182–198 (2001)
Hickson, I.: Server-sent events. https://www.w3.org/TR/eventsource/. Accessed 25 October 2015
Zhao, W., Liu, C., Chen, J.: Automatic composition of information-providing web services based on query rewriting. Sci. China Inf. Sci. 55(11), 2428–2444 (2012)
Wang, G., Yang, S., Han, Y.: Mashroom: end-user mashup programming using nested tables. In: Proceedings of the 18th International Conference on World Wide Web, pp. 861–870. ACM (2009)
Han, Y., Wang, G., Ji, G., Zhang, P.: Situational data integration with data services and nested table. Serv. Oriented Comput. Appl. 7(2), 129–150 (2013)
Genesereth, M.R., Keller, A.M., Duschka, O.M.: Infomaster: an information integration system. SIGMOD Rec. 26(2), 539–542 (1997)
Levy, A.Y., Rajaraman, A., Ordille, J.J.: Querying heterogeneous information sources using source descriptions. In: Proceedings of the 22th International Conference on Very Large Data Bases. In: VLDB 1996, pp. 251–262. Morgan Kaufmann Publishers Inc., San Francisco (1996)
Han, Y., Liu, C., Su, S., Zhu, M., Zhang, Z., Zhang, S.: A proactive service model facilitating stream data fusion and correlation. Int. J. Web Serv. Res. (IJWSR) 14(3), 1–16 (2017)
Gil, D., Ferrández, A., Mora-Mora, H., Peral, J.: Internet of things: a review of surveys based on context aware intelligent services. Sensors 16(7), 1069 (2016)
Acknowledgments
This work is supported by Beijing Natural Science Foundation No. 4172018, National Natural Science Foundation of China No. 61672042, and University Cooperation Projects Foundation of CETC Ocean Corp.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Wang, G., Zuo, X., Hesenius, M., Xu, Y., Han, Y., Gruhn, V. (2018). A Data Services Composition Approach for Continuous Query on Data Streams. In: Cai, Y., Ishikawa, Y., Xu, J. (eds) Web and Big Data. APWeb-WAIM 2018. Lecture Notes in Computer Science(), vol 10988. Springer, Cham. https://doi.org/10.1007/978-3-319-96893-3_9
Download citation
DOI: https://doi.org/10.1007/978-3-319-96893-3_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-96892-6
Online ISBN: 978-3-319-96893-3
eBook Packages: Computer ScienceComputer Science (R0)