
Abstract
Image Multi-label Classification (IMC) assigns a label or a set of labels to an image. The big demand for image annotation and archiving in the web attracts researchers to develop many algorithms for this application domain. The Multi-Instance Multi-Label Learning (MIML) is an important type of machine learning framework proposed recently for IMC. The drawbacks of the existing methods that they did not take into consideration are: (a) the description of the elementary characteristics from the image, (b) the correlation between labels. In this chapter, we propose a novel algorithm (MIML-GABORLPP), which handles these limitations. The algorithm uses Gabor filter bank as feature descriptor to handle the first limitation. It applies the Label Priority Power set as multi-label transformation to solve the problem of label correlation. The experimental work shows that the results of MIML-GABORLPP are better when compared to two other existing techniques.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Image Multi-label Classification (IMC) is an important topic in data mining that assigns a label or a set of labels to an image. The big demand for image annotation and archiving in the web attracts researchers to develop many algorithms for this application domain [1]. The Multi-Instance Multi-label Learning (MIML) is a framework of machine learning proposed recently for computer vision application [2]. In this framework, an image is described with many regions or instances and can be assigned to multiple labels.
For instance, Fig. 1 shows that the image contains three regions for the label “trees.” Each region in the image is a set of instances. These regions can be expressed as different examples called feature vector, and in data mining it is called Multi-Instance Learning. At the same time, the image may be classified simultaneously for more than one label; it is then called Multi-Label Learning. The Multi-Label Learning models the relations between labels and regions (instead of the entire image).

Multi-Instance Multi-label Learning
This will decrease noises in this feature space and increase the accuracy of the model [1]. Figure 2 shows that only three regions in the image are assigned to three labels (sky, mountain, and water).

Comparison between the three learnings [3]
This comparison illustrated that multi-label learning takes into consideration the correlation between labels, while multi-instance learning connects regions to labels. MIML takes both relations simultaneously. MIML has been successfully applied to image text classification, image annotation, video annotation, ecological protection, and other tasks [1,2,3,4].
The first way transforms multi-label to single-label. This transformation is called Multi-Instance Single-label Learning (MISL) and applies multi-instance learner to have Single-Instance Single-label Learning (SISL). The second way transforms multi-instance to single-instance. This transformation is called Single-Instance Multi-label Learning (SIML) and applies multi-label learner to have SISL. Two most important techniques are proposed for these transformations: MIML-Boost and MIML-SVM [4]. We are interested in this chapter in the second transformation as a multi-label problem. The drawbacks of these existing methods do not take into consideration the description of some characteristics from the image and the correlation between labels [5].
This chapter proposes a new framework that improves the MIML. The idea is to extract the feature from the image using Gabor filter bank (GFB). It is a feature extraction algorithm that takes into consideration the local representation, shape, and geometry of an image. Then we apply K-mean to cluster the image into similar groups. The final step consists of applying the Label Priority Power set as multi-label transformation in order to solve the problem of label correlation [6]. Each step of our new contribution is described in Sect. 3.
The remainder of this chapter is organized as follows: Sect. 2 defines the problem formulation. Section 3 defines the problem solution. Section 4 discusses the experimental results. Finally, the conclusions are presented in Sect. 5.
2 Problem Formulation
The MIML is an algorithm that transforms the problem to a single-label classification [4]. In Fig. 3, there are two ways to do this: the first one (T1) transforms MIML to MISL and applies Multi-Instance Learner (L1). The second one (T2) transforms MIML to SIML and applies Multi-Label Learner (L2). A good review can be found in [4]. Two most important techniques are proposed for these transformations:

MIML solutions [4]
-
1.
MIML-BOOST: It is an MISL transformation. Each region in the image is transformed into a set of multi-instance called bags. Thus, original data-set can be split into a number of multi-instance datasets with only one label each. The learning task is transformed to traditional single-label learning. Figure 4 shows that the region in the original data-set is assigned to three labels (red green blue) from four (red green blue purple). In this algorithm, the region is split into four multi-instance regions.

MIML-boost illustrations [4]
-
2.
MIML-SVM: It is an SIML transformation. Each object is mapped into a feature vector using Hausdoff distance from a number of medoids generated first. The learning task is transformed to traditional multi-label learning.
Figure 5 shows that the region is mapped into a feature vector with three features computed using Hausdoff distance after using 3-medoids clustering algorithm. Figure 6 illustrates the steps of MIML-SVM.

MIML-SVM illustrations [4]

MIML-SVM steps
The drawbacks of these existing methods are that they do not take into consideration the following:
-
1.
The description of some characteristics from the image: color, shape, regions, textures and motion, and some elementary characteristics. The image could be assigned to sky or lake based on the relative size and placement of the components [5].
-
2.
The correlation between labels: In multi-label learning, labels are correlated. For example, if the mountain label is assigned to the image with rocks and sky and the field label is assigned to image with grass and sky, then an image with grass, rocks, and sky would be assigned with both labels, field and mountain [5].
3 Problem Solution
3.1 Two-Dimensional Gabor Filter
This is a linear filter used in several domains in image processing [7, 8]. Formally, the two-dimensional Gabor filter family is expressed by the following equations:
Four parameters are important to determine the Gabor filter, as shown in Fig. 7, which shows the variation of
-
1.
The wavelength of the sinusoidal factor λ
-
2.
The orientation of the normal to the parallel stripes of a Gabor function θ
-
3.
The phase offset ψ
-
4.
γ is the spatial aspect ratio

Variations of the Gabor parameters [9]
Moreover, σ is the sigma of the Gaussian envelope and usually it is equals one.
3.2 The Label Priority Power Set (LPP)
The LPP is a transformation method of multi-label learning into SISL [6]. It orders the label by importance. The advantage of this method is that it solves the problem of label correlation [6]. Figure 8 shows the conversion of multi-label data D to a multi-label dataset D′ sorted by the frequency of each label.

LPP transformation
3.3 Framework MIML-LPPGABOR
This section proposes a new framework that improves the MIML. The idea extracts important features (Mean, Standard Deviation, Skewness, Kurtosis, Entropy, First Quartile, Median, Third Quartile) from image using Gabor filter bank. It is a feature extraction algorithm that takes into consideration the local representation, shape, and geometry of an image. The first three features are the first central moments. They reflect the center position, the dispersion, and the asymmetry of the probability distribution. The drawback for these three features is that they are sensitive to outliers. Therefore, we add three features that divide the data in the image into four equal groups and they are not sensitive to outliers. Thus, we solve the first and second limitation of MIML. We then apply K-mean to cluster the image into similar groups. The final step consists of applying the Label Priority Power set as multi-label transformation in order to solve the problem of label correlation. The challenge of such learning is that the image contains many concepts existing in several regions at the same time. We faced the following issues:
-
1.
The images do not have the same size [10].
-
2.
Selection of the suitable feature from the image.
-
3.
Different objects in the image could be similar [11].
-
4.
Multiple objects in the same image.
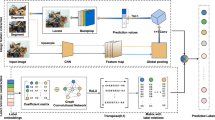
Figure 9 shows block diagram of the new framework compared to MIML (Fig. 6). The following is a detailed representation:

Block diagram of the proposed method
Phase 1: Image Preprocessing
Resizing the image consists of changing the sample rate of the original image, preserving the important content and structure. Formally, let I be an image with m rows and n columns I mxn. The resized image is an image I′m′xn′. The output of this step is a dataset D(I1m′xn′, I2m′xn′,…, Ip m′xn′), where p is number of images in the dataset. All images in the dataset D have the same dimension. The advantage of this step is to prepare a dataset for the feature extraction process. The limitation is that only uniform scaling can be applied when resizing the image [10]. Figure 10 shows an example of resizing a sample of images.

Resizing a sample of images
Phase 2: Feature Extraction Using Gabor Filter Bank
Gabor filter bank (GFB) is composed of many distinct Gabor filters with different parameters. Two parameters are useful for extracting the suitable features from image [8]: the orientations and the frequencies. They are calculated using the following equations:
Figure 11 shows GFB with five orientations and five frequencies.

GFB with five orientations and five frequencies
The process of extracting feature from image, as shown in Fig. 12, consists of:
-
1.
Reading the original image.
-
2.
Resizing the image and transforming it from RGB to gray space color. The output is an image I with the size (m = 128, n = 128).
-
3.
Applying each Gabor filter from GFB to I. Formally, this involves convolving each region in the image with the Gabor filter. The output of this step (c) is 25 filtered images with the same size as I.
-
4.
Normalizing each filtered image by zero mean and unit variance. Then, it is sub-sampled by two factors: d1 and d2 = (4,4), as in Fig. 12. That is, meaning that we will select 32 = 128/4 rows and 32 columns from the image. The output of this step is an image Is with the size (Ms = 32, Ns = 32). Each Is is partitioned into 4 × 4 Blocks. We extract nine features (Mean, Standard deviation, Skewness, Kurtosis, Entropy, First Quartile, Median, and Third Quartile) from each 2 × 2 blocks

Feature extraction using GFB
Phase 3: K-Means Clustering
There are two kinds of cluster analysis techniques: K-Means and hierarchical Clustering. K-Means is better than hierarchical clustering in case of big amount of data [11]. K-Means consists of grouping similar images into different k mutually exclusive clusters. The output of this step is K clusters C1, C2, …, Ck. An image may belong to exactly one of these clusters. The advantage of K-Means is that it is better than hierarchical clustering in case of big amount of data when K is small. The disadvantage of K-Means is the difficulty of predicting the K representing the number of clusters. Figure 13 shows the centroids of four clusters generated by the 4-means algorithm.

Clustering method using K-Means
Phase 4: Converting Multi-label Dataset to Multiclass Dataset using LPP
We will use in this step the transformation problem through breaking down the multi-label dataset into a single-label dataset using LPP transformation [6]. The output of this step is a dataset Ds = {(X1,y1), …, (XP,yP)}, where Xi is the feature extracted from Gabor and yi is the decimal conversion of binary multi-label value as shown in Fig. 14. The importance of this step is the reduction of the complexity of learning process.

Conversions to decimal
Tree Decision is a powerful classifier used in this phase because of its ease of use and its independence of the features of the dataset and their distribution. The output of this step is k trees, where k is the number of clusters. The advantage of this step is to applying single-label classification in a multi-label problem. Figure 15 shows the tree decisions constructed in the training phase for four cluster (the content of each tree is not important in the figure).

Training phase
4 Experimental Results
Our contribution is built on the image multi-label classification domain. For this purpose, we use scene dataset. It is a benchmark used for this purpose for several state-of-the-art algorithms [4]. It consists of 2000 images belonging to five natural scenes: mountains, desert, sunset, trees, and sea. We split it into 1600 training examples and 400 testing examples. Therefore, five evaluation metrics are used: Hamming Loss (HL), Ranking Loss (RL), One Error (OE), Average Precision (AP) and Coverage [4, 12]. These metrics are commonly used to evaluate the performance of multi-label classification, taking into consideration:
-
The mis-classification of examples–labels pairs (HL)
-
The order of the proper label (RL and OE)
-
Proper label ranked above particular label (AP)
It is clear from the above sections that there are many important parameters to be set up. We will discuss them in each phase.
Table 1 shows the values of parameters taken in the experiments. The size of the image 128 × 128 in the first phase and the couple (scale, orientation) is used in several references [8]. The parameter K should be small to have enough labels during the training phase.
The last parameter is the single-label classifier used in LPP. We used the decision tree as classifier. It is a powerful nonparametric method independent of the distribution of the feature vector space.
Table 2 presents:
-
Better results compared to the five evaluation metrics (HL, RL, AP, OE, Coverage) according to the major MIML methods found in the literature. (MIMLBoost, MIMLSVMmi, and MIMLNN) [4].
-
The results of our method using four parameters (Size of the image, Scale, Orientation, and the number of clusters K).
The analysis of this table shows a significant enhancement in all metrics using our method compared with the others of MIML. The transformation of multi-label to single-label gives better accuracy (single label metric) using LPP. This affects positively the results in all multi-label metrics.
5 Conclusion
The aim of this chapter was to introduce a new framework for image multi-label classification. It is an improvement of the MIML framework. We presented the advantages of our method over three main MIML methods. The strengths of our method were found in its simplicity with regard to its implementation, solving the challenge of the description of the elementary characteristics from the image, and the correlation between labels and overall competitiveness in terms of the five evaluation metrics used. In the future, a new method can be developed in the feature extraction phase that optimizes the choice of each parameter.
References
R.S. Cabral, F. Torre, J.P. Costeira and A. Bernardino, Matrix completion for multi-label image classification. In Advances in Neural Information Processing Systems, pp. 190–198, 2011.
S.J. Huang., W. Gao and Z.H. Zhou, “Fast multi-instance multi-label learning”. In Twenty-Eighth AAAI Conference on Artificial Intelligence, 21 June 2014.
Z. J. Zha, X. S. Hua, T. Mei, J. Wang,,G. J. Qi and Z. Wang, “Joint multi-label multi-instance learning for image classification”. In Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on (pp. 1–8). IEEE, June 2008.
ML. Zhang and ZH. Zhou, “A review on multi-label learning algorithms.” IEEE transactions on knowledge and data engineering 26.8: pp. 1819–1837, August 2014.
M.R. Boutell, J. Luo, X. Shen, and C.M. Brown, “Learning multi-label scene classification”. Pattern recognition, 37(9), pp. 1757–1771, 2004.
Z. Abdallah, A. El-Zaart, and M. Oueidat. “An Improvement of Label PowerSet Method Based on Priority Label Transformation.” International Journal of Applied Engineering Research 11.16: pp. 9079–9087, 2016.
M. Nosrati, R. Karimi, M. Hariri and K. Malekian, “Edge detection techniques in processing digital images: investigation of canny algorithm and gabor method”. World Applied Programming, pp. 116–21, March 2013.
S. Khan, M. Hussain, H. Aboalsamh, H. Mathkour, G. Bebis and M. Zakariah, “Optimized Gabor features for mass classification in mammography”. Applied Soft Computing, pp. 267–80, 31 July 2016.
N. Sonawane and BD. Phulpagar, “Review on Content-Aware Image Re-sizing Using Improved Seam Carving and Frequency Domain Analysis”, 2015
M. Kaur and U. Kaur, “Comparison between k-means and hierarchical algorithm using query redirection”. International Journal of Advanced Research in Computer Science and Software Engineering, July 2013.
Abdallah, Ziad, Ali El Zaart, and Mohamad Oueidat. “Experimental analysis and comparison of multilabel problem transformation methods for multimedia domain.” Applied Research in Computer Science and Engineering (ICAR), 2015 International Conference on. IEEE, 2015
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Abdallah, Z., El-Zaart, A., Oueidat, M. (2018). Proposed Multi-label Image Classification Method Based on Gabor Filter. In: Alja’am, J., El Saddik, A., Sadka, A. (eds) Recent Trends in Computer Applications. Springer, Cham. https://doi.org/10.1007/978-3-319-89914-5_4
Download citation
DOI: https://doi.org/10.1007/978-3-319-89914-5_4
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-89913-8
Online ISBN: 978-3-319-89914-5
eBook Packages: Computer ScienceComputer Science (R0)