
Abstract
In this article, we investigate which features are required to enhance a credit scoring model for a Brazilian retail enterprise. In order to find attributes that can improve the performance of classifier algorithms for credit granting, a national and an international survey were carried out. A logistic regression classifier was used and the main result has improved the performance of data mining classifiers. The main contribution of this article was the verification that additional financial and behavioral data increase defaulting prediction performance on credit granting.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
- Credit granting
- Attribute assessment
- Classifier algorithms
- Logistic regression
- Receiver operating characteristic (ROC)
1 Introduction
On the last decades, the efficiency of management decisions has been representing an increase in the economic success of enterprises. Credit granting decisions became part of this scenario.
The development and use of more efficient mechanisms for credit analysis and defaulting predictions have been representing fundamental issues for the commercial success of financial enterprises [2, 8, 9].
The use of predictive models for credit analysis has been implemented by the so-called credit scoring systems [1]. These systems, based upon recent customers’ historical data in financial relationship with enterprises, can provide customers’ different scores, allowing adequate analysis for credit decisions [10].
This research tackles the case study of a Brazilian retailer enterprise with hundreds of stores spread around the country, providing its customers with credit cards.
Typically, a credit-seeking candidate may go to a store and request a credit card, which can be used for shopping or acquiring services.
Once the credit is granted, a customer can then perform credit card transactions or obtain some personal loans, being limited to a predetermined credit profile.
The objective of the enterprise is to develop a system that allows to identify credit defaulting customers, among other available functionalities. The system uses data mining algorithms for customer defaulting predictions.
In order to improve the performance of several algorithms that presented unsatisfactory results, using demographic variables, with the Area Under Curve—Receiver Operating Characteristic (AUC-ROC) value = 0.9, we investigated which additional attributes must be used for better defaulting predictions.
The main contribution of this article was the verification that additional financial and behavioral data increase defaulting prediction performance on credit granting.
The rest of this article is organized as follows: Sect. 41.2 presents a survey on behavioral and financial attributes used for credit granting; Sect. 41.3 describes experiments using the logistic regression and others classifiers and its results; finally, Sect. 41.4 presents some conclusions, recommendations and suggestions for future work.
2 Data Set Assessment
The choice and definition of data sets to be used in the defaulting prediction was a non-trivial process and the data quality has been influenced by the performance of the used algorithm. For this investigation, a sample of the data set was used and validated by the enterprise.
The initial data consisted of 6158 records, with 4461 related to the non-defaulting customers and 1696 related to defaulting customers.
The sample data set contains eight attributes: income (customer’s income); gender (customer’s gender); mar_status (customer’s marital status); dependents (number of customer dependents); residence (customer residence type); points (customer’s internal score value); ext_credit_lim (customer credit limit for external transactions); and default (the target class, classifying the customer as defaulting or non-defaulting).
2.1 Predictive Variables Used in Credit Scoring Systems from the International Literature
In the survey of the international specialized literature carried out by Hörkkö [7], involving 11 scientific articles, it was reported the predictive variables used for the development of theoretical and practical applications of credit scoring. Table 41.1 shows a tabulation by frequency of the variables identified within the research carried out.
In another survey of the international specialized literature, Delamaire [4] has elaborated a more in-depth research, involving 35 scientific articles, in which he has identified the predictive variables used for the development of credit scoring applications. Table 41.2 shows a frequency tabulation of the attributes identified in the investigation.
From this review, Delamaire [4] has concluded that the attributes used by researchers in credit scoring applications are different, depending upon the credit institution that provides the data.
However, socio demographic attributes such as income, age, marital status, type of housing, type of employment, number of dependents (children), or residence time at the current address are often mentioned.
Additional detailed banking information, electoral information, union membership information, nationality, and certain demographics and bank references are attributes that are not commonly used in credit scoring applications.
The review suggests that attributes such as age, for instance, are highly predictive.
Birth date has the advantage of being a fixed element and is generally a highly predictive attribute.
It is possible to assume that the reason why certain attributes are recurrent in application forms is that they have a high explanatory power to identify defaulting customers.
Thus, for example, the 12 main variables surveyed (in terms of % of frequency) are often used in the development of credit granting systems, while some other attributes mentioned in these bibliographic reviews will be predictive or not, depending on the enterprise and also from the type of product for which the system was designed.
2.2 Predictive Variables Used in Credit Scoring Systems from the Brazilian Literature
It was carried out an investigation from the Brazilian specialized literature on the variables used in credit scoring applications, involving 36 articles, dissertations, and theses. The research results, describing the identified list of variables are presented in Table 41.3, in frequency tabulation mode.
The socio demographic variables are similar, with slight differences, from the revisions made. It is observed that the income and age variables appear in all articles. As already commented, these variables probably have a high predictive power. Other variables of this type also have intersections with the reviews carried out.
The so-called financial and behavioral variables, that contain information about customer’s financial behavior, appear to be specific to the credit granting business and vary in application type.
In terms of number of variables to be used, in a research carried out by Aniceto [3], it was found that 53% of the surveyed articles used between 11 and 20 variables.
Finally, it has been observed that in the reviews, the socio demographic attributes are very similar, and attributes that characterize client’s financial behavior are highly dependent on the business domain.
Behavioral variables provided by the Brazilian enterprise are presented in Table 41.4 that presents attributes, a small description, and the used aggregation function.
The provided sample data set correspond to a period of almost 2 years of financial activities.
However, for this investigation, it was considered an initial period of 13 months (10/2015 up to 10/2016). This sample data set has been stored in tables of a Data Base Management System (DBMS), in order to allow a more appropriate manipulation.
3 Experiments
The following experiments were performed using a different samples strategy for training and testing classifiers. The logistic regression classifier was chosen for these experiments, mainly because assessments have shown that it performs better, when compared to other classifiers.
One of the objectives of these experiments was to evaluate with past information, if it is possible to predict, with what performance and accuracy, future customer behaviors in terms of default patterns.
In order to implement these experiments, it was decided to use the Orange tool [5].
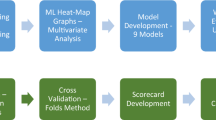
The created model is shown in Fig. 41.1, applying k-fold cross-validation (k = 10), where the initial data set was randomly partitioned into k subsets (folds) k1, k2, …, kk of mutually exclusive sizes of approximately equal size. Training and testing were performed k times, and for each iteration i, the subset Di was used as test set, and the other subsets were used for training the model [6, 11].

The created model in the orange tool
3.1 The Experiment Number 1
For the execution of this experiment 1, table bhs-band-2015-10-12-cadast-behav contains training samples and table bhs-band-2016-10-01-cadast-behav contains test samples.
In this experiment, it was used logistic regression classifier and gain ratio metric, to define the most important attributes for defaulting predictions.
After the classifier execution, the result of the AUC-ROC metric and other obtained measures, is shown in Fig. 41.2. It is observed that the value of the ROC Curve (AUC-ROC) is 0.986.

Results of the experiment number 1
The confusion matrix obtained from this experiment has presented a percentage of false positives of 2.3% and of false negatives of 4.3%. As noticed, the classifier predicted 100 non-default customers as defaulting customers and predicted 36 defaulting customers as non-defaulting.
3.2 The Experiment Number 2
For the second experiment, the bhs-band-2015-10-12-cadast-behav and bhs-band-adi-defaults-2016-not-2015 tables were used. The last table contains customers from the year 2016 data set who are not at the year 2015 data set. The metric gain ratio was used to define the most important attributes in prediction.
By executing the regressive model, the result of the AUC-ROC metric and other measures of classifier’s performance used is shown in Fig. 41.3. The value of the ROC Curve (AUC-ROC) was equal to 0.987 in training.

Results of the experiment number 2
As observed from the obtained confusion matrix, the classifier has predicted 20 non-defaulting customers as defaulting customers (about 3.0% of customers as false positives) and has predicted 5 defaulting customers as non-defaulting customers (about 2.8% of defaulting customers as false negatives). It is noticed that with this training, based on data from the year 2015, predictions were made about the defaulting customer in data from 2016, for customers who were not at the data set from the 2015 year.
3.3 The Experiment Number 3
For this experiment, two data sets were generated: one containing attributes characterized as demographics attributes and other containing attributes considered as financial/behavioral attributes. The performed analysis consisted of the evaluation of the performance of certain classifiers in the two data sets, in order to measure the improvement of the prediction with the use of these data sets.
From the specific case of the first data set, named B1-Cadast, which contains only demographics data, the following classifiers were used: Logistic Regression (LR), k-Nearest Neighbors (kNN), Decision Trees (DT), and Support Vector Machine (SVM). The Orange tool was used to perform the evaluation.
The assessment consisted of submitting the classifiers for several executions and, in each of them, a certain attribute was removed, based upon its value of the gain ratio metric (the attributes of smaller values were first removed).
Figure 41.4 presents the evaluation of the four classifiers mentioned, used in the B1-Cadast data set. It was observed that the LR classifier has obtained the best performance in terms of AUC-ROC values, and the kNN classifier was the second best result in the evaluation. The DT and SVM classifiers obtained the worst results.

The evaluation of classifier’s results with demographic data
The next evaluation consisted of submitting the same classifiers to a new data set, called B1-Cadast-Behav, containing demographic data, together with the behavioral/financial data.
The four classifiers previously mentioned were used in this data set and Fig. 41.5 presents the evaluation of the classifiers. It is again observed that the LR classifier was the one that obtained the best performance, in terms of AUC-ROC values, and the DT classifier obtained the second best result in this evaluation. The kNN and SVM classifiers had the worst results.

Evaluation of classifier’s results with demographic and behavioral data
It is observed that the junction of the two data sets, B1-Cadast and B1-Cadast-Behav significantly increases the predictive capacity of the LR classifier model, especially when only 19 variables are used, with an AUC-ROC value equal to 0.997.
Some observations obtained from these three experiments are necessary to state here:
-
The use of behavioral variables significantly improves the prediction of defaulting customers, and classifiers get AUC-ROC values approximate from what was obtained in the specialized literature; and
-
the data provided by the retail enterprise have allowed to confirm, based on performed tests, that high quality data (demographic and behavioral) were provided, which allows a significant accuracy in the classifier used.
4 Conclusion
This investigation was carried out on aspects inherent to data extraction from the development of the credit scoring system prototype. Initial demographic data used were not adequate for defaulting predictions.
In order to improve accuracy on prediction, additional behavioral/finance data was investigated in specialized literature, to obtain also additional features to improve credit scoring. Real data was used and provided by a Brazilian retailer enterprise.
The Logistic Regression (LR) classifier was used and the results have shown that additional data have improved the classifier performance.
One area for further work is to use different classifiers and analyze their performance. Other area is getting more behavioral/finance attributes.
References
J. Abellán, G. Castellano, A comparative study on base classifiers in ensemble methods for credit scoring. Expert Syst. Appl. 73, 1–10 (2017)
M. Ala’raj, M.F. Abbod, A new hybrid ensemble credit scoring model based on classifiers consensus system approach. Expert Syst. Appl. 64, 36–55 (2016)
M.C. Aniceto, Estudo comparativo entre técnicas de aprendizado de máquina para estimação de risco de crédito. Dissertação (Mestrado em Administração). Universidade de Brasília, Brasília, 2016
L. Delamaire, Implementing a credit risk management system based on innovative scoring techniques, Ph.D. thesis, University of Birmingham, 2012
J. Demšar, T. Curk, A. Erjavec, Č. Gorup, T. Hočevar, M. Milutinovič, M. Možina, M. Polajnar, M. Toplak, A. Starič, M. Stajdohar, L. Umek, L. Zagar, J. Zbontar, M. Zitnik, B. Zupan, Orange: data mining toolbox in python. J. Mach. Learn. Res. 14, 2349–2353 (2013)
J. Han, M. Kamber, J. Pei, Data Mining - Concepts and Techniques, 3rd edn. (Morgan Kaufmann, Amsterdam, 2012)
M. Hörkkö, The determinants of default in consumer credit market. Masters thesis, Aalto University School of Economics (2010). Retrived from http://epub.lib.aalto.fi/en/ethesis/pdf/12299/hse_ethesis_12299.pdf
M.B. Pascual, A.M. Martínez, A.M. Alamillos, Redes bayesianas aplicadas a problemas de credit scoring. Una aplicación práctica. Cuadernos de Economía 37(104), 73–86 (2014)
R.M. Stein, The relationship between default prediction and lending profits: Integrating ROC analysis and loan pricing. J. Bank. Finance 29, 1213–1236 (2005)
B. Waad, B.M. Ghazi, L. Mohamed, A three-stage feature selection using quadratic programming for credit scoring. Appl. Artif. Intell. Int. J. 27, 8 (2013)
I. Witten, E. Frank, Data Mining Practical Machine Learning Tools and Techniques, 2nd edn. (Elsevier, Amsterdam, 2005)
Acknowledgements
The authors would like to thank: the Brazilian Aeronautics Institute of Technology (ITA); the Casimiro Montenegro Filho Foundation (FCMF); the Software Engineering Research Group (GPES) members; and the 2RP Net Enterprise for their infrastructure, assistance, advice, data set, and financial support for this work.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG, part of Springer Nature
About this paper

Cite this paper
Cunha, S.C., Carneiro, E.M., Mialaret, L.F.S., Dias, L.A.V., da Cunha, A.M. (2018). Investigating Attribute Assessment for Credit Granting on a Brazilian Retail Enterprise. In: Latifi, S. (eds) Information Technology - New Generations. Advances in Intelligent Systems and Computing, vol 738. Springer, Cham. https://doi.org/10.1007/978-3-319-77028-4_41
Download citation
DOI: https://doi.org/10.1007/978-3-319-77028-4_41
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-77027-7
Online ISBN: 978-3-319-77028-4
eBook Packages: EngineeringEngineering (R0)