
Abstract
Through recycling textile waste, greenhouse gas emissions can drastically be reduced. Such textile recycling has become a lot easier with clothing retailers now starting to offer recycling checkpoints. Moreover, people today are often challenged by overloaded wardrobes and store many clothing items that they never use. In this paper, we describe an Internet of Things system that creates incentives for the users to recycle their clothes, benefiting the environmental sustainability. We propose a content-based recommendation approach that utilizes semantic web technologies and that leverages a set of context signals obtained from the system’s architecture, to recommend clothing items that might be relevant for the user to recycle. Experiments on a real-world dataset show that our proposed approach outperforms a baseline which does not utilize semantic web technologies.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
- Internet of Things
- Recommender systems
- Content-based recommendation
- Textile recycling
- Linked open data
- Bag of concepts
1 Introduction
In today’s world, overconsumption is becoming a huge concern. The equivalent for fast food called ‘fast fashion’ is becoming a phenomenon, and people continue to purchase large quantities of clothes. Because of this, textile recycling has become a pressing issue. Textile recycling has old history but was earlier often just concerned with the economic benefits. As of now, the environment has become the number one factor for doing textile recycling. For every pound of recycled textile, more greenhouse gas emissions are prevented than for every pound of glass, plastic, and paper—combined [1]. Moreover, Klepp and Laitala found that 20% of the clothes in Norwegians’ wardrobes were never or rarely used [2]. Because of this, clothing retailers are now starting to offer checkpoints where people can recycle their clothes in order to enhance the environmental sustainability.
It is important that people get incentives to use these recycling checkpoints. Such incentives can be generated by recommender systems and Internet of Things technology. Traditionally, recommender systems try to predict items that might be of interest to the users. A popular technique for recommender systems is known as content-based filtering [3]. Content-based recommendations build a user profile of item properties that the user has shown an interest of in the past and then computes item similarities with other items that the user has not seen yet. In previous studies, content-based recommender systems enabled with semantic web technologies have shown promising results by increasing the accuracy of the recommendations [4]. Linked Open Data (LOD) is a semantic web technology that forms a set of rules for publishing data so that the data become machine-readable and free of use for anyone [5].
In [6], we proposed a system called Connected Closet—a smart closet where clothing items enabled with radio-frequency identification (RFID) tags can be scanned in the user’s closet, tracking the usage history of the clothes. The system’s mobile application leverages data collected from the smart closet, to guide users in their everyday lives and making the users’ wardrobes explorable on a mobile device. In [7], we proposed a recommendation approach for recommending daily outfits to the users. In this paper, we propose a semantic content-based recommender system that leverages a set of context signals obtained from the system’s architecture to provide recycling suggestions to users of the system. By utilizing semantic web technology, the recommender system’s accuracy improves. Moreover, it can improve the system’s transparency and increase the user’s trust and confidence in the system.
Contributions. The main contributions of this paper may be summarized as follows:
-
1.
We propose a content-based recommender system that utilizes LOD to recommend clothing items to be recycled from a smart closet.
-
2.
We evaluate our proposed recommender system on a real-world dataset and compare it to a baseline that does not utilize semantic web technology.
The remainder of this paper is structured as follows. In Sect. 2, we describe the contextual models addressed when computing the recommendations. Then, we describe our recommendation algorithm in Sect. 3. In Sect. 4, we evaluate our proposed approach and discuss related work in Sect. 5. We conclude with a summary and discuss future work in Sect. 6.
2 Contextual Models
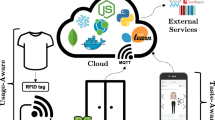
In this section, we describe the contextual signals obtained from the proposed system’s architecture depicted in Fig. 1. We describe how they are obtained and how they affect the recommendation algorithm for recycling recommendations.

Architecture for a sustainable wardrobe. The figure indicates where in the system the contextual signals are obtained from.
2.1 Usage-Aware
The user’s clothing items are enabled with RFID tags. These can be manually scanned through an RFID reader connected to a tiny computer embedded in the user’s Closet. The computer will broadcast a message containing information about the scan to a set of services deployed in the Cloud. Each scan is added to the set S.
Clothing items that are often checked out of the user’s closet will achieve a higher user rating. More formally, based on item usage, we calculate the user’s rating of a clothing item as follows:
where \(S_{u,i}\) is the set of all scans of clothing item i done by user u.
2.2 Taste-Aware
In the Mobile Application, the user can save his favorite outfits. An outfit is represented as a tuple (one top and one bottom). The user’s favorite outfits are added to the set \(O_u\). Items that occur in many outfit combinations will achieve a high rating. More formally, the user rating based on the user’s favorite outfits is defined as follows:
2.3 Season-Aware
The usage pattern of some items might only occur during a season, e.g., a winter coat will only be used in the winter. Such seasonal clothing items are assigned to a season \(\{\text {winter} | \text {spring} | \text {summer} | \text {fall}\}\). If a seasonal clothing item is recommended for recycling, we check if the item was used during the last assigned season. This is done by looking up the latest item scans in S. If the item was used during the season, the item is removed from the recommended list and not displayed to the user.
3 Semantic Content-Based Recommender System
In [6], we proposed a model for recycling recommendations that recommended the lowest rated items. Although, considering how the ratings are obtained from the context signals, newly bought clothing items would always be recommended for recycling when using such a model. In this paper, we propose a content-based recommender system that recommends the items that are as least similar as possible to the user profile.
3.1 Vector Space Model
In our recommendation approach, we adopt the Vector Space Model, where we represent each clothing items as a vector. We then use the Bag of Concepts [14] approach to create the vectors using entities from Wikidata Footnote 1, which is a Knowledge Base published as LOD. As a weighting scheme, the Concept Frequency (CF) is used. Here, the term concept refers to the Wikidata entities.
The user profile is represented as a set of clothing item vectors:
where \(\hat{r}(u,i)\) is an aggregate of \(\hat{r}_{\mu }(u,i)\) and \(\hat{r}_{\tau }(u,i)\), and \(\mathbf{i}\) is the CF vector representing clothing item i.
The user’s clothing items are then sorted ascending in a ranked list using this scoring function:
where \(dist(\mathbf{i},\mathbf{j})\) is a distance measure between the vectors representing the clothing items i and j. In our approach we use the Euclidean distance defined as follows:
where \(\mathbf {q}\) and \(\mathbf {p}\) are both vectors of n dimensions.
3.2 Semantic Item Representation
Figure 2 shows an excerpt of the services deployed in the Cloud. When new clothing items are fed into the system, they are inputted with a free text description to the Catalog service. To represent the clothing items as vectors using Wikidata entities with CF, the following process is performed on the item’s text description (the location of where in the system each step is performed is depicted in Fig. 2):
-
(1)
Entity extraction. We extract Wikidata entities by using the TextRazor API Footnote 2. For disambiguating entities, each entity is ranked with a confidence score based on multiple signals in the text.
-
(2)
Weighting. We generate vectors using the CF weighting scheme from the entities returned by Step 1.
-
(3)
Storing. The vectors are then stored in the system’s graph database called Item storage.
In the system’s current stage, removal of stop entities and generic entities, is not addressed and will be included in the process in future research.

Excerpt of the system’s services deployed in the Cloud. An illustration of the process of a new item being stored in the system.
4 Experiments
To demonstrate the validity of our approach, we perform an evaluation on a dataset collected from the Web.
4.1 Dataset
In order to evaluate our approach, we desired a dataset consisting of users with outfit ratings, the user’s usage history on clothing items, and information on which clothing items that have been recycled. Because our system is not yet in full scale production and there seems to be little available data in this domain, we could only obtain a dataset addressing outfit ratings.
The dataset was collected from the social media site PolyvoreFootnote 3. Polyvore is a site where users can create fashion outfits. Other people can rate these outfits using a ‘like’ button on a unary rating scale. This mirrors the functionality found in the smart closet’s mobile app. The collected dataset consists of 260 rated outfits composed by 158 clothing items, 7093 users and 19287 outfit ratings.
Figure 3 shows an example from one of the items in the collected dataset. The top shows the representation of the item using the classic Bag of Words approach with a Term Frequency (TF) vector. Below, is the representation of the item after it has gone through the process described in Sect. 3.2. The blue node (item) represent the clothing item, while the green nodes (labels starting with‘Q’) represent the Wikidata entities describing the clothing item. To visualize the context signals, we have included one user’s interactions with the item. In the figure, \(\hat{r}_{\mu }(u,i)\) (USAGE_COUNT) and \(\hat{r}_{\tau }(u,i)\) (OUTFIT_LIKES) are represented as relations from the user node to the item node.

Representation of a sample item. Text description: “Miu Miu’s vibrant Resort ’17 collection is inspired by the ’90s rave scene. Knitted in a kaleidoscope of hues, this cropped sweater has sumptuous touches of wool, mohair and [...] Dry clean.. Made in Italy..”. Given this description, the Wikidata entities such as Q42329 (wool), Q232191 (sweater), and Q552230 (Miu Miu) are extracted.
4.2 Evaluation Method
Due to the nature of the dataset, we can only consider the ratings obtained by the Taste-Aware context signal. For this reason, the other signals are neglected in this experiment. Moreover, the dataset does not contain clothing items that have been recycled by the users. This means that we need to make an assumption for when a clothing item is relevant for recycling. In this experiment, a clothing item that is relevant for recycling is a clothing item that occurs only once in the user’s favorite outfits, i.e., \(\hat{r}_{\tau }(u,i) = 1\).
Evaluation protocol. We evaluate all the users in the dataset that has at least one item i such that \(\hat{r}_{\tau }(u,i) > 3\). Moreover, we set \(\lambda = 2\) in Eq. 3. We then assume that the user only owns items that occurs at least once in his favorite outfits, i.e., \(\hat{r}_{\tau }(u,i) > 0\). For these items, we generate a recommended list to the users using Eq. 4.
Evaluation metrics. To assess the quality of the recommendations we apply the traditional evaluation metrics Recall and Precision defined as follows:
where tp is the number of correctly recommended relevant items, fn is the number of wrongly recommended relevant items, and fp is the number of wrongly recommended non-relevant items. We report Recall@N and Precision@N which is the Recall and Precision in a ranked list just considering the first N items.
Baseline method. As a baseline, we use the classic Bag of Words approach and represent the free text descriptions of the clothing items as TF vectors as opposed to CF in our proposed approach.
4.3 Results
We report the results in Fig. 4. For the evaluation metrics, we focused on \(\text {N} = 5\), since our system will display 5 recycling recommendations to the user. From the figure, we note that our proposed approach using the CF weighting scheme outperforms the baseline in both categories.

Experiment results of Recall@5 and Precision@5 for the baseline (TF) and our proposed approach (CF). The reported results are the average of Recall@5 and Precision@5 for each user evaluated in the experiment.
5 Related Work
Smart closets. Previous works [8, 9] have proposed similar architectures with RFID-enabled clothing items that is leveraged to generate outfit recommendations. Some other earlier works [10, 11] are also leveraging RFID technology—as shown in this paper, but the applications in these works are limited to inventory overview. In this paper, we mainly focus on leveraging our proposed architecture to recommend textile recycling suggestions.
Recommendation approach. In recent years, LOD in recommender systems has been frequently researched and various applications have been proposed [4, 12]. The most common application is to calculate semantic similarity of items based on the item’s relationships found in datasets published as LOD. Using concepts from a LOD Knowledge Base to model the user profile have shown promising results in past work, e.g., [13]. Many of these past works use DBpedia Footnote 4 as a LOD Knowledge Base and focus on recommendation in the traditional domains where large datasets are available, such as movies, music, and books.
Our recommender system addresses a relatively unexplored domain and exploits a LOD Knowledge Base lacking previous research. To the best of our knowledge, recommending items that are no longer of interest to the user is a quite recent idea. Moreover, with the proposed approach built into the architecture of the Internet of Things wardrobe, this paper’s proposed recommender system in the fashion domain is the first of its kind.
6 Discussion
CF vs. TF. In the following, we highlight the advantages our proposed CF approach has over the TF baseline. These highlights should give an idea of why the CF outperforms TF. A drawback of Bag of Words is that it considers all words in the text descriptions as equally important. To use the item in Fig. 3 as an example, it represents the item as an item containing the word ’miu’ two times, when—in fact—‘Miu Miu’ is the brand of the item and is of vital importance to the representation of the item. For clothing items with brand names of common terms, such as ’Jean Shop’, the Bag of Words approach is in deep trouble. In advantage, the Bag of Concepts approach is able to extract the ‘Miu Miu’ entity (Q552230) and able to capture the semantic context of the item. Moreover, the Bag of Words approach will describe the item using words such as ’clean’, which does not characterize the item in any way.
Textile recycling recommendations. By recycling textile waste, benefits can be seen in the environmental, the economical, and the social sustainability. With today’s recommender systems already making a huge impact on people’s pre-purchase behaviour, it is evident that they also can affect people’s post-purchase behaviour. A system architecture and a recommender system as described in this paper, is a good candidate to affect people’s post-purchase behaviour for the social good, by recommending clothes that the system’s users can remove from their wardrobes.
7 Conclusion and Future Work
In this paper, we describe an Internet of Things wardrobe enabled with a proposed semantic content-based recommendation approach to recommend clothing items for recycling. We describe a set of context signals obtained from the wardrobe’s architecture and how they affect the recommended list displayed to the user. Evaluation of our approach shows that our approach outperforms a baseline in terms of accuracy. Moreover, previous research has shown that LOD can increase recommender system’s transparency and increase the user’s trust in the system by computing convincing explanations to the recommendations [15]. The proposed approach facilitates opportunities for this and is planned for later research. Hence, the approach poses as a promising fit for the system.
Future work will also be devoted to improving the recommendation approach with a Concept Frequency - Inverse Document Frequency weighting scheme, and to develop further steps in system for the users to act on the recommendations.
References
Chavan, R.B.: Environmental sustainability through textile recycling. J. Text. Sci. Eng. 1–6 (2014). https://www.omicsonline.org/special-issues/textile-recycling-its-applications.html
Klepp, I.G., Laitala, K.: Clothing consumption in Norway. Technical report, Consumption Research Norway (SIFO), in Norwegian (2016)
Lops, P., Gemmis, M.D., Semeraro, G.: Content-based recommender systems: state of the art and trends. In: Ricci, F., Rokach, L., Shapira, B., Kantor, P. (eds.) Recommender Systems Handbook, pp. 73–105. Springer, Boston (2011). https://doi.org/10.1007/978-0-387-85820-3_3
Noia, T.D., Mirizzi, R., Ostuni, V.C., Romito, D., Zanker, M.: Linked open data to support content-based recommender systems. In: Proceedings of the 8th International Conference on Semantic Systems, I-SEMANTICS 2012, pp. 1–8. ACM, New York (2012)
Bizer, C., Heath, T., Berners-Lee, T.: Linked data-the story so far. Int. J. Semantic Web Inf. Syst. (IJSWIS) 5(3), 1–22 (2009)
Kolstad, A., Özgöbek, Ö., Gulla, J.A., Litlehamar, S.: Connected closet - a semantically enriched mobile recommender system for smart closets. In: Proceedings of the 13th International Conference on Web Information Systems and Technologies, WEBIST 2017, Porto, Portugal, pp. 298–305 (2017)
Kolstad, A., Özgöbek, Ö., Gulla, J.A., Litlehamar, S.: Rethinking conventional collaborative filtering for recommending daily fashion outfits. In: Proceedings of RecSysKTL Workshop @ ACM RecSys 17, RecSysKTL 2017, Como, Italy, pp. 22–29 (2017)
Goh, K.N., Chen, Y.Y., Lin, E.S.: Developing a smart wardrobe system. In: 2011 IEEE Consumer Communications and Networking Conference (CCNC), pp. 303–307, January 2011
Yu-Chu, L., Kawakita, Y., Suzuki, E., Ichikawa, H.: Personalized clothing-recommendation system based on a modified bayesian network. In: 2012 IEEE/IPSJ 12th International Symposium on Applications and the Internet, pp. 414–417, July 2012
Toney, A.P., Thomas, B.H., Marais, W.: Managing smart garments. In: 2006 10th IEEE International Symposium on Wearable Computers, pp. 91–94, October 2006
Ling, S., Indrawan, M., Loke, S.W.: RFID-based user profiling of fashion preferences: blueprint for a smart wardrobe. Int. J. Internet Protoc. Technol. 2(3/4), 153–164 (2007)
Figueroa, C., Vagliano, I., Rocha, O.R., Morisio, M.: A systematic literature review of linked data-based recommender systems. Concurr. Comput.: Pract. Exp. 27(17), 4659–4684 (2015)
Piao, G., Breslin, J.G.: Exploring dynamics and semantics of user interests for user modeling on Twitter for link recommendations. In: Proceedings of the 12th International Conference on Semantic Systems, SEMANTiCS 2016, pp. 81–88. ACM, New York (2016)
Sahlgren, M., Cöster, R.: Using bag-of-concepts to improve the performance of support vector machines in text categorization. In: Proceedings of the 20th International Conference on Computational Linguistics, COLING 2004, Stroudsburg, PA, USA. Association for Computational Linguistics (2004)
Musto, C., Narducci, F., Lops, P., Gemmis, M.D., Semeraro, G.: ExpLOD: a framework for explaining recommendations based on the linked open data cloud. In: Proceedings of the 10th ACM Conference on Recommender Systems, RecSys 2016, pp. 151–154. ACM, New York (2016)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 ICST Institute for Computer Sciences, Social Informatics and Telecommunications Engineering
About this paper

Cite this paper
Kolstad, A., Özgöbek, Ö., Gulla, J.A., Litlehamar, S. (2018). Context-Aware Recommendations for Sustainable Wardrobes. In: Guidi, B., Ricci, L., Calafate, C., Gaggi, O., Marquez-Barja, J. (eds) Smart Objects and Technologies for Social Good. GOODTECHS 2017. Lecture Notes of the Institute for Computer Sciences, Social Informatics and Telecommunications Engineering, vol 233. Springer, Cham. https://doi.org/10.1007/978-3-319-76111-4_6
Download citation
DOI: https://doi.org/10.1007/978-3-319-76111-4_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-76110-7
Online ISBN: 978-3-319-76111-4
eBook Packages: Computer ScienceComputer Science (R0)