
Abstract
Spectral graph wavelets introduce a notion of scale in networks, and are thus used to obtain a local view of the network from each node. By carefully constructing a wavelet filter function for these wavelets, a multi-scale community detection method for monoplex networks has already been developed. This construction takes advantage of the partitioning properties of the network Laplacian. In this paper we elaborate on a novel method which uses spectral graph wavelets to detect multi-scale communities in temporal networks. To do this we extend the definition of spectral graph wavelets to temporal networks by adopting a multilayer framework. We use arguments from Perturbation Theory to investigate the spectral properties of the supra-Laplacian matrix for clustering purposes in temporal networks. Using these properties, we construct a new wavelet filter function, which attenuates the influence of uninformative eigenvalues and centres the filter around eigenvalues which contain information on the coarsest description of prevalent community structures over time. We use the spectral graph wavelets as feature vectors in a connectivity-constrained clustering procedure to detect multi-scale communities at different scales, and refer to this method as Temporal Multi-Scale Community Detection (TMSCD). We validate the performance of TMSCD and a competing methodology on various benchmarks. The advantage of TMSCD is the automated selection of relevant scales at which communities should be sought.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
Networks are used to model complex relationships in a wide range of real-life applications throughout the social, biological, physical, information technology and engineering sciences. Due to limitations in data collection and storage, mainly static (monoplex) networks have been studied. However, many real-world systems have relationships between entities that evolve over time [15]. Technological advances have increased the amount of recorded temporal information. As a result, the sequence of networks describing changes occurring over time have been formalized as temporal networks (also known as time-varying or time-stamped) [15]. Examples of temporal networks include the functional brain networks [2, 5], social media interactions [36], financial markets [1] or politics [22].
One aspect of temporal network analysis is the discovery of community structures, which are groups of nodes that are more densely connected to each other than they are to the rest of the network [26]. Changes in the configuration of communities over time signals important turns in the evolution of the system. Real data networks are often observed to have communities with a hierarchical structure referred to as multi-scale communities [29]. Changes in the community structure over time might take place either at one scale or across all scales of the community structure. For this reason, there is interest in methods that are able to investigate communities at different “scales” over time [25, 26, 35].
Some recent approaches to community detection in temporal networks rely on a simple network aggregation procedure whereby all time networks are first collapsed into a single network. Afterward traditional algorithms for community detection can be used [34]. These methods, however, ignore valuable information about the evolution of the community structures over time. Other methods investigate each time network individually [1, 11, 17, 22], thus ignoring the dependence of community structures between neighbouring time points.
There exist methods that extend algorithms from one to multiple networks by using the multilayer formulation of a temporal network [18]. This special data structure allows inter-layer couplings between neighbouring time networks [18, 25]. One method, which is extended in this way, is the modularity maximization [26]. The modularity of a network is defined as the number of connections within a community compared to the expected number of such connections in an equivalent random network. The generalisation of the modularity maximization introduced in [25] overcomes the obstacles mentioned earlier by using the multilayer formulation. In this way it introduces a dependence between communities identified in one layer and connectivity patterns in other layers.
Modularity maximization is controlled by a resolution parameter \(\gamma \), determining the size of the detected communities and supporting the detection of multi-scale communities. However, the range of parameter values must be manually selected. The importance of relevant scales is assessed using stability procedures, which compare the detected communities to those obtained from random networks [28, 30]. When dealing with real life data, communities at one or more scales can go undetected if appropriate parameter values are not selected. The modularity maximization has also been used to investigate the effect of constant inter-layer weights between consecutive time layers [3] on the behavior of community detection.
Other approaches to multi-scale community mining in monoplex networks have been proposed to address some of the issues experienced by the modularity maximization. The method in [35] relies on spectral graph wavelets [14] and introduces a notion of scale in the network. These wavelets are thus used to obtain a local view of the network from each node. The clustering properties of the spectrum of the Laplacian in clustering [4, 12, 21] are used to construct a wavelet filter function which enables the spectral graph wavelets [14] to be sensitive to multi-scale communities. Contrary to the modularity maximization, this method is able to automatically select the range of scales to be investigated for existing communities. For a better understanding of the current paper we suggest the reader gets acquainted with articles [14, 35].
In this paper we extend spectral graph wavelets to temporal networks. For this extension we use the supra-Laplacian of the temporal network, which is defined as the Laplacian of the matrix representation of its multilayer formulation. A challenge we face here is the need to take into account the fundamental difference between within-layer and inter-layer edges when studying the spectral properties of the supra-Laplacian [9, 18, 33]. Although some studies explain the effect of different inter-layer weights over the eigenvalues of the supra-Laplacian [24, 31], there is no work related to the interpretation of the eigenvectors of the supra-Laplacian for clustering purposes.
Using Perturbation theory [6, 32], we argue that the eigenvectors corresponding to the smallest eigenvalues of the supra-Laplacian are a linear combination of the eigenvectors – corresponding to all zero eigenvalues – of the Laplacian matrices of the separate time layers. From spectral graph theory [7], it is known that an eigenvector corresponding to the zero eigenvalue of the Laplacian matrix is not informative of the community structure. For this reason, the eigenvectors of the supra-Laplacian matrix, which can be obtained as approximations to these eigenvectors, cannot be used to identify communities within the time layers, and larger eigenvalues should be sought. Using the above arguments as a stepping stone, we propose a novel Temporal Multi-Scale Community Detection (TMSCD) method, which extends the notion of spectral graph wavelets to temporal networks and automatically selects relevant scales at which multi-scale community partitions are obtained. The method uses the relevance of a newly identified eigenvalue of the supra-Laplacian, which captures the coarse description of communities prevalent over time.
In what follows, we first define the notation used throughout this paper in Sect. 2. Section 3 describes the method for multi-scale community detection in temporal networks which uses the spectral properties of the supra-Laplacian to identify relevant scale. In Sect. 4 we compare the performance of TMSCD to the modularity maximization [25]. Section 5 concludes this paper.
2 Notation
Let \(G=(V,A)\) be an N-node network where V is the set of nodes and \(A\in \mathbb {R} ^{N\times N}\) is the adjacency matrix with edge weights between pairs of nodes \(\left\{ A_{ij}|i,j\in \left\{ 1,2,...,N\right\} \right\} \). We only consider undirected, adjacency matrices (\(A_{ij}=A_{ji}\) for all i and j). The degree of a node i is \(d_{i}={\sum _{j=1}^{N}}A_{ij}\), and the degree matrix D has \(d_{1},d_{2},...,d_{N}\) on its main diagonal. Network G is associated with the normalized Laplacian matrix \(L=D^{-\frac{1}{2}}\left( D-A\right) D^{-\frac{1}{2}}\).
The networks representing different time points in the temporal network are known as layers. We use the notation \(G^{t}=\left( V,A^{t}\right) \) for layer t in the temporal network \(\mathcal {T}=\left\{ G^{1},G^{2},...,G^{T}\right\} \), which is the ordered sequence of networks for \(t\in \left\{ 1,2,...,T \right\} \) time points, and we denote node i in layer t by \(i_{t}\). We work with temporal network in which each node is present in all layers. The multilayer framework of a temporal network considers a diagonal ordinal coupling of layers [2, 18, 25]. In essence, inter-layer weights exist only between corresponding nodes in neighboring time layers. We denote the inter-layer edge weight for node i between consecutive layers t and \(t+1\) by \(\omega _{i}^{t,t+1}\in \mathbb {R}\). Else \(\omega _{i}^{t,p}=0\) for \(p\ne t-1,t+1\).
This temporal network \(\mathcal {T}\) has an associated adjacency matrix \(\mathcal {A}\) of size \(NT\times NT\) – the supra-Adjacency matrix. The time-dependent diagonal blocks of \(\mathcal {A}\), \(\mathcal {A}_{t,t}\), are the adjacency matrices \(A^{t}\), and the off-diagonal blocks, \(\mathcal {A}_{t,t+1}\), are the inter-layer weight matrices \(W^{t,t+1}=diag(\omega _{1}^{t,t+1},\omega _{2} ^{t,t+1},...,\omega _{N}^{t,t+1})\). Else \(\mathcal {A}_{t,p}\) is a \(N\times N\) zero matrix for \(p\ne t-1,t+1\).
The within-layer degree of node i in layer \(G^{t}\) is \(d_{i}^{t}:={\sum _{j=1}^{N}}A_{ij}^{t}\) while the multilayer node degree of node i in layer \(G^{t}\) is \(\mathfrak {d}_{i}^{t}:=d_{i}^{t}+\omega _{i}^{t,t-1}+\omega _{i}^{t,t+1}\). These define the degree matrix \(\mathcal {D}\) with diagonal entries \(\mathcal {D}:=diag\left( \mathfrak {d}_{1}^{1},\mathfrak {d}_{2}^{1} ,...,\mathfrak {d}_{N}^{1},\mathfrak {d}_{1}^{2},...,\mathfrak {d}_{N} ^{2},...,\mathfrak {d}_{N}^{T}\right) \). The normalized supra-Laplacian \(\mathcal {L}\) is computed as \(\mathcal {L}\,\mathfrak {=}\,\mathcal {D}^{-\frac{1}{2}}\left( \mathcal {D-A}\right) \mathcal {D}^{-\frac{1}{2}}\).
3 Temporal Multi-scale Community Detection (TMSCD)
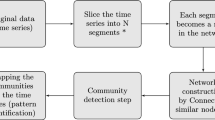
The proposed TMSCD method is a multilayer extension of the multi-scale community detection procedure via spectral graph wavelets developed in [35]. The advantage of this method is the automated selection of relevant scales at which community partitions are obtained. In Sect. 3.1 we define new inter-layer weights at each node adapted for community detection in temporal networks. In Sect. 3.2 we extend the definition of a wavelet at a node (in a monoplex network) to that for a wavelet at a node at a particular time layer. By construction, a wavelet associated to a node at a time layer is local in the whole temporal network. The wavelet is centred around this node and spreads on its neighbourhood, which consists of its neighbours in the current layer and the corresponding nodes in the neighbouring time layers. The larger the scale is, the larger the spanned neighbourhood is – more nodes in current layer and more nodes in neighbouring layers.
The most central part of our method is the construction of the wavelet filter function g. In Sect. 3.3 we use arguments from Perturbation theory to investigate the spectral properties of the supra-Laplacian matrix for community detection purposes, and propose a procedure for the selection of appropriate eigenvalues around which to center the wavelet filter function. In Sect. 3.4, we introduce the wavelet filter function based on a B-spline, we choose the parameters of this function, and define relevant scales for community investigation.
Finally, in Sect. 3.5 for any given scale, we use the wavelet of a node at a given time layer to cluster together nodes whose associated wavelets are correlated using an agglomerative connectivity-constrained clustering procedure which respects the time sequence of the temporal network.
3.1 Inter-layer Couplings \(\omega _{i}^{t,t+1}\) for Community Detection
The choice of inter-layer weights \(\omega _{i}^{t,t+1}\) is important - they control the ordinal coupling between time layers t and \(t+1\) via the node i. We believe that inter-layer couplings should be strong enough to indicate similarity of a node’s neighbourhood in two consecutive networks and indicate shared community structures over time. The main principle is, inter-layer weights should be strong enough to reflect on local topological similarity of nodes across layers, but they should not interfere with the within-layer structure.
Let the set of neighbours of node i in layer \(G^t\) be denoted by \(\mathcal {N}_{i}^{t}:=\{j_{t}:A_{ij}^{t}=1\}.\)
We introduce the inter-layer weight \(\omega _{i\ }^{t,t+1}\) as follows:
We refer to these inter-layer weights as LART-type since they were the basic ingredients of the LART algorithm [19]. The LART algorithm is a method for the detection of communities that are shared by either some or all the layers in a multilayer network. The algorithm is based on a random walk and the transition probabilities defining the random walk are allowed to depend on the local topological similarity between layers at any given node.
It can be derived that \(\omega _{i}^{t,t+1}\le \frac{\min \left( d_{i}^{t},d_{i}^{t+1}\right) }{2}\). From this follows that the multilayer node degree of \(i_{t}\) is \(\mathfrak {d}_{i}^{t}\le 2d_{i}^{t}\). Thus at least half of the influence, which node \(i_{t}\) has over the properties of \(\mathcal {A}\) and therefore \(\mathcal {L},\) comes from the connections of node i within layer t, rather than from the inter-layer weights \(\omega _{i}^{t,t-1}\) and \(\omega _{i}^{t,t+1}\).
3.2 Construction of Spectral Graph Wavelets for Temporal Networks
Upon obtaining matrices \(\mathcal {A}\) and \(\mathcal {L}\), we construct the spectral graph wavelet transform and the corresponding wavelet basis using the spectral decomposition of \(\mathcal {L}\) as in [14, 35]. Let \(\varLambda =\left\{ \lambda _{j}\right\} _{j=1}^{NT}\) be the vector of eigenvalues of the supra-Laplacian \(\mathcal {L}\) satisfying \(\lambda _{1}\le \lambda _{2}\le \cdot \cdot \cdot \le \lambda _{NT}.\) Let \(\chi =\left[ \chi _{1}|\chi _{2}|...|\chi _{NT}\right] \) be the \(NT\times NT\) matrix of column eigenvectors which correspond to those eigenvalues.
Denote by \(\psi _{s,i}^{t}\) the wavelet at scale \(s\in \mathbb {R}^{+}\) centred around node \(i\in V\) at time layer t. The wavelets are generated by stretching a unique wavelet filter function \(g\left( \varvec{\cdot }\right) \) by a scale parameters \(s>0\) in the network Fourier domain. The matrix representation of the stretched filter is
that is diagonal on the Fourier modes (the NT eigenvectors of \(\mathcal {L} \)). Hence the wavelet basis at scale s reads as
where \(\psi _{s,i}^{t}\) is the wavelet at scale s centred around node i at the time point t. For a wavelet at scale s centered around node i at time point t, we have the relation \(\psi _{s,i}^{t}=\chi \mathcal {G}_{s}\chi ^{\top }\delta _{i,t}\), which is a column vector of size NT. Its value at each node j at time point p is given by \(\psi _{s,i}^{t}(j,p)\).
3.3 Spectral Properties of the Supra-Laplacian Matrix for Community Detection Purposes
In our context, we interpret each \(G^{t}\) as disconnected components and the inter-layer weights as small perturbations. The resulting diagonal blocks of the supra-Laplacian, \(\mathcal {L}_{t,t}\), are then perturbed versions of the corresponding Laplacian \(L^{t}\). We use Davis-Kahan theorem from matrix Perturbation theory (p. 246 in [32] and p. 212 in [6]) discussed in [21] to justify the choice of an eigenvalue around which to center the wavelet filter function. According to the Davis-Kahan theorem, some of the first T perturbed eigenvectors of \(\mathcal {L}\) are very close to the linear space generated by the vectors \(v_{0}^{t}\mathbbm {1}_{G^{t}}\). Here \(v_{0}^{t}\) is the eigenvector corresponding to eigenvalue 0 of matrix \(L^{t}\), while \(\mathbbm {1}_{G^{t}}\) is the NT zero-padded indicator vector, which has entries 1 at the node positions of layer \(G^t\).
From spectral graph theory [7] it follows that the eigenvector \(v_{0}^{t}\) corresponding to the 0 eigenvalue of the normalized Laplacian matrix \(L^{t}\) (of the undirected connected network \(G^t\)) is not informative of the community structure, since it is equal to the squared node degrees, \(D_{t}^{\frac{1}{2}}\). It follows that in the spectrum of the supra-Laplacian there exists a set of small eigenvalues \(\lambda \), whose corresponding eigenvectors are uninformative for the community structure within the layers.
These eigenvalues and their corresponding eigenvectors can only be used to identify each time layer \(G^{t}\) as a separate layer. In fact, the smallest non-zero eigenvalue \(\lambda \), whose eigenvector is not spanned by the set of eigenvectors \(v_{0}^{t}\), is sensitive to within-layer connectivity patterns since it may appear as perturbation of the separate layers’ Fiedler vectors used for clustering [7]. We center our wavelet filter function around this eigenvalue, denoted by \(\lambda ^{*}\), since \(\lambda ^{*}\) is carrier of the coarse description of communities within time layers. We also use \(\lambda ^{*}\) to automatically determine the range of scales s, for which relevant communities can be discovered.
Denote by \(\overline{\varLambda }\) the set of smallest eigenvalues whose eigenvectors are well-approximated by the subspace of eigenvectors \(v_{0}^{t}\). According to the Davis-Kahan theorem, the eigenvectors v corresponding to \(\lambda \in \overline{\varLambda }\) satisfy
for a small \(\varepsilon >0\). For the rest of the eigenvalues, the left hand side of this inequality is much larger than \(\varepsilon .\) Then eigenvalue \(\lambda ^{*}\) is the first eigenvalue which is a perturbation of the Fiedler vectors of the separate time layers, i.e. we have the equality
In practice, we discover the position of the eigenvalue \(\lambda ^{*}\) by solving a series of regression problems: for each of the ordered eigenvectors of the supra-Laplacian \(v_{\tau }=\chi _{\tau }\) (\(\tau =1,2,...,NT\)), we fit the multivariate regression \(v_{\tau }=\sum _{t=1}^{T}\beta _{t}\alpha _{t}v_{0}^{t}+\varepsilon _{\tau }\). We select \(\lambda ^{*}\) at the \(\tau \) position for which \(\left\| \varepsilon _{\tau }\right\| >0.8\), where this bound was empirically selected. Since \(\lambda ^{*}\le \lambda _{T+1}\), we have to solve at most \(T+1\) regression problems in order to find the position of \(\lambda ^{*}.\)
3.4 Graph Wavelet Filter g via B-Splines and Parameter Selection
We propose a new wavelet filter function g modeled as a cubic \(B-\)spline [8] with appropriately chosen knots. This function is not only smooth but also has a compact support. Namely, we put
where for the knots of the cubic \(B-\)spline \(B_{3}\) we have
and the function g is zero out of the interval \(\left[ 0,y_{4}\right] \). By the properties of \(B-\)splines, \(B_{3}>0\) for \(y\in \left( 0,y_{4}\right) \). As indicated, this spline function has a double knot at \(y_{2}=y_{3}.\) Function g inherits the basic properties of B-splines [8], including good properties of the Fourier coefficients of g since g(y) may be extended for \(y<0\) and \(y>y_{4}\) periodically to belong to \(C^{1}\), which is important for the invertibility of the Fourier wavelet transforms. Other functions can further be pursued depending on the application at hand, and possible options have been reviewed in [20].
In the following we describe how to choose parameters \(y_{1},\) \(y_{2}=y_{3},\) and \(y_{4}\) of the wavelet filter function g, and the range of scales s relevant for multi-scale communities within and across layers of the temporal network. Some of the arguments we make are the same as in [14, 35]. However, we adapt these to the nature of g and the aim of centering it around an appropriate eigenvalue.
First, the maximum scale \(s_{\max }\) is set so that the filter function \(g\left( s_{\max }y\right) \) starts decaying as a power law only after \(y=\lambda ^{*}\), hence \(\lambda ^{*}s_{\max }=y_{2}=y_{3}.\) Second, we need to keep a part of the corresponding eigenvector \(\chi _{\lambda ^{*}}\) in the wavelets of every scale, so that all wavelets are sensitive to the large scale community structure within each time point. We propose as minimum scale \(s_{\min }\) the one for which \(g\left( s_{\min }\lambda ^{*}\right) \) becomes smaller than 1. Therefore, \(s_{\min }\lambda ^{*}=y_{1}.\) We also impose that \(g\left( s_{\min }\varvec{\cdot }\right) \) spans at least the whole range of eigenvalues between 0 and 1 which implies \(s_{\min }\times 1=y_{2}.\)
We require that the filter at the maximum scale be highly selective around \(\lambda ^{*}\). For this purpose all other eigenvalues and especially \(\lambda ^{q+1}\), where we have put \(\lambda ^{*}=\lambda ^{q}\), have to be attenuated. Choosing an attenuation by a factor 10, leads to \(g\left( s_{\max }\lambda ^{q}\right) =10\left( s_{\max }\lambda ^{q+1}\right) \). We thereby ensure that the filter at the maximum scale essentially keeps the information from \(\chi _{\lambda ^{*}}\).
This argumentation gives us spectrum adapted equations for \(s_{\min }\), \(s_{\max }\):
where we see that \(y_{1}\) has the unique effect of translating the scale boundaries \(s_{\min }\) and \(s_{\max }\) on the \( \mathbb {R} ^{+}\) axis. Therefore, \(y_{1}\) can be safely fixed to 1, i.e. \(y_{1}=1\). Finally, similar to the approach in [14, 35] we choose a logarithmically spaced sampling of M scales between the scale boundaries \(s_{\min }\) and \(s_{\max }\): \(S=\left\{ s_{1}=s_{\min ,}s_{2},...,s_{M}=s_{\max }\right\} \).

B-spline based filter function g for four different scales s. The actual eigenvalues \(\lambda \) are obtained from a temporal multi-scale benchmark whose communities at large scales change over time (discussed in Sect. 4). The temporal network has \(N=640\) nodes for each of the \(T=33\) time layers with Sales-Pardo parameters \(\rho =1\) and \(\bar{k}=16\). In (a) filter g is centred around \(\lambda _{2}\) as originally proposed in [35] for monoplex networks. In (b) the filter g is centred around \(\lambda ^{*}\), which is \(\lambda _{10}\) obtained as proposed in Sect. 3.3. In total 50 scales were obtained and the four visualized scales correspond to the \(7^{th},13^{th},25^{th}\) and \(47^{th}\) scale.
Rather than fixing the first parameter \(y_{2}\) of filter g around the second eigenvalue \(\lambda _{2}\) of the supra-Laplacian, we fix \(y_{2}\) centred around \(\lambda ^{*}\). Thus we attenuate the role of the eigenvalues \(\lambda _{j}\in \varLambda \) with \(\lambda _{j}<\lambda ^{*},\) since as we explained above the eigenvectors of these eigenvalues \(\lambda _{j}\) are not relevant for discovering community structures prevalent at each time point.
In Fig. 1 we visualize function g for a temporal network and compare the shape of g when it is centred around \(\lambda _{2}\) and around \(\lambda ^{*}\) – obtained as proposed. The eigenvalues were obtained from a multi-scale benchmark temporal network whose communities at large scales change over time.
3.5 Agglomerative Connectivity-Constrained Clustering and Detection of Stable Partitions
For small scales s, \(\psi _{s,i}^{t}\) is localized around the direct neighbours of i in layer t and to few nodes in neighbouring time layers. With an increasing scale s, \(\psi _{s,i}^{t}\) spreads to a larger neighbourhood which eventually becomes the whole multilayer network. Hence, we use \(\psi _{s,i}^{t}\) as a feature vector for \(i_{t}\) at scale s.
Similar to [35], we determine the distance \(D_{s}(i_{t},j_{p})\) between nodes \(i_{t}\) and \(j_{p}\) (\(i,j=1,2,3,...,N\); \(t,p=1,2,3,...,T\)) at scale s using the correlation distance between wavelets \(\psi _{s,i}^{t}\) and \(\psi _{s,j}^{p}\). We speed up computations of the full spectrum of \(\mathcal {L}\) and all \(D_{s}(i_{t},j_{p})\) using approximations proposed in [14, 35].
We cluster nodes into communities using distances \(D_{s}(i_{t},j_{p})\) and an agglomerative connectivity-constrained clustering procedure [19, 27] with “average” linkage. In this way we respect the time-ordered structure of the temporal network since nodes in the same time layer or nodes across neighbouring time layers are considered first for merging. We obtain the partition at scale s, \(P_{s}\), by cutting the resulting dendrogram at a height equal to the average of the maximal gaps of all the root-leaf paths of the dendrogram [35]. Repeating the above for all \(s\in S\), we obtain the multi-scale set of partitions \(\mathcal {P}=\left\{ P_{s}\right\} _{s\in S}\). We calculate the stability \(\gamma _{a}(s)\) of the partition at a given scale s using the approach outlined in [35].
4 Experimental Results
In this section we provide simulation experiments to measure the performance of the TMSCD method on two types of benchmarks for temporal networks in comparison to the performance of the modularity maximization (MM) method [25], for different resolution parameter values \(\gamma \) on the same set of benchmarks.
The first type of benchmark networks we use is a further contribution of the present work, since we identify three classes of temporal networks which may serve as benchmarks for multi-scale community detection on temporal networks. We construct these benchmarks as time-varying Sales-Pardo (SP) networks [29]. An SP has three scales of communities based on which the network is constructed using parameters \(\rho \) (quantifies how separated the three scales are) and \(\overline{k}\) (the average node degree that controls how dense the network is). For a given length of the temporal network T, we generate SP multi-scale community structures that merge and split over time. Based on these community structures, we simulate a time-ordered sequence of Sales-Pardo networks. The three classes are determined by the scale at which the change occurs: small scale (SSC), medium scale (MSC) or large scale (LSC) change over time. The second type of benchmarks, proposed in [13], have one “true” partition at each time point.
The performance of a given algorithm at a given scale (resolution) is measured as the maximum value of the adjusted rand index (ARI) [16] between the “true” partition of the benchmark and the partition P at this scale (resolution). Since the SP benchmarks have three true partitions corresponding to three different scales, we refer to the large (resp. medium, small) scale as LS (resp. MS, SS). We also investigate the performance of TMSCD and MM on benchmarks produced using different values of \(\rho \) and \(\overline{k}\).
For the TMSCD method, the instability \(1-\gamma _{a}\) at scale s is obtained as outlined in [35]. The smaller \(1-\gamma _{a}\), the more stable is the community partition for scale s. For the MM method, the instability for a resolution parameter \(\gamma \) is obtained as described in [10] and is measured by the normalized variation of information (VI) metric [23]. The smaller VI, the more stable is the community partition at resolution parameter \(\gamma \).
4.1 Comparative Results on Temporal Benchmark Networks with Multi-scale Community Structure
Discussion on Effect of Inter-layer Weights on the Performance of TMSCD and MM. First, we illustrate the performance of the TMSCD and MM method on an SSC network with \(T=21\) time layers, where \(\rho =1\), \(\bar{k}=16\), and \(N=640\) at each time point. For both methods, we use different fixed inter-layer weights \(\omega =0.5,1,2,5,10\) and the LART-type inter-layer weight \(\omega _{i}^{t,t+1}\) proposed in Sect. 3.1, which we refer to as \(\omega =LART\). For TMSCD, we set \(M=50\) scales \(s\in S\), and for MM we manually set 60 values of resolution parameters \(\gamma \) in the interval [0.05, 40] such that there are more values in the interval \(\left[ 0.05,1\right] \). For both methods we use 20 repetitions to obtain instability \(\gamma _{a}\left( s\right) \) at scale s and \(VI(\gamma )\) at each resolution \(\gamma \).
The results of TMSCD and MM on a realization of the SSC and the instabilities \(1-\gamma _{a}\) versus scale s (VI versus parameter \(\gamma \)) for different weights \(\omega \) are presented in Fig. 2. Results for realization of the MSC and LSC are omitted in this paper but the plots are similar and conclusions are identical.
Overall, the TMSCD recovers perfectly communities at all three scales and inter-layer weights \(\omega \) have almost no effect over the results. For small \(\omega \) (\(\omega =0.5,1,2\)) instability is high, but for \(\omega =LART\) and \(\omega =5,10\) the associated partitions of scales with low instability correspond to the true partitions. For large \(\omega \) (\(\omega =5,10\) and \(\omega =LART\)) a fourth stable scale appears at the smallest s. This is stable for \(\omega =5,10\) but unstable for \(\omega =LART\), which signifies the importance of carefully selected weights. MM recovers perfectly communities at LS and MS, but there is increased variability at recovering communities at SS for an increasing inter-layer weight \(\omega \). The instability of MM is not as sensitive as the one that is used for TMSCD.
To conclude, using \(\omega =LART\) inter-layer weights appears to provide us with low instability only at the true partitions. This includes a higher instability at the fourth scale which appears for larger \(\omega \) (\(\omega =10\)) - the partition at this scale is formed for N communities, and each community is formed by the set of nodes \(\left\{ i_{t}:t=1,2,...,T\right\} \). As discussed in Sect. 3.1, this phenomenon is a results of larger inter-layer weights, which affect more the properties of a node i at layer t than its within-layer connections which have an average node degree \(\bar{k}=16\). In contrast, the LART weights, in the range [0, 8], follow a bell-shaped distribution centred around 4. Thus they do not interfere with the within-layer connections and support the community detection process over time.
On the other hand, the instability procedure for MM is not as sensitive. In the case of real data it would be challenging to select parameters \(\gamma \) for which to investigate community partitions.

TMSCD (top) and MM (bottom) results for SSC multi-scale benchmark network. Each pair of plots corresponds to different inter-layer weights \(\omega \). First, we plot the results of TMSCD and MM on a realization of SSC. Each scale outputs a partition for all nodes across all time points. For each scale s, we plot the similarity with the small (SS) (medium (MS), large (LS)) theoretical scale, computed as the average over all time points including std.dev. error bars. We observe scales where the exact small (resp. medium, large) scale theoretical partition is uncovered. Second, for TMSCD we plot instability \(1-\gamma _{a}\) versus scale s; for MM we plot variation of information (VI) versus parameter \(\gamma \). The associated partitions of scales with low instability corresponding to the theoretical partitions.

Comparison between the LSR, MSR and SSR values obtained for the TMSCD and MM multi-scale community mining methods on (a) SSC, (b) MSC and (c) LSC temporal benchmark network for different parameters: left (resp. right) column for \(\rho =1\) (resp. \(\rho =2\)) and different values of \(\bar{k}\). We plot the average and the ± one standard deviation over the five best results for each of the 50 realizations of each type of network for each set of parameters.
Discussion on Overall Performance of TMSCD and MM. We compare TMSCD and MM for different sets of parameters \(\rho =1,2\) and \(\bar{k}=11,13,15,17,19,21\), where we set LART-type inter-layer weights. We compare the obtained communities to the ground truth for 50 realizations of the SSC (Fig. 3(a)), MSC (Fig. 3(b)) and LSC (Fig. 3(c)). For each combination \((\rho ,\bar{k})\), the large scale rate (LSR) (resp. medium (MSR) and small (SSR) scale rates) indicates the success rate of the communities found by TMSCD and MM being compared to the large (resp. medium, small) scale ground truth community structure. The success rate is the average over the top five adjusted rand index (ARI) values over all scales s or parameter values \(\gamma \).
For \(\rho =1\), both methods perform equally well in all three cases with almost full recovery of communities at all scales. In some cases, TMSCD has slight advantage of recovering MS and LS communities. For \(\rho =2\), the performance of both methods decreases for small \(\bar{k}\). Both methods perform equally well at recovering MS communities, but we can note that TMSCD performs better at recovering LS communities for larger \(\bar{k}\).
Overall TMSCD performs slightly better than MM and has much smaller deviation in the final results. In general, uncovering communities when \(\rho =2\) is harder since \(\rho \) controls how separated are the communities at the three scales. When \(\rho \) is larger, the separation of the communities is not as clear, so SS communities cannot be distinguished easily. Furthermore, we note that when \(\bar{k}\) is small nodes have fewer edges and it is difficult for both methods to uncover SS communities since they fade in the MS communities.
4.2 Comparative Results on Benchmarks with One True Partition
We compare the performance of TMSCD and MM on the Grow, Merge and Mixed benchmark networks proposed in [13], with default model parameters, and we set \(T=100\) and \(N=128\). We produce 100 realizations of each benchmark. Parameters of TMSCD and MM are set as in Sect. 4.1, where we use LART-type inter-layer weights. The success rate of each realization of a benchmark is the average over the top five adjusted rand index (ARI) values over all scales s or parameter values \(\gamma \). The results are summarized in Table 1.
Both methods perform equally well for the Grow model. In the Mixed model case, TMSCD has better performance with lower variability. In the Merge model case, TMSCD performs much better than MM but with larger variability in the results. The Merge model is challenging for both MM and TMSCD. This is caused by the nature of the communities: when two communities are separate they exist at a smaller scale, but when they merge they exist at a larger scale.
5 Discussion and Conclusion
The work in this paper is motivated by the need to develop new methods for multi-scale community detection in temporal networks with automatic selection of relevant scales. The modularity maximization [25] achieves excellent results at detecting such communities but it lacks the flexibility of automatically selecting resolution parameter ranges relevant to the prevalent community structures over time. We have used results from Perturbation theory to interpret inter-layer weights as perturbations between time layers, and thus we identify the set of eigenvectors of the supra-Laplacian that are perturbations of the separate layers’ Fiedler vectors. These can be used for detecting communities prevalent over time.
This result gives a completely new point of view on temporal networks. To design the TMSCD method, we reconsidered the role of the Fiedler vector in community detection for temporal networks. Indeed, the eigenvectors of \(\mathcal {L}\) (corresponding to the smallest eigenvalues) represent all time-layers as separate communities. Hence, we cannot use them for the detection of communities prevalent over time. We successfully attenuated the influence of these small eigenvalues in the process of community detection, by properly constructing the wavelet filter function g of the spectral graph wavelets. An important step in our algorithm was the identification of the uninformative small eigenvalues.
Using simulated data, we have demonstrated that TMSCD method performs equally well compared to the modularity maximization method [25]. There are two main advantages to using TMSCD. First, of utmost importance is the automatic selection of scales at which wavelets should be obtained and which encompass all relevant within-layer and inter-layer communities. Second, the proposed LART-type inter-layer weights \(\omega _{i}^{t,t+1}\) lead to the best results in terms of balance between uncovering multi-scale communities and the stability of those communities at the relevant scales. The stability procedure used by TMSCD is more sensitive than the modularity maximization one. This is an advantage when handling real life data sets where the true scales are not known and a reliable indicator for stable partitions is required. The supremacy of the LART-type inter-layer weights [19] over using fixed ones indicates the advantage of using adaptable inter-layer weights that reflect the similarity of nodes across layers.
Given the above results, TMSCD would be an ideal tool for applications to neuroscience and social network analysis.
References
Aynaud, T., Guillaume, J.L.: Static community detection algorithms for evolving networks. In: 2010 Proceedings of the 8th International Symposium on Modeling and Optimization in Mobile, Ad Hoc and Wireless Networks (WiOpt), pp. 513–519. IEEE (2010)
Bassett, D.S., Wymbs, N.F., Porter, M.A., Mucha, P.J., Carlson, J.M., Grafton, S.T.: Dynamic reconfiguration of human brain networks during learning. Proc. Natl. Acad. Sci. U. S. A. 108(18), 7641–7646 (2011)
Bazzi, M., Porter, M.A., Williams, S., McDonald, M., Fenn, D.J., Howison, S.D.: Community detection in temporal multilayer networks, and its application to correlation networks. Multiscale Model. Simul. 14(1), 1–41 (2014)
Bertrand, A., Moonen, M.: Seeing the bigger picture: how nodes can learn their place within a complex ad hoc network topology. IEEE Signal Process. Mag. 30(3), 71–82 (2013)
Betzel, R.F., Griffa, A., Avena-Koenigsberger, A., Goni, J., Thiran, J.P., Hagmann, P., Sporns, O.: Multi-scale community organization of the human structural connectome and its relationship with resting-state functional connectivity. Netw. Sci. 1(03), 353–373 (2014)
Bhatia, R.: Matrix Analysis. Graduate Texts in Mathematics, vol. 169. Springer, Heidelberg (1997). https://doi.org/10.1007/978-1-4612-0653-8
Chung, F.: Spectral Graph Theory. CBMS (1996)
De Boor, C.: A Practical Guide to Splines. Springer, Heidelberg (2001)
De Domenico, M., Solé-Ribalta, A., Cozzo, E., Kivelä, M., Moreno, Y., Porter, M.A., Gómez, S., Arenas, A.: Mathematical formulation of multilayer networks. Phys. Rev. X 3(4), 041022 (2013)
Delvenne, J.C., Yaliraki, S.N., Barahona, M.: Stability of graph communities across time scales. Proc. Natl. Acad. Sci. U. S. A. 107(29), 12755–12760 (2010)
Fenn, D.J., Porter, M.A., Mcdonald, M., Williams, S., Johnson, N.F., Jones, N.S.: Dynamic communities in multichannel data: an application to the foreign exchange market during the 2007-2008 credit crisis. Chaos 19, 033119 (2009)
Fortunato, S.: Community detection in graphs. Phys. Rep. 486(3–5), 75–174 (2010)
Granell, C., Darst, R.K., Arenas, A., Fortunato, S., Gómez, S.: Benchmark model to assess community structure in evolving networks. Phys. Rev. E. Stat. Nonlin. Soft Matter Phys. 92(1), 012805 (2015)
Hammond, D.K., Vandergheynst, P., Gribonval, R.: Wavelets on graphs via spectral graph theory. Appl. Comput. Harmon. Anal. 30(2), 129–150 (2011)
Holme, P., Saramäki, J.: Temporal networks. Phys. Rep. 519(3), 97–125 (2012)
Hubert, L., Arabie, P.: Comparing partitions. J. Classif. 2(1), 193–218 (1985)
Lee, J.D., Maggioni, M.: Multiscale analysis of time series of graphs. In: International Conference on Sampling Theory and Applications (2011)
Kivelä, M., Arenas, A., Barthelemy, M., Gleeson, J.P., Moreno, Y., Porter, M.A.: Multilayer networks. J. Complex Netw. 2(3), 203–271 (2014)
Kuncheva, Z., Montana, G.: Community detection in multiplex networks using locally adaptive random walks. In: Proceedings of the 2015 IEEE/ACM International Conference on Advances in Social Networks Analysis and Mining, ASONAM 2015, pp. 1308–1315. ACM Press, New York, August 2015
Leonardi, N., Van De Ville, D.: Tight wavelet frames on multislice graphs. IEEE Trans. Signal Process. 61(13), 3357–3367 (2013)
Luxburg, U.V.: A tutorial on spectral clustering. Technical report, Max Planck Institute (2007)
Macon, K.T., Mucha, P.J., Porter, M.A.: Community structure in the united nations general assembly. Phys. A Stat. Mech. Appl. 391(1), 343–361 (2012)
Meila, M.: Comparing clusterings - an information based distance. J. Multivar. Anal. 98(5), 873–895 (2007)
Moreno, Y., Arenas, A.: Diffusion dynamics on multiplex networks. Phys. Rev. Lett. 1–6 (2013)
Mucha, P.J., Richardson, T., Macon, K., Porter, M.A., Onnela, J.P.: Community structure in time-dependent, multiscale, and multiplex networks. Science 328, 876–878 (2010)
Newman, M.E.J.: Modularity and community structure in networks. Proc. Natl. Acad. Sci. U.S.A. 103(23), 8577–8582 (2006)
Pons, P., Latapy, M.: Computing communities in large networks using random walks. J. Graph Algorithms Appl. 10(2), 1910218 (2006)
Lambiotte, R.: Multi-scale modularity in complex networks. In: 2010 Proceedings of the 8th International Symposium on Modeling and Optimization in Mobile, Ad Hoc and Wireless Networks (WiOpt), pp. 546–553 (2010)
Sales-Pardo, M., Guimerà, R., Moreira, A.A., Amaral, L.A.N.: Extracting the hierarchical organization of complex systems. Proc. Natl. Acad. Sci. U.S.A. 104(39), 15224–15229 (2007)
Schaub, M.T., Delvenne, J.C., Yaliraki, S.N., Barahona, M.: Markov dynamics as a zooming lens for multiscale community detection: non clique-like communities and the field-of-view limit. PLoS ONE 7(2), e32210 (2012)
Sol, A., Domenico, M.D., Kouvaris, N.E.: Spectral properties of the Laplacian of multiplex networks. Phys. Rev. E 88(3), 032807 (2013)
Stewart, G.W., Sun, J.G.: Matrix Perturbation Theory. Academic Press, New York (1990)
Taylor, D., Myers, S.A., Clauset, A., Porter, M.A., Mucha, P.J.: Eigenvector-based centrality measures for temporal networks. arxiv Prepr., p. 34, July 2015
Traud, A.L., Mucha, P.J., Porter, M.A.: Social structure of Facebook networks. Phys. A Stat. Mech. Appl. 391(16), 4165–4180 (2011)
Tremblay, N., Borgnat, P.: Graph wavelets for multiscale community mining. IEEE Trans. Signal Process. 62(20), 5227–5239 (2014)
Zhao, X., Sala, A., Wilson, C., Wang, X., Gaito, S., Zheng, H., Zhao, B.Y.: Multi-scale dynamics in a massive online social network. In: Proceedings of the 12th ACM SIGKDD Internet Measurement Conference, pp. 171–184, May 2012
Acknowledgments
ZK acknowledges partial support by the Engineering and Physical Sciences Research Council (EPSRC) and by grant no. I02/19 of Bulgarian NSF.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper

Cite this paper
Kuncheva, Z., Montana, G. (2017). Multi-scale Community Detection in Temporal Networks Using Spectral Graph Wavelets. In: Guidotti, R., Monreale, A., Pedreschi, D., Abiteboul, S. (eds) Personal Analytics and Privacy. An Individual and Collective Perspective. PAP 2017. Lecture Notes in Computer Science(), vol 10708. Springer, Cham. https://doi.org/10.1007/978-3-319-71970-2_12
Download citation
DOI: https://doi.org/10.1007/978-3-319-71970-2_12
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-71969-6
Online ISBN: 978-3-319-71970-2
eBook Packages: Computer ScienceComputer Science (R0)