
Abstract
Linear response eigenvalue problems arise from the calculation of excitation states of many-particle systems in computational materials science. In this paper, from the point of view of numerical linear algebra and matrix computations, we review the progress of linear response eigenvalue problems in theory and algorithms since 2012.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others


1 Introduction
The standard Linear Response Eigenvalue Problem (LREP) is the following eigenvalue problem
where A and B are n × n real symmetric matrices such that the symmetric matrix \(\left [\begin{array}{*{10}c} A&B\\ B & A \end{array} \right ]\) is positive definite. Such an eigenvalue problem arises from computing excitation states (energies) of physical systems in the study of collective motion of many particle systems, ranging from silicon nanoparticles and nanoscale materials to the analysis of interstellar clouds (see, for example, [12, 27, 33, 34, 38, 50] and references therein). In computational quantum chemistry and physics, the excitation states and absorption spectra for molecules or surface of solids are described by the Random Phase Approximation (RPA) or the Bethe-Salpeter (BS) equation. For this reason, the LREP (1) is also called the RPA eigenvalue problem [17], or the BS eigenvalue problem [5, 6, 42]. There are immense recent interest in developing new theory, efficient numerical algorithms of the LREP (1) and the associated excitation response calculations of molecules for materials design in energy science [16, 28, 40, 41].
In this article, we survey recent progress in the LREP research from numerical linear algebra and matrix computations perspective. We focus on recent work since 2012. A survey of previous algorithmic work prior to 2012 can be found in [2, 51] and references therein. The rest of this paper is organized as follows. In Sect. 2, we survey the recent theoretical studies on the properties of the LREP and minimization principles. In Sect. 3, we briefly describe algorithmic advances for solving the LREP. In Sect. 4, we state recent results on perturbation and backward error analysis of the LREP. In Sect. 5, we remark on several related researches spawn from the LREP (1), including a generalized LREP.
2 Theory
Define the symmetric orthogonal matrix
It can be verified that \(J^{\mathop{\mathrm{T}}\nolimits }J = J^{2} = I_{2n}\) and
This means that the LREP (1) is orthogonally similar to
where K = A − B and M = A + B. Both eigenvalue problems (1) and (4) have the same eigenvalues with corresponding eigenvectors related by
Furthermore, the positive definiteness of the matrix \(\left [\begin{array}{*{10}c} A&B\\ B & A \end{array} \right ]\) is translated into that both K and M are positive definite since
Because of the equivalence of the eigenvalue problems (1) and (4), we still refer to (4) as an LREP which will be one to be studied from now on, unless otherwise explicitly stated differently.
2.1 Basic Eigen-Properties
It is straightforward to verify that
This implies that the eigenvalues of H come in pair {λ, −λ} and their associated eigenvectors enjoy a simple relationship. In fact, as shown in [1], there exists a nonsingular \(\varPhi \in \mathbb{R}^{n\times n}\) such that
where \(\varLambda =\mathop{ \mathrm{diag}}\nolimits (\lambda _{1},\lambda _{2},\ldots,\lambda _{n})\) and \(\varPsi =\varPhi ^{-\mathop{\mathrm{T}}\nolimits }\). In particular
Thus H is diagonalizable and has the eigen-decomposition (8b).
The notion of invariant subspace (aka eigenspace) is an important concept for the standard matrix eigenvalue problem not only in theory but also in numerical computation. In the context of LREP (4), with consideration of its eigen-properties as revealed by (7) and (8b), in [1, 2] we introduced a pair of deflating subspaces of {K, M}, by which we mean a pair \(\{\mathscr{U},\mathscr{V }\}\) of two k-dimensional subspaces \(\mathscr{U} \subseteq \mathbb{R}^{n}\) and \(\mathscr{V } \subseteq \mathbb{R}^{n}\) such that
Let \(U \in \mathbb{R}^{n\times k}\) and \(V \in \mathbb{R}^{n\times k}\) be the basis matrices of \(\mathscr{U}\) and \(\mathscr{V }\), respectively. Then (9) can be restated as that there exist \(K_{\text{R}} \in \mathbb{R}^{k\times k}\) and \(M_{\text{R}} \in \mathbb{R}^{k\times k}\) such that
and vice versa, or equivalently,
i.e., \(\mathscr{V } \oplus \mathscr{U}\) is an invariant subspace of H [1, Theorem 2.4]. We call {U, V, K R , M R } an eigen-quaternary of {K, M} [57].
Given a pair of deflating subspaces \(\{\mathscr{U},\mathscr{V }\} =\{ \mathscr{R}(U),\mathscr{R}(V )\}\), a part of the eigenpairs of H can be obtained via solving the smaller eigenvalue problem [1, Theorem 2.5]. Specifically, if
then \((\lambda,\left [\begin{array}{*{10}c} V \hat{y}\\ U\hat{x} \end{array} \right ])\) is an eigenpair of H. The matrix H R is the restriction of H onto \(\mathscr{V } \oplus \mathscr{U}\) with respect to the basis matrices V ⊕ U. Moreover, the eigenvalues of H R are uniquely determined by the pair of deflating subspaces \(\{\mathscr{U},\mathscr{V }\}\) [2].
There are infinitely many choices of {K R , M R } in (10). The most important one introduced in [57] is the Rayleigh quotient pair, denoted by {K RQ , M RQ }, of the LREP (4) associated with \(\{\mathscr{R}(U),\mathscr{R}(V )\}\):
and accordingly,
Note that H RQ so defined is not of the LREP type because K RQ and M RQ are not symmetric unless \(U^{\mathop{\mathrm{T}}\nolimits }V = I_{k}\). To circumvent this, we factorize \(W:= U^{\mathop{\mathrm{T}}\nolimits }V\) as \(W = W_{1}^{\mathop{\mathrm{T}}\nolimits }W_{2}\), where \(W_{i} \in \mathbb{R}^{k\times k}\) are nonsingular, and define
Thus H RQ is similar to H SR . The latter is of the LREP type and has played an important role in [1, 2] for the LREP, much the same role as played by the Rayleigh quotient matrix in the symmetric eigenvalue problem [36].
Up to this point, our discussion is under the assumption that \(\{\mathscr{R}(U),\mathscr{R}(V )\}\) is a pair of deflating subspaces. But as far as the construction of H RQ is concerned, this is not necessary, so long as \(U^{\mathop{\mathrm{T}}\nolimits }V\) is nonsingular. The same statement also goes for H SR . In fact, a key component in [2, 58] on eigenvalue approximations for the LREP is the use of the eigenvalues of H SR to approximate part of the eigenvalues of H.
2.2 Thouless’ Minimization Principle
Back to 1961, Thouless [49] showed that the smallest positive eigenvalue λ 1 of the LREP (1) admits the following minimization principle:
where ρ t (u, v) is defined by
The minimization in (14) is taken among all vectors u, v such that \(u^{\mathop{\mathrm{T}}\nolimits }u - v^{\mathop{\mathrm{T}}\nolimits }v\neq 0\).
By the similarity transformation (3) and using the relationships in (5), we have
and thus equivalently
The minimization here is taken among all vectors x, y such that \(x^{\mathop{\mathrm{T}}\nolimits }y\neq 0\) [53].
We will refer to both ρ t (u, v) and ρ(x, y) as the Thouless functionals but in different forms. Although ρ t (u, v) ≡ ρ(x, y) under (5), in this paper we primarily work with ρ(x, y) to state extensions of (17) and efficient numerical methods.
2.3 New Minimization Principles and Cauchy Interlacing Inequalities
In [1], we have systematically studied eigenvalue minimization principles for the LREP to mirror those for the standard symmetric eigenvalue problems [7, 36]. We proved the following subspace version of the minimization principle (14):
among all \(U,V \in \mathbb{R}^{n\times k}\). Moreover if λ k < λ k+1, then for any U and V that attain the minimum, \(\{\mathscr{R}(U),\mathscr{R}(V )\}\) is a pair of deflating subspaces of {K, M} and the corresponding H RQ has eigenvalues ±λ i (1 ≤ i ≤ k).
Equation (18) suggests that
is a proper subspace version of the Thouless functional in the form of ρ(⋅ , ⋅ ). Exploiting the close relation through (5) between the two different forms of the Thouless functionals ρ t (⋅ , ⋅ ) and ρ(⋅ , ⋅ ), we see that
is a proper subspace version of the Thouless functional in the form of ρ t (⋅ , ⋅ ). Also as a consequence of (18), we have
among all \(U,V \in \mathbb{R}^{n\times k}\).
In [1], we also derived the Cauchy-type interlacing inequalities. Specifically, let \(U,V \in \mathbb{R}^{n\times k}\) such that \(U^{\mathop{\mathrm{T}}\nolimits }V\) is nonsingular, and denote by ±μ i (1 ≤ i ≤ k) the eigenvalues ofFootnote 1 H RQ , where 0 ≤ μ 1 ≤ ⋯ ≤ μ k . Then
where \(\gamma = \sqrt{\min \{\kappa (K),\kappa (M)\}}/\cos \angle (\mathscr{U},\mathscr{V })\), \(\mathscr{U} = \mathscr{R}(U)\) and \(\mathscr{V } = \mathscr{R}(V )\). Furthermore, if λ k < λ k+1 and λ i = μ i for 1 ≤ i ≤ k, then \(\{\mathscr{U},\mathscr{V }\}\) is a pair of deflating subspaces of {K, M} corresponding to the eigenvalues ±λ i (1 ≤ i ≤ k) of H when both K and M are definite.
2.4 Bounds on Eigenvalue Approximations
Let \(U,\,V \in \mathbb{R}^{n\times k}\) and \(U^{\mathop{\mathrm{T}}\nolimits }V = I_{k}\). \(\{\mathscr{R}(U),\mathscr{R}(V )\}\) is a pair of approximate deflating subspaces intended to approximate \(\{\mathscr{R}(\varPhi _{1}),\mathscr{R}(\varPsi _{1})\}\), where Φ 1 = Φ (: ,1: k) and Ψ 1 = Ψ (: ,1: k). Construct H SR as in (13). We see H SR = H RQ since \(U^{\mathop{\mathrm{T}}\nolimits }V = I_{k}\). Denote the eigenvalues of H SR by
We are interested in bounding
-
1.
the errors in μ i as approximations to λ i in terms of the error in \(\{\mathscr{R}(U),\mathscr{R}(V )\}\) as an approximation to \(\{\mathscr{R}(\varPhi _{1}),\mathscr{R}(\varPsi _{1})\}\), and conversely
-
2.
the error in \(\{\mathscr{R}(U),\mathscr{R}(V )\}\) as an approximation to \(\{\mathscr{R}(\varPhi _{1}),\mathscr{R}(\varPsi _{1})\}\) in terms of the errors in μ i as approximations to λ i .
To these goals, define
We know 0 < λ i ≤ μ i by (22); so δ k defines an error measurement in all μ i as approximations to λ i for 1 ≤ i ≤ k. Suppose λ k < λ k+1. It is proved in [58] that
where \(\varTheta _{M^{-1}}(U,\varPhi _{1})\) is the diagonal matrix of the canonical angles between subspaces \(\mathscr{R}(U)\) and \(\mathscr{R}(\varPhi )\) in the M −1-inner product, the largest of which is denoted by \(\theta _{M^{-1}}(U,\varPhi _{1})\), and similarly for \(\theta _{M^{-1}}(U,MV )\), \(\varTheta _{K^{-1}}(V,\varPsi _{1})\), and \(\theta _{K^{-1}}(V,KU)\) (see, e.g., [58] for precise definitions). As a result,
The inequalities in (24) address item 1 above, while item 2 is answered by these in (25).
3 Numerical Algorithms
In [2], we reviewed a list of algorithms for solving the small dense and large sparse LREPs up to 2012. In the recent work [42] for solving dense complex and real LREP, authors established the equivalence between the eigenvalue problem and real Hamiltonian eigenvalue problem. Consequently, a structure preserving algorithm is proposed and implemented using ScaLAPACK [10] on distributed memory computer systems. In this section, we will review recently proposed algorithms for solving large sparse LREPs.
3.1 Deflation
Whether already known or computed eigenpairs can be effectively deflated away to avoid being recomputed is crucial to numerical efficiency in the process of computing more eigenpairs while avoiding the known ones. In [4], we developed a shifting deflation technique by a low-rank update to either K or M and thus the resulting K or M performs at about comparable cost as the original K or M when it comes to do matrix-vector multiplication operations. This deflation strategy is made possible by the following result.
Let \(\mathbb{J} =\{ i_{j}\,:\, 1 \leq j \leq k\} \subset \{ 1,2,\ldots,n\}\), and let \(V \in \mathbb{R}^{n\times k}\) with \(\mathop{\mathrm{rank}}\nolimits (V ) = k\) satisfying \(\mathscr{R}(V ) = \mathscr{R}(\varPsi _{(:,\mathbb{J})})\), or equivalently \(V =\varPsi _{(:,\mathbb{J})}Q\) for some nonsingular \(Q \in \mathbb{R}^{k\times k}\). Let ξ > 0, and define
Then H and \(\underline{H}\) share the same eigenvalues ±λ i for \(i\not\in \mathbb{J}\) and the corresponding eigenvectors, and the rest of eigenvalues of \(\underline{H}\) are the square roots of the eigenvalues of \(\varLambda _{1}^{2} +\xi QQ^{\mathop{\mathrm{T}}\nolimits }\), where \(\varLambda _{1} =\mathop{ \mathrm{diag}}\nolimits (\lambda _{i_{1}},\ldots,\lambda _{i_{k}})\). There is a version of this result for updating M only, too.
3.2 CG Type Algorithms
One of the most important numerical implications of the eigenvalue minimization principles such as the ones presented in Sect. 2.2 is the possibility of using optimization approaches such as the steepest descent (SD) method, conjugate gradient (CG) type methods, and their improvements. A key component in these approaches is the line search. But in our case, it turns out that the 4D search is a more natural approach to take. Consider the Thouless functional ρ(x, y). Given a search direction \(\left [\begin{array}{*{10}c} q\\ \,p \end{array} \right ]\) from the current position \(\left [\begin{array}{*{10}c} y\\ x \end{array} \right ]\), the basic idea of the line search [27, 29] is to look for the best possible scalar argument t to minimize ρ:
on the line \(\left \{\left [\begin{array}{*{10}c} y\\ x \end{array} \right ] + t\left [\begin{array}{*{10}c} \,q\\ \,p \end{array} \right ]\,:\, t \in \mathbb{R}\right \}.\) While (27) does have an explicit solution through calculus, it is cumbersome. Another related search idea is the so-called dual-channel search [13] through solving the minimization problem
where the search directions p and q are selected as the partial gradients ∇ x ρ and ∇ y ρ to be given in (31). The minimization problem (28) is then solved iteratively by freezing one of s and t and minimizing the functional ρ over the other in an alternative manner.
In [2] we proposed to look for four scalars α, β, s, and t for the minimization problem
where U = [x, p] and V = [y, q]. This no longer performs a line search (27) but a 4-dimensional subspace search (4D search for short) within the 4-dimensional subspace:
There are several advantages of this 4D search over the line search (27) and dual-channel search (28): (1) the right-hand side of (29) can be solved by the LREP for the 4 × 4 H SR constructed with U = [x, p] and V = [y, q], provided \(U^{\mathop{\mathrm{T}}\nolimits }V\) is nonsingular; (2) the 4D search yields a better approximation because of the larger search subspace; (3) most importantly, it paves the way for a block version to simultaneously approximate several interested eigenpairs.
The partial gradients of the Thouless functional ρ(x, y) with respect to x and y will be needed for various minimization approaches. Let x and y be perturbed to x + p and y + q, respectively, where p and q are assumed to be small in magnitude. Assuming \(x^{\mathop{\mathrm{T}}\nolimits }y\neq 0\), up to the first order in p and q, we have [2]
to give the partial gradients of ρ(x, y) with respect to x and y
With the partial gradients (31) and the 4D-search, extensions of the SD method and nonlinear CG method for the LREP are straightforward. But more efficient approaches lie in their block versions. In [39], a block 4D SD algorithm is presented and validated for excitation energies calculations of simple molecules in time-dependent density functional theory. Most recently, borrowing many proven techniques in the symmetric eigenvalue problem such as LOBPCG [19] and augmented projection subspace approaches [15, 18, 23, 37, 55], we developed an extended locally optimal block preconditioned 4-D CG algorithm (ELOBP4dCG) in [4]. The key idea for its iterative step is as follows. Consider the eigenvalue problem for
which is equivalent to the LREP for \(\underline{H}\) in (26). This is a positive semidefinite pencil in the sense that \(\boldsymbol{A} -\lambda _{0}\boldsymbol{B}\succeq 0\) for λ 0 = 0 [25, 26]. Now at the beginning of the (i + 1)st iterative step, we have approximate eigenvectors
where n b is the block size, the superscripts (i−1) and (i) indicate that they are for the (i − 1)st and ith iterative steps, respectively. We then compute a basis matrix \(\left [\begin{array}{*{10}c} V _{1} \\ U_{1} \end{array} \right ]\) of
where Π is some preconditioner such as \(\underline{\boldsymbol{A}}^{-1}\) and \(\mathscr{K}_{m}(\varPi [\underline{\boldsymbol{A}} -\rho (x_{j}^{(i)},y_{j}^{(i)})\boldsymbol{B}],z_{j}^{(i)})\) is the mth Krylov subspace, and then compute two basis matrices V and U for the subspaces
respectively, and finally solve the projected eigenvalue problem for
to construct new approximations z j (i+1) for 1 ≤ j ≤ n b . When m = 2 in (33), it gives the LOBP4dCG of [1].

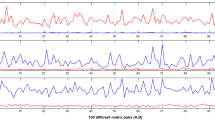
Top row: convergence of LOB4dCG (i.e., m = 2) without preconditioning (left) and with deflation (right). Bottom row: convergence of extended LOB4dCG (ELOB4dCG) with m = 3 without preconditioning (left) and with deflation (right)
As an illustrative example to display the convergence behavior of ELOBP4dCG, Fig. 1, first presented in [4], shows iterative history plots of LOBP4dCG and ELOBP4dCG on an LREP arising from a time-dependent density-functional theory simulation of a Na2 sodium in QUANTUM EXPRESSO [39]. At each iteration i, there are 4 normalized residuals \(\|\underline{H}z -\mu z\|_{1}/((\|\underline{H}\|_{1}+\mu )\|z\|_{1})\) which move down as i goes. As soon as one reaches 10−8, the corresponding eigenpair (μ, z) is deflated and locked away, and a new residual shows up at the top. We see dramatic reductions in the numbers of iterations required in going from from m = 2 to m = 3, and in going from “without preconditioning” to “with preconditioning”. The powers of using a preconditioner and extending the searching subspace are in display prominently. More detail can be found in [4].
3.3 Other Methods
There is a natural extension of Lanczos method based on the following decompositions. Given \(0\neq v_{0} \in \mathbb{R}^{n}\) and \(0\neq u_{0} \in \mathbb{R}^{n}\) such that Mv 0 = u 0, there exist nonsingular \(U,\,V \in \mathbb{R}^{n\times n}\) such that V e 1 = αv 0 and Ue 1 = βu 0 for some \(\alpha,\beta \in \mathbb{R}\), and
where T is tridiagonal, D is diagonal and \(U^{\mathop{\mathrm{T}}\nolimits }V = I_{n}\). Partially realizing (36) leads to the first Lanczos process in [46]. A similar Lanczos process is also studied in [11] for estimating absorption spectrum with the linear response time-dependent density functional theory. There is an early work by Tsiper [52, 53] on a Lanczos-type process to reduce both K and M to tridiagonal. Generically, Tsiper’s Lanczos process converges at only half the speed of the Lanczos process based on (36).
Recently, Xu and Zhong [56] proposed a Golub-Kahan-Lanczos type process that partially realize the factorizations:
where G is bidiagonal, \(X^{\mathop{\mathrm{T}}\nolimits }KX = I_{n}\) and \(Y ^{\mathop{\mathrm{T}}\nolimits }MY = I_{n}\). The basic idea is to use the singular values of the partially realized G to approximate some positive eigenvalues of H. Numerical results there suggest that the Golub-Kahan-Lanczos process performs slightly better than the Lanczos process based on (36).
The equations in (8a) implies KM = ΦΛ 2 Φ −1. Noticing λ i 2 for 1 ≤ i ≤ k lie in low end of the spectrum of KM, in [48] the authors devised a block Chebyshev-Davidson approach to build subspaces through suppress components of vectors in the direction of eigenvectors associated with λ i 2 for i > k + 1. Numerical results there show that the approach can work quite well.
Most recently, structurally inverse-based iterative solvers for very large scale BS eigenvalue problem using the reduced basis approach via low-rank tensor factorizations are presented in [5, 6]. In [21], an indefinite variant of LOBPCG is also proposed.
4 Perturbation and Error Analysis
First we consider the perturbation of the LREP (4). Recall the eigen-decompositions in (8), and let
Suppose H is perturbed to \(\widetilde{H}\) with correspondingly positive definite \(\widetilde{K}\) and \(\widetilde{M}\). The same decompositions as in (8) for \(\widetilde{H}\) exist. Adopt the same notations for the perturbed LREP for \(\widetilde{H}\) as those for H except with a tilde on each symbol. It was proved in [57] that
These inequalities involve the norms ∥Z∥2 and \(\|\widetilde{Z}\|_{2}\) which are not known a priori. But they can be bounded in terms of the norms of K, M, their inverses, and bounds on λ 1 and λ n .
Previously in Sect. 2.1, we note that for an exact pair \(\{\mathscr{U},\mathscr{V }\}\) of deflating subspaces we have (10). In particular, KU = V K RQ and MV = UM RQ , where \(U \in \mathbb{R}^{n\times k}\) and \(V \in \mathbb{R}^{n\times k}\) are the basis matrices for \(\mathscr{U}\) and \(\mathscr{V }\), respectively. When \(\{\mathscr{U},\mathscr{V }\}\) is only an approximate pair, it would be interesting to seek backward perturbations ΔK and ΔM to K and M, respectively, such that
In the other word, \(\{\mathscr{U},\mathscr{V }\}\) is an exact pair for {K + ΔK, M + ΔM}. Since K and M are symmetric, we further restrict ΔK and ΔM to be symmetric, too. The first and foremost question is, naturally, if such perturbations ΔK and ΔM exist, i.e., if the set
is not empty. Indeed \(\mathbb{B}\neq \varnothing\) [57]. Next we are interested in knowing
where ∥⋅ ∥ is some matrix norm. Without loss of generality, we assume \(U^{\mathop{\mathrm{T}}\nolimits }U = V ^{\mathop{\mathrm{T}}\nolimits }V = I_{k}\). It is obtained in [57] that
where \(\eta _{\mathop{\mathrm{F}}\nolimits }\) and η 2 are the ones of (41) with the Frobenius and spectral norms, respectively, and \(\mathscr{R}_{K}(K_{\text{RQ}}):= KU - V K_{\text{RQ}}\) and \(\mathscr{R}_{M}(M_{\text{RQ}}):= MV - UM_{\text{RQ}}\). An immediate consequence of such backward error analysis is bounds on approximation errors by the eigenvalues of H RQ to some of those of H.
There are a couple of recent work [47, 54] on the perturbation of partitioned LREP. Let K and M be partitioned as

If K 21 = M 21 = 0, then \(\{\mathscr{U}_{0},\mathscr{V }_{0}\}\) is a pair of deflating subspaces, where \(\mathscr{U}_{0} = \mathscr{V }_{0} = \mathscr{R}(\left [\begin{array}{*{10}c} I_{k}\\ 0\end{array} \right ])\). But what if K 21 ≠ 0 and/or M 21 ≠ 0 but tiny in magnitude? Then \(\{\mathscr{U}_{0},\mathscr{V }_{0}\}\) can only be regarded as a pair of approximate deflating subspaces, and likely there would exist an exact pair \(\{\widetilde{\mathscr{U}},\widetilde{\mathscr{V }}\}\) of deflating subspaces nearby. Specifically, we may seek
for some P and Q. It resembles the well-known Stewart’s perturbation analysis for the standard and generalized eigenvalue problems [43–45]. The study along this line for the LREP has been recently conducted in [54].
Alternatively, if K 21 = M 21 = 0 in (44), then \(\mathop{\mathrm{eig}}\nolimits (H) =\mathop{ \mathrm{eig}}\nolimits (H_{1}) \cup \mathop{\mathrm{eig}}\nolimits (H_{2})\), where \(H_{i} = \left [\begin{array}{*{10}c} 0 &K_{i} \\ M_{i}& 0 \end{array} \right ]\) for i = 1, 2, and \(\mathop{\mathrm{eig}}\nolimits (H)\) is the set of eigenvalues of H and similarly for \(\mathop{\mathrm{eig}}\nolimits (H_{i})\). Again what if K 21 ≠ 0 and/or M 21 ≠ 0 but tiny in magnitude? They may be treated as tiny perturbations. It would be interesting to know the effect on the eigenvalues from resetting them to 0, as conceivably to decouple H into two smaller LREPs. It is shown that such an action brings changes to the eigenvalues of H at most proportional to ∥K 21∥2 2 + ∥M 21∥2 2 and reciprocally proportional to the gaps between \(\mathop{\mathrm{eig}}\nolimits (H_{1})\) and \(\mathop{\mathrm{eig}}\nolimits (H_{2})\) [47].
5 Concluding Remarks
Throughout, we have focused on recent studies of the standard LREP (4) with the assumption that K and M are real and symmetric as deduced from the original LREP (1). There are several directions to expand these studies by relaxing the assumption on K and M and, for that matter, accordingly on A and B.
An immediate expansion is to allow K and M to be complex but Hermitian and still positive definite. All surveyed results with a minor modification (by changing all transposes to conjugate transposes) hold. Most of the theoretical results in Sects. 2.2 and 2.3 are still valid when only one of K and M is positive and the other is semidefinite, after changing “min” in (17) and (14) to “inf”.
Although often K and M are definite, there are cases that one of them is indefinite while the other is still definite [35]. In such cases, all theoretical results in Sects. 2.2–2.4 no longer hold. But some of the numerical methods mentioned in Sect. 3.3, namely, the Lanczos type methods in [46] and the Chebyshev-Davidson approach [48], still work. Recently in [24], a symmetric structure-preserving ΓQR algorithm is developed for LREPs in the form of (1) without any definiteness assumption.
The following generalized linear response eigenvalue problem (GLREP) [14, 32, 33]
was studied in [3], where A and B are the same as the ones in (1), and and Σ and Δ are also n × n with Σ being symmetric while Δ skew-symmetric (i.e., \(\varDelta ^{\mathop{\mathrm{T}}\nolimits } = -\varDelta\)) such that \(\left [\begin{array}{*{10}c} \varSigma &\varDelta \\ \varDelta &\varSigma \end{array} \right ]\) is nonsingular. Performing the same orthogonal similarity transformation, we can transform GLREP (45) equivalently to
where \(E_{+}^{\mathop{\mathrm{T}}\nolimits } = E_{-}\) is nonsingular. Many results parallel to what we surveyed so far for the LREP (4) are obtained in [3].
Both (4) and (46) are equivalent to the generalized eigenvalue problem for
Since \(\boldsymbol{A} - 0 \cdot \boldsymbol{ B} =\boldsymbol{ A}\) is positive definite, \(\boldsymbol{A} -\lambda \boldsymbol{ B}\) falls into the category of the so-called positive semi-definite matrix pencils (positive definite if both K and M are positive definite). Numerous eigenvalue min-max principles, as generalizations of the classical ones, are obtained in [8, 9, 20, 22, 30, 31] and, more recently, [25, 26].
Notes
- 1.
In [1], it was stated in terms of the eigenvalues of H SR which is similar to H RQ and thus both have the same eigenvalues.
References
Bai, Z., Li, R.-C.: Minimization principles for the linear response eigenvalue problem, I: theory. SIAM J. Matrix Anal. Appl. 33(4), 1075–1100 (2012)
Bai, Z., Li, R.-C.: Minimization principle for linear response eigenvalue problem, II: Computation. SIAM J. Matrix Anal. Appl. 34(2), 392–416 (2013)
Bai, Z., Li, R.-C.: Minimization principles and computation for the generalized linear response eigenvalue problem. BIT Numer. Math. 54(1), 31–54 (2014)
Bai, Z., Li, R.-C., Lin, W.-W.: Linear response eigenvalue problem solved by extended locally optimal preconditioned conjugate gradient methods. Sci. China Math. 59(8), 1443–1460 (2016)
Benner, P., Khoromskaia, V., Khoromskij, B.N.: A reduced basis approach for calculation of the Bethe-Salpeter excitation energies using low-rank tensor factorization. Technical Report, arXiv:1505.02696v1 (2015)
Benner, P., Dolgov, S., Khoromskaia, V., Khoromskij, B.N.: Fast iterative solution of the Bethe-Salpeter eigenvalue problem using low-rank and QTT tensor approximation. Technical Report, arXiv:1602.02646v1 (2016)
Bhatia, R.: Matrix Analysis. Springer, New York (1996)
Binding, P., Ye, Q.: Variational principles for indefinite eigenvalue problems. Linear Algebra Appl. 218, 251–262 (1995)
Binding, P., Najman, B., Ye, Q.: A variational principle for eigenvalues of pencils of Hermitian matrices. Integr. Equ. Oper. Theory 35, 398–422 (1999)
Blackford, L., Choi, J., Cleary, A., D’Azevedo, E., Demmel, J., Dhillon, I., Dongarra, J., Hammarling, S., Henry, G., Petitet, A., Stanley, K., Walker, D., Whaley, R.: ScaLAPACK Users’ Guide. SIAM, Philadelphia (1997)
Brabec, J., Lin, L., Shao, M., Govind, N., Yang, C., Saad, Y., Ng, E.: Efficient algorithm for estimating the absorption spectrum within linear response TDDFT. J. Chem. Theory Comput. 11(11), 5197–5208 (2015)
Casida, M.E.: Time-dependent density-functional response theory for molecules. In: Chong, D.P. (ed.) Recent advances in Density Functional Methods, pp. 155–189. World Scientific, Singapore (1995)
Challacombe, M.: Linear scaling solution of the time-dependent self-consistent-field equations. Computation 2, 1–11 (2014)
Flaschka, U., Lin, W.-W., Wu, J.-L.: A KQZ algorithm for solving linear-response eigenvalue equations. Linear Algebra Appl. 165, 93–123 (1992)
Golub, G., Ye, Q.: An inverse free preconditioned Krylov subspace methods for symmetric eigenvalue problems. SIAM J. Sci. Comput. 24, 312–334 (2002)
Grüning, M., Marini, A., Gonze, X.: Exciton-plasmon states in nanoscale materials: breakdown of the Tamm-Dancoff approximation. Nano Lett. 9, 2820–2824 (2009)
Grüning, M., Marini, A., Gonze, X.: Implementation and testing of Lanczos-based algorithms for random-phase approximation eigenproblems. Comput. Mater. Sci. 50(7), 2148–2156 (2011)
Imakura, A., Du, L., Sakurai, T.: Error bounds of Rayleigh-Ritz type contour integral-based eigensolver for solving generalized eigenvalue problems. Numer. Algorithms 71, 103–120 (2016)
Knyazev, A.V.: Toward the optimal preconditioned eigensolver: locally optimal block preconditioned conjugate gradient method. SIAM J. Sci. Comput. 23(2), 517–541 (2001)
Kovač-Striko, J., Veselić, K.: Trace minimization and definiteness of symmetric pencils. Linear Algebra Appl. 216, 139–158 (1995)
Kressner, D., Pandur, M.M., Shao, M.: An indefinite variant of LOBPCG for definite matrix pencils. Numer. Algorithms 66, 681–703 (2014)
Lancaster, P., Ye, Q.: Variational properties and Rayleigh quotient algorithms for symmetric matrix pencils. Oper. Theory Adv. Appl. 40, 247–278 (1989)
Li, R.-C.: Rayleigh quotient based optimization methods for eigenvalue problems. In: Bai, Z., Gao, W., Su, Y. (eds.) Matrix Functions and Matrix Equations. Series in Contemporary Applied Mathematics, vol. 19, pp. 76–108. World Scientific, Singapore (2015)
Li, T., Li, R.-C., Lin, W.-W.: A symmetric structure-preserving gamma-qr algorithm for linear response eigenvalue problems. Technical Report 2016-02, Department of Mathematics, University of Texas at Arlington (2016). Available at http://www.uta.edu/math/preprint/
Liang, X., Li, R.-C.: Extensions of Wielandt’s min-max principles for positive semi-definite pencils. Linear Multilinear Algebra 62(8), 1032–1048 (2014)
Liang, X., Li, R.-C., Bai, Z.: Trace minimization principles for positive semi-definite pencils. Linear Algebra Appl. 438, 3085–3106 (2013)
Lucero, M.J., Niklasson, A.M.N., Tretiak, S., Challacombe, M.: Molecular-orbital-free algorithm for excited states in time-dependent perturbation theory. J. Chem. Phys. 129(6), 064114 (2008)
Lusk, M.T., Mattsson, A.E.: High-performance computing for materials design to advance energy science. MRS Bull. 36, 169–174 (2011)
Muta, A., Iwata, J.-I., Hashimoto, Y., Yabana, K.: Solving the RPA eigenvalue equation in real-space. Progress Theor. Phys. 108(6), 1065–1076 (2002)
Najman, B., Ye, Q.: A minimax characterization of eigenvalues of Hermitian pencils. Linear Algebra Appl. 144, 217–230 (1991)
Najman, B., Ye, Q.: A minimax characterization of eigenvalues of Hermitian pencils II. Linear Algebra Appl. 191, 183–197 (1993)
Olsen, J., Jørgensen, P.: Linear and nonlinear response functions for an exact state and for an MCSCF state. J. Chem. Phys. 82(7), 3235–3264 (1985)
Olsen, J., Jensen, H.J.A., Jørgensen, P.: Solution of the large matrix equations which occur in response theory. J. Comput. Phys. 74(2), 265–282 (1988)
Onida, G., Reining, L., Rubio, A.: Electronic excitations: density-functional versus many-body Green’s function approaches. Rev. Mod. Phys 74(2), 601–659 (2002)
Papakonstantinou, P.: Reduction of the RPA eigenvalue problem and a generalized Cholesky decomposition for real-symmetric matrices. Europhys. Lett. 78(1), 12001 (2007)
Parlett, B.N.: The Symmetric Eigenvalue Problem. SIAM, Philadelphia (1998)
Quillen, P., Ye, Q.: A block inverse-free preconditioned Krylov subspace method for symmetric generalized eigenvalue problems. J. Comput. Appl. Math. 233(5), 1298–1313 (2010)
Ring, P., Schuck, P.: The Nuclear Many-Body Problem. Springer, New York (1980)
Rocca, D., Bai, Z., Li, R.-C., Galli, G.: A block variational procedure for the iterative diagonalization of non-Hermitian random-phase approximation matrices. J. Chem. Phys. 136, 034111 (2012)
Rocca, D., Lu, D., Galli, G.: Ab initio calculations of optical absorpation spectra: solution of the Bethe-Salpeter equation within density matrix perturbation theory. J. Chem. Phys. 133(16), 164109 (2010)
Saad, Y., Chelikowsky, J.R., Shontz, S.M.: Numerical methods for electronic structure calculations of materials. SIAM Rev. 52, 3–54 (2010)
Shao, M., da Jornada, F.H., Yang, C., Deslippe, J., Louie, S.G.: Structure preserving parallel algorithms for solving the Bethe-Salpeter eigenvalue problem. Linear Algebra Appl. 488, 148–167 (2016)
Stewart, G.W.: Error bounds for approximate invariant subspaces of closed linear operators. SIAM J. Numer. Anal. 8, 796–808 (1971)
Stewart, G.W.: On the sensitivity of the eigenvalue problem Ax = λBx. SIAM J. Numer. Anal. 4, 669–686 (1972)
Stewart, G.W.: Error and perturbation bounds for subspaces associated with certain eigenvalue problems. SIAM Rev. 15, 727–764 (1973)
Teng, Z., Li, R.-C.: Convergence analysis of Lanczos-type methods for the linear response eigenvalue problem. J. Comput. Appl. Math. 247, 17–33 (2013)
Teng, Z., Lu, L., Li, R.-C.: Perturbation of partitioned linear response eigenvalue problems. Electron. Trans. Numer. Anal. 44, 624–638 (2015)
Teng, Z., Zhou, Y., Li, R.-C.: A block Chebyshev-Davidson method for linear response eigenvalue problems. Adv. Comput. Math. (2016). springerlink.bibliotecabuap.elogim.com/article/10.1007/s10444-016-9455-2
Thouless, D.J.: Vibrational states of nuclei in the random phase approximation. Nucl. Phys. 22(1), 78–95 (1961)
Thouless, D.J.: The Quantum Mechanics of Many-Body Systems. Academic, New York (1972)
Tretiak, S., Isborn, C.M., Niklasson, A.M.N., Challacombe, M.: Representation independent algorithms for molecular response calculations in time-dependent self-consistent field theories. J. Chem. Phys. 130(5), 054111 (2009)
Tsiper, E.V.: Variational procedure and generalized Lanczos recursion for small-amplitude classical oscillations. J. Exp. Theor. Phys. Lett. 70(11), 751–755 (1999)
Tsiper, E.V.: A classical mechanics technique for quantum linear response. J. Phys. B: At. Mol. Opt. Phys. 34(12), L401–L407 (2001)
Wang, W.-G., Zhang, L.-H., Li, R.-C.: Error bounds for approximate deflating subspaces for linear response eigenvalue problems. Technical Report 2016-01, Department of Mathematics, University of Texas at Arlington (2016). Available at http://www.uta.edu/math/preprint/
Wen, Z., Zhang, Y.: Block algorithms with augmented Rayleigh-Ritz projections for large-scale eigenpair computation. Technical Report, arxiv: 1507.06078 (2015)
Xu, H., Zhong, H.: Weighted Golub-Kahan-Lanczos algorithms and applications. Department of Mathematics, University of Kansas, Lawrence, KS, January (2016)
Zhang, L.-H., Lin, W.-W., Li, R.-C.: Backward perturbation analysis and residual-based error bounds for the linear response eigenvalue problem. BIT Numer. Math. 55(3), 869–896 (2015)
Zhang, L.-H., Xue, J., Li, R.-C.: Rayleigh–Ritz approximation for the linear response eigenvalue problem. SIAM J. Matrix Anal. Appl. 35(2), 765–782 (2014)
Acknowledgements
Bai is supported in part by NSF grants DMS-1522697 and CCF-1527091, and Li is supported in part by NSF grants DMS-1317330 and CCF-1527104, and NSFC grant 11428104.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Bai, Z., Li, RC. (2017). Recent Progress in Linear Response Eigenvalue Problems. In: Sakurai, T., Zhang, SL., Imamura, T., Yamamoto, Y., Kuramashi, Y., Hoshi, T. (eds) Eigenvalue Problems: Algorithms, Software and Applications in Petascale Computing. EPASA 2015. Lecture Notes in Computational Science and Engineering, vol 117. Springer, Cham. https://doi.org/10.1007/978-3-319-62426-6_18
Download citation
DOI: https://doi.org/10.1007/978-3-319-62426-6_18
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-62424-2
Online ISBN: 978-3-319-62426-6
eBook Packages: Mathematics and StatisticsMathematics and Statistics (R0)