
Abstract
Scale is one of the most interesting issues in land change science. Although much research has been done on this topic, our understanding of its effects on data and models is still sketchy. We therefore decided to investigate how cartographic scale and minimum mapping unit (MMU) influence modeling results, for which purpose we chose a heterogeneous, dynamic study area in central Asturias (Spain). As opposed to most of the literature on this subject, which focuses on the grain component of scale comparing the same map resampled at different spatial resolutions, we used two different land use and land cover (LULC) maps (SIOSE and CORINE) at different resolutions (12.5 and 50 m) and with minimum mapping units of 0.5–2 and 25 ha respectively. We compared the input and simulated maps using spatial metrics and the matrix proposed by Pontius and Millones to find out the quantity and allocation disagreement. The results can provide a better understanding of the implications of the choice of input maps in LULC modeling.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


Keywords
1 Introduction
Scale has been described as a priority topic of research in relation to spatial information analysis and representation (Turner et al. 1989; Quattrochi and Goodchild 1997b; Castilla et al. 2009) and in modeling issues (Ménard and Marceau 2005; Lesschen et al. 2005; Houet et al. 2010; van Delden et al. 2011; Committee on Needs and Research Requirements for Land Change Modeling et al. 2014). Mike Goodchild (2001) even went so far as to say that “scale is perhaps the most important topic of geographical information science”, and to view scale as a science in itself (Quattrochi and Goodchild 1997a; Wu and Qi 2000; Quattrochi et al. 2001).
Scale can be understood in a wide variety of ways (Lam and Quattrochi 1992; Wu 2004; Ménard and Marceau 2005), such as cartographic scale (ratio), observational or geographical scale (map size or study area size) or operational scale (scale at which certain processes operate in the environment). When we talk about scale we may also be referring to the level of detail represented in a map (Agarwal et al. 2002; Verburg et al. 2004). There is also the relation between scale and spatial, temporal and thematic resolution. Some researchers refer to this as spatial scale (spatial resolution) or temporal scale (temporal resolution) (O’Sullivan and Perry 2013).
When assessing the relation between scale and spatial resolution, a key concept is the minimum mapping unit (MMU), i.e. the minimum area of the smallest unit in a map. This will be smaller at fine scales and bigger at coarse scales. Castilla et al. (2009) considered the MMU to be an important parameter, which should be included in the concept of scale together with thematic resolution, while Saura (2002) stressed its importance in the variance of spatial data representation.
The main objective of this chapter is to analyse how the scale of the selected LULC (Land Use Land Cover) maps can affect modeling. This involves analysing how scale can cause maps to show different information and studying the ways in which model behaviour varies depending on the data detail (MMU). In order to achieve these objectives, we compared two LULC maps (SIOSE and CORINE) with different cartographic scales (1:25,000 vs. 1.100,000) and different MMU (0.2–2 ha vs. 25 ha).
The chapter is divided into five main sections. After an initial introduction, the second section describes the study area and data sets. Section 3 explains how we adjusted the LULC maps to obtain two comparable sources and then goes on to describe the model we used and how it was calibrated. It also has a short introduction to the methods we used in the analysis and assessment of data. In section four we present the results and in section five we discuss the main findings of the research.
2 Test Area and Data Sets
2.1 Test Area
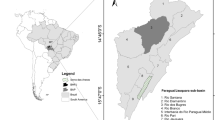
Our chosen study area was the Asturias Central Area, which as its name suggests, is in the centre of the Asturias region, in northern Spain (Fig. 1). Although from a geographical point of view it is not a coherent homogeneous space that is clearly differentiated from its surroundings, there is a functional link between its different component parts (Fernández García et al. 2007; Carrero de Roa 2012) and as a result it has been declared a special planning area within the Asturias Territorial Plan (Directrices Regionales de Ordenación del Territorio).

Map showing the location of the Asturias Central Area (2015). Source National Topographic Map 1:200,000, DEM 25 m (National Geographic Institute)
Most of the LULC (Land Use Land Cover) changes taking place in Asturias are represented in this Central Area. These changes are essentially rural-urban and rural-industrial, and take place in the main centres of economic activity. Within the study area there are several sub-areas with a specific economic profile (Rodríguez Gutiérrez et al. 2009), which are therefore affected by specific LULC dynamics. For the whole study area, transport infrastructures, and above all roads, are the main drivers of change.
2.2 Data Sets
We selected CORINE and SIOSE as our two data sets (Fig. 2). CORINE (Coordination of Information on the Environment) is a well-known LULC resource that has often been used in modeling studies (Verburg and Overmars 2009; Camacho Olmedo et al. 2013; Renwick et al. 2013). It is updated every six years and covers most European Union countries. This standardized approach allows users to make comparison studies across the EU. Nevertheless, some authors have noted that each member state has its own CORINE team applying slightly different criteria, each of which has produced a CORINE map with a different validity rate (Waser and Schwarz 2006).

LULC for an example area (Lugones-Llanera) as represented by SIOSE (left) and CORINE (right). This area is one of the most dynamic spaces in the study area
The CORINE scale of reference is 1:100,000. It has a minimum mapping unit (MMU) of 25 ha and a minimum polygon width (MPW) (minimum distance between two polygon sides) of 100 m. As a general rule, only changes affecting areas of over 5 ha are drawn. The final product is a map made by photointerpretation in which each polygon is assigned to a single category (classification system) (Hernández 2016).
CORINE is very useful for studies at regional and national levels. However, when studying urban land covers with complex patterns and a heterogeneous nature, this scale may be insufficient (Antrop 2004; Herold et al. 2005). This is also true for studies which require more detailed analysis (Chas-amil and Touza 2015), especially those focusing on local or sub-regional areas.
SIOSE (Sistema de Información sobre Ocupación del Suelo de España—Information System about Land Cover in Spain) is an LULC map made at a scale of 1:25,000. This allows for more detail, with a MMU of between 0.5 and 2 ha depending on the particular land cover (e.g. 0.5 ha for wetlands, 1 ha for urban areas and 2 ha for forests). The MPW in SIOSE is 15 m. Nevertheless, in certain cases SIOSE accepts even lower widths and areas below the specified minimum. This is very important because it makes a big difference in the spatial representation of the terrain, allowing infrastructures such as roads to be represented on the map. These infrastructures create barriers that produce additional divisions of the covers that cannot be seen on maps at smaller scales. When updating SIOSE maps, small changes affecting areas of less than 0.4 ha are not included.
The SIOSE data set has two different parts. Firstly, a polygon map which marks out homogeneous areas with similar characteristics (either single categories or mosaics of various different categories) and secondly, a database which compiles all the land cover information for each polygon without scale restrictions, i.e. each polygon has a log in the database where the different land covers that make up the polygon and their proportions are registered. This database model is called Application Schema (ISO 19101) (ISO/IEC 2014) and this way of gathering information is known as a description system (Hernández 2016).
One of the main advantages of the SIOSE database model is the enormous detail it provides about the earth’s surface. Nevertheless, this wealth of detailed information must be generalized in order to produce a map in which each polygon is allocated to a single class or category, i.e. to move from a description system to a classification system. The resulting map will vary according to the thresholds we use in the generalization process. This introduces uncertainty in the analysis that must be addressed in further research.
Since 2012 the Spanish CORINE has been obtained from a generalization of SIOSE. The new CORINE production method has caused important changes in the CORINE map, which has many striking differences from the previous version (2006). Every time CORINE is updated, the previous map is reviewed. Hence with the updating of CORINE in 2012, the National Geographic Institute of Spain produced a new version of CORINE 2006 that is coherent with CORINE 2012, so enabling comparisons to be made. However, as SIOSE only started in 2005, this retroactive adjustment of CORINE cannot be performed for earlier versions, making it impossible to analyse change over longer periods (from 1990 to 2012).
Both data sets are vector data, which must be rasterized to be used as input in the chosen model (Dinamica EGO). Vector data allows for more precise feature allocation, but modeling is more difficult in this structure because each spatial entity has a different shape and form; e.g. computing neighbourhood interactions is much more complex than with rasters, characterized by a simple, regular shape (Burrough et al. 2015).
In our case study, we have selected the two dates for which both maps were available: 2005–2006 and 2011–2012. As CORINE has been generalized from SIOSE for both these dates, the baseline information is the same for both maps. This enables us to compare the two maps and analyse the changes in Land Use Cover over this period.
Summarizing, the uncertainty arising from the use of diverse data sets is dependent on the following variables: cartographic scale, minimum mapping unit, generalization process and dates.
3 Methodology
We began by adjusting the two data sets (SIOSE and CORINE) to produce two comparable LULC maps with the same legend (see Fig. 3). These maps were then compared to identify any differences between them. Once we had obtained the model inputs, one model was calibrated for each input map using criteria based on expert knowledge. Finally, both models were run to obtain a simulation for the year 2020. Differences between the two simulations were analysed and compared with real changes over the calibration period (2005–2011).

Flowchart of the methodological procedure we followed to produce two calibrated models, one for each input map (SIOSE and CORINE)
3.1 Data Set Processing
SIOSE and CORINE were adjusted to make them comparable (same legend). The legend we chose is a slight modification of the Level 3 CORINE legend, which we simplified in order to focus on the most important types of cover in the study area.
As SIOSE was designed to serve as a basis for the production of CORINE by generalization, there are no significant problems in the equivalence between the two legends; each SIOSE category fits well with the meaning of broader categories in CORINE. The associations between the categories on the two maps were made in accordance with similar category meanings. The definitions of the categories were obtained from the technical guide.
The most crucial step in the processing of the data sets was the generation of a SIOSE map from the numerical information provided in the SIOSE database, that is, the respective proportions of each of the categories that make up each polygon. We have established a set of rules which, for each land cover, establish the thresholds above which a specific proportion of land cover or an association of several land covers with different proportions can be given an individual label (e.g. when three quarters of a polygon is occupied by a particular LULC category, the entire polygon will be allocated to this category).
The final step in the data set treatment was the rasterization of the maps, given that modeling software requires raster data. We chose the resolution following the method established by Tomislav Hengl (2006). Bearing in mind the cartographic scales of the reference maps (1:25,000 and 1:100,000) we opted for a resolution of 12.5 m for SIOSE and 50 m for CORINE.
All this data set processing inevitably introduces uncertainty into the analysis. Even the choice of legend can affect the results of the model (Dietzel and Clarke 2006; Conway 2009). However, this question would be best addressed in additional future research. We have tried to maintain the maximum thematic detail by avoiding introducing external factors (such as thematic resolution) into the analysis.
The vector to raster conversion has also introduced new uncertainty. Comparison of the final raster maps with the vector data has shown a maximum difference per category of 7.6 ha for SIOSE and 22 ha for CORINE, with a mean difference of 3.9 and 1.3 ha respectively. This uncertainty is minimal, although some studies have also noted the important influence of rasterization in the analysed pattern (Dendoncker et al. 2008). Finally, the way we processed the SIOSE maps (generalization) also introduced additional uncertainties.
It is therefore necessary to compare the two input maps in order to distinguish their initial differences from the simulations, differences caused by the fact that the model behaves differently depending on the specific data set being modelled. This analysis was carried out for maps for 2011–12 according to methods explained at the end of this section (Data analysis and assessment).
3.2 Modeling
3.2.1 Modeling Framework
We used the DINAMICA EGO software, which has been widely tried and tested in recent modeling research (Maeda et al. 2011; Ahmed and Bramley 2015). Furthermore, several model comparison studies praised DINAMICA’s architecture and flexibility (Mas et al. 2011; Pérez-Vega et al. 2012; Mas et al. 2014).
It is a stochastic cellular automata model that models transitions through two different functions: expander and patcher. The expander function models new pixels as an expansion of previous patches, whereas the patcher function models one or several new pixels as a new patch for the category. In addition, the model uses the weights of evidence method to produce a probability map of occurrence for each transition. More information about the components of the model and its characteristics can be found in Soares et al. (2002). It is compared with other models in Follador et al. (2008) and in the technical notes at the end of this book.
3.2.2 Model Calibration and Simulation
We set up two models (Fig. 3), one for each of the LULC maps we compared (SIOSE and CORINE). These maps were calibrated against real data for the period 2005-06 – 2011-12, the only available dates. The model then ran a simulation up to the year 2020, which fits well with the short calibration period (six years).
The land covers modelled were the most dynamic artificial (soil-sealing) covers in the study area. We selected the most significant transitions (i.e. those affecting the largest areas of land) during the calibration period (2005-06 – 2011-2012). Usually, a threshold of 10 ha was applied. Different transitions were selected for each model because of the different input maps (SIOSE and CORINE). These measure a different amount of change between categories.
Transition rates were computed by Dinamica Ego using a Markov matrix, which was obtained by comparing LULC maps for the selected dates (2005-06 – 2011-12). Since each pair of LULC maps measure a different amount of change, the transition rates are also dissimilar.
For each transition, we chose a set of driving forces according to information collected in interviews with experts in this field together with information provided by academic studies about the study area (Fernández García et al. 2007; Rodríguez Gutiérrez et al. 2009; Alonso Ibáñez and Pérez Fernández 2012). The selection of explanatory variables was based on expert knowledge, methodological orientation (Pontius Jr. et al. 2008) and the availability of data. Although the drivers were the same for both models, when the source offered the same data at different scales we created separate variables according to the input data scale (Table 1). Therefore, there are slight differences between the two models because of the different scale used in these separate variables.
The models were calibrated using the Weights of Evidence method according to the knowledge provided by the experts we interviewed and information from previous research. When strange or incorrect behaviour was detected, we corrected it manually. Variables with a correlation (Cramer’s Coefficient) greater than 0.5 were discarded according to thresholds established by similar studies (Quiroz Ortuño 2009; Maeda et al. 2011).
The flexibility of the Dinamica modeling framework, which allows the user to manually modify the calculated weights of evidence, enabled us to adjust the model parameters in order to obtain the maximum similarity between the two simulations. Thus, both models were run with the same weights of evidence, according to the expert criteria.
The patcher and expander function parameters (proportion of changes simulated as expansion, patch isometry and patch mean and variance) were established according to the pattern of real changes in the calibration period.
Transition rates for the simulation year (2020) were modified (Table 2) in accordance with the different trends of change forecast for the coming years (economic crisis) in the study area by the experts we interviewed.
Summing up, the two models differ because of the transitions selected, the transition rates (quantity of change), the input data (SIOSE and CORINE maps and driving forces maps) and the expander and patcher parametrization (proportion of changes simulated as expansion, patch isometry and patch mean and variance). However, the land use change logic is the same for both models in that they follow the same methodological procedure with the same drivers of change.
3.3 Data Analysis and Assessment
There is a great deal of academic research about scale and its influence on data. The most frequently used methods include fractal analysis, local variance method, variograms, wavelets or texture analysis methods (Cao and Siu-Ngan Lam 1997; Zong-Guo and Clarke 1997; Oliver 2001). Several studies have also used spatial metrics (Saura 2002; Wu 2004; Uuemaa et al. 2005), which allow us to analyse the effects of the scale of the input maps on the patterns being modelled. Numerous validation techniques have also been created in modeling research (Paegelow et al. 2014). They usually compare simulated maps with real maps in order to assess the fitness of the model. However, they can also be used to compare two maps and highlight their differences. The method proposed by Pontius and Millones (2011) to evaluate quantity and allocation disagreement is a good validation tool to analyse the differences between two maps. It shows two types of error: quantity and allocation (omission and commission) errors.
We compared the input maps (SIOSE and CORINE) and real (2005-6 – 2011-12 cross tabulation) and simulated changes (2011-12 – 2020-21 cross tabulation). When comparing the input maps, we only analysed the land covers that took part in the modelled transitions. When comparing the changes, we only analysed the land covers that are actively modelled (i.e. the categories allocated by the model).
Spatial metrics were calculated using FRAGSTATS 4.2 for the evaluation of the pattern difference between input maps (SIOSE and CORINE maps) as well as for the analysis of the pattern difference between real (2005-6 – 2011-12) and simulated changes (2011-12 – 2020-21). The metrics were selected according to the information that they provided, that is, according to the variability of their results. These metrics are: Total Area, Number of Patches, Largest Patch Index, Weighted Mean Patch Area, Area Coefficient of Variation, Mean Fractal Dimension, Proportion of Like Adjacencies and Patch Cohesion Index. A detailed description of each metric can be found in the FRAGSTATS help guide (McGarigal et al. 2015) and in Leitão et al. (2012).
The matrix proposed by Pontius and Millones was applied for the comparison of input maps and simulated changes. The results highlight the differences between simulations in terms of quantity and allocation disagreement compared with the same disagreements between the SIOSE and CORINE maps.
4 Results
4.1 Quantity Disagreement
4.1.1 Input Maps
There is an important quantity disagreement between the input maps. This disagreement varies from one category to the next, as shown in Fig. 4, where confusion bars represent the confusion of one input map with regard to the other for each category. Each confusion bar is divided into various sections, one for each category on the map. Each section of the bar represents the proportion of pixels that are allocated to a different category on the other map. When the section for any particular category (e.g. arable land) is larger on one confusion bar than on the other, this means that there is a quantity disagreement, which is equal to the difference between the two sections for that category. The rest of the disagreement is allocation disagreement.

Agreement bars for input maps. The first bar depicts the overall components of agreement between the two maps. The second bar depicts the SIOSE disagreements with regard to CORINE, and the third bar depicts the CORINE disagreements with regard to SIOSE
These differences in quantities result from the fact that different minimum mapping units (MMU) were used in the two input maps. When cartographic scale is reduced and the MMU is bigger, the polygons that do not meet the mapping criteria (MMU) must be absorbed by others with similar definitions (generalization process).
Categories with flexible definitions incorporate polygons from other categories and increase their area (e.g. discontinuous urban fabric, forests) whereas categories with rigid definitions lose polygons and their total area diminishes (e.g. areas with sparse vegetation, dump sites). João (2001) called this process “competition for map space”. It results in a disproportionately high representation of categories with flexible definitions and a low representation of categories with rigid definitions in maps at smaller scales with bigger MMU.
The categories that absorb other categories during the generalization process are different for the two input maps (e.g. arable land for CORINE and pastures for SIOSE). This results in large quantity disagreements and allocation disagreements between the maps. This disagreement can be attributed to the use of different criteria in the generalization process for SIOSE (conducted by the author, as explained in Sect. 3.1) and for CORINE (conducted by the National Geographic Institute of Spain, as explained in Sect. 2.2).
4.1.2 Simulated Changes
The simulated changes for the period 2011-12 – 2020-21 show a high degree of quantity confusion as illustrated in the bar chart below (Fig. 5). The simulated changes are greater in SIOSE than in CORINE because when the two calibration maps (2005–2006 and 2011–2012) were compared, there was a larger amount of change in SIOSE than in CORINE. The MMU for SIOSE allows us to detect small changes, in addition to the changes it also detects for CORINE. In consequence, the transition rates (Markov matrix obtained through comparison of the input maps) are greater for SIOSE than for CORINE.

Agreement bars for simulated changes. The first bar depicts the overall components of agreement between the two maps. The second bar depicts the CORINE simulation disagreements with regard to the SIOSE simulation, and the third bar depicts the SIOSE simulation disagreements with regard to the CORINE simulation
4.2 Allocation Disagreement
4.2.1 Input Maps
There is also a significant level of allocation disagreement between the input maps that varies from one category to the next. Mixed categories (complex cultivation patterns and land principally occupied by agriculture) show a high degree of error (Fig. 6). Because of the vague definition of these categories, real covers labelled as such are very different in the two input maps.

Agreement, quantity and allocation disagreement for categories in input maps (SIOSE and CORINE)
Allocation disagreement analysis also provides information about which categories are confused with the quantity disagreement of other categories. We observed for example a relation in the error between pastures and arable lands and between continuous and discontinuous urban fabric. Visual comparison of the two LULC maps have proved this relation: some locations labelled as pastures in one map are classified as arable lands in the other. The same relation can be observed for continuous and discontinuous urban fabric. Therefore, the same covers are assigned to different categories on each map.
The model was set up on the basis of the definitions of the categories and expert knowledge. Same category definitions were considered independent of the model and the same criteria were applied to them. Since the same categories do not represent the same covers in both models, different results were expected in the simulations. e.g. we used the same drivers for the transition from pastures to continuous urban fabric. However, the land allocated to these two categories is different in the two input maps (allocation disagreement in Fig. 6).
4.2.2 Simulated Changes
The agreement between changes in the two simulations is minimum (Fig. 7) and can be attributed purely to chance (Fig. 5). Most of the pixels allocated by the two calibrated models are in different positions.

Agreement bars per category for changes in SIOSE and CORINE simulations. SIOSE and CORINE disagreements refer to changes simulated by each model that do not correspond to the same change in the other model
The disagreement is mostly (94% of total disagreement) related to persistence (i.e. areas with no change) on the other map: 62% of the confusion in the SIOSE simulation is with areas that do not change in the CORINE simulation, whereas 32% of the confusion in the CORINE simulation is with areas that do not change in the SIOSE simulation (Fig. 5). This is because of the allocation disagreement between input maps due to different category definitions, as pointed out in the previous section. The candidate areas (i.e. those in which transition is possible) are different in both models, whereas the drivers of change and therefore the candidate areas in which change is most likely, are very similar.
4.3 Pattern Disagreement
4.3.1 Input Maps
As expected, fragmentation (the number of patches or polygons) is greater in SIOSE than in CORINE (Table 3). The smaller the MMU, the higher the number of patches. And the higher the number of patches, the smaller the weighted mean area (mean area corrected according to polygon size).
Therefore, SIOSE maps have more polygons and smaller polygons than CORINE maps. In consequence, SIOSE has more potential pixels to be modelled as an expansion of previous patches, whereas CORINE is more sensitive to the patcher function. Any new patch modelled in CORINE should meet the MMU criteria. If not, the simulation would result in a more fragmented landscape.
In short, in the case of input maps, more fragmented and complex patterns are expected at larger scales. At these scales the land cover information resembles the real situation more closely. This means that the SIOSE maps are more realistic, but also more complex and there is no relation between complexity and the good performance of the model (Clarke 2004; Wainwright and Mulligan 2013).
4.3.2 Simulated and Real Changes
Real changes (2005–6—2011–12) and simulated changes (2011–12—2020–21) show a different pattern. While the effect of MMU is evident in real changes (fewer and larger changing patches for CORINE), it is practically non-existent in the simulations. The number of CORINE patches increases with the simulation whereas the number of SIOSE patches falls (Table 4).
The proportion of like adjacencies and patch cohesion index, which measure the grouping of patches that belong to the same class (McGarigal et al. 2015), also show different results. Simulated changes are more disaggregated than real changes, especially in the CORINE simulation.
These different patterns between simulated and real changes are a consequence of the logic of the model. The pixel is the essential unit of work of any raster LULC model, such that the location of the first change simulated will be the most suitable pixel for each specific transition. The pixel area is much smaller than the MMU (156 m2 vs. 0.2–0.5 ha in SIOSE and 0.25 ha vs. 25 ha in CORINE). The simulated changes will therefore be characterized by smaller (area-weighted mean patch area), more poorly connected patches (proportion of like adjacencies and patch cohesion index), when compared with the real changes, which are affected by the MMU rules.
The bigger the contrast between the MMU and the spatial resolution (pixel size), the more evident the fragmentation in the simulation. This means that compact input maps are more sensitive to model allocation change than fragmented input maps.
As regards the total area, in both cases, the proportion of modelled changes compared to real changes (Table 4) is higher than the proportion of selected transition rates with regard to original rates (Table 2). This is due to the transition rates function, which estimates the real changes through a Markov Matrix. This introduces a new source of uncertainty into the model. The estimated changes are different depending on the model and method used (Mas et al. 2011).
5 Discussion
5.1 Data Sets Uncertainty
The study area can be displayed in very different ways depending on the cartographic source used, even though they are apparently similar. Previous studies have proved this by analysing several data sets for the same area (Waser and Schwarz 2006; Schmit et al. 2006; Chasamil and Touza 2015).
In our study case, SIOSE and CORINE showed big dissimilarities despite the fact that one map was obtained from the other by generalization. The only differences between the input maps are the cartographic scale, minimum mapping unit (MMU), minimum polygon width (MPW) and generalization criteria. It is these factors therefore that cause the maps to provide dissimilar information.
More transparency is required with regard to the generalization process used in CORINE. Although we have based our SIOSE generalization on CORINE class definitions, as described in its technical specifications, important disagreements appear due to the different generalization criteria. More information about how CORINE was obtained from SIOSE would result in more correspondence between the two maps.
Uncertainty analysis of the input data should be a critical step in modeling research, as shown by Verburg et al. (2011) and Pai and Saraswat (2013). Nevertheless, when addressing this problem of uncertainty, researchers usually present accuracy rates obtained by error analysis based on data gathered in the field. These general rates can vary widely across local areas and categories. This means that the extent and the thematic resolution of the analysis must be chosen carefully.
In our study case, most of the errors come from confusion between the following classes: scrub and grasslands; pastures and agricultural areas; and continuous and discontinuous urban fabric. A simplified legend which grouped these categories together into larger, more broadly-defined classes would remove these errors. This confirms the ideas of Verstegen et al. (2012), who pointed out that uncertainty is usually lower at coarser scales since local changes are omitted. Given that some level of generalization is always needed because of the impossibility of representing the real situation exactly on a scale map, it is sometimes better for input maps to ensure greater accuracy even if this means less detail. Hence, smaller scales and bigger MMU are sometimes preferable.
5.2 Model Parameters
Maps at finer scales (smaller MMU) provide more detailed information and, ergo, show more changes. Consequently, different rates of change and potential transitions are obtained. Similar results have been noted for the analysis of other components of scale such as extent (Bhatti et al. 2015) or thematic resolution (Pontius Jr and Malizia 2004; Conway 2009).
Fine scale maps can be useful for local studies, because they provide essential detailed information about local dynamics (Wang and Marceau 2013; Zhao 2013). However, the probability of error as noise in maps at finer scales is higher. The probability of introducing this noise into the model is also greater (Blanchard et al. 2015).
At finer scales, transitions rarely occur alone and different processes or transitions happen simultaneously (Wang and Marceau 2013). The patterns of change are also more complex. This makes calibration of the model more challenging and errors more likely. Sometimes simpler models work better (Clarke 2004; Wainwright and Mulligan 2015). In fact, if the drivers of change are simple and we cannot explain the local changes, as in SIOSE, input maps at coarser scales and with bigger MMU are advisable.
Applying the same criteria to the two calibrated models results in different simulated changes because the models do not show the same dynamics. More detailed knowledge is required to enable the model to be properly calibrated with SIOSE data since the experts only considered the main dynamics in the study area and, therefore, ignored most of the small changes. However, CORINE mapping rules do not fit well with the size of most of the changes in the area. Neither system offers a perfect data set and consequently the modeller must try to strike a balance between generality, precision and realism (O’Sullivan and Perry 2013).
Explanatory drivers of change vary with the scale (Verburg et al. 2003; Moreira et al. 2009; Bhatti et al. 2015). However, in this case the two scales of analysis (both local-regional) are too similar to be affected by contrasting driving forces. Nonetheless, additional driving forces could be included in the model with SIOSE as input maps because of the additional local processes involved in this model.
Explanatory factors were the same for both models and the maps were very similar: same source but different scale. The variations resulting from these different scales are essentially a question of the degree of precision in the location of attributes. Consequently, the areas with the greatest transition potential for each land cover are similar in both models despite the substantial differences in land cover information. As a result, an area with high transition potential could be located under a particular land cover in one model and under a different one in the other. This results in significant incoherence between LULC maps and driving forces. Making driver maps from LULC maps is an alternative way to achieve coherence in the datasets that define the model. However, this would limit the variety of drivers.
5.3 Modelled Pattern
The changes in the LULC pattern are similar in both models, regardless of the MMU. The simulated pattern is always more fragmented than the initial pattern and this is more obvious when the pattern of the initial map is more compact.
As explained in Sect. 4.3.2, model allocation function allocates changes as pixels whereas input maps only measure changing polygons that meet the MMU criteria. Input map resolutions do not fit the MMU rules. Consequently, the simulated landscape is more fragmented than the real one and this is clearer for the CORINE simulation because of its larger MMU.
The patcher and expander functions of DINAMICA can be parametrized (mean area and variance of simulated polygons) to achieve the simulation pattern we want. Although some studies have proved effective (Soares-Filho et al. 2003), this did not work in our study area. The transitions modelled are only possible when there is a suitable area (obtained from the drivers) inside the polygons of the destination category for the transition. If this happens, the model then considers the user’s parameters. Suitable areas for specific transitions are going to be smaller in models at large scales (smaller MMU) than in models at coarse scales (bigger MMU) because of the respective size of the polygons in each model. It is therefore more difficult to vary the modelled patterns in models with fine scales.
Finer resolution models show problems in the allocation process because real changes tend to take place in a group of pixels. Models at coarser resolutions are more suited to deal with these problems (Kocabas and Dragicevic 2006; Blanchard et al. 2015). Thus, there is a relation between the behaviour we observed in our models and their spatial resolution, which is related to the cartographic scale and MMU of the input data. Although the rasterization method we followed (Hengl 2006) links the chosen spatial resolution with the cartographic scale and the MMU, there is still an inconsistency between the two in the model. Some authors have proposed patch-based models to solve this problem (Wang and Marceau 2013). There is also a wide body of literature about spatial resolution influence in LULC modeling (mainly CA-based models), which reaches similar conclusions (Marceau et al. 2005; Pan et al. 2010; Blanchard et al. 2015).
5.4 Allocation Differences
Although one might imagine that the higher quantity of change detected by input maps would result in a simulation that was closer to the true situation, this is not always the case. The transition rates could result from changes caused by different processes. However, the driving forces defining the most likely transition areas were the same for both models. As a result, the model at finer scale (SIOSE) could extrapolate changes from one process to changes from other processes, e.g. both simulations allocated changes in ‘Dump sites’ in the area around the central dump in Asturias, forecasting expansion of this dump. Over the calibration period CORINE only detected changes in this area, while SIOSE also detected changes in other parts of the study area, resulting from other processes such as road building works.
Regarding the spatial resolution, models at finer spatial resolutions simulate more pixels than models at coarser spatial resolutions. This means that the possibility of error in the two models is different. The larger the quantity of pixels to allocate, the more likely the model is to make a mistake. Validation is therefore dependent on the spatial resolution of the model. We must not compare errors in models with different spatial resolutions.
Finally, the difference between pixel-based modeling and MMU rules must also be borne in mind in the validation step. Many models are validated by LULC maps that follow MMU rules (Paegelow and Olmedo 2005; Pontius Jr. and Malanson 2005; Pérez-Vega et al. 2012). Changes that do not obey these rules do not appear on the map. However, changes simulated by the model will be located in the most suitable area, regardless of the minimum area of these changes. This means that real changes could be considered as errors in validation analysis.
6 Conclusion and Outlook
Model results can vary greatly depending on the cartographic scale and minimum mapping unit of the input data.
Most of the uncertainty comes from the differences between the input maps. The choice of a suitable cartographic source is therefore crucial. In-depth research must be done on this issue, comparing different cartographic sources and their influence on land cover representation. Great care must also be taken with the generalization of LULC maps, since most of their dissimilarities result from different generalization criteria.
Minimum mapping unit affects the quantities of change obtained and selected transitions since maps with smaller MMU measure more changes and more varied ones. This makes the resulting model more complex. If the user cannot manage this complexity properly, it will produce more uncertainty, because most of the analysed change is not interpreted in the model. Thus, the modeller must strike a balance between model complexity and its explanatory power.
Modelled patterns are also dependent on spatial resolution. This is linked with the minimum mapping unit: small MMU imply finer spatial resolution than larger units. Big differences between pixel size and MMU result in more fragmented scenarios. Patch-based models can be a solution to this problem.
Other components of scale, such as extent or thematic resolution, also influence modeling results and changes in these components could help resolve some of the problems we encountered, such as LULC input map disagreement. Therefore, in-depth research must focus on the influence of scale in modeling and, especially, on the relation between the different meanings of scale and their general influence on modeling.
References
Agarwal C, Green GM, Grove JM, et al (2002) A review and assessment of land-use change models: dynamics of space, time, and human choice. Newtown
Ahmed S, Bramley G (2015) How will Dhaka grow spatially in future? Modelling its urban growth with a near future planning scenario perspective. Int J Sustain Built Environ 4:359–377. doi:10.1016/j.ijsbe.2015.07.003
Alonso Ibáñez M rosario, Pérez Fernández JM (2012) Espacio metropolitano y difusión urbana: su incidencia en el medio rural. Consejo Económico y Social del Principado de Asturias, Oviedo
Antrop M (2004) Landscape change and the urbanization process in Europe. Landsc Urban Plan 67:9–26. doi:10.1016/S0169-2046(03)00026-4
Bhatti SS, Tripathi NK, Nitivattananon V et al (2015) A multi-scale modeling approach for simulating urbanization in a metropolitan region. Habitat Int 50:354–365. doi:10.1016/j.habitatint.2015.09.005
Blanchard SD, Pontius RG Jr, Urban KM (2015) Implications of Using 2 m versus 30 m spatial resolution data for suburban residential land change modeling. J Environ Inform 25:1–13. doi:10.3808/jei.201400284
Burrough PA, McDonnell RA, Lloyd CD (2015) Principles of geographical information systems. OUP, Oxford
Camacho Olmedo MT, Paegelow M, Mas JF (2013) Interest in intermediate soft-classified maps in land change model validation: suitability versus transition potential. Int J Geogr Inf Sci 27:2343–2361. doi:10.1080/13658816.2013.831867
Cao C, Siu-Ngan Lam N (1997) Understanding the scale and resolution effects in remote sensing and GIS. In: Quattrochi DA, Goodchild MF (eds) Scale in remote sensing and GIS. CRC Press, pp 57–72
Carrero de Roa M (2012) Transformaciones en los espacios rururbanos del área metropolitana de asturias. Espacio metropolitano y difusión urbana: su incidencia en el medio rural. Consejo Económico y Social del Principado de ASturias, Oviedo, pp 135–154
Castilla G, Larkin K, Linke J, Hay GJ (2009) The impact of thematic resolution on the patch-mosaic model of natural landscapes. Landsc Ecol 24:15–23. doi:10.1007/s10980-008-9310-z
Chas-amil ML, Touza J (2015) Assessment of the Spanish land cover information to estimate forest area in Galicia. Boletín la Asoc Geógrafos Españoles 69:333–350
Clarke KC (2004) The limits of simplicity: toward geocomputational honesty in urban modeling. In: Atkinson P, Foody G, Darby S, Wu F (eds) Geodynamics. CRC Press, Boca Raton, pp 215–232
Committee on Needs and Research Requirements for Land Change Modeling, Geographical Sciences Committee, Board on Earth Sciences and Resources et al (2014) Advancing land change modeling. National Academies Press, Washington, DC
Conway TM (2009) The impact of class resolution in land use change models. Comput Environ Urban Syst 33:269–277. doi:10.1016/j.compenvurbsys.2009.02.001
Dendoncker N, Schmit C, Rounsevell M (2008) Exploring spatial data uncertainties in land-use change scenarios. Int J Geogr Inf Sci 22:1013–1030. doi:10.1080/13658810701812836
Dietzel C, Clarke K (2006) The effect of disaggregating land use categories in cellular automata during model calibration and forecasting. Comput Environ Urban Syst 30:78–101. doi:10.1016/j.compenvurbsys.2005.04.001
Fernández García A, Ortega Montequín M, Sevilla Álvarez J et al (2007) Población, administración y territorio en Asturias. Consejo Económico y Social del Principado de Asturias, Oviedo
Follador M, Villa N, Paegelow M (2008) Tropical deforestation modelling: comparative analysis of different predictive approaches. The case study of Peten, Guatemala. In: Paegelow M, Camacho Olmedo MT (eds) Modelling environmental dynamics. Springer, Berlin, Heidelberg, pp 77–107
Hengl T (2006) Finding the right pixel size. Comput Geosci 32:1283–1298. doi:10.1016/j.cageo.2005.11.008
Hernández JD (2016) Methodology of classification extraction from descriptive systems of land cover and land use
Herold M, Couclelis H, Clarke KC (2005) The role of spatial metrics in the analysis and modeling of urban land use change. Comput Environ Urban Syst 29:369–399. doi:10.1016/j.compenvurbsys.2003.12.001
Houet T, Verburg PH, Loveland TR (2010) Monitoring and modelling landscape dynamics. Landsc Ecol 25:163–167. doi:10.1007/s10980-009-9417-x ISO/IEC (2014) ISO 19101-1. 48
João E (2001) Measuring scale effects caused by map generalization and the importance of displacement. In: Tate NJ, Atkinson PM (eds) Modelling scale in geographical information science. Wiley, Chichester, New York, Weinheim, Brisbane, Singapore, Toronto, pp 161–179
Kocabas V, Dragicevic S (2006) Assessing cellular automata model behaviour using a sensitivity analysis approach. Comput Environ Urban Syst 30:921–953. doi:10.1016/j.compenvurbsys.2006.01.001
Lam NS-N, Quattrochi D (1992) On the issues of scale, resolution, and fractal analysis in the mapping sciences. Prof Geogr 44:88–98. doi:10.1111/j.0033-0124.1992.00088.x
Leitão AB, Miller J, Ahern J, McGarigal K (2012) Measuring landscapes: a planner’s handbook. Island press, Washington, Covelo, London
Lesschen JP, Verburg PH, Staal SJ (2005) Statistical methods for analysing the spatial dimension of changes in land use and farming systems. Citeseer
Maeda EE, de Almeida CM, de Carvalho Ximenes A et al (2011) Dynamic modeling of forest conversion: Simulation of past and future scenarios of rural activities expansion in the fringes of the Xingu National Park, Brazilian Amazon. Int J Appl Earth Obs Geoinf 13:435–446. doi:10.1016/j.jag.2010.09.008
Marceau DJ, others, Ménard A, Marceau DJ (2005) Exploration of spatial scale sensitivity in geographic cellular automata. Environ Plan B Plan Des 32:693–714. doi:10.1068/b31163
Mas J-F, Kolb M, Houet T et al (2011) Éclairer le choix des outils de simulation des changements des modes d’occupation et d’usages des sols. Une approche comparative. Rev Int Géomatique 21:405–430. doi:10.3166/RIG.15.297-322
Mas J-F, Kolb M, Paegelow M et al (2014) Inductive pattern-based land use/cover change models: A comparison of four software packages. Environ Model Softw 51:94–111. doi:10.1016/j.envsoft.2013.09.010
McGarigal K, Cushman SA, Neel MC, Ene E (2015) FRAGSTATS: spatial pattern analysis program for categorical and continuous maps
Ménard A, Marceau DJ (2005) Exploration of spatial scale sensitivity in geographic cellular automata. Environ Plan B Plan Des 32:693–714. doi:10.1068/b31163
Moreira E, Costa S, Aguiar AP et al (2009) Dynamical coupling of multiscale land change models. Landsc Ecol 24:1183–1194. doi:10.1007/s10980-009-9397-x
O’Sullivan D, Perry GLW (2013) Spatial simulation: exploring pattern and process. Wiley, Chichester
Oliver MA (2001) Determining the spatial scale of variation in environmental properties using the variogram. In: Modelling scale in geographical information science, pp 193–219
Paegelow M, Camacho Olmedo MT, Mas J-F, Houet T (2014) Benchmarking of LUCC modelling tools by various validation techniques and error analysis. Cybergeo. doi:10.4000/cybergeo.26610
Paegelow M, Olmedo MTC (2005) Possibilities and limits of prospective GIS land cover modelling—a compared case study: Garrotxes (France) and Alta Alpujarra Granadina (Spain). Int J Geogr Inf Sci 19:697–722. doi:10.1080/13658810500076443
Pai N, Saraswat D (2013) Impact of land use and land cover categorical uncertainty on SWAT hydrologic modeling. Trans ASABE 56:1387–1397. doi:10.13031/trans.56.10062
Pan Y, Roth A, Yu Z, Doluschitz Reiner R (2010) The impact of variation in scale on the behavior of a cellular automata used for land use change modeling. Comput Environ Urban Syst 34:400–408. doi:10.1016/j.compenvurbsys.2010.03.003
Pérez-Vega A, Mas J-F, Ligmann-Zielinska A (2012) Comparing two approaches to land use/cover change modeling and their implications for the assessment of biodiversity loss in a deciduous tropical forest. Environ Model Softw 29:11–23. doi:10.1016/j.envsoft.2011.09.011
Pontius RG Jr, Boersma W, Castella J-C et al (2008) Comparing the input, output, and validation maps for several models of land change. Ann Reg Sci 42:11–37. doi:10.1007/s00168-007-0138-2
Pontius RG Jr, Malanson J (2005) Comparison of the structure and accuracy of two land change models. Int J Geogr Inf Sci 19:243–265. doi:10.1080/13658810410001713434
Pontius Jr. RG, Malizia NR (2004) Effect of category aggregation on map comparison. In: Geographic information science. Springer, pp 251–268
Pontius RG Jr, Millones M (2011) Death to Kappa: birth of quantity disagreement and allocation disagreement for accuracy assessment. Int J Remote Sens 32:4407–4429. doi:10.1080/01431161.2011.552923
Quattrochi DA, Emerson CW, Siu-Ngan Lam N, Qui H (2001) Fractal characterization of multitemporal remote sensing data. In: Tate NJ, Atkinson PM (eds) Modelling scale in geographical information science. Wiley, Chichester, New York, Weinheim, Brisbane, Singapore, Toronto, pp 13–34
Quattrochi DA, Goodchild MF (1997a) Scale, multiscaling, remote sensing, and GIS. In: Quattrochi DA, Goodchild MF (eds) Scale in remote sensing and GIS. CRC Press, pp 1–11
Quattrochi DA, Goodchild MF (1997b) Scale in remote sensing and GIS. CRC Press
Quiroz Ortuño Y (2009) Modelo dinámico de cambio de cobertura y uso del suelo en una zona de transición urbano-rural, entre la ciudad de Morelia y el ejido Jesús del Monte. Universidad Autónoma de México
Renwick A, Jansson T, Verburg PH et al (2013) Policy reform and agricultural land abandonment in the EU. Land Use Policy 30:446–457. doi:10.1016/j.landusepol.2012.04.005
Rodríguez Gutiérrez F, Menéndez Fernández R, Blanco Fernández J (2009) El área metropolitana de Asturias. Ciudad Astur: el nacimiento de una estrella urbana en Europa. Trea, Oviedo
Saura S (2002) Effects of minimum mapping unit on land cover data spatial configuration and composition. Int J Remote Sens 23:4853–4880. doi:10.1080/01431160110114493
Schmit C, Rounsevell MD a., La Jeunesse I (2006) The limitations of spatial land use data in environmental analysis. Environ Sci Policy 9:174–188. doi:10.1016/j.envsci.2005.11.006
Soares-Filho BS, Cerqueira GC, Pennachin CL (2002) DINAMICA—a stochastic cellular automata model designed to simulate the landscape dynamics in an Amazonian colonization frontier. Ecol Modell 154:217–235. doi:10.1016/S0304-3800(02)00059-5
Soares-Filho BS, Corradi Filho L, Cerqueira GC, Leite Araujo W (2003) Simulating the spatial patterns of change through the use of the dinamica model. In: XI Simpósio Brasileiro de Sensoriamento Remoto - SBSR. Belo Horizonte, pp 721–728
Turner MG, O’Neill RV, Gardner RH, Milne BT (1989) Effects of changing spatial scale on the analysis of landscape pattern. Landsc Ecol 3:153–162. doi:10.1007/BF00131534
Uuemaa E, Roosaare J, Mander Ü (2005) Scale dependence of landscape metrics and their indicatory value for nutrient and organic matter losses from catchments. Ecol Indic 5:350–369. doi:10.1016/j.ecolind.2005.03.009
van Delden H, van Vliet J, Rutledge DT, Kirkby MJ (2011) Comparison of scale and scaling issues in integrated land-use models for policy support. Agric Ecosyst Environ 142:18–28. doi:10.1016/j.agee.2011.03.005
Verburg P, Schot P, Dijst M, Veldkamp A (2004) Land use change modelling: current practice and research priorities. GeoJournal 61:309–324. doi:10.1007/s10708-004-4946-y
Verburg PH, de Groot WT, Veldkamp AJ (2003) Methodology for multi-scale land-use change modelling: concepts and challenges. In: Dolman AJ, Verhagen A, Rovers CA (eds) Global environmental change and land use. Springer, Dordrecht, pp 17–51
Verburg PH, Neumann K, Nol L (2011) Challenges in using land use and land cover data for global change studies. Glob Chang Biol 17:974–989. doi:10.1111/j.1365-2486.2010.02307.x
Verburg PH, Overmars KP (2009) Combining top-down and bottom-up dynamics in land use modeling: exploring the future of abandoned farmlands in Europe with the Dyna-CLUE model. Landsc Ecol 24:1167–1181. doi:10.1007/s10980-009-9355-7
Verstegen JA, Karssenberg D, van der Hilst F, Faaij A (2012) Spatio-temporal uncertainty in spatial decision support systems: a case study of changing land availability for bioenergy crops in Mozambique. Comput Environ Urban Syst 36:30–42. doi:10.1016/j.compenvurbsys.2011.08.003
Wainwright J, Mulligan M (2013) Environmental modelling: finding simplicity in complexity, 2nd edn. Wiley, New York
Wang F, Marceau DJ (2013) A patch-based cellular automaton for simulating land-use changes at fine spatial resolution. Trans GIS 17:828–846. doi:10.1111/tgis.12009
Waser LT, Schwarz M (2006) Comparison of large-area land cover products with national forest inventories and CORINE land cover in the European Alps. Int J Appl Earth Obs Geoinf 8:196–207. doi:10.1016/j.jag.2005.10.001
Wu J (2004) Effects of changing scale on landscape pattern analysis: scaling relations. Landsc Ecol 19:125–138. doi:10.1023/B:LAND.0000021711.40074.ae
Wu J, Qi Y (2000) Dealing with scale in landscape analysis: an overview. Ann GIS 6:1–5. doi:10.1080/10824000009480528
Zhao G (2013) Effects of spatial scale in cellular automata model for land use change. In: Gaol FL (ed) Recent progress in data engineering and internet technology. Springer, Berlin, Heidelberg, pp 101–106
Zong-Guo X, Clarke KC (1997) Approaches to scaling of geo-spatial data. In: Quattrochi DA, Goodchild MF (eds) Scale in remote sensing and GIS. CRC Press, pp 309–360
Acknowledgements
This work has been supported in part by project SIGEOMOD_2020, BIA2013-43462-P (Spanish Ministry of Economy and Competitiveness and the Feder European Regional Development Fund). The author is also grateful to the Spanish Ministry of Economy and Competitiveness and the European Social Fund for the funding of his research activity (Ayudas para contratos predoctorales para la formación de doctores 2014).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2018 Springer International Publishing AG
About this chapter
Cite this chapter
García-Álvarez, D. (2018). The Influence of Scale in LULC Modeling. A Comparison Between Two Different LULC Maps (SIOSE and CORINE). In: Camacho Olmedo, M., Paegelow, M., Mas, JF., Escobar, F. (eds) Geomatic Approaches for Modeling Land Change Scenarios. Lecture Notes in Geoinformation and Cartography. Springer, Cham. https://doi.org/10.1007/978-3-319-60801-3_10
Download citation
DOI: https://doi.org/10.1007/978-3-319-60801-3_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-60800-6
Online ISBN: 978-3-319-60801-3
eBook Packages: Earth and Environmental ScienceEarth and Environmental Science (R0)