
Abstract
Injuries in cervical spine X-ray images are often missed by emergency physicians. Many of these missing injuries cause further complications. Automated analysis of the images has the potential to reduce the chance of missing injuries. Towards this goal, this paper proposes an automatic localization of the spinal column in cervical spine X-ray images. The framework employs a random classification forest algorithm with a kernel density estimation-based voting accumulation method to localize the spinal column and to detect the orientation. The algorithm has been evaluated with 90 emergency room X-ray images and has achieved an average detection accuracy of 91% and an orientation error of 3.6\(^{\circ }\). The framework can be used to narrow the search area for other advanced injury detection systems.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
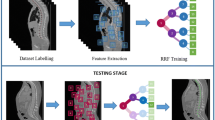
The cervical spine is vulnerable to high-impact accidents like automobile collision, sports mishaps and falls. Due to the scanning time required, cost, and the position of the spine in the human body, X-ray is the first mode of investigation for cervical spine injuries. Unfortunately, roughly 20% of cervical vertebrae related injuries remain undetected by emergency physicians and about 67% of these missing injuries result in tragic consequences like loss of motor control, disability to move the neck and other neurological deteriorations [1, 2]. Providing emergency physicians with an automated analysis of the cervical X-ray images has a great potential to reduce the chances of missing injuries. Towards that goal, this paper takes the first step to localise the cervical spine in an arbitrary X-ray image. Our method involves a machine learning process which employs a patch based framework to localize the vertebrae column. It is also able to predict the orientation of the spinal curve.
Some limited work has been presented in the literature for global localization of the cervical spine on X-ray images. Most of the methods revolve around the generalized Hough transform (GHT). Tezmol et al. [3] used a GHT based framework using mean vertebra templates and an innovative voting accumulator structure. A more recent work [4], proposed another template matching based approach relying on GHT which involves a training phase. In contrast, our work is designed as a machine learning classification problem and votes are accumulated, then refined in a novel fashion to generate a bounding box.
Random forest is a popular machine learning algorithm [5]. It has been used in recent vertebra related literature [6,7,8,9,10,11]. Glocker et al. presented a random regression forest based localization and identification framework for vertebrae in arbitrary CT scans [10]. They proposed another framework using random classification forest which have shown better performance in localizing and identifying vertebrae with pathological cases [11]. Our work also uses random classification forest. But instead of localizing and identifying each vertebrae, it finds the global position and orientation of the vertebral column in cervical X-ray images.
The recent work by Bromiley et al. [6], demonstrated a segmentation method based on constrained local model (CLM) and random forest regression voting (RFRV). Like other statistical shape model (SSM)-based approaches [7, 12], this work also requires initialization of the mean shape near the actual vertebra. The initialization is usually done with help of manual click points [6, 12] or other automatic methods [7]. Random regression forest-based initialization method described in [7] requires a bounding box from where the input features are collected. In their work, the bounding box around the vertebrae curve is generated using hard parameters which are empirically found based on the training images. In our work, we propose an automatic way to locate the vertebrae column in X-ray images.
In this work, 90 cervical X-ray images of emergency room patients were evaluated. The images contain a total of 450 cervical vertebrae (C3–C7). A random forest is trained to distinguish between vertebra and non-vertebra image patches from the images. The task is designed as a binary classification problem: vertebra and non-vertebra. The framework employs a two-stage coarse-to-fine approach. In the first coarse localization stage, a sliding window sparsely scans a test image to vote for vertebrae patches. After this sparse voting, an accumulation phase converts the votes into a bounding box which indicates the position of the spinal column inside the image. The fine localization stage scans the resultant bounding box of the first stage densely with different patch sizes and orientations. The same voting accumulation phase is applied again and a refined bounding box is generated. The angle of this bounding box determines the predicted orientation of the vertebrae column. Even on a dataset of emergency room X-ray images, 91% of the vertebrae area has been detected under the first stage bounding box and an average error of 3.6\(^{\circ }\) has been achieved for orientation prediction with the second stage bounding box.
2 Data
Our dataset of 90 lateral view emergency room X-ray images was collected from the Royal Devon and Exeter Hospital, and consists of patients exhibiting symptoms, ranging from pain to serious trauma. Different radiography systems were used. The resolution of the images were in the range from 0.1 to 0.194 mm per pixel and the exposure time varied from 16 to 345 ms. The ages of the patients were in the range from 18 to 91. All the scans were digital and taken in 2014–15. These images were anonymized and collected through appropriate procedures to be used for research.
Along with the data, our partners at University of Exeter have also provided manual segmentations of the vertebrae. A set of 20 landmark (LM) points per vertebra was annotated by experts in the field and these annotations were used in training and to evaluate the performance of our algorithm quantitatively. Figure 1a shows example images from our dataset and Fig. 1b shows manual segmentation points on a spine. For this work, vertebra C3 to C7 are considered. C1 and C2 are not studied as their appearance is ambiguous in lateral cervical X-ray images.

(a) X-ray images in the dataset. (b) Manual segmentation points.
3 Methodology
The localization framework is based on the detection of vertebrae patches in the images. The detection is done by image patches where a machine learning algorithm decides whether the patch belongs to a vertebra or not. To learn this, a random classification forest [5] has been used. Image patches are generated from the image datasets and labelled into vertebra class and non-vertebra class. The patches are considered with different patch sizes and patch orientations. To generate positive patches, the manual segmentation of the vertebra points is used. The center of the vertebra is used as an anchor point on which different sizes and orientations are considered for training. In order to generate patches for the non-vertebra class, 50% of the patches are considered from both sides of the vertebral column and the rest are collected from other areas of the image. Figure 2a shows the areas from which the positive and negative patches are collected; positive patches are collected from the green box, 50% of the negatives patches are collected from the blue boxes and other negative patches are collected from the remainder of the image randomly. More importance is provided in the areas adjacent to the vertebral column for negative patch creation so that the forest has a better opportunity to distinguish these areas. These image patches are then converted to structured forest (SF) feature vectors [13, 14]. This feature vector collects gradient magnitude and orientation information at different scales and angles. This feature vector recently has shown outstanding performance on the edge detection problem [14]. As vertebrae patches are mostly filled with edge-like structures, this feature vector is chosen. Once the feature vectors and corresponding binary output labels are ready, a random classification forest is trained on the data.

(a) Area of positive patches (green box) and area of 50% of the negative patches (blue boxes). (b) Positive patch boundaries around a vertebra with different orientations and sizes. (Color figure online)
3.1 Stage 1: Coarse Localization
At test time, a new image is fed into the framework for localization. A set of test points is generated on the image at fixed step size (\(S_1\)). A single orientation 0\(^\circ \) (\(O_1\)) and a fixed patch size, \(P_1\), is considered to generate image patches, one at each of the test points. The generated image patches overlap neighbouring image patches. The amount of overlapping is controlled by the parameters \(S_1\) and \(P_1\). These patches are fed into the forest. The forest determines which test points belong to vertebrae. These positive predicted points, \(\varvec{x}_i\)s, are then passed to the vote accumulation phase to generate a bounding box.
Vote Accumulator: The vote accumulator adds a Gaussian kernel at each of the positive votes. The bandwidth, t, of these kernels are automatically estimated using a diffusion-based technique proposed by Botev et al. [15]. This method allows the bandwidth (t) to change dynamically based on the vote distribution from image to image. The resultant distributions are then added together to form a single distribution, F, over the image space.
where N is the number of total positive votes coming to the accumulator.

(a) Positive votes on the image. (b) Resultant distribution F. (c) F after binarization. (d) F after elimination of invalid areas with the minimum bound parallelogram.
This distribution over the image space is converted to a binary image, B, by dynamic thresholding (Eq. 2). The resulting binary image may be divided into a number of parts, \(B_j\)s (Fig. 3c). The area of these parts are measured (\(A_j\)) and weighted (\(w_j\)) based on the distance from the image center (\(C_{image}\)) to the centroid of the concerned image part (\(C_{B_j}\)). As the images are taken to diagnose cervical vertebrae related injuries, the assumption is that the spine should be located near the image center, not at any extreme corner of the image. Then some of these areas are eliminated if they are small enough or located far from any adjacent areas (Eq. 6). This process reduces the chance of misdetection, for example, the area in the skull region of Fig. 3c. Finally, a minimal bounding parallelogram is generated to enclose the rest of areas [16]. This parallelogram is the output of the coarse localization stage. The process is summarized in Fig. 3.
where \(F_t = K\times max(F)\) and K is an empirically chosen constant. As max(F) is different for different images, \(F_t\) dynamically changes accordingly.
where \(j = 1, 2, ..., M\); M is the number of disconnected areas in B and \(C_a\) denotes the centroid of the area a. In Fig. 3c \(M = 3\).
where \(A_t\) and \(d_j\) are the empirical area and distance threshold respectively.
where mBP computes the minimum bound parallelogram enclosing the valid \(B_j\)s [16] and O is the number of valid disconnected areas. In Fig. 3d \(O = 2\).
3.2 Stage 2: Fine Localization
The previous stage is a single resolution single orientation phase, thus less probable to find vertebra with uncommon orientation or size. As the bounding box of the previous stage is only meant to find the approximate area covered by the vertebra, coarse localization is enough. But in order to find the orientation of the vertebrae curve, a finer localization with multiple patch resolutions and orientations is necessary. In this stage, a new set of test points is created within the coarse localization bounding box, with varying step sizes, \(S_2\). At each test point, multiple patches are generated with different patch sizes (\(P_2\)) and angles (\(O_2\)). Then the same random forest patch classification and vote accumulation phase are conducted. This creates a refined bounding box within the first stage bounding box. The orientation angle of this smaller bounding box is computed as the orientation of the vertebrae column.
4 Experiment and Results
To train the random classification forest, different sizes and orientations of the image patches have been considered. The orientation of the patch is defined as the rotation of the angle from the mean vertebral axis. To train the forest, 7 different patch sizes with a step of 0.5 mm (starting from the vertebra size) and 19 orientations of −45\(^{\circ }\) to +45\(^{\circ }\) with a step of 5\(^{\circ }\) have been used. From the 450 cervical vertebrae of our dataset, a total of \(450 \times 7 \times 19 = 59,850\) vertebra (positive) images patches were generated. To balance the data, equal numbers of non-vertebra patches were generated from the rest part of each image. Each these image patches was converted to a SF feature vector of length 6116.
The random forest has a number free parameters: maximum allowable tree depth (nD), minimum number of sample at a node (nMin), number of trees (nTree) and number of variables to test at node split (nVar) and number of thresholds to choose from (nThresh). To find optimum parameters, a sequential parameter search has been applied to a fixed set of training and test images from the dataset. Final parameters are reported in Table 1. To measure the performance of the trained forest, a ten-fold cross-validation scheme is followed. For each fold, 10% of the images are considered as test images and others are used for forest training. Table 2 reports the patch classification accuracies of each forest.
The localization framework also has a set of free parameters mentioned in Sects. 3.1 and 3.2 which are empirically chosen and reported in Table 1. The localization algorithm has been applied on all the images and for each image, the forest was chosen from the ten forests such that the test image is not used in training. We have reported two metrics for the coarse localization bounding box: (1) Average percentage of vertebrae area covered inside the bounding box and (2) Average percentage of landmark points falling outside the bounding box. The orientation of the second stage bounding box is calculated based on the angle of the longer axis of the parallelogram with the horizontal axis. The ground truth orientation is measured by a smallest possible parallelogram that covers the manual annotations (Fig. 4a). The error is calculated by the absolute different between the ground truth orientation and predicted orientation in degrees (\(^{\circ }\)). The results are reported in Tables 3 and 4. Overall 91% of the vertebra area fell inside the predicted bounding box. Only 12% of the landmark points were outside the box. The best performance is achieved by the vertebra C4 at 99%, followed by C3 and C5 both at 97%. The performance is worse as we go down the spine, C6 reports 92% and C7 69%. In terms of percentage of landmark points falling outside the bounding box, from C3 to C7, the numbers are 7%, 2%, 4%, 11%, and 37%. Figure 5 demonstrates the metrics graphically. Almost 80% of the vertebrae have no parts of it outside the bounding box. In terms of landmark points, 70% the vertebrae have no LM points outside the bounding box and about 80% have less than three points out of 20 LM points (15%).
The orientation error metric can be computed in two ways. One with all the vertebrae (ALMP), C3–C7, the other with only the landmark points that fall inside the bounding box of the first stage (FLMP). As the second stage can only use the information what’s inside the first stage bounding box, the later seems more fair to judge its ability. When considering all the vertebra the average error is 4.59\(^{\circ }\) while the other results in an average of 3.6\(^{\circ }\). For the coarse localization bounding box the average errors are larger: 8.16\(^{\circ }\) and 6.26\(^{\circ }\) respectively.

(a) Manual annotation points and ground truth bounding box (green). (b)–(p) Coarse (blue) and fine (cyan) localization bounding boxes. (p) An example of the ongoing vertebral curve detection method (magenta). (Color figure online)
Table 5 reports the average Dice coefficient, sensitivity (true positive rate) and specificity (true negative rate) of the coarse and fine localization bounding boxes. These metrics are computed by comparing the ground truth bounding box (Fig. 4a) with predicted bounding boxes. The Dice coefficient for coarse localization bounding box averages at 0.62 where it stands at 0.69 for the fine localization bounding box. However in terms of sensitivity, the first stage bounding box scores 0.88 while the second stage bounding box scores only 0.62. Specificity is high for both bounding boxes: 0.97 for coarse localization and 0.99 for fine localization.

Percentage of area and landmark points outside the coarse localization bounding box.
5 Discussion and Conclusion
In this work, a coarse to fine cervical spine localization algorithm has been evaluated on a set of 90 emergency room X-ray images. The algorithm is based on a random forest patch classifier which distinguishes between the vertebra and the non-vertebra image patches. Based on the centers of vertebra patches on a test image, a novel vote accumulator converts the votes into a bounding box. A second multi-resolution multi-orientation patch classification is applied inside the initial bounding box to determine the orientation of the vertebral column. The resultant coarse localization bounding box covers 91% of the all vertebral area on an average with a maximum of 99% for vertebra C4. C4’s location on the spine is key to the increased accuracy. On average only 12% of the landmark points fell outside the bounding box, most of which are from the lowest vertebra, C7, where the image quality is often reduced.
While coarse localization creates a larger bounding box, the fine localization creates a smaller and refined bounding box. This bounding box predicts the orientation of the spinal column better. The average orientation error of the fine localization bounding box is 3.6\(^{\circ }\) only while for the coarse bounding box, the error is 6.26\(^{\circ }\). The fine localization scans the coarse localization box with more variation and thus it can find the spinal orientation with better accuracy.
To measure the compactness of the both bounding boxes, Dice coefficients and sensitivity metrics are computed. The Dice coefficient of the fine localization bounding box is 9% higher than the Dice coefficient of the coarse localization box. However, in terms of sensitivity, coarse localization outperforms fine localization bounding box by 30%. Based on the application in which the bounding boxes will be used, the user may choose between the two options.
Our algorithms outperformed the performances of [3, 4]. [3] reported an average orientation error of 4.16\(^{\circ }\) and [4] reports a vertebra detection 89%. However, [3] report only 10% landmark points to be outside the bounding box which is lower than our 12%. But their landmark points did not consider the posterior points. It is also important to mention that both of these works, has been performed on a small (40 and 50) images from NHANES-II dataset of scanned X-ray images, where the images are collected from healthy patients for the purpose of developing automatic algorithms thus contains less variation, injuries and exposure differences. In our case, the dataset represents X-ray images collected from real life emergency room images where resolution, patient age, injury, orientation, X-ray exposure all vary widely. Figure 4 shows examples of images with low contrast (h, i), bone implants (f, l, n), displacements (j, m) and osteoporosis (d, k). Our algorithm works well in all these conditions.
The algorithm is written in MATLAB2014b on a Intel Core-i5 3 GHz machine with 8GB RAM and have not been optimized for execution time. The unoptimized code takes on average around 2.5 s to run the whole localization procedure (both coarse and fine). The execution time varies based on the image size, resolution and number of positive votes at each stage.
The performance of our algorithm can be attributed to the training of the forests and to the novel voting accumulation process. The patch classification accuracy of forests is in the range of 95 to 98% (Table 2) which eliminates the majority of the false detections. The novel voting accumulation method which utilises dynamic diffusion based kernel density estimation and weighted area filtering eliminates the rest of the false detection and thus the final results are good. We are currently working on a vertebral curve detection method (Fig. 4(p)), which can detect the anterior and posterior vertebral curves. A single orientation angle is not capable of describing the spinal column accurately. In many cases, the spinal column is a curve than a straight line (Fig. 4(d, m)). Thus, these curves will tell us more about the global orientation of the spine. Our next target is to detect the vertebrae centers or other landmarks automatically like [6,7,8,9]. The output of this work will be helpful in order to limit our search over the image. It can also help algorithms [7,8,9] where the search area was manually reduced with hard coded parameters.
References
Platzer, P., Hauswirth, N., Jaindl, M., Chatwani, S., Vecsei, V., Gaebler, C.: Delayed or missed diagnosis of cervical spine injuries. J. Trauma Acute Care Surg. 61(1), 150–155 (2006)
Morris, C., McCoy, E.: Clearing the cervical spine in unconscious polytrauma victims, balancing risks and effective screening. Anaesthesia 59(5), 464–482 (2004)
Tezmol, A., Sari-Sarraf, H., Mitra, S., Long, R., Gururajan, A.: Customized hough transform for robust segmentation of cervical vertebrae from x-ray images. In: Fifth IEEE Southwest Symposium on Image Analysis and Interpretation, Proceedings, pp. 224–228. IEEE (2002)
Larhmam, M.A., Mahmoudi, S., Benjelloun, M.: Semi-automatic detection of cervical vertebrae in X-ray images using generalized hough transform. In: 2012 3rd International Conference on Image Processing Theory, Tools and Applications (IPTA), pp. 396–401. IEEE (2012)
Breiman, L.: Random forests. Mach. Learn. 45(1), 5–32 (2001)
Bromiley, P.A., Adams, J.E., Cootes, T.: Localisation of vertebrae on DXA images using constrained local models with random forest regression voting. In: Yao, J., Glocker, B., Kinder, T., Li, S. (eds.) Recent Advances in Computational Methods and Clinical Applications for Spine Imaging. LNCVB, pp. 159–171. Springer, Heidelberg (2015)
Roberts, M.G., Cootes, T.F., Adams, J.E.: Automatic location of vertebrae on DXA images using random forest regression. In: Ayache, N., Delingette, H., Golland, P., Mori, K. (eds.) MICCAI 2012. LNCS, vol. 7512, pp. 361–368. Springer, Heidelberg (2012). doi:10.1007/978-3-642-33454-2_45
Al-Arif, S.M.M.R., Asad, M., Knapp, K., Gundry, M., Slabaugh, G.: Hough forest-based corner detection for cervical spine radiographs. In: Proceedings of the 19th Conference on Medical Image Understanding and Analysis (MIUA), pp. 183–188 (2015)
Al-Arif, S.M.M.R., Asad, M., Knapp, K., Gundry, M., Slabaugh, G.: Cervical vertebral corner detection using Haar-like features and modified Hough forest. In: 2015 5th International Conference on Image Processing Theory, Tools and Applications (IPTA). IEEE (2015)
Glocker, B., Feulner, J., Criminisi, A., Haynor, D.R., Konukoglu, E.: Automatic localization and identification of vertebrae in arbitrary field-of-view CT scans. In: Ayache, N., Delingette, H., Golland, P., Mori, K. (eds.) MICCAI 2012. LNCS, vol. 7512, pp. 590–598. Springer, Heidelberg (2012). doi:10.1007/978-3-642-33454-2_73
Glocker, B., Zikic, D., Konukoglu, E., Haynor, D.R., Criminisi, A.: Vertebrae localization in pathological spine CT via dense classification from sparse annotations. In: Mori, K., Sakuma, I., Sato, Y., Barillot, C., Navab, N. (eds.) MICCAI 2013. LNCS, vol. 8150, pp. 262–270. Springer, Heidelberg (2013). doi:10.1007/978-3-642-40763-5_33
Benjelloun, M., Mahmoudi, S., Lecron, F.: A framework of vertebra segmentation using the active shape model-based approach. J. Biomed. Imaging 2011, 9 (2011)
Dollár, P., Zitnick, C.L.: Structured forests for fast edge detection. In: ICCV (2013)
Dollár, P., Zitnick, C.L.: Fast edge detection using structured forests. In: PAMI (2015)
Botev, Z.I., Grotowski, J.F., Kroese, D.P., et al.: Kernel density estimation via diffusion. Ann. Stat. 38(5), 2916–2957 (2010)
Schwarz, C., Teich, J., Welzl, E., Evans, B.: On finding a minimal enclosing parallelogram. Citeseer (1994)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing AG
About this paper
Cite this paper
Al Arif, S.M.M.R., Gundry, M., Knapp, K., Slabaugh, G. (2016). Global Localization and Orientation of the Cervical Spine in X-ray Images. In: Yao, J., Vrtovec, T., Zheng, G., Frangi, A., Glocker, B., Li, S. (eds) Computational Methods and Clinical Applications for Spine Imaging. CSI 2016. Lecture Notes in Computer Science(), vol 10182. Springer, Cham. https://doi.org/10.1007/978-3-319-55050-3_6
Download citation
DOI: https://doi.org/10.1007/978-3-319-55050-3_6
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-55049-7
Online ISBN: 978-3-319-55050-3
eBook Packages: Computer ScienceComputer Science (R0)