
Abstract
This paper proposes a unified facial motion tracking and expression recognition framework for monocular video. For retrieving facial motion, an online weight adaptive statistical appearance method is embedded into the particle filtering strategy by using a deformable facial mesh model served as an intermediate to bring input images into correspondence by means of registration and deformation. For recognizing facial expression, facial animation and facial expression are estimated sequentially for fast and efficient applications, in which facial expression is recognized by static anatomical facial expression knowledge. In addition, facial animation and facial expression are simultaneously estimated for robust and precise applications, in which facial expression is recognized by fusing static and dynamic facial expression knowledge. Experiments demonstrate the high tracking robustness and accuracy as well as the high facial expression recognition score of the proposed framework.
Access provided by CONRICYT-eBooks. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
Facial motion and expression enable users to communicate with computers using natural skills. Constructing robust systems for facial motion tracking and expression recognition is an active research topic.
Generally, 2D approaches [1, 2] or 3D approaches [3, 4] can be conducted for this task. Compared with 2D methods, 3D methods are more qualified for the view-independent and illumination insensitive tracking and recognition situations [5]. For 3D methods, a 3D facial mesh model or a depth camera is often used [4,5,6,7,8]. Because the high cost-effectiveness of single video cameras, they are used as inputs here by a 3D facial mesh model, which is served as the priori knowledge and constraints.
For facial motion tracking [9], appearance-based techniques [12, 13] are more robust compared with feature-based ones [10, 11], and often implemented statistically to increase the robustness. Offline statistical appearance-based models [3, 14], such as 3D shape regression [15, 16], use a face image dataset taken under different conditions to learn the parameters of appearance model, while online statistical appearance models (OSAM) [17,18,19] are more flexible and efficient than the offline ones by updating the learned dataset progressively. In addition, an adequate motion filtering strategy should be adopted to obtain the true value. Particle filtering [19] has been widely used for the global optimization ability by using the Monte Carlo technique.
For facial expression recognition [20,21,22], static techniques use spatial ones or spatio-temporal features related to a single frame [23] to classify expressions by several statistical analysis tools [24,25,26,27,28,29,30], such as neural network, while dynamic techniques use the temporal variations of facial deformation to classify expressions by several statistical analysis tools [31,32,33], such as dynamic Bayesian networks.
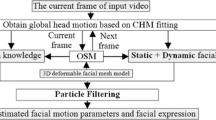
In this paper, a framework (Fig. 1) is proposed for pose robust and illumination insensitive facial motion tracking and expression recognition on each video frame base on the work in [34].

Framework.
Firstly, facial animation and facial expression are obtained sequentially in particle filtering. To alleviate the illumination variation difficulty during facial motion tracking, OSAM is improved to illumination weight adaptive online statistical appearance model (IWA-OSAM), in which 13 basis point light positions are constructed to model the lighting condition of each video frame. Then facial expressions are recognized by the static facial expression knowledge learned from the anatomical definitions in [35].
Secondly, because both the temporal dynamics and static information are important for recognizing expressions [36], they are combined and fused here by tracking facial motion and recognizing facial expression simultaneously in particle filtering. Compared with the sequential approach discussed above, particles are not only generated by the resampling, but also predicted by the dynamic knowledge; thus resulting into a more accurate recognition result.
2 Facial Motion Tracking
2.1 OSM-Based Facial Motion Tracking
The model (Fig. 2(a)): CANDIDE3 [37] is served as the priori knowledge and constraints for facial motion tracking, and defines the facial motion parameters as:
where \( \varvec{h}{ = [}\theta_{\text{x}} ,\theta_{y} ,\theta_{z} ,t_{x} ,t_{y} ,t_{z} ]^{T} \) is global head motion parameters. \( \varvec{\beta ,\alpha } \) are shape and animation parameter. 10 shape parameter and 7 animation parameter are used.

(a) CANDIDE3 model. (b) A frame of input video. (c) The projection of CANDIDE3 under \( \varvec{b} \). (d) The GNFI. (e) The improved GNFI. (f) Selected facial areas.
A face texture is represented as a geometrically normalized facial image (GNFI) [37]. Figure 2(b)–(d) illustrate the process of obtaining a GNFI with an input image. Different facial areas may have different levels of influence on the tracking performance. Because the part above the eyebrows hardly take effect on the facial motion, and is often contaminated by the hair, it is removed from the GNFI. In addition, we found that the top part of the nose and the temples seldom undergo local motions. However, the appearance of these two facial areas is often influenced by head pose change and illumination variation. Therefore, the image regions corresponding to these two facial areas are removed from GNFI. The resulting image, called improved GNFI (Fig. 2(e)), is then used for measurements extraction.
Because the pixel color values are easily influenced by environment, and thus not robust for tracking, a more robust measurement is extracted from the improved GNFI as follows according to the discussion in [34]: for the improved GNFIs of the first and current frames, we obtain the illumination ratio images, and compute Gabor wavelet coefficients on the selected facial areas (Fig. 2(f)) where high frequency appearance changes more likely.
Moreover, illumination variation is one of the most important factors which reduce significantly the performance of face recognition system. It has been proved that the variations between images of the same face due to illumination are almost always larger than image variations due to change in face identity. So eliminating the effects due to illumination variations relates directly to the performance and practicality of face recognition. To alleviate this problem, a low-dimensional illumination space representation (LDISR) of human faces for arbitrary lighting conditions [38] is proposed for recognition. The key idea underlying the representation is that any lighting condition can be represented by 9 basis point light sources. The lighting subspace is constructed not using the eigenvectors from the training images with various lighting conditions directly but the light sources corresponding to the eigenvectors. The 9 basis light positions are shown in Table 1.
However, it is only used for the situation in which the face has only the 2D in-plane rotation, while the face with out-of-plane rotation is a common situation for the face in the real scene. Therefore, we extend the LDISR from 2D to 3D, in which the in-plane rotation and out-of-plane rotation are both considered. The training process is similar to that in the method discussed in [38], and the obtained 13 basis light positions are shown in Table 2.
Because different human faces have similar 3D shapes, the LDISR of different faces is also similar. In addition, by using the normalization with GNFI (Fig. 2), it can be assumed that different persons have the same LDISR.
Suppose the 13 basis images obtained under 13 basis lights are \( L_{i} ,i = 1, \cdots ,13 \), the LDISR of human face can be denoted as \( \varvec{A} = \left[ {L_{1} ,L_{2} , \cdots ,L_{13} } \right] \). Given an image of human face \( \varvec{I}_{x} \) under an arbitrary lighting condition, it can be expressed as:
where \( \varvec{\lambda}= \left[ {\lambda_{1} ,\lambda_{2} , \cdots ,\lambda_{13} } \right]^{T} ,1 \le \lambda_{i} \le 1 \) is the lighting parameters of image \( \varvec{I}_{x} \), and can be calculated by minimizing the energy function \( E\left( \lambda \right) \) as:
Then the lighting parameters can be obtained as:
In practice, the image pixel will be less influenced by lighting if the light positions are distributed more evenly. In this case, the values of \( \lambda_{1} ,\lambda_{2} , \cdots ,\lambda_{13} \) should be close for the 13 basis light positions discussed above. With this fact, an index can be defined to evaluate the lighting influence on the pixel values of each triangular patch of the improved GNFI. To achieve this goal, these triangular patches are first split to 13 areas corresponding to 13 basis point light positions, and then the lighting influence weight of the \( kth,k = 1, \cdots ,13 \) area is given for the \( tth \) video frame as follows:
where \( j \) is the index of the pixel in the \( kth \) area of the triangular patches in Fig. 1(e).
Based on the lighting influence weight discussed above, OSAM is extended to illumination weight adaptive online statistical appearance model (IWA-OSAM). The details are as follows.
\( \varvec{m}\left( {\varvec{b}_{t} } \right) \) with size d, abbreviated as \( \varvec{m}_{t} \), is the concatenation of pixel color value at time t, and it is modeled as a Gaussian Mixture stochastic variable with 3 components, \( s,w,l \), as Jepson et al. [17] does. \( \left\{ {\varvec{\mu}_{i,t} ;i = s,w,l} \right\} \) is the mean vector. \( \left\{ {\varvec{\sigma}_{i,t} ;i = s,w,l} \right\} \) is the vector composed of the square roots of the diagonal elements of the covariance matrix. \( \left\{ {\varvec{k}_{i,t} ;i = s,w,l} \right\} \) is the mixed probability vector. The observation likelihood is \( p\left( {{{\varvec{m}_{t} } \mathord{\left/ {\vphantom {{\varvec{m}_{t} } {\varvec{b}_{t} }}} \right. \kern-0pt} {\varvec{b}_{t} }}} \right) \), which is represented by the sum of the Gaussian distributions of 3 components, \( s,w,l \), weighted by \( \left\{ {\varvec{k}_{i,t} ;i = s,w,l} \right\} \).
The IWA-OSAM represents the stochastic process of all observations until time t-1: \( \varvec{m}_{1:t - 1} \). In order to enable IWA-OSAM to track target, \( \left\{ {\varvec{k}_{i,t} ;i = s,w,l} \right\} \) and \( \varvec{\mu}_{s,t} \), \( \varvec{\sigma}_{s,t} \) are updated when \( \varvec{b}_{t} \), \( \varvec{m}_{t} \) are got [18]. The following equations are valid for \( j = 1,2, \cdots ,d \). \( c = 0.2 \) is forgetting factor.
Moreover, the methods discussed in [19] are used to reduce the influences of occlusion and outlier here.
Once the solution \( \varvec{b}_{t} \) is solved, the corresponding pixels in the resulting synthesis texture will be used to update IWA-OSAM. While IWA-OSAM are not updated for outlier or occlusion pixels, thus the outlier and occlusion cannot deteriorate IWA-OSAM.
3 Facial Expression Recognition
Static knowledge and dynamic knowledge are extracted to cope with the complex variability of facial expression.
3.1 Static Facial Expression Knowledge
The retrieved \( \varvec{\alpha} \) of one frame from the input video can be seen as a description of facial muscles activations of the person in that frame according to the definitions of action units in [36]. Therefore, the relationship between \( \varvec{\alpha} \) and facial expression modes is established, namely 7 typical vectors \( \left\{ {\varvec{\alpha}_{su} ,\varvec{\alpha}_{di} ,\varvec{\alpha}_{fe} ,\varvec{\alpha}_{ha} ,\varvec{\alpha}_{sa} ,\varvec{\alpha}_{an} ,\varvec{\alpha}_{ne} } \right\} \) are chosen as the representatives of 7 universal facial expressions: surprise, disgust, fear, happy, sad, angry and neutral. They are set as the static knowledge for facial expression recognition.
When \( \varvec{\alpha} \) of one frame of input video is retrieved, the Euclidian distances between it and each of \( \left\{ {\varvec{\alpha}_{su} ,\varvec{\alpha}_{di} ,\varvec{\alpha}_{fe} ,\varvec{\alpha}_{ha} ,\varvec{\alpha}_{sa} ,\varvec{\alpha}_{an} ,\varvec{\alpha}_{ne} } \right\} \) are computed, and the facial expression corresponding to the minimum distance is set as the recognition result.
3.2 Dynamic Facial Expression Knowledge
For each expression \( \gamma \), a three layer Radial Basis Function (RBF) network is trained for describing the temporal evolution of facial animations \( \varvec{\alpha}_{t} \) as:
The middle layer contains 400 nodes. \( \varvec{W}(7 \times 400) \), \( \varvec{B}(7 \times 1) \) are the weight matrix and bias vector of the output layer. The \( ith \) node of middle layer is given by RBF:
where \( \varvec{IW}_{i} \) is the \( ith \) row component of the weight matrix of the middle layer \( \varvec{IW}(400 \times 7) \), and represents the mean value of the \( ith \) RBF. \( \left\| {\varvec{\alpha}- IW_{i} } \right\| \) represents the distance between \( \varvec{\alpha} \) and \( IW_{i} \). \( B_{mi} \) is the \( ith \) component of bias vector of the middle layer \( \varvec{B}_{m} (400 \times 1) \), and its reciprocal represents the variance of the \( ith \) RBF. The dynamic of facial animations associated with the neutral expression is simplified as \( \varvec{\alpha}_{t} =\varvec{\alpha}_{t - 1} \).
We define a transition matrix \( \varvec{T} \) whose entries \( T_{{\gamma^{\prime},\gamma }} \) describe the probability of transition between two expressions \( \gamma^{\prime} \) and \( \gamma \). The transition probabilities are learned from a database [39]. Then the RBF network is trained on the 60% of the Extended Cohn-Kanade (CK+) database 25 and the database [39]. The corresponding facial animations \( \varvec{\alpha}_{t} \) are tracked by IWA-OSAM. Therefore, the RBF network is set as the dynamic knowledge for facial expression recognition.
3.3 Framework
Given a facial video, we would like to estimate \( \varvec{b}_{t} \) and the facial expression for each frame at time \( t \), by particle filtering, given all the observations up to time \( t \). Therefore, we create a mixed state \( \left( {\varvec{b}_{t}^{T} ,\gamma_{t} } \right)^{T} \), where \( \gamma_{t} \in \left\{ {1, \cdots ,7} \right\} \) is a discrete state, representing one of 7 universal expressions. For the estimation of \( \left( {\varvec{b}_{t}^{T} ,\gamma_{t} } \right)^{T} \), two schemes are proposed. The first scheme (Fig. 3) is to infer \( \left( {\varvec{b}_{t}^{T} ,\gamma_{t} } \right)^{T} \) sequentially, where facial expression is recognized by static facial expression knowledge. The second scheme (Fig. 4) is to infer \( \left( {\varvec{b}_{t}^{T} ,\gamma_{t} } \right)^{T} \) simultaneously, where facial expression is recognized by fusing the static and dynamic facial expression knowledge.

Inferring the facial motion and facial expression sequentially.

Inferring the facial motion and facial expression simultaneously.
4 Evaluation
A workstation with Intel i7-6700K 4.0G, 8G memory and NVIDIA GTX960 is used.
4.1 Testing Dataset and Evaluation Methods for Facial Motion Tracking
A facial image sequence [5] and the IMM face database [40] with the ground truth landmarks available are used. They support point based comparison for errors, and a texture based test could also be performed on it. Besides, as the pose coverage and illumination condition variations of above databases are not large enough, the 13 videos, including Carphone and Forman image sequences, in the MPEG-4 testing database and 78 captured videos from 48 subjects with the resolution 352 × 288 are also used. The ground truth landmarks of them are obtained by manual adjustment.
Root Mean Square (RMS) landmark error measures the Root Mean Square Error (RMSE) between the ground truth landmark points and the fitted shape points after tracking, and is defined as:
where \( C_{est}^{i} \), \( C_{grd}^{i} \) are the \( x \) or \( y \) coordinate of the \( ith \) fitted shape point and the \( ith \) ground truth landmark point.
4.2 Testing Dataset and Evaluation Methods for Facial Expression Recognition
The Extended Cohn-Kanade (CK+) database [25] and the database [39], not including the training part, are used. The database also presents the baseline results using AAM and a linear support vector machine classifier.
For evaluation, the facial expression recognition score is used, and a confusion matrix between different facial expression is used.
4.3 Facial Motion Tracking for Monocular Videos
Figure 5 shows the facial motion tracking results of several publically and captured videos. By computing the evaluation criteria, we can say that accurate tracking is obtained even in the presence of perturbing factors including significant head pose and illumination as well as facial expression variations.

Facial motion tracking results.
Based on the testing dataset, the comparison between different tracking algorithm is conducted. It should be stated that the work in [3] an offline method, and its performance is highly dependent on the training data. However, Active Shape Model (ASM)/Active Appearance Model (AAM) based trackers, such as that in [3], are the mainstream, and after learning the model in a dataset, the tracker can track any face without further training. Therefore, we compare this work with that in [3]. The images of the training dataset, which approximately correspond to every 4th image in the sequences of the testing dataset, are used to construct the AAM in [3], and the number of bases in the constructed AAM is chosen so as to keep 95% of the variations. The performances is evaluated on the testing data except for the training images.
By computing the evaluation criteria, Table 3 shows the superiority of our algorithm. This is because the IWA-OSAM in our proposed approach can learn the variation of facial motion effectively, and our proposed approach has the ability to alleviate lighting influence. Moreover, this is also because the improved GNFI is less influenced by the head pose change and illumination variation.
4.4 Facial Expression Recognition
Figure 6 shows the facial expression recognition results on the testing database. As can be seen from it, facial expressions can be recognized effectively by our proposed algorithm in the presence of perturbing factors including significant head pose and illumination.

Facial expression recognition results.
Based on the CK+ database, we compare our proposed algorithm to the methods in [20,21,22, 31, 34, 37] (Table 4). The recognition score of our facial expression recognition algorithm is higher than those of other algorithms, and also higher than those of our facial expression recognition algorithm not using illumination modeling.
According to the benchmarking protocol in the CK+ database, the leave-one-subject-out cross-validation configuration is used, and a confusion matrix is used to document the results. Table 5 shows the high recognition scores by our proposed algorithm. This is because that both static and dynamic knowledge are used, illumination is modeled and removed from improved GNFI to increase the accuracy and robustness of facial motion tracking.
5 Conclusion
We propose a unified facial motion tracking and expression recognition framework for monocular video. For retrieving facial motion, an online weight adaptive statistical appearance method is embedded into the particle filtering strategy by using a deformable facial mesh model served as an intermediate to bring input images into correspondence by means of registration and deformation. For recognizing facial expression, facial animation and facial expression are estimated sequentially for fast and efficient applications, in which facial expression is recognized by static anatomical facial expression knowledge. In addition, facial animation and facial expression are simultaneously estimated for robust and precise applications, in which facial expression is recognized by fusing static and dynamic facial expression knowledge. Experiments demonstrate the high tracking robustness and accuracy as well as the high facial expression recognition score of the proposed framework.
In future, the recursive neural network will be used to learn the dynamic expression knowledge.
References
Black, M.J., et al.: Recognizing facial expressions in image sequences using local parameterized models of image motion. IJCV 25(1), 23–28 (1997)
Gokturk, S., et al.: A data-driven model for monocular face tracking. In: ICCV, pp. 701–708 (2001)
Sung, J., Kanade, T., Kim, D.: Pose robust face tracking by combining active appearance models and cylinder head models. IJCV 80(2), 260–274 (2008)
Dornaika, F., Davoine, F.: On appearance based face and facial action tracking. TCSVT 16(9), 1107–1124 (2006)
Zeng, Z.H., et al.: A survey of affect recognition methods: audio, visual, and spontaneous expressions. TPAMI 31(1), 31–58 (2009)
Wen, Z., Huang, T.S.: Capturing subtle facial motions in 3D face tracking. In: ICCV, pp. 1343–1350 (2003)
Sandbach, G., et al.: Static and dynamic 3D facial expression recognition: a comprehensive survey. IVS 30(10), 683–697 (2012)
Fang, T., Zhao, X., et al.: 3D facial expression recognition: a perspective on promises and challenges. In: ICAFGR, pp. 603–610 (2011)
Marks, T.K., et al.: Tracking motion, deformation and texture using conditionally Gaussian processes. TPAMI 32(2), 348–363 (2010)
Zhang, W., Wang, Q., Tang, X.: Real time feature based 3-D deformable face tracking. In: Forsyth, D., Torr, P., Zisserman, A. (eds.) ECCV 2008. LNCS, vol. 5303, pp. 720–732. Springer, Heidelberg (2008). doi:10.1007/978-3-540-88688-4_53
Liao, W.-K., Fidaleo, D., Medioni, G.: Integrating multiple visual cues for robust real-time 3D face tracking. In: Zhou, S.Kevin, Zhao, W., Tang, X., Gong, S. (eds.) AMFG 2007. LNCS, vol. 4778, pp. 109–123. Springer, Heidelberg (2007). doi:10.1007/978-3-540-75690-3_9
Cascia, M.L., et al.: Fast, reliable head tracking under varying illumination: an approach based on registration of texture mapped 3D models. TPAMI 22(4), 322–336 (2000)
Fidaleo, D., Medioni, G., Fua, P., Lepetit, V.: An investigation of model bias in 3D face tracking. In: Zhao, W., Gong, S., Tang, X. (eds.) AMFG 2005. LNCS, vol. 3723, pp. 125–139. Springer, Heidelberg (2005). doi:10.1007/11564386_11
Liao, W.K., et al.: 3D face tracking and expression inference from a 2D sequence using manifold learning. In: CVPR, pp. 3597–3604 (2008)
Cao, C., Lin, Y., Lin, W.S., Zhou, K.: 3D shape regression for real-time facial animation. TOG 32(4), 149–158 (2013)
Cao, C., et al.: Displaced dynamic expression regression for real-time facial tracking and animation. In: SIGGRAPH, pp. 796–812 (2014)
Jepson, A.D., Fleet, D.J., et al.: Robust online appearance models for visual tracking. TPAMI 25(10), 1296–1311 (2003)
Lui, Y.M., et al.: Adaptive appearance model and condensation algorithm for robust face tracking. TSMC Part A 40(3), 437–448 (2010)
Yu, J., Wang, Z.F.: A video, text and speech-driven realistic 3-D virtual head for human-machine interface. IEEE Trans. Cybern. 45(5), 977–988 (2015)
Wang, Y., et al.: Realtime facial expression recognition with Adaboost. In: ICPR, pp. 30–34 (2004)
Bartlett, M., Littlewort, G., Lainscsek, C.: Machine learning methods for fully automatic recognition of facial expressions and facial actions. In: ICSMC, pp. 145–152 (2004)
Zhang, Y., Ji, Q.: Active and dynamic information fusion for facial expression understanding from image sequences. TPAMI 27(5), 699–714 (2005)
Tian, Y.L., et al.: Facial expression analysis. In: Li, S.Z., Jain, A.K. (eds.) Handbook of Face Recognition. Springer, New York (2005)
Chang, Y., et al.: Probabilistic expression analysis on manifolds. In: CVPR, pp. 520–527 (2004)
Lucey, P., et al.: The extended Cohn-Kande dataset (CK+): a complete facial expression dataset for action unit and emotion-specified expression. In: CVPR, pp. 217–224 (2010)
Tian, Y., Kanade, T., Cohn, J.F.: Recognizing action units for facial expression analysis. TPAMI 23, 97–115 (2001)
Hamester, D., et al.: Face expression recognition with a 2-channel convolutional neural network. In: IJCNN, pp. 12–17 (2015)
Wang, H., Ahuja, N.: Facial expression decomposition. In: ICCV, pp. 958–963 (2003)
Lee, C., Elgammal, A.: Facial expression analysis using nonlinear decomposable generative models. In: IWAMFG, pp. 958–963 (2005)
Zhu, Z., Ji, Q.: Robust realtime face pose and facial expression recovery. In: CVPR, pp. 1–8 (2006)
Cohen, L., Sebe, N., et al.: Facial expression recognition from video sequences: temporal and static modeling. CVIU 91(1–2), 160–187 (2003)
North, B., Blake, A., et al.: Learning and classification of complex dynamics. TPAMI 22(9), 1016–1034 (2000)
Zhou, S., Krueger, V., Chellappa, R.: Probabilistic recognition of human faces from video. CVIU 91(1–2), 214–245 (2003)
A Video-Based Facial Motion Tracking and Expression Recognition System. Multimed. Tools and Appl. (2016). doi:10.1007/s11042-016-3883-3
Ekman, P., Friesen, W., et al.: Facial Action Coding System: Research Nexus. Network Research Information, Salt Lake City (2002)
Schmidt, K., Cohn, J.: Dynamics of facial expression: normative characteristics and individual differences. In: ICME, pp. 728–731 (2001)
Dornaika, F., Davoine, F.: Simultaneous facial action tracking and expression recognition in the presence of head motion. IJCV 76(3), 257–281 (2008)
Hu, Y.K., Wang, Z.F.: A low-dimensional illumination space representation of human faces for arbitrary lighting conditions. Acta Automatica Sinica 33(1), 9–14 (2007)
Nordstrøm, M.M., et al.: The IMM face database - an annotated dataset of 240 face images. Technical report, Technical University of Denmark (2004)
Acknowledgement
This work is supported by the National Natural Science Foundation of China (No. 61572450, No. 61303150), the Open Project Program of the State KeyLab of CAD&CG, Zhejiang University (No. A1501), the Fundamental Research Funds for the Central Universities (WK2350000002), the Open Funding Project of State Key Laboratory of Virtual Reality Technology and Systems, Beihang University (No. BUAA-VR-16KF-12), the Open Funding Project of State Key Laboratory of Novel Software Technology, Nanjing University (No. KFKT2016B08).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing AG
About this paper
Cite this paper
Yu, J. (2017). A Unified Framework for Monocular Video-Based Facial Motion Tracking and Expression Recognition. In: Amsaleg, L., Guðmundsson, G., Gurrin, C., Jónsson, B., Satoh, S. (eds) MultiMedia Modeling. MMM 2017. Lecture Notes in Computer Science(), vol 10133. Springer, Cham. https://doi.org/10.1007/978-3-319-51814-5_5
Download citation
DOI: https://doi.org/10.1007/978-3-319-51814-5_5
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-51813-8
Online ISBN: 978-3-319-51814-5
eBook Packages: Computer ScienceComputer Science (R0)