
Abstract
Antibody-based proteomic approaches play an important role in high-throughput, multiplexed protein expression profiling in health and disease. These antibody-based technologies will provide (miniaturized) set-ups capable of the simultaneously profiling of numerous proteins in a specific, sensitive, and rapid manner, targeting high- as well as low-abundant proteins, even in crude proteomes such as serum. The generated protein expression patterns, or proteomic snapshots, can then be transformed into proteomic maps, or detailed molecular fingerprints, revealing the composition of the target (sample) proteome at a molecular level. By using bioinformatics, candidate biomarker signatures can be deciphered and evaluated for clinical applicability. The approaches will provide unique opportunities for e.g. disease diagnostics, biomarker discovery, patient stratification, predicting disease recurrence, and evidence-based therapy selection. In this review, we describe the current status of the antibody-based proteomic approaches, focusing on antibody arrays. Furthermore, the current benefits and limitations of the approaches, as well as a set of selected key applications outlining the applicative potential will be discussed.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others

Keywords
- Affinity proteomics
- Antibody
- Antibody arrays
- Antibody-based proteomics
- Biomarker
- Disease proteomics
- Protein expression profiling
11.1 Introduction
Mass spectrometry (MS ) based approaches have so far constituted the main workhorse for protein expression profiling efforts (Ebhardt et al. 2015; Parker and Borchers 2014; Solier and Langen 2014). MS displays many advantages for this purpose, such as direct (absolute) identification, quantitative read-out possibilities, and suitability for hypothesis-free biomarker discovery. However, MS-based approaches are also associated with significant technical limitations, including sensitivity, resolution, accuracy, and reproducibility, especially when targeting complex samples, such as serum, where protein expression covers a huge dynamic range. The need for new proteomic technologies has been one of the main driving forces in the development of affinity proteomics , mainly represented by antibody-based approaches (Saerens et al. 2008; Uhlen and Ponten 2005; Voshol et al. 2009; Solier and Langen 2014; Borrebaeck and Wingren 2009a, 2014). Antibody-based proteomic approaches, such as antibody microarrays, have rapidly evolved from early proof-of-concept stages to high-performing proteome profiling assays, and today constitutes key established approaches within high-throughput (disease) proteomics (Borrebaeck and Wingren 2009a, 2014).
Antibody-based proteomics can thus be defined as the systematic generation and use of protein-specific antibodies to explore the proteome or parts thereof. The antibodies can be used for analysis of the specific protein targets in a wide range of assay platforms, as outlined in Table 11.1. Aiming for tissue protein profiling, candidate platforms could include immunohistochemistry (IHC), antibody-enriched selected reaction monitoring (SRM), global proteome survey (GPS), Triple-X, and reversed antibody microarrays, or reverse-phase protein microarrays (RPPA). When considering for biofluid protein expression profiling , candidate platforms could include ELISA, antibody-enriched-SRM, GPS, Triple-X, reverse antibody microarrays or RPPA, and antibody nano- and microarrays. The choice of platform will depend on the research question at hand (e.g. discovery study vs. validation study) and technical requirements (e.g., sensitivity, throughput, and degree of multiplexity).
11.2 Choice of Antibody
So far, antibodies are by far the most well-characterized and commonly used probe format within affinity proteomics , i.e. antibody-based proteomic approaches (Borrebaeck and Wingren 2011; Saerens et al. 2008; Solier and Langen 2014; Uhlen and Ponten 2005; Voshol et al. 2009). The antibodies will play a central role, acting as specific capture probes and the antibody format used will be essential, setting the stage for the technology (assay) platform. In more detail, the antibody format will directly or indirectly influence the:
-
(i)
Performance of the probes in the selected technology platform
-
(ii)
Range of specificities that can be generated and included
-
(iii)
Supply/renewability of probes.
Hence, these three central aspects must be considered when selecting the antibody format/design. Here, we will briefly discuss the use of different antibody formats, including polyclonal antibodies (pAbs) vs. monoclonal antibodies (mAbs) vs. recombinant antibodies (recAbs). The use of antibodies vs. affinity reagents based on other scaffolds, such as affibodies (Renberg et al. 2005, 2007) and aptamers (Lao et al. 2009; Walter et al. 2008; Cho et al. 2006; Collett et al. 2005), is outside the scope of this article, and has been reviewed elsewhere (Borrebaeck and Wingren 2007, 2009a; Wingren and Borrebaeck 2006; Wingren and Borrebaeck 2004).
pAbs display the advantage of multiple-epitope binding for the target protein, which makes them more suitable for cross-platform assays, potentially binding to both native and denatured forms of the antigen. However, the production of pAbs relies on immunization, and this probe format often shows a distinct lack of reproducibility upon re-immobilization with the same antigen, which makes this reagent less attractive as a renewable probe resource. While large-scale productions of pAbs have been successfully managed (Berglund et al. 2008; Uhlen and Hober 2009), this still poses a major logistical bottleneck. The pAB format has been successfully used in various antibody-based proteomic approaches, such as ELISA, IHC, Triple-X, and RPPA.
mAb preparations display a single-epitope specificity, making them highly attractive for specific applications. In fact, mAbs are currently the most commonly used immunoreagent in diagnostic applications (Borrebaeck 2000). However, the single-epitope specificity makes this reagent less useful across platforms, where the protein antigen might be partly denatured in different ways. The reagent is fully renewable, making it an attractive reagent, but the initial production of mAbs represents a key logistical bottleneck for large-scale efforts. mAbs have been successfully applied in, e.g., IHC, antibody-enriched SRM, RPPA, and ELISA.
recAbs are often handled and selected using phage display technologies (Borrebaeck and Wingren 2011; Soderlind et al. 2000). Due to technical (size) limitations, the most commonly used antibody format is single-chain fragment variable (scFv) antibody, i.e., the smallest fragment of an antibody still retaining its unique epitope-binding properties. These mono-specific reagents display many beneficial features, such as representing a renewable antibody source, the antibody library can be designed (engineered) on a molecular level to display desired features, such as on-chip stability in array-based applications (Borrebaeck and Wingren 2009a, 2011), they are produced without the use of animals, and they represents an attractive source towards generating antibodies against the entire proteome. Access to high-performing libraries and having the phage display technology established in the laboratory represents practical limitations. recAbs have been successfully used for, e.g., antibody-enriched SRM, GPS, RPPA, ELISA, and in particular antibody nano- and microarrays (Borrebaeck and Wingren 2009a, 2011).
11.3 Antibody-Based Proteomics – Basic Technological Concepts and Considerations
Here, we describe the various antibody-based proteomic approaches used in brief, general terms, and we highlight their advantages and limitations (Table 11.2).
Immunohistochemistry (IHC) is a classical method to discover tissue biomarkers and translate them into routine clinical practice. This approach relies on antibodies to measure levels of the target proteins from formalin-fixed, paraffin embedded (FFPE) tissue slices. To increase the throughput, the set-up has been expanded from one tissue slice per slide to several tissue slices per slide, thus representing tissue microarrays (TMAs) (Table 11.2). For example, the TMA technology enabled up to 1000 FFPE tissue samples to be assembled in an array format (Braunschweig et al. 2004; Hewitt 2004). Hence, TMAs enables researchers to use a single slide to perform studies on large cohorts of tissues using only small amounts of reagents. IHC commonly relies on labelled antibodies for detection, often demanding visual inspection of each slice. Hence, standardization and automation have been central points for further technical developments in recent years. Key advantages are assay sensitivity and the fact that spatial resolution at cellular level can be accomplished, i.e. providing information about where the target protein is located. The latter can provide a deeper insight into normal cellular functions and pathogenic mechanisms. The semi-denatured state of the sample proteins will place high demands on the antibody reagent in terms of specificity, to minimize both false-positive and false-negative results.
Combining the specific capture of the target by the antibody with the power of MS , i.e., antibody-enriched SRM, paves the way for specific and sensitive detection and absolute quantification of proteins (Whiteaker et al. 2007, 2010) (Table 11.2). The antibodies are first used to capture and enrich the target proteins. The captured proteins are then eluted, digested and analyzed on tandem-MS . The MS set-up is pre-set to only look for selected target peptides. The sample could also be digested prior to the specific capture. Polyclonal as well as monoclonal antibodies have been used for capture. The set-up is limited by the fact that the targets are pre-defined and that one antibody per target is required. Hence, the platform is not designed for large-scale discovery efforts. But on the other hand, the set-up displays high specificity, adequate sensitivity, and can be multiplexed. The cost for the MS instrumentation is high. The set-up works for both tissue and biofluid protein expression profiling .
Recently, two similar novel concepts were presented, demonstrating one solution to how the combination of antibody capture and MS detection can be converted into a discovery set-up. The two concepts, were called Triple-X Proteomics (Poetz et al. 2009; Volk et al. 2012; Hoeppe et al. 2011) (TXP) and the Global Proteome Survey (Olsson et al. 2011, 2012a, b; Wingren et al. 2009) (GPS) and they are based on the same fundamental principle, and will provide unique opportunities to perform global proteomics in a species independent manner, using a very limited set of antibodies. Briefly, antibodies are generated against short peptide motifs, only four to six amino acid residues long, each motif being shared by 2–100 different proteins. These context independent motif specific antibodies could then be used to target motif containing peptides in a species independent manner. From a practical point of view, the proteome is digested, e.g. trypsinated, and the peptide-specific antibodies are then used to specifically capture and enrich motif-containing peptides. Next, the motif-containing peptides are detected and identified (sequenced) using tandem mass spectrometry , thereby enabling us to back-track the original proteins in a quantitative manner. By using only 200 motif-specific antibodies, each targeting a motif shared among 50 unique proteins, this would enable us to potentially target about half the non-redundant proteome. The GPS set-up is based on recAbs, while the Triple-X set-up relies on pAbs and/or Mabs. The platforms can be designed to provide absolute quantification, and are compatible with both tissue and biofluid protein expression profiling . The throughput, set by the MS step, represents a key limitation.
ELISA is currently the gold standards in clinical settings for measurements of proteins. The set-up is based on immobilizing the capture antibody, which specifically binds the target protein. A secondary antibody (sandwich set-up) is often used for detection of bound proteins. The set-up can deliver relative as well as absolute levels of the profiled proteins. pAbs and mAbs are the main antibody formats used. Highly specific and sensitive assays can be designed, and any sample format can be targeted as long as the protein (epitope) is accessible. The approach is limited by multiplexing and relatively high sample consumption.
The reverse antibody array, or RPPA, is a novel, miniaturized set-up providing several benefits (Nishizuka and Mills 2016; Voshol et al. 2009). In these set-ups, the sample is arrayed and the antibodies are added one by one to detect the target protein in each individual spot. Key advantages are multiplexing and low sample consumption. The platform enables large-scale screening of virtually any biological fluid, such as serum, urine, and saliva. In addition, tissue samples can also be profiled, provided that the proteins can be solubilized and arrayed. Dispensing low (pL range) volumes of complex samples will, however, limit the sensitivity of the assay. In more detail, the number of molecules of each individual protein adsorbed per spot will be a limiting factor in particular for low-abundant proteins. Hence, this assay set-up is more suitable for profiling medium- to high-abundant proteins.
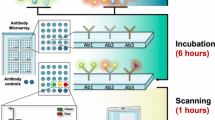
The concept of antibody arrays is based on printing small volumes (pL scale) of numerous (a few to several hundreds) antibodies with the desired specificities on-by-one in an ordered pattern, an array (<1 cm2), onto a solid support (Borrebaeck and Wingren 2009a, 2014). The arrayed antibodies will act as specific catcher molecules for the target proteins. These miniaturized arrays are incubated with μL-scale of crude, non-fractionated sample. Next, specifically bound analytes are detected and semi-quantified, mainly using fluorescence as a mode of detection (Wingren and Borrebaeck 2008). The complete assay is run within less than 4 h, where after the microarray images are transformed into protein expression profiles , or protein maps, revealing the detailed composition of the sample. Depending on the application at hand, different bioinformatic strategies can be applied (Borrebaeck and Wingren 2007, 2009b) to further explore the wealth of data generated, e.g., pin-pointing differentially expressed protein analytes between, e.g., disease patients and healthy controls (Bauer et al. 2006; Carlsson et al. 2011). The advantages of the technology are low consumption of reagents, multiplexing, sensitivity, and high throughput. The number of high-performing antibody array platforms is still low, most likely reflecting the complexity of developing such set-ups, which requires a truly multidisciplinary approach.
The antibody array is a relatively new proteomic technology that has been subject to intense development in recent years, going from proof-of-concept to established proteomic assays. The technology has been found to display a great potential for multiplexed protein expression profiling and biomarker discovery. The antibody array platforms are compatible with both tissue and biofluid protein expression profiling . Based on this, antibody arrays were selected as a showcase technology for antibody-based proteomic approaches and will be described in more detail below.
11.4 Antibody Nano- and Microarrays
The basic approach of generating miniaturized antibody arrays , ranging in size from mm2 (nanoarrays, nm sized spot features) to cm2 (microarrays, μm sized spot features) (Wingren and Borrebaeck 2007) is based on direct printing (Borrebaeck and Wingren 2007; Wingren and Borrebaeck 2007), self-addressing (Svedhem et al. 2003; Wacker and Niemeyer 2004; Wacker et al. 2004), or self-assembly (He et al. 2008a, 2008b; He and Taussig 2001; Ramachandran et al. 2004, 2006, 2008) of small amounts (femtomole range) of individual antibodies onto a solid support (Fig. 11.1). While planar arrays on solid microscope slides, such as plastic, glass, and silicon chips, constitute the dominating format, providing up to 16 sub-arrays per slide, multiplexed arrays have also been produced on the bottom of flat ELISA plate wells as well as on beads in solution, so called bead-arrays (Borrebaeck and Wingren 2009a; Schwenk et al. 2008; Wingren and Borrebaeck 2009; Wong et al. 2009). The array assay is run like a traditional ELISA, but consuming only μL scale volumes of the reagents and samples. It is noteworthy that complex, unfractionated proteomes, such as serum, plasma, urine, and tissue extracts, can, in contrast to many competing proteomic technologies, be directly used, meaning that the key issue of pre-fractionation of the sample is bypassed (Wingren and Borrebaeck 2009). Any sample format can be targeted, as long as the proteins are exposed/available (e.g. cell surface membrane proteins) and/or can be solubilized, including serum, plasma, urine, cerebrospinal fluid, intact cells, cell lysates, cell supernatants, and tissue extracts, etc. (Belov et al. 2001, 2003; Campbell et al. 2006; Dexlin et al. 2008; Dexlin-Mellby et al. 2010; Ingvarsson et al. 2007; Kristensson et al. 2012; Wingren et al. 2007; Alhamdani et al. 2010; Hoheisel et al. 2013). The samples are in most cases labeled with a fluorescent dye, either directly or indirectly, and interfaced with a fluorescent-based sensing (Kusnezow et al. 2007; Wingren and Borrebaeck 2008; Wingren et al. 2007). Label-free detection technologies have also been investigated, but additional technological developments will be required before they can be established and adapted, for review see (Borrebaeck and Wingren 2007, 2009a; Wingren and Borrebaeck 2006). These multiplexed assays display a dynamic four orders of magnitude or more, and assay sensitivities in the pM to fM range. This enables low-abundant (pg/ml) analytes to be directly profiled in crude proteomes. The assay time is similar to that of a conventional ELISA (about 4 h). By detecting and quantifying the signal intensity in each spot, the array images are transformed into protein expression profiles , deciphering the detailed composition of the sample. Finally, bioinformatics is applied to identify differences and similarities in protein expression profiles between the sample cohorts at hand, e.g., cancer versus healthy controls, potentially generating candidate biomarker signatures. Typical applications of antibody-based microarrays include, but are not limited to, glycan profiling, delineation of signaling pathways, identification and detection of bacterial disease (proteins), cell surface membrane protein profiling of intact cells, as well as detection of disease associated biomarkers for diagnosis, prognosis, classification, evidence-based therapy selection, and predicting the risk for relapse (Alhamdani et al. 2010; Carlsson et al. 2010, 2011; Haab 2005; Sanchez-Carbayo et al. 2006; Wingren et al. 2012; Gao et al. 2005; Belov et al. 2001, 2003).

Schematic illustration of the antibody microarray set-up
The process of designing, developing and applying antibody microarrays requires a cross-disciplinary approach to be adopted (Borrebaeck and Wingren 2009a). Consequently, five key basic principle areas needs to be addressed in a parallel manner, including:
-
(i)
Antibody design
-
(ii)
Array design
-
(iii)
Sample handling
-
(iv)
Assay design
-
(v)
Data handling (bioinformatics )
Once these principles have been addressed and optimized, the technology is ready to be applied for the research problem at hand.
11.5 How Antibody Arrays Are Used Today in Research
Antibody microarrays are used to perform relative (or absolute) protein expression profiling of almost any kind of sample format, such as serum, often with the aim to decipher differentially expressed protein analytes and/or to delineate protein signatures for classification, for review see (Borrebaeck and Wingren 2007, 2009a, b; Haab 2005, 2006; Hartmann et al. 2009; Kingsmore 2006; Schwenk et al. 2008; Wingren and Borrebaeck 2009). The throughput per workstation per day varies, but can be in the range of hundred samples, each individual array assay in turn targeting anything from a few to several hundred protein analytes. However, the availability of high-performing antibody arrays, displaying the desired range of specificities, is in general a limiting factor. While a few groups have developed their own in-house antibody array set-ups (Haab and Zhou 2004; Hoheisel et al. 2013; Sanchez-Carbayo et al. 2006; Schroder et al. 2011; Schwenk et al. 2008; Wingren et al. 2007), other rely on commercially available alternatives, for review see (Borrebaeck and Wingren 2007, 2009a; Wingren and Borrebaeck 2009).
To date, a large number of antibody array-based applications have been presented, ranging from small proof-of-concept studies to large semi-global protein expression profiling studies (Table 11.3). As reviewing all antibody-array based applications to date is beyond the scope of this chapter, we have compiled a selected set of both early and more recent applications, giving a broad and representative view of what the technology can be used for. The compilation shows that the antibody array technology has been used in the following areas (Table 11.3)
-
1.
Autoimmunity (Bauer et al. 2006, 2009; Carlsson et al. 2011; Szodoray et al. 2004; Lin et al. 2013; Kristensson et al. 2012)
-
2.
Allergy (Lundberg et al. 2008)
-
3.
Bladder proteomics (Fujita et al. 2006)
-
4.
Cell proteomics (Campbell et al. 2006; De Ceuninck et al. 2004; Dexlin et al. 2008; Ko et al. 2005; Kopf et al. 2005; Tuomisto et al. 2005; Turtinen et al. 2004)
-
5.
Drug abuse (Buechler et al. 1992)
-
6.
Glycomics (Chen and Haab 2009; Chen et al. 2007; Yue et al. 2011)
-
7.
Heart proteomics (Bereczki et al. 2007; Mitchell et al. 2005; Wu et al. 2004)
-
8.
Hereditary disease (Srivastava et al. 2006; Jozwik et al. 2012)
-
9.
Inflammatory conditions/infections (Madan et al. 2007; Kader et al. 2005; Cai et al. 2006; Sharma et al. 2006; Ingvarsson et al. 2007; Sandstrom et al. 2012)
-
10.
Liver proteomics (Yee et al. 2007)
-
11.
Lung proteomics (Izzotti et al. 2004)
-
12.
Medical microbiology (Cai et al. 2005; Zhou et al. 2005, 2012; Gehring et al. 2008; Delehanty and Ligler 2002; Grow et al. 2003; Huang et al. 2003; Ligler et al. 2003; Rowe et al. 1999; Rowe-Taitt et al. 2000; Rubina et al. 2005; Taitt et al. 2002; Ellmark et al. 2006b; Anjum et al. 2006; Rucker et al. 2005)
-
13.
Neurology/psychiatry (Kaukola et al. 2004; Sokolov and Cadet 2006; Krishnan et al. 2005)
-
14.
Obstretics/gynaecology (Dexlin-Mellby et al. 2010; Wang et al. 2007; Centlow et al. 2011)
-
15.
Oncoproteomics (Liu et al. 2011; Ahn et al. 2006; Sanchez-Carbayo et al. 2006; Carlsson et al. 2008, 2010, 2011; Celis et al. 2005; Hudelist et al. 2005; Lin et al. 2004; Orchekowski et al. 2005; Smith et al. 2006; Vazquez-Martin et al. 2007; Sreekumar et al. 2001; Ellmark et al. 2006a, b; Huang et al. 2001; Tannapfel et al. 2003; Belov et al. 2005, 2006; Zhou et al. 2004; Gao et al. 2005; Bartling et al. 2005; Ghobrial et al. 2005; Duffy et al. 2007; Mor et al. 2005; Ingvarsson et al. 2008; Schroder et al. 2010; Wingren et al. 2012; Miller et al. 2003; Shafer et al. 2007; Knezevic et al. 2001; Box et al. 2013; Sukhdeo et al. 2013; Yue et al. 2011; Patel et al. 2011; Sun et al. 2008; Hodgkinson et al. 2012; Shi et al. 2011; Ramirez and Lampe 2010; Yue et al. 2009)
-
16.
Periodontology (Bodet et al. 2007)
-
17.
Phosphoproteomics (Gembitsky et al. 2004; Flores-Delgado et al. 2007)
- 18.
-
19.
Protein signaling (Gaudet et al. 2005)
A majority of the applications have been performed within disease proteomics , and in particular oncoproteomics, but this does not reflect any limitation per se. In fact, as long as the target proteins can be addressed and the range of specificities of the arrayed antibodies is adequate for the application at hand, antibody arrays could be used for more or less any protein expression profiling application.
Using disease proteomics as a representative example, the project teams are frequently organized in a translational manner, involving scientists and clinicians with orthogonal competences, such as array technology, nanotechnology, protein engineering, immunochemistry, surface chemistry, sensing technology, bioinformatics , as well as disease biology, pathogenesis, and therapy (Borrebaeck and Wingren 2009a, b; Wingren and Borrebaeck 2009). The work is organized around a well-defined clinical problem, or set of problems, representing an unmet clinical need, and the project is frequently planned in a cross-disciplinary manner, going from bed-to-bench and back again. As for any proteomic study, it is essential that sequential studies are planned, going from discovery, pre-validation to validation studies, each step involving a new, independent patient data set to be targeted. In addition, the findings reported in each step of the project should also, if possible, be cross-validated using orthogonal methods (e.g., ELISA and mass spectrometry ).
11.6 Antibody Arrays – Selected Applications
As discussed above, we have compiled a selected set of both early and more recent antibody-array based applications, giving a representative view of what the technology can be used for (Table 11.3). The applications range from deciphering biomarker signatures for improved (and early) disease diagnosis, prognosis, predicting the risk for relapse, and evidence-based therapy selection, to detection and serotyping of bacteria. As a review of all of antibody array applications in detail is beyond the scope of this chapter, we have chosen to focus on selected applications within disease proteomics , more specifically within the field of autoimmunity and cancer. To this end, we will display a few examples only as show cases to highlight the workflow and potential of the array methodology.
In the case of systemic lupus erythematosus (SLE), a chronic autoimmune connective tissue disease (Rovin and Zhang 2009; D’Cruz et al. 2007; Rahman and Isenberg 2008), the clinical need for serological/urinary biomarker signatures for improved diagnosis, prognosis, and classification is significant. In a discovery study by Carlsson et al., the authors showed that the first candidate serum biomarker signatures for diagnosis, prognosis, as well as sub-group phenotyping were successfully deciphered using recombinant antibody microarrays (Carlsson et al. 2011). Major efforts are currently under way to pre-validate and validate these promising findings, both enhancing our fundamental understanding of SLE and potentially paving the way for novel and improved clinical management of SLE patients (Wingren et al, unpublished observations).
In order to delineate a biomarker signature for bladder cancer, Sanchez-Carbayo et al. adopted a dual approach, combining the extraordinary power of both DNA microarrays and antibody microarrays (Sanchez-Carbayo et al. 2006). A set of candidate markers were first identified by gene profiling, after which an antibody microarray targeting a selected set of the candidate proteins was designed and applied. The data showed that the candidate biomarker signature discriminated between bladder cancer patients and healthy controls with a 94 % correct classification rate. The data also indicated a potential of stratifying the tumors (patients) into low versus high risk based on the overall survival of the bladder cancer patients.
Several array efforts have been devoted towards defining biomarkers for pancreatic cancer (Ingvarsson et al. 2008; Orchekowski et al. 2005; Schroder et al. 2010; Shi et al. 2011; Wingren et al. 2012; Yue et al. 2009, 2011; Gerdtsson et al. 2015). With an overall 5-year survival rate of less than 2–3 % pancreatic cancer is one of the most lethal types of malignancies (Chu et al. 2010; Jemal et al. 2009), which is why biomarkers for improved and early diagnosis would have a significant impact. Early work by Orchekowski et al. revealed a set of candidate serum biomarkers , but they proved to indicate on a general disease state rather than specifically pin-pointing pancreatic cancer. Interestingly, Yue and co-workers investigated the prevalence and nature of glycan alterations on specific proteins in pancreatic cancer patients using antibody-lectin sandwich arrays (Yue et al. 2009). Their work indicated a small set of significantly altered proteins that provided valuable insight into the prevalence and protein carriers of glycan alterations in pancreatic cancer. This outlines the potential of using glycan measurements on specific proteins for highly effective biomarkers . In three other studies, using recombinant antibody microarrays, candidate biomarkers for (early) diagnosis of pancreatic cancer have been deciphered (Ingvarsson et al. 2008; Wingren et al. 2012; Gerdtsson et al. 2015). Once validated, such biomarker signatures could pave the way for early and improved diagnosis based on a minimally invasive blood sample, which could result in a significantly improved outcome for pancreatic cancer patients. Shi and co-workers explored the possibility of defining potential markers for metastatic progression in pancreatic cancer using antibody microarrays, by comparing a metastatic pancreatic cancer line with its parental line (Shi et al. 2011). Interestingly, four dysregulated proteins were identified and validated, which might prove valuable for understanding pancreatic cancer metastasis and aid in the search for potential markers of metastatic progression.
11.7 Future Perspective
Antibody-based proteomic approaches will play a key role for high-throughput, multiplexed protein expression profiling in health and disease for years to come. This will enable simultaneous profiling of numerous high- and low-abundant proteins in crude sample formats in a highly selective, specific and sensitive manner, while consuming minimal amounts of reagents and sample. Generating high-resolution protein maps will be essential in the quest for deciphering biomarkers . In the end, this will pave the way for the next generation of disease diagnostics, patient stratification (e.g., phenotyping, disease status, and sub-grouping), and predicting disease recurrence, as well as evidence-based therapy selectio n.
References
Ahn, E. H., Kang, D. K., Chang, S. I., Kang, C. S., Han, M. H., & Kang, I. C. (2006). Profiling of differential protekin expression in angiogenin-induced HUVECs using antibody-arrayed ProteoChip. Proteomics, 6(4), 1104–1109.
Alhamdani, M. S., Schroder, C., & Hoheisel, J. D. (2010). Analysis conditions for proteomic profiling of mammalian tissue and cell extracts with antibody microarrays. Proteomics, 10(17), 3203–3207.
Anjum, M. F., Tucker, J. D., Sprigings, K. A., Woodward, M. J., & Ehricht, R. (2006). Use of miniaturized protein arrays for Escherichia coli O serotyping. Clinical and Vaccine Immunology, 13(5), 561–567.
Bartling, B., Hofmann, H. S., Boettger, T., Hansen, G., Burdach, S., Silber, R. E., & Simm, A. (2005). Comparative application of antibody and gene array for expression profiling in human squamous cell lung carcinoma. Lung Cancer, 49(2), 145–154.
Bauer, J. W., Baechler, E. C., Petri, M., Batliwalla, F. M., Crawford, D., Ortmann, W. A., Espe, K. J., Li, W., Patel, D. D., Gregersen, P. K., & Behrens, T. W. (2006). Elevated serum levels of interferon-regulated chemokines are biomarkers for active human systemic lupus erythematosus. PLoS Medicine, 3(12), e491.
Bauer, J. W., Petri, M., Batliwalla, F. M., Koeuth, T., Wilson, J., Slattery, C., Panoskaltsis-Mortari, A., Gregersen, P. K., Behrens, T. W., & Baechler, E. C. (2009). Interferon-regulated chemokines as biomarkers of systemic lupus erythematosus disease activity: A validation study. Arthritis and Rheumatism, 60(10), 3098–3107.
Belov, L., de la Vega, O., dos Remedios, C. G., Mulligan, S. P., & Christopherson, R. I. (2001). Immunophenotyping of leukemias using a cluster of differentiation antibody microarray. Cancer Research, 61(11), 4483–4489.
Belov, L., Huang, P., Barber, N., Mulligan, S. P., & Christopherson, R. I. (2003). Identification of repertoires of surface antigens on leukemias using an antibody microarray. Proteomics, 3(11), 2147–2154.
Belov, L., Huang, P., Chrisp, J. S., Mulligan, S. P., & Christopherson, R. I. (2005). Screening microarrays of novel monoclonal antibodies for binding to T-, B- and myeloid leukaemia cells. Journal Immunological Methods, 305(1), 10–19.
Belov, L., Mulligan, S. P., Barber, N., Woolfson, A., Scott, M., Stoner, K., Chrisp, J. S., Sewell, W. A., Bradstock, K. F., Bendall, L., Pascovici, D. S., Thomas, M., Erber, W., Huang, P., Sartor, M., Young, G. A., Wiley, J. S., Juneja, S., Wierda, W. G., Green, A. R., Keating, M. J., & Christopherson, R. I. (2006). Analysis of human leukaemias and lymphomas using extensive immunophenotypes from an antibody microarray. Brittish Journal of Haematology, 135(2), 184–197.
Bereczki, E., Gonda, S., Csont, T., Korpos, E., Zvara, A., Ferdinandy, P., & Santha, M. (2007). Overexpression of biglycan in the heart of transgenic mice: An antibody microarray study. Journal Proteome Research, 6(2), 854–861.
Berglund, L., Bjorling, E., Oksvold, P., Fagerberg, L., Asplund, A., Szigyarto, C. A., Persson, A., Ottosson, J., Wernerus, H., Nilsson, P., Lundberg, E., Sivertsson, A., Navani, S., Wester, K., Kampf, C., Hober, S., Ponten, F., & Uhlen, M. (2008). A genecentric Human Protein Atlas for expression profiles based on antibodies. Molecular & Cellular Proteomics, 7(10), 2019–2027.
Bodet, C., Andrian, E., Tanabe, S. I., & Grenier, D. (2007). Actinobacillus actinomycetemcomitans lipopolysaccharide regulates matrix metalloproteinase, tissue inhibitors of matrix metalloproteinase, and plasminogen activator production by human gingival fibroblasts: A potential role in connective tissue destruction. Journal of Cellular Physiology, 212(1), 189–194.
Borrebaeck, C. A. K. (2000). Antibodies in diagnostics – From immunoassays to protein chips. Immunology Today, 21(8), 379–382.
Borrebaeck, C. A. K., & Wingren, C. (2007). High-throughput proteomics using antibody microarrays: An update. Expert Review of Molecular Diagnostics, 7(5), 673–686.
Borrebaeck, C. A., & Wingren, C. (2009a). Design of high-density antibody microarrays for disease proteomics: Key technological issues. Journal of Proteomics, 72(6), 928–935.
Borrebaeck, C. A. K., & Wingren, C. (2009b). Transferring proteomic discoveries into clinical practice. Expert Review of Proteomics, 6(1), 11–13.
Borrebaeck, C. A. K., & Wingren, C. (2011). Recombinant antibodies for the generation of antibody arrays. In U. Korf (Ed.), Protein microarrays. methods in molecular biology. (Clifton, NJ), 785, 247–262.
Borrebaeck, C. A. K., & Wingren, C. (2014). Antibody array generation and use. Methods in Molecular Biology (Clifton, NJ), 1131, 563–571.
Box, C., Zimmermann, M., & Eccles, S. (2013). Molecular markers of response and resistance to EGFR inhibitors in head and neck cancers. Frontiers in Bioscience, 18, 520–542.
Braunschweig, T., Chung, J. Y., & Hewitt, S. M. (2004). Perspectives in tissue microarrays. Combinatorial Chemistry & High Throughput Screening, 7(6), 575–585.
Buechler, K. F., Moi, S., Noar, B., McGrath, D., Villela, J., Clancy, M., Shenhav, A., Colleymore, A., Valkirs, G., Lee, T., et al. (1992). Simultaneous detection of seven drugs of abuse by the Triage panel for drugs of abuse. Clinical Chemistry, 38(9), 1678–1684.
Cai, H. Y., Lu, L., Muckle, C. A., Prescott, J. F., & Chen, S. (2005). Development of a novel protein microarray method for serotyping Salmonella enterica strains. Journal Clinical Microbiology, 43(7), 3427–3430.
Cai, M., Yin, W., Li, Q., Liao, D., Tsutsumi, K., Hou, H., Liu, Y., Zhang, C., Li, J., Wang, Z., & Xiao, J. (2006). Effects of NO-1886 on inflammation-associated cytokines in high-fat/high-sucrose/high-cholesterol diet-fed miniature pigs. European Journal Pharmacology, 540(1–3), 139–146.
Campbell, C. J., O’Looney, N., Chong Kwan, M., Robb, J. S., Ross, A. J., Beattie, J. S., Petrik, J., & Ghazal, P. (2006). Cell interaction microarray for blood phenotyping. Analytical Chemistry, 78(6), 1930–1938.
Carlsson, A., Wingren, C., Ingvarsson, J., Ellmark, P., Baldertorp, B., Ferno, M., Olsson, H., & Borrebaeck, C. A. K. (2008). Serum proteome profiling of metastatic breast cancer using recombinant antibody microarrays. European Journal of Cancer, 44(3), 472–480.
Carlsson, A., Persson, O., Ingvarsson, J., Widegren, B., Salford, L., Borrebaeck, C. A. K., & Wingren, C. (2010). Plasma proteome profiling reveals biomarker patterns associated with prognosis and therapy selection in glioblastoma multiforme patients. Proteomics Clinical Applications, 4(6–7), 591–602.
Carlsson, A., Wuttge, D. M., Ingvarsson, J., Bengtsson, A. A., Sturfelt, G., Borrebaeck, C. A. K., & Wingren, C. (2011). Serum protein profiling of systemic lupus erythematosus and systemic sclerosis using recombinant antibody microarrays. Molecular & Cellular Proteomics 10(5), M110 005033.
Celis, J. E., Moreira, J. M., Cabezon, T., Gromov, P., Friis, E., Rank, F., & Gromova, I. (2005). Identification of extracellular and intracellular signaling components of the mammary adipose tissue and its interstitial fluid in high risk breast cancer patients: Toward dissecting the molecular circuitry of epithelial-adipocyte stromal cell interactions. Molecular & Cellular Proteomics, 4(4), 492–522.
Centlow, M., Wingren, C., Borrebaeck, C. A. K., Brownstein, M. J., & Hansson, S. R. (2011). Differential gene expression analysis of placentas with increased vascular resistance and pre-eclampsia using whole-genome microarrays. Journal of Pregnancy, 2011, 472354.
Chen, S., & Haab, B. B. (2009). Analysis of glycans on serum proteins using antibody microarrays. Methods of Molecular Biology, 520, 39–58.
Chen, S., Laroche, T., Hamelinck, D., Bergsma, D., Brenner, D., Simeone, D., Brand, R. E., & Haab, B. B. (2007). Multiplexed analysis of glycan variation on native proteins captured by antibody microarrays. Nature Methods, 4(5), 437–444.
Cho, E. J., Collett, J. R., Szafranska, A. E., & Ellington, A. D. (2006). Optimization of aptamer microarray technology for multiple protein targets. Analytica Chimica Acta, 564(1), 82–90.
Chu, D., Kohlmann, W., & Adler, D. G. (2010). Identification and screening of individuals at increased risk for pancreatic cancer with emphasis on known environmental and genetic factors and hereditary syndromes. Journal of the Pancreas, 11(3), 203–212.
Collett, J. R., Cho, E. J., Lee, J. F., Levy, M., Hood, A. J., Wan, C., & Ellington, A. D. (2005). Functional RNA microarrays for high-throughput screening of antiprotein aptamers. Analytical Biochemistry, 338(1), 113–123.
D’Cruz, D. P., Khamashta, M. A., & Hughes, G. R. (2007). Systemic lupus erythematosus. Lancet, 369(9561), 587–596.
De Ceuninck, F., Dassencourt, L., & Anract, P. (2004). The inflammatory side of human chondrocytes unveiled by antibody microarrays. Biochemical and Biophysical Research Communications, 323(3), 960–969.
Delehanty, J. B., & Ligler, F. S. (2002). A microarray immunoassay for simultaneous detection of proteins and bacteria. Analytical Chemistry, 74(21), 5681–5687.
Dexlin, L., Ingvarsson, J., Frendeus, B., Borrebaeck, C. A. K., & Wingren, C. (2008). Design of recombiant antibody microarrays for cell surface membrane proteomics. Journal of Proteome Research, 7(1), 319–327.
Dexlin-Mellby, L., Sandström, A., Centlow, M., Nygren, S., Hansson, S. R., Borrebaeck, C. A. K., & Wingren, C. (2010). Tissue protome profiling of preeclamptic placenta tissue using recombinant antibody microarrays. Proteomics – Clinical Applications, 4(10–11), 794–807.
Duffy, H. S., Iacobas, I., Hotchkiss, K., Hirst-Jensen, B. J., Bosco, A., Dandachi, N., Dermietzel, R., Sorgen, P. L., & Spray, D. C. (2007). The gap junction protein connexin32 interacts with the Src homology 3/Hook domain of discs large homolog 1. Journal Biological Chemistry, 282(13), 9789–9796.
Ebhardt, H. A., Root, A., Sander, C., & Aebersold, R. (2015). Applications of targeted proteomics in systems biology and translational medicine. Proteomics, 15(18), 3193–3208.
Ellmark, P., Belov, L., Huang, P., Lee, C. S., Solomon, M. J., Morgan, D. K., & Christopherson, R. I. (2006a). Multiplex detection of surface molecules on colorectal cancers. Proteomics, 6(6), 1791–1802.
Ellmark, P., Ingvarsson, J., Carlsson, A., Lundin, B. S., Wingren, C., & Borrebaeck, C. A. K. (2006b). Identification of protein expression signatures associated with Helicobacter pylori infection and gastric adenocarcinoma using recombinant antibody microarrays. Molecular & Cellular Proteomics, 5(9), 1638–1646.
Flores-Delgado, G., Liu, C. W., Sposto, R., & Berndt, N. (2007). A limited screen for protein interactions reveals new roles for protein phosphatase 1 in cell cycle control and apoptosis. Journal Proteome Research, 6(3), 1165–1175.
Fujita, O., Asanuma, M., Yokoyama, T., Miyazaki, I., Ogawa, N., & Kumon, H. (2006). Involvement of STAT3 in bladder smooth muscle hypertrophy following bladder outlet obstruction. Acta Medica Okayama, 60(6), 299–309.
Gao, W. M., Kuick, R., Orchekowski, R. P., Misek, D. E., Qiu, J., Greenberg, A. K., Rom, W. N., Brenner, D. E., Omenn, G. S., Haab, B. B., & Hanash, S. M. (2005). Distinctive serum protein profiles involving abundant proteins in lung cancer patients based upon antibody microarray analysis. BMC Cancer, 5, 110.
Gaudet, S., Janes, K. A., Albeck, J. G., Pace, E. A., Lauffenburger, D. A., & Sorger, P. K. (2005). A compendium of signals and responses triggered by prodeath and prosurvival cytokines. Molecular & Cellular Proteomics, 4(10), 1569–1590.
Gehring, A. G., Albin, D. M., Reed, S. A., Tu, S. I., & Brewster, J. D. (2008). An antibody microarray, in multiwell plate format, for multiplex screening of foodborne pathogenic bacteria and biomolecules. Analytical Bioanalytical Chemistry, 39(1), 497–506.
Gembitsky, D. S., Lawlor, K., Jacovina, A., Yaneva, M., & Tempst, P. (2004). A prototype antibody microarray platform to monitor changes in protein tyrosine phosphorylation. Molecualr & Cellular Proteomics, 3(11), 1102–1118.
Gerdtsson, A. S., Malats, N., Sall, A., Real, F. X., Porta, M., Skoog, P., Persson, H., Wingren, C., & Borrebaeck, C. A. K. (2015). A multicenter trial defining a serum protein signature associated with pancreatic ductal adenocarcinoma. International Journal Proteomics, 2015, 587250.
Ghobrial, I. M., McCormick, D. J., Kaufmann, S. H., Leontovich, A. A., Loegering, D. A., Dai, N. T., Krajnik, K. L., Stenson, M. J., Melhem, M. F., Novak, A. J., Ansell, S. M., & Witzig, T. E. (2005). Proteomic analysis of mantle-cell lymphoma by protein microarray. Blood, 105(9), 3722–3730.
Grow, A. E., Wood, L. L., Claycomb, J. L., & Thompson, P. A. (2003). New biochip technology for label-free detection of pathogens and their toxins. Journal of Microbiology Methods, 53(2), 221–233.
Haab, B. B. (2005). Antibody arrays in cancer research. Molecular & Cellular Proteomics, 4(4), 377–383.
Haab, B. B. (2006). Applications of antibody array platforms. Current Opinion in Biotechnology, 17(4), 415–421.
Haab, B. B., & Zhou, H. (2004). Multiplexed protein analysis using spotted antibody microarrays. Methods in Molecular Biology (Clifton, NJ), 264, 33–45.
Han, M. K., Hong, M. Y., Lee, D., Lee, D. E., Noh, G. Y., Lee, J. H., Kim, S. H., & Kim, H. S. (2006). Expression profiling of proteins in L-threonine biosynthetic pathway of Escherichia coli by using antibody microarray. Proteomics, 6(22), 5929–5940.
Hartmann, M., Roeraade, J., Stoll, D., Templin, M. F., & Joos, T. O. (2009). Protein microarrays for diagnostic assays. Analytical and Bioanalytical Chemistry, 393(5), 1407–1416.
He, M., & Taussig, M. J. (2001). Single step generation of protein arrays from DNA by cell-free expression and in situ immobilisation (PISA method). Nucleic Acids Research, 29(15), E73–73.
He, M., Stoevesandt, O., Palmer, E. A., Khan, F., Ericsson, O., & Taussig, M. J. (2008a). Printing protein arrays from DNA arrays. Nature Methods, 5(2), 175–177.
He, M., Stoevesandt, O., & Taussig, M. J. (2008b). In situ synthesis of protein arrays. Current Opinion in Biotechnology, 19(1), 4–9.
Hewitt, S. M. (2004). Design, construction, and use of tissue microarrays. Methods in Molecular Biology (Clifton, NJ), 264, 61–72.
Hodgkinson, V. C., EL, D., Agarwal, V., Garimella, V., Russell, C., Long, E. D., Fox, J. N., McManus, P. L., Mahapatra, T. K., Kneeshaw, P. J., Drew, P. J., Lind, M. J., & Cawkwell, L. (2012). Proteomic identification of predictive biomarkers of resistance to neoadjuvant chemotherapy in luminal breast cancer: a possible role for 14-3-3 theta/tau and tBID? Journal of Proteomics, 75(4), 1276–1283.
Hoeppe, S., Schreiber, T. D., Planatscher, H., Zell, A., Templin, M. F., Stoll, D., Joos, T. O., & Poetz, O. (2011). Targeting peptide termini, a novel immunoaffinity approach to reduce complexity in mass spectrometric protein identification. Molecular & Cellular Proteomics, 10(2), M110 002857.
Hoheisel, J. D., Alhamdani, M. S., & Schroder, C. (2013). Affinity-based microarrays for proteomic analysis of cancer tissues. Proteomics Clinical Application, 7(1–2), 8–15.
Huang, R. P., Huang, R., Fan, Y., & Lin, Y. (2001). Simultaneous detection of multiple cytokines from conditioned media and patient’s sera by an antibody-based protein array system. Analytical Biochemistry, 294(1), 55–62.
Huang, T. T., Sturgis, J., Gomez, R., Geng, T., Bashir, R., Bhunia, A. K., Robinson, J. P., & Ladisch, M. R. (2003). Composite surface for blocking bacterial adsorption on protein biochips. Biotechnology Bioenginering, 81(5), 618–624.
Hudelist, G., Singer, C. F., Kubista, E., & Czerwenka, K. (2005). Use of high-throughput arrays for profiling differentially expressed proteins in normal and malignant tissues. Anti-Cancer Drugs, 16(7), 683–689.
Ingvarsson, J., Larsson, A., Sjoholm, A. G., Truedsson, L., Jansson, B., Borrebaeck, C. A. K., & Wingren, C. (2007). Design of recombinant antibody microarrays for serum protein profiling: Targeting of complement proteins. Journal of Proteome Research, 6(9), 3527–3536.
Ingvarsson, J., Wingren, C., Carlsson, A., Ellmark, P., Wahren, B., Engstrom, G., Harmenberg, U., Krogh, M., Peterson, C., & Borrebaeck, C. A. K. (2008). Detection of pancreatic cancer using antibody microarray-based serum protein profiling. Proteomics, 8(11), 2211–2219.
Ivanov, S. S., Chung, A. S., Yuan, Z. L., Guan, Y. J., Sachs, K. V., Reichner, J. S., & Chin, Y. E. (2004). Antibodies immobilized as arrays to profile protein post-translational modifications in mammalian cells. Molecular & Cellular Proteomics, 3(8), 788–795.
Izzotti, A., Bagnasco, M., Cartiglia, C., Longobardi, M., & De Flora, S. (2004). Proteomic analysis as related to transcriptome data in the lung of chromium(VI)-treated rats. International Journal of Oncology, 24(6), 1513–1522.
Jemal, A., Siegel, R., Ward, E., Hao, Y., Xu, J., & Thun, M. J. (2009). Cancer statistics, 2009. CA Cancer Journal for Clinicians, 59(4), 225–249.
Jozwik, C. E., Pollard, H. B., Srivastava, M., Eidelman, O., Fan, Q., Darling, T. N., & Zeitlin, P. L. (2012). Antibody microarrays: analysis of cystic fibrosis. Methods Molecular Biology, 823, 179–200.
Kader, H. A., Tchernev, V. T., Satyaraj, E., Lejnine, S., Kotler, G., Kingsmore, S. F., & Patel, D. D. (2005). Protein microarray analysis of disease activity in pediatric inflammatory bowel disease demonstrates elevated serum PLGF, IL-7, TGF-beta1, and IL-12p40 levels in Crohn’s disease and ulcerative colitis patients in remission versus active disease. American Journal Gastroenterology, 100(2), 414–423.
Kaukola, T., Satyaraj, E., Patel, D. D., Tchernev, V. T., Grimwade, B. G., Kingsmore, S. F., Koskela, P., Tammela, O., Vainionpaa, L., Pihko, H., Aarimaa, T., & Hallman, M. (2004). Cerebral palsy is characterized by protein mediators in cord serum. Annual Neurology, 55(2), 186–194.
Kingsmore, S. F. (2006). Multiplexed protein measurement: technologies and applications of protein and antibody arrays. Nature Reviews, 5(4), 310–320.
Knezevic, V., Leethanakul, C., Bichsel, V. E., Worth, J. M., Prabhu, V. V., Gutkind, J. S., Liotta, L. A., Munson, P. J., Petricoin Iii, E. F., & Krizman, D. B. (2001). Proteomic profiling of the cancer microenvironment by antibody arrays. Proteomics, 1(10), 1271–1278.
Ko, I. K., Kato, K., & Iwata, H. (2005). Parallel analysis of multiple surface markers expressed on rat neural stem cells using antibody microarrays. Biomaterials, 26(23), 4882–4891.
Kopf, E., Shnitzer, D., & Zharhary, D. (2005). Panorama Ab Microarray Cell Signaling kit: A unique tool for protein expression analysis. Proteomics, 5(9), 2412–2416.
Krishnan, C., Kaplin, A. I., Graber, J. S., Darman, J. S., & Kerr, D. A. (2005). Recurrent transverse myelitis following neurobrucellosis: Immunologic features and beneficial response to immunosuppression. Journal of Neurovirology, 11(2), 225–231.
Kristensson, M., Olsson, K., Carlson, J., Wullt, B., Sturfelt, G., Borrebaeck, C. A. K., & Wingren, C. (2012). Design of recombinant antibody microarrays for urinary proteomics. Proteomics Clinical Applications, 6(5–6), 291–296.
Kusnezow, W., Banzon, V., Schroder, C., Schaal, R., Hoheisel, J. D., Ruffer, S., Luft, P., Duschl, A., & Syagailo, Y. V. (2007). Antibody microarray-based profiling of complex specimens: Systematic evaluation of labeling strategies. Proteomics, 7(11), 1786–1799.
Lao, Y. H., Peck, K., & Chen, L. C. (2009). Enhancement of aptamer microarray sensitivity through spacer optimization and avidity effect. Analytical Chemistry, 81(5), 1747–1754.
Ligler, F. S., Taitt, C. R., Shriver-Lake, L. C., Sapsford, K. E., Shubin, Y., & Golden, J. P. (2003). Array biosensor for detection of toxins. Analytical Bioanalytical Chemistry, 377(3), 469–477.
Lin, Y., Huang, R., Chen, L., Li, S., Shi, Q., Jordan, C., & Huang, R. P. (2004). Identification of interleukin-8 as estrogen receptor-regulated factor involved in breast cancer invasion and angiogenesis by protein arrays. International Journal of Cancer, 109(4), 507–515.
Lin, M. W., Ho, J. W., Harrison, L. C., dos Remedios, C. G., & Adelstein, S. (2013). An antibody-based leukocyte-capture microarray for the diagnosis of systemic lupus erythematosus. PLoS One, 8(3), e58199.
Liu, T., Xue, R., Dong, L., Wu, H., Zhang, D., & Shen, X. (2011). Rapid determination of serological cytokine biomarkers for hepatitis B virus-related hepatocellular carcinoma using antibody microarrays. Acta Biochimica et Biophysica Sinica Shanghai, 43(1), 45–51.
Lundberg, K., Lindstedt, M., Larsson, K., Dexlin, L., Wingren, C., Ohlin, M., Greiff, L., & Borrebaeck, C. A. K. (2008). Augmented Phl p 5-specific Th2 response after exposure of dendritic cells to allergen in complex with specific IgE compared to IgG1 and IgG4. Clinical Immunology (Orlando Fla), 128(3), 358–365.
Madan, M., Bishayi, B., Hoge, M., Messas, E., & Amar, S. (2007). Doxycycline affects diet- and bacteria-associated atherosclerosis in an ApoE heterozygote murine model: Cytokine profiling implications. Atherosclerosis, 190(1), 62–72.
Miller, J. C., Zhou, H., Kwekel, J., Cavallo, R., Burke, J., Butler, E. B., Teh, B. S., & Haab, B. B. (2003). Antibody microarray profiling of human prostate cancer sera: Antibody screening and identification of potential biomarkers. Proteomics, 3(1), 56–63.
Mitchell, A. M., Brown, M. D., Menown, I. B., & Kline, J. A. (2005). Novel protein markers of acute coronary syndrome complications in low-risk outpatients: A systematic review of potential use in the emergency department. Clinical Chemistry, 51(11), 2005–2012.
Mor, G., Visintin, I., Lai, Y., Zhao, H., Schwartz, P., Rutherford, T., Yue, L., Bray-Ward, P., & Ward, D. C. (2005). Serum protein markers for early detection of ovarian cancer. Procedings of National Academy Science U S A, 102(21), 7677–7682.
Nishizuka, S. S., & Mills, G. B. (2016). New era of integrated cancer biomarker discovery using reverse-phase protein arrays. Drug Metababolism and Pharmacokinetics, 31(1), 35–45.
Olsson, N., Wingren, C., Mattsson, M., James, P., O’Connell, D., Nilsson, F., Cahill, D. J., & Borrebaeck, C. A. K. (2011). Proteomic analysis and discovery using affinity proteomics and mass spectrometry. Molecular & Cellular Proteomics, 10(10), M110 003962.
Olsson, N., James, P., Borrebaeck, C. A. K., & Wingren, C. (2012a). Quantitative proteomics targeting classes of motif-containing peptides using immunoaffinity-based mass spectrometry. Molecular & Cellular Proteomics, 11(8), 342–354.
Olsson, N., Wallin, S., James, P., Borrebaeck, C. A. K., & Wingren, C. (2012b). Epitope-specificity of recombinant antibodies reveals promiscuous peptide-binding properties. Protein Science, 21(12), 1897–1910.
Orchekowski, R., Hamelinck, D., Li, L., Gliwa, E., van Brocklin, M., Marrero, J. A., Vande Woude, G. F., Feng, Z., Brand, R., & Haab, B. B. (2005). Antibody microarray profiling reveals individual and combined serum proteins associated with pancreatic cancer. Cancer Research, 65(23), 11193–11202.
Parker, C. E., & Borchers, C. H. (2014). Mass spectrometry based biomarker discovery, verification, and validation–quality assurance and control of protein biomarker assays. Molecular Oncology, 8(4), 840–858.
Patel, H., Nteliopoulos, G., Nikolakopoulou, Z., Jackson, A., & Gordon, M. Y. (2011). Antibody arrays identify protein-protein interactions in chronic myeloid leukaemia. Brittish Journal of Haematology, 152(5), 611–614.
Poetz, O., Hoeppe, S., Templin, M. F., Stoll, D., & Joos, T. O. (2009). Proteome wide screening using peptide affinity capture. Proteomics, 9(6), 1518–1523.
Rahman, A., & Isenberg, D. A. (2008). Systemic lupus erythematosus. New England Journal of Medicine, 358(9), 929–939.
Ramachandran, N., Hainsworth, E., Bhullar, B., Eisenstein, S., Rosen, B., Lau, A. Y., Walter, J. C., & LaBaer, J. (2004). Self-assembling protein microarrays. Science, 305(5680), 86–90.
Ramachandran, N., Hainsworth, E., Demirkan, G., & LaBaer, J. (2006). On-chip protein synthesis for making microarrays. Methods in Molecular Biology (Clifton, NJ), 328, 1–14.
Ramachandran, N., Raphael, J. V., Hainsworth, E., Demirkan, G., Fuentes, M. G., Rolfs, A., Hu, Y., & LaBaer, J. (2008). Next-generation high-density self-assembling functional protein arrays. Nature Methods, 5(6), 535–538.
Ramirez, A. B., & Lampe, P. D. (2010). Discovery and validation of ovarian cancer biomarkers utilizing high density antibody microarrays. Cancer Biomarker, 8(4–5), 293–307.
Renberg, B., Shiroyama, I., Engfeldt, T., Nygren, P. K., & Karlstrom, A. E. (2005). Affibody protein capture microarrays: Synthesis and evaluation of random and directed immobilization of affibody molecules. Analytical Biochemistry, 341(2), 334–343.
Renberg, B., Nordin, J., Merca, A., Uhlen, M., Feldwisch, J., Nygren, P. A., & Karlstrom, A. E. (2007). Affibody molecules in protein capture microarrays: Evaluation of multidomain ligands and different detection formats. Journal of Proteome Research, 6(1), 171–179.
Rovin, B. H., & Zhang, X. (2009). Biomarkers for lupus nephritis: The quest continues. Clinical Journal of the American Society of Nephrology, 4(11), 1858–1865.
Rowe, C. A., Tender, L. M., Feldstein, M. J., Golden, J. P., Scruggs, S. B., MacCraith, B. D., Cras, J. J., & Ligler, F. S. (1999). Array biosensor for simultaneous identification of bacterial, viral, and protein analytes. Analytical Chemistry, 71(17), 3846–3852.
Rowe-Taitt, C. A., Golden, J. P., Feldstein, M. J., Cras, J. J., Hoffman, K. E., & Ligler, F. S. (2000). Array biosensor for detection of biohazards. Biosensor and Bioelectronics, 14(10–11), 785–794.
Rubina, A. Y., Dyukova, V. I., Dementieva, E. I., Stomakhin, A. A., Nesmeyanov, V. A., Grishin, E. V., & Zasedatelev, A. S. (2005). Quantitative immunoassay of biotoxins on hydrogel-based protein microchips. Analytical Biochemistry, 340(2), 317–329.
Rucker, V. C., Havenstrite, K. L., & Herr, A. E. (2005). Antibody microarrays for native toxin detection. Analytical Biochemistry, 339(2), 262–270.
Saerens, D., Ghassabeh, G. H., & Muyldermans, S. (2008). Antibody technology in proteomics. Brief Functional Genomic Proteomic, 7(4), 275–282.
Sanchez-Carbayo, M., Socci, N. D., Lozano, J. J., Haab, B. B., & Cordon-Cardo, C. (2006). Profiling bladder cancer using targeted antibody arrays. American Journal of Pathology, 168(1), 93–103.
Sandstrom, A., Andersson, R., Segersvard, R., Lohr, M., Borrebaeck, C. A. K., & Wingren, C. (2012). Serum proteome profiling of pancreatitis using recombinant antibody microarrays reveals disease-associated biomarker signatures. Proteomics Clinical Applications, 6(9–10), 486–496.
Schroder, C., Jacob, A., Tonack, S., Radon, T. P., Sill, M., Zucknick, M., Ruffer, S., Costello, E., Neoptolemos, J. P., Crnogorac-Jurcevic, T., Bauer, A., Fellenberg, K., & Hoheisel, J. D. (2010). Dual-color proteomic profiling of complex samples with a microarray of 810 cancer-related antibodies. Molecular & Cellular Proteomics, 9(6), 1271–1280.
Schroder, C., Alhamdani, M. S., Fellenberg, K., Bauer, A., Jacob, A., & Hoheisel, J. D. (2011). Robust protein profiling with complex antibody microarrays in a dual-colour mode. Methods Molecular Biology, 785, 203–221.
Schwenk, J. M., Gry, M., Rimini, R., Uhlen, M., & Nilsson, P. (2008). Antibody suspension bead arrays within serum proteomics. Journal of Proteome Research, 7(8), 3168–3179.
Shafer, M. W., Mangold, L., Partin, A. W., & Haab, B. B. (2007). Antibody array profiling reveals serum TSP-1 as a marker to distinguish benign from malignant prostatic disease. Prostate, 67(3), 255–267.
Sharma, M., Arnason, J. T., Burt, A., & Hudson, J. B. (2006). Echinacea extracts modulate the pattern of chemokine and cytokine secretion in rhinovirus-infected and uninfected epithelial cells. Phytother Research, 20(2), 147–152.
Shi, W., Meng, Z., Chen, Z., Luo, J., & Liu, L. (2011). Proteome analysis of human pancreatic cancer cell lines with highly liver metastatic potential by antibody microarray. Molecular & Cellular Biochemistry, 347(1–2), 117–125.
Smith, L., Watson, M. B., O’Kane, S. L., Drew, P. J., Lind, M. J., & Cawkwell, L. (2006). The analysis of doxorubicin resistance in human breast cancer cells using antibody microarrays. Molecular Cancer Therapy, 5(8), 2115–2120.
Soderlind, E., Strandberg, L., Jirholt, P., Kobayashi, N., Alexeiva, V., Aberg, A. M., Nilsson, A., Jansson, B., Ohlin, M., Wingren, C., Danielsson, L., Carlsson, R., & Borrebaeck, C. A. K. (2000). Recombining germline-derived CDR sequences for creating diverse single-framework antibody libraries. Nature Biotechnology, 18(8), 852–856.
Sokolov, B. P., & Cadet, J. L. (2006). Methamphetamine causes alterations in the MAP kinase-related pathways in the brains of mice that display increased aggressiveness. Neuropsychopharmacology, 31(5), 956–966.
Solier, C., & Langen, H. (2014). Antibody-based proteomics and biomarker research – current status and limitations. Proteomics, 14(6), 774–783. doi:10.1002/pmic.201300334.
Sreekumar, A., Nyati, M. K., Varambally, S., Barrette, T. R., Ghosh, D., Lawrence, T. S., & Chinnaiyan, A. M. (2001). Profiling of cancer cells using protein microarrays: Discovery of novel radiation-regulated proteins. Cancer Research, 61(20), 7585–7593.
Srivastava, M., Eidelman, O., Jozwik, C., Paweletz, C., Huang, W., Zeitlin, P. L., & Pollard, H. B. (2006). Serum proteomic signature for cystic fibrosis using an antibody microarray platform. Molecular Genetics Metabolism, 87(4), 303–310.
Sukhdeo, K., Paramban, R. I., Vidal, J. G., Elia, J., Martin, J., Rivera, M., Carrasco, D. R., Jarrar, A., Kalady, M. F., Carson, C. T., Balderas, R., Hjelmeland, A. B., Lathia, J. D., & Rich, J. N. (2013). Multiplex flow cytometry barcoding and antibody arrays identify surface antigen profiles of primary and metastatic colon cancer cell lines. PLoS One, 8(1), e53015.
Sun, H., Chua, M. S., Yang, D., Tsalenko, A., Peter, B. J., & So, S. (2008). Antibody arrays identify potential diagnostic markers of hepatocellular carcinoma. Biomarker Insights, 3, 1–18.
Svedhem, S., Pfeiffer, I., Larsson, C., Wingren, C., Borrebaeck, C. A. K., & Hook, F. (2003). Patterns of DNA-labeled and scFv-antibody-carrying lipid vesicles directed by material-specific immobilization of DNA and supported lipid bilayer formation on an Au/SiO2 template. Chembiochem, 4(4), 339–343.
Szodoray, P., Alex, P., Brun, J. G., Centola, M., & Jonsson, R. (2004). Circulating cytokines in primary Sjogren’s syndrome determined by a multiplex cytokine array system. Scandinavian Journal Immunology, 59(6), 592–599.
Taitt, C. R., Anderson, G. P., Lingerfelt, B. M., Feldstein, S. M., & Ligler, F. S. (2002). Nine-analyte detection using an array-based biosensor. Analytical Chemistry, 74(23), 6114–6120.
Tannapfel, A., Anhalt, K., Hausermann, P., Sommerer, F., Benicke, M., Uhlmann, D., Witzigmann, H., Hauss, J., & Wittekind, C. (2003). Identification of novel proteins associated with hepatocellular carcinomas using protein microarrays. Journal of Pathology, 201(2), 238–249.
Tuomisto, T. T., Riekkinen, M. S., Viita, H., Levonen, A. L., & Yla-Herttuala, S. (2005). Analysis of gene and protein expression during monocyte-macrophage differentiation and cholesterol loading–cDNA and protein array study. Atherosclerosis, 180(2), 283–291.
Turtinen, L. W., Prall, D. N., Bremer, L. A., Nauss, R. E., & Hartsel, S. C. (2004). Antibody array-generated profiles of cytokine release from THP-1 leukemic monocytes exposed to different amphotericin B formulations. Antimicrobial Agents and Chemotherapy, 48(2), 396–403.
Uhlen, M., & Hober, S. (2009). Generation and validation of affinity reagents on a proteome-wide level. Journal Molecular Recognition, 22(2), 57–64.
Uhlen, M., & Ponten, F. (2005). Antibody-based proteomics for human tissue profiling. Molecular & Cellular Proteomics, 4(4), 384–393.
Vazquez-Martin, A., Colomer, R., & Menendez, J. A. (2007). Protein array technology to detect HER2 (erbB-2)-induced ‘cytokine signature’ in breast cancer. European Journal of Cancer, 43(7), 1117–1124.
Volk, S., Schreiber, T. D., Eisen, D., Wiese, C., Planatscher, H., Pynn, C. J., Stoll, D., Templin, M. F., Joos, T. O., & Potz, O. (2012). Combining ultracentrifugation and peptide termini group-specific immunoprecipitation for multiplex plasma protein analysis. Molecular & Cellular Proteomics, 11(7), O111 015438.
Voshol, H., Ehrat, M., Traenkle, J., Bertrand, E., & van Oostrum, J. (2009). Antibody-based proteomics: Analysis of signaling networks using reverse protein arrays. FEBS Journal, 276(23), 6871–6879.
Wacker, R., & Niemeyer, C. M. (2004). DDI-microFIA–A readily configurable microarray-fluorescence immunoassay based on DNA-directed immobilization of proteins. Chembiochem, 5(4), 453–459.
Wacker, R., Schroder, H., & Niemeyer, C. M. (2004). Performance of antibody microarrays fabricated by either DNA-directed immobilization, direct spotting, or streptavidin-biotin attachment: A comparative study. Analytical Biochemisty, 330(2), 281–287.
Walter, J. G., Kokpinar, O., Friehs, K., Stahl, F., & Scheper, T. (2008). Systematic investigation of optimal aptamer immobilization for protein-microarray applications. Analytical Chemistry, 80(19), 7372–7378.
Wang, C. C., Yim, K. W., Poon, T. C., Choy, K. W., Chu, C. Y., Lui, W. T., Lau, T. K., Rogers, M. S., & Leung, T. N. (2007). Innate immune response by ficolin binding in apoptotic placenta is associated with the clinical syndrome of preeclampsia. Clinical Chemistry, 53(1), 42–52.
Whiteaker, J. R., Zhao, L., Zhang, H. Y., Feng, L. C., Piening, B. D., Anderson, L., & Paulovich, A. G. (2007). Antibody-based enrichment of peptides on magnetic beads for mass-spectrometry-based quantification of serum biomarkers. Analytical Biochemistry, 362(1), 44–54.
Whiteaker, J. R., Zhao, L., Anderson, L., & Paulovich, A. G. (2010). An automated and multiplexed method for high throughput peptide immunoaffinity enrichment and multiple reaction monitoring mass spectrometry-based quantification of protein biomarkers. Molecular & Cellular Proteomics, 9(1), 184–196.
Wingren, C., & Borrebaeck, C. A. K. (2004). High-throughput proteomics using antibody microarrays. Expert Review of Proteomics, 1(3), 355–364.
Wingren, C., & Borrebaeck, C. A. K. (2006). Antibody microarrays – Current status and key technological advances. OMICS, 10(3), 411–427.
Wingren, C., & Borrebaeck, C. A. K. (2007). Progress in miniaturization of protein arrays–a step closer to high-density nanoarrays. Drug Discovery Today, 12(19–20), 813–819.
Wingren, C., & Borrebaeck, C. A. K. (2008). Antibody microarray analysis of directly labelled complex proteomes. Current Opinion in Biotechnology, 19(1), 55–61.
Wingren, C., & Borrebaeck, C. A. K. (2009). Antibody-based microarrays. Methods in Molecular Biology (Clifton, NJ), 509, 57–84.
Wingren, C., Ingvarsson, J., Dexlin, L., Szul, D., & Borrebaeck, C. A. K. (2007). Design of recombinant antibody microarrays for complex proteome analysis: Choice of sample labeling-tag and solid support. Proteomics, 7(17), 3055–3065.
Wingren, C., James, P., & Borrebaeck, C. A. K. (2009). Strategy for surveying the proteome using affinity proteomics and mass spectrometry. Proteomics, 9(6), 1511–1517.
Wingren, C., Sandström, A., Segersvärd, R., Carlsson, A., Andersson, R., Löhr, M., & Borrebaeck, C. A. K. (2012). Identification of serum biomarker signatures associated with pancreatic cancer. Cancer Research, 72(10), 2481–2490.
Wong, J., Sibani, S., Lokko, N. N., LaBaer, J., & Anderson, K. S. (2009). Rapid detection of antibodies in sera using multiplexed self-assembling bead arrays. Journal of Immunological Methods, 350(1–2), 171–182.
Wu, A. H., Smith, A., Christenson, R. H., Murakami, M. M., & Apple, F. S. (2004). Evaluation of a point-of-care assay for cardiac markers for patients suspected of acute myocardial infarction. Clinica Chimica Acta, 346(2), 211–219.
Yee, S. B., Bourdi, M., Masson, M. J., & Pohl, L. R. (2007). Hepatoprotective role of endogenous Interleukin-13 in a Murine Model of Acetaminophen-Induced Liver Disease. Chemical Research in Toxicology
Yue, T., Goldstein, I. J., Hollingsworth, M. A., Kaul, K., Brand, R. E., & Haab, B. B. (2009). The prevalence and nature of glycan alterations on specific proteins in pancreatic cancer patients revealed using antibody-lectin sandwich arrays. Molecular and Cellular Proteomics, 8(7), 1697–1707.
Yue, T., Partyka, K., Maupin, K. A., Hurley, M., Andrews, P., Kaul, K., Moser, A. J., Zeh, H., Brand, R. E., & Haab, B. B. (2011). Identification of blood-protein carriers of the CA 19–9 antigen and characterization of prevalence in pancreatic diseases. Proteomics, 11(18), 3665–3674.
Zhang, Y., Lou, J., Jenko, K. L., Marks, J. D., & Varnum, S. M. (2012). Simultaneous and sensitive detection of six serotypes of botulinum neurotoxin using enzyme-linked immunosorbent assay-based protein antibody microarrays. Analytical Biochemistry, 430(2), 185–192.
Zhou, H., Bouwman, K., Schotanus, M., Verweij, C., Marrero, J. A., Dillon, D., Costa, J., Lizardi, P., & Haab, B. B. (2004). Two-color, rolling-circle amplification on antibody microarrays for sensitive, multiplexed serum-protein measurements. Genome Biology, 5(4), R28.
Zhou, Q., Desta, T., Fenton, M., Graves, D. T., & Amar, S. (2005). Cytokine profiling of macrophages exposed to Porphyromonas gingivalis, its lipopolysaccharide, or its FimA protein. Infectious Immunity, 73(2), 935–943.
Acknowledgements
This study was supported by grants from the Swedish National Science Council (VR-M and VR-NT) and VINNOVA.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Wingren, C. (2016). Antibody-Based Proteomics. In: Végvári, Á. (eds) Proteogenomics. Advances in Experimental Medicine and Biology, vol 926. Springer, Cham. https://doi.org/10.1007/978-3-319-42316-6_11
Download citation
DOI: https://doi.org/10.1007/978-3-319-42316-6_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-42314-2
Online ISBN: 978-3-319-42316-6
eBook Packages: Biomedical and Life SciencesBiomedical and Life Sciences (R0)