
Abstract
Very often, overfitting of the multilayer perceptron can vary significantly in different regions of the model. Excess capacity allows better fit to regions of high, nonlinearity; and backprop often avoids overfitting the regions of low nonlinearity. The used generalized net will give us a possibility for parallel optimization of MLP based on early stopping algorithm.
Access provided by CONRICYT-eBooks. Download chapter PDF
Similar content being viewed by others


1 Introduction
In a series of papers, the process of functioning and the results of the work of different types of neural networks are described by Generalized Nets (GNs). Here, we shall discuss the possibility for training of feed-forward Neural Networks (NN) by backpropagation algorithm. The GN optimized the NN-structure on the basis of connections limit parameter.
The different types of neural networks [1] can be implemented in different ways [2–4] and can be learned by different algorithms [5–7].
2 The Golden Sections Algorithm
Let the natural number N and the real number C be given. They correspond to the maximum number of the hidden neurons and the lower boundary of the desired minimal error.
Let real monotonous function f determine the error f(k) of the NN with k hidden neurons.
Let function c: R × R → R be defined for every x, y ∈ R by
Let \( \varphi = \frac{\sqrt 5 + 1}{2} = 0.61 \) be the Golden number.
Initially, let we put: L = 1; M = [φ 2:N] + 1, where [x] is the integer part of the real number x ≥ 0.
The algorithm is the following:
-
1.
If L ≥ M go to 5.
-
2.
Calculate c(f(L), f(M)). If
$$ c(x,y) = \left\{ \begin{aligned} 1 {\text{ to go 3}} \hfill \\ \frac{ 1}{ 2}{\text{ to go 4}} \hfill \\ 0 {\text{ to go 5}} \hfill \\ \end{aligned} \right. $$ -
3.
L = M + 1; M = M + [φ 2 · (N−M)] + 1 go to 1.
-
4.
M = L + [φ 2 · (N−M)] + 1; L = L + 1 go to 1.
-
5.
End: final value of the algorithm is L.
3 Neural Network
The proposed generalized-net model introduces parallel work in learning of two neural networks with different structures. The difference between them is in neurons’ number in the hidden layer, which directly reflects on the all network’s properties. Through increasing their number, the network is learned with fewer number of epoches achieving its purpose. On the other hand, the great number of neurons complicates the implementation of the neural network and makes it unusable in structures with elements’ limits [5].
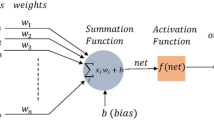
Figure 1 shows abbreviated notation of a classic tree-layered neural network.

xxx
In the many-layered networks, the one layer’s exits become entries for the next one. The equations describing this operation are
where
-
a m is the exit of the m-layer of the neural network for m = 1, 2, 3;
-
w is a matrix of the weight coefficients of the everyone of the entries;
-
b is neuron’s entry bias;
-
f m is the transfer function of the m-layer.
The neuron in the first layer receives outside the entries p. The neurons’ exit from the last layer determine the neural network’s exit a.
Because it belongs to the learning with teacher methods, the algorithm are submitted couple numbers (an entry value and an achieving aim—on the network’s exit)
Q ∈ (1…n), n—numbers of learning couple, where pQ is the entry value (on the network entry), and t Q is the exit’s value replying to the aim. Every network’s entry is preliminary established and constant, and the exit have to reply to the aim. The difference between the entry values and the aim is the error—e = t − a.
The “back propagation” algorithm [6] uses least-quarter error
In learning the neural network, the algorithm recalculates network’s parameters (W and b) to achieve least-square error.
The “back propagation” algorithm for i-neuron, for k + 1 iteration use equations
where
-
α—learning rate for neural network;
-
\( \frac{{\partial \hat{F}}}{{\partial w_{i}^{m} }} \)—relation between changes of square error and changes of the weights;
-
\( \frac{{\partial \hat{F}}}{{\partial b_{i}^{m} }} \)—relation between changes of square error and changes of the biases.
The overfitting [8] appears in different situations, which effect over trained parameters and make worse output results, as show in Fig. 2.

xxx
There are different methods that can reduce the overfitting—“Early Stopping” and “Regularization”. Here we will use Early Stopping [9].
When multilayer neural network will be trained, usually the available data must be divided into three subsets. The first subset named “Training set” is used for computing the gradient and updating the network weighs and biases. The second subset is named “Validation set”. The error on the validation set is monitored during the training process. The validation error normally decreases during the initial phase of training, as does the training set error. Sometimes, when the network begins to overfit the data, the error on the validation set typically begins to rise. When the validation error increases for a specified number of iterations, the training is stopped, and the weights and biases at the minimum of the validation error are returned [5]. The last subset is named “test set”. The sum of these three sets has to be 100 % of the learning couples.
When the validation error ev increases (the changing \( de_{v} \) have positive value) the neural network learning stops when
The classic condition for the learned network is when
where Emax is maximum square error.
4 GN Model
All definitions related to the concept “GN” are taken from [10]. The network, describing the work of the neural network learned by “Backpropagation” algorithm [9], is shown in Fig. 3.

xxx
The below constructed GN model is the reduced one. It does not have temporal components, the priorities of the transitions; places and tokens are equal, the place and arc capacities are equal to infinity.
Initially the following tokens enter in the generalized net:
-
in place S STR—α-token with characteristic
\( x_{0}^{\alpha } = \) “number of neurons in the first layer, number of neurons in the output layer”;
-
in place S e —β-token with characteristic
\( x_{0}^{\beta } = \) “maximum error in neural network learning Emax”;
-
in place S Pt —γ-token with characteristic
\( x_{0}^{\gamma } = \) “{p 1, t 1}, {p 2, t 2}, {p 3, t 3}”;
-
in place S F —one δ-token with characteristic
\( x_{0}^{\delta } = \) “f 1, f 2, f 3”.
The token splits into two tokens that enters respectively in places \( S_{F}^{\prime } \) and \( S_{F}^{\prime \prime } \);
-
in place S Wb —ε-token having characteristics
\( x_{0}^{\varepsilon } \, = \) “w, b”;
-
in place S con —ξ-token with a characteristics
\( x_{0}^{\xi } = \) “maximum number of the neurons in the hidden layer in the neural network—C max ”.
-
in place S dev —ψ-token with a characteristics
\( x_{0}^{\psi } = \) “Training set, Validation set, Test set”.
Generalized net is presented by a set of transitions
where transitions describe the following processes:
-
Z 1—Forming initial conditions and structure of the neural networks;
-
Z 2—Calculating ai using (1);
-
\( Z_{3}^{\prime } \)—Calculating the backward of the first neural network using (3) and (4);
-
\( Z_{3}^{\prime \prime } \)—Calculating the backward of the second neural network using (3) and (4);
-
Z 4—Checking for the end of all process.
Transitions of GN model have the following form. Everywhere
-
p—vector of the inputs of the neural network,
-
a—vector of outputs of neural network,
-
a i —output values of the i neural network, i = 1, 2,
-
e i —square error of the i neural network, i = 1, 2,
-
E max—maximum error in the learning of the neural network,
-
t—learn target;
-
w ik —weight coefficients of the i neural networks i = 1, 2 for the k iteration;
-
b ik —bias coefficients of the i neural networks i = 1, 2 for the k iteration.
where:

and
-
W 13,11 = “the learning couples are divided into the three subsets”;
-
W 13,12 = “is it not possible to divide the learning couples into the three subsets”.
The token that enters in place S 11 on the first activation of the transition Z 1 obtain characteristic
Next it obtains the characteristic
where [l min ;l max ] is the current characteristics of the token that enters in place S 13 from place S 43.
The token that enters place S 12 obtains the characteristic [l min;l max].
where

The tokens that enter places S 21 and S 22 obtain the characteristics respectively
and
where

and
-
\( W^{\prime }_{3A,31} \) = “e 1 > E max or \( de_{1v} < 0 \)”;
-
\( W^{\prime }_{3A,32} \) = “e 1 < E max or \( de_{1v} < 0 \)”;
-
\( W^{\prime }_{3A,33} \) = “(e 1 > E max and n 1 > m) or \( de_{1v} > 0 \)”;
where
-
n 1—current number of the first neural network learning iteration,
-
m—maximum number of the neural network learning iteration,
-
\( de_{1v} \)—validation error changing of the first neural network.
The token that enters place \( S_{31}^{\prime } \) obtains the characteristic “first neural network: w(k + 1), b(k + 1)”, according (4) and (5). The \( \lambda_{1}^{\prime } \) and \( \lambda_{2}^{\prime } \) tokens that enter place \( S_{32}^{\prime } \) and \( S_{33}^{\prime } \) obtain the characteristic
where

and
-
\( W_{3A,31}^{\prime \prime } \) = “e 2 > E max or \( de_{2v} < 0 \)”,
-
\( W_{3A,32}^{\prime \prime } \) = “e 2 < E max or \( de_{2v} < 0 \)”,
-
\( W_{3A,33}^{\prime \prime } \) = “(e 2 > E max and n2 > m) or \( de_{2v} > 0 \)”,
where
-
n 2—current number of the second neural network learning iteration;
-
m—maximum number of the neural network learning iteration;
-
\( de_{2v} \)—validation error changing of the second neural network.
The token that enters place \( S_{31}^{\prime \prime } \) obtains the characteristic “second neural network: w(k + 1), b(k + 1)”, according (4) and (5). The \( \lambda_{1}^{\prime \prime } \) and \( \lambda^{\prime \prime }_{2} \) tokens that enter place \( S_{32}^{\prime \prime } \) and \( S_{33}^{\prime \prime } \) obtain, respectively
where

and
-
W 44,41 = “e 1 < E max” and “e 2 < E max”;
-
W 44,42 = “e 1 > E max and n 1 > m” and “e 2 > E max and n 2 > m”;
-
W 44,43 = “(e 1 < E max and (e 2 > E max and n 2 > m)) or (e 2 < E max and (e 1 > E max and n 1 > m))”.
The token that enters place S 41 obtains the characteristic
Both NN satisfied conditions—for the solution is used the network who wave smaller numbers of the neurons.
The token that enters place S 42 obtain the characteristic
There is no solution (both NN not satisfied conditions).
The token that enters place S 44 obtains the characteristic
the solution is in interval [l min; l max]—the interval is changed using the golden sections algorithm.
5 Conclusion
The proposed generalized-net model introduces the parallel work in the learning of the two neural networks with different structures. The difference between them is in the number of neurons in the hidden layer, which reflects directly over the properties of the whole network.
On the other hand, the great number of neurons complicates the implementation of the neural network.
The constructed GN model allows simulation and optimization of the architecture of the neural networks using golden section rule.
References
http://www.fi.uib.no/Fysisk/Teori/NEURO/neurons.html. Neural Network Frequently Asked Questions (FAQ), The information displayed here is part of the FAQ monthly posted to comp.ai.neural-nets (1994)
Krawczak, M.: Generalized net models of systems. Bull. Polish Acad. Sci. (2003)
Sotirov, S.: Modeling the algorithm Backpropagation for training of neural networks with generalized nets—part 1. In: Proceedings of the Fourth International Workshop on Generalized Nets, Sofia, 23 Sept, pp. 61–67 (2003)
Sotirov, S., Krawczak, M.: Modeling the algorithm Backpropagation for training of neural networks with generalized nets—part 2, Issue on Intuitionistic Fuzzy Sets and Generalized nets, Warsaw (2003)
Hagan, M., Demuth, H., Beale, M.: Neural Network Design. PWS Publishing, Boston, MA (1996)
Rumelhart, D., Hinton, G., Williams, R.: Training representation by back-propagation errors. Nature 323, 533–536 (1986)
Sotirov, S.: A method of accelerating neural network training. Neural Process. Lett. Springer 22(2), 163–169 (2005)
Bellis, S., Razeeb, K.M., Saha, C., Delaney, K., O’Mathuna, C., Pounds-Cornish, A., de Souza, G., Colley, M., Hagras, H., Clarke, G., Callaghan, V., Argyropoulos, C., Karistianos, C., Nikiforidis, G.: FPGA implementation of spiking neural networks—an initial step towards building tangible collaborative autonomous agents, FPT’04. In: International Conference on Field-Programmable Technology, The University of Queensland, Brisbane, Australia, 6–8 Dec, pp. 449–452 (2004)
Haykin, S.: Neural Networks: A Comprehensive Foundation. Macmillan, NY (1994)
Atanassov, K.: Generalized Nets. World Scientific, Singapore (1991)
Gadea, R., Ballester, F., Mocholi, A., Cerda, J.: Artificial neural network implementation on a single FPGA of a pipelined on-line Backpropagation. In: 13th International Symposium on System Synthesis (ISSS’00), pp. 225–229 (2000)
Maeda, Y., Tada, T.: FPGA Implementation of a pulse density neural network with training ability using simultaneous perturbation. IEEE Trans. Neural Netw. 14(3) (2003)
Geman, S., Bienenstock, E., Doursat, R.: Neural networks and the bias/variance dilemma. Neural Comput. 4, 1–58 (1992)
Beale, M.H., Hagan, M.T., Demuth, H.B.: Neural Network Toolbox User’s Guide R2012a (1992–2012)
Morgan, N.: H, pp. 630–637. Bourlard, Generalization and parameter estimation in feedforward nets (1990)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2017 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Krawczak, M., Sotirov, S., Sotirova, E. (2017). Modeling Parallel Optimization of the Early Stopping Method of Multilayer Perceptron. In: Sgurev, V., Yager, R., Kacprzyk, J., Atanassov, K. (eds) Recent Contributions in Intelligent Systems. Studies in Computational Intelligence, vol 657. Springer, Cham. https://doi.org/10.1007/978-3-319-41438-6_7
Download citation
DOI: https://doi.org/10.1007/978-3-319-41438-6_7
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-41437-9
Online ISBN: 978-3-319-41438-6
eBook Packages: EngineeringEngineering (R0)