
Abstract
This chapter outlines some of the challenges and opportunities associated with adopting provenance principles (Cheney et al., Dagstuhl Reports 2(2):84–113, 2012) and standards (Moreau et al., Web Semant. Sci. Serv. Agents World Wide Web, 2015) in a variety of disciplines, including data publication and reuse, and information sciences.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
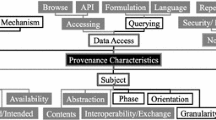
Using provenance in a broad diversity of application areas and disciplines entails a number of challenges, including specialising the generic provenance and domain-agnostic data model, PROV. This chapter provides a brief overview of these challenges, using the provenance lifecycle framework shown in Fig. 1 as a reference.

Schematic of provenance lifecycle
1 Provenance Definitions and Model
PROV, the Provenance standard, is a family of specifications released in 2013 by the Provenance Working Group, as a contribution to the Semantic Web suite of technologies at the World Wide Web Consortium [36]. PROV aims to define a generic data model for provenance that can be extended, in a principled way, to suit many application areas. The PROV-DM document [34] provides an operational definition of provenance for the community to use and build upon:
Provenance is defined as a record that describes the people, institutions, entities, and activities involved in producing, influencing, or delivering a piece of data or a thing.
The document goes on to position the definition in the context of Information Management:
The provenance of information is crucial in deciding whether information is to be trusted, how it should be integrated with other diverse information sources, and how to give credit to its originators when reusing it. In an open and inclusive environment such as the Web, where users find information that is often contradictory or questionable, provenance can help those users to make trust judgements.
1.1 PROV as a Community Data Model and Ontology
The specifications define a data model and an OWL ontology, along with a number of serializations for representing aspects of provenance. The term provenance, as understood in these specifications, refers to information about entities, activities, and people involved in producing a piece of data or thing, which can be used to form assessments about its quality, reliability or trustworthiness (PROV-Overview [40]). The specifications include a combination of W3C Recommendation and Note documents. Recommendation documents include (1) the main PROV data model specification (PROV-DM [34]), with an associated set of constraints and inference rules (PROV-CONSTRAINTS [5]); (2) an OWL ontology that allows a mapping of the data model to RDF (PROV-O [18]), and (3) a notation for PROV with a relational-like syntax, aimed at human consumption (PROV-N [35]). All other documents are Notes. These include PROV-XML, which defines a XSD schema for XML serialization [41]. PROV-AQ, the Provenance Access and Query document [33], which defines a Web-compliant mechanism to associate a dataset to its provenance; PROV-DICTIONARY [39], for expressing the provenance of data collections defined as sets of key-entity pairs; and PROV-DC [38], which provides a mapping between PROV-O and Dublin Core Terms.
1.2 The Provenance of PROV
PROV is the result of a long incubation process within the provenance commnunity, documented for instance in [6]. The idea of a community-grown data model for describing the provenance of data originated around 2006, when consensus began to emerge on the benefits of having a uniform representation for data provenance, process documentation, data derivation, and data annotation, as stated in [32]. The First Provenance Challenge [31] was then launched, to test the hypothesis that heterogeneous systems (mostly in the e-science/cyberinfrastructure space), each individually capable of producing provenance data by observing the execution of data-intensive processes, could successfully exchange such provenance observations with each other, without loss of information. The Open Provenance Model (OPM) [32] was proposed as a common data model for the experiment. Other Provenance Challenges followed, to further test the ability of the OPM to support interoperable provenance.
In September 2009, the W3C Provenance Incubator Group was created. Its mission, as stated in the charter [43], was to “provide a state-of-the art understanding and develop a roadmap in the area of provenance for Semantic Web technologies, development, and possible standardization.” W3C Incubator groups produce recommendations on whether a standardization effort is worth undertaking. Led by Yolanda Gil at University of Southern California, the group produced its final report in December 2010 [44]. The report highlighted the importance of provenance for multiple application domains, outlined typical scenarios that would benefit from a rich provenance description, and summarized the state of the art from the literature, as well as in the Web technology available to support tools that exploit a future standard provenance model. As a result, the W3C Provenance Working Group was created in 2011, chaired by Luc Moreau (University of Southampton) and Paul Groth (Vrije Universiteit Amsterdam). The group released its final recommendations for PROV in June 2013.
1.3 Other Notions of Data Provenance
Other formal models of data provenance exist, specifically in the context of database management. The provenance of a data item that is returned by a database query, for example, is defined by the semantics of the query itself, and mentions the fragments of the database state that were involved in the query processing [4]. An algebraic theory in support of data provenance representation and management has been developed [13]. This form of fine-grained provenance is often contrasted with coarse-grained provenance, which records the input / output derivations that are observed when functions are invoked, typically from within workflows and in the context of scientific data processing [9]. Attempts have also been made to reconcile these two views, e.g., when declarative-style queries are embedded within procedural workflow processing [1].
2 Embracing Provenance: Status and Opportunities
As illustrated in Fig. 1, there are a few key phases in the lifecycle of a provenance document: Production (Capture), persistent storage, Query, Sharing, Association with the underlying data products, and consumption/exploitation (Visualization/Analysis). The remainder of this short overview will only cover issues concerning Capture, Storage and Query, and Analysis, using the following simple example to illustrate key issues in each of these phases.
In PROV, a provenance document is a set of assertions about the derivations that account for the production of a dataset, including, when available, its attribution. For example, one can use PROV to formally express the following facts:
Alice took draft v0.1 of paper P, made some edits during a certain time interval, and produced a new draft v0.2 of P.
In doing so, she used papers p 1, p 2 as reference.
Alice then delegated Robert to do proofreading of P v0.2, which resulted in a new version v0.3 of P.
Alice also published a dataset D as supplementary material to P, which she has uploaded to a public data repository, for others to discover and reuse.
These facts can be expressed formally, using either RDF, XML, or PROV-N, the bespoke near-relational syntax mentioned earlier.
2.1 Extending PROV
The PROV Working Group worked hard to ensure that PROV can be extended in a principled way, in order to fit the needs of multiple disciplines where expressing the provenance of data may be important. Specifically, one can (1) use PROV-O, the PROV OWL ontology, in conjunction with other ontologies, in order to provide rich semantic annotations of data, and (2) extend PROV-O itself with domain-specific provenance concepts.
As an illustration of (1), in the example above one can semantically characterize data products as “papers” of a certain type, along with the associated activities (editing, proofreading) using a suitable vocabulary, while at the same time characterizing their provenance using an RDF serialisation of the example statements above. As a reference, in the recent past we have demonstrated this capability in our specification of the Janus ontology [25]. In brief, provenance and semantic annotations serve complimentary roles: the former tells the history of a data product, while the latter elucidates its meaning.
Regarding extending PROV, one notable example is the ProvONE ontology (formerly known as D-PROV) [27], aimed at capturing at the same time the data dependencies that emerge from observations during data creation (known as retrospective provenance), as well as the static structure of the process that is responsible for the generation of the process (known as prospective provenance) [21]. The latter is deliberately missing from PROV, owing to its generality. The D-PROV ontology specifically extends PROV to account for the structure of scientific workflows, a specific type of data-generating process that is important in many e-science applications.
In particular, the latest embodiment of D-PROV, called ProvONE [45], is currently in production use by the DataONE project (dataone.org). DataONE, a large NSF-funded project (2010–2018), is the largest Research Data conservancy project in the USA, with a focus on Earth Observational Data and ecology/climate data in particular. With a growing federation that already counts tens of member repositories and hundreds of thousands of science data objects, the DataONE architecture places metadata indexing and management at the cornerstone of its data search and discovery capabilities. “Searching by provenance” is a new and unique feature that leverages the ProvONE data model, as well as the automated capture of retrospective provenance whenever R or Matlab (and, soon, Python) scripts that access DataONE science objects are executed.
The ProvONE ontology provides a template for extending PROV, which can be used in a number of other domains, as it illustrates proper use of the PROV extensibility points.
2.2 Provenance Capture
Provenance is the result of observing a data transformation process in execution, including details of its inputs and outputs, be it a database query or a workflow, including processes carried out by humans or only partially automated. Key questions concerning the recording (“capturing”) of provenance include (1) what provenance-related events can be observed, (2) what is the level of detail of these observations, and (3) how does one deal with multiple, overlapping but inconsistent observations?
Regarding scientific data processing, the ability to record provenance relies entirely on the infrastructure on which the processes are executed. An increasing number of tools and systems are being retrofitted with provenance recording capabilities, including the best known workflow management systems [9, 28], and more recently, the Python [37] and the R languages [19, 20] for data analytics. Two specific instances of provenance capture sub-systems for scientific workflows, that we have actively contributed to, are [24], for the Taverna workflow management system developed in Manchester to support bioinformatics researchers [15, 26], and for the eScience Central workflow manager [14].
The case of completely automated processes which run in a centralized environment is, however, the simplest possible scenario. “Human-in-the-loop” processes are obviously more problematic, and are limited to capturing human interactions with information systems through a user interface. Clearly, solutions in this space are necessarily bespoke, with no known publications reporting specific case studies.
In each of these cases, the observations may be available at a specific level of abstraction, which may or may not be appropriate for the type of downstream analysis requirements (see below). These range from fine-grained, high-volume, system-level provenance (ie every file I/O operation in the system) [23], to “coarse-grained” provenance from workflow executions, where only the inputs and outputs of each workflow block can be observed.
As a consequence of these varying levels of details, it becomes necessary to be able to adjust the quantity of information contained in a provenance document, i.e., by creating views over provenance that represent abstractions over provenance. In the example above, we could for instance conflate the editing and proofreading activities into one, high-level “paper preparation” activity, and ignore the interim v0.2 of P. Our own work on provenance abstraction [29] builds upon prior research [2, 10], reflecting the user need not only to simplify the amount of provenance presented to the used, but also to obfuscate provenance in order to preserve its confidentiality.
A further complication in provenance capture, is that the observable processes normally take place on multiple, heterogeneous, autonomous and distributed systems, where the corresponding data is scattered. The provenance of an end data product must therefore be reconstructed by composing multiple, possibly inconsistent, and incomplete provenance fragments harvested from each of those systems. This is a relevant but under-studied area of research for provenance, with many potential applications that extend well beyond the realm of e-science.
2.3 Storage, Retrieval, and Query
Storing, indexing, and querying provenance documents requires a data layer not unlike that used to store the underlying data products that the provenance refers to. Data provenance that describes the history of large volumes of data is itself bound to have a high volume. Furthermore, if one includes in the provenance the intermediate data products that are generated as part of a complex data processing pipeline, it is easy to see that the size of the provenance documents may vastly exceed that of the data whose history it describes. Older and recent research has been devoted to studying the trade-offs between storing intermediate data products as part of provenance, which may incur a high storage cost [46], as opposed to partially re-computing the data products (“ smart rerun” [7]).
Issues of dealing with large-scale provenance were addressed in the BigProv international workshop organized in 2013 and co-located with the EDBT conference. A number of submissions contributed to corroborate the hypothesis that the scalability of provenance management systems is becoming a practical problem if interesting analytics are to be derived from it. Amongst these, a study on reconstructing provenance from log files [12].
Provenance documents such as the one in our example are naturally expressed in the form of a graph. This suggests that graph databases (GDBMS) are suitable for their persistent storage, indexing, and querying. In our past work we have been experimenting with Neo4J, a new generation GDBMS, in order to study the scalability properties of provenance storage. In particular, we have developed ProvGen [11], a generator of synthetic provenance graphs of arbitrary size and with topology constraints. ProvGen is designed to create benchmarks for testing the performance of graph-based provenance data layers. It can generate provenance documents with millions of nodes and stores them in a Neo4J database.
At the same time, the standard RDF serialization of PROV, which specifies how provenance documents can be expressed using RDF triples that comply with the PROV ontology (PROV-O), lends itself well to storing provenance graphs in existing RDF triple stores. However, despite the need for testing provenance data layers at scale, and our own past attempts at soliciting contributions that document scalability of provenance storage and query systems (the ProvBench workshop, co-located with BigProv (see above), to the best of our knowledge no official benchmarks have ever been released.
2.4 Provenance Analytics and Novel Uses for Provenance
With the broad term “provenance analytics” we indicate all forms of consumption and exploitation of provenance corpora, once they have been captured and made available through suitable data engineering solutions, alluded to above. Relevant questions include: what can we learn from a large body of provenance metadata? what techniques and algorithms can be successfully borrowed from the realm of (Big) Data Analytics, in order to gain insight into data through its provenance?
Much has been made of provenance as a key form of metadata to help understanding the quality of data as well as its trustworthiness. A whole special issue of the ACM Journal of Data and Information Quality, has been devoted to the topic [42]. Despite several high quality submissions, however, more research is needed to fully elucidate the connection between data provenance and quality.
Many other opportunities are worth exploring that exploit provenance corpora in several domains. One line of research still in its infancy, concerns using provenance to ascribe transitive credit [16] to scientists and other contributors who publish their datasets in public data repositories, for others to reuse. Data publication is a rapidly growing area of Open Science, which is based upon the assumption that scientists will spontaneously make their datasets public, as long as due credit is given to them through community mechanisms. Unfortunately, these mechanisms are still quite primitive, limited as they are to counting the number of citations to datasets, as they are found in paper publications (see for instance the Making Data Count project [17]). Instead, transitive credit pushes this embrionic notion of “credit for data” much further, as it leverages provenance to take into account multiple generations of data derivation and reuse.
Other disciplines farther away from computing and science will benefit from properly collected provenance, wherever providing accountability of a process execution is important. One example amongst many concerns food safety, where traceability of lots of food along a supply chain is critical to ensuring compliance with quality standards and proper handling, and to answer questions in case of accidents involving consumption of unsafe food.
2.5 Three Key Challenges for Practical Usability of Provenance Data
To conclude this overview, three areas when more research is needed in order to make provenance usable in practice are worth mentioning.
Incomplete and Uncertain Provenance Generation and usage of data naturally occurs in many different ways through multiple, autonomous information systems. As a consequence, the provenance of such data is also naturally fragmented and incomplete. One major problem in provenance research is how to reconstruct a complete “big picture” out of such fragments. We are currently addressing this foundational problem in the specific setting of Open Research Data reuse, as this is a key issue when establishing transitive credit as mentioned above.
Trusted Provenance A second issue concerns accountability of the provenance documents themselves. To the extent that provenance documents are considered as a form of evidence for the underlying data, it is necessary to ensure that the provenance itself can be trusted not to have been tampered with. Using provenance traces in, say, a court of law, requires strong non-repudiability and integrity guarantees, which can only be provided by a trusted computing infrastructure [22, 30]. The notion of tamper-proof (or rather, tamper-evident) provenance has been touched upon in the past [47], but more research is needed as this clearly conflicts with the notion of provenance abstraction through views, alluded to above, namely when generating views involves redacting the provenance document itself [3].
Provenance to Help the Reproducibility of Scientific Processes Lastly, we mention a long-standing promise on which provenance studies have largely yet to deliver. Much has been said (and there is no scope for a full survey here) of the role of provenance to support reproducible science, since the connection between reproducibility and provenance was first made back in 2008 [8].
Reproducibility is a known problem for a large number of scientific processes of the past, which are often encoded as a loose collection of scripts with external dependencies on ever-changing libraries, services, and databases. Practical solutions where provenance is used to ensure that these processes are reproducible are not readily available, however. In the recent past, we have addressed one aspect of this problem, namely by showing that provenance traces can be used to explain the differences between two sets of results that are obtained from the executions of two versions of a process [28], the latest being a reproduction of the original. Much remains to be done, however, to clearly prove the role of provenance data in data-driven, reproducible science.
References
Amsterdamer, Y., Davidson, S.B., Deutch, D., Milo, T., Stoyanovich, J., Tannen, V.: Putting lipstick on pig: enabling database-style workflow provenance. Proc. VLDB Endow. 5 (4), 346–357 (2011)
Biton, O., Cohen-Boulakia, S., Davidson, S.B.: Zoom*UserViews: querying relevant provenance in workflow systems. In: VLDB, pp. 1366–1369 (2007)
Cadenhead, T., Khadilkar, V., Kantarcioglu, M., Thuraisingham, B.: Transforming provenance using redaction. In: Proceedings of the 16th ACM Symposium on Access Control Models and Technologies, SACMAT ’11, pp. 93–102. ACM, New York (2011)
Cheney, J., Chiticariu, L., Tan, W.-C.: Provenance in databases: why, how, and where. Found. Trends Databases 1, 379–474 (2009)
Cheney, J., Missier, P., Moreau, L.: Constraints of the provenance data model. Technical Report (2012)
Cheney, J., Finkelstein, A., Ludaescher, B., Vansummeren, S.: Principles of provenance (Dagstuhl Seminar 12091). Dagstuhl Reports 2 (2), 84–113 (2012)
Cohen-Boulakia, S., Leser, U.: Search, adapt, and reuse: the future of scientific workflows. SIGMOD Rec. 40 (2), 6–16 (2011)
Davidson, S., Freire, J.: Provenance and scientific workflows: challenges and opportunities. In: Proceedings of SIGMOD Conference, Tutorial, pp. 1345–1350 (2008)
Davidson, S., Cohen-Boulakia, S., Eyal, A., Ludäscher, B., McPhillips, T., Bowers, S., Anand, M.K., Freire, J.: Provenance in scientific workflow systems. In: Data Engineering Bulletin, vol. 30. IEEE, New York (2007)
Dey, S., Zinn, D., Ludäscher, B.: ProPub: towards a declarative approach for publishing customized, policy-aware provenance. In: Cushing, J.B., French, J., Bowers, S. (Eds.), Scientific and Statistical Database Management. Lecture Notes in Computer Science, vol. 6809, pp. 225–243. Springer, Berlin, Heidelberg (2011)
Firth, H., Missier, P.: ProvGen: generating synthetic PROV graphs with predictable structure. In: Proceedings of IPAW 2014 (Provenance and Annotations), Koln (2014)
Ghoshal, D., Plale, B.: Provenance from log files: a bigdata problem. In: Proceedings of BigProv Workshop on Managing and Querying Provenance at Scale (2013)
Green, T.J., Karvounarakis, G., Tannen, V.: Provenance semirings. In: PODS, pp. 31–40 (2007)
Hiden, H., Watson, P., Woodman, S., Leahy, D.: e-Science central: cloud-based e-Science and its application to chemical property modelling. Technical Report cs-tr-1227. School of Computing Science, Newcastle University (2011)
Hull, D., Wolstencroft, K., Stevens, R., Goble, C.A., Pocock, M.R., Li, P., Oinn, T.: Taverna: a tool for building and running workflows of services. Nucleic Acids Res. 34, 729–732 (2006)
Katz, D.S.: Transitive credit as a means to address social and technological concerns stemming from citation and attribution of digital products. J. Open Res. Soft. 2 (1), e20 (2014)
Kratz, J.E., Strasser, C.: Making data count. Nature Scientific Data 2, 150039 (2015)
Lebo, T., Sahoo, S., McGuinness, D., Belhajjame, K., Cheney, J., Corsar, D., Garijo, D., Soiland-Reyes, S., Zednik, S., Zhao, J.: PROV-O: The PROV ontology. Technical Report (2012)
Lerner, B.S., Boose, E.R.: Collecting provenance in an interactive scripting environment. In: Proceedings of TAPP’14 (2014)
Lerner, B., Boose, E.: RDataTracker: collecting provenance in an interactive scripting environment. In: 6th USENIX Workshop on the Theory and Practice of Provenance (TaPP 2014) (2014)
Lim, C., Lu, S., Chebotko, A., Fotouhi, F.: Prospective and retrospective provenance collection in scientific workflow environments. In: 2010 IEEE International Conference on Services Computing (SCC), pp. 449–456 (2010)
Lyle, J., Martin, A.: Trusted computing and provenance: better together. In: Proceedings of the 2nd Conference on Theory and Practice of Provenance, TAPP’10, Berkeley, CA, p. 1. USENIX Association, Berkeley, CA (2010)
Macko, P., Chiarini, M., Seltzer, M.: Collecting provenance via the Xen hypervisor. In: Freire, J., Buneman, P. (eds.) TAPP Workshop, Heraklion (2011)
Missier, P., Paton, N., Belhajjame, K.: Fine-grained and efficient lineage querying of collection-based workflow provenance. In: Proceedings of EDBT, Lausanne, Switzerland (2010)
Missier, P., Sahoo, S.S., Zhao, J., Sheth, A., Goble, C.: Janus: from workflows to semantic provenance and linked open data. In: Proceedings of IPAW 2010, Troy, NY (2010)
Missier, P., Soiland-Reyes, S., Owen, S., Tan, W., Nenadic, A., Dunlop, I., Williams, A., Oinn, T., Goble, C.: Taverna, reloaded. In: Gertz, M., Hey, T., Ludaescher, B. (eds.) Proceedings of SSDBM 2010, Heidelberg (2010)
Missier, P., Dey, S., Belhajjame, K., Cuevas, V., Ludaescher, B.: D-PROV: extending the PROV provenance model with workflow structure. In: Proceedings of TAPP’13, Lombard, IL (2013)
Missier, P., Woodman, S., Hiden, H., Watson, P.: Provenance and data differencing for workflow reproducibility analysis. Concurr. Comput. 28 (4), 995–1015 (2016)
Missier, P., Bryans, J., Gamble, C., Curcin, V., Danger, R.: ProvAbs: model, policy, and tooling for abstracting PROV graphs. In: Proceedings of IPAW 2014 (Provenance and Annotations), Koln. Springer, Berlin (2014)
Mitchell, C., Mitchell, C., Mitchell, C.: Trusted computing. In: Chen, L., Mitchell, C.J., Martin, A. (eds.) Proceedings of Trust 2009, Oxford. Springer, Berlin (2005)
Moreau, L., Ludäscher, B., Altintas, I., Barga, R.S.: The first provenance challenge. Concurr. Comput. 20, 409–418 (2008)
Moreau, L., Clifford, B., Freire, J., Futrelle, J., Gil, Y., Groth, P., Kwasnikowska, N., Miles, S., Missier, P., Myers, J., Plale, B., Simmhan, Y., Stephan, E., Van Den Bussche, J.: The open provenance model—core specification (v1.1). Futur. Gener. Comput. Syst. 7 (21), 743–756 (2011)
Moreau, L., Hartig, O., Simmhan, Y., Myers, J., Lebo, T., Belhajjame, K., Miles, S.: PROV-AQ: provenance access and query. Technical Report (2012)
Moreau, L., Missier, P., Belhajjame, K., B’Far, R., Cheney, J., Coppens, S., Cresswell, S., Gil, Y., Groth, P., Klyne, G., Lebo, T., McCusker, J., Miles, S., Myers, J., Sahoo, S., Tilmes, C.: PROV-DM: the PROV data model. Technical Report. World Wide Web Consortium (2012)
Moreau, L., Missier, P., Cheney, J., Soiland-Reyes, S.: PROV-N: the provenance notation. Technical Report (2012)
Moreau, L., Groth, P., Cheney, J., Lebo, T., Miles, S.: The rationale of PROV. Web Semant. Sci. Serv. Agents World Wide Web 35, Part 4, 235–257 (2015)
Murta, L., Braganholo, V., Chirigati, F., Koop, D., Freire, J.: noWorkflow: capturing and analyzing provenance of scripts. In: Proceedings of IPAW’14 (2014)
PROV DC (2013). Available at http://www.w3.org/TR/prov-dc/
PROV Dictionary (2013). Available at http://www.w3.org/TR/prov-dictionary/
PROV-Overview: An Overview of the PROV Family of Documents. Technical Report (2012)
PROV-XML (2013). Available at http://www.w3.org/TR/prov-xml/
Special Issue on Provenance, Data and Information Quality. J. Data Inf. Qual. 5 (3) (2015)
The Provenance Incubator Group Charter (2009). Available at http://www.w3.org/2005/Incubator/prov/charter
The Provenance Incubator Group Final Report (2010). Available at http://www.w3.org/2005/Incubator/prov/XGR-prov-20101214/
The ProvONE provenance model (2014). Available at http://tinyurl.com/ProvONE
Woodman, S., Hiden, H., Watson, P.: Workflow provenance: an analysis of long term storage costs. In: Proceedings of 10th WORKS workshop, Austin, TX (2015)
Zhang, J., Chapman, A., LeFevre, K.: Do you know where your datas been? tamper-evident database provenance. In: Jonker, W., Petkovic, M. (eds.) Secure Data Management. Lecture Notes in Computer Science, vol. 5776, pp. 17–32. Springer, Berlin/Heidelberg (2009)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Missier, P. (2016). The Lifecycle of Provenance Metadata and Its Associated Challenges and Opportunities. In: Lemieux, V. (eds) Building Trust in Information. Springer Proceedings in Business and Economics. Springer, Cham. https://doi.org/10.1007/978-3-319-40226-0_8
Download citation
DOI: https://doi.org/10.1007/978-3-319-40226-0_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-40225-3
Online ISBN: 978-3-319-40226-0
eBook Packages: Economics and FinanceEconomics and Finance (R0)