
Abstract
The static image and video information compression algorithms development over the last 15–20 years, as well as standardized and non-standardized formats for data storage and transmission have been analyzed; the main factors affecting the further development of approaches that eliminate the redundancy of transmitted and stored visual information have been studied. The conclusion on the current prospects for the development of image compression technologies has been made. New approaches that use new low-level quasi-orthogonal matrices as transform operators have been defined. The advantages of such approaches opening new fundamentally different opportunities in the field of applied processing of digital visual information have been identified and presented.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
- Image compression
- Video compression
- Protection against unauthorized access
- M-matrices
- Audiovisual information coding
- Metadata
1 Introduction
The compression of images and video information (successive images of the same scene) has been under research and constant application for the last 40 years. The following factors were the main stimulus to that:
-
Great importance of visual information as such for people;
-
Continuous development of microelectronics and computers, as well as information recording, storage, and playback technology;
-
Emergence and development of network technology providing high-speed information exchange not only for personal or local use, but internationally.
The last stimulus led to the emergence of planetary-scale services that allow people to instantly share images and videos or provide their own visual materials for public display for long periods of time. Last but not least, of course, are the so-called “social media” services, which also seek to provide users with all the necessary features to use visual information along with the text. For example, the number of new images posted on Facebook is doubling every 2 years [1].
Not only the number of new images, but their resolution also increases, which ultimately results in the almost exponential growth of the volume of stored and transmitted data, which is a digital representation of visual images. As a result, the unprecedented increase in storage volumes and channel capacities is continuously competing with the unprecedented increase in the volume of new digital information.
This paper attempts to assess the current situation, and study the trends and prospective areas of research and development in the field of image and video compression. The paper is based on the analysis of existing domestic and foreign publications and the authors’ experience obtained in cooperation with a team of scientists and engineers of one of the R&D companies during the research and development of video image transmission and recording systems, as well as with employees of Department of Computing systems and networks of Saint-Petersburg State University of Aerospace Instrumentation.
2 Standards and Non-standardized Solutions for the Digital Visual Information Compression
2.1 Images Compression
The discrete cosine transformation (DCT) was the base for images compression algorithms for decades. The algorithm, consolidated by the JPEG group standard and which received the name JPEG, became the most popular among them. The main disadvantages of the similar algorithms are known both to experts, and ordinary users. In particular, reticulated character artifacts at significant compression coefficients and contrast boundaries blur.
With the computing systems performance development and, thanks to certain achievements in the “wavelet bases” theory, to replace DCT (or in addition to DCT) the discrete wavelet transform (DWT) came. The JPEG group was noted by the DWT basis standard creation with considerable functionality. The standard appeared at the end of the 2000th year and was called JPEG2000. The increase in compressed and then the restored images quality in comparison with JPEG is noted as the various tests result at identical compression coefficients approximately for 20 %. Especially obvious distinction is noted at big coefficients, because JPEG2000 doesn’t make distortion in the restored images leading to the “blocks” emergence.
It is also necessary to note, that DWT was applied in different variations and also in non-standardized form, including in the hardware codecs form, which perform the real-time processing (for example, integrated circuits ADV601/ADV611 of Analog Devices corporation). They also had rather good results, however, over time JPEG2000 were ousted. In a very short time, after the JPEG2000 standard publication, Analog Devices company begins to produce popular to date hardware single-chip JPEG2000-codec ADV202/ADV212.
It should be noted that there is so called VTC mode as a part of the video compression applied standard—MPEG4, (Visual Texture Coding—coding of the visual textures), which also allows to compress “still images”, using DWT. However, in comparison with JPEG2000, it has a very little functionality.
Something unusual among the applied bases for the images transformation to be compressed, is Walsh functions system and, respectively, Walsh-Hadamard transformation [2]. In particular, WebP [3] format, developed by the Google Inc. company, together with DCT, uses Walsh functions basis. WebP is considered by community as progressive replacement of the JPEG format, however at the time of the article writing, WebP distribution and popularity didn’t become a little more significant. Moreover, some authors prove their skepticism concerning the new algorithm advantages [4]. Presumably, the reasons of failure should be looked for in unprecedented JPEG format prevalence, which have being used for a long time for the large images number storage.
Nevertheless, it should be noted the existence of the additional mechanisms, entered into WebP to increase the compression coefficient. There are several prediction modes, allowing in certain cases to transfer not the separate compressed images blocks (areas), but only the difference (a prediction error) between the next blocks among them. Together all the applied approaches, according to the developers approval at “lossless compression” increase the compression efficiency in WebP relatively to PNG by 26 %, and for the mode “lossy”—relatively to JPEG—at 25–34 %. The equivalence quality assessment is based on SSIM metrics [5].
Actually the algorithms based on DCT and DWT, together with the contents prediction mechanisms of the adjoining spatial areas or without them, are urged to eliminate redundancy in the transferred/stored data. It concerns not purely information redundancy (in this case, more than 2–3 multiple compression can’t be reached), but redundancy in the sense of the human visual system perception. For example, it is known that small details of the visual images (spatially high-frequency) are much less important for the quality picture perception, than large ones (spatially low-frequency). That’s why it is possible to eliminate high-frequency components with the necessary “roughness” degree from the image, making the information losses, but not too disturbing the perception. In chromaticity components such distortions are noticeable significantly less, than in the brightness one, and this fact is also used.
Thus, the images compression algorithms, using different tools, operate the “painless” small details removal idea with some additional receptions, giving a dozen or two percent gain. Meanwhile, the revolutionary ideas, which give a quantum leap of images compression characteristics algorithms aren’t present at the moment and, perhaps, they won’t appear without approach change to the analysis level of this information type in the near future.
2.2 Video Compression
The playing video is presented in the consistently replacing each other images form with a particular frequency. Therefore images compression algorithms are quite applicable for the individual video frames, as evidenced by the existence of the storage video files formats “Motion-JPEG” (compressed video frames as separate image algorithm JPEG) and “Motion-JPEG2000” (video frames are compressed with the algorithm JPEG2000). However all of them aren’t so effective for the video, as the algorithms, operating inter-frame (temporary) redundancy idea, when the difference between the adjacent frames, rather than the whole video frame, is exposed to compression. It is obvious, that in this case it is possible to reach much higher coefficients, since the difference between the video frames is generally very small, because of the small time interval.
There is a limited set of the applications, demanding separate compression of each video frame, however this set is limited. For example, in the cases, when each frame has to represent the complete information unit, but not to be synthesized from some sequence of initial arrays. Or when changes in the recorded picture are essential, but thus it is necessary to keep both quality of the video image, and intensity of the kept information transferred flow is continuous at the set level.
Various mechanisms of the changes prediction in the video sequence and additional reduction need to compress and keep all taken information are actively used in addition to the reduction of inter-frame redundancy. To date the most famous video compression algorithms are that ones, which utilize the mentioned above ideas—H.261, H.263, H.264 and algorithms of MPEG group: MPEG1, MPEG2, MPEG4. It is important to note, that expediency and sufficiency of DCT application (but not DWT) to eliminate the spatial redundancy is repeatedly shown for all these algorithms.
In 2013 the new video images compression standard H.265 [6] was released. Its developers predict approximately double capacity reduction, which are necessary for the transfer, in comparison with the best existing codecs. When developing the standard, the following requirements were formulated:
-
Possibility of compression support without information losses and visible distortions.
-
Frame formats support from QVGA (320 × 240) to 4K and 8K (UHDTV).
-
Color sampling to 4:4:4, broad color coverage and alpha channel, increased color depth support.
-
Constant and variable frame frequency support (up to 60 frames per second and more).
The founders paid special attention for the codec insistence restriction question to the computing resources. Moreover, it is claimed that with the image dimension growth, compression coefficient has to increase a little.
All the statements and estimates certainly demand a practical check on the various platforms to confirm them, and also to except any essential negative sides. Now it is possible to say, that this standard incorporated all the possible algorithmic opportunities, aimed to provide the consumer with qualitative video with the minimum expenses.
2.3 Opportunities to Improve the Compression Algorithms Characteristics
During the last 15–20 years, all the attempts to improve the existing images compression algorithms were expressed in considerable number of the published scientific works and the defended dissertations. The results generalization shows, that the quantitative assessment of “improvements” at objective approach makes 10–20 %, and more rare 30 %, it varies depending on taken image type (gray or color photos, black-and-white text, cartographical images, etc.). For example, mesh artifacts elimination on the image, which passed direct and return JPEG transformation with rather big compression coefficients [7–9] was a classical task during some time. Besides, interesting results were achieved with using nonlinear decomposition by means of wavelet-functions [10], at color transformations application for color images [11] and with use of images perception model by the human vision [12].
To replace DCT by DWT in video information compression technologies was done considerable work in two various directions. The first option is the prediction error coding by means of DWT [13], the second is so-called 3D wavelet decomposition [14, 15]. And though these technologies showed the quality increase in comparison with the existing approaches at the similar compression coefficients, nevertheless, the majority of them are intended to ensure functionality development; for example, scalability and progressive transfer entering (resolution reduction or blur part of the overall image).
When concentrating only on the search of compression coefficients increase opportunities, a number of modern scientific and technical achievements is ignored. In connection with prompt mobile technologies development and the increasing need of Internet users in the video information, besides actually breakthrough compression technology search, development and deployment of the transferred images effective scaling technologies in real time, depending on the information consumer (receiver) characteristics are seemed to be more actual to date. For an illustration it is possible to give an example, when the portable device with a relatively low resolution display transmits Web page images of the Full HD format. This is obviously impractical and, therefore, the transmitted content becomes dependent on the terminal properties. Thus, when defining the receiver content characteristics, at the level of the company, providing the Web server, or the Internet service provider, or even at the routers level it is possible to reduce the demanded information traffic significantly.
3 An Opportunities Assessment in the Compression Technologies Development and the New Approach Advantages
3.1 Possibilities for Compression Algorithms Improvement
In the work [16] the authors give approaches classification to the coding problem (compression) solution of images and video, and also the corresponding consecutive technologies development (see Table 1). In the current work context, the greatest interest will be represented by the 4th and 5th generations, therefore it is necessary to consider in details.
Recognition and restoration involves the content type determining (house, car, landscape, person, etc.) to implement the coding method, focused on certain content. Rather big breakthrough is made in this direction in the MPEG4 algorithm, which applies specific technology of recognition, coding and further “animation” of the person face image.
One more step on the way to the 5th generation is taken in the MPEG7 standard. The certain standard way of the audiovisual information various types description is specified in it. (The elements, which are the description of audiovisual content, are known also as “metadata”.) As soon as the audiovisual content is described in the metadata terms, the image is prepared for the coding process. It should be noted, that in this case, metadata, describing the image, will be coded instead of the image. For example, in a case with the person face—it is enough to set his attributes massif for synthesis on the playback side. The background, on which the person is shown after restoration, can be coded rather roughly or not to be coded at all, and on playback side to create any neutral option.
Since the descriptive content characteristics have to make sense in the application context, they will be various for different appendices. It means that the same content can be described variously depending on the concrete application. For the visual content part, for example, the description of form, size, texture, color, movement (trajectory), position (for example, “where on a scene the object can be placed”), etc. will be the lowest abstraction level. And for the audio-content: key, tonality, speed, speed variations, situation in a sound space. The highest representation level is semantic information like such description: “It is a scene with the barking brown dog at the left and the blue ball falling on the right with a background sound of the passing cars”. Existence of intermediate abstraction levels is allowed. It is possible to examine MPEG7, for example, in [17] in more detail.
It is interesting, that in the simpler option one-dimensional—sound—signals coding algorithms passed the similar way: from the simple “digitization” to the elimination redundancy, then—to the processing on the basis of the hearing person model aid, and at last, to the separate phonemes (for the speech) recognition to transfer only their codes for the further synthesis on the reception side.
3.2 New Quasi-orthogonal Bases in the Visual Information Compression Problems
The research area, related to the recent discovery of matrix bases [18–24] is actively developing nowadays. Emergence of the minimax structured low-level quasi-orthogonal matrices (Hadamard-Mersenne, Hadamard-Euler, Hadamard-Fermat, Hadamard-Walsh matrices)—so-called “M-matrices”, which algorithmic creating is possible for any orders, open essentially new opportunities for reversible images transformation with various purposes. In this case, using a single device, some actual problems in the images processing field, which, as a rule, separated from each other, can be solved at once. The researches show, that at the same time it is possible to carry out: compression, protection against unauthorized access and protection against deliberate distortion of images [25].
DCT and DWT matrices and appropriate algorithms, implemented for images compression, were intended for digitized pictures of television standards and thus do not take into account the progress made in increasing the size of images up to Full-HD, 4K, 8K, obtained from contemporary video sources. Moreover, some sources can form an image of quite arbitrary size using so called “quality-box” technology [26]. In contrast to the matrix of DCT and DWT, which orders are usually multiples of 8, the quasi-orthogonal matrices exist for different orders. This fact opens the possibility of selecting the optimal matrix for each specific application. In the Table 2 there are values or formulas for calculating such matrices elements, given for orders corresponding to different prime numbers, covering the set of natural numbers. As it is seen from the table, the number of different elements modulo in the pointed matrices is not more than three, which shows its simplicity. The structure of these matrices can be determined iteratively [21] and involves different configurations of the elements in them: cyclic, bicyclic, negacyclic, symmetrical and others. It determines both the effectiveness of computing software implementation and the possibility of building efficient structural solutions. Thus the various matrices number of the certain class, various orders and possibility to implement procedure of rows and columns permutation allow speaking about emergence of rich applied tools in the visual information processing field that can be embedded into well-known compression algorithms.
3.3 The Combined Solution of Compression and Protection Tasks of Visual Information at the New Approaches Application
So, one of the new approach advantages, connected with quasi-orthogonal low-level matrices application for the visual information compression is possibility of simultaneous protection against unauthorized access. Application of the mentioned quasi-orthogonal matrices bases to protect images isn’t necessary to be identified with the cryptographic data security methods in general. Though from the work scheme point of view this approach is identical to information security methods “with the closed key”. The matter is that for images, by definition to excess information type, application of traditional protection ways against unauthorized access often doesn’t bring desirable results. Actually the cryptography can hide the valid numerical pixels value, but thus to make insufficient change to the reproduced picture. The high resource intensity of cryptographic algorithms is not a smaller restriction. Taking into account the need of transfer, for example, of high resolution video images (Full-HD, 4K, 8K) in real time to implement such approach an extremely performed computer will needed. It is necessary to note that for this restriction overcoming, the researches with the positive result, allowing to be limited by cryptographic primitives use—the computing procedures, which are the part of any cryptographic algorithm were conducted [27].
The terms “masking” and “unmasking” for the procedures, which are carried out by means of these bases, are used in the works on opportunities and restrictions research in the new quasi-orthogonal bases application. Thus, digital static images and video images with the small relevance time are the target information for them. Further there are the main definitions, connected with it.
Definition 1
Masking is the process of transformation of digital visual information with a short relevance period to a noise-like form in order to protect it from unauthorized access.
Definition 2
After being masked, the resulting data array is called masked visual information or just a masked image.
Definition 3
Unmasking is the process of reverse transformation of masked visual information by way of application of reversed masking operations in order to restore the original content.
There are matrix masking, with low-level quasi-orthogonal matrices use, and cryptographic, with cryptographic primitives use. The cryptographic masking advantage is higher resistance to attacks in comparison with the matrix one, the disadvantage is higher computing performance demands [28].
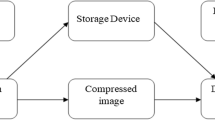
It is important to note that masking with the low-level quasi-orthogonal matrices application isn’t reversible from the point of view of numerical pixels values information integrity. Even without truncation of frequency components bits of the image to compress. It is connected with existence of irrational values as a part of matrix elements, which in the conditions of a limited number of bits for coding inevitably bring inaccuracies at the backward transformation. However for images this fact isn’t a restriction. For an illustration in Fig. 1 there are shown initial (“a”), masked (“b”) and restored (“from”) images, and also the difference reproduced among the initial and restored picture form (“d”).

Masking, unmasking procedures illustration
3.4 The Advantage of New Approaches Concerning Calculating Units Implementation Efficiency
The small levels number (various values of elements of a matrix) allows the matrices authors to implement the computations process very effectively, because the multiplication operation, as the most resource-intensive, can be replaced with the table selection operation (see Fig. 2). As a result, the multiplication is reduced to the fast memory selection operation. The necessary tables number in this case will be equal (k − 1), where k—is the levels number (since one of the elements—is always ‘1’), and each table size—to amount of possible various image pixels values (or color components).

An illustration to the multiplication operations replacement way with the tabular selection for the two-level matrix (with values 1, b) and at image pixel depth, equal to 8
Such computation way is equally simply implemented, both by means of program-controlled systems (on the basis of microprocessors), and programmable logical devices (PLD). That’s why it is difficult to overestimate this advantage in continuously growing dimension of the stored and transferred images the last time.
3.5 The Advantage of the Possibility to Choose the Transformative Matrix Order
Application of the matrices operators intended for the image transfer into the spatial frequency area, with the exclusively fixed size, is a traditional approach for the modern images compression algorithms. Regardless of the image size in pixels and from its contents. This situation remains within decades in spite of the fact, that actually there have already been some technological revolutions during this time that led to multiple increasing of images size.
M-matrices tools existence provides advantage in any reformative matrices order variation (with a single step), when performing compression, based on the image resolution data and on the spatial-frequency characteristics of its separate areas. It is possible to consider critically expediency of the operator 8 dimension application and for lower resolution images, and also for HD resolutions for a primitive illustration of this consideration. And also for the image areas, rich in the small details and large plain areas.
4 Conclusion
The further development of algorithms to reduce channel capacity required for data transmission or amount of free space required for data storage is likely to be governed by the area of application of these algorithms. The current trend of “mobilization” of personal computers that expands the markets of laptops, ultrabooks, communicators and tablet computers, as well as the tendency of the dominance of visual information over the other types of information on the Internet will require the change in the set of approaches to video and image compression. Besides, the traditional methods using the specific aspects of the human visual perception are almost at the end of their development options.
It should be kept in mind that finding more and more efficient ways to reduce the size of data transmitted over the open communication channels is only one of the challenges. It is also necessary to solve the problem of confidentiality with a reasonable increase in the required computing power. In this sense, the emergence of bases of quasi-orthogonal low-level matrices (M-matrices) is very timely. These bases have opened yet inaccessible application possibilities in the field of digital visual information processing, such as:
-
Simultaneous combination of data transformation procedures in order to compress and protect the information from unauthorized access.
-
Reduced performance requirements for computers that perform direct and reverse transformation.
-
Selection of transform matrix dimensions depending on the dimension of pixel matrix of an original image and the data on frequency spatial distribution in its areas.
References
Internet of the Future: We Need a “smart” Visual Search. http://www.cnews.ru/reviews/index.shtml?2012/11/14/509824
Walsh Function. https://en.wikipedia.org/wiki/Walsh_function
WebP, A New Image Format for the WEB. http://blog.chromium.org/2010/09/webp-new-image-format-for-web.html
A New Image Format for the Web. https://developers.google.com/speed/webp/
High Efficiency Video Coding. https://en.wikipedia.org/wiki/High_Efficiency_Video_Coding
Pong, K.K., Kan, T.K.: Optimum loop filter in hybrid coders. IEEE Trans. Circuits Syst. Video Technol. 4(2), 158–167 (1997)
O’Rourke, T., Stevenson, R.L.: Improved image decompression for reduced transform coding artifacts. IEEE Trans. Circuits Syst. Video Technol. 5(6), 490–499 (1995)
Llados-Bernaus, R., Robertson, M.A., Stevenson, R.L.: A stochastic technique for the removal of artifacts in compressed images and video. In: Recovery Techniques for Image and Video Compression and Transmission. Kluwer (1998)
Wajcer, D., Stanhill, D., Zeevi, Y.: Representation and coding of images with nonseparable two-dimensional wavelet. In: Proceedings of the IEEE International Conference on Image Processing. Chicago, USA (1998)
Saenz, M., Salama, P., Shen, K., Delp, E.J.: An evaluation of color embedded wavelet image compression techniques. In: Proceedings of the SPIE/IS&T Conference on Visual Communications and Image Processing (VCIP), 23–29 Jan 1999, pp. 282–293. San Jose, California (1999)
Jayant, N.S., Johnston, J.D., Safranek, R.J.: Signal compression based on models of human perception. Proc. IEEE 81(10), 1385–1422 (1993)
Shen, K., Delp, E.J.: Wavelet based rate scalable video compression. IEEE Trans. Circuits Syst. Video Technol. 9(1), 109–122 (1999)
Podilchuk, C.I., Jayant, N.S., Farvardin, N.: Three-dimensional subband coding of video. IEEE Trans. Image Process. 4(2), 125–139 (1995)
Taubman, D., Zakhor, A.: Multirate 3-D subband coding of video. IEEE Trans. Image Process. 3(5), 572–588 (1994)
Harashima, H., Aizawa, K., Saito, T.: Modelbased analysis synthesis coding of videotelephone images—conception and basic study of intelligent image coding. Trans. IEICE E72(5), 452–458 (1989)
Balonin, N.A., Mironovskii, L.A.: Hadamard matrices of odd order. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2006, no. 3, pp. 46–50 (2006)
Balonin, Yu.N., Sergeev, M.B.: M-Matrix of the 22nd order. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2011, no. 5(54), pp. 87–90 (2011)
Balonin, N.A., Sergeev, M.B., Mironovsky, L.A.: Calculation of Hadamard-Mersenne Matrices. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2012, no. 5, pp. 92–94 (2012)
Balonin, N.A., Sergeev, M.B., Mironovsky, L.A.: Calculation of Hadamard-Fermat matrices. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2012, no. 6, pp. 90–93 (2012)
Balonin, N.A., Sergeev, M.B.: Two ways to construct Hadamard-Euler matrices. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2013, № 1, pp. 7–10 (2013)
Balonin, N.A.: Existence of Mersenne matrices of 11th and 19th orders. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2013, no. 2, pp. 90–91 (2013)
Balonin, N.A., Balonin, YuN, Vostrikov, A.A., Sergeev, M.B.: Computation of Mersenne-Walsh matrices. Vestnik komp’iuternykh i informatsionnykh tekhnologii (VKIT) 2014(11), 51–55 (2014)
Vostrikov, A.A., Chernyshev, S.A.: Implementation of novel quasi-orthogonal matrices for simultaneous images compression and protection. In: Smart Digital Futures 2014. Intelligent Interactive Multimedia Systems and Services (IIMSC-2014), pp. 451–461. IOS Press (2014). doi:10.3233/978-1-61499-405-3-451
Balonin, N.A., Sergeev, M.B.: Initial approximation matrices in search for generalized weighted matrices of global or local maximum determinant. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2015, № 6, pp. 2–9 (2015)
Litvinov, M.Y., Sergeev, A.M.: Problems on formation protected digital images. In: XI International Symposium on Problems of Redundancy in Information and Control Systems: Proceeding, pp. 202–203. Saint-Petersburg (2007)
Vostrikov, A.A., Sergeev, M.B., Litvinov, M.Yu.: Masking of digital visual data: the term and basic definitions. In: Informatsionno-upravliaiushchie sistemy [Information and Control Systems], 2015, no. 5(78), pp. 116–123 (2015)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this paper
Cite this paper
Vostrikov, A., Sergeev, M. (2016). Development Prospects of the Visual Data Compression Technologies and Advantages of New Approaches. In: Pietro, G., Gallo, L., Howlett, R., Jain, L. (eds) Intelligent Interactive Multimedia Systems and Services 2016. Smart Innovation, Systems and Technologies, vol 55. Springer, Cham. https://doi.org/10.1007/978-3-319-39345-2_16
Download citation
DOI: https://doi.org/10.1007/978-3-319-39345-2_16
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-39344-5
Online ISBN: 978-3-319-39345-2
eBook Packages: EngineeringEngineering (R0)