
Abstract
In the previous research the authors developed a family of semantic measures that are adaptable to any semantic graph, being automatically tuned with a set of parameters. The research presented in this paper extends this approach by also tuning the graph. This graph reduction procedure starts with a disconnected graph and incrementally adds edge types, until the quality of the semantic measure cannot be further improved. The validation performed used the three most recent versions of WordNet and, in most cases, this approach improves the quality of the semantic measure.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
This paper is part of an ongoing research [6, 12, 13] aiming at the development of a methodology for creating semantic measures taking as source any given semantic graph. This methodology, called SemArachne, does not require any particular knowledge of the semantic graph and is based on the notion of proximity rather than distance. It considers virtually all paths connecting two terms with weights depending on edge types. SemArachne automatically tunes these weights for a given semantic graph. The validation of this process was performed using WordNet 2.1 [8] with WordSimilarity 353 [9] data set with results better than those in the literature [13].
WordNet 2.1 has a smaller graph when compared with the recent versions of it or even other semantic sources, such as DBpedia or Freebase. Not only the number of nodes and edge types increases as the number of graph arcs expands enabling them to relate semantically a large number of terms, making graphs not only larger but also denser. Compute proximity in these conditions comes with a price. Since SemArachne considers all the paths, the number of paths to process tends to increase.
A rough measure of graph density is the maximum degree of all its nodes. However, consider it can be misleading since there may be a special node where all the edge types are applied. The real challenge is then the graph average node degree. SemArachne computes all paths connecting a pair of terms up tp a given length. The node degree is the branching factor for the paths crossing that node. Hence, a high average node degree reduces the efficiency of the SemArachne measure.
The alternative explored in this paper to reduce graph density is to reduce the number of edge types while keeping all nodes, thus preserving the potential to relate a larger set of terms. The approach is to incrementally build a subgraph of the original semantic graph. This process starts with a full disconnected graph containing all the nodes. At each iteration, a new edge type is added until the semantic measure quality stops to improve. The result of this process is a subgraph where the semantic quality is maximized. The semantic measure used by SemArachne [12] had also some minor adjustments.
The rest of the paper is organized as follows. The next section surveys the state of the art on semantic relatedness. Section 3 summarizes previously published work and Sect. 4 details the approach followed to measure semantic relatedness is larger graphs. The experimental results and their analysis can be found in Sect. 5. Finally, Sect. 6 summarizes what was accomplished so far and identifies opportunities for further research.
2 Related Work
Semantic measures are widely used today to measure the strength of the semantic relationship between terms. This evaluation is based on the analysis of information describing the elements extracted from semantic sources.
There are two different types of semantic sources. The first one are unstructured and semi-structured texts, such as plain text or dictionaries. Texts have evidences of semantic relationships and it is possible to measure those relationships using simple assumptions regarding the distribution of words. This source type is mainly used by distributional approaches.
The second type of semantic sources is more general and includes a large range of computer understandable resources where the knowledge about elements is explicitly structured and modeled. Semantic measures based on this type of source rely on techniques to take advantage of semantic graphs or higher formal knowledge representations. This source type is mainly used by knowledge-based approaches.
Distributional approaches rely on the distributional hypothesis [11] that states that words in a similar context are surrounded by the same words and are likely to be semantically similar. There are several methods following this approach, such as the Spatial/Geometric methods [10], the Set-based methods [5], and the Probabilistic methods [7].
The knowledge-base approaches rely on any form of knowledge representation, namely semantic graphs, since they are structured data from which semantic relationships can be extracted. They consider the properties of the graph and elements are compared by analysing their interconnections and the semantics of those relationships. Several methods have been defined to compare elements in single and multiple knowledge bases, such as Structural methods [14, 15, 22, 24], Feature-based methods [4, 23, 27] and Shannon’s Information Theory methods [16, 19–21].
Knowledge-based approaches have the advantage of controlling which edge types should be considered when comparing pairs of elements in the graph. They are also easier to implement than distributional methods and have a lower complexity. However they require a knowledge representation containing all the elements to compare. On the other hand, using large knowledge sources to compare elements is also an issue due of high computational complexity.
There are also hybrid approaches [2, 3, 18, 24] that mix the knowledge-based and the distributional approaches. They take advantage of both texts and knowledge representations to estimate the semantic measure.
3 Previous Work
This section summarizes previously published work [12, 13] that is the core of SemArachne and relevant for the graph reduction process described in the next section. The first subsection details on the semantic measure and the following subsection on the quality measure. The last subsection details on the fine tune process.
3.1 Semantic Measure
A semantic graph can be defined as \(G=(V,E,T,W)\) where V is the set of nodes, E is the set of edges connecting the graph nodes, T is the set of edge types and W is a mapping of edge types to weight values. Each edge in E is a triplet (u, v, t) where \(u,v \in V\) and \(t \in T\).
The set W defines a mapping \(w:T\mapsto \mathbb {Z}\). The bound of the absolute weight valuesFootnote 1 for all edge types is defined by
To measure the proximity between a pair of terms it is necessary to build a set of distinct paths that connects them by walking through the graph. A path p of size \(n \in \mathbb {N}^+\) is a sequence of unrepeated nodes \(u_0 \ldots u_n \forall _{0 \le i,j \le n} u_i \not = u_j\), linked by typed edges. It must have at least one edge and cannot have loops. A path p is denoted as follows:
The weight of an edge depends on its type. The weight of a path p is the sum of weights of each edge, \(\omega (p) = w(t_1)+w(t_2)+\ldots +w(t_n)\). The set of all paths of size n connecting the pair of concepts is defined as follows and its weight is the sum of all its sub paths.
The semantic measure is based on the previous definition and also considers the path length. \(\varDelta \) is the degree of each node in each path. The proximity function r is defined by the following formula.
Given a graph with a set of nodes V, where \(r: V \times V \mapsto [-1,1]\), the proximity function r takes a pair of terms and returns a “percentage” of proximity between them. The proximity of related terms must be close to 1 and the proximity of unrelated terms must be close to –1.
This definition of proximity depends on weights of transitions. The use of domain knowledge to define them has been proved a naïve approach since an “informed opinion” frequently has no evidence to support it and sometimes is plainly wrong. Also, applying this methodology to a large ontology with several domains can be hard. To be of practical use, the weights of a proximity based semantic relatedness measure must be automatically tuned. To achieve it, it is necessary to estimate the quality of a semantic measure for a given set of parameters.
3.2 Quality Measure
The purpose of the quality measure is to compute the quality of a semantic measure defined by (1) for a particular set of parameters. In order to simplify and optimize the quality measure, it is necessary to factor out weights from the semantic measure definition. Thus its quality may be defined as function of a set of weight assignment.
The first step is to express the semantic measure in terms of weights of edge types. Consider the set of all edge types T with \(\sharp T = m\) and the weight of its elements \(w(t), \forall _t \in T\). The second branch of (1) can be rewritten as follows, where \(c_i(a,b),i \in \{1..m\}\) are the coefficients of each edge type.
Edge type weights are independent of the arguments of r but the coefficients that are factored out depend of these arguments. It is possible to represent both the weights of edges and their coefficients, \((w(t_1), w(t_2),\ldots ,w(t_k)) = {\varvec{w}}\) and \((c_1(a,b),c_2(a,b),\ldots ,c_m(a,b) = {\varvec{c}}(a,b))\) respectively, by defining a standard order on the elements of T. This way the previous definition of r may take as parameter the weight vector, as follows
The method commonly used to estimate the quality of a semantic relatedness algorithm is to compare it with a benchmark data set containing pairs of words and their relatedness. The Spearman’s rank order correlation is widely used to make this comparison.
Consider a benchmark data set with the pairs of words \((a_i,b_i)\) for \(1 \le i \le k\), with a proximity \(x_i\). Given the relatedness function \(r_{{\varvec{w}}}: S \times S \mapsto \mathfrak {R}\) let us define \(y_i = r_{{\varvec{w}}}(a_i,b_i)\). In order to use the Spearman’s rank order coefficient both \(x_i\) and \(y_i\) must be converted to the ranks \(x_i^\prime \) and \(y_i^\prime \).
The Spearman’s rank order coefficient is defined in terms of \(x_i\) and \(y_i\), where \(x_i\) are constants from the benchmark data set. To use this coefficient as a quality measure it must be expressed as a function of \({\varvec{w}}\). Considering that \({\varvec{y}} = (r_{{\varvec{w}}}(a_i,b_i), \ldots , r_{{\varvec{w}}}(a_n,b_n))\) then \({\varvec{y}} = C {\varvec{w}}\), where matrix C is a \(n\times m\) matrix and where each line contains the coefficients for a pair of concepts and each column contains coefficients of a single edge type. Vector \({\varvec{w}}\) is a \(m\times 1\) matrix with the weights assigned to each edge type. The product of these matrices is the relatedness measure of a set of concept pairs.
Considering \(\rho ({\varvec{x}},{\varvec{y}})\) as the Spearman’s rank order of \({\varvec{x}}\) and \({\varvec{y}}\), the quality function \(q : \mathfrak {R}^n \mapsto \mathfrak {R}\) using the benchmark data set \({\varvec{x}}\) can be defined as
The next step in the SemArachne methodology is to determine a \({\varvec{w}}\) that maximizes this quality function.
3.3 Fine Tuning Process
Genetic algorithms are a family of computational models that mimic the process of natural selection in the evolution of species. This type of algorithms uses concepts of variation, differential reproduction and heredity to guide the co-evolution of a set of problem solutions. This algorithm family is frequently used to improve solutions of optimization problems [29].
In the SemArachne the candidate solution – individual – is a weight values vector. Consider a sequence of weights (the genes), \(w(t_1), w(t_2), \ldots , w(t_k)\), taking integer values in a certain range, in a standard order of edge types. Two possible solutions are the vectors \({\varvec{v}} = (v_1, v_2, \ldots , v_k)\) and \({\varvec{t}} = (t_1, t_2, \ldots , tn)\). Using crossover, it is easy to recombine the “genes” of both “parents” resulting in \({\varvec{u}} = (v_1, t_2, \ldots , t_{n-1}, v_k)\).
This is a closer representation of the domain than the typical binary one. It can also be processed more efficiently with large number of weights. In this tuning process the genetic algorithm only have a single kind of mutation: randomly selecting a new value for a given “gene”.
The fitness function plays a decisive role in the selection of the new generation of individuals. In this case, individuals are the vector of weight values \({\varvec{w}}\), hence the fitness function is in fact the quality function previously defined in (2).
4 Graph Reduction Procedure
The previous section explained how to tune the weights of a semantic measure by using a genetic algorithm with an appropriate quality function. This section introduces a procedure for selecting a subgraph of the original semantic source with a reduced density by repeatedly applying that procedure.

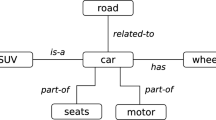
Semantic graph reduction procedure
Figure 1 depicts the overall strategy. It starts with a fully disconnected graph by omitting all the edges. The small graph on the left in Fig. 1 shows the arcs as dotted lines to denote the original connections. When a single property (edge type) is added to this graph a number of paths is created. If the original graph has n property types then one can create n different subgraphs. The quality of these graphs can be measured using the approach described in the last section. The best of these candidates is the selected graph for the first iteration. This process continues until the quality of the candidate graphs cannot be further improved.
More formally, consider a semantic graph \(G=(V,E,T,W)\) where V is the set of nodes, E is the set of edges connecting the graph nodes, T is the set of edge types and W is a mapping of edge types to weight values. The initial graph of this incremental algorithm is \(G_0=(V,\emptyset ,\emptyset ,\emptyset )\). This is a totally disconnected graph just containing the nodes from the original graph, i.e., edges, types and weights are all the empty set.
Each iteration builds a new graph \(G_{k+1}=(V,E_{k+1},T_{k+1},W_{k+1})\) based on \(G_k=(V,E_k,T_k,W_K)\). The new set of types \(T_{k+1}\) has all the types in \(T_{k}\). In fact, several candidate \(G^i_k\) can be considered, depending on the types in \(T - T_k\) that are added to \(T_{k+1}\). The arcs of \(E^i_{k+1}\) are those in E whose type is in \(T^i_{k+1}\). The general idea is to select the \(G^i_{k+1}\) that produces an higher increment on semantic measure quality. This algorithm stops when no candidate is able to improve it.
In general, computing the semantic measure quality of \(G^i_{k+1}\) is a time consuming task. However, there are some ways to make it more efficient. As shown in Fig. 1, if \(G^i_{k+1}\) is not a connected graph then the quality measure cannot be computed. This means that for the first iteration many \(G^1_{k+1}\) can be trivially discarded. Moreover, if \(E^i_{k+1}\) = \(E^i_k\) then the semantic quality measure is the same. This insight can be used to speedup the iterative process. The paths connecting pairs of concepts using arcs in \(E_{k+1}\) are basically the same that used \(E_k\). The new paths must appear on the nodes of previous paths and can only have arcs of types in \(T_{k+1}\). This insight can be used to compute the quality of \(G^i_{k+1}\) incrementally based on the computation of \(G^i_{k}\).
The generation of the sets \(T^i_{k+1}\) is a potential issue. Ideally \(T^i_{k+1}\) would have just one element more than \(T^i_{k}\). However this may not always be possibleFootnote 2. Consider \(T^i_1\), the candidate sets of types for the first iteration. In most cases they will produce a disconnected graph, hence with a null semantic measure quality. They will only produce a connected graph if the selected type creates a taxonomy. In many cases this involves 2 types of arcs: one linking an instance to a class, another linking a class to its super-class. To deal with this issue the incremental algorithm attempts first to generate \(T^i_{k+1}\) such that \(\sharp T^i_{k+1} = \sharp T^i_{k}+1\), where \(\sharp \) stands for set cardinality. In none of these improve the semantic measure quality then it attempts to generate \(T^i_{k+1}\) such that \(\sharp T^i_{k+1} = \sharp T^i_{k}+2\), and so forth.
5 Validation
The validation of SemArachne was performed using the semantic graphs of different versions of WordNet along with three different data sets.
WordNetFootnote 3 [8] is a widely used lexical knowledge base of English words. It groups nouns, verbs, adjectives and adverbs into synsets – a set of cognitive synonyms – that expresses distinct concepts. These synsets are linked by conceptual and lexical relationships. The validation process used three different data sets: WordSimilarity-353Footnote 4 [9] Rubenstein & Goodenough [25] (RG65) and Miller & Charles [17] (MC30).
Table 1 compares the performance of SemArachne against the state of the art for methods using the same knowledge-based approach. For WordNet 2.1, SemArachne achieves a better result than those in the literature when using WordSim-353 data set. Using WordNet 3.1 as semantic graph, SemArachne produces also a better semantic quality than those in the literature. Although results are not the best in the WordNet 3.0, despite the data set used, they have the same order of magnitude.
The quality of the semantic measure produced with graph reduction was validated against several approaches in the literature. An advantage of this methodology is the ability of measure the semantic relatedness regardless the semantic graph used and produce comparable results for each semantic graph and data set. It is also scalable, since it handles gradually larger graphs.
6 Conclusion
As semantic graphs evolve they become larger. Since larger graphs relate more terms this improves their potential as semantic sources for relatedness measures. However, these larger graphs are also a challenge, in particular to semantic measures that consider virtually all paths connecting two nodes, as is the case of SemArachne.
The major contribution of this paper is an incremental approach to select a subgraph with a reduced number of edge types (arcs) but with the same number of entities (nodes). This approach starts with a totally disconnected graph, at each iteration adds an arc type that increases the quality of the semantic measure, and stops when no improvement is possible.
These contributions were validated with different versions of WordNet, a medium size graph typically used as semantic source for relatedness measures. Although this is not the kind of large semantic graphs to which this approach is targeted, it is convenient for initial tests due to its relatively small size.
In the WordNet graph the reduction of properties is not so expressive, since the total number of properties is comparatively small. The obtained subgraphs do not always improve the quality of the SemArachne measure, but produce a result that is similar, and in most cases better, than best method described in the literature for that particular graph.
The immediate objective of the SemArachne project is to extend the validation presented in this paper to other data sets and, most of all, to other graphs. Massive graphs with very high density, such as Freebase, are bound to create new and interesting challenges. Another important consequence of this graph reduction procedure is that it decouples the original graph from the actual semantic source. Thus SemArachne can be extended to process multiple semantic graphs (with shared labels) and create an unified semantic measure combining their semantic power.
Notes
- 1.
This semantic measure accepts negative weights for some types of edges.
- 2.
However, so far this situation has not yet occurred in validation.
- 3.
- 4.
References
Agirre, E., Alfonseca, E., Hall, K., Kravalova, J., Paşca, M., Soroa, A.: A study on similarity and relatedness using distributional and wordnet-based approaches. In: Proceedings of Human Language Technologies: The 2009 Annual Conference of the North American Chapter of the Association for Computational Linguistics, pp. 19–27. Association for Computational Linguistics (2009)
Banerjee, S., Pedersen, T.: An adapted lesk algorithm for word sense disambiguation using wordnet. In: Gelbukh, A. (ed.) CICLing 2002. LNCS, vol. 2276, pp. 136–145. Springer, Heidelberg (2002)
Banerjee, S., Pedersen, T.: Extended gloss overlaps as a measure of semantic relatedness. IJCAI 3, 805–810 (2003)
Bodenreider, O., Aubry, M., Burgun, A.: Non-lexical approaches to identifying associative relations in the gene ontology. In: Pacific Symposium on Biocomputing, p. 91. NIH Public Access (2005)
Bollegala, D., Matsuo, Y., Ishizuka, M.: Measuring semantic similarity between words using web search engines. In: Proceedings of the 16th International Conference on World Wide Web 2007, pp. 757–766 (2007)
Costa, T., Leal, J.P.: Challenges in computing semantic relatedness for large semantic graphs. In: Proceedings of the 18th International Database Engineering and Applications Symposium, pp. 376–377. ACM (2014)
Dagan, I., Lee, L., Pereira, F.C.: Similarity-based models of word cooccurrence probabilities. Mach. Learn. 34(1–3), 43–69 (1999)
Fellbaum, C.: WordNet. Wiley Online Library, New York (1999)
Gabrilovich, E.: The WordSimilarity-353 test collection. http://www.cs.technion.ac.il/gabr/resources/data/wordsim353/
Ganesan, P., Garcia-Molina, H., Widom, J.: Exploiting hierarchical domain structure to compute similarity. ACM Trans. Inf. Syst. (TOIS) 21(1), 64–93 (2003)
Harris, Z.S.: Distributional structure. In: Hiż, H. (ed.) Papers on syntax, pp. 3–22. Springer, The Netherlands (1981)
Leal, J.P.: Using proximity to compute semantic relatedness in RDF graphs. Comput. Sci. Inf. Syst. 10(4), 1727–1746 (2013)
Leal, J.P., Costa, T.: Multiscale parameter tuning of a semantic relatedness algorithm. In: 3rd Symposium on Languages, Applications and Technologies, SLATE, pp. 201–213 (2014)
Li, Y., Bandar, Z.A., McLean, D.: An approach for measuring semantic similarity between words using multiple information sources. IEEE Trans. Knowl. Data Eng. 15(4), 871–882 (2003)
Li, Y., McLean, D., Bandar, Z.A., O’shea, J.D., Crockett, K.: Sentence similarity based on semantic nets and corpus statistics. IEEE Trans. Knowl. Data Eng. 18(8), 1138–1150 (2006)
Lin, D.: An information-theoretic definition of similarity. ICML 98, 296–304 (1998)
Miller, G.A., Charles, W.G.: Contextual correlates of semantic similarity. Lang. Cogn. Process. 6(1), 1–28 (1991)
Patwardhan, S., Banerjee, S., Pedersen, T.: Using measures of semantic relatedness for word sense disambiguation. In: Gelbukh, A. (ed.) CICLing 2003. LNCS, vol. 2588, pp. 241–257. Springer, Heidelberg (2003)
Pirró, G.: A semantic similarity metric combining features and intrinsic information content. Data Knowl. Eng. 68(11), 1289–1308 (2009)
Pirró, G., Euzenat, J.: A feature and information theoretic framework for semantic similarity and relatedness. In: Patel-Schneider, P.F., et al. (eds.) ISWC 2010, Part I. LNCS, vol. 6496, pp. 615–630. Springer, Heidelberg (2010)
Pirró, G., Seco, N.: Design, implementation and evaluation of a new semantic similarity metric combining features and intrinsic information content. In: Meersman, R., Tari, Z. (eds.) OTM 2008, Part II. LNCS, vol. 5332, pp. 1271–1288. Springer, Heidelberg (2008)
Rada, R., Mili, H., Bicknell, E., Blettner, M.: Development and application of a metric on semantic nets. IEEE Trans. Syst. Man Cybern. 19(1), 17–30 (1989)
Ranwez, S., Ranwez, V., Villerd, J., Crampes, M.: Ontological distance measures for information visualisation on conceptual maps. In: Meersman, R., Tari, Z., Herrero, P. (eds.) OTM 2006 Workshops. LNCS, vol. 4278, pp. 1050–1061. Springer, Heidelberg (2006)
Resnik, P.: Using information content to evaluate semantic similarity in a taxonomy. In: IJCAI, pp. 448–453 (1995)
Rubenstein, H., Goodenough, J.B.: Contextual correlates of synonymy. Commun. ACM 8(10), 627–633 (1965)
Siblini, R., Kosseim, L.: Using a weighted semantic network for lexical semantic relatedness. In: RANLP, pp. 610–618 (2013)
Stojanovic, N., Maedche, A., Staab, S., Studer, R., Sure, Y.: SEAL: a framework for developing SEmantic portALs. In: Proceedings of the 1st International Conference on Knowledge Capture, pp. 155–162. ACM (2001)
Strube, M., Ponzetto, S.P.: Wikirelate! Computing semantic relatedness using wikipedia. AAAI 6, 1419–1424 (2006)
Whitley, D.: A genetic algorithm tutorial. Stat. Comput. 4(2), 65–85 (1994)
Acknowledgments
Project “NORTE-07-0124-FEDER-000059” is financed by the North Portugal Regional Operational Programme (ON.2 - O Novo Norte), under the National Strategic Reference Framework (NSRF), through the European Regional Development Fund (ERDF), and by national funds, through the Portuguese funding agency, Fundação para a Ciência e a Tecnologia (FCT).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Costa, T., Leal, J.P. (2015). Reducing Large Semantic Graphs to Improve Semantic Relatedness. In: Sierra-Rodríguez, JL., Leal, JP., Simões, A. (eds) Languages, Applications and Technologies. SLATE 2015. Communications in Computer and Information Science, vol 563. Springer, Cham. https://doi.org/10.1007/978-3-319-27653-3_23
Download citation
DOI: https://doi.org/10.1007/978-3-319-27653-3_23
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-27652-6
Online ISBN: 978-3-319-27653-3
eBook Packages: Computer ScienceComputer Science (R0)