
Abstract
Importance-performance analysis (IPA) is a popular prioritization tool used to formulate effective and efficient quality improvement strategies for products and services. Since its introduction in 1977, IPA has undergone numerous enhancements and extensions, mostly with regard to the operationalization of attribute-importance. Recently, studies have promoted neural network -based IPA approaches to determine attribute-importance more reliably compared to traditional approaches. This chapter describes the application of back-propagation neural networks (BPNN) in an extended IPA framework with the goal of discovering key areas of quality improvements. The value of the extended BPNN-based IPA is demonstrated using an empirical case example of airport service quality .
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
15.1 Introduction
Originally introduced by Martilla and James in 1977 (Martilla and James 1977), the importance-performance analysis (IPA) has become one of the most popular analytical tools for prioritizing improvements of service attributes. According to the SCOPUS citation database, in July 2013 there were more than 300 papers bearing the name of the technique in the title, abstract or keywords, whereas the term appeared anywhere in the text in more than 1000 papers.
IPA usually departs from a formative multi-attribute model of customer satisfaction (CS). Put differently, the focal service is decomposed into key functional and/or psychological attributes that significantly influence the customer experience with the service. Such a model is then used to develop a questionnaire for gathering the necessary IPA -input data. Following the original methodology, one set of measurement items is used to measure perceived attribute-importance, and another set to measure perceived attribute-performance. Arithmetic means of importance and performance ratings are then plotted into a two-dimensional matrix. Grand means of importance and performance ratings (or, alternatively, scale means), are further taken to divide the matrix into four quadrants. Accordingly, four distinct managerial recommendations can then be derived depending on the location of the attributes within the matrix (Fig. 15.1).

Importance-performance matrix
Although the prioritization logic of the original IPA is intuitive and straightforward (priority rises with increasing importance and decreasing performance of attributes), researchers have identified several shortcomings of the technique during the past three decades. Whereas some authors were primarily concerned with technical issues (e.g. the most appropriate way to divide the matrix into different areas), a significantly larger number of scholars have raised conceptual issues that mainly regard the importance-dimension in IPA. In order to enhance the reliability (and validity) of the original methodology, researchers have thus proposed numerous modifications with regard to both the conceptualization and the operationalization of attribute-importance in IPA . Most recently, IPA variants have been introduced that utilize the power of the multilayer perceptron (MLP), a popular type of back-propagation neural networks (BPNN), for assessing attribute-importance. As several studies have shown, the integration of BPNNs into the IPA framework can help to significantly increase the reliability of managerial implications (Deng et al. 2008; Hu et al. 2009; Mikulić and Prebežac 2012; Mikulić et al. 2012).
In this chapter we present an extended BPNN-based IPA analytical framework which solves several significant shortcomings of traditional IPA. The value and application of the extended BPNN-IPA is demonstrated in an empirical case example of airport service quality . Before proceeding to the case study in Sect. 15.3, the following section reviews and summarizes recent advances regarding the IPA , particularly with regard to the integration of BPNNs into the analysis framework.
15.2 Literature Review
15.2.1 IPA and the Conceptualization of Attribute-Importance
The conceptualization and, subsequent, operationalization of attribute-importance is a controversial issue in IPA studies. The original methodology put forward the use of stated importance measures which assess the importance of attributes as perceived by the customer (Martilla and James 1977). This type of importance can be evaluated through rating-, ranking- or constant-sum scales. Contemporary IPA studies, however, employ increasingly derived measures of importance which are obtained by relating attribute-level performance to a measure of global service performance, like overall satisfaction or overall service quality (Grønholdt and Martensen 2005).
While several scholars have argued in favor of one of these two types of importance measures, recent IPA studies have revived the early ideas of Myers and Alpert (Myers and Alpert 1977) who stressed that these two types of measures should not be regarded as competing or conflicting measures. Rather they should be regarded as complementary measures because they assess different dimensions of the importance-construct (Van Ittersum et al. 2007). While stated measures assess an attributes general importance (referred to as relevance), derived measures assess an attributes actual influence in a particular study context (referred to as determinance). Most important, it is not reasonable to assume strong correlation between these two dimensions of importance. Aspects of a service which are perceived very important by the customer do not necessarily have to be those ones that will truly have the strongest influence on his satisfaction in a particular service transaction. If an attribute which is perceived very important by the customer performs according to the customer’s expectations, then its actual influence on the customer’s overall satisfaction might be smaller than the effect of an attribute which is perceived less important. This might occur in cases when the less important attribute performs below or above customer-expected levels, thus causing strong negative or positive customer reactions, respectively.
Following this line of thought, Mikulić and Prebežac (2011, 2012) have proposed a rather simple extension of IPA by integrating both stated and derived measures of attribute-importance into a relevance-determinance matrix (RDM; Fig. 15.2). Since a three-dimensional representation of results might, however, be confusing (i.e. two importance dimensions and one performance dimension), the authors suggest marking attributes in the RDM that perform below and above average with a minus (−) and a plus (+), respectively.

Relevance-determinance matrix
The following recommendations apply to the four attribute categories (Mikulić and Prebežac 2012):
-
Higher-impact core attributes (quadrant 1): These attributes are perceived very important by customers and they have a strong influence on overall satisfaction. The management should primarily focus on this category to strengthen the market position. Attributes from this attribute category that perform relatively low should be assigned highest priority in improvement strategies.
-
Lower-impact core attributes (quadrant 2): These attributes are perceived very important, but they only have a relatively weak influence on overall satisfaction. Market-typical levels of performance should be ensured for these attributes. These attributes can turn into dissatisfiers with a strong influence on overall satisfaction when performance drops below a tolerated threshold.
-
Higher-impact secondary attributes (quadrant 4): These attributes are perceived less important, but they have a strong influence on overall satisfaction. Attributes forming this category are likely part of the augmented product/service and can be used to differentiate from the competition. The importance of these attributes would be completely underestimated if using stated importance measures, only.
-
Lower-importance attributes/Lower-impact secondary attributes (quadrant 3): These attributes should be assigned lower general priority in improvement strategies than the previous three categories.
15.2.2 IPA and the Problem of Multicollinearity
While stated importance is typically assessed through direct rating scales, derived importance is usually assessed by means of multiple regression or correlation analysis. A significant technical problem here, which limits the applicability of popular derived measures of attribute-importance, is strong correlation among the attributes which are used to predict overall CS. In particular, the problem is that a regression on correlated attributes violates a basic assumption of the technique, why it may produce invalid estimates of relative attribute-determinance. Typical consequences are (i) regression coefficients with reversed signs, although the zero-order correlation with the dependent variable is positive, (ii) significantly different weights for equally determinant variables, and (iii) exaggerated/suppressed regression coefficients (Johnson 2000). Although many research areas struggle with correlated variables, the problem can be characterized as a major ‘plague’ in CS research, as this area of research does not rely on metric measures of objective phenomena, but rather on limited scale-range measures of perceptions that frequently tend to be strongly correlated (Weiner and Tang 2005). Moreover, CS studies tend to analyze relatively large numbers of variables, which generally increases the risk of multicollinearity . Since the reliability and validity of derived importance measures directly affects the reliability and validity of attribute-prioritizations, ways need to be found to deal with this problem in IPA . Basically, there are three general options.
-
1.
Bivariate approaches like zero-order correlation or bivariate regressions may be applied to circumvent the multicollinearity problem. However, these approaches are less than optimal because they fail to consider the influence of all other variables in estimations of relative attribute-determinance. Accordingly, these measures are generally not recommended for use with multi-attribute CS models.
-
2.
The risk of high inter-correlations may be reduced by specifying attribute-models in which they are less likely to occur. Since the likelihood of occurrence is typically positively correlated with the number of explanatory variables in a regression model, researchers may, on the one hand, consider the use of hierarchical attribute-models to keep the number of predictors in a model at a reasonable level, but thereby preserving desired levels of detail. On the other hand, if the data are not based on hierarchical models, attributes may be factor analyzed in an exploratory manner to potentially obtain a decreased number of uncorrelated factors that enter the analysis. Similarly, but simpler, correlational matrices can be computed to identify highly correlated attributes that should be reconsidered for inclusion into the final model.
-
3.
Researchers may use approaches that are capable of effectively dealing with correlated predictors. Several regression-based approaches have been proposed, involving measures of average variable contributions to \( R^{2} \) across all possible sub-models (Kruskal 1987; Budescu 1993), variance-decomposition with uncorrelated subsets of predictors (Genizi 1993), or heuristics based on predictor orthogonalization (Johnson 2000). However, in case of larger numbers of attributes, a severe limitation of these approaches is that they are either complicated to implement, or computationally very demanding. For example, ‘all sub-set regression’ procedures require \( 2^{p} - 1 \) models for estimating the importances of \( p \) attributes—i.e.: 31 models for p = 5, 1023 models for p = 10, and even 32,767 models for p = 15. Since none of available statistical packages have built-in features for performing such analyses, these approaches are not very appealing to CS researchers.
15.2.3 IPA and the Application of Artificial Neural Networks
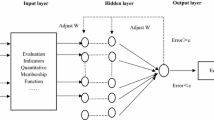
A valuable alternative to traditional statistical approaches that does not assume uncorrelated predictors is the multilayer perceptron (MLP), a popular class of back-propagation neural networks (BPNN) that has been applied in several IPA studies (Deng et al. 2008; Hu et al. 2009; Mikulić and Prebežac 2012; Mikulić et al. 2012). BPNNs are artificial neural networks with feed-forward architecture that use a supervised learning method. Back-propagation is the most widely used neural network architecture for classification and prediction. The idea of the BPNN goes back to 1974 with Werbos discussing the concept, while the algorithm was clearly defined in 1985 by Rumelhart and his colleagues who introduced the Propagation Learning Rule (Rumelhart et al. 1986). Nowadays, BPNNs are widely applied in numerous research areas, such as pattern recognition, medical diagnosis, sales forecasting or stock market returns, among others (Zong et al. 2014; Subbaiah et al. 2014; Kuo et al. 2014; Huo et al. 2014). A graphical presentation of a typical MLP is provided in Fig. 15.3.

Multilayer perceptron
An MLP consists of one input-layer , one or more hidden-layers , and one output-layer . Each layer comprises a number of neurons that process the data via nonlinear activation functions (e.g. sigmoid, hyperbolic-tangent). To draw an analogy to regression, the input-layer neurons can be referred to as predictors and the output-layer neurons as the dependent variable (typically this is one in regression-kind problems).
An important difference compared to regression is, however, that predictors are not directly related to the dependent variable, but via neurons in one or more hidden layers. These in turn determine the mapping relations which are stored as weights of connecting paths between the neurons. The nonlinear activation functions further enable the MLP to straightforwardly deal with indefinable nonlinearity, giving the MLP a significant technical advantage over regular linear regression (DeTienne et al. 2003). The most important difference towards regression is, however, that the MLP is a dynamic network model that uses a back-propagation algorithm to train and optimize the network. Errors between predicted and actual output values are iteratively fed back to the network in order to minimize this discrepancy according to some predefined rule or target (Haykin 1999). Put differently, the MLP learns from the data and dynamically updates the network weights. Sum-of-squares (SOS) error functions are typically used in combination with learning algorithms like the scaled conjugate gradient algorithm (Moller 1993), or the Broyden-Fletcher-Goldfarb-Shanno (BFGS) algorithm (Broyden et al. 1973).
Although MLPs are powerful prediction tools that can explain very large amounts of variance in dependent variables, MLPs do, however, not provide straightforward indicators of predictor determinance (i.e. derived predictor importance). Because of this, ANNs have been frequently termed as “black box” methodologies. Such indicators can, however, be obtained by using one of the following two approaches.
On the one hand, predictor determinance can be derived through connection-weight procedures—i.e. all weights connecting an input-layer neuron over hidden-layers to the output layer neuron are used to calculate a neuron’s determinance (i.e. its influence on the dependent variable). The two most widespread, though conflicting, procedures are the algorithms proposed by Garson (Garson 1991) and Olden and Jackson (Olden and Jackson 2002). An empirical comparison using Monte-Carlo simulated data has, however, come to the conclusion that the latter approach performs significantly better, and thus it should be preferred (Olden and Jackson 2002).
On the other hand, predictor determinance can be derived through stepwise procedures. Here it is analyzed how the discrepancy between predicted and actual output values behaves when predictors are iteratively dropped from, or included into the network (Sung 1998). Analogously to analyzing changes in \( R^{2} \) when dropping/including predictors in a regression model, a relatively larger increase of the network/model error, attributed to the omission of a particular predictor, can be interpreted as relatively larger predictor determinance. Conversely, a decrease of the network error would imply that the respective predictor should rather be omitted from the network, as it, in fact, decreases the overall model quality. Moreover, because the assumption of uncorrelated predictors is not made in MLPs , a noteworthy advantage over regression is that there is no need to average changes in model error over all predictor-orderings to ensure the reliability of determinance estimates. Since all-subset regressions become exponentially time-consuming with larger numbers of predictors (i.e. \( 2^{p - 1} \) models are required to estimate the determinance of \( p \) attributes), this is a significant practical advantage of MLPs over similar regression-based approaches like e.g. dominance analysis, or Kruskal’s averaging over orderings procedure.
15.3 An Application of the Extended BPNN-IPA
An overview of the extended BPNN-IPA methodology is given in Fig. 15.4.

Methodology of the extended BPNN-IPA
The data used in this example were collected as part of a periodical survey on airline passenger satisfaction with services provided at a European international airport. The data were collected by means of a structured questionnaire in face-to-face interviews in the international departure area of the airport. Five-point direct rating scales were used to assess both the importance (1 = less important; 5 = very important) and performance (1 = very poor; 5 = excellent) of a series of airport attributes, as well as the level of overall satisfaction with the airport (1 = disappointed; 5 = delighted). Overall, 2025 fully completed questionnaires entered the subsequent data analysis.
In order to guide management efforts for improving the overall airport experience we will conduct an extended BPNN-based IPA . Following the approach proposed by Mikulić and Prebežac (2011, 2012), the traditional IPA framework is extended by using measures of both attribute-relevance and determinance. This facilitates a relative categorization of attributes according to their general importance, as perceived by passengers (i.e. attribute-relevance, AR), and their actual influence on overall passenger satisfaction with the airport services (i.e. attribute-determinance, AD).
To prepare the necessary input-data arithmetic means of attribute-performance ratings (AP) are first calculated:
where \( p_{i,j} \) is the performance rating for attribute \( i \), \( i \in I \) by respondent \( j \), \( j = 1, \ldots , n \), \( n \) the number of respondents, and \( I \) the set of analyzed attributes \( i \).
Analogously, arithmetic means of importance ratings are calculated to obtain indicators of attribute-relevance (AR). To obtain indicators of AD an MLP -based sensitivity analysis is conducted. This analysis involves the following steps:
-
4.
Specification of MLP architecture: AP ratings are specified as input-layer neurons and ratings of overall satisfaction with the airport as single output-layer neuron in a one-hidden layer MLP. The overall sample is partitioned into training, testing, and holdout samples (60, 20, and 20 % of the samples, respectively). The network training continues as long as the network error is decreasing in both the main dataset (i.e. training samples) and the testing samples. When the error between predicted and true output values starts increasing in the testing sample, training is stopped to prevent over-fitting. This stopping rule is necessary because over-fitted networks usually perform very well or perfect during training, but they also typically perform significantly weaker or badly on unseen data. The holdout samples are further used to cross-validate the performance of the MLP after the training is finished. The MLP can be considered reliable only if the network performs consistently well across all three independent samples.
-
5.
Network training: The network is trained using a sum-of-squares error function and the BFGS learning algorithm. Network performance is assessed using the mean absolute percentage error \( (MAPE) \) and root mean squared error \( (RMSE) \). RMSE can be used to derive network goodness-of-fit \( (R^{2} ) \):
where \( y_{i} \) is the predicted output value for sample \( i \), \( a_{i} \) the actual output value for sample \( i \), \( n \)the number of samples, and \( \upsigma^{2} \) the variance of the actual output.
The following trial-and-error procedure is used to determine the best network configuration. In a first step several networks with varying activation functions and numbers of neurons in the hidden-layer are estimated. The correlations between true and predicted values are then checked to identify the best-performing networks. Here it is important that the network configurations provide consistent performance across the training, testing and holdout samples. After identifying the better-performing activation functions, these are then used to estimate another set of network configurations. The correlations between predicted and true output values are then checked again to identify the best performing activation functions and number of hidden-layer neurons. Using e.g. the automated neural network feature in newer versions of Statsoft Statistica (version 8.0 or higher) this whole trial-and-error procedure can easily be conducted, thereby using large numbers of network configurations to be estimated at a time (e.g. 5000 or higher).
-
6.
Estimation of attribute-determinance: To obtain indicators of AD a global sensitivity analysis of the network error is conducted. While in a local sensitivity analysis the focus is on how sensitive the output is to a given domain of a predictor, global sensitivity focuses on how the output behaves when completely eliminating a predictor from the network. This is done by iteratively fixing the value of each particular predictor to its arithmetic mean before re-estimating the same network (with a particular predictor omitted). Accordingly, a larger increase of the network error can then be regarded as an indicator of larger influence of an attribute in explaining variations in the output (i.e. determinance). This type of indicator is very similar to changes in R2 whichare attributable to the omission of predictors from a regression model.
The results of the network performance assessment for our case example are provided in Table 15.1. The network we choose to estimate indicators of AD has 20 hidden-layer. neurons, exponential activation functions in the hidden layer, and identity functions in the output layer (in bold). For comparison, the coefficient of determination of the respective OLS regression model is \( R^{2} = 0.59887 \).
Min-max normalization is applied to the weights obtained from the sensitivity analysis for easier comparison across attributes (expressed as percentages). Final scores of AD, AR and AP are presented in Table 15.2.
Scores of AD and AR are then used to construct the two-dimensional RDM. The thresholds that divide the matrix into four quadrants are set at the values of the grand means of AD and AR (Fig. 15.5). The basic prioritization logic is to search for attributes that perform relatively lower (e.g. below the grand mean) starting from the first quadrant (higher-impact core attributes; highest general priority), over the fourth quadrant (higher-impact secondary attributes), the second quadrant (lower impact core attributes), to the third quadrant (lower importance attributes; lowest general priority).

BPNN-based importance-performance analysis importance-performance analysis
The BPNN-IPA reveals that most attention should be paid to the quality of (13) the flight network and the (1) traffic connection between the airport and the city. These are the only two attributes located in the first quadrant that perform below average (AP13 = 3.86; AP1 = 3.91). Improving the quality of these two attributes would be likely to significantly enhance overall passenger satisfaction with the airport.
If we move to the fourth quadrant, we see that the only higher-impact secondary attribute performs below average, i.e. (10) availability of luggage carts (AP10 = 3.94). Accordingly, this attribute should be considered next for improvement. It is noteworthy that the importance of this attribute would have been significantly underestimated if only stated importance measures had been used.
A look at the attributes in the second quadrant (lower-impact core attributes) reveals that no immediate action is needed here, because all attributes perform above average.
Finally, the focus is shifted to the attributes located in the third quadrant which have relatively lower general priority than attributes in the other three quadrants. Although these attributes have relatively lower relevance and determinance, the airport management should consider their improvement after having improved the previously mentioned attributes, because all the four attributes perform below average—i.e. (2) parking (AP2 = 3.70), (6) cafes and restaurants (AP6 = 3.66), (9) availability of Internet access (AP9 = 3.59), and (7) shopping possibilities (AP7 = 3.73).
15.4 Conclusion
This chapter described the application of back-propagation neural networks (BPNN) in an extended importance-performance analysis (IPA) framework with the goal of discovering and prioritizing key areas of quality improvements. The application of the extended BPNN-based IPA was demonstrated using an empirical case study of passenger satisfaction with services provided by an international airport. The extended BPNN-based IPA identified the most important key-drivers of passenger satisfaction and provided detailed improvement priorities of the various airport services.
From a methodological point of view, the applied framework solves two important shortcomings of traditional key-driver analyses, in particular of prevailing approaches to IPA :
First, by combining two different dimensions of attribute-importance into IPA (i.e. attribute-relevance and determinance), the general reliability of the analytical framework is significantly increased. With only few exceptions, IPA studies typically use a one-dimensional operationalization of importance, i.e. either they use relevance or determinance. Since these two measures do not necessarily have to converge, the reliability and validity of managerial implications from traditional IPA are at least questionable. That a one-dimensional operationalization of importance might mislead managers has also been demonstrated in the example used in this chapter. The importance of one attribute (availability of luggage carts) would have been significantly underestimated if only measures of relevance had been used. Here, relevance of the attribute was below average, while its determinance was significantly above average.
Second, by using the multilayer perceptron (MLP) , a popular class of BPNNs for deriving attribute-determinance in IPA, the proposed framework provides more reliable determinance estimates compared to traditional regression-based analyses. This is because the MLP can effectively deal with correlated predictors, and it applies nonlinear rather than linear activation functions in modeling the data. The MLP can thus straightforwardly account for possible nonlinearities in the relationship between the performance of various service/product attributes and the level of global satisfaction. Application of the MLP is particularly valuable in customer satisfaction studies, as demonstrated in this chapter, because studies in this area typically analyze larger numbers of product or service attributes. Since there is usually a significant amount of correlation among these attributes, traditional regression-based analyses tend to provide distorted and, subsequently, unreliable determinance scores. With application of the MLP, reliability of determinance-scores is significantly improved. Moreover, since multicollinearity problems tend to increase with larger numbers of analyzed product/service attributes-predictors, application of the MLPdoes not force researchers to make large trade-offs between the desired level of detail of the attribute-model under study and the reliability of results.
For future IPA studies it is generally recommended to apply both relevance and determinance scores to determine an attribute’s importance. With regard to the application of ANNs in assessing an attribute’s influence on a dependent variable (like overall satisfaction), future IPA studies may consider the application of genetic algorithm for network optimization. Also, it would be useful to further investigate and compare different was of obtaining determinance weights from ANNs (e.g. connection-weights procedures vs. stepwise procedures), in order to provide some best practice guidelines for both practitioners and researchers in this area.
Key terms
-
Back-propagation neural network : A feed-forward artificial neural network that uses supervised learning to map a set of input data onto a set of output data. The error (i.e. discrepancies between true and computed data) is back-propagated to the network until it is minimized according to some predefined rule.
-
Importance-performance analysis : A widely applied analytical tool that is used to prioritize product/service attributes for improvement. The rationale is to compare the importance of product/service attributes with the attributes’ performance using a two-dimensional matrix. The analysis is based on data from typical customer satisfaction surveys.
-
Relevance: A dimension of the importance construct that could be referred to as general importance. The literature also uses the term stated importance to denote relevance. The relevance of a product/service attribute such refers to the attribute’s importance without a particular performance context.
-
Determinance: A dimension of the importance construct that could be referred to as actual importance or impact. The literature also uses the term derived importance to denote determinance. The determinance of a product/service attribute such refers to the attribute’s actual influence on e.g. the customer’s satisfaction given a particular context of attribute performances.
-
Relevance-determinance asymmetry: The case when the relevance of a product/service attribute does not correspond with the attribute’s determinance. E.g. the relevance of safety as an attribute of an airline flight certainly is very high. The attribute’s actual importance or impact on a passenger’s flight satisfaction (i.e. determinance), however, certainly depends on the attribute’s level of performance. Such, it should not have a significant impact in case everything went fine on a flight.
References
Broyden, C.G., Dennis, J.E., More, J.J.: On the local and superlinear convergence of quasi-newton methods. IMA J. Appl. Math. 12, 223–246 (1973)
Budescu, D.V.: Dominance analysis: a new approach to the problem of relative importance of predictors in multiple regression. Psychol. Bull. 114, 542–551 (1993)
Deng, W.J., Chen, W.C., Pei, W.: Back-propagation neural network based importance-performance analysis for determining critical service attributes. Expert Syst. Appl. 34, 1115–1125 (2008)
DeTienne, K.B., DeTienne, D.H., Joshi, S.A.: Neural networks as statistical tools for business researchers. Organ. Res. Methods 6, 236–265 (2003)
Garson, G.D.: Interpreting neural-network connection weights. AI Expert 6, 47–51 (1991)
Genizi, A.: Decomposition of R2 in multiple regression with correlated regressors. Stat. Sinica 3, 407–420 (1993)
Grønholdt, L., Martensen, A.: Analysing customer satisfaction data: a comparison of regression and artificial neural networks. Int. J. Market Res. 47, 121–130 (2005)
Haykin, S.: Neural networks: a comprehensive foundation. Prentice-Hall, Upper Saddle River (1999)
Hu, H.Y., Lee, Y.C., Yen, T.M., Tsai, C.H.: Using BPNN and DEMATEL to modify importance-performance analysis model: a study of the computer industry. Expert Syst. Appl. 36, 9969–9979 (2009)
Huo, L., Jiang, B., Ning, T., Yin, B.: A BP neural network predictor model for stock price. In Intelligent Computing Methodologies, pp. 362–368. Springer International Publishing, New York (2014)
Johnson, J.W.: A heuristic method for estimating the relative weight of predictor variables in multiple regression. Multivar. Behav. Res. 35, 1–19 (2000)
Kruskal, W.H.: Relative importance by averaging over orderings. Am. Stat. 41, 6–10 (1987)
Kuo, R.J., Tseng, Y.S., Chen, Z.Y.: Integration of fuzzy neural network and artificial immune system-based back-propagation neural network for sales forecasting using qualitative and quantitative data. J. Intell. Manuf. 1–17 (2014)
Martilla, J.A., James, J.C.: Importance-performance analysis. J. Mark. 41, 77–79 (1977)
Mikulić, J., Prebežac, D.: Rethinking the importance grid as a research tool for quality managers. Total Qual. Manag. 22, 993–1006 (2011)
Mikulić, J., Prebežac, D.: Accounting for dynamics in attribute-importance and for competitor performance to enhance reliability of BPNN-based importance-performance analysis. Expert Syst. Appl. 39, 5144–5153 (2012)
Mikulić, J., Paunović, Z., Prebežac, D.: An extended neural network-based importance-performance analysis for enhancing wine fair experience. J. Travel Tour. Mark. 29, 744–759 (2012)
Moller, M.F.: A scaled conjugate gradient algorithm for fast supervised learning. Neural Netw. 6, 525–533 (1993)
Myers, J.H., Alpert, M.I.: Semantic confusion in attitude research: salience vs Importance vs. Determinance. Adv. Consum. Res. 4, 106–110 (1977)
Olden, J.D., Jackson, D.A.: Illuminating the ‘‘Black Box’’: a randomization approach for understanding variable contributions in artificial neural networks. Ecol. Model. 154, 135–150 (2002)
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning internal representation by error propagation. Parallel Distrib. Proc. 1, 318–362 (1986)
Subbaiah, R.M., Dey, P., Nijhawan, R.: Artificial neural network in breast lesions from fine-needle aspiration cytology smear. Diagn. Cytopathol. 42, 218–224 (2014)
Sung, A.H.: Ranking importance of input parameters of neural networks. Expert Syst. Appl. 15, 405–411 (1998)
Van Ittersum, K., Pennings, J.M.E., Wansink, B., van Trijp, H.C.M.: The validity of attribute-importance measurement: a review. J. Bus. Res. 60, 1177–1190 (2007)
Weiner, J.L., Tang, J.: Multicollinearity in Customer Satisfaction Research. White paper, Ipsos Loyalty (2005)
Zong, R., Zhi, Y., Yao, B., Gao, J., Stec, A.A.: Classification and identification of soot source with principal component analysis and back-propagation neural network. Aust. J. Forensic Sci. 46, 224–233 (2014)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2016 Springer International Publishing Switzerland
About this chapter
Cite this chapter
Mikulić, J., Krešić, D., Miličević, K. (2016). Key-Driver Analysis with Extended Back-Propagation Neural Network Based Importance-Performance Analysis (BPNN-IPA). In: Kahraman, C., Yanik, S. (eds) Intelligent Decision Making in Quality Management. Intelligent Systems Reference Library, vol 97. Springer, Cham. https://doi.org/10.1007/978-3-319-24499-0_15
Download citation
DOI: https://doi.org/10.1007/978-3-319-24499-0_15
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-24497-6
Online ISBN: 978-3-319-24499-0
eBook Packages: EngineeringEngineering (R0)