
Abstract
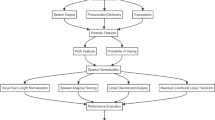
This paper presents a scheme for the development of speech corpus for Standard Yorùbá (SY). The problem herein is the non-availability of phonetically balanced corpus in most resource-scarce languages such as SY. The proposed solution herein is hinged on the development and implementation of a supervised phrase selection using Rule-Based Corpus Optimization Model (RBCOM) to obtain phonetically balanced SY corpus. This was in turn compared with the random phrase selection procedure. The concept of Exploitative Data Analysis (EDA), which is premised on frequency distribution models, was further deployed to evaluate the distribution of allophones of selected phrases. The goodness of fit of the frequency distributions was studied using: Kolmogorov Smirnov, Andersen Darling and Chi-Squared tests while comparative studies were respectively carried out among other techniques. The sample skewness result was used to establish the normality behavior of the data. The results obtained confirmed the efficacy of the supervised phrase selection against the random phrase selection.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


Keywords
References
Abushariah, M.A.A.M., Ainon, R.N., Zainuddin, R., Alqudah, A.A.M., Elshafei Ahmed, M., Khalifa, O.O.: Modern standard Arabic speech corpus for implementing and evaluating automatic continuous speech recognition systems. Journal of the Franklin Institute 349(7), 2215–2242 (2012)
Odéjobí, O.À.: A Quantitative Model of Yoruba Speech Intonation Using Stem-ML. INFOCOMP Journal of Computer Science 6(3), 47–55 (2007)
Adegbola, T., Owolabi, K., Odejobi, T.: Localising for Yorùbá: Experience, challenges and future direction. In: Proceedings of Conference on Human Language Technology for Development, pp. 7–10 (2011)
Àkànbí, L.A., Odéjobí, O.À.: Automatic recognition of oral vowels in tone language: Experiments with fuzzy logic and neural net-work models. Appl. Soft Comput. 11, 1467–1480 (2011)
Aibinu, A.M., Salami, M.J.E., Najeeb, A.R., Azeez, J.F., Rajin, S.M.A.K.: Evaluating the effect of voice activity detection in isolated Yorùbá word recognition system. In: 2011 4th International Conference on Mechatronics (ICOM), pp. 1–5. IEEE (May 2011)
Chomphan, S., Kobayashi, T.: Implementation and evaluation of an HMM-based Thai speech synthesis system. In: Proc. Interspeech, pp. 2849–2852 (August 2007)
Hoogeveen, D., Pauw, D.: CorpusCollie: a web corpus mining tool for resource-scarce languages (2011)
Cucu, H., Buzo, A., Burileanu, C.: ASR for low-resourced languages: Building a phonetically balanced Romanian speech corpus. In: 2012 Proceedings of the 20th European Signal Processing Conference (EUSIPCO), pp. 2060–2064. IEEE (August 2012)
Lecouteux, B., Linares, G.: Using prompts to produce quality corpus for training automatic speech recognition systems. In: MELECON 2008 - The 14th IEEE Mediterranean Electrotechnical Conference, pp. 841–846 (2008)
Nakamura, A., Matsunaga, S., Shimizu, T., Tonomura, M., Sagisaka, Y.: Japanese speech databases for robust speech recognition. In: Proceedings of the Fourth International Conference on Spoken Language, ICSLP 1996, vol. 4, pp. 2199–2202. IEEE (October 1996)
Metze, F., Barnard, E., Davel, M., Van Heerden, C., Anguera, X., Gravier, G., Rajput. N.: The Spoken Web Search Task. In: MediaEval 2012 Workshop, Pisa, Italy, October 4-5 (2012)
Lee, T., Lo, W.K., Ching, P.C., Meng, H.: Spoken language resources for Cantonese speech processing. Speech Communication 36(3), 327–342 (2002)
Abate, S.T., Menzel, W.: Automatic Speech Recognition for an Under-Resourced Language – Amharic. In: Proceedings of INTERSPEECH, pp. 1541–1544 (2007)
Raza, A.A., Hussain, S., Sarfraz, H., Ullah, I., Sarfraz, Z.: Design and development of phonetically rich Urdu speech corpus. In: 2009 Oriental COCOSDA International Conference on Speech Database and Assessments, pp. 38–43. IEEE (August 2009)
Wu, T., Yang, Y., Wu, Z., Li, D.: Masc: A speech corpus in mandarin for emotion analysis and affective speaker recognition. In: IEEE Odyssey 2006 on Speaker and Language Recognition Workshop, pp. 1–5. IEEE (June 2006)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2015 Springer International Publishing Switzerland
About this paper
Cite this paper
Sosimi, A., Adegbola, T., Fakinlede, O. (2015). A Supervised Phrase Selection Strategy for Phonetically Balanced Standard Yorùbá Corpus. In: Gelbukh, A. (eds) Computational Linguistics and Intelligent Text Processing. CICLing 2015. Lecture Notes in Computer Science(), vol 9042. Springer, Cham. https://doi.org/10.1007/978-3-319-18117-2_42
Download citation
DOI: https://doi.org/10.1007/978-3-319-18117-2_42
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-18116-5
Online ISBN: 978-3-319-18117-2
eBook Packages: Computer ScienceComputer Science (R0)