
Abstract
In this paper, we present a novel software framework for recording audio-visual speech corpora with a high-speed video camera (JAI Pulnix RMC 6740) and a dynamic microphone (Oktava MK-012) Architecture of the developed software framework for recording audio-visual Russian speech corpus is described. It provides synchronization and fusion of audio and video data captured by the independent sensors. The software automatically detects voice activity in audio signal and stores only speech fragments discarding non-informative signals. It takes into account and processes natural asynchrony of audio-visual speech modalities as well.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others

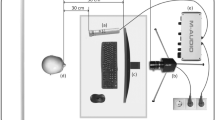
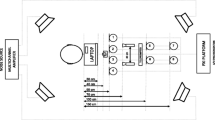
Keywords
References
Karpov, A., Markov, K., Kipyatkova, I., Vazhenina, D., Ronzhin, A.: Large vocabulary Russian speech recognition using syntactico-statistical language modeling. Speech Communication 56, 213–228 (2014)
Kipyatkova, I., Verkhodanova, V., Karpov, A.: Rescoring N-Best Lists for Russian Speech Recognition using Factored Language Models. In: Proc. 4th International Workshop on Spoken Language Technologies for Under-resourced Languages SLTU-2014, St. Petersburg, Russia, pp. 81–86 (2014)
Kipyatkova, I., Karpov, A., Verkhodanova, V., Zelezny, M.: Modeling of Pronunciation, Language and Nonverbal Units at Conversational Russian Speech Recognition. International Journal of Computer Science and Applications 10(1), 11–30 (2013)
Kipyatkova, I., Karpov, A.: Lexicon Size and Language Model Order Optimization for Russian LVCSR. In: Železný, M., Habernal, I., Ronzhin, A. (eds.) SPECOM 2013. LNCS (LNAI), vol. 8113, pp. 219–226. Springer, Heidelberg (2013)
Potamianos, G., et al.: Audio-Visual Automatic Speech Recognition: An Overview. Chapter in Issues in Visual and Audio-Visual Speech Processing. MIT Press (2005)
Bailly, G., Perrier, P., Vatikiotis-Bateson, E.: Audiovisual Speech Processing. Cambridge University Press (2012)
Soldatov, S.: Lip reading: Preparing feature vectors. In: Proc. International Conference Graphicon 2003, Moscow, Russia, pp. 254–256 (2003)
Gubochkin, I.: A system for tracking lip contour of a speaker. In: Modern Science: Actual problems of theory and practice. Natural and Technical Sciences, vol. (4-5), pp. 20–26 (2012) (in Rus.)
Savchenko, A., Khokhlova, Y.: About neural-network algorithms application in viseme classification problem with face video in audiovisual speech recognition systems. Optical Memory and Neural Networks (Information Optics) 23(1), 34–42 (2014)
Krak, Y., Barmak, A., Ternov, A.: Information technology for automatic lip reading of Ukrainian speech. Computational Mathmatics. Kyiv 1, 86–95 (2009) (in Rus.)
Železný, M., Císar, P., Krnoul, Z., Ronzhin, A., Li, I., Karpov, A.: Design of Russian audio-visual speech corpus for bimodal speech recognition. In: Proc. 10th International Conference on Speech and Computer SPECOM 2005, Patras, Greece, pp. 397–400 (2005)
Cisar, P., Zelinka, J., Zelezny, M., Karpov, A., Ronzhin, A.: Audio-visual speech recognition for Slavonic languages (Czech and Russian). In: Proc. International Conference SPECOM 2006, St. Petersburg, Russia, pp. 493–498 (2006)
Karpov, A., Ronzhin, A., Markov, K., Zelezny, M.: Viseme-dependent weight optimization for CHMM-based audio-visual speech recognition. In: Proc. Interspeech 2010 International Conference, Makuhari, Japan, pp. 2678–2681 (2010)
Karpov, A., Ronzhin, A., Kipyatkova, I., Zelezny, M.: Influence of phone-viseme temporal correlations on audio-visual STT and TTS performance. In: Proc. 17th International Congress of Phonetic Sciences ICPhS 2011, Hong Kong, China, pp. 1030–1033 (2011)
Grishina, E.: Multimodal Russian corpus (MURCO): First steps. In: Proc. 7th Int. Conf. on Language Resources and Evaluation LREC 2010, Valetta, Malta, pp. 2953–2960 (2010)
Chitu, A.G., Rothkrantz, L.J.M.: The influence of video sampling rate on lipreading per-formance. In: Proc. SPECOM 2007, Moscow, Russia, pp. 678–684 (2007)
Chitu, A.G., Driel, K., Rothkrantz, L.J.M.: Automatic lip reading in the Dutch language using active appearance models on high speed recordings. In: Sojka, P., Horák, A., Kopeček, I., Pala, K. (eds.) TSD 2010. LNCS (LNAI), vol. 6231, pp. 259–266. Springer, Heidelberg (2010)
Chitu, A.G., Rothkrantz, L.J.M.: Dutch multimodal corpus for speech recognition. In: Proc. LREC 2008 Workshop on Multimodal Corpora, Marrakech, Morocco, pp. 56–59 (2008)
Karpov, A., Ronzhin, A., Kipyatkova, I.: Designing a Multimodal Corpus of Audio-Visual Speech using a High-Speed Camera. In: Proc. 11th IEEE International Conference on Signal Processing ICSP 2012, pp. 519–522. IEEE Press, Beijing (2012)
Young, S., et al.: The HTK Book, Version 3.4. Cambridge Univ. Press (2009)
Liang, L., Liu, X., Zhao, Y., Pi, X., Nefian, A.: Speaker independent audio-visual continuous speech recognition. In: Proc. Int. Conf. on Multimedia & Expo ICME 2002, Lausanne, Switzerland, pp. 25–28 (2002)
Viola, P., Jones, M.: Rapid object detection using a boosted cascade of simple features. In: Proc. IEEE Int. Conf. on Computer Vision and Pattern Recognition CVPR 2001, USA, pp. 511–518 (2001)
Castrillyn, M., Deniz, O., Hernndez, D., Lorenzo, J.: A comparison of face and facial feature detectors based on the Viola-Jones general object detection framework. Machine Vision and Applications 22(3), 481–494 (2011)
Feldhoffer, G., Bardi, T., Takacs, G., Tihanyi, A.: Temporal asymmetry in relations of acoustic and visual features of speech. In: Proc 15th European Signal Processing Conference EUSIPCO 2007, Poznan, Poland, pp. 2341–2345 (2007)
Sekiyama, K.: Differences in auditory-visual speech perception between Japanese and America: McGurk effect as a function of incompatibility. Journal of the Acoustical Society of Japan 15, 143–158 (1994)
Chen, Y., Hazan, V.: Language effects on the degree of visual influence in audiovisual speech perception. In: Proc. 16th International Congress of Phonetic Sciences ICPhS 2007, Saarbrücken, Germany, pp. 2177–2180 (2007)
Karpov, A., Ronzhin, A.: A Universal Assistive Technology with Multimodal Input and Multimedia Output Interfaces. In: Stephanidis, C., Antona, M. (eds.) UAHCI 2014, Part I. LNCS, vol. 8513, pp. 369–378. Springer, Heidelberg (2014)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2014 Springer International Publishing Switzerland
About this paper
Cite this paper
Karpov, A., Kipyatkova, I., Železný, M. (2014). A Framework for Recording Audio-Visual Speech Corpora with a Microphone and a High-Speed Camera. In: Ronzhin, A., Potapova, R., Delic, V. (eds) Speech and Computer. SPECOM 2014. Lecture Notes in Computer Science(), vol 8773. Springer, Cham. https://doi.org/10.1007/978-3-319-11581-8_6
Download citation
DOI: https://doi.org/10.1007/978-3-319-11581-8_6
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-11580-1
Online ISBN: 978-3-319-11581-8
eBook Packages: Computer ScienceComputer Science (R0)