
Abstract
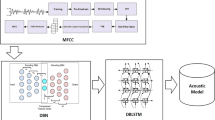
This paper presents continuous Russian speech recognition with deep belief networks in conjunction with HMM. Recognition is performed in two stages. In the first phase deep belief networks are used to calculate the phoneme state probability for feature vectors describing speech. In the second stage, these probabilities are used by Viterbi decoder for generating resulting sequence of words. Two-stage training procedure of deep belief networks is used based on restricted Boltzmann machines. In the first stage neural network is represented as a stack of restricted Boltzmann machines and sequential training is performed, when the previous machine output is the input to the next. After a rough adjustment of the weights second stage is performed using a back-propagation training procedure. The advantage of this method is that it allows usage of unlabeled data for training. It makes the training more robust and effective.
Access provided by Autonomous University of Puebla. Download to read the full chapter text
Chapter PDF
Similar content being viewed by others


References
Rabiner, L.R.: A tutorial on hidden Markov models and selected applications in speech recognition. Proceedings of the IEEE 77(2), 257–285 (1989)
Graves, A., Fernández, S., Schmidhuber, J.: Bidirectional LSTM Networks for Improved Phoneme Classification and Recognition. In: Duch, W., Kacprzyk, J., Oja, E., Zadrożny, S. (eds.) ICANN 2005. LNCS, vol. 3697, pp. 799–804. Springer, Heidelberg (2005)
Hochreiter, S., Schmidhuber, J.: Long Short-Term Memory. Neural Computation 9(8), 1735–1780 (1997)
Hinton, G., Deng, L., Yu, D., Dahl, G., Mohamed, A.-R., Jaitly, N., Senior, A.W., Vanhoucke, V., Nguyen, P., Sainath, T., Kingsbury, B.: Deep Neural Networks for Acoustic Modeling in Speech Recognition. Signal Processing Magazine (2012)
Hinton, G.E., Osindero, S., Teh, Y.: A fast learning algorithm for deep belief nets. Neural Computation 18, 1527–1554 (2006)
Young, S.J., Russel, N.H., Thornton, J.H.S.: Token Passing: A Simple Conceptual Model for Connected Speech Recognition Systems, Cambridge University, technical report (1989)
Young, S.J.: The HTK Book. Version 3.4 (2006)
Hinton, G.E.: Training products of experts by minimizing contrastive divergence. Neural Computation 14(8), 1711–1800 (2002)
Bergstra, J., Breuleux, O., Bastien, F., Lamblin, P., Pascanu, R., Desjardins, G., Turian, J., Warde-Farley, D., Bengio, Y.: Theano: A CPU and GPU Math Expression Compiler. In: Proceedings of the Python for Scientific Computing Conference (SciPy), Austin, June 30-July 3 (2010)
Author information
Authors and Affiliations
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2013 Springer International Publishing Switzerland
About this paper
Cite this paper
Zulkarneev, M., Grigoryan, R., Shamraev, N. (2013). Acoustic Modeling with Deep Belief Networks for Russian Speech Recognition. In: Železný, M., Habernal, I., Ronzhin, A. (eds) Speech and Computer. SPECOM 2013. Lecture Notes in Computer Science(), vol 8113. Springer, Cham. https://doi.org/10.1007/978-3-319-01931-4_3
Download citation
DOI: https://doi.org/10.1007/978-3-319-01931-4_3
Publisher Name: Springer, Cham
Print ISBN: 978-3-319-01930-7
Online ISBN: 978-3-319-01931-4
eBook Packages: Computer ScienceComputer Science (R0)