
Abstract
Time series forecasting lies at the core of important real-world applications in many fields of science and engineering. The abundance of large time series datasets that consist of complex patterns and long-term dependencies has led to the development of various neural network architectures. Graph neural network approaches, which jointly learn a graph structure based on the correlation of raw values of multivariate time series while forecasting, have recently seen great success. However, such solutions are often costly to train and difficult to scale. In this paper, we propose TimeGNN, a method that learns dynamic temporal graph representations that can capture the evolution of inter-series patterns along with the correlations of multiple series. TimeGNN achieves inference times 4 to 80 times faster than other state-of-the-art graph-based methods while achieving comparable forecasting performance.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
From financial investment and market analysis [6] to traffic [21], electricity management, healthcare [4], and climate science, accurately predicting the future real values of series based on available historical records forms a coveted task over time in various scientific and industrial fields. There are a wide variety of methods employed for time series forecasting, ranging from statistical [2] to recent deep learning approaches [22]. However, there are several major challenges present. Real-world time series data are often subject to noisy and irregular observations, missing values, repeated patterns of variable periodicities and very long-term dependencies. While the time series are supposed to represent continuous phenomena, the data is usually collected using sensors. Thus, observations are determined by a sampling rate with potential information loss. On the other hand, standard sequential neural networks, such as recurrent (RNNs) [27] and convolutional networks (CNNs) [20], are discrete and assume regular spacing between observations. Several continuous analogues of such architectures that implicitly handle the time information have been proposed to address irregularly sampled missing data [26]. The variable periodicities and long-term dependencies present in the data make models prone to shape and temporal distortions, overfitting and poor local minima while training with standard loss functions (e. g., MSE). Variants of DTW and MSE have been proposed to mitigate these phenomena and can increase the forecasting quality of deep neural networks [16, 19].
A novel perspective for boosting the robustness of neural networks for complex time series is to extract representative embeddings for patterns after transforming them to another representation domain, such as the spectral one. Spectral approaches have seen much use in the text domain. Graph-based text mining (i. e., Graph-of-Words) [25] can be used for capturing the relationships between the terms and building document-level representations. It is natural, then, that such approaches might be suitable for more general sequence modeling. Capitalizing on the recent success of graph neural networks (GNNs) on graph structured data, a new family of algorithms jointly learns a correlation graph between interrelated time series while simultaneously performing forecasting [3, 29, 32]. The nodes in the learnable graph structure represent each individual time series and the links between them express their temporal similarities. However, since such methods rely on series-to-series correlations, they do not explicitly represent the inter-series temporal dynamics evolution. Some preliminary studies have proposed simple computational methods for mapping time series to temporal graphs where each node corresponds to a time step, such as the visibility graph [17] and the recurrence network [7].
In this paper, we propose a novel neural network, TimeGNN, that extends these previous approaches by jointly learning dynamic temporal graphs for time series forecasting on raw data. TimeGNN (i) extracts temporal embeddings from sliding windows of the input series using dilated convolutions of different receptive sizes, (ii) constructs a learnable graph structure, which is forward and directed, based on the similarity of the embedding vectors in each window in a differentiable way, (iii) applies standard GNN architectures to learn embeddings for each node and produces forecasts based on the representation vector of the last time step. We evaluate the proposed architecture on various real-world datasets and compare it against several deep learning benchmarks, including graph-based approaches. Our results indicate that TimeGNN is significantly less costly in both inference and training while achieving comparable forecasting performance. The code implementation for this paper is available at https://github.com/xun468/Time-GNN.
2 Related Work
Time Series Forecasting Models. Time series forecasting has been a long-studied challenge in several application domains. In terms of statistical methods, linear models including the autoregressive integrated moving average (ARIMA) [2] and its multivariate extension, the vector autoregressive model (VAR) [10] constitute the most dominant approaches. The need for capturing non-linear patterns and overcoming the strong assumptions for statistical methods, e. g., the stationarity assumption, has led to the application of deep neural networks, initially introduced in sequential modeling, to the time series forecasting setting. Those models include recurrent neural networks (RNNs) [27] and their improved variants for alleviating the vanishing gradient problem, namely the LSTM [12] and the GRU [5]. An alternative method for extracting long-term dependencies via large receptive fields can be achieved by leveraging stacked dilated convolutions, as proposed along with the Temporal Convolution Network (TCN) [1]. Bridging CNNs and LSTMs to capture both short-term local dependency patterns among variables and long-term patterns, the Long- and Short-term Time-series network (LSTNet) [18] has been proposed. For univariate point forecasting, the recently proposed N-BEATS model [24] introduces a deep neural architecture based on a deep stack of fully-connected layers with basis expansion. Attention-based approaches have also been employed for time-series forecasting, including Transformer [30] and Informer [35]. Finally, for efficient long-term modeling, the most recent Autoformer architecture [31] introduces an auto-correlation mechanism in place of self-attention, which extracts and aggregates similar sub-series based on the series periodicity.
Graph Neural Networks. Over the past few years, graph neural networks (GNNs) have been applied with great success to machine learning problems on graphs in various fields, including chemistry for drug screening [14] and biology for predicting the functions of proteins modeled as graphs [9]. The field of GNNs has been largely dominated by the so-called message passing neural networks (MPNNs) [8], where each node updates its feature vector by aggregating the feature vectors of its neighbors. In the case of time series data on arbitrary known graphs, e. g., in traffic forecasting, several architectures that combine sequential models with GNNs have been proposed [21, 28, 33, 34].
Joint Graph Structure Learning and Forecasting. However, since spatial-temporal forecasting requires an apriori topology which does not apply in the case of most real-world time series datasets, graph structure learning has arisen as a viable solution. Recent models perform joint graph learning and forecasting for multivariate time series data using GNNs, intending to capture temporal patterns and exploit the interdependency among time series while predicting the series’ future values. The most dominant algorithms include NRI [15], MTGNN [32] and GTS [29], in which the graph nodes represent the individual time series and their edges represent their temporal evolution. MTGNN obtains the graph adjacency from the as a degree-k structure from the pairwise scores of embeddings of each series in the multivariate collection, which might pose challenges to end-to-end learning. On the other hand, NRI and GTS employ the Gumbel softmax trick [13] to differentiably sample a discrete adjacency matrix from the edge probabilities. Both models compute fixed-size representations of each node based on the time series, with the former dynamically producing the representations per individual window and the latter extracting global representations from the whole training series. MTGNN combines temporal convolution with graph convolution layers, and GTS uses a Diffusion Convolutional Recurrent Neural Network (DCRNN) [21], where the hidden representations of nodes are diffused using graph convolutions at each step.
3 Method
Let \(\{\textbf{X}_{i,1:T}\}_{i=1}^m\) be a multivariate time series that consists of m channels and has a length equal to T. Then, \(\textbf{X}_t \in \mathbb {R}^{m}\) represents the observed values at time step t. Let also \(\mathcal {G}\) denote the set of temporal dynamic graph structures that we want to infer.
Given the observed values of \(\tau \) previous time steps of the time series, i. e., \(\textbf{X}_{t-\tau }, \ldots , \textbf{X}_{t-1}\), the goal is to forecast the next h time steps (e. g., \(h=1\) for 1-step forecasting), i. e., \(\hat{\textbf{X}}_{t}, \hat{\textbf{X}}_{t+1}, \ldots ,\) \(\hat{\textbf{X}}_{t+h-1}\). These values can be obtained by the forecasting model \(\mathcal {F}\) with parameters \(\varPhi \) and the graphs \(\mathcal {G}\) as follows:

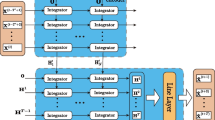
The proposed TimeGNN framework time series for graph learning from raw time series and forecasting based on embeddings learned on the parameterized graph structures.
3.1 Time Series Feature Extraction
Unlike previous methods which extract one feature vector per variable in the multivariate input, our method extracts one feature vector per time step in each window k of length \(\tau \). Temporal sub-patterns are learned using stacked dilated convolutions, similar to the main blocks of the inception architecture [23].
Given the sliding windows \(\textbf{S} = \{\textbf{X}_{t-\tau +k-K}, \ldots , \textbf{X}_{t+k-K-1}\}_{k=1}^K\), we perform the following convolutional operations to extract three feature maps \(\textbf{f}_0^k\), \(\textbf{f}_1^k\), \(\textbf{f}_2^k\), per window \(\textbf{S}^k\). Let \(\textbf{f}_i^k \in \mathbb {R}^{\tau \times d}\) for hidden dimension d of the convolutional kernels, such that:
where \(*\) the convolutional operator, \(\textbf{C}_0^{1,1}\), \(\textbf{C}_1^{1,1}\), \(\textbf{C}_2^{1,1}\) convolutional kernels of size 1 and dilation rate 1, \(\textbf{C}_2^{3,3}\) a convolutional kernel of size 3 and dilation rate 3, \(\textbf{C}_2^{5,5}\) a convolutional kernel of size 5 and dilation rate 5, and \(\textbf{b}_{01}, \textbf{b}_{11}, \textbf{b}_{21}, \textbf{b}_{23}, \textbf{b}_{25}\) the corresponding bias terms.
The final representations per window k are obtained using a fully connected layer on the concatenated features \(\textbf{f}_0^k, \textbf{f}_1^k, \textbf{f}_2^k\), i. e., \(\textbf{z}^k = \text {FC}(\textbf{f}_0^k \Vert \textbf{f}_1^k\Vert \textbf{f}_2^k)\), such that \(\textbf{z}^k \in \mathbb {R}^{\tau \times d}\). In the next sections, we refer to each time step of the hidden representation of the feature extraction module in each window k as \(\textbf{z}_i^k, \forall ~i \in \{1, \ldots \tau \}\).
3.2 Graph Structure Learning
The set \(\mathcal {G} = \{\mathcal {G}^k\}, k \in \mathbb {N}^*\) describes the collection of graph structures that are parameterized for all individual sliding window of length \(\tau \) of the series, where K defines the total number of windows. The goal of the graph learning module is to learn each adjacency matrix \(\textbf{A}^k \in \{0,1\}^{\tau \times \tau }\) for a temporal window of observations \(\textbf{S}^k\). Following the works of [15, 29], we use the Gumbel softmax trick to sample a discrete adjacency matrix as described below.
For the Gumbel softmax trick, let \(\textbf{A}^k\) refer to a random variable of the matrix Bernoulli distribution parameterized by \(\boldsymbol{\theta }^k \in [0,1]^{\tau \times \tau }\), so that \(A_{ij}^k \sim Ber(\theta _{ij}^k)\) is independent for pairs (i, j). By applying the Gumbel reparameterization trick [13] for enabling differentiability in sampling, we can obtain the following:
where \(\textbf{g}_{i,j}^1,\textbf{g}_{i,j}^2\) are vectors of i.i.d samples drawn from Gumbel distribution, \(\sigma \) is the sigmoid activation and s is a parameter that controls the smoothness of samples, so that the distribution converges to categorical values as \(s \xrightarrow {}0\).
The link predictor takes each pair of extracted features \((\textbf{z}_i^k,\textbf{z}_j^k)\) of window k and maps their similarity to a \(\theta _{ij}^k \in [0,1]\) by applying fully connected layers. Then the Gumbel reparameterization trick is used to approximate a sigmoid activation function while retaining differentiability:
In order to obtain directed and forward (i. e., no look-back in previous time steps in the history) graph structures \(\mathcal {G}\) we only learn the upper triangular part of the adjacency matrices.
3.3 Graph Neural Network for Forecasting
Once the collection \(\mathcal {G}\) of learnable graph structures per sliding window k are sampled, standard GNN architectures can be applied for capturing the node-to-node relations, i. e., the temporal graph dynamics. GraphSAGE [11] was chosen as the basic building GNN block of the node embedding learning architecture as it can effectively generalize across different graphs with the same attributes. GraphSAGE is an inductive framework that exploits node feature information and generates node embeddings (i. e., \(\textbf{h}_u\) for node u) via a learnable function, by sampling and aggregating features from a node’s local neighborhood (i. e., \(\mathcal {N}(u)\)).
Let \((\mathcal {V}^k, \mathcal {E}^k)\) correspond to the set of nodes and edges of the learnable graph structure for each \(\mathcal {G}^k\). The node embedding update process for each \(p \in \{1, \ldots , P\}\) aggregation steps, employs the mean-based aggregator, namely convolutional, by calculating the element-wise mean of the vectors in \(\{\textbf{h}_u^{p-1}, \forall u \in \mathcal {N}(u)\}\), such that:
where \(\textbf{W}\) trainable weights. The final normalized (i. e., \(\mathbf {\tilde{h}}_u^{p}\)) representation of the last node (i. e., time step) in each forward and directed graph denoted as \(\textbf{z}_{u_T} = \mathbf {\tilde{h}}_{u_T}^p\) is passed to the output module. The output module consists of two fully connected layers which reduce the vector into the final output dimension, so as to correspond to the forecasts \(\hat{\textbf{X}}_{t}, \hat{\textbf{X}}_{t+1}, \ldots , \hat{\textbf{X}}_{t+h-1}\). Figure 1 demonstrates the feature extraction, graph learning, GNN and output modules of the proposed TimeGNN architecture.
3.4 Training and Inference
To train the parameters of Eq. (1) for the time series point forecasting task, we use the mean absolute error loss (MAE). Let \(\mathbf {\hat{X}}^{(i)}, i \in \{1,...,K\}\) denote the predicted vector values for K samples, then the MAE loss is defined as:
The optimized weights for the feature extraction, graph structure learning, GNN and output modules are selected based on the minimum validation loss during training, which is evaluated as described in the experimental setup (Sect. 4.3)
4 Experimental Evaluation
We next describe the experimental setup, including the datasets and baselines used for comparisons. We also demonstrate and analyze the results obtained by the proposed TimeGNN architecture and the baseline models.
4.1 Datasets
This work was evaluated on the following multivariate time series datasets:
Exchange-Rate which consists of the daily exchange rates of 8 countries from 1990 to 2016, following the preprocessing of [18].
Weather that contains hourly observations of 12 climatological features over a period of four yearsFootnote 1, preprocessed as in [35].

Computation costs of TimeGNN, TimeMTGNN and baseline models. (a) The inference and epoch training time per epoch between datasets. (b) The inference and epoch times with varying window sizes on the weather dataset
Electricity-Load is based on the UCI Electricity Consuming Load datasetFootnote 2 that records the electricity consumption of 370 Portuguese clients from 2011 to 2014. As in [35], the recordings are binned into hourly intervals over the period of 2012 to 2014 and incomplete clients are removed.
Solar-Energy contains the solar power production records in 2006, sampled every 10 minutes from 137 PV plants in Alabama StateFootnote 3.
Traffic is a collection of 48 months, between 2015 and 2016, of hourly data from the California Department of TransportationFootnote 4. The data describes the road occupancy rates (between 0 and 1) measured by different sensors.
4.2 Baselines
We consider five baseline models for comparison with our TimeGNN proposed architecture. We chose two graph-based methods, MTGNN [32] and GTS [29], and three non graph-based methods, LSTNet [18], LSTM [12], and TCN [1]. Also, we evaluate the performance of TimeMTGNN, a variant of MTGNN that includes our proposed graph learning module. LSTM and TCN follow the size of the hidden dimension and number of layers of TimeGNN. Those were fixed to three layers with hidden dimensions of 32, 64 for the Exchange-Rate and Weather datasets and 128 for Electricity, Solar-Energy and Traffic. In the case of MTGNN, GTS, and LSTNet, parameters were kept as close as possible to the ones mentioned in their experimental setups.
4.3 Experimental Setup
Each model is trained for two runs for 50 epochs and the average mean squared error (MSE) and mean absolute error (MAE) score on the test set are recorded. The model chosen for evaluation is the one that performs the best on the validation set during training. The same dataloader is used for all models where the train, validation, and test splits are 0.7, 0.1, and 0.2 respectively. The data is split first and each split is scaled using the standard scalar. The dataloader uses windows of length 96 and batch size 16. The forecasting horizons tested are 1, 3, 6, and 9 time steps into the future, where the exact value of the time step is dependent on the dataset (e. g., 3 time steps would correspond to 3 h into the future for the weather dataset and 3 days into the future for the Exchange dataset). In this paper, we use single-step forecasting for ease of comparison with other baseline methods. For training, we use the Adam optimizer with a learning rate of 0.001. Experiments for the Weather and Exchange datasets were conducted on an NVIDIA T4 and Electricity-Load, Solar, and Traffic on an NVIDIA A40.
4.4 Results
Scalability. We compare the inference and training times of the graph-based models TimeGNN, MTGNN, GTS in Fig. 2. These figures also include recordings from the ablation study of the TimeMTGNN variant, which is described in the relevant paragraph below. Figure 2(a) shows the computational costs on each dataset. Among the baseline models, GTS is the most costly in both inference and training time due to the use of the entire training dataset for graph construction. In contrast, MTGNN learns static node features and is subsequently more efficient. In inference time, as the number of variables increases there is a noticeable increase in inference time for MTGNN and GTS as their graph sizes also increase. TimeGNN’s graph does not increase in size with the number of variables and consequently, the inference time scales well across datasets. The training epoch times follow the observations in inference time.
Since the size of the graphs used by TimeGNN is based on window size, the cost of increasing the window size on the weather dataset is shown in Fig. 2(b). As the window size increases, so does the cost of inference and training for all models. As the graph learning modules for MTGNN and GTS do not interact with the window size, the increase in cost can primarily be attributed to their forecasting modules. MTGNN’s inference times do not increase as dramatically as GTS’s, implying a more robust forecasting module. As the window size increases, TimeGNN’s inference and training cost growth is slower than the other methods and remains the fastest of the GNN methods. The time-based graph learning module does not become overly cumbersome as window sizes increase.
Forecasting Quality. Table 1 summarizes the forecasting performance of the baseline models and TimeGNN for different horizons \(h \in \{1,3,6,9\}\).
In general, GTS has the best forecasting performance on the smaller Exchange-Rate dataset. The use of the training data during graph construction may give GTS an advantage over the other methods on this dataset. TimeGNN however shows signs of overfitting during training and is unable to match the other two GNNs. On the Weather dataset, the purely recurrent methods perform the best in MSE score across all horizons. TimeGNN is competitive with the recurrent methods on these metrics and surpasses the recurrent models on MAE. This suggests TimeGNN is producing more significant outlier predictions than the recurrent methods and TimeGNN is the best performing GNN method.
On the larger Electricity-Load, Solar-Energy, and Traffic datasets, in general, MTGNN is the top performer with LSTNet close behind. However, for larger horizons, TimeGNN performs better than GTS and competitively with LSTNet and the other recurrent models. This shows that time-domain graphs can successfully capture long-term dependencies within a dataset although TimeGNN struggles more with short-term predictions. This could also be attributed to the simplicity of TimeGNN’s forecasting module compared to the other graph-based approaches.
Ablation Study. To empirically examine the effects of the forecasting module and the representation power of the proposed graph construction module in TimeGNN, we conducted an ablation study where we replaced MTGNN’s graph construction module with our own, so-called TimeMTGNN baseline. The remaining modules and the hyperparameters in TimeMTGNN are kept as similar as possible to MTGNN. TimeMTGNN shows comparable forecasting performance to MTGNN on the larger Electricity-Load, Solar-Energy, and Traffic datasets and higher performance on the smaller Exchange-Rate and Weather datasets. This shows the TimeGNN graph construction module is capable of learning meaningful graph representations that do not impede and in some cases improve forecasting quality. As seen in Fig. 2, the computational performance of TimeMTGNN suffers in comparison to MTGNN. A major contributing factor is the number of graphs produced. MTGNN learns a single graph for a dataset while TimeGNN produces one graph per window, accordingly, the number of GNN operations is greatly increased. However, the focus of this experiment was to confirm that the proposed temporal graph-learning module preserves or improves accuracy over static ones rather than to optimize efficiency.
5 Conclusion
We have presented a novel method of representing and dynamically generating graphs from raw time series. While conventional methods construct graphs based on the variables, we instead construct graphs such that each time step is a node. We use this method in TimeGNN, a model consisting of a graph construction module and a simple GNN-based forecasting module, and examine its performance against state-of-the-art neural networks. While TimeGNN’s relative performance differs between datasets, this representation is clearly able to capture and learn the underlying properties of time series. Additionally, it is far faster and more scalable than existing graph methods as both the number of variables and the window size increase.
References
Bai, S., Kolter, J.Z., Koltun, V.: An empirical evaluation of generic convolutional and recurrent networks for sequence modeling. arXiv:1803.01271 (2018)
Box, G.E., Jenkins, G.M., Reinsel, G.C., Ljung, G.M.: Time Series Analysis: Forecasting and Control. Wiley, New York (2015)
Cao, D., et al.: Spectral temporal graph neural network for multivariate time-series forecasting. Adv. Neural. Inf. Process. Syst. 33, 17766–17778 (2020)
Chauhan, S., Vig, L.: Anomaly detection in ECG time signals via deep long short-term memory networks. In: 2015 IEEE International Conference on Data Science and Advanced Analytics (DSAA), pp. 1–7. IEEE (2015)
Cho, K., et al.: Learning phrase representations using RNN encoder-decoder for statistical machine translation. arXiv preprint arXiv:1406.1078 (2014)
Ding, X., Zhang, Y., Liu, T., Duan, J.: Deep learning for event-driven stock prediction. In: Twenty-Fourth International Joint Conference on Artificial Intelligence (2015)
Donner, R.V., Zou, Y., Donges, J.F., Marwan, N., Kurths, J.: Recurrence networks-a novel paradigm for nonlinear time series analysis. New J. Phys. 12(3), 033025 (2010)
Gilmer, J., Schoenholz, S.S., Riley, P.F., Vinyals, O., Dahl, G.E.: Neural message passing for quantum chemistry. In: International Conference on Machine Learning, pp. 1263–1272. PMLR (2017)
Gligorijević, V., et al.: Structure-based protein function prediction using graph convolutional networks. Nat. Commun. 12(1), 3168 (2021)
Hamilton, J.D.: Time Series Analysis. Princeton University Press, Princeton (2020)
Hamilton, W., Ying, Z., Leskovec, J.: Inductive representation learning on large graphs. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Hochreiter, S., Schmidhuber, J.: Long short-term memory. Neural Comput. 9(8), 1735–1780 (1997)
Jang, E., Gu, S., Poole, B.: Categorical reparameterization with Gumbel-Softmax. arXiv preprint arXiv:1611.01144 (2016)
Kearnes, S., McCloskey, K., Berndl, M., Pande, V., Riley, P.: Molecular graph convolutions: moving beyond fingerprints. J. Comput. Aided Mol. Des. 30, 595–608 (2016)
Kipf, T., Fetaya, E., Wang, K.C., Welling, M., Zemel, R.: Neural relational inference for interacting systems. In: International Conference on Machine Learning, pp. 2688–2697. PMLR (2018)
Kosma, C., Nikolentzos, G., Xu, N., Vazirgiannis, M.: Time series forecasting models copy the past: How to mitigate. In: Pimenidis, E., Angelov, P., Jayne, C., Papaleonidas, A., Aydin, M. (eds.) Artificial Neural Networks and Machine Learning–ICANN 2022: 31st International Conference on Artificial Neural Networks, Bristol, UK, 6–9 September 2022, Proceedings, Part I, vol. 13529, pp. 366–378. Springer, Cham (2022). https://doi.org/10.1007/978-3-031-15919-0_31
Lacasa, L., Luque, B., Ballesteros, F., Luque, J., Nuno, J.C.: From time series to complex networks: the visibility graph. Proc. Natl. Acad. Sci. 105(13), 4972–4975 (2008)
Lai, G., Chang, W.C., Yang, Y., Liu, H.: Modeling long-and short-term temporal patterns with deep neural networks. In: The 41st International ACM SIGIR Conference on Research & Development in Information Retrieval, pp. 95–104 (2018)
Le Guen, V., Thome, N.: Deep time series forecasting with shape and temporal criteria. IEEE Trans. Pattern Anal. Mach. Intell. 45(1), 342–355 (2022)
LeCun, Y., Bottou, L., Bengio, Y., Haffner, P.: Gradient-based learning applied to document recognition. Proc. IEEE 86(11), 2278–2324 (1998)
Li, Y., Yu, R., Shahabi, C., Liu, Y.: Diffusion convolutional recurrent neural network: data-driven traffic forecasting. arXiv preprint arXiv:1707.01926 (2017)
Lim, B., Zohren, S.: Time-series forecasting with deep learning: a survey. Phil. Trans. R. Soc. A 379(2194), 20200209 (2021)
Lin, M., Chen, Q., Yan, S.: Network in network. arXiv preprint arXiv:1312.4400 (2013)
Oreshkin, B.N., Carpov, D., Chapados, N., Bengio, Y.: N-beats: neural basis expansion analysis for interpretable time series forecasting. arXiv preprint arXiv:1905.10437 (2019)
Rousseau, F., Vazirgiannis, M.: Graph-of-word and TW-IDF: new approach to Ad Hoc IR. In: Proceedings of the 22nd ACM International Conference on Information & Knowledge Management, pp. 59–68 (2013)
Rubanova, Y., Chen, R.T., Duvenaud, D.K.: Latent ordinary differential equations for irregularly-sampled time series. In: Advances in Neural Information Processing Systems, vol. 32 (2019)
Rumelhart, D.E., Hinton, G.E., Williams, R.J.: Learning representations by back-propagating errors. Nature 323(6088), 533–536 (1986)
Seo, Y., Defferrard, M., Vandergheynst, P., Bresson, X.: Structured sequence modeling with graph convolutional recurrent networks. In: Cheng, L., Leung, A., Ozawa, S. (eds.) Neural Information Processing: 25th International Conference, ICONIP 2018, Siem Reap, Cambodia, 13–16 December 2018, Proceedings, Part I 25, pp. 362–373. Springer, Cham (2018). https://doi.org/10.1007/978-3-030-04167-0_33
Shang, C., Chen, J., Bi, J.: Discrete graph structure learning for forecasting multiple time series. arXiv preprint arXiv:2101.06861 (2021)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Wu, H., Xu, J., Wang, J., Long, M.: Autoformer: decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural. Inf. Process. Syst. 34, 22419–22430 (2021)
Wu, Z., Pan, S., Long, G., Jiang, J., Chang, X., Zhang, C.: Connecting the dots: multivariate time series forecasting with graph neural networks. In: Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, pp. 753–763 (2020)
Yu, B., Yin, H., Zhu, Z.: Spatio-temporal graph convolutional networks: a deep learning framework for traffic forecasting. arXiv preprint arXiv:1709.04875 (2017)
Zhao, L., et al.: T-GCN: a temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. Syst. 21(9), 3848–3858 (2019)
Zhou, H., et al.: Informer: beyond efficient transformer for long sequence time-series forecasting. In: Proceedings of the AAAI Conference on Artificial Intelligence, vol. 35, pp. 11106–11115 (2021)
Acknowledgements
This work is supported by the Wallenberg AI, Autonomous Systems and Software Program (WASP) funded by the Knut and Alice Wallenberg Foundation and the IP Paris “PhD theses in Artificial Intelligence (AI)” funding programme by ANR. Computational resources were provided by the National Academic Infrastructure for Supercomputing in Sweden (NAISS) at Alvis partially funded by the Swedish Research Council through grant agreement no. 2022-06725.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2024 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Xu, N., Kosma, C., Vazirgiannis, M. (2024). TimeGNN: Temporal Dynamic Graph Learning for Time Series Forecasting. In: Cherifi, H., Rocha, L.M., Cherifi, C., Donduran, M. (eds) Complex Networks & Their Applications XII. COMPLEX NETWORKS 2023. Studies in Computational Intelligence, vol 1141. Springer, Cham. https://doi.org/10.1007/978-3-031-53468-3_8
Download citation
DOI: https://doi.org/10.1007/978-3-031-53468-3_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-53467-6
Online ISBN: 978-3-031-53468-3
eBook Packages: EngineeringEngineering (R0)