
Abstract
A phonetic transcription system provides pronunciation of words, mostly in International Phonetic Alphabet (IPA) format. Phonetic transcription is the visual representation of phones in the form of characters and symbols represented in the IPA format. This paper describes the development of an automatic phonetic transcription system for an under-resourced Indian language, Konkani. In this paper, we have proposed an automatic phonetic word transcription generation system based on a set of deterministic linguistic rules mainly derived from the available work on Konkani literature. Some general rules, like Schwa deletion, are also considered in the design process. Parallel 101 sentences with 397 unique words have been used to test the accuracy of the system. Our system shows a Word Error Rate (WER) of 60, whereas existing system had a WER of 92.5.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others



Keywords
- Konkani
- pronunciation
- Phonetic transcription
- Transcription system
- Konkani phonetic transcription
- Phonetic
1 Introduction
Konkani is an Indo-Aryan language that belongs to the Indo-European family of languagesFootnote 1. More than 2.5 million people speak Konkani language. It is the official language of the state of Goa in India and is spoken in the western coastal part of India, including Goa, the Konkan region of Maharashtra, Karwar, Mangaluru, other coastal areas of Karnataka, and parts of Kerala, Gujarat, Dadra & Nagar Haveli and Daman & Diu. Konkani is one of the 22 scheduled languages included in the eighth schedule of the Constitution of IndiaFootnote 2. Konkani and Marathi are often referred to as sister languages, as many words have similar formations and semantics with some variations. The first known Konkani inscription dates back to 1187 CEFootnote 3.
The work presented here is an attempt to create a resource which can be used for Konkani language development. This paper describes the work of creating a phonetic transcription system for Konkani, which can be considered as one of the important component to develop an Automatic Speech Recognition (ASR) System and Text to Speech (TTS) for any language, in this case, for Konakni language.
The paper is organised as follows:- Sect. 1 provides an introduction of the Konkani language and presents the need for this work. The motivation of this work is briefed in Sect. 2. Section 3 defines the problem statement, Sect. 4 presents the Discussions and Methodology used; Finally, Sect. 6 Concludes the paper with future scope for improvements.
2 Motivation
Konkani is a under-resourced language with very few resources available for R & D. Also, there are hardly any applications for the Konkani language. In the recent decade, efforts have been made to develop resources for Konkani, viz., Konkani Wordnet [3, 4, 11], ILCI Corpus [2], CIIL Corpus [7], SPTIL ProjectFootnote 4, etc. However, an online Konkani pronunciation dictionary has not been developed as yet. This motivated our research group to create a Konkani phonetic transcription system, which may be beneficial for future research work of TTS and ASR Systems for Konkani Language.
3 Problem Statement
The goal of the work presented in the paper is to design an Automatic phonetic transcription system specific to the Konkani language. This phonetic transcription system takes a Konkani text in written Devanagari form as input and produces phonetic transcription in IPA. The transcriptions are rule-based one-to-one characters to phonemes mapping and currently do not consider the context of the word.
4 Methodology and Datasets Used
4.1 Rules for Phonetic Mapping
The Devanagari character set for Konkani is taken from A Gold standard Konkani Raw Text Corpus [8]. Tables 1, 2, and 3 show the mapping of Konkani characters with the IPA symbols. Rules for phonetic transcription are identified using previous work, which is reported by [1, 5, 9]. Some IPA mapping for the characters not reported through the above work, has also been provided. Some rules are summarized and presented in a tabular form. The Devanagari characters, approximate IPA notation, phonetic transcription for the dictionary and UTF-8 code for the characters are also presented here. Table 4 provides approximate IPA symbols for Devanagari vowels and diphthongs. Konkani has nine vowels out of which six vowels find place in the script whereas three do not. The nine vowels of the language are:
 . The three vowels that are a part of the vowel system of the language but do not have a unique character representing them in the script are:
. The three vowels that are a part of the vowel system of the language but do not have a unique character representing them in the script are:
 , and
, and
 . There are a few other things that need to be noted with regards to the vowels system of the language:
. There are a few other things that need to be noted with regards to the vowels system of the language:
-
Vowel length is not phonemic in Konkani. Hence, one of the Devanagari character representing vowel length contrast, namely
 and
and
 is redundant for the language.
is redundant for the language. -
Vowels from Sr. No. 16 in Table 4 are not found in the language.
-
The vowel [
 ] occurs in Sanskrit loans only and specifically in proper nouns only. It should be noted that some vowel phonemes in Konkani, like /
] occurs in Sanskrit loans only and specifically in proper nouns only. It should be noted that some vowel phonemes in Konkani, like /
 / and /
/ and /
 /, have the same written representation [5].
/, have the same written representation [5].
 and
and
 is redundant for the language.
is redundant for the language. ] occurs in Sanskrit loans only and specifically in proper nouns only. It should be noted that some vowel phonemes in Konkani, like /
] occurs in Sanskrit loans only and specifically in proper nouns only. It should be noted that some vowel phonemes in Konkani, like /
 / and /
/ and /
 /, have the same written representation [
/, have the same written representation [Before elaborating on the consonant inventory of the language, it would be worth mentioning that voicing and aspiration is phonemic in the language. Nasalization is phonemic in the language with the vowels displaying oral-nasal contrast in almost all positions. The language also has nasal consonant phonemes /m/, /n/, /
 /. Speaking about the labial consonant phonemes, Konkani distinguishes between the voiceless /p/ and the voiced /b/ as well as the aspirated /
/. Speaking about the labial consonant phonemes, Konkani distinguishes between the voiceless /p/ and the voiced /b/ as well as the aspirated /
 / versus the voiced non-aspirated /b/. With the exception of the voiceless aspirated labial consonant
/ versus the voiced non-aspirated /b/. With the exception of the voiceless aspirated labial consonant
 ], other consonants contrast in voicing and aspiration. Scholars have claimed that
], other consonants contrast in voicing and aspiration. Scholars have claimed that
 ] did exist in the older stage of the language but was replaced by the labio-dental fricative /f/ due to the large scale Portuguese borrowings in the language.
] did exist in the older stage of the language but was replaced by the labio-dental fricative /f/ due to the large scale Portuguese borrowings in the language.
Examples of minimal pairs exhibiting differences between labial sounds are given below:
-
There is a contrast between the voiceless plosive /p/ and the voiced plosive /b/., e.g. [paj] ’father-M.SG.’ [baj] ’endearment word for a girl child-N.SG.’
-
The voiceless plosive /p/ also contrasts with the aspirated voiced plosive /
 /), e.g. [
/), e.g. [
 ] ’son-M.SG.’ [
] ’son-M.SG.’ [
 ] ’ghost-N.SG.’
] ’ghost-N.SG.’
 /), e.g. [
/), e.g. [
 ] ’son-M.SG.’ [
] ’son-M.SG.’ [
 ] ’ghost-N.SG.’
] ’ghost-N.SG.’Four dental phonemes /
 /, /
/, /
 /, /
/, /
 / and /
/ and /
 / display voicing and aspiration contrast. Examples for these phonemes are given below:
/ display voicing and aspiration contrast. Examples for these phonemes are given below:
-
voiceless dental plosive /
 / versus voiced dental plosive /
/ versus voiced dental plosive /
 /), e.g., [
/), e.g., [
 ] ‘wick-F.SG.’; ‘candle-F.SG.) [
] ‘wick-F.SG.’; ‘candle-F.SG.) [
 ] ‘dispute’, ‘argument’ (M-SG.)
] ‘dispute’, ‘argument’ (M-SG.) -
voiceless non-aspirated dental plosive /
 / versus voiceless aspirated dental plosive /
/ versus voiceless aspirated dental plosive /
 /, e.g., [
/, e.g., [
 ] ’clap-F.SG.’ [
] ’clap-F.SG.’ [
 ] ‘small plate for eating-F.SG.’
] ‘small plate for eating-F.SG.’ -
voiced non-aspirated dental plosive /
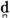 / versus voiced aspirated dental plosive (/
/ versus voiced aspirated dental plosive (/
 /), e.g., [
/), e.g., [
 ] ‘door-N.SG.’ [
] ‘door-N.SG.’ [
 ] ’sharp edge-F.SG.’
] ’sharp edge-F.SG.’
 / versus voiced dental plosive /
/ versus voiced dental plosive /
 /), e.g., [
/), e.g., [
 ] ‘wick-F.SG.’; ‘candle-F.SG.) [
] ‘wick-F.SG.’; ‘candle-F.SG.) [
 ] ‘dispute’, ‘argument’ (M-SG.)
] ‘dispute’, ‘argument’ (M-SG.) / versus voiceless aspirated dental plosive /
/ versus voiceless aspirated dental plosive /
 /, e.g., [
/, e.g., [
 ] ’clap-F.SG.’ [
] ’clap-F.SG.’ [
 ] ‘small plate for eating-F.SG.’
] ‘small plate for eating-F.SG.’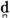 / versus voiced aspirated dental plosive (/
/ versus voiced aspirated dental plosive (/
 /), e.g., [
/), e.g., [
 ] ‘door-N.SG.’ [
] ‘door-N.SG.’ [
 ] ’sharp edge-F.SG.’
] ’sharp edge-F.SG.’With respect to the place of articulation, all the above dental consonants contrast with the retroflex consonant phonemes /
 /, /
/, /
 /, /
/, /
 /, and /
/, and /
 / which also display voicing and aspiration differences. The following pairs of words make this distinction explicit:
/ which also display voicing and aspiration differences. The following pairs of words make this distinction explicit:
-
voiceless retroflex plosive /
 / versus voiced retroflex plosive /
/ versus voiced retroflex plosive /
 /, e.g., [
/, e.g., [
 ] ‘way/path-F.SG.’ [
] ‘way/path-F.SG.’ [
 ] ‘growth-F.SG.’
] ‘growth-F.SG.’ -
voiceless unaspirated retroflex plosive /
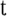 / versus voiceless aspirated retroflex plosive /
/ versus voiceless aspirated retroflex plosive /
 / ), e.g., [
/ ), e.g., [
 ] ’A narrow water course-M.SG.’ [
] ’A narrow water course-M.SG.’ [
 ] ’lesson-M.SG.
] ’lesson-M.SG. -
voiceless aspirated versus voiced aspirated (/
 / versus /
/ versus /
 /) [
/) [
 ] ‘sound of crackers, bullet, etc.’ [
] ‘sound of crackers, bullet, etc.’ [
 ] ‘loud noise of explosion, fall, etc.’
] ‘loud noise of explosion, fall, etc.’ -
Velar consonant phonemes in Konkani namely
 also display a contrast with respect to voicing and aspiration. Konkani also has the velar nasal
also display a contrast with respect to voicing and aspiration. Konkani also has the velar nasal
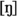 .
.
 / versus voiced retroflex plosive /
/ versus voiced retroflex plosive /
 /, e.g., [
/, e.g., [
 ] ‘way/path-F.SG.’ [
] ‘way/path-F.SG.’ [
 ] ‘growth-F.SG.’
] ‘growth-F.SG.’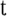 / versus voiceless aspirated retroflex plosive /
/ versus voiceless aspirated retroflex plosive /
 / ), e.g., [
/ ), e.g., [
 ] ’A narrow water course-M.SG.’ [
] ’A narrow water course-M.SG.’ [
 ] ’lesson-M.SG.
] ’lesson-M.SG. / versus /
/ versus /
 /) [
/) [
 ] ‘sound of crackers, bullet, etc.’ [
] ‘sound of crackers, bullet, etc.’ [
 ] ‘loud noise of explosion, fall, etc.’
] ‘loud noise of explosion, fall, etc.’ also display a contrast with respect to voicing and aspiration. Konkani also has the velar nasal
also display a contrast with respect to voicing and aspiration. Konkani also has the velar nasal
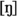 .
.With respect to the place of articulation, all the above dental consonants contrast with the retroflex consonant phonemes /
 , and /
, and /
 / which also display voicing and aspiration differences. The following pairs of words make this distinction explicit: Konkani has dento-palatal affricates /
/ which also display voicing and aspiration differences. The following pairs of words make this distinction explicit: Konkani has dento-palatal affricates /
 /, /
/, /
 / and /
/ and /
 / which contrast with the palatal affricates /
/ which contrast with the palatal affricates /
 /, /
/, /
 /, /
/, /
 / and /
/ and /
 /.
/.
With the exception of the voiceless aspirated counterpart of the dental affricate /
 /, all others contrast with respect to place of articulation, voicing and aspiration. However, the written form of the language (the Devanagari script) lacks separate characters for showing the distinction between these sounds.
/, all others contrast with respect to place of articulation, voicing and aspiration. However, the written form of the language (the Devanagari script) lacks separate characters for showing the distinction between these sounds.
Minimal pairs exhibiting meaning differences for dento-palatal and palatal phonemes are given below:
-
Voiceless unaspirated dento-palatal affricate versus voiced unaspirated versus voiced aspirated affricate (/
 / versus /
/ versus /
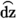 / versus /
/ versus /
 /)[
/)[
 ] ‘climb-IMP.2P.SG.’ [
] ‘climb-IMP.2P.SG.’ [
 ] ‘heavy-ADJ.’ [
] ‘heavy-ADJ.’ [
 ] ‘fall-IMP.2P.SG.’ [
] ‘fall-IMP.2P.SG.’ [
 ] ’graze-IMP.2P.SG.’ [
] ’graze-IMP.2P.SG.’ [
 ] ’if’ [
] ’if’ [
 ] ’spring-F.SG.’
] ’spring-F.SG.’ -
Voiceless unaspirated palatal affricate versus voiced unaspirated palatal affricate (/
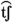 / versus /
/ versus /
 /) [
/) [
 ] ‘four’ [
] ‘four’ [
 ] ‘tired’,
] ‘tired’, -
Voiceless unaspirated palatal affricate versus voiced aspirated palatal affricate (/
 / versus /
/ versus /
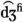 /) [
/) [
 ] ’disciple-M.SG. [
] ’disciple-M.SG. [
 ] ’small garland-M.SG.’
] ’small garland-M.SG.’ -
Voiced unaspirated dento-palatal affricate versus voiced unaspirated palatal affricate (/
 / versus /
/ versus /
 ]’mature-ADJ.’ [
]’mature-ADJ.’ [
 ] ’(month of) June’
] ’(month of) June’
 / versus /
/ versus /
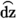 / versus /
/ versus /
 /)[
/)[
 ] ‘climb-IMP.2P.SG.’ [
] ‘climb-IMP.2P.SG.’ [
 ] ‘heavy-ADJ.’ [
] ‘heavy-ADJ.’ [
 ] ‘fall-IMP.2P.SG.’ [
] ‘fall-IMP.2P.SG.’ [
 ] ’graze-IMP.2P.SG.’ [
] ’graze-IMP.2P.SG.’ [
 ] ’if’ [
] ’if’ [
 ] ’spring-F.SG.’
] ’spring-F.SG.’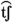 / versus /
/ versus /
 /) [
/) [
 ] ‘four’ [
] ‘four’ [
 ] ‘tired’,
] ‘tired’, / versus /
/ versus /
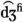 /) [
/) [
 ] ’disciple-M.SG. [
] ’disciple-M.SG. [
 ] ’small garland-M.SG.’
] ’small garland-M.SG.’ / versus /
/ versus /
 ]’mature-ADJ.’ [
]’mature-ADJ.’ [
 ] ’(month of) June’
] ’(month of) June’Konkani also has velar consonant phonemes /k/, /
 /, /g/, /
/, /g/, /
 / which show contrast in voicing and aspiration. Meaning differences arising from this opposition are shown below:
/ which show contrast in voicing and aspiration. Meaning differences arising from this opposition are shown below:
-
voiceless unaspirated velar versus voiceless aspirated velar (/k/ versus /
 /)
/)
 ’banana tree-F.SG.
’banana tree-F.SG.
 ’sport/game-M.SG.’
’sport/game-M.SG.’ -
voiced unaspirated velar versus voiced aspirated velar (/g/ versus /
 /) [
/) [
 ] ;cow-F.SG.’ [
] ;cow-F.SG.’ [
 ] ’wound-M.SG’
] ’wound-M.SG’
 /)
/)
 ’banana tree-F.SG.
’banana tree-F.SG.
 ’sport/game-M.SG.’
’sport/game-M.SG.’ /) [
/) [
 ] ;cow-F.SG.’ [
] ;cow-F.SG.’ [
 ] ’wound-M.SG’
] ’wound-M.SG’Konkani nasals - Konkani has three nasals - the bilabial nasal [m], the dental nasal [n] and the retroflex nasal [
 ]. These contrast with each other. The occurrence of the velar nasal [
]. These contrast with each other. The occurrence of the velar nasal [
 ] and the palatal nasal [
] and the palatal nasal [
 ] is predictable in that they occur as homorganic nasals (as in [
] is predictable in that they occur as homorganic nasals (as in [
 ] ’body-N.SG’, [
] ’body-N.SG’, [
 ] ’a member of the village council-M/F/N.’)
] ’a member of the village council-M/F/N.’)
Contrasts between nasal phonemes is given below:
[ka:n] ’ear-M.SG.’ [ka:m] ’work-N.SG.’
[
 ] ’caution-N.SG.’ [
] ’caution-N.SG.’ [
 ] ’a large vessel of copper or iron-N.SG.’
] ’a large vessel of copper or iron-N.SG.’
There are four fricatives in the language- the labio-dental fricative [f], voiceless alveolar fricative [s], postalveolar [
 ] and the voiceless glotal fricative [h]. Some words showing contrast between these sounds are given below:
] and the voiceless glotal fricative [h]. Some words showing contrast between these sounds are given below:
[fa:r] ’explosion-M.SG.’ [sa:r] ’extract-M.SG.’ [
 ] ’city-N.SG.’ [ha:r] ’python; garland-M.SG.’
] ’city-N.SG.’ [ha:r] ’python; garland-M.SG.’
The retroflex fricative [
 ] which is shown in the script, only occurs in the written form as is confined to proper nouns only.
] which is shown in the script, only occurs in the written form as is confined to proper nouns only.
The language has the labio-dental approximant [
 ] and palatal approximant [j]. Contrast between these is shown below:
] and palatal approximant [j]. Contrast between these is shown below:
[
 ] ’argument-M.SG.’ [
] ’argument-M.SG.’ [
 ] ’memory-F.SG.’
] ’memory-F.SG.’
The language also contrasts between the dental lateral [l] and retroflex lateral [
 ]. The following pair of words display this contrast.
]. The following pair of words display this contrast.
[pa:l] ’lizard-F.SG.’ [
 ] ’root of a tree-N.SG.’
] ’root of a tree-N.SG.’
The language also has the trill [r]. Although so1
me works refer to its place of articulation as dental, it seems to occur in alveolar position in case of some words. Word pair contrasting this sound with the dental approximant [
 ] is given below:
] is given below:
[ra:g] ’anger-M.SG.’ [la:g] ’cajolery; wooing-F.SG.’
The Devanagari script used for the language shows two more characters
 and
and
 which are actually consonant clusters [
which are actually consonant clusters [
 ] and [dn] respectively. The major limitation of the script is that it does not have characters to show some important contrasts that exist in the language and at times shows characters that are not relevant for the language. A need for revising the script was proposed years back by some scholars
] and [dn] respectively. The major limitation of the script is that it does not have characters to show some important contrasts that exist in the language and at times shows characters that are not relevant for the language. A need for revising the script was proposed years back by some scholars
Table 5, presents rules for the vowel diacritics.
In Table 6, transcription rules for Chandrabindu, Anusvara and Visarga are presented. Chandrabindu is used for the tatsama (Sanskrit borrowed) words.
In Table 7, rules for consonant transcription are presented. It should be noted that the place of [
 ] has been taken by labio-dental fricative [
] has been taken by labio-dental fricative [
 ], which is said to be an effect of Portuguese borrowings into the language. Konkani language also has dental and palatal affricates that are phonemic in the Konkani language but are written alike in the writing system of the Konkani language. Nasalization and aspiration are phonemic in Konkani.
], which is said to be an effect of Portuguese borrowings into the language. Konkani language also has dental and palatal affricates that are phonemic in the Konkani language but are written alike in the writing system of the Konkani language. Nasalization and aspiration are phonemic in Konkani.
4.2 Dataset Used
For the testing purpose, we created phonetic transcriptions for Konkani text available from [6] which contains 74 sentences. We also created additional 27 transcriptions of sentences to cover all the phones in the language. These data were used for testing the proposed transcription system.
4.3 Methodology to Create Konkani Phonetic Transcription System and Result

Konkani Phonetic Transcription System Architecture.
The developed transcription system is a rule-based system and not considering the context of the word. Figure 1 demonstrates the Konkani phonetic transcription system architecture diagram. Various steps were followed in the creation of this phonetic transcription system. Here, the Konkani Devanagari sentence is given as input to the system. This sentence is further broken into tokens or words, and then these words/tokens are broken down into characters for phonetic mapping. Python programming language is used for the design of this system. Mapping from Devanagari to Unicode is done using rules provided in Tables 4, 5, 6 and 7 in this paper. After applying all the transcription rules, we get the final transcription in IPA format.
4.4 Evaluation Metrics
To assess the performance of the phonetic transcription system evaluation metric used is Word Error Rate (WER). WER is the percentage of the words not correctly identified by transcription system from the ground-truth test data set. Word accuracy is calculated by subtracting WER from 100 or it is equal to percentage of the words correctly identified by phonetic transcription system from the from the ground-truth test data set.
5 Results and Discussion
This system exhibits a word accuracy of 40%, with WER of 60. Moreover, when the same dataset is evaluated on the existing Devanagari to Phonetic transcription system [10], it demonstrated a word accuracy of 7.50%. Thus our system performs much better as compared to existing systems. However, there is still scope for improvement in the current system. Errors in the system were mainly with regard to the mapping of some characters to their respective phonemes. In this, the mapping of the character
 to phonemes
to phonemes
 and
and
 was crucial. The character in the script did not show the closed and open contrast between the phoneme pair. Similar is the case with regard to the back vowels
was crucial. The character in the script did not show the closed and open contrast between the phoneme pair. Similar is the case with regard to the back vowels
 and
and
 . The phonemes
. The phonemes
 and
and
 also contributed to errors significantly. Alike
also contributed to errors significantly. Alike
 and
and
 , these phonemes too have the same character
, these phonemes too have the same character
 in the script that represents them. The error was also introduced because the phoneme
in the script that represents them. The error was also introduced because the phoneme
 does not get omitted at all places. Identifying schwa deletion rules in depth might help improve the transcription system’s performance.
does not get omitted at all places. Identifying schwa deletion rules in depth might help improve the transcription system’s performance.
6 Conclusion and Future Work
In this paper, we presented the Konkani pronunciation transcription system. This system is developed by using the rule-based character to phonetic mapping to produce the transcriptions in the International Phonetic Alphabet (IPA) format. This work can be improved by identifying additional transcription rules. In future work, we shall focus on improving the accuracy of the phonetic transcription system by adding more transcription rules. Further, with improved accuracy, this system can lead to the creation of a phonetic dictionary which shall act as an essential component for developing the TTS and ASR system for the Konkani language. Also, building the complete ASR system is possible by creating acoustic and language models.
References
Almeida, M.S.: A Description of Konkani. Thomas Stephens Konknni Kendr, Miramar, Panaji (1989)
Bansal, A., Banerjee, E., Jha, G.N.: Corpora creation for Indian language technologies-the ILCI project. In: The Sixth Proceedings of Language Technology Conference (LTC’13) (2013)
Bhatt, B.S., Bhensdadia, C.K., Bhattacharyya, P., Chauhan, D., Patel, K.: Gujarati wordnet: a profile of the indowordnet. In: Dash, N.S., Bhattacharyya, P., Pawar, J.D. (eds.) The WordNet in Indian Languages, pp. 167–174. Springer Singapore, Singapore (2017). https://doi.org/10.1007/978-981-10-1909-8_9
Desai, S.N., Walawalikar, S.W., Karmali, R.N., Pawar, J.D.: Insights on the Konkani wordnet development process. In: Dash, N.S., Bhattacharyya, P., Pawar, J.D. (eds.) The WordNet in Indian Languages, pp. 101–117. Springer Singapore, Singapore (2017). https://doi.org/10.1007/978-981-10-1909-8_6
Fadte, S., Fernandes, E.V., Karmali, R., Pawar, J.D.: Acoustic analysis of vowels in Konkani. ACM Trans. Asian Low-Resource Lang. Inform. Process. 21(5), 1–13 (2022). https://doi.org/10.1145/3474358, https://dl.acm.org/doi/10.1145/3474358
Fadte, S., Vaz, E., Ojha, A.K., Karmali, R., Pawar, J.D.: Empirical analysis of oral and nasal vowels of Konkani (2023)
Kurian, C.: A review on speech corpus development for automatic speech recognition in Indian languages. Int. J. Adv. Netw. Appl. 6(6), 2556 (2015)
Ramamoorthy L. and Narayan, C., Saurabh, V., Rajesha, N., Manasa, G.: A gold standard Konkani raw text corpus (2018)
Sardesai, M.: Bhasabhas Article on Linguistics. Goa, first edn, Goa Konkani Academy (1993)
Ulm, A.: Devanagari to IPA transcription (2022). https://www.ashtangayoga.info/philosophy/sanskrit-and-devanagari/transliteration-tool/
Walawalikar, S., et al.: Experiences in building the Konkani wordnet using the expansion approach (2010)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Fadte, S., Vaz Fernandes, E., Redkar, H., Pawar, J.D. (2023). Konkani Phonetic Transcription System 1.0. In: Karpov, A., Samudravijaya, K., Deepak, K.T., Hegde, R.M., Agrawal, S.S., Prasanna, S.R.M. (eds) Speech and Computer. SPECOM 2023. Lecture Notes in Computer Science(), vol 14339. Springer, Cham. https://doi.org/10.1007/978-3-031-48312-7_19
Download citation
DOI: https://doi.org/10.1007/978-3-031-48312-7_19
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-48311-0
Online ISBN: 978-3-031-48312-7
eBook Packages: Computer ScienceComputer Science (R0)