
Abstract
FPGAs are an attractive type of accelerator for all-purpose HPC computing systems due to the possibility of deploying tailored hardware on demand. However, the common tools for programming and operating FPGAs are still complex to use, specially in scenarios where diverse types of tasks should be dynamically executed. In this work we present a programming abstraction with a simple interface that internally leverages High-Level Synthesis, Dynamic Partial Reconfiguration and synchronisation mechanisms to use an FPGA as a multi-tasking server with preemptive scheduling and priority queues. This leads to a better use of the FPGA resources, allowing the execution of several kernels at the same time and deploying the most urgent ones as fast as possible. The results of our experimental study show that our approach incurs only a 1.66% overhead when using only one Reconfigurable Region (RR), and 4.04% when using two RRs, whilst presenting a significant performance improvement over the traditional non-preemptive full reconfiguration approach.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The end of Moore’s law and loss of Dennard’s scaling has motivated the search of alternative ways of improving the performance of upcoming computational systems. As a result, heterogeneous systems, primarily composed of CPUs and GPUs [2], have become commonplace in HPC machines. However, these architectures are not ideally suited for all codes, and it has been found that when HPC applications are bound by aspects other than compute, for instance memory bound codes, moving to a dataflow style and exploiting the specialisation of FPGAs can be beneficial [3, 8]. Nonetheless, FPGAs have not yet been adopted by any of the large supercomputers, which is due to both the challenges of programmability and flexibility. The former has been partially addressed by High Level Synthesis (HLS) tooling, enabling the programmer to write their code in C or C++. However the latter has been less explored. The entire FPGA is often stalled during fabric reconfiguration which means that dynamic scheduling and preemptive execution of workloads is less common.
In this paper we propose a programming abstraction to easily use an FPGA as a multi-tasking server with preemptive scheduling and priority queues. It hides the complex low-level details of using Dynamic Partial Reconfiguration (DPR) and synchronisation mechanisms to support on-the-fly instantiation, stopping and resumming of kernels on parts of the FPGA fabric whilst the rest of the chip continues executing other workloads independently. The proposal includes, as a case study, the development of a full First-Come-First-Served (FCFS) preemptive scheduler with priority queues. The tasks are programmed as OpenCL kernels managed with the Controller model [4, 7], a heterogeneous programming model implemented as a C99 library of functions. It is oriented to efficiently manage different types of devices with a portable interface. The Controller model has been extended to support multiple kernels and preemption on DPR capable FPGA systems. This solution brings all the benefits of task-based models to FPGAs, with a low programming effort. We also introduce an experimental study to show the efficiency of the proposed solution.
The rest of the paper is organised as follows: Sect. 2 describes related activities tackling flexible execution of kernels for FPGAs. Section 3 presents an overview of the original programming model that we use as a base to devise and implement our proposal. In Sect. 4 we present the techniques and extensions to support our approach, both on the management of the on-chip FPGA infrastructure and on the host code. Section 5 describes the programming level abstractions provided to the user. In Sect. 6 we present an experimental study to evaluate our approach. Section 7 concludes the paper and discusses further work.
2 Related Work
The integration of different types of architectures in heterogeneous systems can enable the execution of workloads more efficiently by using the most appropriate hardware for each part of a program. However, this also requires the user to master the programming models of these architectures. Programming abstractions have been introduced to simplify the management of different types of devices, targeting both functional and performance portability. Many approaches are devised as implementations of a heterogeneous task-based model. They present a common host-side API for orchestrating workloads/tasks, programmed as kernels, among the different accelerators present in the system. Approaches such as Kokkos [6], OpenCL [9], and OpenACC [1] have become popular for mixing CPUs and GPUs. Other approaches also support the FPGAs with a similar high-level approach. However, despite improving general programmability by supporting a common host-side API, these approaches fail to provide the high flexibility potential of FPGAs. For example, these frameworks lack the support to independently swap in and out tasks of varying sizes onto an FPGA accelerator. The FPGA is programmed with a full bitstream that contains the kernels that will be run during the program execution in a non-preemptive way.
The authors of [5] explore these issues. They present a task-based model targeting System on-a Chip (SoC) deployment based on OpenCL and using DPR. They support kernel preemption by enabling checkpointing at the end of each OpenCL workgroup, and whilst this is a natural consistency point in the OpenCL model, the coarse-grained nature of the approach limits scheduling flexibility. For example, tasks of higher priority may need to wait until a previous workgroup with lower priority tasks finishes. Moreover, the user must write their kernel interfaces in a manner that are comformant to the interfaces of the Reconfigurable Regions (RR), causing a conflict between the high-level OpenCL description and the management of the lower-level on-chip infrastructure, which increases the overall development complexity.
3 The Controller Programming Model
Our proposal is devised as an extension of the Controller heterogeneous programming model. In this section we provide and overview of the original model and its features. Controller [4, 7] is a heterogeneous task-based parallel programming model implemented as a C99 library. It provides an abstraction for programming using different types of devices, such as sets of CPU-cores, GPUs, and FPGAs.
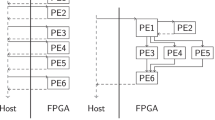
As illustrated in Fig. 1, the model is based around the Controller entity. Each Controller entity is associated to a particular device on its creation and manages the execution or data-transfers with that device.

Extracted from [7].
The Controller programming model, generic FPGA backend.
The main program executes the coordination code in a main thread, using the Controller high-level API to enqueue computation tasks for the device. Each Controller entity has its own thread that dequeues and launches the execution of the kernels associated to the tasks. The model also provides an extra hidden device to execute host-tasks, which are managed through a separate thread. The Controller runtime resolves data dependencies between tasks automatically, performing data transfers in a transparent way. The requests of both kernel executions and data-transfers needed are derived to the internal queues or streams of the device driver, controlling the execution order of kernels, data-transfers and host-tasks with native events. It uses three queues for each device: one for kernel execution, one for host-to-device transfer, and one for device-to-host transfers. This enables a fast control operation and an efficient overlapping of computation and data transfers when it is possible. Portability is achieved using different runtime backends for different device technologies (such as CUDA or OpenCL), to implement the calls to manage the low-level device queues and events. The computations that can be launched as tasks are kernel codes written by the programmer. Controller supports generic codes, written in OpenCL and targeting any kind of device, or specialised kernels programmed in the native programming model of an accelerator such as CUDA for Nvidia GPUs.
4 Approach to Support Preemptive Scheduling on FPGAs
Our approach requires the use of new techniques in two areas, the on-chip FPGA infrastructure and the integration on the host-side of the Controller runtime.
4.1 On-chip Infrastructure
Figure 2 shows the architecture of the static part of the on-chip infrastructure, known as shell, that should be deployed in the FPGA to support the proposed control of Reconfigurable Regions (RR). The example shows two RRs, although this model is scalable to any number of RRs. The example shows details of a reference implementation of the proposal using Xilinx technology, although, these concepts can be easily ported to other FPGAs. This example shell implementation deploys HLS kernels generated by Xilinx’s Vitis with 1 AXI4-Master interface which bundles the data ports to DRAM memory, and an AXI4-Slave interface bundling the control ports. This interface layout is fairly standard. The interrupt controller registers interrupts generated by the RRs upon completion. Thus, the CPU can detect when kernels have finished execution. To support preemption, the shell should be able to interrupt a kernel, saving its context and state, to later resume it. The shell features two on-chip BRAM memory banks (one per RR) to store the interrupted kernels context at arbitrary intervals, defined by the user. BRAM memory is used since its speed and its closeness to the RRs results in very low latency, minimizing the overhead of the context saving operation. These BRAM banks are also connected to a BRAM controller which enables access from the CPU, supporting overall book-keeping of the kernel context when they are being swapped in and out by the scheduler that controls the execution from the host.

Simplified architecture of the system.
Our approach needs support for resetting both the entire FPGA and individual RRs (to undertake partial reconfigurations). The former is achieved via the shell’s global reset (see Fig. 2). The latter is supported by a specific reset functionality for each RR. It is implemented using the GPIO ports of the CPU, with the added complexity that HLS kernels by default contain a low active reset. We negate the GPIO signal and apply a logical and with the global reset signal. The application of the reset signal is asynchronous which means that the kernel might be interrupted unpredictably. The software abstractions described in Sect. 5.2 ensure that the task can be resumed later from a consistent state.
This shell design is provided in netlist form with the RRs instantiated as black boxes. Consequently, to generate the shell’s bitstream the number of RRs required is supplied to the associated TCL script. This generates a corresponding Vivado compatible DPR capable hardware design, which is built and deployed onto the FPGA. The programmer writes their HLS kernels using our proposed software abstractions (see Sect. 5.2), that effectively transform the C code into interface-compliant HLS code during the HLS synthesis.
4.2 Integration into the Controller Framework
A new backend has been written for the Controller framework. It supports interaction with our shell, targeting the Zynq-7020 FPGA in Pynq-Z2. To communicate with the FPGA, our backend uses the Pynq C API [10]. This API exposes low-level functionalities, such as the loading of both full and partial bitstreams, the interaction with design IP such as interrupt controllers or DMA engines through memory mapping, and host-device shared memory. Building on the C Pynq API means that this work is compatible with any other FPGA from the Zynq-7000 family with little modification required.
Each RR is treated as an independent accelerator by our backend to ensure that RR kernels can be executed in parallel. Thus, the Controller’s queue is replicated as many times as the number of RRs, and each instance is managed by a separate thread. A request to reconfigure a region is implemented as an internal task, queued up and executed like any other task. This simplifies the backend structure and allows the scheduling of reconfigurations request before the associated task execution on the fabric. Zynq only provides a single Internal Configuration Access Port (ICAP) [12]. This means that only one RR can be partially reconfigured at a time. Thus, we need to implement a synchronisation between reconfiguration request in the Controller queues. The Zynq-7000 FPGA family architecture supports shared memory which can be accessed by both the FPGA fabric and host CPU. Thus, data-movement operations can be implemented with zero-copy. The backend utilises Userspace I/O (UIO) to interact with the shell’s interrupt controller to detect the interrupts raised by the RRs to indicate kernel termination. We use the select() system call to activate the manager CPU thread when an interrupt is received. Then, the backend queries the interrupt controller to determine which RR raised the interrupt. This avoids the use of an active polling approach that would keep a CPU core busy unnecessarily.
4.3 Use Case: DPR Scheduler
In this section we show the use the proposed DPR approach to build an FCFS scheduler of kernel tasks, with priorities and preemption.
In this proof-of-concept we simulate scenarios where both the time of the next task arrival and the task parameters are randomly generated. We pre-generate a sequence of tasks (tasks_to_arrive), ordered by a random arrival time. Each task has a random priority, a randomly chosen kernel code to execute (from a given set), and random arguments. We design a modular scheduler with separate modules for the generation of random tasks, management of the queues, service of tasks and the main loop of the scheduler. Therefore, it is easy to extend or adapt. It is compatible with any number of RRs.

The main loop of the scheduler is presented in Algorithm 1. The arrival of the next task is simulated with a timeout clock, used in the same select() function that detects the interrupts raised by the end of a kernel in a RR. Thus, the WaitForInterrupt function returns when a new task arrives or when a RR kernel finishes.
The process of serving a task consists of the following steps: (1) Find an available region, i.e., a region where the last task running has already finished. (2) In case no available region was found, if preemption is disabled enqueue the task. If preemption is enabled, check if there is a region executing a task with lower priority. In that case, stop the kernel execution in that region, save the context and state, enqueue the stopped task, and consider the region as available. (3) If the kernel loaded in the available region is distinct from the kernel of the incoming task, enqueue a swapping task to reconfigure the RR. (4) Launch the new task. If it was a previously stopped task, its context is copied back to the device before launching.
5 Programmer’s Abstractions
This section describes the abstractions provided to the programmer to implement kernels and to use the proposed approach, without knowledge of the low-level details of the DPR technology.
5.1 Kernel Interface Abstraction
The generation of interfaces in technologies such as Vitis HLS is done adding pragmas that can be cumbersome and error prone to write. Moreover, a requirement of DPR is that HLS kernels to be deployed into a given RR must present the same external interface to the shell. They must conform to the same number of interface ports and port configurations, such as bus widths [12]. Thus, better abstractions are needed to hide these low-level details to the programmer.

The configuration of the interfaces is a parameter present in our TCL configuration script that generates the shell’s hardware design, as discussed in Sect. 4.1. In the Controller model, the kernel codes are wrapped with curly brackets and preceded by a kernel signature. The kernel signature is provided with a macro-function named CTRL_KERNEL_FUNCTION. It specifies the kernel parameters in a form that is processed by the Controller library to generate the proper low-level interface. Listing 1.1 illustrates the definition of a Median Blur kernel, used in our evaluation in Sect. 6, preceded by its signature. In this work we extend the Controller kernel signature to generate code with a uniform interface, as required by the shell. The parameters of the kernel signature are the following:
\(\mathtt {CTRL\_KERNEL\_FUNCTION(K,~T,~S,~A_{p},~A_{i},~A_{f})}\):
-
K is the name of the kernel.
-
T indicates the backend type that will be targeted. Supported types are: CPU, CUDA, OpenCL, FPGA.
-
S is the subtype of backend that will be targeted, e.g. DEFAULT.
-
\(\mathtt {A_{p}}\) is a list of pointer non-scalar arguments defined with KTILE_ARGS.
-
\(\mathtt {A_{i}}\) is a list of integer scalar arguments defined with INT_ARGS.
-
\(\mathtt {A_{f}}\) is a list of floating point scalar arguments defined with FLOAT_ARGS.
Controller provides a wrapper structure for multi-dimensional arrays named HitTile. Any kind of non-scalar arguments are provided as HitTile arguments. KTILE_ARGS function enables the use of HitTile accessors within the kernel, effectively providing input and output arrays to the kernel, as discussed in [7]. INT_ARGS and FLOAT_ARGS support passing integer and float scalar arguments, respectively. All these functions have variadic arguments to adapt the kernel interface to the number of arguments required by the programmer. The corresponding code generated by the kernel signature for the kernel shown in Listing 1.1 is shown in Listing 1.2. Three integer arguments are provided by the user and five extra dummy arguments \(\mathtt {i\_args\_<n>}\) are generated. Similarly, 8 dummy floating point and 1 dummy pointer arguments are generated to fill the argument count and provide a shell compliant interface. Finally, a pointer to a struct context is added for context book-keeping if the task is interrupted.

5.2 Programmer Abstractions for Preemption
Preemption of a kernel whilst it is running requires saving its state so that it can be resumed in the future. Previous approaches, such as [5] only save the context at the end of an OpenCL workgroup. We also wanted to provide flexibility for the programmer to decide exactly where their code should be checkpointed. We propose a finer-grain and programmer-aware checkpointing approach, where the programmer has the flexibility to indicate when and what data should be chekpointed during the kernel execution. We provide several checkpointing macro-functions. The programmer declares which variables should be stored in the checkpoints using the context_vars macro-function. The checkpoint macro stores one or more of these variables at a given execution point. A for_save macro-function is used in-place of the normal for loop construct, to provide support for resumption on a specific loop iteration. These calls are expanded to the proper code at synthesis time.
An example of their use is shown in Listing 1.1. At line 11 the integer variables k, row, and col are selected to be checkpointed, with lines 11, 12, and 13 using the for_save macro to define loops and for these to be restarted as appropriate. The associated loop variables are checkpointed at lines 17, 18, and 19. This kernel saves the state at each iteration to be able to be resumed without discarding previously computed iterations.

Context saving is done transparently storing the state in the struct context generated in BRAM (see Listing 1.3). In our prototype up to N integers can be nominated by the user to be saved, where N is a compile time parameter. It is trivial to extend the structure to support other data types. The field saved keeps information about whether the variables have already been saved through checkpoint and they should be restored in a resume operation. The valid field is used to indicate if the asynchronous preemption interrupted the kernel during a data saving operation. In that case, the resume operation will be done with the previously saved values.
6 Experimental Study
We present the results of an experimental study to evaluate the efficiency of our approach.
6.1 Use Case: Scheduler of Randomly Generated Image Filter Tasks
In this study we experiment with the scheduler described in Sect. 4.3. The kernels chosen for the experimentation are blur image filters applied to images pre-stored in memory. Tasks execute one of four possible kernels: Median Blur over one, two or three iterations or one iteration of Gaussian Blur. Tasks arrive at random times distributed over \(\mathcal {U}(0,T)\) minutes. The scheduler features optional preemption and priorities. For these experiments we choose to use 5 different priorities, to generate enough preemptions, task switching and reconfigurations. The tasks, their arrival time, and the image on which it should be applied, are randomly generated before the scheduler starts.
6.2 Experimentation Environment
The experiments were conducted on a Xilinx PYNQ-Z2 FPGA. It features a ZYNQ XC7Z020-1CLG400C of the Zynq-7020 family, an ARM Cortex-A9 dual core at 650 MHz CPU and 512 MB DDR3. HLS kernels were compiled using Xilinx Vitis HLS version 2020.2 and the hardware design and corresponding bitstreams were generated with Xilinx Vivado v2020.2. Controller was compiled with GCC 9.3.0 and compilation scripts were generated with CMake 3.20.5.
Several random seeds for the task generation have been tested. We show the results for the value 15. The main observations can be extrapolated for other random sequences. The number of tasks generated was chosen to be 30. We enabled priorities both with and without preemption of tasks. We considered three different rate of arrivals T: busy (0.1), medium (0.5) and idle (0.8). We worked with image sizes \(200\times 200\), \(300\times 300\), \(400\times 400\), \(500\times 500\) and \(600\times 600\). In order to study the sequential vs. the parallel behaviour both one and two RRs were considered. Finally, each experiment was executed ten times to account for variability and the results presented are average times with standard deviation.
6.3 Results
In order to show the effectiveness of our approach we are presenting results for the following metrics: (i) service time, defined as the time it takes for a task to be served since it is generated until it starts execution on the FPGA and (ii) throughput, defined as the number of tasks executed per second. We also compare the use of partial reconfiguration with the more conventional full reconfiguration approach. Figure 3 reports the service time for tasks in every priority queue both with and without preemption for 30 tasks at size \(600\times 600\) accumulated by priority. We chose this number of tasks and image size as it provides enough workload and a sufficient number of tasks to study the behaviour of the scheduler. The results are presented both for one and two RRs. As can be seen, service times are longer for the busy rate of arrival than for medium and idle, as tasks have to wait a longer time until a RR becomes available than when they arrive later, giving the opportunity for kernels to finish. If the priority of an incoming task is higher than one of the tasks running, then its service time will be virtually zero. We can observe this by comparing the plots on the right with plots on the left. For this representative case, on average, preemption reduces service time substantially. This will be the case in general when incoming tasks present a higher priority than running tasks. These results show that our scheduler effectively reduces the total service time of tasks, thus increasing the flexibility, as preemption enables swapping in and out tasks upon a condition — priority in this case. The reduction in service time is heavily dependent on the structure of priorities of the generated tasks, both in terms of the number of tasks enqueued and the number of reconfigurations enforced by incoming kernels not loaded already in the fabric. Note that a task will have to wait until previous tasks of higher or the same priority have completed. Additionally, as shown in Fig. 3, the service time decreases with the number of RRs, as more opportunities are created for kernels of lower priorities to execute.

Service times for 30 tasks at size \(600 \times 600\). 1 RR (left), 2 RRs (right). Per bar group: Non-preemptive (left), preemptive (right).
Figure 4 shows the throughput of the scheduler with 30 tasks both with and without preemption over one and two RRs. As expected, the throughput increases with the rate of arrival of tasks. The lower the dimensions of the images the higher the throughput, as the kernels complete execution faster. It is also noticeable that the overheads incurred by preemption lead to a slightly lower throughput. These are most noticeable for a high rate of arrival of tasks, where throughput losses are 8.3% and 10.7% for the case with one and two RRs, respectively, at size 200 and busy arrival rate. For the rest of cases the loss ranges between 0–4%. Most of this overhead is explained by the time taken by the extra partial reconfigurations imposed by preemption. The dashed red lines show an upper bound of the throughput if full reconfiguration was used instead. This has been calculated from the throughput at busy rate of arrival adding the product of the number of reconfigurations by the average difference on time between full (0.22 s) and partial (0.07 s) reconfiguration. This is a highly optimistic upper bound, since it does not take into account the effects of stalling the FPGA, which impedes the concurrency of kernel execution and reconfiguration, and enforces a preemption of the rest of kernels that are to be kept in the FPGA. Finally, the average preemption overhead observed is 1.66% for one RR with standard deviation 2.60%, and 4.04% for two RRs with a standard deviation of 7.16%. The deviation is high due to a overhead peak of 23.40% for busy rate of arrival at size \(200\times 200\). This indicates that this technique might not be interesting for short tasks whose execution time is comparable to the reconfiguration time.

Throughput for 30 tasks. 1 RR (first row) and 2 RRs (second row). Non-preemptive (first column) and preemptive (second column).
7 Conclusions
This work presents a task-based abstraction for programming FPGAs that enables task preemption using DPR. We abstract the low-level details of the generation of a DPR capable system and provide a high-level API for simple management of kernel launch, data transfer and transparent book-keeping for context preemption. We show that our approach enhances flexibility by reducing the service time of urgent tasks thanks to the ability to swap tasks in and out. The overhead of preemptive vs. non-preemptive scheduling with DPR is 1.66% on average for one RR and 4.04% for two RRs. Finally, our simulations show significant performance gains over the traditional use of full reconfiguration.
Future work includes, in no particular order:
-
1.
Task migration between FPGA and other architectures e.g. GPU and CPU.
-
2.
Extension to data-center FPGAs e.g. as Xilinx Versal and Xilinx Alveo.
-
3.
Extension of the backend to leverage full reconfiguration to provide an accurate measure of the performance gain through the use of DPR.
-
4.
Reduction of the overhead of this technique with a custom ICAP controller, as Xilinx’s can only exploit up to 2.5% of the port bandwidth [11].
References
The OpenACC application programming interface. https://www.openacc.org/sites/default/files/inline-images/Specification/OpenACC-3.2-final.pdf. Accessed 19 May 2022
TOP500. https://www.top500.org/. Accessed 9 May 2022
Brown, N.: Exploring the acceleration of Nekbone on reconfigurable architectures (2020)
Moreton-Fernandez, A., et al.: Controllers: an abstraction to ease the use of hardware accelerators. Int. J. High Perf. Comput. Appl. 32(6), 838–853 (2018)
Vaishnav, A., et al.: Heterogeneous resource-elastic scheduling for CPU+ FPGA architectures. In: Proceedings of the 10th International Symposium on Highly-Efficient Accelerators and Reconfigurable Technologies, pp. 1–6 (2019)
Trott, C.R., et al.: Kokkos 3: programming model extensions for the exascale era. IEEE Trans. Parallel Distrib. Syst. 33(4), 805–817 (2022)
Rodriguez-Canal, G., Torres, Y., Andújar, F.J., Gonzalez-Escribano, A.: Efficient heterogeneous programming with FPGAs using the controller model. J. Supercomput. 77(12), 13995–14010 (2021). https://doi.org/10.1007/s11227-021-03792-7
Brown, N., et al.: It’s all about data movement: Optimising FPGA data access to boost performance. In: 2019 IEEE/ACM International Workshop on Heterogeneous High-performance Reconfigurable Computing (H2RC), pp. 1–10. IEEE (2019)
Munshi, A.: The OpenCL specification. In: 2009 IEEE Hot Chips 21 Symposium (HCS), pp. 1–314. IEEE (2009)
Brown, N.: PYNQ API: C API for PYNQ FPGA board. https://github.com/mesham/pynq_api (2019). Accessed 20 June 2021
Vipin, K., Fahmy, S.A.: FPGA dynamic and partial reconfiguration: a survey of architectures, methods, and applications. ACM Comput. Surv. (CSUR) 51(4), 1–39 (2018)
Xilinx. Vivado design user suite guide - dynamic function eXchange. https://bit.ly/3MEDZTI. Accessed 9 May 2022
Acknowledgements
The authors acknowledge EPCC at the University of Edinburgh and EPSRC who have funded this work and provided the FPGA compute resource. This research has been partially funded by Junta de Castilla y León - FEDER Grants, project PROPHET-2 (VA226P20).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2023 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Rodriguez-Canal, G., Brown, N., Torres, Y., Gonzalez-Escribano, A. (2023). Programming Abstractions for Preemptive Scheduling on FPGAs Using Partial Reconfiguration. In: Singer, J., Elkhatib, Y., Blanco Heras, D., Diehl, P., Brown, N., Ilic, A. (eds) Euro-Par 2022: Parallel Processing Workshops. Euro-Par 2022. Lecture Notes in Computer Science, vol 13835. Springer, Cham. https://doi.org/10.1007/978-3-031-31209-0_10
Download citation
DOI: https://doi.org/10.1007/978-3-031-31209-0_10
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-31208-3
Online ISBN: 978-3-031-31209-0
eBook Packages: Computer ScienceComputer Science (R0)