
Abstract
Medical Vision Question Answer (VQA) is a combination of medical artificial intelligence and visual question answering, which is a complex multimodal task. The purpose is to obtain accurate answers based on images and questions to assist patients in understanding their personal situations as well as to provide doctors with decision-making options. Although CV and NLP have driven great progress in medical VQA, challenges still exist in medical VQA due to the characteristics of the medical domain. First, the use of a meta-learning model for image feature extraction can accelerate the convergence of medical VQA models, but it will contain different degrees of noise, which will degrade the effectiveness of feature fusion in medical VQA, thereby affecting the accuracy of the model. Second, the currently existing medical VQA methods only mine the relation between medical images and questions from a single granularity or focus on the relation within the question, which leads to an inability to comprehensively understand the relation between medical images and questions. Thus, we propose a novel multi-granularity medical VQA model. On the one hand, we apply multiple meta-learning models and a convolutional denoising autoencoder for image feature extraction, and then optimize it using an attention mechanism. On the other hand, we propose to represent the question features at three granularities of words, phrases, and sentences, while a keyword filtering module is proposed to obtain keywords from word granularity, and then the stacked attention module with different granularities is used to fuse the question features with the image features to mine the relation from multiple granularities. Experimental results on the VQA-RAD dataset demonstrate that the proposed method outperforms the currently existing meta-learning medical VQA methods, with an overall accuracy improvement of 1.8% compared to MMQ, and it has more advantages for long questions.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

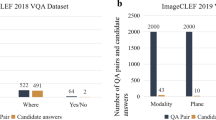
Keywords
1 Introduction
Medical VQA focuses on answering questions related to the content of a given medical image by fusing the image with question information. In practice, it has a wide range of applications, such as improving patient engagement [12] and supporting clinical decision-making [7]; therefore, it has recently become a popular topic in the medical field. The Medical VQA model includes an image feature extraction module, a question feature extraction module, a feature fusion module, and an answer prediction module, each of which affects the performance of the model to varying degrees.
Image feature extraction is the basic module of the Medical VQA model, and it affects the convergence speed and accuracy of the model. Pretraining VGG [19] or ResNet [8] feature extraction networks on natural image datasets such as ImageNet [18] and then fine-tuning the medical VQA model on the medical VQA data can alleviate the training difficulties caused by the scarcity of medical data; however, the above image feature extraction approach is not effective when used in medical VQA models [1, 21] due to the content differences between medical and natural images. A mixture of enhanced visual features (MEVF) [16] combined model-agnostic meta-learning (MAML) [3] and convolutional denoising autoencoder (CDAE) [15] to extract image features. MAML can be quickly adapted to new tasks to accelerate model convergence, and CDAE is robust to noisy images. Leveraging the advantages of both, MEVF improves the accuracy of medical VQA tasks; however, the dataset used to train MAML by manual annotation may have noisy labels. Multiple meta-model quantifying (MMQ) [2] proposed a multiple meta-model quantifying method that is designed to increase meta-data by auto-annotation, deal with noisy labels, and output multiple meta-learning models that provide robust features for medical VQA. The image features extracted by different meta-learning models should have different importance, but MMQ views each image feature equivalently and applies it to the medical VQA directly. In addition, medical images such as MRI, CT, and X-ray may carry noise during acquisition and transmission, which results in image features that also contain varying degrees of noise, further affecting the accuracy of the medical VQA model.
Solving the semantic gap between images and text is the key to multimodal tasks; thus, image and question feature fusion is the core module of the medical VQA task. SAN [22] proposed a stacked attention approach to fuse image and question features. The question features are used as query vectors to find the regions in the image that are relevant to the answer, and the answer is derived by multiple reasoning. BAN [10] finds bilinear attention distributions to utilize given image and question information seamlessly. The above feature fusion methods improve the performance of general VQA tasks and are also widely used in medical VQA. However, due to the high similarity of human tissues themselves, medical images of the same part and the same body state are very similar, which makes medical image processing more difficult than natural images and thus requires stronger inference ability. Directly applying the above general VQA model to medical VQA, only a single granularity of fusing image features with question features [2, 5, 16] leads to a lack of inference ability and unsatisfactory performance.
To address the above problems, we propose the Multi-granularity Feature Fusion Network(M2FNet), which consists of an image feature extraction module, a multi-granularity question feature extraction module, an attention-based multi-granularity fusion module, and an answer prediction module. The image feature extraction module uses multiple meta-learning models to obtain image features understood from different perspectives and introduces the squeeze-and-excitation block (SE) [9] to assign weights to the image features extracted to suppress redundant information and emphasize important information while using CDAE to obtain the denoised high-level semantic features. The image feature extraction module obtains image features with robustness by combining the meta-learning models, CDAE and SE. The multi-granularity question feature extraction module represents question features at three granularities: word, phrase, and sentences. Further keywords are obtained from word granularity using the keyword filtering module. The attention-based multi-granularity fusion module adopts three different granularity stacked attention modules to fuse question features with image features to achieve multi-granularity mining of the relation between images and questions. The answer prediction module combines three granularities of fused features to answer questions related to medical images more accurately.
2 Related Work
2.1 Vision Question Answer
VQA is a complex multimodal task and the fusion of image and question features is the core of the VQA task. Early works applied simple concatenation, summation, or pixel-level multiplication for cross-modal feature fusion. Bilinear Fusion [6] has been proposed to apply bilinear pooling to fuse the features of two modalities to mine the high-level semantic relation between modalities. To overcome the computationally intensive problem of bilinear pooling, [4] embeds image and question features into a high-dimensional space and then performs convolution operations in Fourier space to fuse image and question information, improving performance with fewer parameters. Multimodal pooling is an important technique for fusing image features and question features, and there are some other works apply this technique, such as [11, 24, 25]. Since attention mechanisms are widely used in the field of CV and NLP, SAN [22] proposed a stacked attention approach to fuse image and question features; it treats the question features as query vectors to find the regions in the image that are relevant to the answer and arrive at the answer by multiple queries. Attention-based methods are also available in [5, 14], and [23] further explores the application of attention in VQA by fusing features using a transformer [20]. The attention mechanism has led to the further development of VQA. However, currently existing medical VQA methods only mine the relation between medical images and questions at a single granularity [2, 5, 16] or focus on the relation within the question, failing to capture content in the images from multiple granularities to comprehensively understand the relation between medical images and questions.
2.2 Meta Learning
MAML [3] proposed meta-learning methods to enable rapid convergence of the model in new tasks using only small datasets. Due to data scarcity in medical VQA tasks, feature extractors pretrained with natural images are usually required to optimize the training process; however, the content differences between medical and natural images lead to unsatisfactory results of such methods. Therefore, MEVF [16] proposed a combination of MAML and CDAE; CDAE is an encoder-decoder architecture trained with unlabeled data, which improves the robustness of the model by adding noise to the image data, allowing the encoder to extract valid information from the noisy image for downstream tasks. It takes advantage of meta-learning and CDAE techniques to achieve better performance on small datasets for medical VQA, proving that meta-learning and CDAE are effective in medical VQA. MMQ [2] proposed a multiple meta-model quantifying method that is designed to increase meta-data by auto-annotation, deal with noisy labels, and output multiple meta-learning models that provide robust features for medical VQA. Although the MMQ meta-learning approach can alleviate the training difficulties associated with data scarcity in medical VQA, it views equally the image features extracted by multiple meta-learning models, and the extracted features may carry varying degrees of noise.
3 Method
3.1 Overview
In this paper, we propose the M2FNet model for medical VQA tasks, which takes images as the core and mines the relation between images and questions at multiple granularities. Figure 1 illustrates an overview of our framework.

The framework of our proposed M2FNet.
The M2FNet processes images and questions through two branches: image feature extraction and multi-granularity question feature extraction, and then the output of the branches is fused by the attention-based multi-granularity fusion module to obtain fused features for answer prediction.Image feature extraction consists of CDAE’s encoder, n meta-learning models, and the SE module. The images are passed through n meta-learning models to obtain n feature maps \(V_{1} \sim V_{n}\) with robustness, which are input to the SE module to learn the importance of each channel after concatenation and then combine the importance weights with the feature maps to obtain the meta-learning feature map \(V_{meta }\), while the CDAE’s encoder extracts high-level semantic features \(V_{ a }\). The final image features V are obtained by concatenating \(V_{meta }\) and \(V_{ a }\). To extract question features from multiple granularities, we take the word embedding vector \(Q_{ a }\) as the input of LSTM, Phrase Embedding, and Keywords Filtering for encoding questions to obtain sentence-granularity, phrase-granularity, and word-granularity features \(Q_{s }\), \(Q_{p }\), and \(Q_{w }\), respectively. The question features \(Q_{s }\), \(Q_{p }\), and \(Q_{w }\) are input with the image features V to the attention-based multi-granularity fusion module consisting of SANs, SANp, and SANw to obtain the fused features \(Q_{s,a}\),\(Q_{p,a}\), \(Q_{w,a}\), achieving multiple granularities understanding of the relation between images and questions. Finally, the three fusion features are summed at the pixel level to jointly make answer predictions. The modules are described in detail as follows.
3.2 Image Feature Extraction
We propose combining multiple meta-learning models and CDAE to extract image features and introduce a SE module to optimize the feature extraction. The meta-learning model can be quickly applied to other tasks, achieving fast convergence even on small datasets of medical VQA. CDAE is robust to noisy images and still extracts high-level semantic features from medical images such as MRI, CT, and X-ray that may carry noise. The SE module learns the importance weights of the input features for each channel, emphasizing important information and suppressing redundant information, we apply it to assign weights to the image features obtained from different meta-learning models to maximize the effect of each image feature. There are n meta-learning models in Fig. 1, and each meta-learning model consists of four 3*3 convolutional layers and a mean pooling layer. N image features \(V_{i }\) with robustness are obtained by feeding images to n meta-learning models,\(i\in (1,n)\), and then are concatenated at the channel level to obtain \(V_{meta }^{c}\). The pink part represents the SE module, including a pooling layer and two fully connected layers. \(V_{meta }^{c}\) is input to the SE module, the global feature representation of each channel is obtained by the pooling layer, and then the importance weight of each channel is learned by the fully connected layer, which is used to adjust the feature map to obtain \(V_{meta}\). CDAE includes an encoder and a decoder. The encoder extracts the high-level semantic features of the image, which consists of three 3*3 convolutional layers, each of which is followed by a max-pooling layer. The decoder consisting of two 3*3 deconvolutions and two 3*3 convolutions reconstructs the image using the high-level semantic features.
We extract the image features \(V_{a }\) using the encoder of the pretrained CDAE and then concatenate \(V_{meta }\) and \(V_{a}\) to obtain the final image feature V. The above process is expressed as the following equation.

Phrase feature extraction module.
3.3 Multi-granularity Question Feature Extraction
When people understand complex statements, they often read multiple times to understand the semantics precisely. Based on human thinking patterns, this paper argues that semantic information should also be obtained at multiple granularities in complex medical VQA tasks and therefore proposes a multi-granularity question feature extraction module to represent question features at three granularities of words, phrases, and sentences. The input question is first unified to a 12-word sentence, which is zero-padded if the length of the question is less than 12. Then, each word in the question is transformed into a vector using 600-D GloVe [17], which results in a vector \(Q_{a} \in R^{n \times d_{w}}\), where \(n=12\) denotes the number of words and \(d_{w }=600\) denotes the word dimension. Furthermore, we pass the vector \(Q_{a}\) through keyword filtering (KF) to obtain keywords pointing to the pathological regions and properties, which results in word-granularity question features \(Q_{w} \in R^{n \times d_{w}}\). The filter is the intersection of two lists, one of which contains words in the question of the medical VQA dataset, and the other is a stop-words list based on NLTK [13]. Input \(Q_{a}\) into the phrase feature extraction module to obtain the phrase-granularity question feature vector \(Q_{p} \in R^{d_{p}}\), with \(d_{p }=1024\) denoting the dimension of the question feature. The phrase feature extraction module is shown in Fig. 2, which consists of three 1-D convolutions with different kernel sizes to output feature vectors \(Q_{p}^{unigram }\), \(Q_{p}^{bigram }\),and \(Q_{p}^{trigram }\), and then the phrase-granularity question feature vector \(Q_{p}\) is obtained after concatenation and max-pooling. The above process is expressed as the following formulas.
We apply the 1024-D LSTM on the \(Q_{a }\) vector to obtain the sentence-granularity question features \(Q_{S} \in R^{d_{s}}\), \(d_{s }=1024\). Through the above process, the multi-granularity question feature extraction module outputs three question feature vectors of sentence-granularity, phrase-granularity and word-granularity.

Attention-Based multi-granularity fusion module: The left and right sides represent two executions of query and fusion operations, and the three layers of depth represent SANi of different granularities
3.4 Attention-Based Multi-granularity Fusion Module
In a complex task such as medical VQA, capturing key regions in an image based on semantic information at different granularities to obtain fused features that jointly participate in answer prediction helps improve model performance. In this paper, we propose an attention-based multi-granularity fusion module that fuses question features with image features at different granularities using three SANi modules, where \(i\in (w,p,s)\), V and \(Q_{i }\) are the inputs to SANi, and the question feature vector \(Q_{i }\) queries image feature vector V to obtain attention vector \(Att_{i}^{1}\). The result is combined with \(Q_{i }\) to obtain \(Q_{\tilde{\imath }}\) as a new question feature vector querying the image feature V again, resulting in a high-level attention \(Att_{i}^{2}\). High-level attention will give a more accurate attention distribution to focus on the region related to the answer, fuse it with the current question feature \(Q_{\tilde{\imath }}\),and finally output the fusion feature \(Q_{i,a}\). The three granularity fused features predict the answer together. Figure 3 shows the architecture of the fusion module. The attention-based multi-granularity fusion module enables a comprehensive understanding of the relation between images and questions to achieve deep inference and improve model performance.
3.5 Answer Prediction and Model Training
Answer Prediction. In this paper, we treat the medical VQA task as a classification task based on answer sets. We use a 2-layer MLP as a classifier to predict the category scores and obtain the final answers. The fused features \(Q_{w,a}\), \(Q_{p,a}\), and \(Q_{s,a}\) at the word, phrase, and sentence granularity output by the fusion module are first summed at the pixel level and then fed into the classifier, resulting in category score prediction \(\hat{y}\), The classifier is trained using a cross-entropy loss function. The prediction scores are calculated as follows.
Model Training. We first initialize the network parameters using the pretrained meta-learning models and CDAE weights and then optimize the model on the medical VQA data, the training data used by different meta-learning models are cross and different. To enhance the robustness of the model, we also introduce a CDAE image reconstruction task to assist in the optimization of the medical VQA task and train the model using a multi-task loss function. The loss function L consists of two terms. \(L_{v q a}\) is the cross-entropy loss for the medical VQA task, and \(L_{a}\) is the loss of the reconstruction task using MSE loss, with the following equations.
where \(\alpha \) is a hyperparameter for balancing the two loss terms, \(\hat{y}\) and y denote the predicted score and ground truth of the answer, \(\hat{x}\) denotes the reconstructed image and \(x_{o}\) is the original image.
4 Experiments
4.1 Datasets and Metrics
Datasets. We evaluate the proposed M2FNet on the VQA-RAD dataset, which is a manually constructed radiology dataset, and the image set contains three parts: head, chest and abdomen, MRI and CT for head, X-ray for chest and CT for abdomen, with 315 images in total. There are 3515 question-answer pairs, and each image corresponds to 10 questions on average, of which 3064 are used as the training set and 315 as the test set. The question-answer pairs can be divided into open questions and closed questions according to the responses, where open questions are those where the responses are ’Yes/No’ or give options, and closed questions are those where the responses are free-form questions. The question-answer pairs can be categorized into 11 types, such as modal, organ, and abnormal, according to the type of question. There are 458 answer types in the dataset, and our model treats medical VQA as a classification task based on the answer set. Although this dataset is small compared to other automatically constructed datasets, it is more representative of how one should answer questions as an AI radiologist due to its manual construction.
Metrics. The M2FNet is a classification-based medical VQA model, so the accuracy is used as a metric to evaluate the model on the VQA-RAD dataset. The accuracy rate is the percentage of the number of correctly predicted samples to the total number of samples, and the formula is as follows.
4.2 Experimental Setup
Our model is implemented with PyTorch, and we conduct experiments on a GTX 1080ti GPU. The model is trained with a batch size of 32 and a learning rate of 0.001 using the Adamax optimizer for 40 epochs. The hyperparameter \(\alpha \) in the loss function is set to 0.001.
4.3 Model Comparisons
The M2FNet proposed in this paper is compared with four existing meta-learning methods MAML, MEVF, MMQ and MMQ+MEVF. MAML uses a meta-learning model to initialize the weights of the image feature extraction network for fast adaptation to medical VQA tasks, which enables medical VQA models to achieve better performance even with small datasets. MEVF combines meta-learning models with CDAE to extract image features and achieves further performance improvements. MMQ proposes to mine the metadata of the dataset itself, using the metadata to train the meta-learning model, and continuously updating the training data. It iterates this process to output multiple meta-learning models that provide robust features for medical VQA. To achieve better performance, MMQ is combined with MEVF.
As shown in Table 1, M2FNet achieves the highest accuracy on the dataset VQA-RAD compared to the meta-learning methods in the table. Compared with the advanced meta-learning method MMQ+MEVF, the overall accuracy and close-ended accuracy improve by 0.6% and 1.1%, respectively.
4.4 Ablation Study
Effectiveness of SE and KF. We evaluate the effectiveness of SE and KF in our proposed M2FNet by performing an ablation study. In Table 2, ‘baseline’ represents the base model proposed in this paper, ‘baseline+SE’ indicates the model after introducing the SE module, and ‘baseline+SE+KF’ indicates the introduction of the SE and KF modules, which is the M2FNet model proposed in this paper.
As seen from Table 2, the overall accuracy improves by 0.7% with close-ended and open-ended accuracy increasing by 0.5% and 0.8% after the introduction of the SE module, and further, the overall accuracy achieves a large improvement of 2.6% after the introduction of the KF module. The results illustrate the effectiveness of SE and KF in our model.
Scheme of Using the SE Module. In this paper, we propose to optimize feature extraction with the SE module. To maximize the effect of the SE module, we compare the effect of the SE module acting on m meta-learning models and n meta-learning models. In Table 3, ‘n’ refers to the MMQ+MEVF method directly using n meta-learning models for image feature extraction, ‘m+SE’ means that the image features are extracted using the unfiltered m meta-learning models and the SE module acts on the m feature maps, while ‘n+SE’ utilizes the filtered n meta-learning models.
Table 3 shows that the accuracy of ‘n+SE’ is 0.3% higher than that of ‘m+SE’, which indicates that the best performance is obtained by adding the SE module to the n meta-learning model; therefore, it is the design approach ultimately adopted for our model. At the same time, the accuracy of ‘n+SE’ is 0.6% higher than that of ‘n’, which again shows the effectiveness of the SE module.
4.5 Qualitative Evaluation
The visualization experiment in Table 4 compares the effect of our proposed M2FNet and MMQ+MEVF based on the prediction confidence scores of the Top 5 answers. The table covers three types of medical images with different modalities and different organs, and the red and blue bars represent the confidence scores of correct and incorrect answers, respectively. The first three data show that the M2FNet model is more accurate in predicting answers compared to MMQ+MEVF. The fourth data shows that the M2FNet model has more advantages in dealing with long questions. This indicates that the proposed multi-granularity question feature extraction module can effectively obtain the semantic information of complex questions, thus enhancing the effect of the fusion module, which effectively improves the accuracy of the answer prediction of the medical VQA model.
5 Conclusion
In this paper, we propose a novel neural network model with multiple granularities to mine the relation between images and questions for the medical VQA task. In addition, we introduce the SE module to optimize the image feature extraction process. To capture the key regions related to the answer in the image, a KF module is proposed to further fine-grain the question features of word granularity. The above enables multi-granularity inference and thus improves the model performance. Extensive experimental results on the VQA-RAD dataset show that the M2FNet model proposed in this paper outperforms the currently existing meta-learning medical VQA model. The visualization results of qualitative analyses intuitively reflect the performance of M2FNet while indicating that M2FNet is more advantageous in dealing with long questions.
References
Allaouzi, I., Ahmed, M.B., Benamrou, B.: An encoder-decoder model for visual question answering in the medical domain. In: CLEF (Working Notes) (2019)
Do, T., Nguyen, B.X., Tjiputra, E., Tran, M., Tran, Q.D., Nguyen, A.: Multiple meta-model quantifying for medical visual question answering. In: de Bruijne, M., et al. (eds.) MICCAI 2021. LNCS, vol. 12905, pp. 64–74. Springer, Cham (2021). https://doi.org/10.1007/978-3-030-87240-3_7
Finn, C., Abbeel, P., Levine, S.: Model-agnostic meta-learning for fast adaptation of deep networks. In: International Conference on Machine Learning, pp. 1126–1135. PMLR (2017)
Fukui, A., Park, D.H., Yang, D., Rohrbach, A., Darrell, T., Rohrbach, M.: Multimodal compact bilinear pooling for visual question answering and visual grounding. arXiv preprint arXiv:1606.01847 (2016)
Gao, P., et al.: Dynamic fusion with intra-and inter-modality attention flow for visual question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6639–6648 (2019)
Gao, Y., Beijbom, O., Zhang, N., Darrell, T.: Compact bilinear pooling. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 317–326 (2016)
Hasan, S.A., Ling, Y., Farri, O., Liu, J., Müller, H., Lungren, M.: Overview of imageclef 2018 medical domain visual question answering task. Technical Report 10–14 September 2018 (2018)
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141 (2018)
Kim, J.H., Jun, J., Zhang, B.T.: Bilinear attention networks. In: Advances in Neural Information Processing Systems, vol. 31 (2018)
Kim, J.H., et al.: Hadamard product for low-rank bilinear pooling. arXiv preprint arXiv:1610.04325 (2016)
Kovaleva, O., et al.: Towards visual dialog for radiology. In: Proceedings of the 19th SIGBioMed Workshop on Biomedical Language Processing.,pp. 60–69 (2020)
Loper, E., Bird, S.: Nltk: The natural language toolkit. arXiv preprint cs/0205028 (2002)
Lu, J., Yang, J., Batra, D., Parikh, D.: Hierarchical question-image co-attention for visual question answering. In: Advances in Neural Information Processing Systems, vol. 29 (2016)
Masci, J., Meier, U., Cireşan, D., Schmidhuber, J.: Stacked convolutional auto-encoders for hierarchical feature extraction. In: International conference on artificial neural networks. pp. 52–59. Springer, (2011)
Nguyen, B.D., Do, T.-T., Nguyen, B.X., Do, T., Tjiputra, E., Tran, Q.D.: Overcoming data limitation in medical visual question answering. In: Shen, D., Shen, D., et al. (eds.) MICCAI 2019. LNCS, vol. 11767, pp. 522–530. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-32251-9_57
Pennington, J., Socher, R., Manning, C.D.: Glove: global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), pp. 1532–1543 (2014)
Russakovsky, O., et al.: ImageNet large scale visual recognition challenge. Int. J. Comput. Vis. 115(3), 211–252 (2015)
Simonyan, K., Zisserman, A.: Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556 (2014)
Vaswani, A., et al.: Attention is all you need. In: Advances in Neural Information Processing Systems, vol. 30 (2017)
Yan, X., Li, L., Xie, C., Xiao, J., Gu, L.: Zhejiang university at ImageCLEF 2019 visual question answering in the medical domain. In: CLEF (Working Notes), vol. 85 (2019)
Yang, Z., He, X., Gao, J., Deng, L., Smola, A.: Stacked attention networks for image question answering. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 21–29 (2016)
Yu, Z., Yu, J., Cui, Y., Tao, D., Tian, Q.: Deep modular co-attention networks for visual question answering. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pp. 6281–6290 (2019)
Yu, Z., Yu, J., Fan, J., Tao, D.: Multi-modal factorized bilinear pooling with co-attention learning for visual question answering. In: Proceedings of the IEEE International Conference on Computer Vision, pp. 1821–1830 (2017)
Yu, Z., Yu, J., Xiang, C., Fan, J., Tao, D.: Beyond bilinear: generalized multimodal factorized high-order pooling for visual question answering. IEEE Trans. Neural Netw. Learn. Syst. 29(12), 5947–5959 (2018)
Acknowledgements
This work is supported by the National Natural Science Foundation of China under (Grant No.62072135), Innovative Research Foundation of Ship General Performance (26622211), Ningxia Natural Science Foundation Project (2022AAC03346), Fundamental Research project (No. JCKY2020210B019), Fundamental Research Funds for the Central Universities (3072022TS0604).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2022 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Wang, H., Pan, H., Zhang, K., He, S., Chen, C. (2022). M2FNet: Multi-granularity Feature Fusion Network for Medical Visual Question Answering. In: Khanna, S., Cao, J., Bai, Q., Xu, G. (eds) PRICAI 2022: Trends in Artificial Intelligence. PRICAI 2022. Lecture Notes in Computer Science, vol 13630. Springer, Cham. https://doi.org/10.1007/978-3-031-20865-2_11
Download citation
DOI: https://doi.org/10.1007/978-3-031-20865-2_11
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-031-20864-5
Online ISBN: 978-3-031-20865-2
eBook Packages: Computer ScienceComputer Science (R0)