
Abstract
Selecting a potential reviewer to review a manuscript, submitted at a conference is a crucial task for the quality of a peer-review process that ultimately determines the success and impact of any conference. The approach adopted to find the potential reviewer needs to be consistent with its decision of allocation. In this work, we propose a framework for evaluating the reliability of different NLP approaches that are implemented for the match-making process. We bring various algorithmic approaches from different paradigms and an existing system Erie, implemented in IEEE INFOCOM conference, on a common platform to study their consistency of predicting the set of the potential reviewers, for a given manuscript. The consistency analysis has been performed over an actual multi-track conference organized in 2019. We conclude that Contextual Neural Topic Modeling (CNTM) with a balanced combinatorial optimization technique showed better consistency, among all the approaches we choose to study.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The peer-review process in a conference is the cornerstone in the current academic and research field which is majorly regarded as an important part of scholarly communications. The selection of an expert reviewer plays a crucial role in the peer-review process. A reviewer, while reviewing, needs to focus on a) technical quality of the work b) reproducibility of the work c) impact of paper over the community, and d) extent of the work to be original and novel. For this, the reviewer assigned to the manuscript must be an expert in the domain of the submitted manuscript.
A framework is required to be developed that scrutinizes all the allocations of the expert reviewers to the submitted manuscripts. This work is not an attempt to propose a better reviewer-manuscript match-making system but rather to propose a framework for evaluating the reliability of match-making algorithms. This framework is agnostic to any conference, of whether the actual (semi)-manual allocation is perfect or not.
Certain attempts have been made to develop automated systems like TPMS [9], GRAPE [10], SubSift [11], Erie [20] to find a perfect match. The authors [28] have generalized the range of approaches for matching a reviewer with the manuscript. The authors in [12, 14, 16, 17, 24] have considered keywords as a matching parameter. The authors in [4, 15, 18, 26] have used Latent Dirichlet Allocation (LDA) approach while in [27], apart from LDA, authors also considered the concept of freshness for understanding the change in the research interest of a reviewer with time. Even the bibliography-based matching was been proposed by the authors in [21]. The authors in [22] worked on expertise, authority and diversity parameters while the authors in [23] considered a set of references and pedagogical facets. Hiepar-MLC approach [31] used a two-level bidirectional GRU with an attention mechanism to capture word-sentence-document information. To the best of our knowledge, any kind of consistency analysis of the implemented approaches in the context of reviewer-manuscript matching has not been performed yet.
By consistency, we here show that, if the approach agrees with a certain set of reviewers by providing a higher similarity score, then it should provide a significantly lower similarity score to the other set of reviewers, proving the system to be less ambivalent. A detailed explanation of consistency is given in Sect. 2. We attempt to bring different paradigms together to perform the analysis over the actual dataset provided by the conference organized in 2019. Over the analysis we performed, Contextual Neural Topic Modeling (CNTM) approach provided us with more stable and reliable results giving a new direction to explore CNTM in a more further detailed version that can be used in developing a reviewer-manuscript match-making system.
2 Problem Formulation
The reviewer-manuscript match-making process is accomplished majorly by imposing two constraints: a) workload constraint and b) review coverage constraint. Workload constraint is the maximum number of manuscripts that can be allocated to an individual reviewer to review, while review coverage constraint deals with the number of reviews required per manuscript to fulfill the peer-review process.
Let’s consider \(\mathcal {R}=\{r^{(i)}\}_{i=1}^{n}\) be the set of n-reviewers, \(\mathcal {M}=\{m^{(j)}\}_{j=1}^{m}\) be the set of m-manuscripts submitted to review. Let \([\varPi ]^{n}\) denote the profiles of n reviewers defined as \([\varPi ]^{n}=(\pi ^{(1)},\pi ^{(2)},\dots \pi ^{(n)})\). Here, profile of reviewers represents the expertise of reviewers. The process of formulation of profiles is mentioned in Sect. 4.1. We define sigma (\(\sigma _{rt}\)) as the match-making similarity function applied over the reviewer’s and manuscript profile, to obtain the similarity score matrix in-between the reviewers and manuscripts, using any match-making representational technique (let’s say rt). A similarity tensor S can be obtained as:
\(S_{ij} \in [0,1]^{nxm}\) be the similarity matrix between the reviewer and manuscript. Higher the similarity score, more inclined the reviewer’s expertise to the manuscript’s theme. Let \(\{\mathcal {R}^{(ar)}\}\) be the set of K-allocated reviewers to a particular manuscript and \(\{\mathcal {R}^{(nar)}\}\) be the set of non-allocated reviewers. Here, \(\{\mathcal {R}^{(nar)}\}=\mathcal {R} - \{\mathcal {R}^{(ar)}\}\).

Example of consistency for an algorithmic approach, selecting a set of reviewers out of the global pool of reviewers who signed up for the review process
It is necessary to determine the consistency of the approach adopted to calculate the similarity. By consistency, we mean the agreement of any match-making algorithmic approach to a certain set of reviewers by providing a higher similarity score, while it should disagree with the remaining set of the reviewers by providing a significantly lower similarity score. We define a term, here, a degree of consistency, denoted as \(\varDelta \), that shows the consistency in the decision of predicting the reviewers by a particular algorithm. Figure 1 shows the set of reviewers predicted by any match-making algorithm to review a particular manuscript out of the global pool of the reviewers who actually signed up for the review process. The degree of consistency can be defined as, the absolute difference in the average similarity score of the predicted reviewers and the average similarity score of the remaining set of reviewers.
Here, \(AS_{ar}\) is the average similarity score of allocated reviewers, while \(AS_{nar}\) is the average similarity score of non-allocated reviewers. \(\varDelta \) represents the degree of consistency. More the value of \(\varDelta \), more consistent the algorithm is, with its decision of predicting the reviewers.
3 Conference Dataset Description
The Technical Program Committee Chair of the “MultiTrack Conf”Footnote 1 conference provided us with the complete data of a) all submitted manuscripts, b) the full list of reviewers with their affiliations (which we call Global pool), c) track-wise list of reviewers (which we call Track pool), and d) manuscripts allocated to a set of reviewers (which we call Original allocation). “MultiTrack Conf” was an engineering domain multi-track conference organized in 2019. Table 1 gives a summary of the conference data.
4 Methodologies Implemented and Result Analysis
This section includes various representation approaches that have been used for the match-making process. This section also focuses on the experimental setup and the evaluation method that has been undertaken to evaluate the consistency of different approaches.
4.1 Experimental Setup
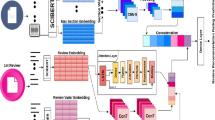
The first step is to create profiles of the manuscripts and the reviewers. From the reviewers’ names and affiliation, the publications title and the publication years are extracted using Orcid [1]. Using the publication details, the DOI number is extracted using Crossref [3]. Finally, the abstracts of the papers are extracted using Semantic Scholar [2]. Publication details of some reviewers are not available in Orcid, hence their abstracts are extracted by web scraping.
In order to build the reviewer’s profile, we hypothesize that the past 5 years or recent 20 papers (which we empirically derive from the publication frequency of reviewers in our dataset) are an indicator of the research domain of operation/interests of the reviewer. Hence, for each reviewer, publications of last 5 years or recent 20 publications, whichever was earlier, are profiled. The title and abstract of the publications collectively formed the reviewer’s profile. The title and abstract provided by the conference, are used to build the manuscript’s profile. From the generalized structural property of the research papers, it is evident that the title and abstract reflect the core theme of the entire paper.
Before applying any match-making algorithm, a pre-processing task involving the removal of English stopwords and research stopwords was carried out. The research stopwords like author, efficiency, proposal, study, etc. are the set of words which are frequently repeated in the publications. They generally, do not convey sufficient information as a standalone entity.

The match-making process between the reviewer and manuscript is mentioned in Algorithm 1. During each allocation, the reviewer workload and manuscript coverage constraints are taken into consideration. The balanced optimized Hungarian approach [19] is adopted for the assignment process. The constraint pair \((\mu ,\lambda )\) is taken as (6, 3). The similarity matrix S between reviewer and manuscript can be obtained using different approaches mentioned in Sect. 4.3.
4.2 Evaluation Method
To evaluate the approaches, top-3 reviewers are assigned to each of the submitted manuscripts using Algorithm 1. This allocation is compared with the original allocation done by the track chair. Three other modes of allocation are also done to study the consistency of approaches. These modes include the allocation to the reviewers among the global pool, which we call here as global pool allocation. The allocation was also studied by restricting the reviewers to the track they have selected, which we call as track-based reviewer allocation. The third mode of allocation includes the allocation of a particular manuscript among the set of reviewers who were actually not being allocated that particular manuscript to review, which we call it as global pool minus original allocation. Let \(AS_{oa}\) be the average similarity score of original allocated reviewers, while \(AS_{goa}\) be the average similarity score of global pool minus original allocated reviewers. The Eq. 1 for the degree of consistency can now be moulded as:
4.3 Methodologies Description and Implementation
This subsection includes discussion of representational paradigms of queries (manuscripts) and targets (reviewers), along with their implementation to obtain the similarity between the reviewer and manuscript. We have implemented various approaches that includes Statistical approach based Keyword extraction methods like TextRank [25], RAKE [30] and YAKE [7], probabilistic topic modeling approach like Latent Dirichlet Allocation (LDA) [6], neural topic modeling approaches like Contextual Neural Topic Modeling (CNTM) [5] and BERTopic [13], Transformer based embedding approaches like Universal Sentence Encoder (USE) [8] and Sentence BERT (SBERT) [29]. We also observed the consistency over the existing system Erie [20] implemented in IEEE INFOCOM conference. Table 2 shows the description of approaches with their implementations, to obtain the similarity between the reviewers and manuscripts.
4.4 Result Analysis
Using the approaches mentioned in Sect. 4.3, the similarity between the reviewer and manuscript has been obtained. Now, to calculate the consistency of each of these approaches, the degree of consistency (\(\varDelta \)) is been computed using Eq. 2. Figure 2 is the comparison graph showing the consistency of different approaches and existing system Erie over the original allocation and the three other modes of allocation of reviewers. With the perspective of the degree of consistency \((\varDelta )\), it can be seen from the Fig. 2 that CNTM using word embedding variant shows better consistency among other approaches.

Comparison chart of consistency in terms of similarity score with the delta differential (\(\varDelta \)) as a measure of consistency
Keywords are the important facets of any paper. Authors tend to provide very specific yet peripheral keywords (e.g. Adam optimizer) or the broader category of keywords (e.g. Artificial intelligence). It may not serve a good idea to rely only on author-tagged keywords. Hence, a technique like keyword extraction is adopted to extract the core concepts of the paper. It can be observed that these approaches showed consistency with low delta differential value. Keywords based matching doesn’t consider semantically relevant concepts like plagiarism and copy as similar ones. So, we decided to introduce transformer-based contextual embedding in the representation to study their consistency. They showed higher similarity agreements but have lower delta differential component.
A publication is a collection of (latent) topics representing certain themes. So, we analyzed a topic modeling approach like LDA to study consistency. This approach clustered topics based on the representing words, but the issue of semantic relevance still persists. So, we decided to introduce and test the contextual embedding over the topic modeling approach like CNTM, where the semantically relevant words were classified in the same topic cluster. For instance, biological cell and electrolytic cell, despite having common word cell, would fall in different clusters representing biological/medical topic and in electronics domain respectively. Variants of CNTM are also applied to study their consistency. The consistency analysis is also performed over the existing reviewer assignment system, Erie implemented in the IEEE INFOCOM conference. As seen in Fig. 2, the CNTM model using word embeddings proved to have better consistency than any other approaches that we have considered in this study.
5 Conclusion and Future Work
We bring various algorithmic approaches from different paradigms and an existing system Eire, on a common platform, to study a framework of consistency, in evaluating match-making approaches. From the analysis performed, it can be established that the reviewer-manuscript match-making system based on Contextual Neural Topic Modelling (CNTM) using Word Embedding approach may result in a better match, as it directly considers SBERT embeddings used in the model. In the future, we plan to develop a match-making system considering Conflict of Interests (COIs), with sentiment analysis performed over the reviews provided by the reviewers. This will help in identifying the detailed quality reviews. We would like to extend the study of consistency over the full text of publications. We plan to develop a match-making system that may reduce the burden over the TPCs and thus promising a better quality of peer-review process in the conference.
Notes
- 1.
Due to the data privacy and confidentiality conditions, the original conference’s name is not revealed.
References
Orcid. https://orcid.org/. Accessed 14 July 2021
Semantic scholar \(|\) AI-powered research tool. https://www.semanticscholar.org/. Accessed 14 July 2021
You are crossref - crossref. https://www.crossref.org/. Accessed 14 July 2021
An automated conflict of interest based greedy approach for conference paper assignment system. J. Informetr. 14(2), 101022 (2020). https://doi.org/10.1016/j.joi.2020.101022. https://www.sciencedirect.com/science/article/pii/S1751157719301373
Bianchi, F., Terragni, S., Hovy, D.: Pre-training is a hot topic: contextualized document embeddings improve topic coherence. arXiv preprint arXiv:2004.03974 (2020)
Blei, D.M., Ng, A.Y., Jordan, M.I.: Latent Dirichlet allocation. J. Mach. Learn. Res. 3(null), 993–1022 (2003)
Campos, R., Mangaravite, V., Pasquali, A., Jorge, A., Nunes, C., Jatowt, A.: YAKE! Keyword extraction from single documents using multiple local features. Inf. Sci. 509, 257–289 (2020). https://doi.org/10.1016/j.ins.2019.09.013
Cer, D., et al.: Universal sentence encoder (2018)
Charlin, L., Zemel, R.: The Toronto paper matching system: an automated paper-reviewer assignment system (2013)
Di Mauro, N., Basile, T., Ferilli, S.: GRAPE: an expert review assignment component for scientific conference management systems, pp. 789–798, June 2005. https://doi.org/10.1007/11504894_109
Flach, P.A., et al.: Novel tools to streamline the conference review process: experiences from SIGKDD’09. SIGKDD Explor. Newsl. 11(2), 63–67 (2010). https://doi.org/10.1145/1809400.1809413
Goldsmith, J., Sloan, R.: The AI conference paper assignment problem. In: AAAI Workshop - Technical Report, January 2007
Grootendorst, M.: BERTopic: leveraging BERT and c-TF-IDF to create easily interpretable topics (2020). https://doi.org/10.5281/zenodo.4430182
Hartvigsen, D., Wei, J., Czuchlewski, R.: The conference paper-reviewer assignment problem*. Decis. Sci. 30, 865–876 (2007). https://doi.org/10.1111/j.1540-5915.1999.tb00910.x
Jin, J., Geng, Q., Zhao, Q., Zhang, L.: Integrating the trend of research interest for reviewer assignment. In: Proceedings of the 26th International Conference on World Wide Web Companion. WWW 2017 Companion, International World Wide Web Conferences Steering Committee, Republic and Canton of Geneva, CHE, pp. 1233–1241 (2017). https://doi.org/10.1145/3041021.3053053
Kalmukov, Y.: Architecture of a conference management system providing advanced paper assignment features. Int. J. Comput. Appl. 34, 51–59 (2011). https://doi.org/10.5120/4083-5888
Kalmukov, Y.: Describing papers and reviewers’ competences by taxonomy of keywords. Comput. Sci. Inf. Syst. 9, 763–789 (2012). https://doi.org/10.2298/CSIS110906012K
Kou, N.M., Leong Hou, U., Mamoulis, N., Gong, Z.: Weighted coverage based reviewer assignment. In: Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data, SIGMOD 2015, New York, NY, USA, pp. 2031–2046. Association for Computing Machinery (2015). https://doi.org/10.1145/2723372.2723727
Kuhn, H.W.: The Hungarian method for the assignment problem. Naval Res. Logist. Q. 2(1–2), 83–97 (1955)
Li, B., Hou, Y.T.: The new automated IEEE INFOCOM review assignment system. IEEE Netw. 30(5), 18–24 (2016). https://doi.org/10.1109/MNET.2016.7579022
Li, X., Watanabe, T.: Automatic paper-to-reviewer assignment, based on the matching degree of the reviewers. Procedia Comput. Sci. 22, 633–642 (2013). https://doi.org/10.1016/j.procs.2013.09.144. https://www.sciencedirect.com/science/article/pii/S187705091300937X. 17th International Conference in Knowledge Based and Intelligent Information and Engineering Systems - KES 2013
Liu, X., Suel, T., Memon, N.: A robust model for paper reviewer assignment. In: Proceedings of the 8th ACM Conference on Recommender Systems, RecSys 2014, New York, NY, USA, pp. 25–32. Association for Computing Machinery (2014). https://doi.org/10.1145/2645710.2645749
Medakene, A.N., Bouanane, K., Eddoud, M.A.: A new approach for computing the matching degree in the paper-to-reviewer assignment problem. In: 2019 International Conference on Theoretical and Applicative Aspects of Computer Science (ICTAACS), vol. 1, pp. 1–8 (2019). https://doi.org/10.1109/ICTAACS48474.2019.8988127
Merelo-Guervós, J.J., Castillo-Valdivieso, P., et al.: Conference paper assignment using a combined greedy/evolutionary algorithm. In: Yao, X. (ed.) PPSN 2004. LNCS, vol. 3242, pp. 602–611. Springer, Heidelberg (2004). https://doi.org/10.1007/978-3-540-30217-9_61
Mihalcea, R., Tarau, P.: TextRank: bringing order into text. In: EMNLP (2004)
Nguyen, J.: Knowledge aggregation in people recommender systems: matching skills to tasks (2019)
Peng, H., Hu, H., Wang, K., Wang, X.: Time-aware and topic-based reviewer assignment. In: Bao, Z., Trajcevski, G., Chang, L., Hua, W. (eds.) DASFAA 2017. LNCS, vol. 10179, pp. 145–157. Springer, Cham (2017). https://doi.org/10.1007/978-3-319-55705-2_11
Price, S., Flach, P.A.: Computational support for academic peer review: a perspective from artificial intelligence. Commun. ACM 60, 70–79 (2017)
Reimers, N., Gurevych, I.: Sentence-BERT: sentence embeddings using siamese BERT-networks (2019)
Rose, S., Engel, D., Cramer, N., Cowley, W.: Automatic keyword extraction from individual documents. Text Min. Appl. Theory 1, 1–20 (2010). https://doi.org/10.1002/9780470689646.ch1
Zhang, D., Zhao, S., Duan, Z., Chen, J., Zhang, Y., Tang, J.: A multi-label classification method using a hierarchical and transparent representation for paper-reviewer recommendation. ACM Trans. Inf. Syst. 38(1), February 2020. https://doi.org/10.1145/3361719
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this paper

Cite this paper
Kotak, N., Roy, A.K., Dasgupta, S., Ghosal, T. (2021). A Consistency Analysis of Different NLP Approaches for Reviewer-Manuscript Matchmaking. In: Ke, HR., Lee, C.S., Sugiyama, K. (eds) Towards Open and Trustworthy Digital Societies. ICADL 2021. Lecture Notes in Computer Science(), vol 13133. Springer, Cham. https://doi.org/10.1007/978-3-030-91669-5_22
Download citation
DOI: https://doi.org/10.1007/978-3-030-91669-5_22
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-91668-8
Online ISBN: 978-3-030-91669-5
eBook Packages: Computer ScienceComputer Science (R0)