
Abstract
Increasing memory bandwidth bottleneck, die cost, lower yields at scaled nodes and need for more compact and power efficient devices have led to sustained innovations in integration methodologies. While the semiconductor market has already started witnessing some of these in product forms, many other techniques are currently under investigation in both academia and industry. In this chapter, we explore a 2.5D integrated system where the interconnects are modelled in the form of coplanar microstrip lines. A model is developed to understand the behavior of these wireline structures and is used to study their signaling characteristics. Generally, the conventional NRZ signaling is used to transmit data. As an alternative, we explore a higher order modulation scheme, namely, PAM4. Through the simulation study, we demonstrate that PAM4 can provide up to 63% better energy efficiency and 27% higher bandwidth density than NRZ.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
The power, performance, area, and cost (PPAC) benefits of semiconductor-based electronic systems have traditionally been addressed via conventional scaling. With the slowing down of Moore’s Law-an empirical rule which predicted that the number of transistor densities doubles every two years, both the computing performance and the DRAM capacity have plateaued in the last couple of years as depicted in Fig. 1 [1]. The feature size which was once defined as the gate length (but no longer is) has shrunk and in the past few years, a node actually encompasses several consecutive technology generations and has been enabled by process optimizations and circuit redesign. The unstated assumption of Moore’s Law is that the die size remains unchanged so that doubling of the number of transistors will lead to doubling of performance. However, at nodes 10 nm and lower, this assumption fails to hold due to the yield issues and costs. The cost of the dies continues to increase at lower technology nodes indicating that increasing die size are not economically viable (Fig. 2 [2]), Fig. 3 [3].
Performance scaling can be achieved through solutions like heterogeneous integration where instead of fabricating large single die, multiple smaller dies will be tessellated. These smaller dies will communicate in order to achieve same functionality and achieve same performance as the single large die. This appears to address the two main issues of lower yield and higher manufacturing cost. But we need to make sure that the cost of “putting together” or integrating the smaller dies is reasonable and the connections between these dies will be as efficient as it were a single die in terms of speed and quality of the signals. We henceforth call these smaller dies as chiplets and is defined as any die which is integrated with such other dies (or chiplets).
Heterogeneous Integration can be defined as the assembly and packaging of multiple separately manufactured components onto a single chip in order to improve functionality and enhance operating characteristics. It allows for components of different functionalities, different process technologies (that may be incompatible otherwise), and many times separate manufacturers to operate as a single entity. It also offers ways to continue the use of dies that are not performance critical with high performance dies from newer generation.

(a) Uniprocessor Performance Scaling and (b) DRAM Capacity Scaling.
The idea of assembling dies is well-known in the industry. Multiple chips like power regulators, transceivers, processors, memories have been interconnected to form a system using printed circuit boards (PCBs). Typically, several PCBs are connected through a back plane. For the PCBs, we need to have a packaged chip which even though has been the mainstay, has disadvantages like low structural integrity due to chip-package-interactions [4] and low IO density. The large bump pitches limit the number of IOs that emanate from the chip. The board level latencies also become prominent in high performance systems. The dimensions of the package features have scaled by 3-5\(\times \) while silicon has scaled by 1000\(\times \) [5] over the last 50 years. Also, with an increasing need for high-performance and high-efficiency computing, due to increasing cloud, mobile, and edge-based devices, the PPAC targets are increasingly challenged by interconnect bandwidth demands between the dies (mainly CPU and memory), which require low-power, high bandwidth interconnects [6]. Thus, the PCB based SOC approach has been replaced with many technologies like EMIB, CoWoS, HIST, Foveros etc., which are discussed in next section.
1.1 Overview
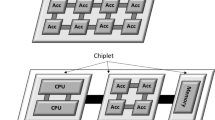
A general prototype of a heterogeneous integrated system is shown in Fig. 4. One of the constraints for such a system is that the chiplets must be able to communicate as if they were a single entity. Hence, there is a huge demand for the bandwidth (BW) of such systems. The BW depends directly on the number of interconnects that are connected between two chiplets. While the size of the chiplets (the amount of surface area available for interconnect connections) dictates the number of interconnects, it is a natural tendency to pack as many interconnects as possible in the given area. However, this is not possible, as the number of interconnects that can be drawn depends on (i) the technology which governs the interconnect pitch and (ii) cross-talk interference factors which increase as more interconnects are crammed together in a smaller area. Thus, in a heterogeneously integrated system, as pitch (distance of separation between two interconnects) decreases, more physical IO get packed in a much smaller area leading to higher shoreline -BW-density albeit with increased cross-talk and interference. One way to increase the bandwidth is to explore alternative signaling techniques which can transmit more information in a given clock period. This is the key idea presented in this work where higher order signaling scheme like PAM4 is systematically studied.
First, a sample system is modelled to understand the channel characteristics of inter-chiplet communication systems. After analysis of the system, we apply two types of signals viz., conventional NRZ and PAM4 to determine the highest operating frequency of the system. We vary the channel length and pitch to study the behavior of fine pitch and long length interconnect systems and understand how the frequency of operation varies. In order to quantify the performance, we use two metrics namely shoreline-BW density and energy per bit transmitted. Simple transceiver models are used to estimate energy efficiency of transmission.

Die Cost per mm2 across technology nodes
2 Literature Survey
The need for high bandwidth and low energy chip-to-chip signal interconnections can be addressed with multi-die heterogeneous integration (HI) schemes, such as 2.5D and 3D integration, to enable opportunities in low-power and high performance mobile and server computing [7]. This approach involves partitioning large SoCs into smaller dice, improving yield, hence reducing cost, and subsequently aggregating the partitioned known good dice (KGD). KGD from different nodes or technologies (e.g. silicon CMOS and emerging non-volatile memories) can be integrated together to enable HI, thus supporting flexible product migration to advanced nodes further reducing cost. HI can also facilitate packing more silicon than traditional approaches enable.
There are multiple types of die integration architectures that can be used to enable HI of disparate active dice. While the objective of this work is to explore coplanar microstrip based channels as a model for die to die interconnects for 2.5D integration, and evaluate the use of higher order modulation schemes for die-to-die signaling, in this section we provide a summary of different multi-die integration techniques, their potential applications, and associated technical tradeoffs.

IC Design Cost Breakdown
2.1 2D and 2D Enhanced Architectures
The Heterogeneous Integration Roadmap (HIR) 2019 [8] describes a 2D architecture as one where two or more active silicon dice are arranged laterally on an underlying package and are interconnected on the package. An example of a conventional 2D architecture where interconnection is accomplished using an organic package, as shown in Fig. 5b. However, any form of integration with an enhancement in interconnect density over mainstream organic packages, and with interconnection achieved through an underlying substrate can be termed as a 2D enhanced architecture. The choice of underlying substrates for 2D enhanced architectures can include silicon/ceramic/glass interposers, bridges (both embedded and non-embedded), and organic material. As noted in [8], architectures with significant interconnection enhancements over conventional 2D architectures (such as two or more dice integrated with flip-chip technology on an organic package substrate (Fig. 5b)) are typically referred to as 2.x architectures.

Generic Prototype of Heterogeneous Integrated System
Figure 6 illustrates four common types of 2D enhanced (or 2.5D) integration architectures. The first approach (Fig. 6a) represents a bridge-based integration where a silicon"bridge chip" is embedded within an organic package substrate. Dense interconnects on the Si-bridge along with fine-pitch \(\mu \)-bumps are used for die-to-die interconnection. Figure 6b represents a traditional interposer-based integration which uses through silicon vias (TSV) for signaling and power delivery to the interconnected dice. The third approach (Fig. 6c) de-embeds the silicon bridge chip and places it between the active chips and the package. The fourth approach, typically referred to as wafer-level packaging (WLP), is a method of packaging dice while they are still on a silicon wafer or on a reconstituted wafer, post singulation. There are primarily two kinds of WLP: fan-in and fan-out. In fan-in WLP the I/O density is limited to the die size, whereas with a fan-out WLP the redistribution layer (RDL) is processed on the wafer, and the interconnect area can be larger than the die area, thus, I/O distribution is not limited by die size. An illustration example of a fan-out WLP cross-section is shown in Fig. 6d.
Silicon interposer-based integration is capable of supporting higher interconnect densities (0.5–1.0 \(\upmu \)m line/space) than organic substrates (2–5 \(\upmu \)m) along with less thermal coupling and lower package power densities compared to 3D integration [9]. However, Si-interposers are more expensive compared to organic substrates, highlighting a tradeoff between cost and density. Moreover, interposer-based links can also have higher energy-per-bit (EPB) and latency for die-to-die connections compared to 3D integration due to the potentially longer interconnects leading to higher parasitics.

(a) Conventional flip-chip and (b) multi-chip module (MCM) integration using controlled collapse chip connection (C4) and ball grid arrays (BGA).
2.5D integration of field-programmable gate arrays (FPGA) based on silicon interposers can achieve an aggregate BW in excess of 400 Gb/s [10]. The 3D processor-on-memory integration using through silicon vias (TSVs) exhibits a maximum memory BW of 510.4 Gb/s at 277 MHz [11]. Recent demonstrations using passive interposer technology include TSMC’s CoWoS used to integrate two chiplets on a silicon interposer [12]. One of the first demonstrations of 2.5D integration of chiplets on an active interposer include the work from Vivet et al. [13]. There have also been multiple demonstrations of multi-die packages using bridge-chip technology, including embedded multi-interconnect bridge technology [14] and heterogeneous interconnection stitching technology [15] to enable 2.5D microsystems. In its simplest form, bridge-chip technology utilizes a silicon die with high-density interconnects for inter-die communication. The performance metrics of these 2.5D integration technologies are comparable to interposer-based 2.5D solutions, but many other benefits are offered, including the elimination of TSVs. The Kaby Lake G from Intel [9] is an example of a consumer-end product which integrates silicon from different process nodes and providers: intel 8th Gen core CPUs, AMD Radeon discrete GPU, and high bandwidth memory (HBM) using the EMIB bridge technology.
2.2 3D Architectures
An architecture where two or more active dice are vertically arranged and interconnected without the means of a package is defined as a 3D architecture, according to the HIR [8]. 3D integration can be broadly classified into two types. First is monolithic 3D integration, where two or more active device layers and interconnects are sequentially processed using standard lithography tools. The other type is TSV-based 3D, which utilizes TSVs along with either solder capped copper pillars (or \(\mu \)-bumps) or wafer-level hybrid bonds to establish vertical interconnections between stacked KGDs.

2.5D chip stack using (a) bridge-chip technology, (b) interposer technology, (c) Non-embedded bridge-chip using multi-height microbumps technology, and (d) fan-out wafer level packaging.

3D chip stack. (a) TSV-based and (b) monolithic inter-layer via-based integration.
Compared to single die system-on-chips (Fig. 5a), 3D integration architectures such as TSV-based 3D 7a and Monolithic 3D 7b can provide certain benefits. TSV-based 3D enables diverse heterogeneity in device integration from different technology nodes and improves overall yield through splitting larger monolithic dice into multiple smaller dice [16]. Monolithic 3D integration [17], enabled through fabrication of high-density fine-pitch inter layer vias (ILVs), can enable higher inter-layer connectivity compared to both conventional 2D and TSV-based 3D and higher interconnect density than TSV-based 3D [18, 19]. Based on these studies, there exists a performance gap between TSV-based 3D and monolithic 3D ICs in terms of energy, bandwidth, and interconnect density.
With conventional air-cooling, 3D integration of logic-on-logic tiers can lead to a worst case 73% higher maximum junction temperature (\(T_{j,max}\)) compared to an equivalent 2.5D case [20]. This difference in \(T_{j,max}\) can be attributed to increased volumetric power in 3D ICs, which can lead to higher inter-tier steady state temperatures and transient thermal coupling. However, 3D integration technologies present significant electrical benefits including lower signaling EPB, lower interconnect latency, and higher interconnect density compared to 2.5D integration schemes such as interposers and bridge-based integration [9, 21, 22].
A few benefits of TSV-based 3D integration include lower signaling EPB, lower link latency, and higher interconnect density compared to other enhanced-2D integration schemes such as interposers and bridge-based integration. However, relative to monolithic 3D ICs, conventional TSV-based 3D integration is expected to have higher EPB, higher inter-chip link latency, and lower interconnect density [21]. Monolithic 3D integration is a promising option for increased BW, which achieves higher BW than TSV-based 3D integration resulting from the utilization of shorter and denser nanoscale vertical vias [23]. Owing to this performance gap, there is a significant interest in monolithic 3D fabrication. However, limitations in devices, materials, and temperatures make monolithic 3D integration challenging and limiting.
A number of recent 3D integration demonstrations have been explored to enable opportunities in high-performance computing [24], imaging [25, 26], and gas sensing [27]. In these demonstrations, 3D integration of multiple active device layers is realized primarily through TSV-based 3D stacking [22, 28, 29] or fabrication of multiple active layers within the same IC (monolithic 3D integration) [30, 31]. Sinha et al. [22] demonstrated a 3D stacking of 2 active dice using high-density face-to-face wafer-bonding technology at 5.76 \(\upmu \)m pitch and TSVs. They demonstrated an order-of-magnitude better bandwidth (204–307 GB/s), BW (2276–3413 GB/s/mm2), and EPB (0.013–0.021 pJ/bit) compared to existing 2.5D/3D bump-based techniques.
3 Channel Modelling
The prototype model shown in Fig. 4 electrically resembles the coplanar microstrip lines. A close-up figure focusing on the interconnects is depicted in Fig. 8. In our case, we keep the structure symmetrical i.e., the spacing between the microstrips (referred to as the pitch) is uniform and all the channels are of equal width. In this system, we transmit signals on all channels textit(SSS) as compared to others where it can be either an interleaving of signal and ground signals (SG-SG-SG) or multiple grounds with a signal (GSG-GSG-GSG) which can possibly use asymmetric signal-ground pitches and different widths for signal and ground interconnects. Here, the ground signal will be a common plane beneath the channel and a dielectric material of height h. The microstrip lines have the benefits as they are planar in nature, easily fabricable, have good heat sinking and good mechanical support. It is a wire over a ground plane structure and thus tends to radiate as the spacing between the channel and the ground plane increases. The two-media nature or the substrate discontinuity of the coplanar microstrip causes the dominant mode of transmission to be quasi-TEM (hybrid) which means it has non-zero electric and magnetic fields in the direction of propagation.

Coplanar Microstrip Channel Model
Due to the quasi-TEM mode of propagation, the phase velocity, characteristic impedance, and the field variation across the channel become frequency dependent. One of the guiding criteria for stipulating the physical dimension of the coplanar microstrip lines is provided by [32] which are used mainly for developing closed form equations for effective dielectric constants, characteristic impedance etc., The physical dimensions should satisfy:
where s is the spacing between the conductors (channels) or the pitch, h is the thickness of the dielectric, w is the width of the channel, t is the thickness of the channel and the ground plane. s/h = g denotes the normalized gap factor and w/h = u denotes the normalized channel width. Table 1 shows the various parameters used in the model building. The concept of effective dielectric constant was introduced to account to the fact that most of the electric fields are constrained within the dielectric substrate but, a fraction of the total energy exists within the air above. The variation of effective dielectric constant with the pitch is depicted in Fig. 9 and that for intrinsic impedance with pitch is shown in Fig. 10 [33,34,35,36,37].
The analytic expressions for the same are given by [38]
where
and K(x) denotes Complete Elliptic Integral of First Kind

Variation of Effective Dielectric Constant with Channel Pitch
A coplanar microstrip model has been designed in HFSS. Each terminal of the channel acting as a port yielding frequency dependent 6 port scattering parameters in the form of touchstone files. The microstrip lines show higher radiation due to lower isolation and thus more cross-talk. The cross-talk experienced by a channel due to the adjacent channels depends on the pitch while the amount of signal attenuation depends on how far the signal has to travel which is the length of the channel. Thus, pitch and length are the two factors that dictate the quality of the received signal. In order to study their effects on the system performance, we parametrically vary them: the pitch is changed from 5 \(\upmu \)m to 50 \(\upmu \)m in steps of 5 \(\upmu \) and the length is varied from 100 \(\upmu \)m to 1 mm in increments of 100 \(\upmu \). The effect of E-field coupling can be observed in Fig. 11 with three cases that show the variation of magnitude of electric field on the victim channel with (a) no aggressors, (b) one aggressor and (c) two aggressors. Noting this, we use the generated touchstone files for performing the channel simulation. But, before applying signals to the channel, it is recommended that the models be checked for passivity.

Variation of Intrinsic Impedance with Channel Pitch
The Passivity theorem states that the Scattering matrix S(s) represents a passive linear system iff
-
1.
S(s*) = S*(s) where * denotes complex conjugate operator.
-
2.
Each element of S(s) is analytic in \({Re\{s\} > 0}\)
-
3.
\([1 - S^{H}(s)S(s)] \ge 0\) for all \(\omega \)
The S parameters have been verified in ADS to be passive.
4 Transceiver System Architecture
4.1 Bundle Data Clock Forwarded Channels
Each of the coplanar microstrip lines act as a channel transmitting data from the transmitter to the receiver in the form of voltage signals. As mentioned earlier, the BW of the interconnects is critical. Thus, in order to improve the useful BW, and to enhance the area utilization, we propose single ended transmission as opposed to differential mode which uses two links to transmit one signal, though differential signaling offers lesser crosstalk and higher signal swings. Meanwhile, the negative effects of single ended data transmission like simultaneous switching and reference offset can be mitigated by adjusting the voltage amplitude of the signal. In order to minimize the energy per bit, we propose not to use any equalization at both transmitter and receiver side. We also try to eliminate other sources of link power consumption like clock data recovery circuits at the receiver side by using clock forwarding.

E field coupling for different Scenario (a) No Aggressor Active, (b) One Aggressor Active (c) Both Aggressor Active
This essentially allows a fully parallel IO design. This is a distinguishing factor in the design of current parallel chiplet to chiplet communication technologies and is simpler to design than traditional SERDES. This is effective because in the target designs the channel lengths are short. Thus, there can be one additional clock signal for a bundle of few data signals (8 or 16) which can be used to forward the reference clock generated on the transmitter to the receiver as shown in Fig. 12.
4.2 Signaling
Here we evaluate two types of signaling schemes.
Non-Return to Zero (NRZ). Here the data is represented in the form of single 0’s and 1’s. When signaling a “0” bit, a voltage of 0V is sent on the channel and for transmitting a “1” bit, a voltage of Vdd is sent. A sample waveform for a given stream of bits is shown in the Fig. 13.
4 Level Pulse Amplitude Modulated (PAM4). In this scheme, two bits of data are grouped to signal a voltage value. Since 4 combinations of 2-bit sequence are possible, we have 4 voltage levels. \(00 \longrightarrow 0V\), \(01 \longrightarrow V_{dd}/3\), \(10 \longrightarrow 2V_{dd}/3 \) and \(11 \longrightarrow V_{dd}\). The sample waveform of PAM4 for the same bit stream is shown in Fig. 13. The symbol rate in PAM4 is half that of the NRZ or the data rate is twice that of the NRZ.
With two different signaling schemes, we have the corresponding transmitter and receivers.

Bundle Data Clock Forwarded Channel

NRZ and PAM4 waveforms for an arbitrary bit stream
4.3 Transmitter
NRZ. Since we do not use pre-emphasis or equalization, the transmitter can be a simple buffer which transmits voltages on to the channel. The only design constraint for these buffers is that they must be suitably sized to be able to drive the pad capacitance of the receiver along with that of the channel.
PAM4. Here, two bits need to be transmitted as one value of voltage. The input data is passed through a serializer which is then input to a simple 2-bit Digital to Analog Converter (DAC). The DAC will convert it to a mapped voltage and is transmitted on to the channel by a current mode driver.
4.4 Receiver
NRZ. Similar to the transmitter, the receiver is a simple buffer which will detect the voltage on the channel and decode it as a 0 or a 1. Thus, the buffer acts as a high gain voltage comparator which will compare the signal value to the trip-point voltage of the buffer in order to make the decision.
PAM4. The four voltage levels on the channel need to decoded back to two bits. Here, we use a simple 2-bit Analog to Digital Converter (ADC) to do the conversion. Due to its high speed of operation, a flash-ADC is best suitable for the purpose. The Flash-ADC in-turn comprises of three high gain comparators which compare the signal value against the external reference voltage. The ADC output is then encoded to binary.
The NRZ and PAM4 systems are shown in Fig. 14.

Circuits of (a) NRZ and (b) PAM4 Systems.
5 Channel Simulation
5.1 Setup
The simulation is performed in Keysight Advanced Digital System (ADS) platform for a 28 nm technology node and the simulation setup is as shown in Fig. 15. The transmitter is a Pseudo-Random Bit Sequence (PRBS) generator with the bits being electrically encoded to voltage signals. In this study, a PRBS-7 system is used for which the sequence generating monic polynomial is given by \({x^{7}+x^{6}+1}\). The transmitter has a transmit resistance denoted by R-TX which is typically around 50\(\varOmega \) in parallel with the pad capacitance (Cpad) which for a typical 28 nm node is around 5 pF.
The transmitter and receiver for the NRZ is a buffer as explained in the previous section. For PAM4, we use IBIS-AMI model along with the executables generated from MATLAB SERDES toolkit which can be used in conjunction with the ADS setup. The supply voltage is chosen to be 1 V for both NRZ and PAM4.
The channel is modelled in the form of a 6 port S-parameter network. We use the touchstone files generated from the HFSS models. The six ports represent the three transmitter and three receiver ports which constitute the three channels. The middle channel is the victim channel that needs to carry the required data signal under the influence of the two aggressor channels on the side which contribute to the crosstalk. To emulate the worst-case crosstalk scenario, we have the crosstalk generators (“XTalk” Transmitter) which are configured to operate at the same data rate as the main transmitter but generate out of phase signals.
On the receiver side, we have the pad capacitance. The termination resistance used in most of communication channels will impact power as it causes the received signals to attenuate. Thus, in order to reduce the power consumption, short links typically eliminate the legacy termination resistance. This will make the load on the receiver side to be purely capacitive which will cause the received signal to be reflected back to the transmitter affecting the quality of the transmitted signal and increasing inter-symbol interference (ISI). With the channel length being considerably small, the lack of termination resistance does not affect the bit error rate (BER) significantly.

Channel Simulation Setup in ADS Platform
5.2 Simulation
The channel simulation controller performs statistical convolution of channel impulse response with that of the data transmitted and the eye-diagram is generated at the receiver side. The channel simulation is performed for different pitch and channel length configurations. The following is the trend that is desirable to be observed:
-
1.
At a constant data rate, as the channel pitch decreases, the opening of the eye diagram decreases. This is due to the fact that the channels will get closer and the crosstalk increases.
-
2.
At a constant data rate, as the channel length increases, the opening of eye diagram decreases because the signals suffer more attenuation when it travels longer distance on the dissipative media.
-
3.
With constant dimensions, the eye-opening decreases with the increase in data rate due to higher inter-symbol interference.
Figures 16 and 17 show the eye diagrams for a sample of four pitch-length configurations at a constant data rate. In an ideal case, the eye-opening must be minimum for 1000 \(\upmu \)m length-5 \(\upmu \)m pitch channel due to highest attenuation and crosstalk and maximum for 100 \(\upmu \)m length-50 \(\upmu \)m pitch channel due to lowest attenuation and crosstalk. However, we note that the electromagnetics of the coplanar microstrip line is much more complex than simple linear relationships between frequency of operation and channel dimensions.

NRZ Eye for (a) L = 100 \(\upmu \)m, P = 5 \(\upmu \)m (b) L = 100 \(\upmu \)m, P = 50 \(\upmu \)m (c) L = 1000 \(\upmu \)m, P = 5 \(\upmu \)m, (d) L = 1000 \(\upmu \)m, P = 50 \(\upmu \)m

PAM4 Eye for (a) L = 100 \(\upmu \)m, P = 5 \(\upmu \)m (b) L = 100 \(\upmu \)m, P = 50 \(\upmu \)m (c) L = 1000 \(\upmu \)m, P = 5 \(\upmu \)m, (d) L = 1000 \(\upmu \)m, P = 50 \(\upmu \)m
5.3 Role of Termination Resistance
As mentioned earlier, the termination resistance at the receiver side is the major cause of signal attenuation and power dissipation. But, the main role of using a termination resistance is to avoid signal reflection back to the transmitter causing more ISI. The effect of termination resistance can be seen when trying to push the design operating frequency to a higher value. The Fig 18a shows the eye diagram for a relatively smaller length and very high pitch coplanar microstrip design at 10 GS/s for PAM4. There is no clear eye opening and the diagram looks completely distorted. The Fig 18b shows the eye diagram for the same design but with a 50 \(\varOmega \) termination resistance. We see that the eye has clear and well-defined openings making the received signal easily detectable.

10 GS/s PAM4 receiver eye diagram (a) without and (b) with 50 \(\varOmega \) termination resistance.
Notice that amplitude of the eye diagram before the addition of the termination resistance is 1 V while that after addition is approximately 0.4 V. This is the signal attenuation mentioned above. Thus, adding a termination resistance will be a design choice to either embrace lower energy per bit at lower data rate or higher energy per bit at higher data rate. In this article, we chose to forgo the slight improvement in data rate for lower energy per bit transmitted.
5.4 Channel Operating Margin and Highest Signaling Rate
The channel operating margin (COM) is a measure of channel performance which was originally developed for IEEE 802.3bj and IEEE 802.3bs Gigabit Ethernet (GbE) standards. The concept of COM has been applied for the channels under consideration. The COM is defined w.r.t to eye-diagram in Fig. 19 as

Channel Operating Margin Definition based on Eye Diagram for (a) NRZ and (b) PAM4
The standard requirement for a communication channel transmitting NRZ data is that COM \(\ge \) 3 dB. For PAM4 signaling, since the amplitude of the ideal signal is 1/3rd that of NRZ, the target COM \(\ge \) 9.5 dB. In the limiting case, it will be 3 dB for NRZ and 9.5 dB for PAM4. For PAM4, the average of COM for all the three eyes is taken. Here in the simulation, we determine the highest data rate that can be achieved while meeting the COM requirement for every configuration of channel length and pitch. This is done by setting an optimization goal to meet the COM requirement and sweeping over a suitable frequency range. All the measurements are made for a BER of 1e-15.
The intensity plot versus the channel dimensions are depicted in Fig. 20 for NRZ system and Fig. 21 for PAM4 system [39]. The channel pitch is along the X axis and the channel length is along the Y axis. The highest data rate that can be achieved for the given pitch and length while meeting the Channel Operating Margin requirement is indicated by intensity of the color in each box.

Maximum Frequency of Operation for NRZ for iso-BER of 1e-15

Maximum Frequency of Operation for PAM4 for iso-BER of 1e-15
The ideal scenario of data rate increasing with increasing channel pitch can be seen for channel length of 600 \(\upmu \)m in case of NRZ. At 40 \(\upmu \)m pitch in PAM4, the ideal trend of data rate decreasing with increasing channel length can be observed. That being said, we need to look at the general trend of the data rate as the channel dimensions are varied while considering that the maximum frequency of operation is controlled by the electromagnetics of the channel, effective dielectric constant of the substrate, characteristic impedance, resonant frequencies and so on. Traditionally channels are designed by fixing most of the physical channel parameters, but here we perform a design space exploration to identify the limits of parallel IO links.
Figure 22 show the shoreline BW density vs channel length for a sample of four pitch configurations for NRZ and PAM4 systems. The direct implication of the finer pitch is increased shoreline density.

Shoreline BW density versus Channel Length for (a) NRZ and (b) PAM4.
6 Power Estimations
6.1 Transmitter
NRZ: In our assumptions of single ended voltage mode transmission, the driver is a buffer circuit that needs to drive the wire and the pad capacitance. The magnitude of the wire capacitance is much smaller compared to that of the pad capacitance. If Cpad is the pad capacitance, fclk is the frequency of operation at which the data bits are transmitted, Vdd is the supply voltage, then the power dissipation can be written as
PAM4: The transmitter for PAM4 is a 2-bit DAC. We consider a simple capacitive binary-weighted array DAC structure as show in Fig. 23. The capacitive switching will be the key component of power consumption in this structure. [40] provides a power estimation of such structures; when applied to a 2-bit DAC with equal probability of 0’s and 1’s gives Eq. (13). fclk is the frequency of operation, C0 is the capacitance of the unit capacitor, Vref is the reference voltage for the conversion.
A simple current mode driver comprising of two binary weighted current sources with tail currents IT and 2IT can be utilized to drive the signal as shown in Fig. 24. The power is given be (14)

Binary Weighted 2 bit Capacitive DAC

2 bit Current Mode Driver
6.2 Receiver
NRZ: The single ended receiver is a buffer that decodes the signal to a 0 or 1 level and has the same power expression as that of the transmit buffer given by (5) but with load capacitance just another buffer.
PAM4: The receiver for PAM4 is a 2-bit ADC. With the inherent advantages of high speed of operation and the low-resolution requirements for case under discussion, a flash ADC is the best candidate. A flash ADC consists of \({2^{N}-1}\) comparators and an encoder. For a N = 2 bit flash ADC, we will need three comparators (Fig. 25). The power of a matching limited comparator [41] is given by (15), where \({C_{ox}}\) is the oxide capacitance, \({A_{VT}}\) is the threshold voltage mismatch coefficient, \({V_{in p-p}}\) is the peak to peak input voltage, \({C_{Cmin}}\) is the minimum required capacitance.
The power of a Wallace Encoder [42] in terms of number of bits N, typical gate energy \({E_{gate}}\) and operating frequency \({f_{clk}}\) is given by

Two bit Flash ADC with three comparators and Wallace Encoder
6.3 Phase Locked Loop (PLL)
A generic block diagram of a PLL is shown in Fig. 26. Here, we consider a non-differential 5 stage VCO along with the phase-frequency detector (PFD) from [43]. [44] provides with elaborate power estimations treating PLL as a second order continuous time system. Given the damping factor of 0.707 and a natural frequency of 9.375 MHz with a multiplier of N = 32, the power of the PLL can be written as (17), where \(C_{PFD}\), \({C_{DIV}}\), \({C_{VCO}}\) are the total capacitances of Phase-Frequency Detector, Frequency Divider and Voltage Controlled Oscillator respectively. The frequency divider circuit under consideration is a series of True Single Phase Clocked (TSPC) Flops [45] along with Transmission Gate (TG) multiplexers and inverters and \({P_{BIAS}}\) is the power of the bias circuitry..

Generic Structure of Phase Locked Loop

Power consumption of various components of NRZ and PAM4 system for their highest frequency of Operation
The value of various parameters used in power estimation is shown in Table 2. The total power for a 2.345 Gb/s NRZ is 31.2 mW leading to an energy-efficiency of 13.323 pJ/b. For the 1.49 GS/s PAM system, the power is 14.53 mW producing an energy-efficiency of 4.876 pJ/bit.
Figure 27 show the breakdown of power consumption. As expected, the PLL is the major consumer with up to 62.4% in NRZ and 86.5% in PAM. The receiver in both cases is negligible, as we do not use any equalizer or CDR.
7 Conclusion and Future Scope
In this paper we develop a tool chain from channel modelling to channel simulation and power estimation. The different industry standard tools used in the process include HFSS, ADS and MATLAB. We explore the coplanar microstrip based channels as a model for die to die interconnects for 2.5D integration. We show that higher order modulation like PAM can be applied with more than 63% energy efficiency per bit. This is enabled by the simple transceiver structures for short channel lengths. At high channel densities of up to 5 \(\upmu \)m pitch, we note that we can achieve 445 Gb/s/mm of shoreline-BW-density with NRZ and 565 Gb/s/mm with PAM4.
As an extension to the current work, we are also tuning the design to match the industry trends. Currently we propose to explore ultra-fine pitches of up to 1 \(\upmu \)m and characterize the same. The choice of the substrate material is another important factor. We also need to quantify the energy per bit at various termination resistance and choose the one that yields the best results. The circuits discussed need to be simulated for more accurate power numbers. Thus, we think there is sufficient opportunity to enhance this design simulation framework.
References
Hennessy, J.: The End of Moore’s Law & Faster General Purpose Computing, and a New Golden Age, DARPA ERI Summit, July 2018
Holt, B.: Advancing Moore’s Law. Intel Investor Meeting, Santa Clara (2015)
LaPadeus, M.: Big Trouble At 3nm, Semiconductor Engineering, June 2018. https://semiengineering.com/big-trouble-at-3nm/
Zhang, X., Im, S.H., Huang, R., Ho, P.S.: Chip package interactions. In: Bakir, M., Meindl, J. (eds.) Integrated Interconnect Technologies for 3D Nanoelectronic Systems, Artech House, Norwood, MA, USA, Chapter 2 (2008)
Iyer, S.S.: Heterogeneous Integration for Performance and Scaling. IEEE Trans. Compon. Packag. Manuf. Technol. 6, 973–982 (2016)
Mahajan, R., et al.: Embedded multidie interconnect bridge–a localized, high-density multichip packaging interconnect. IEEE Trans. Compon. Package. Manuf. Technol. 9(10), 1952–1962 (2019). https://doi.org/10.1109/TCPMT.2019.2942708
Collaert, N.: 1.3 future scaling: where systems and technology meet. In: IEEE International Solid-State Circuits Conference (ISSCC), pp. 25–29 (2020). https://doi.org/10.1109/ISSCC19947.2020.9063033
Heterogeneous Integration Roadmap (HIR): Chapter 22: Interconnects for 2D and 3D Architectures. https://eps.ieee.org/images/files/HIR_2019/HIR1_ch22_2D-3D.pdf
Lee, H.J., Mahajan, R., Sheikh, F., Nagisetty, R., Deo, M.: Multi-die integration using advanced packaging technologies. In: IEEE Custom Integrated Circuits Conference (CICC), pp. 1–7 (2020). https://doi.org/10.1109/CICC48029.2020.9075901
Erdmann, C., et al.: A heterogeneous 3D-IC consisting of two 28 nm FPGA die and 32 reconfigurable high-performance data converters. IEEE J. Solid-State Circuits 50(1), 258–269 (2015). https://doi.org/10.1109/JSSC.2014.2357432
Kim, D.H., et al.: Design and analysis of 3D-MAPS (3D massively parallel processor with stacked memory). IEEE Trans. Comput. 64(1), 112–125 (2015). https://doi.org/10.1109/TC.2013.192
Lin, M.S., et al.: A 7nm 4GHz Arm®-core-based CoWoS® Chiplet design for high performance computing. In: Symposium on VLSI Circuits, Kyoto, Japan, pp. C28–C29 (2019). https://doi.org/10.23919/VLSIC.2019.8778161
Vivet, P., et al.: 2.3 a 220GOPS 96-core processor with 6 Chiplets 3D-stacked on an active interposer offering 0.6 ns/mm latency, 3Tb/s/mm2 Inter-Chiplet Interconnects and 156mW/mm2@ 82%-Peak-Efficiency DC-DC Converters. In: IEEE International Solid-State Circuits Conference (ISSCC), San Francisco, CA, USA, pp. 46–48 (2020). https://doi.org/10.1109/ISSCC19947.2020.9062927
Mahajan, R., et al.: Embedded multi-die interconnect bridge (EMIB) - a high density, high bandwidth packaging interconnect. In: IEEE Electronic Components and Technology Conference (ECTC), Las Vegas, NV, pp. 557–565 (2016). https://doi.org/10.1109/ECTC.2016.201
Jo, P.K., Rajan, S.K., Gonzalez, J.L., Bakir, M.S.: Embedded polylithic integration of 2.5-D and 3-d chiplets enabled by multi-height and fine-pitch CMIs. IEEE Trans. Comput. Packag. Manuf. Technol. 10(9), 1474–1481 (2020). https://doi.org/10.1109/TCPMT.2020.3011325
England, L., Arsovski, I.: Advanced packaging saves the day! - How TSV technology will enable continued scaling. In: IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, pp. 3.5.1–3.5.4 (2017). https://doi.org/10.1109/IEDM.2017.8268320
Wei, H., Shulaker, M., Wong, H.S.P., Mitra, S.: Monolithic three-dimensional integration of carbon nanotube FET complementary logic circuits. In: IEEE International Electron Devices Meeting (IEDM), Washington, DC, pp. 19.7.1–19.7.4 (2013). https://doi.org/10.1109/IEDM.2013.6724663
Liu, C., Lim, S.K.: A design tradeoff study with monolithic 3D integration. In: International Symposium on Quality Electronic Design (ISQED), Santa Clara, CA, pp. 529–536 (2013). https://doi.org/10.1109/ISQED.2012.6187545
Beyne, E.: Short course on: heterogeneous system partitioning and the 3D interconnect technology landscape. In: Symposia on VLSI Technology and Circuits (2020)
Kaul, A., Peng, X., Kochupurackal Rajan, S., Yu, S., Bakir, M.S.: Thermal modeling of 3D polylithic integration and implications on BEOL RRAM performance. In: IEEE International Electron Devices Meeting (IEDM), Virtual Conference (2020)
Zhang, Y., Zhang, X., Bakir, M.S.: Benchmarking digital die-to-die channels in 2.5-D and 3-D heterogeneous integration platforms. IEEE Trans. Electron. Devices 65(12), 5460–5467 (2018). https://doi.org/10.1109/TED.2018.2876688
Sinha, S., et al.: A high-density logic-on-logic 3DIC design using face-to-face hybrid wafer-bonding on 12nm FinFET process. IEEE International Electron Devices Meeting (IEDM), Virtual Conference (2020)
Panth, S., Samadi, K., Du, Y., Lim, S.K.: High-density integration of functional modules using monolithic 3D-IC technology. In: Asia and South Pacific Design Automation Conference (ASP-DAC), Yokohama, pp. 681–686 (2013). https://doi.org/10.1109/ASPDAC.2013.6509679
Lee, C.C., et al.: An overview of the development of a GPU with integrated HBM on silicon interposer. In: Electronic Components and Technology Conference (ECTC), Las Vegas, NV, pp. 1439–1444 (2016). https://doi.org/10.1109/ECTC.2016.348
Tsugawa, H., et al.: Pixel/DRAM/logic 3-layer stacked CMOS image sensor technology. In: IEEE International Electron Devices Meeting (IEDM), San Francisco, CA, 2017, pp. 3.2.1–3.2.4 (2017). https://doi.org/10.1109/IEDM.2017.8268317
Srimani, T., Hills, G., Lau, C., Shulaker, M.: Monolithic three-dimensional imaging system: carbon nanotube computing circuitry integrated directly over silicon imager. In: IEEE International Electron Devices Meeting (IEDM), Symposium on VLSI Technology, Kyoto, Japan, 2019, pp. T24–T25 (2019). https://doi.org/10.23919/VLSIT.2019.8776514
Shulaker, M.M., et al.: Three-dimensional integration of nanotechnologies for computing and data storage on a single chip. Nature 547, 74–78 (2017). https://doi.org/10.1038/nature22994
Lee, J.C.: High bandwidth memory(HBM) with TSV technique. In: International SoC Conference(ISOCC), Jeju, pp. 181–182 (2016). https://doi.org/10.1109/ISOCC.2016.7799847
Gomes, W., et al.: 8.1 Lakefield and mobility compute: A 3D stacked 10nm and 22FFL hybrid processor system in 1212mm2, 1mm package-on-package. In: IEEE International Solid-State Circuits Conference - (ISSCC), San Francisco, CA, USA, pp. 144–146 (2020). https://doi.org/10.1109/ISSCC19947.2020.9062957
Batude, P., et al.: 3D monolithic integration. In: IEEE International Symposium on Circuits and Systems (ISCAS), Rio de Janeiro, pp. 2233–2236 (2011). https://doi.org/10.1109/ISCAS.2011.5938045
Bishop, M.D., Wong, H.S.P., Mitra, S., Shulaker, M.M.: Monolithic 3-D integration. IEEE Micro 39(6), 16–27 (2019). https://doi.org/10.1109/MM.2019.2942982
Kirschning, M., Jansen, R.H.: Accurate wide-range design equations for the frequency dependent characteristic of parallel coupled microstrip lines. MTT-32, January 1984. https://doi.org/10.1109/TMTT.1984.1132616
Veyres, C, Fouad Hanna, V. : Extension of the application of conformal mapping techniques to coplanar lines with finite dimensions. Int. J. Electron. 48(1), 47–56 (1980)
Ghione, G., Naldi, C.U.: Parameters of coplanar waveguides with lower ground plane. Electron. Lett. 19(18), 734–735 (1983)
Ghione, G., Naldi, C.U.: Coplanar waveguides for MMIC applications: effect of upper shielding, conductor backing, finite-extent ground planes, and line-to-line coupling. IEEE Trans. Microwave Theory Tech. 35(3), 260–267 (1987)
Bedair, S., Wolff, I.: Fast and accurate analytic formulas for calculating the parameters of a general broadside-coupled coplanar waveguide for MMIC applications. IEEE Trans. Microwave Theory Tech. 37(5), 843–850 (1989)
Wang, Y.C., Okoro, J.A.: Impedance calculations for modified coplanar waveguides. Int. J. Electron. 68(5), 861–875 (1990)
Simons, R.N.: Coplanar Waveguide Circuits, Components, and Systems. Wiley (2001). ISBN 0-471-16121-7
Saligram, R, Kaul, A, Bakir, M. S, Raychowdhury, A: A model study of multilevel signaling for high-speed chiplet-to-chiplet communication in 2.5D integration. In: 28th IFIP/IEEE International Conference on Very Large Scale Integration (VLSI-SoC), October 2020
Saberi, M., Lotfi, R., Mafinezhad, K., Serdijn, W.A.: Analysis of power consumption and linearity in capacitive digital-to-analog converters used in successive approximation ADCs. IEEE Trans. Circuits Syst. I Regular Papers 58 (2011). https://doi.org/10.1109/TCSI.2011.2107214
O’Driscoll, S., Shenoy, K. V., Meng, T. H.: Adaptive resolution ADC array for an implantable neural sensor. IEEE Trans. Biomed. Circuits Syst. 5(2), 120–130 (2011). https://doi.org/10.1109/TBCAS.2011.2145418
Murmann, B.: Energy Limits in A/D Converters, SSCS Talk (2012)
Jeong, D.K., Borriello, G., Hodges, D.A., Katz, R.H.: Design of PLL-based clock generation circuits. IEEE J. Solid-State Circuits 22(2), pp. 255–261 (1987). https://doi.org/10.1109/JSSC.1987.1052710
Duarte, D., Vijaykrisnan, N., Irwin, M.J.: A complete phase-locked loop power consumption model. In: Proceedings 2002 Design, Automation and Test in Europe Conference and Exhibition, Paris, France, 2002, p. 1108. https://doi.org/10.1109/DATE.2002.998464
Rabaey, J.: Digital Integrated Circuits: A Design Perspective. Prentice-Hall International, NJ (2003)
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 IFIP International Federation for Information Processing
About this paper

Cite this paper
Saligram, R., Kaul, A., Bakir, M.S., Raychowdhury, A. (2021). Multilevel Signaling for High-Speed Chiplet-to-Chiplet Communication. In: Calimera, A., Gaillardon, PE., Korgaonkar, K., Kvatinsky, S., Reis, R. (eds) VLSI-SoC: Design Trends. VLSI-SoC 2020. IFIP Advances in Information and Communication Technology, vol 621. Springer, Cham. https://doi.org/10.1007/978-3-030-81641-4_8
Download citation
DOI: https://doi.org/10.1007/978-3-030-81641-4_8
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-81640-7
Online ISBN: 978-3-030-81641-4
eBook Packages: Computer ScienceComputer Science (R0)