
Abstract
Structural reliability methods aim at the computation of failure probabilities of structural systems with methods of statistical analysis due to varied uncertainties occurring during their design, building or even operating conditions. However, in the field of civil engineering, the use of structural reliability methods unfortunately remains limited to specific cases. Most of the software available has still a limited range concerning wide parametric studies for analysis with reliability methods in civil engineering. This paper describes a new open-source software library as an effective tool for reliability analysis in civil engineering. The goal is to facilitate the adoption of reliability methods among engineers in practice as well as to provide an open platform for further scientific collaboration. The new library is being developed as a so-called “R package” in open-source programming software “R”. The package is capable of carrying out systematic parameter studies using different probabilistic reliability methods, as FORM, SORM, Monte Carlo Simulation. Based on this, an overview on the probabilistic reliability methods implemented in the package as well as results of parametric studies is given. The performance of the package will be shown with a parametric study on a practical example. Most important results of the parametric study as well as the correctness of different reliability methods will be described in the paper. By describing probabilistic methods using an example in practice, engineers can get a basic understanding behind the ideas of probability theories. Further work will result in large parameter studies, which will support the development of a new guideline for reliability in civil engineering. This guideline describes techniques of code calibration as well as to determine new partial safety factors (e.g. for non-metallic reinforced concrete, fixing anchors, etc.). Furthermore, advanced reliability methods (e.g. Monte Carlo with Subset Sampling) will be implemented in the new R package.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others

Keywords
1 Introduction
By accounting uncertainty of load and material properties, civil engineering researchers like Freudenthal [1] changed the classic deterministic perspective of structural design towards a more scientific approach. Since 1950, substantial research has been done and published, e.g. refer to the CEB/FIP Bulletin No. 112 [2] or the “Probabilistic Model Code” documents [3], developed by the Joint Committee on Structural Safety. Furthermore, scientific committees provided the international code ISO 2394 “General principles on reliability for structures” [4] as a step for international standardisation of safety elements.
The goal of reliability analysis is to determinate the probability of failure with statistical methods. Safety elements can be derived by deterministic, the so-called “semi-probabilistic”, and probabilistic methods. Eurocode 0 [5] categorises such probabilistic methods into Level I (partial safety factors are assumed to achieve a certain failure probability), Level II (approximated calculation of the failure probability) and Level III (exact determination of the failure probability). The Eurocode itself uses Level I methods in the design equations and offers a generic description of Level II and Level III methods. Eurocode 0 [5] gives only a detailed view on the Mean Value First Order Second Moment Method (MVFOSM), which can be considered inconsistent regarding the reliability, as it is shown e.g. by Ricker [6].
In mathematical terms, the determination of the reliability index β is easier than the calculation of the probability of failure. Current international codes, as Eurocode 0 [5], provide different target values for the probability of failure and the respective reliability indices β, depending on certain boundary conditions, e.g. β = 3.8 is defined for a 50-year reference period. To calculate the probability of failure with Level II and Level III reliability methods, it is needed an algorithm to solve the multidimensional probability integral. In most cases, it is not possible to use analytic mathematic methods for joint density functions, depending on an arbitrary number of random variables with different distribution functions, and sophisticated limit state functions.
So far, there are few commercial software tools as well as non-commercial and open-source software tools for reliability analysis available. An example is the software tool “mistral” (Methods in Structural Reliability Analysis) that is written as a R-package [7]. The new software tool, which is described in this paper, has several more features (e.g. an algorithm for the automation of parametric studies) and more probabilistic methods are available.
2 Reliability Methods
The fundamental mathematical problem of reliability analysis is based on the assessment of the probability of failure pf by solving the following high-dimensional convolution integral:
where \( g(\vec{x}) \) ≤ 0 is denoted the failure domain and fx(\( \vec{x} \)) is the joint probability density function of the basic random variables in a resistance or load function. In many cases, no analytical mathematical solution exists. Thus, only numerical methods give acceptable (or satisfactory) results. There are several reliability analysis techniques to calculate a reliability index and the respective probability of failure. Table 1 gives an overview on some common methods and their respective accuracy.
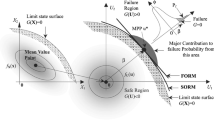
In the field reliability analysis in structural concrete members, FORM, SORM, and Monte Carlo simulation methods are the most relevant techniques. The solution of a high dimensional integral, which is the probability of failure, can be described as a (non-linear) optimisation problem with boundary conditions. Figure 1 illustrates the geometrical interpretation of the reliability index β in relation to the probability of failure and respective the safe region or the unsafe region (failure).

Fundamental mathematical problem of reliability analysis
2.1 FORM Algorithm
The solution of a high dimensional integral can be described as a (non-linear) optimisation problem with side conditions. This optimisation problem is not simple and, therefore, leads to the development of several algorithms. One of the most relevant approximation methods, the so-called “First Order Reliability Methods” (FORM), were developed 40 years ago and are still considered as robust algorithms for the safety level assessment. In fact, the FORM methods have a great importance in civil engineering regarding code calibrating and reliability in general [8]. For an almost linear limit state function, the FORM algorithm provides satisfactory results that are comparable with the results attained with Level III methods.
The FORM algorithm is an iterative procedure and non-normal distributed random variables are approximated by the so called “Tail Approximation” whereby the density function fX(\( \vec{x} \)) and probability function FX(\( \vec{x} \)) in the point \( \vec{x}_{i}^{*} \) from the original distribution and the standard normal distribution are equalised. The Starting vector \( \vec{x}_{i = 1}^{*} \) is of great importance because it is possible that the algorithm finds local minimas.
Figure 2 shown the procedure of a common FORM algorithm.

Procedure of a FORM algorithm (adapted from [17])
2.2 SORM Algorithm
The second-order reliability method (SORM) has been established as an attempt to improve the accuracy of the first-order methods, as the FORM. In first-order methods, since the limit state function is approximated by a linear function, accuracy problems can occur when the performance function is strongly nonlinear [9]. As opposed to the first-order methods, in the SORM, the integration boundary \( g\left( {\overrightarrow {x} } \right) \) = 0, denoted the limit-state surface, is no longer approximated by a hyperplane; instead, the boundary \( g\left( {\overrightarrow {x} } \right) \) = 0 is replaced by a paraboloid in a transformed standard normal space [10,11,12].
The requirements for this approximation are, however, that the limit state function is continuous near the approximation point and can be differentiated at least twice. Fundamentally, for convex functions \( g\left( {\overrightarrow {x} } \right) \) = 0 an approximation as a hypersphere and an approximation as a linear hyperplane represent an upper limit and a lower limit for the failure probability pf (Fig. 3).

Schematic representation of the integration areas (adapted from [18])
It is assumed that, in the standard normal space, the reliability index β corresponds to the minimum distance from the origin of the axes to the limit state surface. The minimum distance point on the limit state surface is denoted the design point \( \vec{x}^{*} \).
In the curvature-fitting SORM, the paraboloid is defined by matching its principal curvatures to the principal curvatures of the limit state surface at the design-point \( \vec{x}^{*} \) [13]. To this end, Eq. (1) is transformed into a so-called quadric function. A quadric function depends on the number of variables and can be a curve, surface or hyper surface of second order. The basic variables Xi are converted into standard normal distributed variables Ui. The coordinate system (u1, u2, …, un) is rotated around its origin so that one of the coordinate axes coincides with the design point. In the new coordinate system, the design point has the coordinates (0, …, β). This rotation is carried out through an orthogonal transformation matrix by using, for example, the Gram-Schmidt orthogonalization algorithm. Then, at the design point, the principal curvatures of the limit-state surface are obtained as the eigenvalues of Hessian matrix [13].
The exact calculation of the probability of failure can be rather complex. Breitung [10], for example, has derived an asymptotic approximate equation that provides insight into the nature of the contribution of each curvature, where the probability of failure is expressed as:
in which Φ(.) is the standard normal cumulative distribution function, β is the distance from the coordinate origin (i.e. reliability index). The first term in Eq. (1) represents the first-order approximation of the failure probabilities pf, and the product term involving the quantities (1 – β ki), with β ki being the main curvatures at the design point, represents the second-order correction [13].
2.3 Monte Carlo Simulation
The Monte Carlo simulation method uses techniques of statistical calculation by generating uniform distributed (pseudo) random numbers. By generating a stochastically independent, high number of those random variables, the probability of failure can be calculated using Eq. (3):
where N is the total number of realisations (or number of simulations) and nF is the number of simulations, for which the performance function is less or equal to zero: g ≤ 0).
If the number of realizations increases, the accuracy of the simulation will also increase, whereas the coefficient of variation will decrease.
For arbitrary types of distributions (e.g. lognormal, gamma, …), the generated uniformly distributed random variables have to be transformed with the probability function FX(\( \vec{x} \)), applicable for the certain distribution type (Fig. 4).

Principle of Monte Carlo simulation
3 Implementation of Reliability Methods
Chapter 3 describes a new open-source software library for reliability analysis in civil engineering. The goal is to facilitate the adoption of reliability methods among engineers in practice as well as to provide an open platform for further scientific collaboration in software language “R” [14].
3.1 Description of Software Tool
The new library is being developed as a so-called “R package” in open-source programming software “R”. The package is capable of carrying out systematic parameter studies using different probabilistic reliability methods (e.g. FORM, SORM, Monte Carlo Simulation). Based on this, an overview on the probabilistic reliability methods implemented in the package as well as results of first parametric studies are given. The developed package allows to perform systematic and large parameter studies and provides different algorithms of reliability analysis in an effective way. The structure of the software tool is shown in Fig. 5.

Structure of the software tool
3.2 Example of Parameter Study
As a practical example, the limit state function of the bending problem for steel reinforced concrete members is chosen. Equations (5) and (6) shows a formula of the state function g which is used for the parameter study.
Table 2 shows the statistical parameters of the basic variables (mean and standard deviation) and their distribution types.
In Fig. 6, the resulting reliability indices β are presented in dependence of the varied effective depth. For the parametric study, three different reliability methods (FORM, SORM, Monte Carlo) were used.

Results parameter study of bending problem
It can be seen that the curvature of the limit state function shows the non-linear effect of the limit state function (Fig. 6). The results of the SORM algorithm (Level II) and the Crude Monte Carlo method (Level III) are almost the same, and therefore, it gives a first indication that the software is suitable for parametric studies with the reliability methods described in Chap. 2. The new software code is working well and this first example shows the effectiveness of the new software library, especially for large parameter studies.
4 Conclusions and Outlook
It is shown in this paper how different reliability methods can be implemented in program code. In addition, the results of a first parameter studies are presented to illustrate the correctness and functionality of the new software package.
The parametric study highlighted two important aspects. On the one hand, the implementation of reliability methods in civil engineering is an important step towards a wider application of statistical methods, to which this contribution should motivate. On the other hand, the parameter study presented shows the application of the probabilistic methods using a practical example with a nonlinear limit state function and non-normally distributed basic variables.
Furthermore, advanced reliability methods (e.g. Monte Carlo with Subset Sampling Simulation) will be implemented in the new R package. Further work will result in larger parameter studies, which will support the development of a new guideline for the application of reliability methods in civil engineering, and will continue the progress of reliability research mentioned in Chap. 1. In the project “TesiproV”, the authors will provide a new guideline, which describes certain techniques of code calibration, based on reliability methods, as well as the assessment of new partial safety factors.
References
Freudenthal, A. (1947). The safety of structure. Transactions of the American Society of Civil Engineers, 112(1), 125–159.
Joint-Committee CEB/CECM/CIB/FIB/IABSE Structural Safety. (1974). First order reliability concepts for design codes (documentation). Paris: Comite Europeen du Beton (Bulletin d’Information, No. 112).
Joint Committee on Structural Safety. (2001). Probabilistic model code (12th draft). www.jcss.ethc.ch.
ISO 2394:2015(E). (2015). General principles on reliability for structures. Geneva: International Organization for Standardization (ISO).
DIN EN 1990. (2010). Grundlagen der Tragwerksplanung; Deutsche Fassung EN 1990:2002. Berlin: Beuth Verlag.
Ricker, M., Feiri, T., Nille-Hauf, K., Adam, V., & Hegger, J. (2020). Enhanced reliability assessment of punching shear resistance models for flat slabs without shear reinforcement. Preprint submitted to Engineering Structures.
Walter, C. et al (2016). Mistral: Methods in structural reliability analysis. http://cran.r-project.org/package=mistral.
Melchers, R., & Becks, A. (2018). Structural analysis and prediction. Hoboken: Wiley.
Zhao, Y. G., & Ono, T. (1999). A general procedure for first/second-order reliability method (FORM/SORM). Structural Safety, 21(2), 95–112.
Breitung, K. (1984). Asymptotic approximations for multinormal integrals. Journal of Engineering Mechanics, 110(3), 357–366.
Der Kiureghian, A., Lin, H. Z., & Hwang, S. J. (1987). Second-order reliability approximations. Journal of Engineering Mechanics, 13(8), 1208–1225.
Tvedt, L. (1990). Distribution of quadratic form in normal space—Application to structural reliability. Journal of Engineering Mechanic, 116(6), 1183–1197.
Kirugehian, A. D., & Stefano, M. D. (1991). Efficient algorithm for second-order reliability analysis. Journal of Enigneering Mechanics, 117(12), 2904–2923.
R Project. (2020). www.r-project.org.
Ricker, M. (2009). Zur Zuverlässigkeit der Bemessung gegen Durchstanzen bei Einzelfundamenten, Dissertation, RWTH Aachen University.
DIN EN 1992-1-1. (2011). Bemessung und Konstruktion von Stahlbeton- und Spannbetontragwerken – Teil 1-1: Allgemeine Bemessungsregeln und Regeln für den Hochbau; Deutsche Fassung EN 1992-1-1:2004 + AC:2010. Berlin: Beuth Verlag.
Faber, M. H. (2009). Risk and safety in engineering. Lectures Notes. Zurich: ETH Zurich.
Neumann, H. J., Fiessler, B., & Rackwitz, R. (1977). Die genäherte Berechnung der Versagenswahrscheinlichkeit mit Hilfe rotationssymmetrischer Grenzzustandsflächen 2. [zweiter] Ordnung. Sonderforschungsbereich 96, Techn. Univ.
Ditlevsen, O., & Madsen, H.O. (2007). Structural reliability methods.
Bronstein, I. N., & Semendjajew, K. A. (1988). Ergänzende Kapitel zum Taschenbuch der Matehmatik, Bd 1, 5 bearbeitete und erweitert Auflage. Frankfurt: Verlag Harri Deutsch.
Acknowledgements
The authors would like to thank the German Federal Ministry for Economic Affairs and Energy (BMWI) for funding the project TesiproV “Allgemeingültiges Verfahren zur Herleitung von Teilsicherheitsbeiwerten im Massivbau auf Basis probabilistischer Verfahren anhand ausgewählter Versagensarten – Erstellung eines Richtlinienentwurfs” within the research funding program “WIPANO” (No. 03TNK003).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Schulze-Ardey, J.P., Feiri, T., Hegger, J., Ricker, M. (2021). Implementation of Reliability Methods in a New Developed Open-Source Software Library. In: Matos, J.C., et al. 18th International Probabilistic Workshop. IPW 2021. Lecture Notes in Civil Engineering, vol 153. Springer, Cham. https://doi.org/10.1007/978-3-030-73616-3_30
Download citation
DOI: https://doi.org/10.1007/978-3-030-73616-3_30
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-73615-6
Online ISBN: 978-3-030-73616-3
eBook Packages: EngineeringEngineering (R0)