
Abstract
In this paper, we present and compare the accuracy of two types of classifiers to be used in a Brain–Computer Interface (BCI) based on the P300 waveforms of three post-stroke patients and six healthy subjects. Multilayer Perceptrons (MLPs) and Support Vector Machines (SVMs) were used for single-trial P300 discrimination in EEG signals recorded from 16 electrodes. The performance of each classifier was obtained using a five-fold cross-validation technique. The classification results reported a maximum accuracy of 91.79% and 89.68% for healthy and disabled subjects, respectively. This approach was compared with our previous work also focused on the P300 waveform classification.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
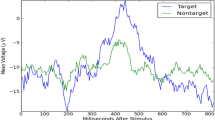
A Brain–Computer Interface (BCI) is a system that records, analyzes, and classifies brain signals to control an external device or a computer. Also, it allows healthy subjects or patients to communicate through brain activity [1]. The electroencephalographic signals (EEG) are a suitable and common way to register and analyze brain signals while a subject develops different sorts of mental activities. Some of these, such as resting states and cognitive tasks, are specially studied for BCI design purposes. Different paradigms such as motor imagery (MI), oddball, and steady-state visual evoked potential (SSVEP) [2], elicit specific potentials that are then used to build BCI systems. Speller is one application of a BCI based on the P300 waveform which is commonly used as an alternative communication way, especially for disabled people. This application uses the oddball paradigm which consists of showing infrequent stimulus (targets) blended with irrelevant stimuli sequences (non-targets). For each target, 300 ms after, the P300 waveform is elicited and can be identified in the EEG [3]. This paradigm requires less training periods than others [4], thereby making it a successful tool for BCI design [5].
In [5], a system for the detection of visual P300 in healthy and disabled subjects was developed. Bayesian Linear Discriminant Analysis (BLDA) was tested for the classification of visual P300. The best classification accuracy was on average 94.97%, and the maximum bit rate reached for the disable subjects was 25 bits per minute. EEG data in [6] was classified using a Backpropagation Neural Network (BPNN). The authors achieved a score classification of 96.3% and 96.8% for disabled and healthy subjects. The best bit rate was 21.4 and 35.9 bits per minute for disabled and healthy subjects, respectively. A support vector machine (SVM) algorithm and one modification of the speller (6 × 6 to 4 × 10) were proposed in [7] to classify the P300 visual evoked potential. The data from six healthy subjects were analyzed, and the results reported an average accuracy of 75%. In [8], it was developed a P300 BCI system based on ordinal pattern features and Bayesian Linear Discriminant Analysis (BLDA). Their best bit rate was 16.715 bits per minute for disabled subjects and 26.595 bits per minute for healthy subjects. A stepwise linear discriminant analysis (SWLDA) was proposed in [9] to classify P300 waves from a 6 × 6 speller. The results from eight healthy subjects reported an average accuracy of 92%. In [10], a Hidden Markov Model (HMM) was used to classify EEG data of a 6 × 6 speller reaching a classification result of 85% offline and 92.3% online.
About Smart Homes using BCI, in [11], the authors proposed a random forest classifier for P300 classify from three subjects. The best classification accuracy for the subjects was on average 87.5%. A 6 × 6 character speller and icon speller were compared and their performance analyzed in [12] for nine subjects. The authors achieved a score classification of 80% for character speller and 50% for icon speller. A Stepwise Linear Discriminant Analysis (SWLDA) was used to classify EEG data from one subject with Amyotrophic Lateral Sclerosis (ALS) using a 6 × 6 row–column speller to control television in [13]. The classification accuracy was 83%. Regarding Virtual Reality Environments (VRE), [14] proposed to control a smart home application using different speller masks (i.e., music, tv channels, etc.) testing with twelve subjects. Average classification accuracy of 75% was reported.
This work presents a P300-based BCI for post-stroke people and healthy people. The output of this BCI can be used to control home appliances. The aim of this work is to discriminate the presence of the P300 waveform in EEG from 16 channels using Multilayer Perceptron (MLP) and Support Vector Machine (SVM) classifiers. Results outperformed our previous work [15]. This work is presented as follows: In Sect. 2 is presented the experimental procedure including participants, experimental setup, and EEG acquisition. The methods are presented in Sect. 3 which describes preprocessing, feature vectors, and classifiers. The results and discussion are presented in Sect. 4. Finally, we present the conclusions and future work in Sect. 5.
2 Experimental Procedure
2.1 Participants
The volunteers are grouped by healthy and disabled subjects, aged between 20 and 55. Table 1 shows the age, gender, and medical diagnosis of each volunteer. The six healthy participants (S01 to S06) acted as the control group for the three post-stroke patients (S07 to S09). Subject S08 exhibited limited spoken communication and was able to perform restricted movements of his legs. Subject S07 exhibited reduced spoken communication skills and was able to perform movements with his extremities. Finally, subject S09 was able to perform restricted movements with his hands and arms. The Ethics Committee from the Universidad Peruana Cayetano Heredia issued the ethical approval for the experiment and informed written consent. All participants that opted to participate were also informed about the academic objective of the research, as well as ensured preservation of their anonymity.
2.2 Experimental Setup
Six images that are placed in two rows and three columns, above a white background as shown in Fig. 1, were displayed on the screen of a computer. Each image represents an option that provides the subject the capability to interact with another individual or with its surroundings without speaking or moving his arms [5].

Display of six images on a computer screen
The protocol of the experiment, based on Hoffmann’s [5], is displayed in Fig. 2. As can be seen, one image (out of six) is flashed in a random sequence during the first 100 ms, and during the next 300 ms, as shown in Fig. 2, a white background is displayed. This process is repeated until the completion of the six images sequence. The group of six images randomly flashed is called one block, and one run represents the interval between 20 and 25 blocks, which are also chosen randomly in each experiment. The database contains four recording sessions per subject, and each session includes six runs. All subjects who participate in this experiment were forbidden to talk and were told to count how many times the image they were told to pay attention to appear on the screen. Each session was separated by one break of 10 min, and two sessions were performed per day.

Stimuli timing diagram used in each experiment
2.3 EEG Acquisition
The EEG signals were recorded using an electroencephalograph of the brand g.tec. Sixteen bipolar electrodes (Fz, FC1, FC2, C3, Cz, C4, CP1, CP2, P7, P3, Pz, P4, P8, O1, O2, and Oz) were placed in accordance with the international 10/20 system in order to record the brain signals. The ground and reference electrode were placed at the right mastoid and at the left earlobe, respectively. Also, the EEG signals were sampled at 2400 Hz. Figure 3 displays the experiment setup. Furthermore, the C++ programming language and MATLAB R2016a were used to analyze the EEG data.

Subject in P300 speller experiments
3 Methods
3.1 Preprocessing
A six-order bandpass Butterworth filter with cut-off frequencies 1 and 15 Hz was used to filter the EEG data after it was downsampled from 2400 to 120 Hz. For each electrode, all data samples between 0 and 1000 ms posterior to the beginning of the stimulus were extracted obtaining 120 samples per trial. Artifacts were eliminated by winsorization: each channel signal under the 10th percentile and above 90th percentile was replaced by the 10th percentile or the 90th percentile, respectively [5]. Finally, the data was standardized.
3.2 P300 Classification
Feature Vectors and Training Matrices
The feature vector construction begins rearranging the data from a single trial. Specifically, the samples of each channel are concatenated with the others in the following way:
where for a single sample \(S_{i}^{k}\), \(i\) indicates the channel to which it belongs and \(k\) its position with respect of time. The vectors obtained from all the trials present in the four sessions of a subject are stacked shaping the training and testing matrices. Each trial, and therefore each \(V\), has a label associated which points out the presence of a P300 waveform in it. When that is the case, the trial is considered as target and when not, non-target.
Since there is an uneven amount of trials target and non-target, due to the experimental procedure for EEG recording, a balanced process is required before training to avoid biasing in classification. The same number of target trials is chosen randomly from a non-target trial pool, resulting in an even-class matrix. Two types of classifiers will use these matrices for their training process: Multilayered Perceptron and Support Vector Machine. The whole process is illustrated in Fig. 4.

EEG signal processing block diagram
Multilayered Perceptron Architecture
Authors, like [16], had used neural networks to discriminate the presence of ERPs in EEG signals. Multilayer Perceptrons (MLPs) are neural nets that can be described as function approximators [17]. Multiple parameters, like weights and biases, are adjusted in the training stage trying to match known outputs (target or non-target) with specific inputs (trials data). This process results in a model able to predict the class or label of future new inputs with similar characteristics.
The number of inputs, hidden layers, outputs, and total neurons defines MLP architecture. Modifying these can completely change its behavior and could also affect its capacity to find patterns and learn from them [18]. The architecture proposed here for P300 discrimination consists of a net with four hidden layers of 60, 40, 30, and 20 neurons on each, respectively. Each neuron has a hyperbolic tangent sigmoid as its activation function, except for the output one, which is a logistic sigmoid.
Support Vector Machine
It is a machine learning algorithm for binary classification. The idea behind its classification criteria is the construction of a decision hyperplane in a high dimensional feature space were input vectors are mapped [19]. This decision boundary can be linear or nonlinear depending on the kernel employed, and it has a direct impact on the model generalization or learning capability. An SVM with a Gaussian or radial basis function (RBF) kernel is trained for P300 discrimination in EEG signals.
Classifiers Training and Validation
The classification accuracy of each classifier is obtained after fivefold cross-validation. For the MLPs, the inputs were renormalized from −1 to 1 before these enter the net. In each subject training stage, the number of epochs used was defined trying to achieve the net full convergence. All subjects required only 150 epochs except for subjects S03, S04, and S07, which required 300, 2000 and 2500 epochs, respectively. The algorithm used in the MLPs training process was the scaled conjugate gradient backpropagation. The training stage for each MLP took approximately three minutes using an Nvidia GTX 1050 Graphics Processing Unit (GPU) for the calculations; and for the SVM classifiers, it took less than one minute in an Intel Core i7 CPU.
4 Results and Discussions
In this section, we compare the performance of the classifiers for all the subjects. Table 2 presents the classification accuracy of the two classifiers in the training and testing stage. It also highlights which of the two classifiers obtained higher results in testing for a single subject. Overall, the performance of each healthy subject was similar and above 80% with the exception of S04. Clearly, the MLP model achieved a higher precision in classification over the SVM one. Nonetheless, both classifiers can be used for the design of a P300 based BCI.
The performance of patients S08 and S09 was similar and even better than most healthy subjects. The P300 waveform in subjects S01 and S08 was apparently easily recognized by the MLP yielding the highest accuracies in classification. However, patient S07 performance was the lowest in comparison with the rest. A possible explanation for this is the patient critical condition (hemorrhagic stroke). Our results show that patients who had suffered ischemic strokes are able to use a BCI based on the P300 paradigm as their average classification accuracy is greater than 80%. In comparison with our previous work [15], both classifiers presented here outperformed the Adaptive Neuro-Fuzzy Inference Systems (ANFIS) ensemble for the healthy subjects (S01, S02, S03, and S06) and post-stroke patients (S08 and S09).
5 Conclusions and Future Work
A comparison between the SVM and MLP classifiers for P300 discrimination in EEG signals was presented. Both obtained significant results for the two types of subjects present in this study. Patients who had suffered an ischemic stroke seem to be suitable users of a P300-based BCI since their performances were similar to the healthy ones. However, patients with more critical conditions, like the one who had experienced a hemorrhagic stroke, may require another type of classifier with more learning capabilities or a longer training period.
As future work, we intend to validate these classifiers with more post-stroke patients and include amyotrophic lateral sclerosis (ALS) ones. We will also extend the methodology presented in this work by employing deep learning tools and extreme learning machine algorithms.
References
Wang, Y.T., Nakanishi, M., Wang, Y., Wei, C.S., Cheng, C.K., Jung, T.P.: An online brain-computer interface based on SSVEPs measured from non-hairbearing areas. IEEE Trans. Neural Syst. Rehabil. Eng. 25, 14–21 (2017)
Lotte, F., Bougrain, L., Cichocki, A., Clerc, M., Congedo, M., Rakotomamonjy, A., Yger, F.: A review of classification algorithms for EEG-based brain–computer interfaces: a 10 year update. J. Neural Eng. 15, 031005 (2018)
Farwell, L.A., Donchin, E.: Talking off the top of your head: toward a mental prosthesis utilizing event-related brain potentials. Electroencephalogr. Clin. Neurophys. (1988)
Han-Jeong Hwang, S.C., Kim, S., Im, C.-H.: EEG-based brain–computer interfaces: a thorough literature survey. J. Human–Comput. Interact. 29, 814–826 (2013)
Hoffmann, U., Vesin, J.-M., Ebrahimi, T., Diserens, K.: An efficient P300-based brain–computer interface for disabled subjects. J. Neurosci. Methods 167(1), 115–125 (2008)
Turnip, A., Soetraprawata, D.: The performance of EEG-P300 classification using backpropagation neural networks. Mechatron. Electr. Power, Veh. Technol. 4(2), 81–88 (2013)
He, S., Huang, Q., Li, Y.: Toward improved p 300 speller performance in outdoor environment using polarizer. In: 2016 12th World Congress on Intelligent Control and Automation (WCICA), pp. 3172–3175, June 2016
Alhaddad, M.J., Kamel, M.I., Bakheet, D.M.: P300-brain computer interface based on ordinal analysis of time series. In: 2014 International Conference on Computational Science and Computational Intelligence (2014)
Krusienski, D.J., Sellers, E.W., Cabestaing, F., Bayoudh, S., McFarland, D.J., Vaughan, T.M., Wolpaw, J.R.: A comparison of classification techniques for the p300 speller. J. Neural Eng. 3(4), 299 (2006)
Speier, W., Arnold, C., Lu, J., Deshpande, A., Pouratian, N.: Integrating language information with a hidden markov model to improve communication rate in the p300 speller. IEEE Trans. Neural Syst. Rehabil. Eng. 22, 678–684 (2014)
Masud, U., Baig, M.I., Akram, F., Kim, T.: A p 300 brain computer interface based intelligent home control system using a random forest classifier. In: 2017 IEEE Symposium Series on Computational Intelligence (SSCI), pp. 1–5, Nov 2017
Carabalona, R., Grossi, F., Tessadri, A., Castiglioni, P., Caracciolo, A., de Munari, I.: Light on! real world evaluation of a p300-based brain–computer interface (BCI) for environment control in a smart home. Ergonomics 55(5), 552–563 (2012)
Sellers, E.W., Vaughan, T.M., Wolpaw, J.R.: A brain-computer interface for long-term independent home use. Amyotrophic Lateral Sclerosis 11(5), 449–455 (2010)
Holzner, C., Guger, C., Edlinger, G., Gronegress, C., Slater, M.: Virtual smart home controlled by thoughts. In: 2009 18th IEEE International Workshops on Enabling Technologies: Infrastructures for Collaborative Enterprises, pp. 236–239, June 2009
Achanccaray, D., Flores, C., Fonseca, C., Andreu-Perez, J.: A p 300-based brain computer interface for smart home interaction through an ANFIS ensemble. In: 2017 IEEE International Conference on Fuzzy Systems (FUZZ-IEEE), pp. 1–5, July 2017
Gupta, L., Molfese, D.L., Tammana, R.: An artificial neural-network approach to ERP classification. Brain Cogn. 27(3), 311–330 (1995)
Winston, P.H.: Artificial Intelligence, 3rd edn. Addison-Wesley Longman Publishing Co., Inc., Boston, MA, USA (1992)
Wu, F.Y., Slater, J.D., Honig, L.S., Ramsay, R.E.: A neural network design for event-related potential diagnosis. Comput. Biol. Med. 23(3), 251–264 (1993)
Cortes, C., Vapnik, V.: Support-vector networks. Mach. Learn. 20(3), 273–297 (1995)
Acknowledgements
This work used the database made in a collaborative project between the Universidad Cayetano Heredia and the Universidad de Ingeniería y Tecnología supported by the Programa Nacional de Innovación para la Competitividad y Productividad of Peru, under the grant PIAP-3-P-483-14.
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 The Editor(s) (if applicable) and The Author(s), under exclusive license to Springer Nature Switzerland AG
About this paper

Cite this paper
Cortez, S.A., Flores, C., Andreu-Perez, J. (2021). A Smart Home Control Prototype Using a P300-Based Brain–Computer Interface for Post-stroke Patients. In: Iano, Y., Arthur, R., Saotome, O., Kemper, G., Borges Monteiro, A.C. (eds) Proceedings of the 5th Brazilian Technology Symposium. Smart Innovation, Systems and Technologies, vol 202. Springer, Cham. https://doi.org/10.1007/978-3-030-57566-3_13
Download citation
DOI: https://doi.org/10.1007/978-3-030-57566-3_13
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-57565-6
Online ISBN: 978-3-030-57566-3
eBook Packages: EngineeringEngineering (R0)