
Abstract
One of the applications of image processing and computer vision is to detect the skin regions for a wide range of human–computer interaction and content based utilizations. Detecting nude parts in the movies, face detection, tracking of human body parts, and people recognizing in multimedia databases are a small part of its applications. Therefore, designing an efficient technique for skin area detection can help a lot to the determined applications. The grasshopper optimization algorithm is a new optimization algorithm evolutionary algorithm which is recently introduced to solve optimization problems. The main purpose of this paper is to propose a newly developed version of this algorithm to optimize the weights of the backpropagation neural network to design a good segmentation tool for skin area segmentation. The method has been compared with the traditional multi-layer perception and the ICA-MLP to declare the proposed method’s efficiency.
Access provided by Autonomous University of Puebla. Download chapter PDF
Similar content being viewed by others


Keywords
- Skin segmentation
- Artificial neural network
- Grasshopper optimization algorithm
- Modified
- Mathematical morphology
1 Introduction
The science of image processing is one of the most useful sciences in engineering applications and has been extensively studied and researched in the field for many years. The speed of these advances has been so rapid, that now, after a short period of time, the impact of image processing can be clearly seen in many sciences and industries. While some of these applications are dependent on image processing, they cannot be used without it. As the science of image processing is integrated and specialized in today’s world, it is becoming more and more important. Recently, human skin area detection has found a wide range of applications in image processing. This field has several utilizations in the human–computer interaction domains [1]. Applications such as face detection [2], detecting and tracking of human body parts [3], naked people detection [4], and people retrieval in multimedia databases [5], all benefit from skin detection [6]. Also, color-based skin detection gains attention in contributing to blocking objectionable images or video content on the Internet automatically [7].
Using the color-based skin detection has an advantage toward grayscale-based one due to the extra dimensions of color such that it may happen a situation in which two objects have similar gray tones but different color space textures. This shows that human skin has a feature for easily recognizing the humans [2]. The color-space features are pixel-based characteristics that need no spatial context which improves its orientation and size invariant and the processing period.
In the recent decade, the applications of artificial neural networks have been increasing exponentially due to its potency in modeling complicated systems [6,7,8]. Using an artificial neural network (ANN) classifiers for skin-like pixels segmentation is a principal step of skin detection that requires a suitable insulator between the skin and the environment. Among different types of ANNs, a multi-layer perceptron (MLP) network have a wide application due to its simplicity and good efficiency. The connection weights and biases of the MLP networks have been trained normally by a backpropagation learning algorithm [9].
The backpropagation learning algorithm is a classic learning algorithm which is so complicated for big networks. It also has a big problem with trapping in the local minimum to find the minimum error. Several approaches have been used in solving this problem. One of the useful approaches is to use meta-heuristic algorithms. There are different types of meta-heuristics such as Genetic Algorithm (GA) [10], world cup optimization algorithm (WCO) [11], variance reduction of Gaussian distribution (VRGD) algorithm [12], humpback whale optimization (HWO) algorithm [13], Emperor penguin optimizer (EPO) [14]. Meta-heuristic algorithms can improve the ANN efficiency by applying to the different levels such as weight training, learning rules, architecture adaptation (for determining the number of hidden layers, and a number of node transfer functions and hidden neurons).
This study focuses on the weight optimization of ANN to propose an optimized algorithm for better classification of the skin pixels detection. To do so, a new improved meta-heuristic technique called modified grasshopper optimization algorithm has been utilized for optimizing the weights of Multilayer Perceptron (MLP).
2 RGB Color Space
The purpose of selecting a color model is to facilitate the identification of colors in a standard. In essence, the color model defines a three-dimensional and sub-spatial coordinate system within that system in which each color system is expressed by a single point. Most color models now in use tend toward hardware such as monitors and color printers or applications that aim to work with color, such as producing color graphics for animation. RGB model (blue, red, green) is one of the most common hardware-oriented models for color screens. This model is based on the Cartesian coordinate system. Because of the cube’s favorite color space is the image below. In the RGB model, the gray range from black to white is along the line and origin of these two points, and the other colors are points on or inside the cube defined by vectors passing through the origin. To simplify the model, it is assumed that all color values are aligned such that the image cube is below the unit cube, meaning that all values of G, R and B are in the range of [0, 255].
Each image in the RGB color model has three separate pages, each page being the primary color. When these three pages are given to the RGB display, they are combined on the phosphor screen to produce a color image.
So when the images themselves are naturally expressed in terms of three color pages, it makes sense to use the RGB model for image processing. Also, most color cameras use this format for digital imaging, which makes the RGB model an important model in image processing. As can be seen in Fig. 1, the RGB color space is a single cube and each axis represents one of the primary colors. The coordinate origin is where the cube lacks three primary colors and this dot represents black, while the opposite vertex is the combination of three primary colors, and this dot in the cube represents white.

The RGB color cube
The other vertices represent the cyan, purple and yellow secondary colors, each of which comes from a combination of two primary colors. In this model, all other colors within the cube are specified by three components, each point specifying the number of primary colors needed to create a particular color. Each of these components is usually specified by one byte. For example, light red has the value [255, 0, 0] and light yellow the value [255, 255, 0]. Since red, blue and green can be independently assigned, 2563 colors can be produced with three main colors. In the image file, three pages, or rather three matrices, each page is the same color, is used to store each image. Since each pixel is indicated by three bytes, the image depth is 24 bits, and the size of each color image is three times the size of a gray-level image. RGB color images are also known as true color or 24-bit images. Figure 1 shows the RGB Color Cube.
A sample of the 3D plot for skin and non-skin pixels in this space is shown in Fig. 2.

Analysis of skin colors in the RGB color-space: 3D-plot of skin (blue), 3D-plot of non-skin (red); the skin colors approximately distributed in a linear fashion in the RGB color space
3 Skin Color Feature Extraction
The main application of machine learning algorithms is to extract or learn from existing data. Like a child who learns by observing people and parental recommendations. For example, he or she can figure out whether the heater is hot or should not go down the street alone. In fact, machine learning algorithms work to find a summarize of data or to actually create a model of data in any way. As you know, a model always contains a summary of the data. The World Map, for example, is a model of the world that models countries and roads without much detail (for example, what shop is on the street).
Supervised classification is a type of machine learning in which input and output are specified and there is a so-called supervisor that provides information to the learner, thereby trying to learn a function from input to output. After extracting the RGB color information from the input image for skin region detection, it should be used as input data for the classifier to the classification. Image classification is a principal tool in image processing with different applications. This tool can be also utilized for image segmentation which is our purpose in this study. The classifier system divides the input data into two parts of the training and testing categories. In this study, 60% of data has been utilized for training and the 40% remained data have been selected as the testing set. Figure 3 shows the steps of classification.

Steps in supervised classification
4 The Improved Grasshopper Optimization Algorithm
4.1 The Standard Grasshopper Optimization Algorithm
The grasshopper optimization algorithm (GOA) is a new swarm-based optimization algorithm that is derived from grasshopper insect behavior [15].
In this algorithm, the population includes a collective of grasshoppers which is called a swarm. Each member of the swarm is a probable solution to the problem. The first step is started by generating a random swarm as the initial solution to the problem [16]. Then, the cost of each grasshopper is determined by obtaining the value of the cost function.
The process is continuous by absorbing the swarm via considered grasshoppers into their location to attract the grasshoppers to move into the considered grasshopper. Here, two main behaviors of the grasshoppers are considered: the tiny and slow movement of the larval grasshoppers in order to the long-range and no sequence movement drive adults and food searching process which is divided into two separate parts of exploitation and exploration.
The development of the ith grasshopper next to the target grasshopper is defined by Pi and is obtained as below:
where, \(GF_{i}\) describes the gravity force on the ith grasshopper, \(WA_{i}\) is the wind advection, and \(SA_{i}\) describes the social interaction, and R1, R2, and R3 are random constants in the interval [0, 1].
The social interaction of the ith grasshopper (\(SA_{i}\)) related to the social forces between two grasshoppers and is a repulsion force to stop collisions and an attraction force purpose over a small length scale.
where, \(D_{lk}\) describes the length of the Euclidian of the kth with the lth position grasshopper, and \(\hat{D}_{lk}\) represents the present unit vector between the lth grasshopper and the kth grasshopper.
The intensity attraction strength is modeled by the following formula:
where, SF determines the strong point of the social forces that are evaluated by the following:
where, L describes the length scale of attraction, and fi is the intensity force of attraction.
GF is another parameter of the algorithm that is achieved as follows:
where, Gi describes a constant for the gravity force, and \(\widehat{e}_{g}\) is a direction for unity vector alongside the wind.
The wind advection model (WAi) is finally obtained as follows:
where, U describes the drift constant.
The gravity assumptions and wind effects can be formulated as follows:
where, N is the grasshoppers quantity, \(LB_{d}\) and \(UB_{d}\) are the lower and the upper limitations in the dth dimension, respectively, \(\mathop {T_{d} }\limits^{ \wedge }\) acts objective magnitude of dth dimension by the objective grasshopper, c describes the reducing factor to the proper area of the repulsion region and attraction region, \(c_{\max }\) and \(c_{\min }\) are the highest value and the lowest value of the factor c, respectively, and finally, l and L are the current iteration and the total number of iteration, respectively.
4.2 Improved Grasshopper Optimization Algorithm Based on Chaos Theory
In this subsection, a technique is proposed for modifying the essential parameters of the Grasshopper optimization algorithm to improve its convergence speed. The keys parameters of Grasshopper optimization algorithm convergence are R1, R2, R3, and U. the modification is applied based on chaos theory.
Chaos theory is the study of unpredictable and random processes. The main idea of the chaos theory is to study the highly sensitive dynamic systems that can be affected by any small variations.
By the explanations above, a large diversity can be made for the swarm generation in GOA to improve the diversity of the algorithm.
This part improves the GOA algorithm capability from the point of the convergence speed and also for escaping from falling into the local optimal point [17, 18]. A general form for the chaos theory is formulated below:
where, k describes the map dimension, and \(f(CM_{i}^{j} )\) is the chaotic model generator function.
In the presented GOA, the parameters R1, R2, R3, and U are modeled based on the Singer mechanism chaotic map as follows:
where, k is the number of iteration.
Figure 4 shows the flowchart diagram of the presented CGOA.

The diagram flowchart of the CGOA
4.3 Validation of the CGOA
For performance analysis of the presented method, 4 standard test functions have been studied. Experimental simulation s of the presented CGOA are compared with some different popular and newly introduced algorithms including genetic algorithm (GA) [10], shark smell optimization (SSO) algorithm [19], particle swarm optimization algorithm (PSO) [20], world cup optimization algorithm (WCO) [11], and the original grasshopper optimization algorithm (GOA) [16].
The simulations are established based on MATLAB R2017b platform on a laptop computer with processor Intel® CoreTM i7-4720 HQ CPU@2.60 GHz with 16 GB RAM. Table 1 demonstrates the results of the simulation.
The results of the mean deviation (MD) and the standard deviation (SD) values of the methods for the analyzed benchmarks are illustrated in Table 2.
The results from Table 2 show that in all four benchmarks, the proposed CFSO algorithm gives satisfying results toward the other methods, especially the original FSO algorithm.
5 Artificial Neural Network
The very high speed and processing power of the human brain go back to the very large interconnections that exist between the brain-forming cells, and basically, without these communication links, the human brain would be reduced to a normal system and certainly not have the current capabilities. After all, the brain’s excellent performance in solving a variety of problems and its high performance has made brain simulation and its capabilities the most important goal of hardware and software architects. In fact, if there is a day (but apparently not too far away) that we can build a computer with the same capabilities of the human brain, there will surely be a major revolution in science, industry, and of course, human life. Since the decades that computers have enabled computational algorithms to simulate human computational behavior, much research has been undertaken by computer scientists, engineers, and mathematicians, whose results are in the field of artificial intelligence and it is classified under the subcategory of computational intelligence as the topic of “Artificial Neural Networks”. In the field of artificial neural networks, numerous mathematical and software models have been proposed to inspire the human brain which is applied to solve a wide range of scientific, engineering and practical problems in various fields.
Several types of computational models have been introduced as generic artificial neural networks, each of which can be used for a variety of applications, each inspired by a particular aspect of the capabilities and properties of the human brain. In all of these models, a mathematical structure is assumed to be graphically presentable and has a set of adjustable parameters. This general structure is adjusted and optimized by a training algorithm so that it can exhibit good behavior. A look at the learning process in the human brain also shows that we actually experience a similar process in the brain and all of our skills, knowledge, and memories are shaped by the weakening or strengthening of the communication between neurons. This reinforcement and weakening in mathematical language model and describe itself as a parameter (called Weight). One of the most basic neural models available is the Multi-Layer Perceptron (MLP) model that simulates the transient function of the human brain. In this type of neural network, most of the network behavior of the human brain and its signal propagation has been taken into account, and hence are sometimes referred to as Feedforward Networks. Each of the neurons in the human brain, called neurons, processes it after receiving input (from one neuronal or non-neuronal cell) and transmits the result to another cell (neuronal or non-neuronal). This behavior continues until a definite result is reached, which may eventually lead to a decision, process, thought, or move. The most popular method in the feed-forward networks is backpropagation (BP). This method evaluates the error on all of the training pairs and adjusts the weights to fit the desired output. To do so, several epochs have been considered and the process continues until achieving the minimum value for the total error on the training set or until the termination criteria are reached.
This method adopts supervised learning to train the network using the data for which inputs, as well as target outputs, are noticed. After training, the weights of the networks are fixed and can be employed for evaluating the output values of the new given samples.
BP is a method based on gradient descent algorithm on the error space that sometimes gets trapped into the local minimum, succeeded it entirely dependent on initial (weight) settings. This drawback can be covered by an exploration searching capability of the evolutionary algorithms.
6 ANN Weights Evolution Using CGOA
Due to modeling by artificial neural networks, they can obtain the desired precision to determine the optimal network architecture by receiving feedback from the network and the test process and time consuming, but this increases the hidden layers and the complexity of the neural network architecture. CGOA can be used as a method to find optimal values of different neural network parameters. This algorithm starts the search with a primitive set of random solutions called the initial population and can perform multilaterally and user searches on a population of variables that increase the likelihood of finding the global optimal point. This algorithm can then simultaneously determine the optimal network structure and weights using a function that is a measure of the optimal performance quality of the response produced. The method of optimal parameter selection of the weights based on the proposed grasshopper optimization algorithm can be formulated as follows:
-
1.
Start algorithm
-
2.
Generate N number of initial random grasshoppers as the weight of the network
-
3.
Calculate the cost of the network based on each grasshopper
-
4.
Apply the CGOA operators to each of the grasshoppers to generate the next generation
-
5.
If the termination condition is reached, go (5), else go (2)
-
6.
End of algorithm.
Consider a simple multi-layer perceptron network with its weights (w) and biases (b):
where, H is the number of neurons in the hidden layer, w describes the weights of the network, b denotes the bias value and f is the activation function of each neuron which in this case is considered as sigmoid.
The network can be optimized by optimal selection of the weights and biases based on minimizing the mean squared error of the network (MSE) as follows:
where, m describes the output nodes number, g represents the number of training samples, \(Y_{j} (k)\) is the desired output, and \(T_{j} (k)\) describes the real output.
7 Dataset Description
We used the Bao dataset to show our proposed method; this database includes 370 face images from various races, with 221 images with multiple people and other 149 images of one person mostly from Asia, with a wide range of size, lighting and background. In this paper, Bao Face Database has been utilized. This database is introduced by Frischholz that includes 370 face images from different races, mostly from Asia, with a wide range of size, lighting and background [21]. The database has no using or distribution policies or license.
8 Simulation Results
This study considers two categories including skin and non-skin classes. The method is based on pixels information that uses this information for classifying the skin-like and non-skin-like pixels one by one. This method reduces the image information into objects of interest, like faces or hands during skin pixels detection.
The input of the proposed classifier is a matrix of 3 × n pixel coefficients from the images either skin or non-skin image which n determines the number of neurons in the hidden layer. Since the employed transfer function is sigmoid, the output image gives different values in the range 0 and 255 (uint8 mode).
Since we need two labels in the final output (skin or non-skin), the output of the neural classifier should be thresholded so that it is either 0 or 1. In this study, Otsu thresholding has been used for this purpose, such that the output values of the neural network have been classified into two categories of 0 and 1 [22].
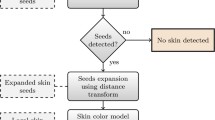
After thresholding the output, mathematical morphology has been applied to remove the extra parts. In this study, three operators have been utilized including opening, closing and filing holes [23]. Figure 5 shows the impact of the mathematical morphology on the images.

a Original image, b skin region segmentation and thresholding, c applying mathematical morphology, d skin area detection
For validating the efficiency in the proposed system, three performance indices have been employed. The first metric is the false acceptance rate (FAR) that defines the ratio of the identification moments in which false acceptance happens. The second index is the false rejection rate (FRR) which is the percentage of the identification moments in which false rejection happens and the final index is the correct detection rate (CDR) which shows the correctly classified pixels to the total pixels.
Figure 6 shows the utilized test set from the skin and the non-skin to measure the metric efficiency.

Test set: A skin sets, B non-skin sets
Here, the least mean square error minimization has been utilized for improving the network weights between the desired and the real outputs of the network. Comparison results of the proposed method with basic MLP and HNN-ICA [6] are tabulated in Table 3. As can be observed, the proposed optimized network performs better and gives a higher correct detection rate.
Figures 7 and 8 show the extent of the match between the measured and predicted skin rate of the train set and validation phases by CGOA-ANN in terms of a scatter diagram.

Real output and CGOA-ANN network output for the training data

Real output and CGOA-ANN network output for the test data
For more clarification, some sample outputs have been shown in Fig. 9. As can be observed, using the proposed CGOA-ANN classifier gives satisfying results for skin regions detection including face, hands, and neck.

Experimental results for skin region detection: a original image, b skin segmented result
9 Conclusion
This paper proposed a new optimized method for skin area classification. A new improved version of the grasshopper optimization algorithm was adopted to decrease the mean square error of the neural network to escape from the local minimum. Here, RGB color space was utilized for decreasing the computational cost. The proposed algorithm reduces the number of false detection ratio toward a gradient descent algorithm. The skin region detection method based on CGOA-ANN is compared with some methods to validate and analyze the efficiency.
References
Rashid Sheykhahmad F, Razmjooy N, Ramezani M (2015) A novel method for skin lesion segmentation. Int J Inf Secur Syst Manag 4:458–466
Sun X, Wu P, Hoi SC (2018) Face detection using deep learning: an improved faster RCNN approach. Neurocomputing 299:42–50
Jalal A, Kamal S, Azurdia-Meza CA (2019) Depth maps-based human segmentation and action recognition using full-body plus body color cues via recognizer engine. J Electr Eng Technol 14:455–461
Tian C, Zhang X, Wei W, Gao X (2018) Color pornographic image detection based on color-saliency preserved mixture deformable part model. Multimed Tools Appl 77:6629–6645
Aygun R, Benesova W (2018) Multimedia retrieval that works. In: 2018 IEEE conference on multimedia information processing and retrieval (MIPR), pp 63–68
Razmjooy N, Mousavi BS, Soleymani F (2013) A hybrid neural network Imperialist Competitive Algorithm for skin color segmentation. Math Comput Model 57:848–856
Razmjooy N, Ramezani M (2016) Training wavelet neural networks using hybrid particle swarm optimization and gravitational search algorithm for system identification. Int J Mechatron Electr Comput Technol 6:2987–2997
Razmjooy N, Sheykhahmad FR, Ghadimi N (2018) A hybrid neural network–world cup optimization algorithm for melanoma detection. Open Med 13:9–16
Zhang Z (2018) Artificial neural network. In: Multivariate time series analysis in climate and environmental research. Springer, pp 1–35
Holland JH (1992) Genetic algorithms. Sci Am 267:66–73
Razmjooy N, Khalilpour M, Ramezani M (2016) A new meta-heuristic optimization algorithm inspired by FIFA world cup competitions: theory and its application in PID designing for AVR system. J Control Autom Electr Syst 27:419–440
Namadchian A, Ramezani M, Razmjooy N (2016) A new meta-heuristic algorithm for optimization based on variance reduction of Gaussian distribution. Majlesi J Electr Eng 10:49
Clapham PJ (2000) The humpback whale. In: Cetacean societies, field studies of dolphins and whales. The University of Chicago, Chicago, pp 173–196
Dhiman G, Kumar V (2018) Emperor penguin optimizer: a bio-inspired algorithm for engineering problems. Knowl-Based Syst 159:20–50
Mirjalili S, Lewis A (2016) The whale optimization algorithm. Adv Eng Softw 95:51–67
Mirjalili SZ, Mirjalili S, Saremi S, Faris H, Aljarah I (2018) Grasshopper optimization algorithm for multi-objective optimization problems. Appl Intell 48:805–820
Yang D, Li G, Cheng G (2007) On the efficiency of chaos optimization algorithms for global optimization. Chaos Solitons Fract 34:1366–1375
Rim C, Piao S, Li G, Pak U (2018) A niching chaos optimization algorithm for multimodal optimization. Soft Comput 22:621–633
Abedinia O, Amjady N, Ghadimi N (2018) Solar energy forecasting based on hybrid neural network and improved metaheuristic algorithm. Comput Intell 34:241–260
Bansal JC (2019) Particle swarm optimization. In: Evolutionary and swarm intelligence algorithms. Springer, pp 11–23
Frischholz R (2012) Bao face database at the face detection homepage
Otsu N (1979) A threshold selection method from gray-level histograms. IEEE Trans Syst Man Cybern 9:62–66
Razmjooy N, Mousavi BS, Soleymani F (2012) A real-time mathematical computer method for potato inspection using machine vision. Comput Math Appl 63:268–279
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2021 Springer Nature Switzerland AG
About this chapter

Cite this chapter
Razmjooy, N., Razmjooy, S., Vahedi, Z., Estrela, V.V., de Oliveira, G.G. (2021). Skin Color Segmentation Based on Artificial Neural Network Improved by a Modified Grasshopper Optimization Algorithm. In: Razmjooy, N., Ashourian, M., Foroozandeh, Z. (eds) Metaheuristics and Optimization in Computer and Electrical Engineering. Lecture Notes in Electrical Engineering, vol 696. Springer, Cham. https://doi.org/10.1007/978-3-030-56689-0_9
Download citation
DOI: https://doi.org/10.1007/978-3-030-56689-0_9
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-56688-3
Online ISBN: 978-3-030-56689-0
eBook Packages: Computer ScienceComputer Science (R0)