
Abstract
Uncertain data classification makes it possible to reduce the decision risk through abstaining from classifying uncertain cases. Incorporating this idea into the process of computer aided diagnosis can greatly reduce the risk of misdiagnosis. However, for deep neural networks, most existing models lack a strategy to handle uncertain data and thus suffer the costs of serious classification errors. To tackle this problem, we utilize Dempster-Shafer evidence theory to measure the uncertainty of the prediction output by deep neural networks and thereby propose an uncertain data classification method with evidential deep neural networks (EviNet-UC). The proposed method can effectively improve the recall rate of the risky class through involving the evidence adjustment in the learning objective. Experiments on medical images show that the proposed method is effective to identify uncertain data instances and reduce the decision risk.
Access provided by Autonomous University of Puebla. Download conference paper PDF
Similar content being viewed by others


Keywords
1 Introduction
In data classification tasks, the data instances that are uncertain to be classified form the main cause of prediction error [2, 9, 23]. Certain classification methods strictly assign a class label to each instance, which may produce farfetched classification results for uncertain instances. Uncertain classification methods aim to measure the uncertainty of data instances and accordingly reject uncertain cases [3, 10, 15]. The methodology of uncertain classification is helpful to reduce the decision risk and involve domain knowledge in classification process [21, 22, 24]. For instance, in decision support for cancer diagnosis, filtering out uncertain cases for further cautious identification, may allow us to avoid serious misdiagnosis [1].
Due to their very good performance, deep neural networks have been widely used in the classification of complex data [14, 17], such as various kinds of medical images. However, most existing deep neural networks lack a strategy to handle uncertain data and may produce serious classification mistakes. For example, classifying CT images using convolutional neural networks without considering uncertainty may lead to overconfident decisions.
Trying to implement uncertain data classification based on deep neural networks, Geifman and El-Yaniv propose a selective classification method with deep neural networks, in which a selection function is constructed to quantify the reliability of predictions [8, 11]. The method relies on the quality of the selection function. If the quantification of reliability is not accurate, the identification of uncertain data cannot be guaranteed. Dempster-Shafer (D-S) evidence theory [5] is also used to measure the uncertainty in machine learning models [6, 7, 20]. Sensoy, Kaplan and Kandemir formulate the uncertainty in deep neural networks from the view of evidence theory [18]. Moreover, evidential neural networks have been constructed and applied for the uncertain classification of medical images [13, 19]. However, if the decision costs of different classes are imbalanced, evidential neural networks are not effective to classify the uncertain data instances of the risky class.
To address these problems, we construct a novel evidential deep neural network model and propose an uncertain data classification method. We formalize the uncertainty of the prediction output with evidence theory. A strategy to adjust the uncertainty in classification is also designed to improve the identification of certain and uncertain data instances in the risky class. The contributions of this paper are summarized as follows:
-
Propose a novel evidential deep neural networks with the loss objective of both prediction error and evidence adjustment;
-
An uncertain data classification method based on evidential deep neural networks (EviNet-UC) is proposed and applied to medical image diagnosis.
The rest of this paper is organized as follows. Section 2 presents the uncertain data classification method with evidential deep neural networks, which includes the model description and the strategy for uncertain data identification. In Sect. 3, we apply the proposed uncertain classification method to medical image data sets and show that the proposed method is effective to reduce the decision costs. Conclusions are given in Sect. 4.
2 Uncertain Data Classification with Evidential Deep Neural Networks
Given a dataset \(\mathcal {D}=\left\{ x_{i}, y_{i}\right\} _{i=1}^{N}\) of N labeled data instances where \(y_{i}\) is the class label of the instance \(x_{i}\), the loss of data classification with the evidential deep neural networks consists of the prediction error term \(L_{i}^{p}\) and the evidence adjustment term \(L_{i}^{e}\) as
where \(\lambda =\min (1.0, t/10)\) is the annealing coefficient to balance the two terms, t is the index of the current training epoch. At the beginning of model training, \(\lambda <1\) makes the network focus on reducing the prediction error. When \(t \ge 10\) the two terms play equal roles in the loss.
2.1 Prediction Error
For the binary classification of \(x_{i}\), we define the model output \(e_{i}^{+}, e_{i}^{-}\) as the evidence collected by the deep neural network for the positive and negative classes. The sum of the total evidence is \(E=e_{i}^{+}+e_{i}^{-}+2\). According to the evidence, we define the belief values of \(x_{i}\) belonging to positive and negative classes as \(b_{i}^{+}=e_{i}^{+}/E, b_{i}^{-}=e_{i}^{-}/E\), the uncertainty of classification is defined as \(u_{i}=1-b_{i}^{+}-b_{i}^{-}\). Similar to the model proposed in [13], we adopt Beta distribution to formulate the distribution of the prediction with the evidences \(e_{i}^{+}, e_{i}^{-}\). Suppose \(p_{i}\) is the prediction of the instance \(x_{i}\) belonging to the positive class, the probability density function of the prediction is
where the parameters of Beta distribution are \(\alpha _{i}=e_{i}^{+}+1, \beta _{i}=e_{i}^{-}+1\) and \(\varGamma (\cdot )\) is the gamma function. The prediction of the positive class can be obtained by \(p_{i}=\alpha _{i}/E\) and \(1-p_{i}=\beta _{i}/E\) denotes the prediction of negative class.
Based on the probability density of the prediction, we construct the prediction error term for each data instance \(x_{i}\) as the following expectation of squared error,
Referring to the properties of the expectation and variance of Beta distribution, the formula (4) can be derived as
2.2 Evidence Adjustment
Besides the prediction error, the uncertain cases in the classification should also be considered in real application scenarios. Identifying uncertain data instances for abstaining from classification is helpful to reduce the decision risk. In [13], a regularization term is integrated into the objective of neural network to reduce the evidences of uncertain instances. But this strategy ignores the difference of the risks of uncertain instances from different classes. To find out the uncertain instances of risky class effectively, we expect to rescale the data uncertainty u through adjusting the evidence and add an evidence adjustment term into the loss objective. The evidence adjustment term is constructed by the Kullback-Leibler divergence between the distributions of prediction with original and adjusted evidences. We also adopt the Beta distribution for the prediction with adjusted evidences and define \(\lambda >1\) as the evidence adjustment factor. The evidence adjustment term is expressed as
where \((1, \tilde{\lambda })=\left( 1, y_{i} \lambda +\left( 1-y_{i}\right) \right) \), \(\left( \tilde{\alpha }_{i}, \tilde{\beta }_{i}\right) =\left( \left( 1-y_{i}\right) \alpha _{i}+y_{i}, y_{i} \beta _{i}+\left( 1-y_{i}\right) \right) \) are the parameters of the Beta distributions of the prediction \(p_{i}\) with adjusted and original evidences.
Let ‘1’ denote the positive class and ‘0’ denote the negative class. When the instance \(x_{i}\) belongs to positive class, \(y_{i}=1,(1, \tilde{\lambda })=(1, \lambda )\) and \(\left( \tilde{\alpha }_{i}, \tilde{\beta }_{i}\right) =\left( 1, \beta _{i}\right) \). If \(x_{i}\) belongs to negative class, \(y_{i}=0,(1, \tilde{\lambda })=(1,1)\) and \(\left( \tilde{\alpha }_{i}, \tilde{\beta }_{i}\right) =\left( \alpha _{i}, 1\right) \). For a negative-class instance, the adjustment term guides the parameter \(\alpha _{i}\) to 1 and thereby reduce the evidence of positive class to 0. For a positive-class instance, the adjustment term guides the parameter \(\beta _{i}\) to \(\lambda \). This will force the neural networks to promote the positive-class evidence for certain positive instances to reduce the prediction error.
According to the definition of KL divergence, the evidence adjustment term can be further simplified as
Referring to the properties of Beta distribution, the expectations in (13) can be further derived for computation as
and
in which \(\psi (\cdot )\) denotes the digamma function.
2.3 Classification of Uncertain Data
As explained above, based on the belief values of \(x_{i}\) belonging to positive and negative classes \(b_{i}^{+}=e_{i}^{+}/E, b_{i}^{-}=e_{i}^{-}/E\), we can measure the classification uncertainty of \(x_{i}\) by \(u_{i}=1-b_{i}^{+}-b_{i}^{-}\). With this uncertainty measure, applying the evidential neural networks to classify data, we can not only assign class labels to instances but also identify the uncertain ones. Through sorting the classified instances according to their uncertainty in ascending order, we select the top k uncertain instances for classification rejection to reduce the prediction risk.

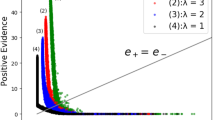
Evidence distribution of positive-class instances with different rejection rates. (a) rejection rate = 0%, (b) rejection rate = 10%, (c) rejection rate = 20%, (d) rejection rate = 30%.
Applying the proposed evidential neural network to the Breast IDC dataset (see the Sect. 3), Fig. 1(a) shows the evidence distribution of all the instances of positive class for multiple values of \(\lambda \). We can see that the factor \(\lambda \) adjusts the evidences of instances and the evidences of certain positive instances are promoted. The data instances with low-level evidences for both classes have high uncertainty in classification. Thus the instances located in the bottom-left corner indicate uncertain cases. Figure 1(b–d) display the evidence distribution of data instances after filtering out 10%, 20%, 30% uncertain instances, respectively. Based on the uncertain data identification strategy, we implement the uncertain data classification method with an evidential neural network (EviNet-UC). The effectiveness of the proposed method will be demonstrated in the following section.
3 Experimental Results
To show that the uncertain classification method with evidential neural network is effective to reduce decision costs, we tested the proposed method on the medical datasets Breast IDC [4] and Chest Xray [16]. The Breast IDC dataset consists of the pathological images of patients with infiltrating ductal carcinoma of the breast. The training set has 155314 images and the test set has 36904 images. We set the cancer case as positive class and the normal case as negative class. The Chest Xray dataset has 2838 chest radiographs, in which 427 images are chosen as the test data and the rest are set as the training data. The pneumonia and normal cases are set as positive class and negative class, respectively. For the algorithm implementation, we constructed the evidential deep neural networks based on the resnet18 architecture [14] and we modified the activation function of the output layer to the ReLU function.
To achieve the overall evaluation of the classification methods, we adopt the measures of accuracy, F1 score, precision, recall rate and decision cost. Suppose the number of the instances of negative class is N and the number of positive-class instances is P, TP and FP denote the numbers of true positive and false positive instances, TN and FN denote the true negative and false negative instances respectively. The measures are defined as
Assuming correct classification to have zero cost, \({\text {cost}}_{N P}, \cos t_{P N}\) denote the costs of false-positive classification and false-negative classification, respectively. The average decision cost of classification can be calculated as
Based on the measures above, we carried out two experiments to evaluate the performance of the proposed uncertain classification method with evidential neural network (EviNet-UC). The first experiment aims to verify the superiority of the classification of the proposed method. Specifically, we compared the EviNet-UC method with other four uncertain classification methods based on deep neural networks: EvidentialNet [13], SelectiveNet [12], Resnet-pd and Resnet-md [19]. For fair comparison, we implemented all the methods above based on the resnet18 architecture.
We set rejection rate = 0 (no rejection), \({\text {cost}}_{P N}=5, \cos t_{N P=1}\) and applied all the classification methods to the Breast IDC dataset. The comparative experimental results are presented in Fig. 2 and Table 1. We can find that the proposed EviNet-UC method achieves the highest recall rate and the lowest decision cost among all the comparative methods. This means that the proposed method is effective to reduce the misclassification of the risky class (cancer case). Moreover, we changed the rejection rate from 0 to 0.5 to further compare the classification methods. Figure 3 presents the recall rates and the decision costs of different methods with different rejection rates. We can see that the EviNet-UC method achieves the best performance for all rejection rates. Compared to other methods, the proposed method is more effective to reduce the classification risk.

Comparative experimental results on Breast IDC dataset.

(a) Recall rates of different classification methods with varying rejection rates, (b) decision costs with rejection rates.
The second experiment aims to show that the proposed method is effective to identify uncertain data. Varying the rejection rate in [0, 1] and applying EviNet-UC on the Chest Xray dataset, we obtained the classification results for different numbers of rejected uncertain radiographs. Figure 4 illustrates the evaluation of the classification based on EviNet-UC with varying rejection rates. It can be seen that accuracy, precision, recall rate and F1 score increase as the rejection rate increases. This indicates that the rejected data instances have uncertainty for classification and the EviNet-UC method can improve the classification results through filtering out the uncertain instances.

Classification evaluation of EviNet-UC with varying rejection rates.

(a) certain negative-class instance (normal case), (b) certain positive-class instance (pneumonia), (c) uncertain normal case, (d) uncertain pneumonia case.
When rejection rate = 10%, Fig. 5 presents the certain and uncertain instances identified by EviNet-UC. Figure 5 (a) shows a certain negative-class instance of normal radiograph, in which the lung area is very clear. EviNet-UC produces high negative probability \(p^{-}\) = 0.95 and low uncertainty u = 0.09 to indicate the confident classification. In contrast, Fig. 5 (b) shows a certain positive-class instance of pneumonia radiograph, in which there exist heavy shadows. Correspondingly, EviNet-UC produces high positive probability \(p^{+}\) = 0.95 and low uncertainty u = 0.1.
Figure 5 (c) displays an uncertain normal case. In general, the lung area is clear but there exists a dense area of nodule in the right part (marked in red circle). EviNet-UC produces high uncertainty u = 0.44 to indicate the judgement is not confident. Figure 5 (d) shows another uncertain case of pneumonia. In the radiograph, there exists a shadow area in the right lung but the symptom is not prominent, which leads to the uncertainty u = 0.35 for pneumonia identification. The uncertain radiographs will be rejected for cautious examination to further reduce the cost of misclassification.
4 Conclusions
Certain classification methods with deep neural networks strictly assign a class label to each data instance, which may produce overconfident classification results for uncertain cases. In this paper, we propose an uncertain classification method with evidential neural networks which measures the uncertainty of the data instances with evidence theory. Experiments on medical images validate the effectiveness of the proposed method for uncertain data identification and decision cost reduction. Our method currently focuses on only binary classification problem and the relationship between the decision cost and the evidence adjustment factor also requires theoretical analysis. Exploring the evidence adjustment factor in multi-class classification problems and constructing the precise uncertainty measurement for reducing decision risk will be future works.
References
Chen, Y., Yue, X., Fujita, H., Fu, S.: Three-way decision support for diagnosis on focal liver lesions. Knowl.-Based Syst. 127, 85–99 (2017)
Chow, C.: On optimum recognition error and reject tradeoff. IEEE Trans. Inf. Theory 16(1), 41–46 (1970)
Cortes, C., DeSalvo, G., Mohri, M.: Boosting with abstention. In: Advances in Neural Information Processing Systems, pp. 1660–1668 (2016)
Cruz-Roa, A., et al.: Automatic detection of invasive ductal carcinoma in whole slide images with convolutional neural networks. In: Medical Imaging 2014: Digital Pathology, vol. 9041, p. 904103. International Society for Optics and Photonics (2014)
Dempster, A.P.: Upper and lower probabilities induced by a multivalued mapping. In: Classic Works of the Dempster-Shafer Theory of Belief Functions, pp. 57–72. Springer (2008). https://doi.org/10.1007/978-3-540-44792-4_3
Denoeux, T.: Maximum likelihood estimation from uncertain data in the belief function framework. IEEE Trans. Knowl. Data Eng. 25(1), 119–130 (2011)
Denoeux, T.: Logistic regression, neural networks and Dempster-Shafer theory: a new perspective. Knowl.-Based Syst. 176, 54–67 (2019)
El-Yaniv, R., Wiener, Y.: On the foundations of noise-free selective classification. J. Mach. Learn. Res. 11(May), 1605–1641 (2010)
Fumera, G., Roli, F.: Support vector machines with embedded reject option. In: Lee, S.-W., Verri, A. (eds.) SVM 2002. LNCS, vol. 2388, pp. 68–82. Springer, Heidelberg (2002). https://doi.org/10.1007/3-540-45665-1_6
Fumera, G., Roli, F., Giacinto, G.: Reject option with multiple thresholds. Pattern Recogn. 33(12), 2099–2101 (2000)
Geifman, Y., El-Yaniv, R.: Selective classification for deep neural networks. In: Advances in Neural Information Processing Systems, pp. 4878–4887 (2017)
Geifman, Y., El-Yaniv, R.: Selectivenet: a deep neural network with an integrated reject option. arXiv preprint arXiv:1901.09192 (2019)
Ghesu, F.C., et al.: Quantifying and leveraging classification uncertainty for chest radiograph assessment. In: Shen, D., et al. (eds.) MICCAI 2019. LNCS, vol. 11769, pp. 676–684. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-32226-7_75
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 770–778 (2016)
Hellman, M.E.: The nearest neighbor classification rule with a reject option. IEEE Trans. Syst. Sci. Cybern. 6(3), 179–185 (1970)
Kermany, D.S., Goldbaum, M., Cai, W., Valentim, C.C., Liang, H., Baxter, S.L., McKeown, A., Yang, G., Wu, X., Yan, F., et al.: Identifying medical diagnoses and treatable diseases by image-based deep learning. Cell 172(5), 1122–1131 (2018)
LeCun, Y., Bengio, Y., Hinton, G.: Deep learning. Nature 521(7553), 436–444 (2015)
Sensoy, M., Kaplan, L., Kandemir, M.: Evidential deep learning to quantify classification uncertainty. In: Advances in Neural Information Processing Systems, pp. 3179–3189 (2018)
Tardy, M., Scheffer, B., Mateus, D.: Uncertainty measurements for the reliable classification of mammograms. In: Shen, D., et al. (eds.) MICCAI 2019. LNCS, vol. 11769, pp. 495–503. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-32226-7_55
Tong, Z., Xu, P., Denœux, T.: ConvNet and Dempster-Shafer theory for object recognition. In: Ben Amor, N., Quost, B., Theobald, M. (eds.) SUM 2019. LNCS (LNAI), vol. 11940, pp. 368–381. Springer, Cham (2019). https://doi.org/10.1007/978-3-030-35514-2_27
Yao, Y.: Three-way decisions with probabilistic rough sets. Inf. Sci. 180(3), 341–353 (2010)
Yue, X., Chen, Y., Miao, D., Fujita, H.: Fuzzy neighborhood covering for three-way classification. Inf. Sci. 507, 795–808 (2020)
Yue, X., Chen, Y., Miao, D., Qian, J.: Tri-partition neighborhood covering reduction for robust classification. Int. J. Approximate Reasoning 83, 371–384 (2017)
Yue, X., Zhou, J., Yao, Y., Miao, D.: Shadowed neighborhoods based on fuzzy rough transformation for three-way classification. IEEE Trans. Fuzzy Syst. 28(5), 978–991 (2020)
Acknowledgment
This work was supported by National Natural Science Foundation of China (Nos. 61976134, 61573235, 61991410, 61991415) and Open Project Foundation of Intelligent Information Processing Key Laboratory of Shanxi Province (No. CICIP2018001).
Author information
Authors and Affiliations
Corresponding author
Editor information
Editors and Affiliations
Rights and permissions
Copyright information
© 2020 Springer Nature Switzerland AG
About this paper

Cite this paper
Yuan, B., Yue, X., Lv, Y., Denoeux, T. (2020). Evidential Deep Neural Networks for Uncertain Data Classification. In: Li, G., Shen, H., Yuan, Y., Wang, X., Liu, H., Zhao, X. (eds) Knowledge Science, Engineering and Management. KSEM 2020. Lecture Notes in Computer Science(), vol 12275. Springer, Cham. https://doi.org/10.1007/978-3-030-55393-7_38
Download citation
DOI: https://doi.org/10.1007/978-3-030-55393-7_38
Published:
Publisher Name: Springer, Cham
Print ISBN: 978-3-030-55392-0
Online ISBN: 978-3-030-55393-7
eBook Packages: Computer ScienceComputer Science (R0)